Производительность. СУБД должна выполнять свои функции с максимальной производительностью
Заголовок содержит фиксированное множество атрибутов или, точнее, пар <имя‑атрибута : имя‑домена>:
На практике большинство отношений имеют только один потенциальный ключ, хотя в общем случае их может быть несколько
Если каждое из них имеет одно и то же множество имен атрибутов (следовательно, заметьте, они заведомо должны иметь одну и ту же степень);
Следует заметить, что речь здесь пойдет о логическом, а не физическом макете
Правая часть (зависимая часть) каждой ФЗ множества S содержит только один атрибут (т.е. является одноэлементным множеством)
Диаграммы ER-экзрмпляров
Степени связи между сущностями (1:1, 1:М, М:1, М:М);
Булевы данные. Некоторые СУБД явным образом поддерживают логические значения (TRUE или FALSE)
Константа, показывающая, что в каждой строке результатов запроса должно содержаться одно и то же значение
Пользователь имеет доступ к объекту, только если его уровень допуска больше или равен уровню классификации объекта
ALTER – позволяет модифицировать структуру таблиц (DB2, Oracle);
Далее этот процесс следует повторить для вставки среднего значения W в родительский элемент Р на более высоком структурном уровне
В последовательности проекций данного отношения можно игнорировать все проекции, кроме последней. Таким образом, выражение
Долговечность. Когда транзакция выполнена, ее обновления сохраняются, даже если в следующий момент произойдет сбой системы
Транзакция, предназначенная для извлечения кортежа, прежде всего должна наложить S‑блокировку на этот кортеж
Перед выполнением каких-либо операций с некоторым объектом (например, с кортежем базы данных) транзакция должна заблокировать этот кортеж
Несколько клиентов могут использовать один и тот же сервер (действительно, это довольно обычная ситуация)
Навигация
Константа, показывающая, что в каждой строке результатов запроса должно содержаться одно и то же значение
Организация баз данных
362757
знаков
48
таблиц
34
изображения
2. константа, показывающая, что в каждой строке результатов запроса должно содержаться одно и то же значение,
3. выражение, показывающее, что SQL должен вычислять значение, помещаемое в результаты запроса, по формуле, определенной в выражении.
9.3.2 Предложение FROMПредложение FROM состоит из ключевого слова FROM, за которым следует список спецификаторов таблиц, разделенных запятыми Каждый спецификатор таблицы идентифицирует таблицу, содержащую данные, которые считывает запрос Такие таблицы называются исходными таблицами запроса (и оператора SELECT), поскольку все данные, содержащиеся в таблице результатов запроса, берутся из них.
Результатом SQL-запроса на чтение всегда является таблица, содержащая данные и ничем не отличающаяся от таблиц базы данных
Кроме столбцов, значения которых считываются непосредственно из базы данных, SQL-запрос на чтение может содержать вычисляемые столбцы, значения которых определяются на основании значений, хранящихся в базе данных. Чтобы получить вычисляемый столбец, в списке возвращаемых столбцов необходимо указать выражение.
Иногда требуется получить содержимое всех столбцов таблицы. На практике такая ситуация может возникнуть, когда вы впервые сталкиваетесь с новой базой данных и необходимо быстро получить представление о ее структуре и хранимых в ней данных. С учетом этого в SQL разрешается использовать вместо списка .возвращаемых столбцов символ звездочки (*), который означает, что требуется прочитать все столбцы:
Показать все данные, содержащиеся в таблице Students.
SELECT *
FROM Students
Повторяющиеся строки из таблицы результатов запроса можно удалить, если в операторе SELECT перед списком возвращаемых столбцов указать ключевое слово DISTINCT.
9.3.3 Отбор строк (предложение WHERE)SQL-запросы, считывающие из таблицы все строки, полезны при просмотре базы данных и создании отчетов, однако редко применяются для чего-нибудь еще Обычно требуется выбрать из таблицы несколько строк и включить в результаты запроса только их Чтобы указать, какие строки требуется отобрать, следует использовать предложение WHERE.
Предложение WHERE состоит из ключевого слова WHERE, за которым следует условие поиска, определяющее, какие именно строки требуется прочитать.
Если условие поиска имеет значение TRUE, строка будет включена в результаты запроса.
Если условие поиска имеет значение FALSE или NULL, то строка исключается из результатов запроса.
9.3.4 Условия поискаВ SQL используется множество условий поиска, позволяющих эффективно и естественным образом создавать различные типы запросов. Ниже рассматриваются пять основных условий поиска (в стандарте ANSI/ISO они называются предикатами).
Сравнение (=, <>, <, <=, >, >=). Наиболее распространенным условием поиска в SQL является сравнение. При сравнении SQL вычисляет и сравнивает значения двух выражений для каждой строки данных. Выражения могут быть как очень простыми, например содержать одно имя столбца или константу, так и более сложными – арифметическими выражениями.
Ниже приведен синтаксис оператора сравнения.
Выражение1 = | <> | < | <= | > | >= Выражение2
Проверка на принадлежность диапазону значений (BETWEEN). Другой формой условия поиска является проверка на принадлежности диапазону значений (ключевое слово BETWEEN). При этом проверяется, находится ли значение данных между двумя определенными значениями.
Проверяемое_выражение [NOT] BETWEEN нижнее_выражение AND верхнее_выражение
При проверке на принадлежность диапазону верхний и нижний пределы считаются частью диапазона, поэтому в результаты запроса.
Если выражение, определяющее нижний предел диапазона, имеет значение NULL, то проверка BETWEEN возвращает значение FALSE тогда, когда проверяемое значение больше верхнего предела диапазона, и значение NULL в противном случае.|
Если выражение, определяющее верхний предел диапазона, имеет значение NULL, то проверка BETWEEN возвращает значение FALSE, когда проверяемое значение меньше нижнего предела, и значение NULL противном случае.
Поверка на членство в множестве (IN). Еще одним распространенным условием поиска является проверка на членство в множестве (IN). В этом случае проверяется, соответствует ли значение данных какому-либо значению из заданного списка.
проверяемое_выражение [NOT] IN (константа, …)
Например: вывести список фамилий студентов, которые учатся в группах с кодами 1, 3, 5 и 10.
SELECT StName
FROM Students
WHERE GrNo IN (1, 3, 5, 10)
Проверка на соответствие шаблону (LIKE). Для чтения строк, в которых содержимое некоторого текстового столбца совпадает с заданным текстом, можно использовать простое сравнение, однако иногда необходимо осуществить сравнение на основе фрагмента строки.
Поверка на соответствие шаблону (ключевое слово LIKE), позволяет определить, соответствует ли значение данных в столбце некоторому шаблону. Шаблон представляет собой строку, в которую может входить один или более подстановочных знаков. Эти знаки интерпретируются особым образом.
имя_столбца [NOT] LIKE шаблон [ESCAPE символ_пропуска]
Подстановочные знаки. Подстановочный знак % совпадает с любой последовательностью из нуля или более символов. Например, следующий запрос выведет информацию о студентах, чья фамилия начинается с "Иван":
SELECT *
FROM StudentsWHERE StName LIKE 'Иван%'
Подстановочный знак "_" (символ подчеркивания) совпадает с любым отдельным символом. Например, если вы уверены, что имя студентки- либо "Наталья", либо "Наталия", то можете воспользоваться следующим запросом:
SELECT *
FROM Students WHERE StName LIKE 'Натал_я'
Подстановочные знаки можно помещать в любое место строки шаблона, и в одной строке может содержаться несколько подстановочных знаков.
Символы пропуска. При проверке строк на соответствие шаблону может оказаться, что подстановочные знаки входят в строку символов в качестве литералов. Например, нельзя проверить, содержится ли знак процента в строке, просто включив его в шаблон, поскольку SQL будет считать этот знак подстановочным. Как правило, это не вызывает серьезных проблем, поскольку подстановочные знаки довольно редко встречаются в именах, названиях товаров и других текстовых данных, которые обычно хранятся в базе данных.
В стандарте ANSI/ISO определен способ проверки наличия в строках литералов, использующихся в качестве подстановочных знаков. Для этом применяются символы пропуска. Когда в шаблоне встречается такой символ то символ, следующий непосредственно за ним, считается не подстановочным знаком, а литералом. (Происходит пропуск символа.) Непосредственно за символом пропуска может следовать либо один из двух подстановочных знаков, либо сам символ пропуска, поскольку он тоже приобретает в шаблоне особое значение.
Символ пропуска определяется в виде строки, состоящей из одного символа, и предложения ESCAPE. Ниже приведен пример использования знака доллара ($) в качестве символа пропуска:
SELECT *
FROM DataTable WHERE Text LIKE '%менее 50$% %' ESCAPE $
Проверка на равенство значению NULL (IS NULL). Значения NULL обеспечивают возможность применения трехзначной логики в условиях поиска. Для любой заданной строки результат применения условия поиска может быть TRUE, FALSE или NULL (в случае, когда в одном из столбцов содержится значение NULL). Иногда бывает необходимо явно проверять значения столбцов на равенство NULL и непосредственно обрабатывать их. Для этого в SQL имеется специальная проверка на равенство значению NULL (IS NULL).
IS [NOT] NULL имя_ столбца
Составные условия поиска (AND, OR и NOT). Простые условия поиска, описанные в предыдущих параграфах, после применения к некоторой строке возвращают значения TRUE, FALSE или NULL. С помощью правил логики эти простые условия можно объединять в более сложные. Условия поиска, объединенные с помощью ключевых слов AND, OR и NOT, сами могут быть составными.
WHERE [NOT] условие_поска [AND | OR] [NOT] условие_поска …
9.3.5 Сортировка результатов запроса (предложение ORDER BY).Строки результатов запроса, как и строки таблицы базы данных, не имеют определенного порядка. Включив в оператор SELECT предложение ORDER BY, можно отсортировать результаты запроса. Это предложение состоит из ключевых слов ORDER BY, за которыми следует список имен столбцов, разделенных запятыми.
ORDER BY имя_столбца [ASC | DESC], …
В предложении ORDER BY можно выбрать возрастающий или убывающий порядок сортировки. По умолчанию, данные сортируются в порядке возрастания. Чтобы сортировать их по убыванию, следует включить в предложение сортировки ключевое слово DESC.
Например: вывести список фамилий студентов учащихся в группе с кодом 1 в обратном алфавитном порядке.
SELECT StName
FROM Students ORDER BY DESC StName
9.4 Многотабличные запросы на чтение (объединения).На практике многие запросы считывают данные сразу из нескольких таблиц базы данных.
9.4.1 Запросы с использованием отношения предок/потомок.Среди многотабличных запросов наиболее распространены запросы к двум таблицам, связанным с помощью отношения предок/потомок. Запрос о студентах, учащихся в группе с некоторым названием является примером такого запроса. У каждого студента (потомка) есть соответствующая ему группа (предок), и каждая группа (предок) может иметь много студентов (потомков). Пары строк, из которых формируются результаты запроса, связаны отношением предок/потомок.
Например: вывести список фамилий студентов с названием группы, в которой он учится
SELECT StName, GrName
FROM Students, Groups
WHERE Students.GrNo = Groups.GrNo
9.4.2 Прочие объединения таблиц по равенствуОгромное множество многотабличных запросов основано на отношениях предок/потомок, но в SQL не требуется, чтобы связанные столбцы представляли собой пару "внешний ключ – первичный ключ". Любые два столбца из двух таблиц могут быть связанными столбцами, если только они имеют сравнимые типы данных.
Объединение таблиц по неравенству. Термин "объединение" применяется к любому запросу, который объединяет данные из двух таблиц базы данных путем сравнения значений в двух столбцах этих таблиц. Самыми распространенными являются объединения, созданные на основе равенства связанных столбцов (объединения по равенству). Кроме того, SQL позволяет объединять таблицы с помощью других операций сравнения. Например, получить все коды дисциплин по которым студентом с кодом 1 была получена оценка большая, чем по дисциплине с кодом 1.
SELECT Marks1.SubjNo
FROM Marks AS Marks1, Marks AS Marks2
WHERE Marks1.Mark > Marks2.Mark
AND Marks2.SubjNo = 1 AND Marks1.StNo = 1
Следует признать, что данный пример имеет несколько искусственный характер и является иллюстрацией того, почему столь мало распространены объединения по неравенству. Однако они могут оказаться полезными в приложениях, предназначенных для поддержки принятия решений, и в других приложениях, исследующих более сложные взаимосвязи в базе данных.
Полные имена столбцов. В учебной базе данных имеется несколько случаев, когда две таблицы содержат столбцы с одинаковыми именами. Например, столбцы с именем GrNo имеются в таблицах Groups и Students.
Чтобы исключить разночтения, при указании столбцов необходимо использовать их полные имена. Полное имя столбца содержит имя столбца и имя таблицы, в которой он находится. Полные имена двух столбцов GrNo в учебной базе данных будут такими:
Groups.GrNo Students.GrNo
В операторе SELECT вместо простых имен столбцов всегда можно использовать полные имена. Таблица, заданная в полном имени столбца, должна, конечно, соответствовать одной из таблиц, заданных в предложении FROM.
Чтение всех столбцов. Как уже говорилось ранее, оператор SELECT * используется для чтения всех столбцов таблицы, указанной в предложении FROM. В многотабличном запросе звездочка означает выбор всех столбцов из всех таблиц, указанных в предложении FROM.
Самообъединения. Некоторые многотабличные запросы используют отношения, существующие внутри одной из таблиц. Предположим, например, что требуется вывести список имен всех преподавателей и их руководителей. Каждому преподавателю соответствует одна строка в таблице Teachers, а столбец ChiefNo содержит идентификатор преподавателя, являющегося руководителем. Столбцу ChiefNo следовало бы быть внешним ключом для таблицы, в которой хранятся данные о руководителях. И он им, фактически, является – это внешний ключ для самой таблицы Teachers.
Для объединения таблицы с самой собой в SQL применяется именно такой подход: использование "виртуальной копии". Вместо того чтобы на самом деле сделать копию таблицы, SQL позволяет вам сослаться на нее, используя другое имя, которое называется псевдонимом таблицы.
Например: вывести список всех преподавателей и их руководителей.
SELECT Teachers. TName, Chiefs.TName
FROM Teachers, Teachers Chiefs
WHERE Teachers. ChiefNo = Chiefs.TNo
Псевдонимы таблиц. Как уже было сказано в предыдущем параграфе, псевдонимы таблиц необходимы в запросах, включающих самообъединения. Однако псевдоним можно использовать в любом запросе (например, если запрос касается таблицы другого пользователя или если имя таблицы очень длинное и использовать его в полных именах столбцов утомительно).
Внешнее объединение таблиц. Операция объединения в SQL соединяет информацию из двух таблиц, формируя пары связанных строк из этих двух таблиц. Объединенную таблицу образуют пары тех строк из различных таблиц, у которых в связанных столбцах содержатся одинаковые значения. Если строка одной из таблиц не имеет пары, то такой вид объединения, называемый внутренним объединением, может привести к неожиданным результатам (потере некоторых данных в результате запроса). Для создания объединений таблиц, имеющих неодинаковые значения в столбцах, на основе которых осуществляется связь, применяют внешнее объединение таблиц наиболее полно представленное в стандарте SQL2.
Литература:
1. Джеймс Р. Грофф, Пол Н. Вайнберг. SQL: полное руководство: пер.с англ. –К.: Издательская группа BHV, 2000.–608с. Стр. 31–39,69–166.
ЛЕКЦИЯ 10. Язык SQL (продолжение)10.1 Объединения и стандарт SQL2
10.2 Итоговые запросы на чтение. Агрегатные функции
10.3 Запросы с группировкой (предложение GROUP BY)
10.4 Вложенные запросы
10.1 Объединения и стандарт SQL2
В стандарте SQL2 был определен совершенно новый метод поддержки внешних объединений, который не опирался ни на одну популярную СУБД. В спецификации стандарта SQL2 поддержка внешних объединений осуществлялась в предложении FROM с тщательно разработанным синтаксисом, позволявшим пользователю точно определить, как исходные таблицы должны быть объединены в запросе. Расширенное предложение FROM поддерживает также операцию UNION над таблицами и допускает сложные комбинации запросов на объединение операторов SELECT и объединений таблиц.
10.1.1 Внутренние объединения в стандарте SQL2Две объединяемые таблицы соединяются явно посредством операции JOIN, а условие поиска, описывающее объединение, находится теперь в предложении ON внутри предложения FROM В условии поиска, следующем за ключевым словом ON, могут быть заданы любые критерии сравнения строк двух объединяемых таблиц.
Например: вывести список фамилий студентов, и названия групп, к которых они учаться.
SELECT StName, GrName
FROM Students INNER JOIN Groups
ON Students.GrNo = Groups.GrNo
(В этих простых двухтабличных объединениях все содержимое предложения WHERE просто перешло в предложение ON, и предложение ON не добавляет ничего нового в язык SQL.
Стандарт SQL2 допускает еще один вариант запроса на простое внутреннее объединение таблиц Students и Groups. Так как связанные столбцы этих таблиц имеют одинаковые имена и сравниваются на предмет равенства (что делается довольно часто), то можно использовать альтернативную форму предложения ON, в которой задается список имен связанных столбцов:
SELECT StName, GrName
FROM Students INNER JOIN Groups USING (GrNo)
Ниже приведен синтаксис оператора JOIN:
1. естественное соединение.
FROM спецификация_таблиц,…,
таблица1
NATURAL {INNER|FULL[OUTER]|LEFT[OUTER]|RIGHT[OUTER]}JOIN
таблица2 …
2. соединение с использованием выражения.
FROM спецификация_таблицы,…,
таблица1
{INNER|[OUTER] FULL|[OUTER]LEFT|[OUTER]RIGHT} JOIN
таблица2
ON условие | USING(список_столбцов),…
3. объединение или декартово произведение.
FROM спецификация_таблицы,…,
таблица1 {UNION | CROSS JOIN} таблица2 ,…
Объединение двух таблиц, в котором связанные столбцы имеют идентичные имена, называется естественным объединением, так как обычно это действительно самый "естественный" способ объединения двух таблиц. Запрос на выборку пар фамилия студента/название группы, в которой он учиться, можно выразить как естественное объединение следующим образом:
SELECT StName, GrName
FROM Students NATURAL INNER JOIN Groups
10.1.2 Внешние объединения в стандарте SQL2Стандарт SQL2 обеспечивает полную поддержку внешних объединений, расширяя языковые конструкции, используемые для внутренних объединений. Например, для построения таблицы подчиненности преподавателей можно применить следующий запрос:
SELECT Chief.TName, SubOrdinate.TName
FROM Teachers AS Chief FULL OUTER JOIN Teachers AS SubOrdinate
ON Chief.TNo = SubOrdinate.TChiefNo
Результат такого запроса (данные из Приложения А) приведен на рис. 10.1.
| Chief.TName | SubOrdinate.TName |
| NULL | Иванов |
| Иванов | Петров |
| Петров | Стрельцов |
| Петров | Сидоров |
| Сидоров | NULL |
| Стрельцов | NULL |
рис. 10.1 Результатом такого запроса на внешнее объединение.
Таблица результатов запроса будет содержать по одной строке для каждой связанной пары начальник/подчиненный, а также по одной строке для каждой несвязанной записи для начальника или подчиненного, расширенной значениями NULL в столбцах другой таблицы.
Ключевое слово OUTER, так же как и ключевое слово INNER, в стандарте SQL2 не является обязательным. Поэтому предыдущий запрос можно, было бы переписать следующим образом:
SELECT Chief.TName, SubOrdinate.TName
FROM Teachers AS Chief FULL JOIN Teachers AS SubOrdinate
ON Chief.TNo = SubOrdinate.TChiefNo
По слову FULL СУБД сама определяет, что запрашивается внешнее объединение.
Вполне естественно, что в стандарте SQL2 левое и правое внешние объединения обозначаются словами LEFT и RIGHT вместо слова FULL. Вот вариант того же запроса, определяющий левое внешнее объединение:
SELECT Chief.TName, SubOrdinate.TName
FROM Teachers AS Chief LEFT OUTER JOIN Teachers AS SubOrdinate
ON Chief.TNo = SubOrdinate.TChiefNo
В результате такого запроса (данные из Приложения А.) будет получено следующее отношение (рис. 10.2).
| Chief.TName | SubOrdinate.TName |
| Иванов | Петров |
| Петров | Стрельцов |
| Петров | Сидоров |
| Сидоров | NULL |
| Стрельцов | NULL |
рис. 10.2 Результатом такого запроса на внешнее объединение
10.1.3 Перекрестные объединения и запросы на объединение в SQL2Расширенное предложение FROM в стандарте SQL2 поддерживает также два других способа соединения данных из двух таблиц – декартово произведение и запросы на объединение. Строго говоря, ни один из них не является операцией "объединения", но они поддерживаются в стандарте SQL2 с помощью тех же самых предложений, что и внутренние и внешние объединения. Вот запрос, создающий декартово произведение таблиц Students и Groups:
SELECT *
FROM Students CROSS JOIN Groups
10.1.4 Многотабличные объединения в стандарте SQL2Одно из крупных преимуществ расширенного предложения FROM заключается в том, что оно дает единый стандарт для определения как внутренних и внешних объединений, так и произведений и запросов на объединение. Другим, даже еще более важным преимуществом этого предложения является то, что оно обеспечивает очень ясную и четкую спецификацию объединений трех и четырех таблиц, а также произведений и запросов на объединение. Для построения этих сложных объединений любые выражения описанные ранее, могут быть заключены в круглые скобки. Результирующее выражение, в свою очередь, можно использовать для создания других выражений объединения, как если бы оно было простой таблицей. Точно так же, как SQL позволяет с помощью круглых скобок комбинировать различные арифметические операции (+, –, * и /) и строить сложные выражения, стандарт SQL2 дает возможность создавать сложные выражения для объединений.
10.2 Итоговые запросы на чтение. Агрегатные функции
Для подведения итогов по информации, содержащейся в базе данных, в SQL предусмотрены агрегатные (статистические) функции. Агрегатная функция принимает в качестве аргумента какой-либо столбец данных целиком, а возвращает одно значение, которое определенным образом подытоживает этот столбец. Например, агрегатная функция AVG() принимает в качестве аргумента столбец чисел и вычисляет их среднее значение.
В SQL имеется шесть агрегатных функций, которые позволяют получать различные виды итоговой информации. Ниже описан синтаксис этих функций:
1. функция SUM() вычисляет сумму всех значений, содержащихся в столбце:
SUM(выражение | [DISTINCT] имя_столбца)
2. функция AVG() вычисляет среднее всех значений, содержащихся в столбце:
AVG(выражение | [DISTINCT] имя_столбца)
3. функция MIN() находит наименьшее среди всех значений, содержащихся в столбце:
MIN(выражение | имя_столбца)
4. функция МАХ() находит наибольшее среди всех значений, содержащихся в столбце:
MAX(выражение | имя_столбца)
5. функция COUNT() подсчитывает количество значений, содержащихся в столбце:
COUNT([DISTINCT] имя_столбца)
6. функция COUNT(*) подсчитывает количество строк в таблице результатов запроса:
COUNT(*)
10.2.1 Агрегатные функции и значения NULLВ стандарте ANSI/ISO также определены следующие точные правила обработки значений NULL в агрегатных функциях:
1. если какие-либо из значений, содержащихся в столбце, равны NULL, при вычислении результата функции они исключаются;
2. если все значения в столбце равны NULL, то функции SUM(), AVG(), MIN() и MAX () возвращают значение NULL; функция COUNT () возвращает ноль;
3. если в столбце нет значений (т.е. столбец пустой), то функции SUM() , AVG(), MIN() и МАХ() возвращают значение NULL; функция COUNT() возвращает ноль;
4. функция COUNT(*) подсчитывает количество строк и не зависит от наличия или отсутствия в столбце значений NULL; если строк в таблице нет, эта функция возвращает ноль.
10.3 Запросы с группировкой (предложение GROUP BY)
Итоговые запросы, о которых до сих пор шла речь в настоящей главе рассчитывают итоговые результаты на основании всех записей в таблице. Однако необходимость в таких вычислениях возникает достаточно редко, чаще бывает необходимо получать промежуточные итоги на основании групп записей в таблице. Эту возможность предоставляет предложение GROUP BY оператора SELECT.
Запрос, включающий в себя предложение GROUP BY, называется запросом с группировкой, поскольку он объединяет строки исходных таблиц в группы и для каждой группы строк генерирует одну строку таблицы результатов запроса. Столбцы, указанные в предложении GROUP BY, называются столбцами группировки, поскольку именно они определяют, по какому признаку строки делятся на группы. Например, получить список фамилий студентов и их средних оценок.
SELECT StName, AVG(Mark)
FROM Marks INNER JOIN Students USING(StNo)
GROUP BY StName
10.3.1 Несколько столбцов группировкиSQL позволяет группировать результаты запроса на основании двух или более столбцов. Например, получить список фамилий студентов и их средних оценок за каждый семестр.
SELECT StName, Semester, AVG(Mark)
FROM Marks INNER JOIN Students USING(StNo)
GROUP BY StName, Semester
10.3.2 Ограничения на запросы с группировкойНа запросы, в которых используется группировка, накладываются дополнительные ограничения. Столбцы с группировкой должны представлять собой реальные столбцы таблиц, перечисленных в предложении FROM. Нельзя группировать строки на основании значения вычисляемого выражения.
Кроме того, существуют ограничения на элементы списка возвращаемых столбцов. Все элементы этого списка должны иметь одно значение для каждой группы строк. Это означает, что возвращаемым столбцом может быть:
1. константа;
2. агрегатная функция, возвращающая одно значение для всех строк, входящих в группу;
3. столбец группировки, который, по определению, имеет одно и то же значение во всех строках группы;
4. выражение, включающее в себя перечисленные выше элементы.
На практике в список возвращаемых столбцов запроса с группировкой всегда входят столбец группировки и агрегатная функция. Если последняя не указана, значит, запрос можно более просто выразить с помощью ключевого слова DISTINCT без использования предложения GROUP BY. И наоборот, если не включить в результаты запроса столбец группировки, вы не сможете определить, к какой группе относится каждая строка результатов.
10.3.3 Значения NULL в столбцах группировкиВ стандарте ANSI определено, что два значения NULL в предложении GROUP BY равны.
Строки, имеющие значение NULL в одинаковых столбцах группировки и идентичные значения во всех остальных столбцах группировки, помещаются в одну группу.
10.3.4 Условия поиска групп (предложение HAVING)Точно так же, как предложение WHERE используется для отбора отдельных строк, участвующих в запросе, предложение HAVING можно применить для отбора групп строк. Его формат соответствует формату предложения WHERE. Предложение HAVING состоит из ключевого слова HAVING, за которым следует условие поиска. Таким образом, данное предложение определяет условие поиска для групп.
10.3.5 Ограничения на условия поиска группПредложение HAVING используется для того, чтобы включать и исключать группы строк из результатов запроса, поэтому на используемое в нем условие поиска наложены такие же ограничения, как и на элементы списка возвращаемых столбцов.
10.3.6 Предложение HAVING без GROUP BYПредложение HAVING почти всегда используется в сочетании с предложением GROUP BY, однако синтаксис оператора SELECT не требует этого. Если предложение HAVING используется без предложения GROUP BY, SQL рассматривает полные результаты запроса как одну группу. Другими словами, агрегатные функции, содержащиеся в предложении HAVING, применяются к одной и только одной группе, и эта группа состоит из всех строк. На практике предложение HAVING очень редко используется без соответствующего предложения GROUP BY.
10.4 Вложенные запросыВложенным (или подчиненным) запросом называется запрос, содержащийся в предложении WHERE или HAVING другого оператора SQL. Вложенные запросы позволяют естественным образом обрабатывать запросы, выраженные через результаты других запросов.
Чаще всего вложенные запросы указываются в предложении WHERE оператора SQL. Когда вложенный запрос содержится в данном предложении, он участвует в процессе отбора строк.
Например, вывести список фамилий студентов, средний балл которых выше 4,5:
SELECT StName
FROM Students
WHERE (SELECT AVG(Mark)
FROM Marks
WHERE Marks.StNo = Students.StNo) > 4.5
Вложенный запрос всегда заключается в круглые скобки, но по-прежнему сохраняет знакомую структуру оператора SELECT, содержащего предложение FROM и необязательные предложения WHERE, GROUP BY и HAVING. Структура этих предложений во вложенном запросе идентична их структуре в оператора SELECT; во вложенном запросе эти предложения выполняют свои обычные функции. Однако между вложенным запросом и оператором SELECT имеется ряд отличий:
1. Таблица результатов вложенного запроса всегда состоит из одного столбца. Это означает, что в предложении SELECT вложенного запроса всегда указывается один возвращаемый столбец.
2. Во вложенный запрос не может входить предложение ORDER BY. Результаты вложенного запроса используются только внутри главного запроса и для пользователя остаются невидимыми, поэтому нет смысла их сортировать.
3. Вложенный запрос не может быть запросом на объединение нескольких различных операторов SELECT; допускается использование только одного оператора SELECT.
4. Имена столбцов во вложенном запросе могут являться ссылками на столбцы таблиц главного запроса. Это так называемые внешние ссылки (ссылка на Students.StNo в предыдущем примере). Внешние ссылки необязательно должны присутствовать во вложенном запросе.
10.4.1 Условия поиска во вложенном запросе
Вложенный запрос всегда является частью условия поиска в предложении WHERE или HAVING. Ранее были рассмотрены простые условия поиска, которые могут использоваться в этих предложениях. Кроме того, в SQL имеются следующие условия поиска во вложенном запросе.
Сравнение с результатом вложенного запроса (=, <>, <, <=, >, >=). Сравнивает значение выражения с одним значением, возвращенным вложенным запросом. Эта проверка напоминает простое сравнение.
проверяемое_выражение | = | <> | < | <= | > | >= | вложенный_запрос
Сравнение с результатом вложенного запроса является модифицированной формой простого сравнения. Значение выражения сравнивается со значением, возвращенным вложенным запросом, и если условие сравнения выполняется, то проверка возвращает значение TRUE. Эта проверка используется для сравнения значения из проверяемой строки с одним значением, возвращенным вложенным запросом, как показано первом примере.
Проверка на принадлежность результатам вложенного запроса (IN). Проверка на принадлежность результатам вложенного запроса (ключевое слово IN) является видоизмененной формой простой проверки на членство в множестве.
проверяемое_выражение [NOT] IN вложенный_запрос
Одно значение сравнивается со столбцом данных, возвращенных вложенным запросом, и если это значение равно одному из значений в столбце, проверка возвращает TRUE. Данная проверка используется, когда необходимо сравнить значение из проверяемой строки с множеством значений, возвращенных вложенным запросом. Например, вывести всю информацию о студентах, учащихся в группах сназваниями, начинающимися на букву ²А²:
SELECT *
FROM Students
WHERE GrNo IN (SELECT GrNo FROM Groups WHERE GrName LIKE ‘А%’)
Проверка на существование (EXISTS). В результате проверки на существование (ключевое слово EXISTS) можно выяснить, содержится ли в таблице результатов вложенного запроса хотя бы одна строка. Аналогичной простой проверки не существует. Проверка на существование используется только с вложенными запросами.
[NOT] EXISTS вложенный_запрос
Например, вывести фамилии студентов, которые в 1-м семестре сдали хотябы одну дисциплину:
SELECT StName
FROM Students
WHERE EXISTS (SELECT *
FROM Marks
WHERE Marks.StNo = Students.StNo AND Semester = 1)
Многократное сравнение (ANY и ALL). В проверке IN выясняется, не равно ли некоторое значение одному из значений, содержащихся в столбце результатов вложенного запроса. В SQL имеется две разновидности многократного сравнения – ANY и ALL, расширяющие предыдущую проверку до уровня других операторов сравнения. В обеих проверках некоторое значение сравнивается со столбцом данных, возвращенным вложенным запросом.
проверяемое_выражение | = | <> | < | <= | > | >= | ANY | ALL вложенный_запрос
Проверка ANY. В проверке ANY используется один из шести операторов сравнения (=, <>, <, <=, >, >=) для того, чтобы сравнить одно проверяемое значение со столбцом данных, возвращенным вложенным запросом. Проверяемое значение поочередно сравнивается с каждым значением, содержащимся в столбце. Если любое из этих сравнений дает результат TRUE, то проверка ANY возвращает значение TRUE.
Например, вывести список фамилий студентов, получивших в первом семестре хотя бы одну отличную оценку.
SELECT StName
FROM Students
WHERE 5 = ANY (SELECT Mark
FROM Marks
WHERE Marks.StNo = Students.StNo AND Semester = 1)
Если вложенный запрос в проверке ANY не создает ни одной строки результата или если результаты содержат значения NULL, то в различных СУБД проверка ANY может выполняться по-разному. В стандарте ANSI/ISO для языка SQL содержатся подробные правила, определяющие результаты проверки ANY, когда проверяемое значение сравнивается со столбцом результатов вложенного запроса:
1. если вложенный запрос возвращает пустой столбец результатов, то проверка ANY имеет значение FALSE (в результате выполнения вложенного запроса не получено ни одного значения, для которого выполнялось бы условие сравнения).
2. если операция сравнения имеет значение TRUE хотя бы для одного значения в столбце, то проверка ANY возвращает значение TRUE (имеется некоторое значение, полученное вложенным запросом, для которого условие сравнения выполняется).
3. если операция сравнения имеет значение FALSE для всех значений в столбце, то проверка ANY возвращает значение FALSE (можно утверждать, что ни для одного значения, возвращенного вложенным запросом, условие сравнения не выполняется);
4. если операция сравнения не имеет значение TRUE ни для одного значения в столбце, но в нем имеется одно или несколько значений NULL то проверка ANY возвращает результат NULL. (В этой ситуации невозможно но с определенностью утверждать, существует ли полученное вложенным запросом значение, для которого выполняется условие сравнения; может быть, существует, а может и нет – все зависит от "настоящих" значений неизвестных данных.)
Проверка ALL. В проверке ALL, как и в проверке ANY, используется один из шести операторов (=, <>, <, <=, >, >=) для сравнения одного проверяемого значения со столбцом данных, возвращенным вложенным запросом. Проверяемое значение поочередно сравнивается с каждым значением, содержащимся в столбце. Если все сравнения дают результат TRUE, то проверка ALL возвращает значение TRUE.
Например, вывести список фамилий студентов, получивших в первом семестре только удовлетворительные оценки.
SELECT StName
FROM Students
WHERE 3 = ALL (SELECT Mark
FROM Marks
WHERE Marks.StNo = Students.StNo AND Semester = 1)
Если вложенный запрос в проверке ALL не возвращает ни одной строки или если результаты запроса содержат значения NULL, то в различных СУБД проверка ALL может выполняться по-разному. В стандарте ANSI/ISO для языка SQL содержатся подробные правила, определяющие результаты проверки ALL, когда проверяемое значение сравнивается со столбцом результатов вложенного запроса:
1. если вложенный запрос возвращает пустой столбец результатов, то проверка ALL имеет значение TRUE. Считается, что условие сравнения выполняется, даже если результаты вложенного запроса отсутствуют.
2. если операция сравнения дает результат TRUE для каждого значения в столбце, то проверка ALL возвращает значение TRUE. Условие сравнения выполняется для каждого значения, полученного вложенным запросом.
3. если операция сравнения дает результат FALSE для какого-нибудь значения в столбце, то проверка ALL возвращает значение FALSE. В этом, случае можно утверждать, что условие поиска выполняется не для каждого значения, полученного вложенным запросом.
4. если операция сравнения не дает результат FALSE ни для одного значения в столбце, но для одного или нескольких значений дает результат NULL, то проверка ALL возвращает значение NULL. В этой ситуации нельзя с определенностью утверждать, для всех ли значений, полученных вложенным запросом, справедливо условие сравнения; может быть, для всех, а может и нет – все зависит от "настоящих" значений неизвестных данных.
10.4.2 Вложенные запросы и объединенияПри чтении данной главы вы, возможно, заметили, что многие запросы, записанные с применением вложенных запросов, можно также записать в виде многотабличных запросов. Такое случается довольно часто, и SQL позволяет записать запрос любым способом.
10.4.3 Уровни вложенности запросовВсе рассмотренные до сих пор запросы были "двухуровневыми" и состояли из главного и вложенного запросов. Точно так же, как внутри главной запроса может находится вложенный запрос, внутри вложенного запроси может находиться еще один вложенный запрос.
10.4.4 Вложенные запросы в предложении HAVINGХотя вложенные запросы чаще всего применяются в предложении WHERE их можно использовать и в предложении HAVING главного запроса. Когда вложенный запрос содержится в предложении HAVING, он участвует в отбор группы строк.
Литература:
1. Джеймс Р. Грофф, Пол Н. Вайнберг. SQL: полное руководство: пер.с англ. –К.: Издательская группа BHV, 2000.–608с. Стр. 169–217.
ЛЕКЦИЯ 11. Язык SQL. (продолжение)11.1 Внесение изменений в базу данных.
11.2 Удаление существующих данных (Оператор DELETE)
11.3 Обновление существующих данных (Оператор UPDATE)
11.4 Определение структуры данных в SQL
11.5 Понятие представления.
11.6 Представления в SQL.
11.7 Системный каталог (самостоятельное изучение)
11.1 Внесение изменений в базу данных.
SQL представляет собой полноценный язык, предназначенный для работы с данными и позволяющий не только извлекать информацию из базы данных с помощью запросов на чтение, но и изменять содержащуюся в ней информацию с помощью запросов на добавление, удаление и обновление.
По сравнению с оператором SELECT, с помощью которого выполняются запросы на чтение, операторы SQL, изменяющие содержимое базы данных, являются более простыми. Однако при изменении содержимого базы данных к СУБД предъявляется ряд дополнительных требований. При внесении изменений СУБД должна сохранять целостность данных и разрешать ввод в базу данных только допустимых значений, а также обеспечивать непротиворечивость базы данных даже в случае системной ошибки. Помимо этого, СУБД должна обеспечивать возможность одновременного изменения базы данных несколькими пользователями таким образом, чтобы они не мешали друг другу.
11.1.1 Добавление новых данных (оператор INSERT).Однострочный оператор INSERT, синтаксис которого описан ниже, добавляет в таблицу новую строку. В предложении INTO указывается таблица, в которую добавляется новая строка (целевая таблица), а в предложении VALUES содержатся значения данных для новой строки. Список столбцов определяет, какие значения в какой столбец заносятся.
INSERT INTO имя_таблицы (имя_столбца,…) VALUES (константа | NULL,…)
Ниже приведен пример оператора INSERT, который добавляет информацию о новой группе ²К-99-51² в учебную базу данных:
INSERT INTO Groups(GrNo, EnterYear, GrName)
VALUES(6, 1999, 'К-99-51')
Добавление значений NULL. При добавлении в таблицу новой строки всем столбцам, имена которых отсутствуют в списке столбцов оператора INSERT, автоматически присваивается значение NULL.
Добавление всех столбцов. Для удобства в SQL разрешается не включать список столбцов в оператор INSERT. Если список столбцов опущен, он генерируется автоматически и в нем слева направо перечисляются все столбцы таблицы. При выполнении оператора SELECT * генерируется такой же список столбцов. Пользуясь этой сокращенной формой записи, оператор INSERT из предыдущего примера можно переписать таким образом:
INSERT INTO Groups
VALUES(6, 1999, 'К-99-51')
Если список столбцов опущен, то в списке значений необходимо явно указывать значение NULL. Кроме того, последовательность значений данных должна в точности соответствовать порядку столбцов в таблице.
Многострочный оператор INSERT, добавляет в целевую таблицу несколько строк. В этой разновидности оператора INSERT значения данных для новых строк явно не задаются. Источником новых строк служит запрос на чтение, содержащийся внутри оператора INSERT.
INSERT INTO имя_таблицы (имя_столбца,…) запрос
11.2 Удаление существующих данных (Оператор DELETE)Наименьшей единицей информации, которую можно удалить из реляционной базы данных, является одна строка.
Оператор DELETE, синтаксис которого изображен ниже, удаляет выбранные строки данных из одной таблицы.
DELETE FROM имя_таблицы [WHERE условие_поиска]
В предложении FROM указывается таблица, содержащая строки, которые требуется удалить. В предложении WHERE указываются строки, которые должны быть удалены.
Например, удалить из учебной базы данных студента с кодом 3.
DELETE FROM Students
WHERE StNo = 3
Хотя предложение WHERE в операторе DELETE является необязательным, оно присутствует почти всегда. Если же оно отсутствует, то удаляются все строки целевой таблицы.
Иногда отбор строк необходимо производить, опираясь на данные из других таблиц. Для этого можно использовать вложенные запросы.
11.3 Обновление существующих данных (Оператор UPDATE)Оператор UPDATE, обновляет значения одного или нескольких столбцов в выбранных строках одной таблицы.
UPDATE имя_таблицы
SET имя_столбца = выражение,...
[WHERE условие_поиска]
В операторе указывается целевая таблица, которая должна быть модифицирована, при этом пользователь должен иметь разрешение на обновление таблицы и каждого конкретного столбца. Предложение WHERE отбирает строки таблицы, подлежащие обновлению. В предложении SET указывается, какие столбцы должны быть обновлены, и для них задаются новые значения.
Например, Изменить фамилию студента ²Петрова² с кодом 2 на фамилию ²Петренко²:
UPDATE Students
SET StName = 'Петренко'
WHERE StNo = 2
Условия поиска, которые могут быть заданы в предложении WHERE оператора UPDATE, в точности соответствуют условиям поиска, доступным в операторах SELECT и DELETE.
Как и оператор DELETE, оператор UPDATE может одновременно обновить несколько строк, соответствующих условию поиска.
Предложение WHERE в операторе UPDATE является необязательным. Если оно опущено, то обновляются все строки целевой таблицы.
В операторе UPDATE, так же как и в операторе DELETE, вложенные запросы могут играть важную роль, поскольку они дают возможность отбирать строки для обновления, опираясь на информацию из других таблиц.
11.4 Определение структуры данных в SQL
В реляционной базе данных наиболее важным элементом ее структуры является таблица. В многопользовательской базе данных основные таблицы, как правило, создает администратор, а пользователи просто обращаются и ним в процессе работы. При работе с базой данных часто оказывается удобным создавать собственные таблицы и хранить в них собственные данные, а также данные, прочитанные из других таблиц. Такие таблицы могут быть временными и существовать только в течение одного интерактивного SQL‑сеанса, но могут сохраняться и в течение нескольких недель или даже месяцев.
11.4.1 Создание таблицы (оператор CREATE TABLE)Оператор CREATE TABLE, синтаксис которого изображен ниже, определяет новую таблицу. Различные предложения оператора задают элементы определений таблицы. следует также помнить, что не все параметры стандарта SQL2 присутствуют во всех СУБД.
После выполнения оператора CREATE TABLE появляется новая таблица, которой присваивается имя, указанное в операторе. Имя таблицы должно быть идентификатором, допустимым в SQL, и не должно конфликтовать с именами существующих таблиц.
CREATE TABLE имя_таблицы(
определение столбцов
имя_столбца тип_данных [DEFAULT значение] [NOT NULL],…
определение первичного ключа
PRIMARY KEY(имя_столбца,…),
определение внешних ключей
FOREIGN KEY имя_ограничения (имя_столбца,…)
REFERENCE имя_таблицы
[ON DELETE CASCADE | SET NULL | SET DEFAULT | NO ACTION]
[ON UPDATE CASCADE | SET NULL | SET DEFAULT | NO ACTION],
условие уникальности данных
UNIQUE(имя_столбца,…),
условие проверки
CHECK(условие_поиска)
)
Определения столбцов. Столбцы новой таблицы задаются в операторе CREATE TABLE. Определения столбцов представляют собой заключенный в скобки список, элементы которого отделены друг от друга запятыми. Порядок следования определений столбцов в списке соответствует расположению столбцов в таблице. Каждое такое определение содержит следующую информацию:
1. Имя столбца, которое используется для ссылки на столбец в оператора SQL. Каждый столбец в таблице должен иметь уникальное имя, но' разных таблицах имена столбцов могут совпадать.
2. Тип данных столбца, показывающий, данные какого вида хранятся в столбце.
3. Указание на то, обязательно ли столбец должен содержать данные. Предложение NOT NULL предотвращает занесение в столбец значений NULL, в противном случае значения NULL допускаются.
4. Значение по умолчанию для столбца СУБД, которое заносится в столбец в том случае, если в операторе INSERT для таблицы не определено значение данного столбца.
Определения первичного и внешнего ключей. Кроме определений столбцов таблицы, в операторе CREATE TABLE указывается информация о первичном ключе таблицы и о ее связях с другими таблицами базы данных Эта информация содержится в предложениях PRIMARY KEY и FOREIGN KEY.
В предложении PRIMARY KEY задается столбец или столбцы, которые образуют первичный ключ таблицы. Этот столбец (или комбинация столбцов) служит в качестве уникального идентификатора строк таблицы. СУБД автоматически следит за тем, чтобы первичный ключ каждой строки таблицы имел уникальное значение. Кроме того, в определениях столбцов первичного ключа должно быть указано, что они не могут содержать значения NULL .
В предложении FOREIGN KEY задается внешний ключ таблицы и определяется связь, которую он создает для нее с другой таблицей (таблицей-предком). В нем указываются:
1. столбец или столбцы создаваемой таблицы, которые образуют внешний ключ;
2. таблица, связь с которой создает внешний ключ. Это таблица-предок;
3. необязательное имя для этого отношения; оно не используется в операторах SQL, но может появляться в сообщениях об ошибках и потребуется в дальнейшем, если будет необходимо удалить внешний ключ;
4. как СУБД должна обращаться со значениями NULL в одном или нескольких столбцах внешнего ключа при связывании его со строками таблицы-предка;
5. необязательное правило удаления для данного отношения (CASCADE, SET NULL, SET DEFAULT или NO ACTION), которое определяет действие, предпринимаемое при удалении строки-предка;
6. необязательное правило обновления для данного отношения, которое определяет действие, предпринимаемое при обновлении первичного ключа в строке-предке;
7. необязательное условие проверки, которое ограничивает данные в таб лице так, чтобы они отвечали определенному условию поиска.
Например, создать таблицу Students.
CREATE TABLE Students (
StNo INT NOT NULL,
GrNo INT NOT NULL,
StName CHAR(30) NOT NULL,
CityNo INT,
PRIMARY KEY (StNo),
FOREIGN KEY Students_Groups(GrNo)
REFERENCES Groups,
FOREIGN KEY Students_Cities(CityNo)
REFERENCES Cities,
CHECK(CHAR_LENGTH(StName)>10)
)
11.4.2 Удаление таблицы (оператор DROP TABLE)Таблицы можно удалить из базы данных посредством оператора DROP TABLE.
DROP TABLE имя_таблицы CASCADE | RESTRICT
Оператор содержит имя удаляемой таблицы. Обычно пользователь удаляет одну из своих собственных таблиц и указывает в операторе неполное. имя таблицы. Имея соответствующее разрешение, можно также удалите таблицу другого пользователя, но в этом случае необходимо указывать полное имя таблицы.
Стандарт SQL2 требует, чтобы оператор DROP TABLE включал в себя либо параметр CASCADE, либо RESTRICT, которые определяют, как влияет удаление таблицы на другие объекты базы данных. Если задан параметр RESTRICT и в базе данных имеются объекты, которые содержат ссылку на удаляемую таблицу, то выполнение оператора DROP TABLE закончится неуспешно. В большинстве коммерческих СУБД допускается применение оператора DROP TABLE без каких-либо параметров.
11.4.3 Изменение определения таблицы (оператор ALTER TABLE)В процессе работы с таблицей иногда возникает необходимость добавить в таблицу некоторую информацию. Для изменения структуры таблицы используется оператор ALTER TABLE, с помощью которого возможно:
1. добавить в таблицу определение столбца;
2. изменить значение по умолчанию для какого-либо столбца;
3. добавить или удалить первичный ключ таблицы;
4. добавить или удалить новый внешний ключ таблицы;
5. добавить или удалить условие уникальности;
6. добавить или удалить условие проверки.
ALTER TABLE имя_таблицы
ADD определение_столбца
ALTER имя_столбца SET DEFAULT значение | DROP DEFAULT
DROP имя_столбца CASCADE | RESTRICT
ADD определение_первичного_ключа
ADD определение_внешнегого_ключа
ADD условие_уникальности_данных
ADD условие_проверки
DROP CONSTRAINT имя_ограничения CASCADE | RESTRICT
11.4.4 Определения доменовДля содержимого отдельного столбца таблицы в реляционной базе данных существует ограничение: значения столбца во всех строках таблицы должны быть одного и того же типа. Например, все названия городов в столбце CityName таблицы Sities являются символьными строками переменной длины.
В стандарте SQL2 формально определение домена реализовано как часть определения базы данных. Согласно этому стандарту, домен является именованной совокупностью значений данных и широко используется в определении базы данных как дополнительный тип данных. Домен создается посредством оператора CREATE DOMAIN на основе базовых типов данных. После создания домена на него можно ссылаться внутри определения таблицы как на тип данных.
11.4.5 Индексы (операторы CREATE/DROP INDEX)Одним из структурных элементов физической памяти, присутствующих в большинстве реляционных СУБД, является индекс – средство обеспечивающее быстрый доступ к строкам таблицы на основе значения одного или нескольких столбцов.
Для создания и удаления индексов применяются операторы CREATE INDEX и DROP INDEX, синтаксис которых описан ниже.
Следует также заметить, что СУБД автоматически создает индексы для первичных ключей.
CREATE [UNIQUE] INDEX имя_индекса ON имя_таблицы (имя_столбца [ASC | DESC],…)
DROP INDEX имя_индекса
11.5 Понятие представления.Когда СУБД встречает в операторе SQL ссылку на представление, она отыскивает его определение, сохраненное в базе данных. Затем СУБД преобразует пользовательский запрос, ссылающийся на представление, в эквивалентный запрос к исходным таблицам представления, и выполняет этот запрос. Таким образом, СУБД создает иллюзию существования представления в виде отдельной таблицы и в то же время сохраняет целостность исходных таблиц.
11.5.1 Преимущества представленийПрименение представлений в базах данных различных типов может оказаться полезным в самых разнообразных ситуациях. В базах данных на персональных компьютерах представления применяются для удобства и позволяют упрощать запросы к базе данных. В промышленных базах данных представления играют главную роль в создании собственной структуры базы данных для каждого пользователя и обеспечении ее безопасности. Основные преимущества представлений перечислены ниже.
1. Безопасность. Каждому пользователю можно разрешить доступ к небольшому числу представлений, содержащих только ту информацию, которую ему позволено знать. Таким образом, можно осуществить ограничение доступа пользователей к хранимой информации.
2. Простота запросов. С помощью представления можно прочитать данные из нескольких таблиц и представить их как одну таблицу, превращая тем самым запрос ко многим таблицам в однотабличный запрос к представлению.
3. Простота структуры. С помощью представлений для каждого пользователя можно создать собственную "структуру" базы данных, определив ее как множество доступных пользователю виртуальных таблиц.
4. Защита от изменений. Представление может возвращать непротиворечивый и неизменный образ структуры базы данных, даже если исходные таблицы разделяются, реструктуируются или переименовываются.
5. Целостность данных. Если доступ к данным или ввод данных осуществляется с помощью представления, СУБД может автоматически проверять, выполняются ли определенные условия целостности.
11.5.2 Недостатки представленийНаряду с перечисленными выше преимуществами, представления обладают и двумя существенными недостатками;
1. Производительность. Представление создает лишь видимость существования соответствующей таблицы, и СУБД приходится преобразовывать запрос к представлению в запрос к исходным таблицам. Если представление отображает многотабличный запрос, то простой запрос к представлению становится сложным объединением и на его выполнение может потребоваться много времени.
2. Ограничения на обновление. Когда пользователь пытается обновить строки представления, СУБД должна установить их соответствие строкам исходных таблиц, а также обновить последние. Это возможно только для простых представлений; сложные представления обновлять нельзя, они доступны только для чтения.
Указанные недостатки означают, что не стоит без разбора применять представления вместо исходных таблиц. В каждом конкретном случае необходимо учитывать перечисленные преимущества и недостатки представлений.
11.6 Представления в SQL.Оператор CREATE VIEW, синтаксис которого изображен ниже, используется для создания представлений. В нем указываются имя представления и запрос, лежащий в его основе. Для успешного создания представления необходимо иметь разрешение на доступ ко всем таблицам, входящим в запрос.
CREATE VIEW имя_представления (имя_столбца,…) AS запрос
При необходимости в операторе CREATE VIEW можно задать имя для каждого столбца создаваемого представления. Если указывается список имен столбцов, то он должен содержать столько элементов, сколько столбцов содержится в запросе. Обратите внимание на то, что задаются только имена. Например, создать представление, содержащее фамилии студентов группы A-98-51.
CREATE VIEW GroupA98 (Name) AS
SELECT StName
FROM Students INNER JOIN Groups ON Students.GrNo = Groups.GrNo
WHERE Groups.GrName = 'A-98-51'
11.6.1 Обновление представлений и стандарт ANSI/ISOВ стандарте SQL1 точно указано, для каких представлений в базе данных должна существовать возможность обновления. Согласно стандарту, представление можно обновлять в том случае, если определяющий его запрос соответствует следующим требованиям:
1. Должен отсутствовать предикат DISTINCT, т.е. повторяющиеся строки не должны исключаться из таблицы результатов запроса.
2. В предложении FROM должна быть задана только одна таблица, которую можно обновлять; т.е. у представления должна быть одна исходная таблица, а пользователь должен иметь соответствующие права доступа к ней. Если исходная таблица сама является представлением, то оно также должно удовлетворять этим условиям.
3. Каждое имя в списке возвращаемых столбцов должно быть ссылкой на простой столбец; в этом списке не должны содержаться выражения, вычисляемые столбцы или агрегатные функции.
4. Предложение WHERE не должно содержать вложенный запрос; в нем могут присутствовать только простые условия поиска.
5. В запросе не должно содержаться предложение GROUP BY или HAVING.
Правила, установленные в стандарте SQL1, являются очень жесткими. Существует множество представлений, которые теоретически можно обновлять, хотя они не соответствуют этим правилам. Кроме того, существуют представления, над которыми можно производить не все операции обновления, а также представления, в которых можно обновлять не все столбцы. В большинстве коммерческих СУБД правила обновления представлений значительно менее строги, чем в стандарте SQL1.
11.6.2 Удаление представления (оператор DROP VIEW)В стандарте SQL2 было формально закреплено использование оператора DROP VIEW для удаления представлений. В нем также детализированы правила удаления представлений, на основе которых были созданы другие представления.
DROP VIEW имя_представления CASCADE | RESTRICT
11.7 Системный каталог (самостоятельное изучение)
11.7.1 Понятие системный каталог
Системным каталогом называется совокупность специальных таблиц базы данных. Их создает, сопровождает и владеет ими сама СУБД. Эти системные таблицы содержат информацию, которая описывает структуру базы данных. Таблицы системного каталога создаются автоматически при создании базы данных. Обычно они объединяются под специальным "системным идентификатором пользователя" с таким именем, как SYSTEM, SYSTEM, MASTER или DBA.
При обработке операторов SQL СУБД постоянно обращается к данным системного каталога. Например, чтобы обработать двухтабличный оператор SELECT, СУБД должна:
1. проверить, существуют ли две указанные таблицы;
2. убедиться, что пользователь имеет разрешение на доступ к ним;
3. проверить, существуют ли столбцы, на которые имеются ссылки в данном запросе;
4. установить, к каким таблицам относятся неполные имена столбцов;
5. определить тип данных каждого столбца.
Если бы системные таблицы служили только для удовлетворения внутренних потребностей СУБД, то для пользователей базы данных они не представляли бы практически никакого интереса. Однако системные таблицы, как правило, доступны также и для пользователей – запросы к системным каталогам разрешены почти во всех СУБД для персональных компьютеров и больших ЭВМ. С помощью запросов к системным каталогам вы можете получить информацию о структуре базы данных, даже если никогда раньше с ней не работали.
Пользователи могут только считывать информацию из системного каталога. СУБД запрещает пользователям модифицировать системные таблицы непосредственно, так как это может нарушить целостность базы данных. СУБД сама вставляет, удаляет и обновляет строки системных таблиц во время модификации структуры базы данных. Изменения в системных таблицах происходят также в качестве побочного результата выполнения таких операторов DDL, как CREATE, ALTER, DROP, GRANT И REVOKE.
11.7.2 Системный каталог и стандарт ANSI/ISOВ стандарте SQL1 ничего не говорится о структуре и содержании системного каталога. Стандарт фактически не требует даже наличия самого системного каталога. Однако во всех основных реляционных СУБД в той или иной форме он создается. Структура каталога и содержащиеся в нем таблицы значительно отличаются друг от друга в разных СУБД.
В связи с растущим значением инструментальных программ общего назначения, предназначенных для работы с базами данных и требующих доступа к системному каталогу, в стандарт SQL2 включена спецификация набора представлений, обеспечивающая стандартизированный доступ к информации, которая обычно содержится в системном каталоге. СУБД, соответствующая стандарту SQL2, должна поддерживать эти представления, (обозначаемые все вместе как INFORMATION_SCHEMA (информационная схема).
11.7.3 Содержимое системного каталогаКаждая таблица системного каталога содержит информацию об отдельном структурном элементе базы данных. В состав почти всех коммерческих реляционных СУБД входят, с небольшими различиями, системные таблицы, каждая из которых описывает один из следующих пяти элементов:
1. Таблицы. В каталоге описывается каждая таблица базы данных: указывается ее имя, владелец, число содержащихся в ней столбцов, их размер и т.д.
2. Столбцы. В каталоге описывается каждый столбец базы данных: приводится имя столбца, имя таблицы, которой он принадлежит, тип данных столбца, его размер, разрешены ли значения null и т.д.
3. Пользователи. В каталоге описывается каждый зарегистрированный пользователь базы данных: указываются имя пользователя, его пароль в зашифрованном виде и другие данные.
4. Представления. В каталоге описывается каждое представление, имеющееся в базе данных: указываются его имя, имя владельца, запрос, являющийся определением представления, и т.д.
5. Привилегии. В каталоге описывается каждый набор привилегий, предоставленных в базе данных: приводятся имена тех, кто предоставил привилегии, и тех, кому они предоставлены, указываются сами привилегии, объект, на которые они распространяются, и т.д.
11.7.4 Информационная схема в стандарте SQL2В стандарте SQL2 не определена форма системного каталога, которую должны поддерживать реляционные СУБД. Поскольку в то время, когда принимался стандарт SQL2, уже существовал широкий разброс характеристик коммерческих СУБД различных типов и огромные различия в их системных каталогах, было невозможно достичь согласия по вопросу стандартной спецификации системного каталога. Вместо этого авторы стандарта дали определение "идеализированного" системного каталога, который поставщики СУБД могли бы применять при разработке "с нуля" СУБД, соответствующих стандарту SQL2. Таблицы этого идеализированного системного каталога (который в стандарте называется схема определений) приведены в табл. 11.1.
табл. 11.1 Идеализированный системный каталог, описанный в стандарте SQL2
| Системная таблица | Содержимое |
| USERS | Одна строка для каждого идентификатора пользователя в каталоге |
| SCHEMATA | Одна строка для каждой информационной схемы в каталоге |
| DATA_TYPE_DESCRIPTOR | Одна строка для каждого домена или столбца, имеющего какой-то тип данных |
| DOMAINS | Одна строка для каждого домена |
| DOMAIN_CONSTRAINTS | Одна строка для каждого ограничительного условия, наложенного на домен |
| TABLES | Одна строка для каждой таблицы или представления |
| VIEWS | Одна строка для каждого представления |
| COLUMNS | Одна строка для каждого столбца в каждом определении таблицы или представления |
| VIEW_TABLE_USAGE | Одна строка для каждой таблицы, на которую имеется ссылка в каком-либо определении представления (если определением представления является многотабличный запрос, каждая таблица будет представлена отдельной строкой) |
| VIEW_COLUMN_USAGE | Одна строка для каждого столбца, на который имеется ссылка в каком-либо представлении |
| TABLE_CONSTRAINTS | Одна строка для каждого ограничительного условия, заданного в каком-либо определении таблицы |
| KEY_COLUMN_USAGE | Одна строка для каждого столбца, на который наложено условие уникальности и который присутствует в определении первичного или внешнего ключа (если в определении ключа или условия уникальности указано несколько столбцов, то это определение будет представлено несколькими строками) |
| REFERENTIAL_CONSTRAINTS | Одна строка для каждого определения внешнего ключа, присутствующего в определении таблицы |
| CHECK_CONSTRAINTS | Одна строка для каждого условия проверки, заданного в определении таблицы |
| CHECK_TABLE_USAGE | Одна строка для каждой таблицы, на которую имеется ссылка в условии проверки, ограничительном условии для домена или утверждении |
| CHECK_COLUMN_USAGE | Одна строка для каждого столбца, на который имеется ссылка в условии проверки, ограничительном условии для домена или утверждении |
| ASSERTIONS | Одна строка для каждого заданного утверждения |
| TABLE_PRIVILEGES | Одна строка для каждой привилегии, предоставленной на какую-либо таблицу |
| COLUMN_PRIVILEGES | Одна строка для каждой привилегии, предоставленной на какой-либо столбец |
| USAGE_PRIVILEGES | Одна строка для каждой привилегии, предоставленной на какой-либо домен, набор символов и т.п. |
| CHARACTER_SETS | Одна строка для каждого заданного набора символов |
| COLLATIONS | Одна строка для каждой заданной последовательности сравнения |
| TRANSLATIONS | Одна строка для каждого заданного преобразования |
| SQL_LANGUAGES | Одна строка для каждого языка (например, COBOL, С и т.д.), поддерживаемого СУБД данного типа |
Стандарт SQL2 не требует, чтобы СУБД поддерживали таблицы системного каталога, приведенные в табл. 11.1 или какие-либо иные. Вместо этого в стандарте SQL2 определен ряд представлений, основанных на этих системных таблицах. Данные представления содержат те объекты базы данных, которые должны быть доступны для рядового пользователя. (Эти представления системного каталога называются в стандарте информационной схемой). Для того чтобы СУБД соответствовала стандарту SQL2, она должна поддерживать эти представления. Такой подход дает пользователю стандартный способ получения информации о доступных ему объектах базы данных с помощью стандартных запросов к представлениям системного каталога.
На практике коммерческие реляционные СУБД поддерживают стандартные представления каталога путем создания соответствующих представлений на основе таблиц своих собственных системных каталогов. Информация в системных каталогах большинства СУБД достаточно близка к требуемой в стандарте, поэтому определения стандартных представлений каталога, создаваемых в этих СУБД, будут относительно простыми.
Представления системного каталога, требуемые стандартом SQL2, приведены в табл. 11.2. В ней дается краткое описание информации, которая содержится в каждом представлении. В стандарте определены также три домена, которые .используются представлениями системного каталога и являются доступными для пользователей. Эти домены приведены в табл. 11.3.
табл. 11.2 Представления системного каталога, установленные стандартом SQL2
| Представление в системном каталоге | Содержимое |
| INFORMATION_SСНЕМА_CATALOG_NAME | Одна строка с именем базы данных для каждого пользователя ("каталога" по терминологии стандарта SQL2), описываемого данной информационной схемой |
| SCHEMATA | Одна строка для каждой информационной схемы в базе данных, принадлежащей текущему пользователю; содержит имя схемы, набор символов по умолчанию и т.д. |
| DOMAINS | Одна строка для каждого домена, доступного текущему пользователю; содержит имя домена, базовый тип данных, набор символов, максимальную длину, степень, точность и т.д. |
| DOMAIN_CONSTRAINTS | Одна строка для каждого ограничительного условия домена; содержит имя условия и его характеристики |
| TABLES | Одна строка для каждой таблицы или представления, доступных пользователю; содержит имя и признак того, идет ли речь о таблице или представлении |
| VIEWS | Одна строка для каждого представления, доступного пользователю; содержит имя, информацию о режиме контроля и возможности обновления. |
| COLUMNS | Одна строка для каждого столбца, доступного пользователю; содержит имя столбца, имя таблицы или представления, которые содержат данный столбец, тип содержащихся в нем данных, степень, точность, набор символов и т.д. |
| TABLE_PRIVILEGES | Одна строка для .каждой привилегии на таблицу, предоставленной пользователю или предоставленной им другому пользователю; содержит имя таблицы, тип привилегии, указание на то, кто предоставил привилегию, кому она предоставлена и имеет ли пользователь право предоставления этой привилегии |
| COLUMN_PRIVILEGES | Одна строка для каждой привилегии на столбец, предоставленной пользователю или предоставленной им другому пользователю; содержит имя таблицы и столбца, тип привилегии, указание на то, кто предоставил привилегию, кому она предоставлена и имеет ли пользователь право предоставления этой привилегии |
| USAGE_PRIVILEGES | Одна строка для каждой привилегии, предоставленной пользователю или пользователем на какой-либо домен, набор символов и т.п. |
| TABLE_CONSTRAINTS | Одна строка на каждое ограничительное условие (первичный ключ, внешний ключ, условие уникальности или условие проверки), заданное для таблицы, которой владеет пользователь; содержит имя условия и таблицы, тип условия и его характеристики |
| REFERENTIAL_CONSTRAINTS | Одна строка для каждого ссылочного ограничения (определения внешнего ключа) на таблицу, которой владеет пользователь; содержит имя ограничения, имя таблицы-потомка и имя таблицы-предка |
| CHECK__CONSTRAINTS | Одна строка на каждое условие проверки для таблицы, которой владеет пользователь |
| KEY_COLUMN_USAGE | Одна строка для каждого столбца первичного или внешнего ключа, на который (столбец) наложено ), условие уникальности и который входит в таблицу, принадлежащую пользователю; строка содержит имя таблицы, имя столбца и позицию столбца в ключе |
| ASSERTIONS | Одна строка для каждого утверждения, которым владеет пользователь; содержит имя утверждения и его характеристики |
| CHARACTER_SETS | Одна строка для каждого определения набора символов, доступного пользователю |
| COLLATIONS | Одна строка для каждого определения последовательности сравнения, доступного пользователю |
| TRANSLATIONS | Одна строка для каждого определения преобразования, доступного пользователю |
| VIEW_TABLE_USAGE | Одна строка для каждой таблицы, на которую имеется ссылка в определениях представлений, принадлежащих пользователю; строка содержит имя таблицы |
| VIEW_COLUMN_USAGE | Одна строка для каждого столбца, на который имеется ссылка в представлениях, принадлежащих пользователю; строка содержит имя столбца и таблицы, в которую входит столбец |
| CONSTRAINT_TABLE_ | Одна строка для каждой таблицы, на которую имеется ссылка в условии проверки, условии уникальности, утверждении и определении внешнего ключа, принадлежащих пользователю |
| CONSTRAINT_COLUMN_ | Одна строка для каждого столбца, на который имеется ссылка в условии проверки, условии уникальности, утверждении и определении внешнего ключа, принадлежащих пользователю |
| SQL_LANGUAGES | Одна строка для каждого языка (например, COBOL, С и т.д.), поддерживаемого СУБД данного типа; в строке указывается уровень соответствия языка стандарту SQL2, тип поддерживаемого диалекта SQL и т.д. |
табл. 11.3 Домены, определенные в стандарте SQL2
| Системный домен | Область значений домена |
| SQL_IDENTIFIER | Домен всех символьных строк переменной длины, которые являются допустимыми идентификаторами SQL согласно стандарту SQL2. Любое значение, взятое из этого (домена, является допустимым именем таблицы, именем столбца и т.д. |
| CHARACTER_DATA | Домен всех символьных строк переменной длины, имеющих длину от нуля до максимального значения, поддерживаемого данной СУБД. Значение, взятое из этого домена, является допустимой символьной строкой. |
| CARDINAL_NUMBER | Домен всех неотрицательных чисел от нуля до максимального целого числа, с которым может работать данная СУБД. Значение, взятое из этого домена, является нулем или допустимым положительным числом. |
Вот примеры нескольких запросов, используемых для извлечения информации о структуре базы данных из представлений системного каталога, определенных в стандарте SQL2:
1. Вывести имена всех таблиц и представлений пользователя, работающего в настоящий момент с базой данных.
SELECT TABLE_NAME
FROM TABLES
2. Вывести имя, позицию и тип данных для каждого столбца во всех представлениях.
SELECT TABLE_NAME, С.COLUMN_NAME, ORDINAL_POSITION, DATAJTYPE
FROM COLUMNS
WHERE (COLUMNS.TABLE_NAME IN (SELECT TABLE_NAME FROM VIEWS))
3. Определить, сколько столбцов имеется в таблице STUDENTS.
SELECT COUNT(*)
FROM COLUMNS
WHERE (TABLE_NAME = 'STUDENTS')
Литература:
1. Джеймс Р. Грофф, Пол Н. Вайнберг. SQL: полное руководство: пер.с англ. –К.: Издательская группа BHV, 2000.–608с. Стр. 295–346.
ЛЕКЦИЯ 12. Обеспечение безопасности БД12.1 Общие положения
12.2 Методы обеспечения безопасности
12.3 Избирательное управление доступом
12.4 Обязательное управление доступом
12.5 Шифрование данных
12.6 Контрольный след выполняемых операций
12.7 Поддержка мер обеспечения безопасности в языке SQL
12.8 Директивы GRANT и REVOKE
12.9 Представления и безопасность
12.1 Общие положения
Термины безопасность и целостность в контексте обсуждения баз данных часто используется совместно, хотя на самом деле, это совершенно разные понятия. Термин безопасность относится к защите данных от несанкционированного доступа, изменения или разрушения данных, а целостность – к точности или истинности данных. По-другому их можно описать следующим образом:
1. под безопасностью подразумевается, что пользователям разрешается выполнять некоторые действия;
2. под целостностью подразумевается, что эти действия выполняются корректно.
Между ними есть, конечно, некоторое сходство, поскольку как при обеспечении безопасности, так и при обеспечении целостности система вынуждена проверить, не нарушают ли выполняемые пользователем действия некоторых правил. Эти правила должны быть заданы (обычно администратором базы данных) на некотором удобном для этого языке и сохранены в системном каталоге. Причем в обоих случаях СУБД должна каким-то образом отслеживать все действия пользователя и проверять их соответствие заданным правилам.
Среди многочисленных аспектов проблемы безопасности необходимо отметить следующие:
1. Правовые, общественные и этические аспекты (имеет ли право некоторое лицо получить запрашиваемую информацию, например об оценках студента).
2. Физические условия (например, закрыт ли данный компьютер или терминальная комната или защищен каким-либо другим образом).
3. Организационные вопросы (например, как в рамках предприятия, обладающего некой системой, организован доступ к данным).
4. Вопросы реализации управления (например, если используется метод доступа по паролю, то как организована реализация управления и как часто меняются пароли).
5. Аппаратное обеспечение (обеспечиваются ли меры безопасности на аппаратном уровне, например, с помощью защитных ключей или привилегированного режима управления).
6. Безопасность операционной системы (например, затирает ли базовая операционная система содержание структуры хранения и файлов с данными при прекращении работы с ними).
7. И наконец, некоторые вопросы, касающиеся непосредственно самой системы управления базами данных (например, существует ли для базы данных некоторая концепция предоставления прав владения данными).
В настоящей лекции рассматриваются вопросы, касающиеся последнего пункта этого перечня.
12.2 Методы обеспечения безопасностиВ современных СУБД поддерживается один из двух широко распространенных подходов к вопросу обеспечения безопасности данных, а именно избирательный подход или обязательный подход. В обоих подходах единицей данных или "объектом данных", для которых должна быть создана система безопасности, может быть как вся база данных целиком или какой-либо набор отношений, так и некоторое значение данных для заданного атрибута внутри некоторого кортежа в определенном отношении. Эти подходы отличаются следующими свойствами:
1. В случае избирательного управления некий пользователь обладает различными правами (привилегиями или полномочиями) при работе с разными объектами. Более того, разные пользователи обычно обладают и разными правами доступа к одному и тому же объекту. Поэтому избирательные схемы характеризуются значительной гибкостью.
2. В случае обязательного управления, наоборот, каждому объекту данных присваивается некоторый классификационный уровень, а каждый пользователь обладает некоторым уровнем допуска. Следовательно, при таком подходе доступом к определенному объекту данных обладают только пользователи с соответствующим уровнем допуска. Поэтому обязательные схемы достаточно жестки и статичны.
Независимо от того, какие схемы используются – избирательные или обязательные, все решения относительно допуска пользователей к выполнению тех или иных операций принимаются на стратегическом, а не техническом уровне. Поэтому они находятся за пределами досягаемости самой СУБД, и все, что может в такой ситуации сделать СУБД, – это только привести в действие уже принятые ранее решения. Исходя из этого, можно отметить следующее:
Во-первых. Результаты стратегических решений должны быть известны системе (т.е. выполнены на основе утверждений, заданных с помощью некоторого подходящего языка) и сохраняться в ней (путем сохранения их в каталоге в виде правил безопасности, которые также называются полномочиями).
Во-вторых. Очевидно, должны быть некоторые средства регулирования запросов доступа по отношению к соответствующим правилам безопасности. (Здесь под "запросом, доступа" подразумевается комбинация запрашиваемой операции, запрашиваемого, объекта и запрашивающего пользователя.) Такая проверка выполняется подсистемой безопасности СУБД, которая также называется подсистемой полномочий.
В-третьих. Для того чтобы разобраться, какие правила безопасности к каким запросам доступа применяются, в системе должны быть предусмотрены способы опознания источника этого запроса, т.е. опознания запрашивающего пользователя. Поэтому в момент входа в систему от пользователя обычно требуется ввести не только его идентификатор (например, имя или должность), но также и пароль (чтобы подтвердить свои права на заявленные ранее идентификационные данные). Обычно предполагается, что пароль известен только системе и некоторым лицам с особыми правами.
В отношении последнего пункта стоит заметить, что разные пользователи могут обладать одним и тем же идентификатором некоторой группы. Таким образом, в системе могут поддерживаться группы пользователей и обеспечиваться одинаковые права доступа для пользователей одной группы, например для всех лиц из расчетного отдела. Кроме того, операции добавления отдельных пользователей в группу или их удаления из нее могут выполняться независимо от операции задания привилегий для этой группы. Обратите внимание, однако, что местом хранения информации о принадлежности к группе также является системный каталог (или, возможно, база данных).
Перечисленные выше методы управления доступом на самом деле являются частью более общей классификации уровней безопасности. Прежде всего в этих документах определяется четыре класса безопасности (security classes) – D, С, В и А. Среди них класс D наименее безопасный, класс С – более безопасный, чем класс D, и т.д. Класс D обеспечивает минимальную защиту, класс С – избирательную, класс В – обязательную, а класс А – проверенную защиту.
Избирательная защита. Класс С делится на два подкласса – С1 и С2 (где подкласс С1 менее безопасен, чем подкласс С2), которые поддерживают избирательное управление доступом в том смысле, что управление доступом осуществляется по усмотрению владельца данных.
Согласно требованиям класса С1 необходимо разделение данных и пользователя, т.е. наряду с поддержкой концепции взаимного доступа к данным здесь возможно также организовать раздельное использование данных пользователями.
Согласно требованиям класса С2 необходимо дополнительно организовать учет на основе процедур входа в систему, аудита и изоляции ресурсов.
Обязательная защита. Класс В содержит требования к методам обязательного управления доступом и делится на три подкласса – В1, В2 и В3 (где В1 является наименее, а В3 – наиболее безопасным подклассом).
Согласно требованиям класса В1 необходимо обеспечить "отмеченную защиту" (это значит, что каждый объект данных должен содержать отметку о его уровне классификации, например: секретно, для служебного пользования и т.д.), а также неформальное сообщение о действующей стратегии безопасности.
Согласно требованиям класса В2 необходимо дополнительно обеспечить формальное утверждение о действующей стратегии безопасности, а также обнаружить и исключить плохо защищенные каналы передачи информации.
Согласно требованиям класса В3 необходимо дополнительно обеспечить поддержку аудита и восстановления данных, а также назначение администратора режима безопасности.
Проверенная защита. Класс А является наиболее безопасным и согласно его требованиям необходимо математическое доказательство того, что данный метод обеспечения безопасности совместимый и адекватен заданной стратегии безопасности.
Хотя некоторые коммерческие СУБД обеспечивают обязательную защиту на уровне класса В1, обычно они обеспечивают избирательное управление на уровне класса С2.
12.3 Избирательное управление доступомИзбирательное управление доступом поддерживается многими СУБД. Избирательное управление доступом поддерживается в языке SQL.
В общем случае система безопасности таких СУБД базируется на трех компонентах:
1. Пользователи. СУБД выполняет любое действия с БД от имени какого-то пользователя. Каждому пользователю присваивается идентификатор – короткое имя, однозначно определяющее пользователя в СУБД. Для подтверждения того, что пользователь может работать с введенным идентификатором используется пароль. Таким образом, с помощью идентификатора и пароля производится идентификация и аутентификация пользователя. Большинство коммерческих СУБД позволяет объединять пользователей с одинаковыми привилегиями в группы – это позволяет упростить процесс администрирования.
2. Объекты БД. По стандарту SQL2 защищаемыми объектами в БД являются таблицы, представления, домены и определенные пользователем наборы символов. Большинство коммерческих СУБД расширяет список объектов, добавляя в него хранимые процедуры и др. объекты.
3. Привилегии. Привилегии показывают набор действий, которые возможно производить над тем или иным объектом. Например пользователь имеет привилегию для просмотра таблицы.
12.4 Обязательное управление доступом
Методы обязательного управления доступом применяются к базам данных, в которых данные имеют достаточно статичную или жесткую структуру, свойственную, например, правительственным или военным организациям. Как уже отмечалось, основная идея заключается в том, что каждый объект данных имеет некоторый уровень классификации, например: секретно, совершенно секретно, для служебного пользования и т.д., а каждый пользователь имеет уровень допуска с такими же градациями, что и в уровне классификации. Предполагается, что эти уровни образуют строгий иерархический порядок, например: совершенно секретно ® секретно ® для служебного пользования и т.д. Тогда на основе этих сведений можно сформулировать два очень простых правила безопасности:
Похожие работы
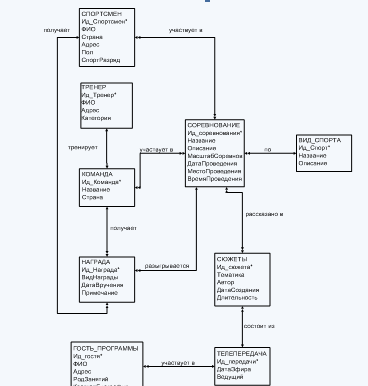
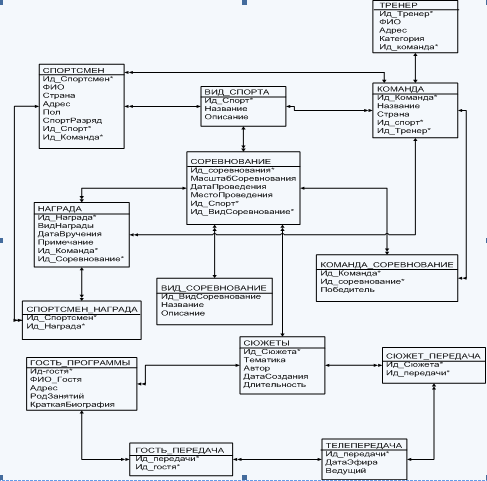
... для предметной области «Спортивная программа» показана на рис.1 Рис.1 – КМД для предметной области «Спортивная программа» Двойная стрелка означает «многие», одинарная стрелка означает «один» во взаимосвязи между объектами. Ключевые атрибуты обозначены *. Описание реляционной модели данных Реляционная модель данных (РМД) представляет БД в виде множества взаимосвязанных отношений, в том ...
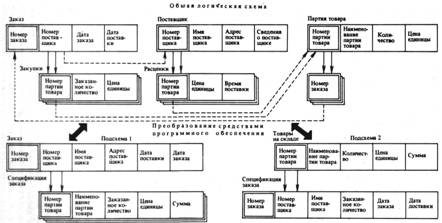
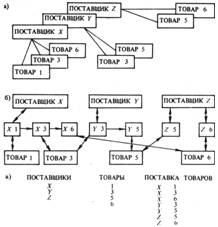
... и прикладных программ (логическая независимость данных) и возможность изменения физического расположения и организации данных без изменения общей логической структуры данных и структур данных прикладных программистов (физическая независимость). Рис. 1 2. Системы управления базами данных Использование систем управления базами данных (СУБД) позволяет исключить из прикладных программ ...

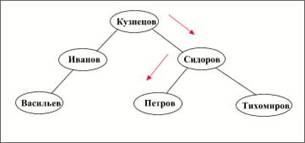
... (в виде связей). В последнее время все большее значение приобретает объектно-ориентированный подход к представлению данных. Физическая организация баз данных Физическая организация данных определяет собой способ непосредственного размещения данных на машинном носителе. В современных прикладных программных средствах этот уровень организации обеспечивается автоматически без вмешательства ...
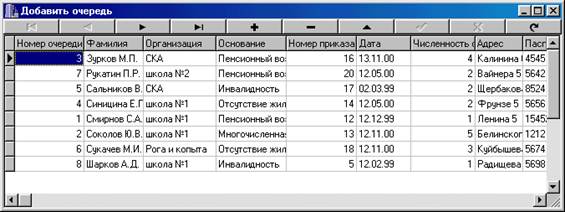
... отчет. Базовый отчет: Отчет по организациям: Программа предназначена для учёта очереди по организациям, а также для предоставления оперативной информации о очереди. К входящей информации относятся: номер очереди, фамилия, организация, основание, номер приказа, дата, численность семьи, адрес , паспорт. Т. е файл: Также Справочник 1 и 2: К выходящей информации в отчёте ...
0 комментариев