Базовые
функции языка
Средства
языка для работы
с числами.
(Математические
и логические
функции)
Функция
ввода
Последовательные
вычисления
Применяющие
функционалы
Точечная
нотация
Представление
знаний
Интерфейс
пользователя
Расширение
библиотеки
функций dlisp
П. Уинстон
Особенности
диалектов языка
Лисп
Понятия
языка Лисп
Основные
типы знаний
Навигация
5. П. Уинстон
«Искусственный интеллект»
Москва «Мир» 1980 г.
«Искусственный интеллект применение в интегрированных
производственных системах»
Москва «Машиностроение» 1991 г.
«Искусственный интеллект:
программные и аппаратные средства» Справочник.
Москва «Радио и связь» 1990 г. Т.3
Дж. Малпас
«Реляционный язык Пролог и его применение»
Москва «Наука» 1990 г.
И. Братко
«Программирование на языке Пролог для искусственного интеллекта»
Москва «Мир» 1990 г.
П. Грей
«Логика, алгебра и базы данных»
Москва «Машиностроение» 1983 г.
Л. Н. Преснухин, В. А. Шахнов
«Конструирование электронных вычислительных машин и систем»
Москва «Высшая школа» 1986 г.
«Основы инженерной психологии»
Москва «Высшая школа» 1986 г.
1 Литературный обзор.
Краткая история развития искусственного интеллекта.
Искусственный интеллект (ИИ) - это область исследований, находящаяся на стыке наук, специалисты, работающие в этой области, пытаются понять, какое поведение, считается разумным (анализ), и создать работающие модели этого поведения (синтез). Практической целью является создание методов и техники, необходимой для программирования «разумности» и ее передачи вычислительным машинам (ВМ), а через них всевозможным системам и средствам.[1]
В 50-х годах исследователи в области ИИ пытались строить разумные машины, имитируя мозг. Эти попытки оказались безуспешными по причине полной непригодности как аппаратных так и программных средств.
В 60-х годах предпринимались попытки отыскать общие методы решения широкого класса задач, моделируя сложный процесс мышления. Разработка универсальных программ оказалась слишком трудным и бесплодным делом. Чем шире класс задач, которые может решать одна программа, тем беднее оказываются ее возможности при решении конкретной проблемы.[5]
В начале 70-х годов специалисты в области ИИ сосредоточили свое внимание на разработке методов и приемов программирования, пригодных для решения более специализированных задач: методов представления (способы формулирования проблемы для решения на средствах вычислительной техники (ВТ)) и методах поиска (способы управления ходом решения так, чтобы оно не требовало слишком большого объема памяти и времени).
И только в конце 70-х годов была принята принципиально новая концепция, которая заключается в том, что для создания интеллектуальной программы ее необходимо снабдить множеством высококачественных специальных знаний о некоторой предметной области. Развитие этого направления привело к созданию экспертных систем (ЭС).[6]
В 80-х годах ИИ пережил второе рождение. Были широко осознаны его большие потенциальные возможности как в исследованиях, так и в развитии производства. В рамках новой технологии появились первые коммерческие программные продукты. В это время стала развиваться область машинного обучения. До этих пор перенесение знаний специалиста-эксперта в машинную программу было утомительной и долгой процедурой. Создание систем, автоматически улучшающих и расширяющих свой запас эвристических (не формальных, основанных на интуитивных соображениях) правил - важнейший этап в последние годы. В начале десятилетия в различных странах были начаты крупнейшие в истории обработки данных национальные и международные исследовательские проекты, нацеленные на «интеллектуальные ВМ пятого поколения».[1]
Исследования по ИИ часто классифицируются, исходя из области их применения, а не на основе различных теорий и школ. В каждой из этих областей на протяжении десятков лет разрабатывались свои методы программирования, формализмы; каждой из них присущи свои традиции, которые могут заметно отличаться от традиций соседней области исследования. В настоящее время ИИ применяется в следующих областях:
обработка естественного языка;
экспертные системы (ЭС);
символьные и алгебраические вычисления;
доказательства и логическое программирование;
программирование игр;
обработка сигналов и распознавание образов;
и др.
1.2 Языки программирования ИИ.
1.2.1 Классификация языков и стилей программирования.
Все языки программирования можно разделить на процедурные и декларативные языки. Подавляющее большинство используемых в настоящее время языков программирования (Си, Паскаль, Бейсик и т. п.) относятся к процедурным языкам. Наиболее существенными классами декларативных языков являются функциональные (Лисп, Лого, АПЛ и т. п.) и логические (Пролог, Плэнер, Конивер и др.) языки (рис.1).
На практике языки программирования не являются чисто процедурными, функциональными или логическими, а содержат в себе черты языков различных типов. На процедурном языке часто можно написать функциональную программу или ее часть и наоборот. Может точнее было бы вместо типа языка говорить о стиле или методе программирования. Естественно различные языки поддерживают разные стили в разной степени.[1]
Процедурная программа состоит из последовательности операторов и предложений, управляющих последовательностью их выполнения. Типичными операторами являются операторы присваивания и передачи управления, операторы ввода-вывода и специальные предложения для организации циклов. Из них можно составлять фрагменты программ и подпрограммы. В основе процедурного программирования лежат взятие значения какой-то переменной, совершение над ним действия и сохранения нового значения с помощью оператора присваивания, и так до тех пор пока не будет получено (и, возможно, напечатано) желаемое окончательное значение.[2]
ЯЗЫКИ ПРОГРАММИРОВАНИЯ
ПРОЦЕДУРНЫЕ ЯЗЫКИ ДЕКЛАРАТИВНЫЕ ЯЗЫКИ
Паскаль, Си, Фортран, ...
ЛОГИЧЕСКИЕ ЯЗЫКИ ФУНКЦИОНАЛЬНЫЕ ЯЗЫКИ
Пролог, Mandala... Лисп, Лого, АРЛ, ...
Рис.1 Классификация языков программирования
Логическое программирование - это один из подходов к информатике, при котором в качестве языка высокого уровня используется логика предикатов первого порядка в форме фраз Хорна. Логика предикатов первого порядка - это универсальный абстрактный язык предназначенный для представления знаний и для решения задач. Его можно рассматривать как общую теорию отношений. Логическое программирование базируется на подмножестве логики предикатов первого порядка, при этом оно одинаково широко с ней по сфере охвата. Логическое программирование дает возможность программисту описывать ситуацию при помощи формул логики предикатов, а затем, для выполнения выводов из этих формул, применить автоматический решатель задач (т. е. некоторую процедуру). При использовании языка логического программирования основное внимание уделяется описанию структуры прикладной задачи, а не выработке предписаний компьютеру о том, что ему следует делать. Другие понятия информатики из таких областей, как теория реляционных баз данных, программная инженерия и представление знаний, также можно описать (и, следовательно, реализовать) с помощью логических программ.[8].
Функциональная программа состоит из совокупности определений функций. Функции, в свою очередь, представляют собой вызовы других функций и предложений, управляющих последовательностью вызовов. Вычисления начинаются с вызова некоторой функции, которая в свою очередь вызывает функции, входящие в ее определение и т. д. в соответствии с иерархией определений и структурой условных предложений. Функции часто либо прямо, либо опосредованно вызывают сами себя.[2]
Каждый вызов возвращает некоторое значение в вызывавшую его функцию, вычисление которой после этого продолжается; этот процесс повторяется до тех пор пока запустившая вычисления функция не вернет конечный результат пользователю.
«Чистое» функциональное программирование не признает присваиваний и передач управления. Разветвление вычислений основано на механизме обработки аргументов условного предложения. Повторные вычисления осуществляются через рекурсию, являющуюся основным средством функционального программирования.[1]
Сравнительные характеристики языков ИИ.
На первом этапе развития ИИ (в конце 50-х - начале 60-х годов) не существовало языков и систем, ориентированных специально на области знаний. Появившиеся к тому времени универсальные языки программирования казались подходящим инструментом для создания любых (в том числе и интеллектуальных ) систем, поскольку в этих языках можно выделить декларативную и процедурную компоненты. Казалось, что на этой базе могут быть интерпретированы любые модели и системы представления знаний. Но сложность и трудоемкость таких интерпретаций оказались настолько велики, что прикладные системы для реализации были недоступны. Исследования показали, что производительность труда программиста остается постоянной независимо от уровня инструментального языка, на котором он работает, а соотношение между длиной исходной и результирующей программ примерно 1:10. Таким образом, использование адекватного инструментального языка повышает производительность труда разработчика системы на порядок, и это при одноступенчатой трансляции. Языки предназначенные для программирования интеллектуальных систем содержат иерархические (многоуровневые) трансляторы и увеличивают производительность труда в 100-ни раз. Все это подтверждает важность использования адекватных инструментальных средств.[7]
Языки обработки символьной информации.
Лисп.
Язык Лисп был разработан в Стэнфорде под руководством Дж. Маккарти в начале 60-х годов. По первоначальным замыслам он должен был0 включать наряду со всеми возможностями Фортрана средства работы с матрицами, указателями и структурами из указателей и т. п. Но для такого проекта не хватило средств. Окончательно сформированные принципы положенные в основу языка Лисп: использование единого спискового представления для программ и данных; применение выражений для определения функций; скобочный синтаксис языка.[4]
Лисп является языком низкого уровня, его можно рассматривать как ассемблер, ориентированный на работу со списковыми структурами. Поэтому на протяжении всего существования языка было много попыток его усовершенствования за счет введения дополнительных базисных примитивов и управляющих структур. Но все эти изменения , как правило, не становились самостоятельными языками. В новых своих редакциях Лисп быстро усваивал все ценные изобретения своих конкурентов.[2]
После создания в начале 70-х годов мощных Лисп-систем Маклисп Интерлисп попытки создания языков ИИ, отличных от Лиспа, но на той же основе, сходят на нет. Дальнейшее развитие языка идет, с одной стороны, по пути его стандартизации (Стандарт-Лисп, Франц-Лисп, Коммон Лисп), а с другой - в направлении создания концептуально новых языков для представления и манипулирования знаниями в Лисп среде. В настоящее время Лисп реализован на всех классах ЭВМ, начиная с ПЭВМ и кончая высоко производительными вычислительными системами.
Лисп - не единственный язык, используемый для задач ИИ. Уже в середине 60-х годов разрабатывались языки, предлагающие другие концептуальные основы. Наиболее важные из них в области обработки символьной информации - СНОБОЛ и Рефал.
СНОБОЛ.
Это язык обработки строк, в рамках которого впервые появилась и была реализована в достаточно полной мере концепция поиска по образцу. Язык СНОБОЛ был одной из первых практических реализаций развитой продукционной системы. Наиболее известная и интересная версия этого языка - Снобол-4 Здесь техника задания образцов и работа с ними существенно опередили потребности практики. По существу, он так и остался «фирменным» языком программирования, хотя концепции СНОБОЛа, безусловно, оказали влияние и на Лисп, и на другие языки программирования задач ИИ.
Рефал.
Язык Рефал - алгоритмический язык рекурсивных функций. Он был создан Турчиным в качестве метаязыка, предназначенного для описания различных, в том числе и алгоритмических, языков и различных видов обработки таких языков. При этом имелось в виду и использование Рефала в качестве метаязыка над самим собой. Для пользователя это язык обработки символьной информации. Поэтому, помимо описания семантики алгоритмических языков, он нашел и другие применения. Это выполнение громоздких аналитических выкладок в теоретической физике и прикладной математике, интерпретация и компиляция языков программирования, доказательство теорем, моделирование целенаправленного поведения, а в последнее время и задачи ИИ. Общим для всех этих применений являются сложные преобразования над объектами, определенными в некоторых формализованных языках.
В основу языка Рефал положено понятие рекурсивной функции, определенной на множестве произвольных символьных выражений. Базовой структурой данных этого языка являются списки, но не односвязные, как в Лиспе, а двунаправленные. Обработка символов ближе к продукционной парадигме. При этом Активно используется концепция поиска по образцу, характерная для СНОБОЛа.
Программа написанная на Рефале, определяет некоторый набор функций, каждая из которых имеет один аргумент. Вызов функции заключается в функциональные скобки.
Во многих случаях возникает необходимость из программ, написанных на Рефале, вызывать программы, написанные на других языках. Это просто, так как с точки зрения Рефала первичные функции (Функции, описанные не на Рефале, но которые тем не менее можно вызывать из программ, написанных на этом языке.) - это просто некоторые функции, внешние по отношению к данной программе, поэтому, вызывая какую-либо функцию, можно даже и не знать, что это - первичная функция.
Семантика Рефал-программы описывается в терминах абстрактной Рефал-машины. Рефал-машина имеет поле памяти и поле зрения. В поле памяти Рефал-машины помещается программа, а в поле зрения - данные, которые будут обрабатываться с ее помощью, т. е. перед началом работы в поле памяти заносится описание набора функций, а в поле зрения - выражение, подлежащее обработке.
Часто бывает удобно разбить Рефал-программу на части, которые могут обрабатываться компилятором Рефала независимо друг от друга. Наименьшая часть Рефал-программы, которая может быть обработана компилятором независимо от других, называется модулем. Результат компиляции исходного модуля на Рефале представляет собой объектный модуль, который перед исполнением Рефал-программы должен быть объединен с другими модулями, полученными компиляцией с Рефала или других языков это объединение выполняется с помощью редактора связей и загрузчиков. Детали зависят от используемой ОС.
Таким образом, Рефал вобрал в себя лучшие черты наиболее интересных языков обработки символьной информации 60-х годов. В настоящее время язык Рефал используется для автоматизации построения трансляторов, систем аналитических преобразований, а также, подобно Лиспу, в качестве инструментальной среды для реализации языков представления знаний.[7]
Пролог.
В начале 70-х годов появился новый язык составивший конкуренцию Лиспу при реализации систем, ориентированных на знания - Пролог. Этот язык не дает новых сверхмощных средств программирования по сравнению с Лиспом, но поддерживает другую модель организации вычислений. Его привлекательность с практической точки зрения состоит в том, что, подобно тому, как Лисп скрыл от программиста устройство памяти ЭВМ, Пролог позволил ему не заботится о потоке управления в программе.[8]
Пролог - европейский язык, был разработан в Марсельском университете в 1971 году. Но популярность он стал приобретать только в начале 80-х годов. Это связано с двумя обстоятельствами: во-первых, был обоснован логический базис этого языка и, во-вторых, в японском проекте вычислительных систем пятого поколения он был выбран в качестве базового для одной из центральных компонент - машины вывода.
Язык Пролог базируется на ограниченном наборе механизмов, включающих в себя сопоставление образцов, древовидное представление структур данных и автоматический возврат. Пролог особенно хорошо приспособлен для решения задач, в которых фигурируют объекты и отношения между ними.[9]
Пролог обладает мощными средствами, позволяющими извлекать информацию из баз данных, причем методы поиска данных, используемые в нем, принципиально отличаются от традиционных. Мощь и гибкость баз данных Пролога, легкость их расширения и модификации делают этот язык очень удобным для коммерческих приложений.
Пролог успешно применяется в таких областях как: реляционные базы данных (язык особенно полезен при создании интерфейсов реляционных баз данных с пользователем); автоматическое решение задач; понимание естественного языка; реализация языков программирования; представление знаний; экспертные системы и др. задачи ИИ.[9]
Теоретической основой Пролога является исчисление предикатов. Прологу присущ ряд свойств, которыми не обладают традиционные языки программирования. К таким свойствам относятся механизм вывода с поиском и возвратом, встроенный механизм сопоставления с образцом. Пролог отличает единообразие программ и данных. Они являются лишь различными точками зрения на объекты Пролога. В языке отсутствуют указатели, операторы присваивания и безусловного перехода. Естественным методом программирования является рекурсия.
Пролог программа состоит из двух частей: базы данных (множество аксиом) и последовательности целевых утверждений, описывающих в совокупности отрицание доказываемой теоремы. Главное принципиальное отличие интерпретации программы на Прологе от процедуры доказательства теоремы в исчислении предикатов первого порядка состоит в том, что аксиомы в базе данных упорядочены и порядок их следования весьма существенен, так как на этом основан сам алгоритм, реализуемый Пролог-программы. Другое существенное ограничение Пролога в том, что в качестве логических аксиом используются формулы ограниченного класса - так называемые дизъюнкты Хорна. Однако при решении многих практических задач этого достаточно для адекватного представления знаний. Во фразах Хорна после единственного заключения следует ноль и более условий.
Поиск «полезных» для доказательства формул - комбинаторная задача и при увеличении числа аксиом число шагов вывода катастрофически быстро растет. Поэтому в реальных системах применяют всевозможные стратегии, ограничивающие слепой перебор. В языке Пролог реализована стратегия линейной резолюции, предлагающая использование на каждом шаге в качестве одной из сравниваемых формул отрицание теоремы или ее «потомка», а в качестве другой - одну из аксиом. При этом выбор той или иной аксиомы для сравнения может сразу или через несколько шагов завести в «тупик». Это принуждает вернуться к точке, в которой производился выбор, чтобы испытать новую альтернативу, и т. д. Порядок просмотра альтернативных аксиом не произволен - его задает программист, располагая аксиомы в базе данных в определенном порядке. Кроме того в Прологе предусмотрены достаточно удобные «встроенные» средства для запрещения возврата в ту или иную точку в зависимости от выполнения определенных условий. Таким образом процесс доказательства в Прологе более прост и целенаправлен чем в классическом методе резолюций.
Смысл программы языка Пролог может быть понят либо с позиций декларативного подхода, либо с позиций процедурного подхода.[8]
Декларативный смысл программы определяет, является ли данная цель истинной (достижимой) и, если да, при каких значениях переменных она достигается. Он подчеркивает статическое существование отношений. Порядок следования подцелей в правиле не влияет на декларативный смысл этого правила. Декларативная модель более близка к семантике логики предикатов, что делает Пролог эффективным языком для представления знаний. Однако в декларативной модели нельзя адекватно представить те фразы, в которых важен порядок следования подцелей. Для пояснения смысла фраз такого рода необходимо воспользоваться процедурной моделью.
При процедурной трактовке Пролог-программы определяются не только логические связи между головой предложения и целями в его теле, но еще и порядок, в котором эти цели обрабатываются. Но процедурная модель не годится для разъяснения смысла фраз, вызывающих побочные эффекты управления, такие как остановка выполнения запроса или удаление фразы из программы.[9]
Для решения реальных задач ИИ необходимы машины, скорость которых должна превышать скорость света, а это возможно лишь в параллельных системах. Поэтому последовательные реализации следует рассматривать как рабочие станции для создания программного обеспечения будущих высокопроизводительных параллельных систем, способных выполнять сотни миллионов логических выводов в секунду. В настоящее время существуют десятки моделей параллельного выполнения логических программ вообще и Пролог-программ в частности. Часто это модели, использующие традиционный подход к организации параллельных вычислений: множество параллельно работающих и взаимодействующих процессов. В последнее время значительное внимание уделяется и более современным схемам организации параллельных вычислений - потоковым моделям. В моделях параллельного выполнения рассматриваются традиционный Пролог и присущие ему источники параллельности.
На эффективности Пролога очень сильно сказываются ограниченность ресурсов по времени и пространству. Это связано с неприспособленностью традиционной архитектуры вычислительных машин для реализации прологовского способа выполнения программ, предусматривающего достижение целей из некоторого списка. Вызовет ли это трудности в практических приложениях, зависит от задачи. Фактор времени практически не имеет значения, если пролог-программа, запускаемая по несколько раз в день, занимает одну секунду, а соответствующая программа на другом языке - 0.1 секунды. Но разница в эффективности становится существенной, если эти две программы требуют 50 и 5 минут соответственно.
С другой стороны, во многих областях применения Пролога он может существенно сократить время разработки программ. Программы на Прологе легче писать, легче понимать и отлаживать, чем программы, написанные на традиционных языках, т. е. язык Пролог привлекателен своей простотой. Пролог-программу легко читать, что является фактором, способствующим повышению производительности при программировании и увеличению удобств при сопровождении программ. Поскольку Пролог основан на фразах Хорна, исходный текст Пролог-программ значительно менее подвержен влиянию машинно-зависимых особенностей, чем исходные тексты программ, написанных на других языках. Кроме того в различных версиях языка Пролог проявляется тенденция к единообразию, так что программу, написанную для одной версии, легко можно преобразовать в программу для другой версии этого языка. Кроме того Пролог прост в изучении.[8]
При выборе языка Пролог как базового языка программирования в японском проекте вычислительных систем пятого поколения в качестве одного из его недостатков отмечалось отсутствие развитой среды программирования и неприспособленность Пролога для создания больших программных систем. Сейчас ситуация несколько изменилась, хотя говорить о действительно ориентированной на логическое программирование среде преждевременно.
Среди языков, с появлением которых возникали новые представления о реализации интеллектуальных систем, необходимо выделить языки, ориентированные на программирование поисковых задач.
Языки программирования интеллектуальных решателей.
Группа языков, которые можно назвать языками интеллектуальных решателей, в основном ориентирована на такую подобласть ИИ, как решение проблем, для которой характерны, с одной стороны, достаточно простые и хорошо формализуемые модели задач, а с другой - усложненные методы поиска их решения. Поэтому основное внимание в этих языках было уделено введению мощных структур управления, а не способам представления знаний. Это такие языки как Плэнер, Конивер, КюА-4, КюЛисп.
Плэнер.
Этот язык дал толчок мощному языкотворчеству в области ИИ. Язык разработан в Массачуссетском технологическом институте в 1967-1971гг. Вначале это была надстройка над Лиспом, в таком виде язык реализован на Маклиспе под названием Микро Плэнер. В дальнейшем Плэнер был существенно расширен и превращен в самостоятельный язык. В СССР он реализован под названием Плэнер-БЭСМ и Плэнер-Эльбрус. Этот язык ввел в языки программирования много новых идей: автоматический поиск с возвратами, поиск данных по образцу, вызов процедур по образцу, дедуктивный метод и т. д.
В качестве своего подмножества Плэнер содержит практически весь Лисп (с некоторыми модификациями) и во многом сохраняет его специфические особенности. Структура данных (выражений, атомов и списков), синтаксис программ и правила их вычисления в Плэнере аналогичны лисповским. Для обработки данных в Плэнере в основном используются те же средства, что и в Лиспе: рекурсивные и блочные функции. Практически все встроенные функции Лиспа, в том числе и функция EVAL, включены в Плэнер. Аналогично определяются новые функции. Как и в Лиспе , с атомами могут быть связаны списки свойств.
Но между Лиспом и Плэнером существуют и различия. Отметим некоторые из них. В Лиспе при обращении к переменной указывается только ее имя, например Х, сам же атом как данное указывается как ‘X. В Плэнере используется обратная нотация: атомы обозначают самих себя, а при обращении к переменным перед их именем ставится префикс. При этом префикс указывает как должна быть использована переменная. Отличается от лисповского и синтаксис обращения к функциям, которое в Плэнере записывается в виде списка не с круглыми, а с квадратными скобками.
Для обработки данных в Плэнере используются не только функции, но и образцы и сопоставители.
Образцы описывают правила анализа и декомпозиции данных и поэтому их применение облегчает написание программ и сокращает их тексты.
Сопоставители определяются также, как функции, только их определяющее выражение начинается с ключевого слова, а в качестве тела указывается образец. Их выполнение заключается не в вычислении какого либо значения, а в проверке, обладает ли сопоставляемое с ним выражение определенным свойством.
Рассмотренное подмножество Плэнера можно использовать независимо от других его частей: оно представляет собой мощный язык программирования, удобный для реализации различных систем символьной обработки. Остальные части Плэнера ориентируют его на область ИИ, предоставляя средства для описания задач (исходных ситуаций, допустимых операций, целей), решения которых должна искать система ИИ, реализуемая на Плэнере, и средства, упрощающие реализацию процедур поиска решения этих задач.
На Плэнере можно программировать описывая то, что имеется и то что надо получить, без явного указания, как это делать. Ответственность же за поиск решения описываемой задачи берет на себя встроенный в язык дедуктивный механизм (механизм автоматического достижения целей), в основе которого лежит вызов теорем по образцу. Однако только вызова теорем по образцу не достаточно для такого механизма. Необходим механизм перебора, и такой механизм - режим возвратов - введен в язык.
Выполнение программы в режиме возвратов удобно для ее автора тем, что язык берет на себя ответственность за запоминание развилок и оставшихся в них альтернатив, за осуществление возвратов к ним и восстановления прежнего состояния программы - все это делается автоматически. Но такой автоматизм не всегда выгоден, так как в общем случае он ведет к «слепому» перебору. И может оказаться так, что при вызове теорем наиболее подходящая из них будет вызвана последней, хотя автор программы заранее знает о ее достоинствах. Учитывая это Плэнер предоставляет средства управления режимом возвратов.[7]
Конивер.
Язык Конивер был разработан в 1972 году, реализован как надстройка над языком Маклисп. Авторы языка Конивер выступили с критикой некоторых идей языка Плэнер. В основном она относилась к автоматическому режиму возвратов, который в общем случае ведет к неэффективным и неконтролируемым программам, особенно если она составляется неквалифицированными пользователями. Авторы Конивер отказались от автоматического режима возвратов, считая, что встраивать в язык какие-то фиксированные дисциплины управления (кроме простейших - циклов, рекурсий) не следует и что автор программы должен сам организовывать нужные ему дисциплины управления, а для этого язык должен открывать пользователю свою структуру управления и предоставлять средства работы с ней. Эта концепция была реализована в Конивер следующим образом.
При вызове процедуры в памяти отводится место, где хранится информация, необходимая для ее работы. Здесь, в частности, располагаются локальные переменные процедуры, указатели доступа (ссылка на процедуру, переменные которой доступны из данной) и возврата (ссылка на процедуру, которой надо вернуть управление). Обычно эта информация скрыта от пользователя, а в языке Конивер такой участок памяти (фрейм) открыт: пользователь может просматривать и менять содержимое фрейма. В языке фреймы представляют специальный тип данных, доступ к которым осуществляется по указателям.
Недостаток языка в том, что хотя пользователь и получает гибкие средства управления, одновременно на него ложится трудная и кропотливая работа, требующая высокой квалификации. Язык Конивер хорош не для реализации сложных систем, а как база, на основе которой квалифицированные программисты готовят нужные механизмы управления для других пользователей.
Учитывая сложность реализации дисциплин управления, авторы языка были вынуждены включить в него ряд фиксированных механизмов управления, аналогов процедур-развилок и теорем языка Плэнер. Но в отличии от Плэнера, где разрыв между выбором альтернативы в развилке и ее анализом, а в случае необходимости выработкой неуспеха может быть сколь угодно велик, в языке Конивер этот разрыв сведен к минимуму. Этим Конивер избавляется от негативных последствий глобальных возвратов по неуспеху, когда приходится отменять предыдущую работу чуть ли не всей программы.[7]
Языки представления знаний.
В рамках каждого базового языка ИИ явным образом выделяются и прямое его использование, и расширение за счет пакетов функций, и создание «автономного» языка представления знаний (ЯПЗ) с последующей интерпретацией или компиляцией программ на созданном языке. Но в последнем случае базовый язык, как правило, становится инструментальным средством для реализации ЯПЗ.
Независимо от реализации ЯПЗ должен отвечать следующим требованиям:
наличие простых и вместе с тем достаточно мощных средств представления сложно структурированных и взаимосвязанных объектов;
возможность отображения описаний объектов на разные виды памяти ЭВМ;
наличие гибких средств управления выводом, учитывающих необходимость структурирования правил работы решателя;
«прозрачность» системных механизмов для программиста, т. е. возможность их до определения и переопределения на уровне входного языка;
возможность эффективной реализации, как программной, так и аппаратной;
Конечно, перечисленные требования во многом противоречивы. Но лишь тогда, когда в рамках разумного компромисса учтены все эти требования, создаются удачные ЯПЗ.
Среди ЯПЗ первого поколения (70-е годы) лишь некоторые сыграли заметную роль в программной поддержке систем представления знаний (СПЗ). Выделим среди них KRL, FRL, KL-ONE. Характерными чертами этих языков были: двухуровневое представление данных, представление закономерностей предметной области и связей между понятиями в виде присоединенных процедур, семантический подход к сопоставлению образцов и поиску по образцу.
KRL.
Один из самых интересных языков этой группы - KRL, в основу которого были положены следующие концепции: организация знаний в виде специально выделенных единиц с присоединенными описаниями и процедурами; наличие средств представления многоаспектного и/или неполного знания об объектах; возможность описания объектов через сопоставление их с другими объектами с учетом уточняющих описаний; наличие гибкого набора базовых средств описания стратегий вывода решений и возможность их динамического изменения. Однако KRL широко не использовался в интеллектуальных системах из-за некоторой его громоздкости и отсутствия собственных средств описания процедур. Как следствие, в KRL активно использовался Лисп. Часто нельзя было понять, имеем мы дело с KRL-программой и присоединенными Лисп-функциями или с Лисп-программой, в которой применяется KRL как способ представления данных.
FRL.
Язык FRL не самостоятельный язык, а хорошо продуманная библиотечная система над Лиспом. В FRL не предлагается принципиально новых по сравнению с KRL концепций представления знаний, но тем не менее он оказался более удобным благодаря тщательному и экономному отбору базовых алгоритмических средств, а также более простому их синтаксическому оформлению. Здесь имеются развитые средства манипулирования иерархическими списками свойств объектов, включая механизмы наследования свойств и набор присоединенных к описаниям процедур.
Для всех ЯПЗ по сравнению с традиционными языками программирования характерна существенно большая «активность» данных, что приводит к стиранию граней между декларативной и процедурной компонентами. Кроме того, реальные объемы обрабатываемых данных требуют при реализации ЯПЗ использования концепции базы данных и методов, развитых при создании СУБД. И, наконец, ЯПЗ тяготеют больше к режиму интерпретации, чем к компиляции, характерной для реализации обычных языков программирования. В области разработки и реализации ЯПЗ можно выделить три круга проблем: определение входных языков СПЗ; выбор выходного языка соответствующего транслятора и собственно проблемы этапа трансляции.
Входной язык СПЗ должен быть близок к языку предметной области и по лексике, и по синтаксису, и по семантике.
От выбора выходного языка зависит не только эффективность, но и сама возможность реализации ЯПЗ. Выходной язык должен отвечать по крайней мере следующим требованиям: иметь достаточно большой набор примитивов работы с образцами; обладать встроенными средствами эффективной поддержки рекурсии; иметь гибкие средства описания потоков управления. Кроме того, в рамках выходного языка необходимы средства отображения данных на основную и внешнюю память и удобные средства работы с этими данными. И, наконец, желательно, чтобы в нем имелись достаточно развитые средства определения новых типов данных.
В настоящее время языков программирования, где имела бы место эффективная реализация всех указанных требований, пока нет. Поэтому выбор целевого языка ЯПЗ-транслятора всегда компромисс.
На данном этапе существует сотни языков и систем представления знаний. Поэтому рассмотрим лишь некоторые особенности нескольких ЯПЗ.
RLL.
Это фреймовый язык представления знаний (представитель популярного в 70-х годах подхода «фреймы до конца», является инструментальной средой для создания специализированных ЯПЗ.
Подобно другим инструментальным средствам, RLL содержит два слоя: базисные примитивы и средства их комбинирования на более высоком уровне, чем Лисп. При этом технология конструирования специальных ЯПЗ в рамках RLL-среды сводится, как правило, к редактированию уже существующих заготовок и последующему конвертированию их в Лисп.
Учитывая последовательную ориентацию RLL на концепцию фреймов, все структуры (декларативные и процедурные), более сложные чем список значений, описываются здесь в виде фрейм-подобных RLL-элементов.
С помощью RLL-элементов описываются понятия не только предметной области, но и самой RLL-среды (например, слот, механизм наследования, структура управления и т. д.). Заранее на уровне RLL-интерпретатора или конвертора фиксируется семантика ограниченного числа системных понятий - это множества, списки, слоты и др. RLL-элементы имеют явно специфицированные родовидовые отношения, которые также являются системными понятиями, и встроенный механизм описания отношений с помощью многосвязных списков.
В RLL имеется и библиотека удачных управляющих структур, и определенные средства конструирования из них решателей, необходимых для конкретной ЭС.
Одним из основных стандартных механизмов вывода решений в RLL является agenda (управляющий список с динамической коррекцией элементов).
ART.
Этот язык демонстрирует другую парадигму «фреймы плюс продукции», характерную для начала 80-х годов. Это не только язык представления знаний, но и определенное программное окружение, включающее редакторы, отладчики, трансляторы и модули управления.
Входной язык системы ART весьма гибкий и обеспечивает использование фактов, схем, комбинаций этих понятий и правил. Декларативную компоненту этого ЯПЗ составляют факты и схемы. По определению, факт включает три основных компонента: утверждение, значение истинности и точку зрения. С каждым утверждением может быть связано одно из трех значений истинности true, false или unknown, а также определенные сферы его справедливости, которое и называется точкой зрения. Факты описываются экземплярами фреймов. Фреймы-прототипы в ART представляются схемами, каждая из которых описывает объекты и/или классы объектов с фиксированными свойствами. Механизмы наследования свойств при этом поддерживаются самой системой.
В целом язык ART погружен в Лисп-среду, так что синтаксически и фреймовые и продукционные структуры выражаются здесь как атомы, функции и списки языка Лисп. Такой подход в ART естественен, так как первоначально был реализован на Лисп-машинах. Средства описания фактов в языке ART почти полностью «отданы на откуп» Лиспу, что снижает концептуальную целостность языка , так как средства описания схем и правил здесь хотя и похожи на лисповские, но свои. В ART пользователю дается небольшой набор встроенных стратегий вывода решений и весьма ограниченный выбор из ART-действий, взаимодействующих с модулем вывода. Но в системе имеется возможность выхода в базовый язык Лисп, где программируются любые управляющие стратегии.
В полном объеме ART представляет разработчику ЭС достаточно мощные средства представления знаний, но эффективно в системе ART могут работать только квалифицированные Лисп-программисты, готовые реализовать в этом языке все процедуры поддержки ЯПЗ.
Дальнейшее развитие ЯПЗ смещается в сторону продукций. Вместе с тем в настоящее время уже редко удается классифицировать языки и системы представления знаний на шкале «фреймы - продукции - семантические сети - ...» однозначно. И хотя тот или иной формализм представления знаний накладывает в большей или меньшей степени свой отпечаток на соответствующий ЯПЗ, современные языки и системы, как правило, поддерживают несколько формализмов одновременно.
Похожие работы
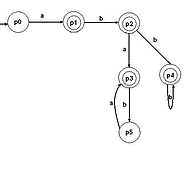
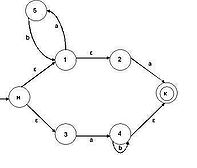
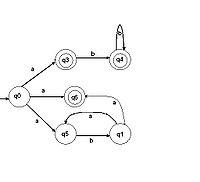
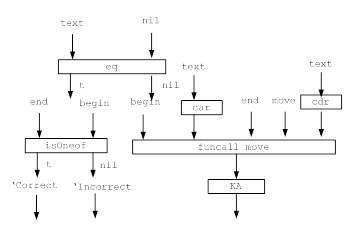
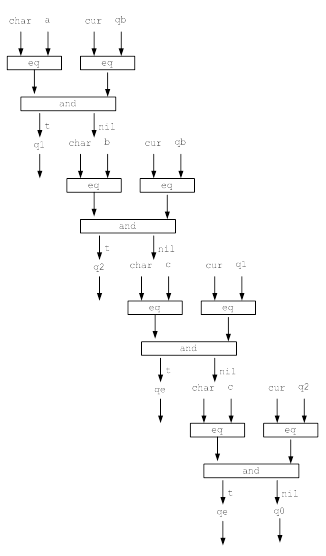
... цифр с требуемым числом разрядов и, таким образом, запомнить любое самое большое число данной разрядности. Целью данной курсовой работы является ЛИСП-реализация конечных автоматов.1. Постановка задачи Конечный автомат – автомат, проверяющий допустимость слова на ленте, и возвращающий True / False (в данном случае Correct / Incorrect). Конечный автомат может двигаться по ленте только в одном ...
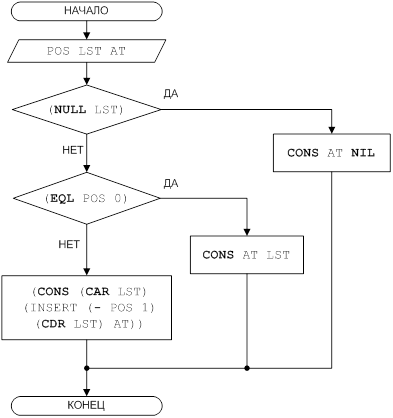
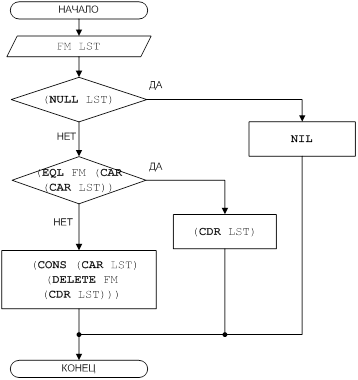
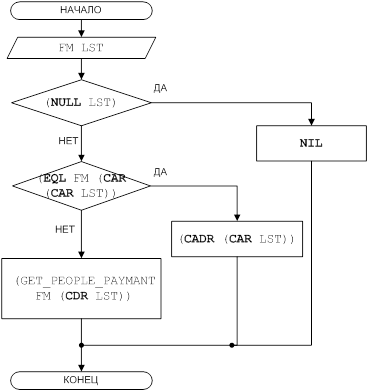
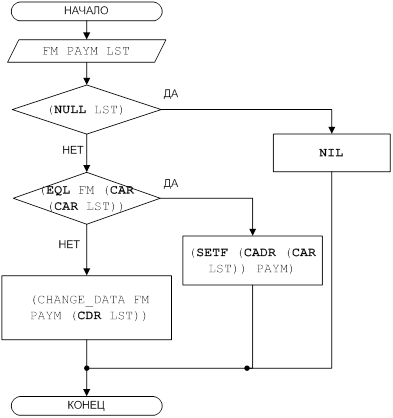
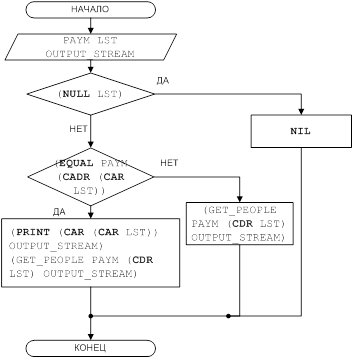
... При работе пользователя с базой данных над ее содержимым выполняются следующие основные операции: выбор, добавление, модификация (замена) и удаление данных. Целью данной курсовой работы является ЛИСП – реализация основных операций над базами данных. 1 Постановка задачи Требуется разработать программу, реализующую основные операции над базами данных: выбор, добавление, модификация и удаление ...
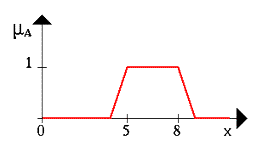
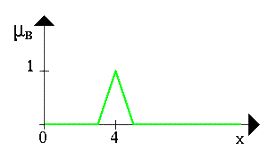
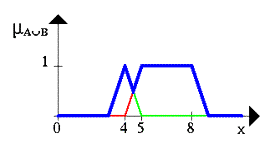
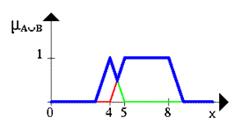
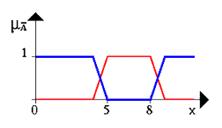
... новых рынков, биржевой игре, оценки политических рейтингов, выборе оптимальной ценовой стратегии и т.п. Появились и коммерческие системы массового применения. Целью данной курсовой работы является ЛИСП – реализация основных операций над нечеткими множествами. 1.Постановка задачи Требуется реализовать основные операции над нечеткими множествами: 1) содержание; 2) равенство; 3) ...
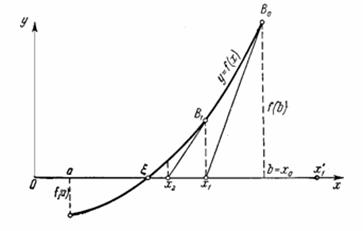
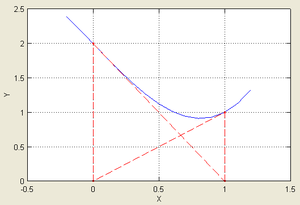
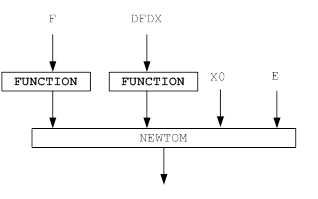

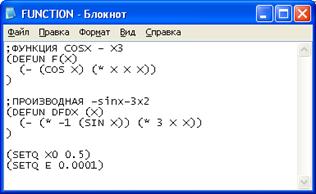
... метода Ньютона на случай мнимых корней полиномов степени выше второй и комплексных начальных приближений. Эта работа открыла путь к изучению теории фракталов. Целью данной курсовой работы является Лисп – реализация нахождения корней уравнения методом Ньютона. 1. Постановка задачи Дано уравнение: . Требуется решить это уравнение, точнее, найти один из его корней (предполагается, что ...
0 комментариев