Классификация статистических показателей
Критический момент – момент времени, по состоянию на который регистрируются данные. Устанавливается при исследовании динамично изменяющегося объекта
Виды статистических группировок
Частотные характеристики рядов распределения
Средняя арифметическая величина и ее расчет прямым способом
Степенные средние
Измерители вариации
Упрощенный способ расчета дисперсии и средне квадратического отклонения
Моменты распределения
Ошибка выборки
Малая выборка
Распространение результатов выборочного распределения на генеральную совокупность
Способ моментных наблюдений
Классификация методов исследования взаимосвязей
Парная регрессия
Множественная корреляция и регрессия
Обеспечение сопоставимости рядов динамики
Изучение основной тенденции развития, социально-экономического развития во времени
Корреляция в рядах динамики
Сводные индексы
Средние индексы
Навигация
Парная регрессия
Статистика
128810
знаков
46
таблиц
0
изображений
3. Парная регрессия.
Регрессия – это линия, характеризующая наиболее общую тенденцию во взаимосвязи факторного и результативного признаков.
Предполагается, что аналитическое уравнение выражает подлинную форму зависимости, а все отклонения от этой функции обусловлены действием различных случайных причин. Так как изучаются корреляционные связи, изменению факторного признака соответствует изменение среднего уровня результативного признака. При построении аналитических группировок мы рассматривали эмпирическую линию регрессии. Однако, эта линия не пригодна для экономического моделирования и ее форма зависит от произвола исследователя. Теоретически линия регрессии в меньшей степени зависит от субъективизма исследователя, однако, здесь так же может быть произвол при выборе формы или функции взаимосвязи. Считается, что выбор функции должен опираться на глубокое знание специфики предмета исследования.
На практике чаще всего применяются следующие формы регрессионных моделей:
- Линейная ;
- Полулогарифметическая кривая ;
- Гипербола ;
- Парабола второго порядка ;
- Показательная функция ;
- Степенная функция .
Помимо содержательного подхода существует формальная оценка адекватности подобранной регрессионной модели. Лучшей из них считается та, которая наименее удалена от исходных данных.
Данное свойство средней, гласящее, что сумма квадратов отклонений всех вариантов ряда от средней арифметической меньше суммы квадратов их отклонений от любого другого числа, положено в основу метода наименьших квадратов, позволяющего рассчитать параметры избранного уравнения регрессии таким образом, чтобы линия регрессии была в среднем наименее удалена от эмпирических данных.
Пример: данная система двух уравнений с двумя неизвестными а0 и а1 позволяет определить точное значение коэффициентов линейной регрессии.
Анализ формы и параметров взаимосвязи между ценой килограмма репчатого лука и объемом его продаж.
| Цена 1 кг лука, руб. | Объем продаж, кг | Товарооборот, руб. | ||||||
| 3 | 175 | 525 | 9 | -107,73 | 205,68 | -30,68 | 941,26 | 30625 |
| 3,5 | 200 | 700 | 12,25 | -125,69 | 187,73 | 12,28 | 150,68 | 40000 |
| 4 | 180 | 720 | 16 | -143,64 | 169,77 | 10,23 | 104,65 | 32400 |
| 4,5 | 150 | 675 | 20,25 | -161,60 | 151,82 | -1,815 | 3,29 | 22500 |
| 5 | 160 | 800 | 25 | -179,55 | 133,86 | 26,14 | 683,30 | 25600 |
| 5,5 | 120 | 660 | 30,25 | -197,51 | 115,91 | 4,09 | 16,77 | 14400 |
| 6 | 85 | 510 | 36 | -215,46 | 97,95 | -12,95 | 167,70 | 7225 |
| 6,5 | 90 | 585 | 42,25 | -233,42 | 80,00 | 10,00 | 100,10 | 8100 |
| 7 | 50 | 350 | 49 | -251,37 | 62,04 | -12,04 | 144,96 | 2500 |
| 7,5 | 40 | 300 | 56,25 | -269,33 | 44,09 | -4,09 | 16,69 | 1600 |
| 8 | 25 | 200 | 64 | -287,28 | 26,13 | -1,13 | 1,28 | 625 |
| 60,5 | 1275 | 6025 | 360,25 | -2172,56 | 1274,96 | 0,045 | 2330,68 | 185575 |
Предположим, что связь между ценой и объемом реализации лука линейная. Тогда для расчета параметров а0 и а1 необходимо решить систему уравнений
,
подставляя расчетные значения в систему нормальных уравнений и решая ее. Одним из методов получим коэффициенты уравнения линейной регрессии.
- уравнение регрессии или функция, характеризующая теоретическую зависимость объемов продаж лука от цены на него. Знак минус указывает на обратную зависимость.
Параметр а0 характеризует условное значение результативного признака при нулевом значении факторного признака (условный объем продаж лука при нулевой цене на него).
Параметры уравнения регрессии оцениваются на вероятностную надежность. Для этого величина каждого из параметров сравнивается с соответствующей средней ошибкой выборки, то есть , где - расчетное значение критерия Стьюдента, а - остаточное среднеквадратическое отклонение, характеризующее вариацию эмпирических значений результативного признака относительно соответствующих им теоретических значений (вариацию около линии регрессии).
Расчетное значение t критерия сравнивается с табличным значением для степеней свободы и заданной вероятности. Если p=0,95 то табличное значение равно t=2,262, то есть , следовательно, параметр а0 с вероятностью 0,95 надежен. Параметр а1 оценивается по формуле:
, где - это показатель вариации факторного признака.
В нашем примере удобнее всего рассчитывать по формуле:
Параметры уравнения регрессии надежны, следовательно, с вероятностью 0,95 можно утверждать, что полученное уравнение регрессии объективно отражает форму зависимости между ценой и объемом продаж лука.
По данным регрессионного анализа можно рассчитать коэффициент эластичности, характеризующий пропорцию взаимосвязи между вариацией факторного и результативного признаков.
Коэффициент эластичности показывает, что с ростом цены на 1%, объем реализации лука снижается на 1,7%.
4. Измерения тесноты связи.
Методы измерения тесноты взаимосвязи условно делятся на непараметрические и параметрические.
Непараметрические методы применяются для измерения тесноты связи качественных и альтернативных признаков, а так же количественных признаков, распределение которых отличается от нормального распределения.
Для измерения связи альтернативных признаков применяются коэффициент ассоциации Дэвида Юла и коэффициент контингенции Карла Пирсона. Для расчета этих показателей применяется следующая матрица взаимного распределения частот.
a, b, c, d – частоты взаимного распределения признаков.
| 1 признак 2 признак | ДА | НЕТ |
| ДА | a | b |
| НЕТ | c | d |
При прямой связи частоты сконцентрированы по диагонали a-d, при обратной связи по диагонали b-c, при отсутствии связи частоты практически равномерно распределены по всему полю таблицы.
Коэффициент ассоциации
Пример: проанализируем зависимость между полом и фактом совершения покупки посетителями магазина.
| 1 признак 2 признак | М | Ж | Итого |
| Купил | 24 | 32 | 56 |
| Не купил | 16 | 28 | 44 |
| Итого | 40 | 60 |
Наблюдается очень слабая прямая связь между полом и фактом свершения покупки. Предельное абсолютное значение коэффициента может быть близко к единице.
Коэффициент ассоциации непригоден для расчета в том случае, если одна из частот по диагонали равна 0. В этом случае применяется коэффициент контингенции, который рассчитывается по формуле:
Коэффициент контингенции также указывает на практическое отсутствие связи между признаками (его величина всегда меньше Кас).
Если значения признака распределены более чем по 2 группам, то для определения тесноты связи применяют коэффициенты взаимной сопряженности признаков Пирсона, Чупрова и др.
Показатель Пирсона определяется по формуле , где - показатель взаимной сопряженности признаков, который рассчитывается на основе матрицы взаимного распределения частот.
| 1 гр. | 2 гр. | 3 гр. | Итого | |
| 1 гр. | s11 | s12 | s13 | n1 |
| 2 гр. | s21 | s22 | s23 | n2 |
| 3 гр. | s31 | s32 | s33 | n3 |
| Итого | m1 | m2 | m3 |
Пример: рассмотрим зависимость между величиной магазина и формой обслуживания.
| Самообслуживание | Традиционное | Итого | |
| Мелкие магазины | 12 | 45 | 57 |
| Средние | 19 | 10 | 29 |
| Крупные | 14 | 4 | 18 |
| Итого | 45 | 59 |
Коэффициент свидетельствует о наличии заметной связи между величиной магазина и формой его обслуживания. Более точным показателем тесноты связи является коэффициент Чупрова, который определяется по формуле:
, где - соответственно число групп, выделенных по каждому признаку. В нашем примере:
Непараметрические методы измерения тесноты взаимосвязи количественных признаков были первыми из методов измерения тесноты взаимосвязи. Впервые попытался измерить тесноту связи в 30-ч годах 19 века французский ученый Гиррий. Он сопоставлял между собой среднегрупповые значения факторного и результативного признаков. При этом абсолютные значения заменялись их отношениями к некоторым константам. Полученные результаты ранжировались в порядке возрастания. О наличии или отсутствии связи Гиррий судил сопоставляя ранее по группам и подсчитывая количество совпадений и несовпадений рангов. Если преобладало число совпадений – связь считалась прямой. Несовпадение – обратной. При равенстве совпадений и несовпадений – связь отсутствовала.
Методика Гиррий была использована Фехнером при разработке своего коэффициента, а так же Спирменом при разработке коэффициента корреляции рангов.
Расчет коэффициента Фехнера.
| Цена 1 кг лука, руб. | Объем продаж, кг | Знаки отклонений | Сравнение знаков | |
| 3 | 175 | -2,5 | 59,1 | н |
| 3,5 | 200 | -2 | 84,1 | н |
| 4 | 180 | -1,5 | 64,1 | н |
| 4,5 | 150 | -1 | 34,1 | н |
| 5 | 160 | -0,5 | 44,1 | н |
| 5,5 | 120 | 0 | 4,1 | с |
| 6 | 85 | 0,5 | -30,9 | н |
| 6,5 | 90 | 1 | -25,9 | н |
| 7 | 50 | 1,5 | -65,9 | н |
| 7,5 | 40 | 2 | -75,9 | н |
| 8 | 25 | 2,5 | -90,9 | н |
Коэффициент указывает на наличие весьма тесной обратной связи.
На ряду с коэффициентом Фехнера для измерения взаимосвязи количественных признаков применяются коэффициенты корреляции рангов. Наиболее распространенным среди них является коэффициент корреляции рангов Спирмена.
Пример: вычисление коэффициента Спирмена для измерения тесноты взаимосвязи между товарооборотом и уровнем издержек обращения в магазинах.
| Однодневный товарооборот, тыс. руб. | Издержки в % к товарообороту | Ранги | Разность рангов | ||
| 18 | 20,5 | 1 | 4 | -3 | 9 |
| 23 | 23,4 | 2 | 6 | -4 | 16 |
| 29 | 21,2 | 3 | 5 | -2 | 4 |
| 45 | 18,9 | 4 | 2 | 2 | 4 |
| 78 | 19,2 | 5 | 3 | 2 | 4 |
| 93 | 17,5 | 6 | 1 | 5 | 25 |
| Всего | 62 | ||||
Коэффициент корреляции рангов может принимать значение в пределах от –1 (обратная связь, близкая к функциональной) до +1 (прямая связь, близкая к функциональной).
Непараметрические методы учитывают направления изменений значений признаков, но не зависят от того, насколько интенсивно колеблются значения результативного признака в результате изменения факторного признака. Это позволяют сделать параметрические методы.
Для измерения тесноты линейной взаимосвязи применяется коэффициент корреляции. Базовая форма коэффициента корреляции следующая:
Фактически, коэффициент корреляции – это среднее произведения нормативных отклонений:
Если связь между признаками отсутствует, то результативный признак не варьирует при изменении факторного признака, следовательно . Такой же результат получается при сбалансированности сумм отрицательных и положительных произведений.
Обычно для расчета коэффициента корреляции применяются формулы, использующие те показатели, которые уже рассчитывались при определении параметров уравнения регрессии. Наиболее удобной для расчетов является формула:
Величина коэффициента корреляции свидетельствует о наличии очень тесной обратной связи между признаками. Качественная оценка тесноты связи дается с помощью шкалы Чедока.
| Показатель тесноты связи | 0,1-0,3 | 0,3-0,5 | 0,5-0,7 | 0,7-0,9 | 0,9-0,99 | 1,0 |
| Характеристика связи | Слабая | Умеренная | Заметная | Тесная | Очень тесная | Функциональная |
Для оценки значимости коэффициента корреляции применяют критерий t-Стьюдента, расчетная величина критерия определяется по формуле:
Табличное значение критерия t-Стьюдента:
Следовательно, параметр надежен.
Для измерения тесноты криволинейных зависимостей применяются универсальные показатели тесноты связи, коэффициенты детерминации, теоретические корреляционные отношения или индексы корреляции. Эти показатели построены на принципе соизмерения дисперсий результативных признаков.
При этом по правилу сложения дисперсий получается взаимосвязь между дисперсиями: .
Коэффициент детерминации:
Теоретическое корреляционное отношение: .
Для линейной связи величина теоретического корреляционного отношения равна коэффициенту корреляции.
Индекс корреляции, по сути, аналогичен теоретическому корреляционному отношению, его рассчитывают на основе правила сложения дисперсий, используя общую и остаточную дисперсии.
Индекс корреляции:
Похожие работы
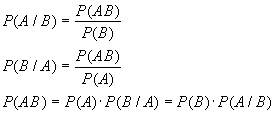
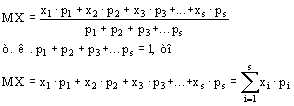
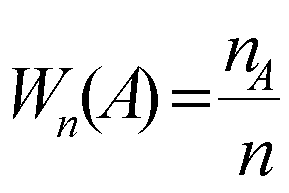
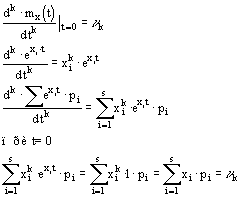
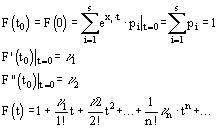
... Доказать: По определению второй смешанной производной. Найдем по двумерной плотности одномерные плотности случайных величин X и Y. Т.к. полученное равенство верно для всех х, то подинтегральные выражение аналогично В математической теории вероятности вводится как базовая формула (1) ибо предлагается, что плотность вероятности как аналитическая функция может не существовать. Но т.к. в нашем ...
... распределения генеральной совокупности F(x) и – эмпирической функция распределения Fn(x) , построенной по выборке х1,…,хn, называется функция. Теорема. Если F(x) непрерывна, то распределения статистики Колмогорова Dn не зависит от F(x). Условные математические ожидания и условные распределения. Св-ва условных мат. ожиданий. Аналоги формул полной вероятности и формулы Байеса для мат. ожиданий ГММЕ ...
... дает возможность статистического моделирования, происходящих в населении процессов. Потребность в моделировании возникает в случае невозможности исследования самого объекта. Наибольшее число моделей, применяемых в статистике населения, разработано для характеристики его динамики. Среди них выделяются экспоненциальные и логистические. Особое значение в прогнозе населения на будущие периоды имеют ...
... на задний план традиционными постановками. Несколько лет назад при описании современного этапа развития статистических методов нами были выделены [29] пять актуальных направлений, в которых развивается современная прикладная статистика, т.е. пять "точек роста": непараметрика, робастность, бутстреп, интервальная статистика, статистика объектов нечисловой природы. Обсудим их. 5. ...
0 комментариев