Производительность. СУБД должна выполнять свои функции с максимальной производительностью
Заголовок содержит фиксированное множество атрибутов или, точнее, пар <имя‑атрибута : имя‑домена>:
На практике большинство отношений имеют только один потенциальный ключ, хотя в общем случае их может быть несколько
Если каждое из них имеет одно и то же множество имен атрибутов (следовательно, заметьте, они заведомо должны иметь одну и ту же степень);
Следует заметить, что речь здесь пойдет о логическом, а не физическом макете
Правая часть (зависимая часть) каждой ФЗ множества S содержит только один атрибут (т.е. является одноэлементным множеством)
Диаграммы ER-экзрмпляров
Степени связи между сущностями (1:1, 1:М, М:1, М:М);
Булевы данные. Некоторые СУБД явным образом поддерживают логические значения (TRUE или FALSE)
Константа, показывающая, что в каждой строке результатов запроса должно содержаться одно и то же значение
Пользователь имеет доступ к объекту, только если его уровень допуска больше или равен уровню классификации объекта
ALTER – позволяет модифицировать структуру таблиц (DB2, Oracle);
Далее этот процесс следует повторить для вставки среднего значения W в родительский элемент Р на более высоком структурном уровне
В последовательности проекций данного отношения можно игнорировать все проекции, кроме последней. Таким образом, выражение
Долговечность. Когда транзакция выполнена, ее обновления сохраняются, даже если в следующий момент произойдет сбой системы
Транзакция, предназначенная для извлечения кортежа, прежде всего должна наложить S‑блокировку на этот кортеж
Перед выполнением каких-либо операций с некоторым объектом (например, с кортежем базы данных) транзакция должна заблокировать этот кортеж
Несколько клиентов могут использовать один и тот же сервер (действительно, это довольно обычная ситуация)
Навигация
Степени связи между сущностями (1:1, 1:М, М:1, М:М);
Организация баз данных
362757
знаков
48
таблиц
34
изображения
1. степени связи между сущностями (1:1, 1:М, М:1, М:М);
2. класса принадлежности экземпляров сущностей (обязательный и необязательный).
Рассмотрим формулировки шести правил формирования отношений на основе диаграмм ER-типа.
8.4.1 Степень связи 1:1, класс принадлежности обеих сущностей обязательныйЕсли степень бинарной связи 1:1 и класс принадлежности обеих сущностей обязательный, то формируется одно отношение. Первичным ключом этого отношения может быть ключ любой из двух сущностей.
На рис. 8.9 приведены диаграмма ER-типа и отношение, сформированное по правилу 8.4.1 на ее основе.
 рис. 8.9 Диаграмма и отношения для правила 8.4.1
рис. 8.9 Диаграмма и отношения для правила 8.4.1
На рис. 8.9 используются следующие обозначения:
Cl, C2 – сущности 1 и 2;
Kl, K2 – ключи первой и второй сущности соответственно;
Rl – отношение 1, сформированное на основе первой и второй сущностей;
Kl, K2,... означает, что ключом сформированного отношения может быть либо К1, либо К2.
8.4.2 Степень связи 1:1, класс принадлежности одной сущности обязательный, а второй – необязательныйЕсли степень связи 1:1 и класс принадлежности одной сущности обязательный, а второй – необязательный, то под каждую из сущностей формируется по отношению с первичными ключами, являющимися ключами соответствующих сущностей. Далее к отношению, сущность которого имеет обязательный КП, добавляется в качестве атрибута ключ сущности с необязательным КП.
На рис. 8.10 приведены диаграмма ER-типа и отношения, сформированные по правилу 8.4.2 на ее основе.
 рис. 8.10 Диаграмма и отношения для правила 8.4.2
рис. 8.10 Диаграмма и отношения для правила 8.4.2
Если степень связи 1:1 и класс принадлежности обеих сущностей является необязательным, то необходимо использовать три отношения. Два отношения соответствуют связываемым сущностям, ключи которых являются первичными в этих отношениях. Третье отношение является связным между первыми двумя, поэтому его ключ объединяет ключевые атрибуты связываемых отношений.
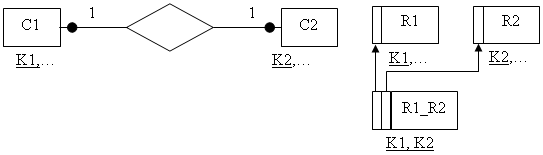 рис. 8.11 Диаграмма и отношения для правила 8.4.3
рис. 8.11 Диаграмма и отношения для правила 8.4.3
На рис. 8.11 приведены диаграмма ER-типа и отношения, сформированные по правилу 8.4.3 на ее основе.
Сформулируем аналогичные два правила для вариантов, степень связи между сущностями которых 1:М. Если две сущности С1 и С2 связаны как 1:М, сущность С1 будем называть односвязной (1-связной), а сущность С2-многосвязной (М-связной). Определяющим фактором при формировании отношений, связанных этим видом связи, является класс принадлежности М-связной сущности. Так, если класс принадлежности М-связной сущности обязательный, то в результате применения правила получим два отношения, если необязательный – три отношения. Класс принадлежности односвязной сущности не влияет на результат.
8.4.4 Степень связи между сущностями 1:М (или М:1), класс принадлежности М-связной сущности обязательныйЕсли степень связи между сущностями 1:М (или М:1) и класс принадлежности М-связной сущности обязательный, то достаточно формирование двух отношений (по одному на каждую из сущностей). При этом первичными ключами этих отношений являются ключи их сущностей. Кроме того, ключ 1-связной сущности добавляется как атрибут (внешний ключ) в отношение, соответствующее М-связной сущности.
На рис. 8.12 приведены диаграмма ER-типа и отношения, сформированные по правилу 8.4.4.
 рис. 8.12 Диаграмма и отношения для правила 8.4.4.
рис. 8.12 Диаграмма и отношения для правила 8.4.4.
Если степень связи 1:М (М:1)и класс принадлежности М-связной сущности является необязательным, то необходимо формирование трех отношений (рис. 8.13).
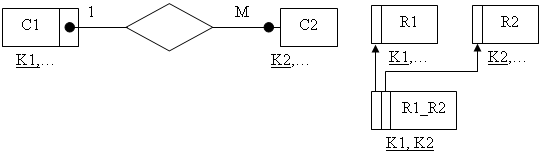
рис. 8.13 Диаграмма и отношение для правила 8.4.5
Два отношения соответствуют связываемым сущностям, ключи которых являются первичными в этих отношениях. Третье отношение является связным между первыми двумя (его ключ объединяет ключевые атрибуты связываемых отношений).
При наличии связи М:М между двумя сущностями необходимо три отношения независимо от класса принадлежности любой из сущностей. Использование одного или двух отношений в этом случае не избавляет от пустых полей или избыточно дублируемых данных.
8.4.6 Степень связи М:М, независимо от класса принадлежности сущностейЕсли степень связи М:М, то независимо от класса принадлежности сущностей формируются три отношения Два отношения соответствуют связываемым сущностям и их ключи являются первичными ключами этих отношений. Третье отношение является связным между первыми двумя, а его ключ объединяет ключевые атрибуты связываемых отношений.
На рис. 8.14 приведены диаграмма ER-типа и отношения, сформированные по правилу 8.4.6. В конспекте показан вариант с классом принадлежности сущностей Н-Н, хотя, согласно правилу 8.4.6, он может быть произвольным.
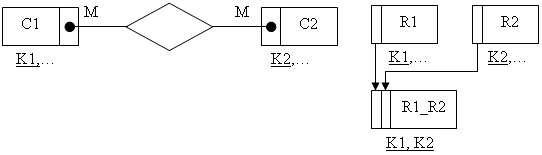 рис. 8.14. Диаграмма и отношения для правила 8.4.6.
рис. 8.14. Диаграмма и отношения для правила 8.4.6.
Аналогичные результаты получаются и для трех других вариантов, различающихся классами принадлежности их сущностей.
8.5 Методология IDEF1 (самостоятельное изучение)Метод IDEF1, разработанный Т. Рэмей (T. Ramey), также основан на подходе П. Чена и позволяет построить модель данных, эквивалентную реляционной модели в третьей нормальной форме. В настоящее время на основе совершенствования методологии IDEF1 создана ее новая версия - методология IDEF1X. IDEF1X разработана с учетом таких требований, как простота изучения и возможность автоматизации. IDEF1X-диаграммы используются рядом распространенных CASE-средств (таких, как, ERwin, Design/IDEF).
Сущность в методологии IDEF1X является независимой от идентификаторов или просто независимой, если каждый экземпляр сущности может быть однозначно идентифицирован без определения его отношений с другими сущностями (рис. 8.15). Сущность называется зависимой от идентификаторов или просто зависимой, если однозначная идентификация экземпляра сущности зависит от его отношения к другой сущности (рис. 8.16).
 рис. 8.15. Независимые от идентификатора сущности.
рис. 8.15. Независимые от идентификатора сущности.
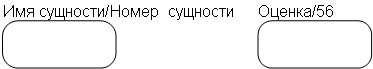 рис. 8.16. Зависимые от идентификатора сущности.
рис. 8.16. Зависимые от идентификатора сущности.
Каждой сущности присваивается уникальное имя и номер, разделяемые косой чертой "/" и помещаемые над блоком.
Связь может дополнительно определяться с помощью указания степени или мощности (количества экземпляров сущности-потомка, которое может существовать для каждого экземпляра сущности-родителя). В IDEF1X могут быть выражены следующие мощности связей:
5. каждый экземпляр сущности-родителя может иметь ноль, один или более связанных с ним экземпляров сущности-потомка;
6. каждый экземпляр сущности-родителя должен иметь не менее одного связанного с ним экземпляра сущности-потомка;
7. каждый экземпляр сущности-родителя должен иметь не более одного связанного с ним экземпляра сущности-потомка;
8. каждый экземпляр сущности-родителя связан с некоторым фиксированным числом экземпляров сущности-потомка.
Если экземпляр сущности-потомка однозначно определяется своей связью с сущностью-родителем, то связь называется идентифицирующей, в противном случае – неидентифицирующей.
Связь изображается линией, проводимой между сущностью-родителем и сущностью-потомком с точкой на конце линии у сущности-потомка. Мощность связи обозначается как показано на рис. 8.17 (мощность по умолчанию – N).
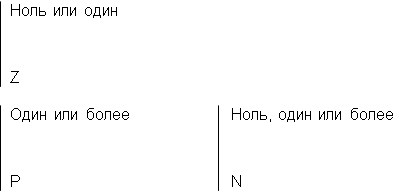
рис. 8.17. Мощность связи.
Идентифицирующая связь между сущностью-родителем и сущностью-потомком изображается сплошной линией (рис. 8.18). Сущность-потомок в идентифицирующей связи является зависимой от идентификатора сущностью. Сущность-родитель в идентифицирующей связи может быть как независимой, так и зависимой от идентификатора сущностью (это определяется ее связями с другими сущностями).
 рис. 8.18. Идентифицирующая связь.
рис. 8.18. Идентифицирующая связь.
Пунктирная линия изображает неидентифицирующую связь (рис. 8.19). Сущность-потомок в неидентифицирующей связи будет независимой от идентификатора, если она не является также сущностью-потомком в какой-либо идентифицирующей связи.
 рис. 8.19. Неидентифицирующая связь.
рис. 8.19. Неидентифицирующая связь.
Атрибуты изображаются в виде списка имен внутри блока сущности. Атрибуты, определяющие первичный ключ, размещаются наверху списка и отделяются от других атрибутов горизонтальной чертой (рис. 8.20).
 рис. 8.20. Атрибуты и первичные ключи.
рис. 8.20. Атрибуты и первичные ключи.
Сущности могут иметь также внешние ключи (Foreign Key), которые могут использоваться в качестве части или целого первичного ключа или неключевого атрибута. Внешний ключ изображается с помощью помещения внутрь блока сущности имен атрибутов, после которых следуют буквы FK в скобках (рис. 8.21).
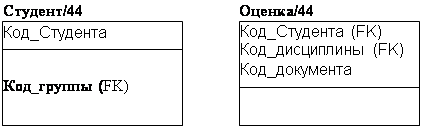 рис. 8.21. Примеры внешних ключей.
рис. 8.21. Примеры внешних ключей.
Литература:
1. Базы данных: Учебник для высших учебных заведений /Под ред. проф. А.Д. Хомоненко. –Спб.: КОРОНА принт, 2000. –416с. Стр. 147–161.
2. Сергей Кузнецов, “Основы современных баз данных”. Центр Информационных Технологий, http://www.citforum.ru/database/osbd/contents.shtml
ЛЕКЦИЯ 9. Язык SQL9.1 История создания и развития SQL
9.2 Основные понятия SQL
9.3 Запросы на чтение данных. Оператор SELECT
9.4 Многотабличные запросы на чтение (объединения).
9.1 История создания и развития SQL
Язык для взаимодействия с БД SQL появился в середине 70-х и был разработан в рамках проекта экспериментальной реляционной СУБД System R. Исходное название языка SEQUEL (Structered English Query Language) только частично отражает суть этого языка. Конечно, язык был ориентирован главным образом на удобную и понятную пользователям формулировку запросов к реляционной БД, но на самом деле уже являлся полным языком БД, содержащим помимо операторов формулирования запросов и манипулирования БД средства определения и манипулирования схемой БД; определения ограничений целостности и триггеров; представлений БД; возможности определения структур физического уровня, поддерживающих эффективное выполнение запросов; авторизации доступа к отношениям и их полям; точек сохранения транзакции и откатов. Таким образом, SQL стал достаточно мощным языком для взаимодействия с СУБД. На сегодняшний день SQL является единственным стандартным языком запросов. Язык SQL обладает следующими достоинствами:
1. независимость от конкретных СУБД. Если при создании БД не использовались нестандартные возможности языка SQL предоставляемые некоторой СУБД, то такую БД можно без изменений перенести на СУБД другого производителя. К сожалению большинство БД используют особенности СУБД, на которой работают, что затрудняет их перенос на другую СУБД без изменений;
2. реляционная основа. Реляционная модель имеет солидный теоретический фундамент. Язык SQL основан на реляционной модели и является единственным языком для реляционных БД;
3. SQL обладает высокоуровневой структурой, напоминающей английский язык.
4. SQL позволяет создавать различные представления данных для различных пользователей;
5. SQL является полноценным языком для работы с БД;
6. стандарты языка SQL. Официальный стандарт языка SQL опубликован ANSI и ISO в 1989 году и значительно расширен в 1992 году.
9.2 Основные понятия SQL 9.2.1 ОператорыВ SQL используется приблизительно тридцать операторов, каждый из которых "просит" СУБД выполнить определенное действие, например, прочитать данные, создать таблицу или добавить в таблицу новые данные. Все операторы SQL имеют одинаковую структуру, которая показана на рис. 9.1.
рис. 9.1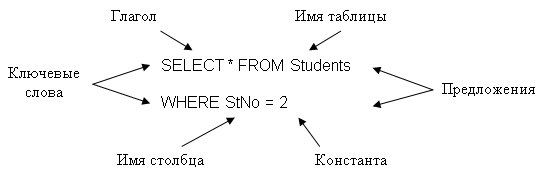 Структура оператора SQL.
Структура оператора SQL.
Каждый оператор SQL начинается с глагола, т.е. ключевого слова, описывающего действие, выполняемое оператором. Типичными глаголами являются SELECT (выбрать), CREATE (создать), INSERT (добавить), DELETE (удалить), COMMIT(завершить). После глагола идет одно или несколько предложений. Предложение описывает данные, с которыми работает оператор, или содержит уточняющую информацию о действии, выполняемом оператором. Каждое предложение также начинается с ключевого слова, такого как WHERE (где), FROM (откуда), INTO (куда) и HAVING (имеющий). Одни предложения в операторе являются обязательным, а другие – нет. Конкретная структура и содержимое предложения могут изменяться. Многие предложения содержат имена таблиц или столбцов; некоторые из них могут содержать дополнительные ключевые слова, константы и выражения.
В стандарте ANSI/ISO определены ключевые слова, которые применяются в качестве глаголов и в предложениях операторов. В соответствии со стандартом, эти ключевые слова нельзя использовать для именования объектов базы данных, таких как таблицы, столбцы и пользователи
9.2.2 Имена.У каждого объекта в базе данных есть уникальное имя. Имена используются в операторах SQL и указывают, над каким объектом базы данных оператор должен выполнить действие. В стандарте ANSI/ISO определено, что имена имеются у таблиц, столбцов и пользователей. Во многих реализациях SQL поддерживаются также дополнительные именованные объекты, такие как хранимые процедуры, именованные отношения "первичный ключ – внешний ключ" и формы для ввода данных.
В соответствии со стандартом ANSI/ISO, в SQL имена должны содержать от 1 до 18 символов, начинаться с буквы и не содержать пробелы или специальные символы пунктуации. В стандарте SQL2 максимальное число символов в имени увеличено до 128.
Полное имя таблицы состоит из имени владельца таблицы и собственно ее имени, разделенных точкой (.). Например, полное имя таблицы Students, владельцем которой является пользователь по имени Admin, имеет следующий вид:
Admin.Students
Если в операторе задается имя столбца, SQL сам определяет, в какой из указанных в этом же операторе таблиц содержится данный столбец. Однако если в оператор требуется включить два столбца из различных таблиц, но с одинаковыми именами, необходимо указать полные имена столбцов, которые однозначно определяют их местонахождение. Полное имя столбца состоит из имени таблицы, содержащей столбец, и имени столбца (простого имени), разделенных точкой (.). Например, полное имя столбца StName из таблицы Students имеет следующий вид:
Students.StName
9.2.3 Типы данных в SQLВ стандарте ANSI/ISO определены типы данных, которые можно использовать для представления информации в реляционной базе данных. Типы данных, имеющиеся в стандарте SQL1, составляют лишь минимальный набор и поддерживаются во всех коммерческих СУБД. В табл. 9.1 перечислены типы данных, определенные в стандартах SQL1 и SQL2.
табл. 9.1 Типы данных в SQL.
| Тип данных | Описание |
| CHAR (длина) | Строки символов постоянной длины |
| CHARACTER (длина) | |
| VARCHAR(длина) | Строки символов переменной длины* |
| CHAR VARYING(длина) | |
| CHARACTER VARYING (длина) | |
| NСНАР(длина) | Строки локализованных символов постоянной длины* |
| NATIONAL CHAR(длина) | |
| NATIONAL CHARACTER(длина) | |
| NCHAR VARYING(длина) | Строки локализованных символов переменной длины* |
| NATIONAL CHAR VARYING(длина) | |
| NATIONAL CHARACTER VARYING(длина) | |
| INTEGER | Целые числа |
| INT | |
| SMALLINT | Маленькие целые числа |
| BIT(длина) | Строки битов постоянной длины* |
| BIT VARYNG(длина) | Строки битов переменной длины* |
| NUMERIC(точность, степень) | Масштабируемые целые (десятичные) числа |
| DECIMAL(точность, степень) | |
| DEC(точность, степень) | |
| FLOAT(точность) | Числа с плавающей запятой |
| REAL | Числа с плавающей запятой низкой точности |
| DOUBLE PRECISION | Числа с плавающей запятой высокой точности |
| DATE | Календарная дата* |
| TIME(точность) | Время |
| TIME STAMP(точность) | Дата и время* |
| INTERVAL | Временной интервал* |
В SQL1 используются следующие типы данных:
1. Строки символов постоянной длины. В столбцах, имеющих этот тип данных, обычно хранятся имена людей и компаний, адреса, описания и т д.
2. Целые числа. В столбцах, имеющих этот тип данных, обычно хранятся данные о счетах, количествах, возрастах и т.д. Целочисленные столбцы часто используются также для хранения идентификаторов, таких как идентификатор клиента, служащего или заказа.
3. Масштабируемые целые числа. В столбцах данного типа хранятся числа,) имеющие дробную часть, которые необходимо вычислять точно, например курсы валют и проценты. Кроме того, в таких столбцах часто хранятся) денежные величины.
4. Числа с плавающей запятой. Столбцы этого типа используются для хранения величин, которые можно вычислять приблизительно, например веса и расстояния. Числа с плавающей запятой могут представлять больший диапазон значений, чем десятичные числа, однако при вычислениях могут возникать погрешности округления.
В большинстве коммерческих СУБД помимо типов данных, определенных в стандарте SQL1, имеется множество дополнительных типов данных, большинство из которых вошло в стандарт SQL2. Ниже перечислены наиболее важные из них:
1. Строки символов переменной длины. Почти во всех СУБД поддерживается тип данных VARCHAR, позволяющий хранить строки символов, длина которых изменяется в некотором диапазоне В стандарте SQL1 были определены строки постоянной длины, которые справа дополняются пробелами.
2. Денежные величины. Во многих СУБД поддерживается тип данных MONEY или CURRENCY, который обычно хранится в виде десятичного числа или числа с плавающей запятой. Наличие отдельного типа данных для представления денежных величин позволяет правильно форматировать их при выводе на экран.
3. Дата и время. Поддержка значений даты/времени также широко распространена в различных СУБД, хотя способы ее реализации довольно сильно отличаются друг от друга. Как правило, над значениями этого типа данных можно выполнять различные операции. В стандарт SQL2 входит определение типов данных DATE, TIME, TIMESTAMP и INTERVAL, включая поддержку часовых поясов и возможность указания точности, представления времени (например, десятые или сотые доли секунды).
Похожие работы
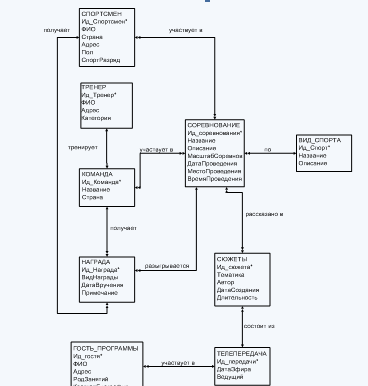
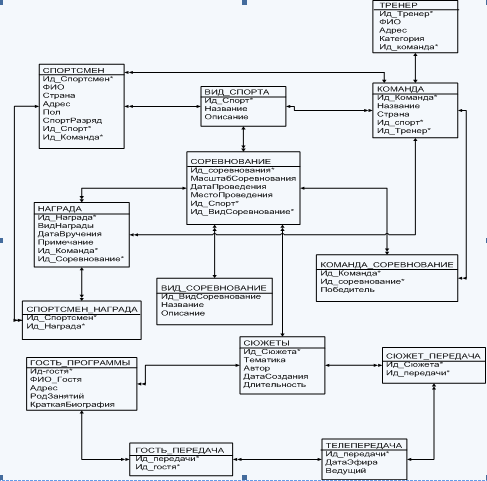
... для предметной области «Спортивная программа» показана на рис.1 Рис.1 – КМД для предметной области «Спортивная программа» Двойная стрелка означает «многие», одинарная стрелка означает «один» во взаимосвязи между объектами. Ключевые атрибуты обозначены *. Описание реляционной модели данных Реляционная модель данных (РМД) представляет БД в виде множества взаимосвязанных отношений, в том ...
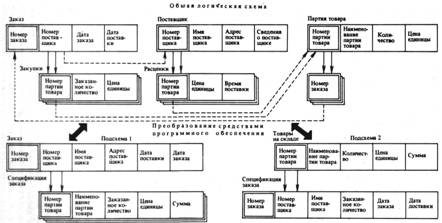
... и прикладных программ (логическая независимость данных) и возможность изменения физического расположения и организации данных без изменения общей логической структуры данных и структур данных прикладных программистов (физическая независимость). Рис. 1 2. Системы управления базами данных Использование систем управления базами данных (СУБД) позволяет исключить из прикладных программ ...

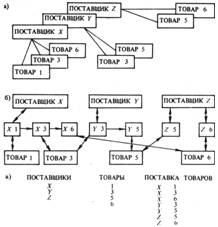
... (в виде связей). В последнее время все большее значение приобретает объектно-ориентированный подход к представлению данных. Физическая организация баз данных Физическая организация данных определяет собой способ непосредственного размещения данных на машинном носителе. В современных прикладных программных средствах этот уровень организации обеспечивается автоматически без вмешательства ...
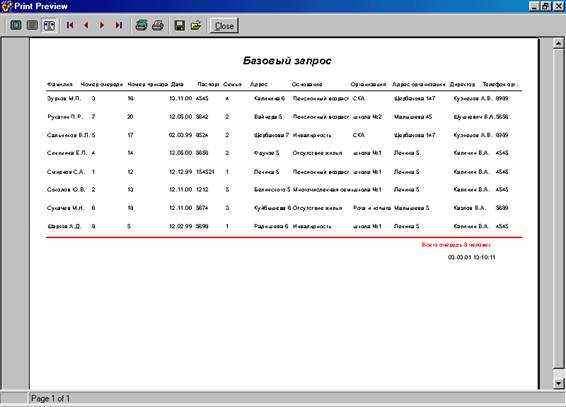
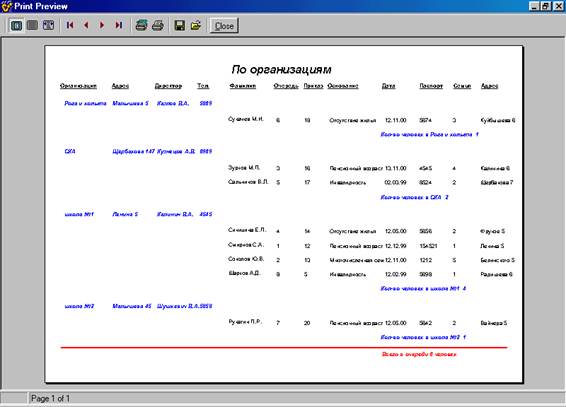
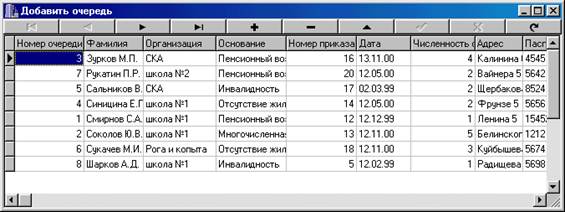
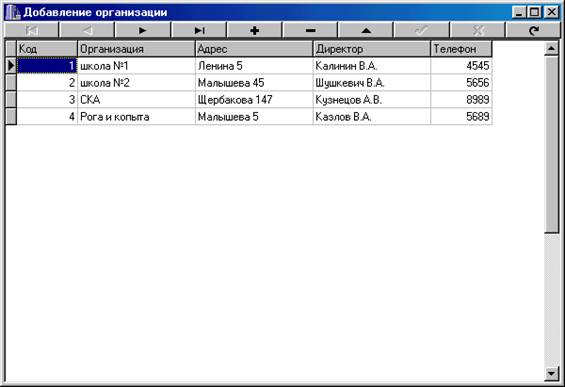
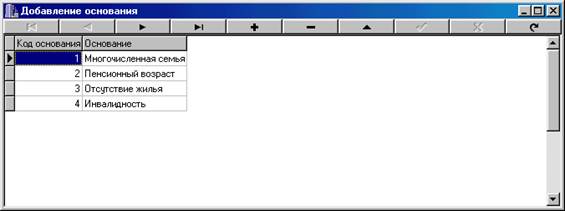
... отчет. Базовый отчет: Отчет по организациям: Программа предназначена для учёта очереди по организациям, а также для предоставления оперативной информации о очереди. К входящей информации относятся: номер очереди, фамилия, организация, основание, номер приказа, дата, численность семьи, адрес , паспорт. Т. е файл: Также Справочник 1 и 2: К выходящей информации в отчёте ...
0 комментариев