Производительность. СУБД должна выполнять свои функции с максимальной производительностью
Заголовок содержит фиксированное множество атрибутов или, точнее, пар <имя‑атрибута : имя‑домена>:
На практике большинство отношений имеют только один потенциальный ключ, хотя в общем случае их может быть несколько
Если каждое из них имеет одно и то же множество имен атрибутов (следовательно, заметьте, они заведомо должны иметь одну и ту же степень);
Следует заметить, что речь здесь пойдет о логическом, а не физическом макете
Правая часть (зависимая часть) каждой ФЗ множества S содержит только один атрибут (т.е. является одноэлементным множеством)
Диаграммы ER-экзрмпляров
Степени связи между сущностями (1:1, 1:М, М:1, М:М);
Булевы данные. Некоторые СУБД явным образом поддерживают логические значения (TRUE или FALSE)
Константа, показывающая, что в каждой строке результатов запроса должно содержаться одно и то же значение
Пользователь имеет доступ к объекту, только если его уровень допуска больше или равен уровню классификации объекта
ALTER – позволяет модифицировать структуру таблиц (DB2, Oracle);
Далее этот процесс следует повторить для вставки среднего значения W в родительский элемент Р на более высоком структурном уровне
В последовательности проекций данного отношения можно игнорировать все проекции, кроме последней. Таким образом, выражение
Долговечность. Когда транзакция выполнена, ее обновления сохраняются, даже если в следующий момент произойдет сбой системы
Транзакция, предназначенная для извлечения кортежа, прежде всего должна наложить S‑блокировку на этот кортеж
Перед выполнением каких-либо операций с некоторым объектом (например, с кортежем базы данных) транзакция должна заблокировать этот кортеж
Несколько клиентов могут использовать один и тот же сервер (действительно, это довольно обычная ситуация)
Навигация
Перед выполнением каких-либо операций с некоторым объектом (например, с кортежем базы данных) транзакция должна заблокировать этот кортеж
Организация баз данных
362757
знаков
48
таблиц
34
изображения
1. Перед выполнением каких-либо операций с некоторым объектом (например, с кортежем базы данных) транзакция должна заблокировать этот кортеж.
2. После снятия блокировки транзакция не должна накладывать никаких других блокировок.
Таким образом, транзакция, которая подчиняется этому протоколу, характеризуется двумя фазами: фазой наложения блокировки и фазой снятия блокировки.
Характеристика упорядочения может быть выражена следующим образом. Если A и B являются любыми двумя транзакциями некоторого графика запуска, допускающего возможность упорядочения, то либо A логически предшествует B, либо B логически предшествует A, т.е. либо B использует результаты выполнения транзакции A, либо A использует результаты выполнения транзакции B. (Если транзакция A приводит к обновлению кортежей р, q, ... r и транзакция B использует эти кортежи в качестве входных данных, то используются либо все обновленные с помощью A кортежи, либо полностью не обновленные кортежи до выполнения транзакции A, но никак не их смесь.) Наоборот, график запуска является неверным и не подлежит упорядочению, если результат выполнения транзакций не соответствует либо сначала выполнению транзакции A, а затем транзакции B, либо сначала выполнению транзакции B, а затем транзакции A.
В настоящее время с целью понижения требований к ресурсам и, следовательно, повышения производительности и пропускной способности в реальных системах обычно предусмотрено использование не двухфазных транзакций, а транзакций с "ранним снятием блокировки" (еще до выполнения операции прекращения транзакции) и наложением нескольких блокировок. Однако следует понимать, что использование таких транзакций сопряжено с большим риском. Действительно, при использовании недвухфазной транзакции A предполагается, что в данной системе не существует никакой другой чередующейся с ней транзакции B (в противном случае в системе возможно получение ошибочных результатов).
15.9 Уровни изоляции транзакции
Термин уровень изоляции, грубо говоря, используется для описания степени вмешательства параллельных транзакций в работу некоторой заданной транзакции. Но при обеспечении возможности упорядочения не допускается никакого вмешательства, иначе говоря, уровень изоляции должен быть максимальным. Однако, как уже отмечалось, в реальных системах по различным причинам обычно допускаются транзакции, которые работают на уровне изоляции ниже максимального.
Уровень изоляции обычно рассматривается как некоторое свойство транзакции. В реальных СУБД может быть реализовано различное количество уровней изоляции.
Кроме того помимо кортежей могут блокироваться другие единицы данных, например целое отношение, база данных или (пример противоположного характера) некоторое значение атрибута внутри заданного кортежа.
15.10 Поддержка в языке SQLSQL поддерживает операции COMMIT и ROLLBACK для фиксации и отката транзакции соответственно.
Специальный оператор SET TRANSACTION используется для определения некоторых характеристик транзакции, которую нужно будет инициировать, такие, как режим доступа и уровень изоляции.
В стандарте языка SQL не предусмотрена поддержка явным образом возможности блокировки (фактически, блокировка в нем вообще не упоминается). Блокировки накладываются неявно, при выполнении операторов SQL.
Литература:
1. Дейт К.Дж. Введение в системы баз данных. –Пер. с англ. –6-е изд. –К. Диалектика, 1998. Стр. 354–392.
ЛЕКЦИЯ 16. Технологии СУБД16.1 Распределенные базы данных
16.2 Принципы функционирования распределенной БД
16.3 Системы типа клиент/сервер
16.4 Серверы баз данных
16.1 Распределенные базы данных
16.1.1 Предварительные замечания.
Системы дистрибутивных баз данных состоят из набора узлов, связанных вместе коммуникационной сетью, в которой:
1. каждый узел обладает своими собственными системами баз данных;
2. узлы работают согласованно, поэтому пользователь может получить доступ к данным на любом узле сети, как будто все данные находятся на его собственном узле.
Из этого следует, что так называемая "распределенная база данных" на самом деле является типом виртуального объекта, части которого физически сохраняются в ряду отдаленных "реальных" баз данных на удаленных узлах (фактически, это логическая единица всех этих реальных баз данных).
Каждый узел обладает своими собственными базами данных, собственными локальными пользователями, собственной СУБД и программным обеспечением для управления транзакциями (включая собственное программное обеспечение для блокирования, регистрации, восстановления и т.д.), а также своим собственным локальным диспетчером передачи данных. В частности, пользователь может на собственном локальном узле выполнять операции с данными так, как будто этот узел вовсе не является частью распределенной системы.
16.2 Принципы функционирования распределенной БД
Теперь, после краткого введения, можно привести формулировку фундаментального принципа распределенной базы данных: для пользователя распределенная система должна выглядеть точно так же, как нераспределенная система.
1. Изложенный фундаментальный принцип приводит к следующему набору правил и целе9ф:Локальная автономия;Независимость от центрального узла;Непрерывное функционирование;Независимость от расположения
2. Независимость от фрагментации;
3. Независимость от репликации;
4. Обработка распределенных запросов;
5. Управление распределенными транзакциями;
6. Независимость от аппаратного обеспечения;
7. Независимость от операционной системы;
8. Независимость от сети;
9. Независимость от СУБД.
16.2.1 Локальная автономияВ распределенной системе узлы следует делать автономными. Локальная автономия означает, что операции на данном узле управляются этим узлом, т.е. функционирование любого узла X не зависит от успешного выполнения некоторых операций на каком-то другом узле Y (в противном случае может возникнуть крайне нежелательная ситуация, а именно: выход из строя узла Y может привести к невозможности исполнения операций на узле X, даже если с узлом X ничего не случилось). Из принципа локальной автономии также следует, что владение и управление данными осуществляется локально вместе с локальным ведением учета.
16.2.2 Независимость от центрального узлаПод локальной автономией подразумевается, что все узлы должны рассматриваться как равные. Следовательно, не должно существовать никакой зависимости и от центрального "основного" узла с некоторым централизованным обслуживанием, например централизованной обработкой запросов, централизованным управлением транзакциями или централизованным присвоением имен.
Зависимость от центрального узла нежелательна по крайней мере по двум причинам. Во-первых, центральный узел может быть "узким" местом всей системы, а во-вторых, более важно то, что система в таком случае становится уязвимой, т.е. при повреждении центрального узла может выйти из строя вся система.
16.2.3 Непрерывное функционированиеОдним из основных преимуществ распределенных систем является то, что они обеспечивают более высокую надежность и доступность.
1. Надежность (вероятность того, что система исправна и работает в любой заданный момент) повышается благодаря работе распределенных систем не по принципу "все или ничего", а в постоянном режиме; т.е. работа системы продолжается, хотя и на более низком уровне, даже в случае неисправности некоторого отдельного компонента, например отдельного узла.
2. Доступность (вероятность того, что система исправна и работает в течение некоторого промежутка времени) повышается частично по той же причине, а частично благодаря возможности репликации данных (подробнее это описывается ниже).
16.2.4 Независимость от расположенияОсновная идея независимости от расположения (которая также называется прозрачностью расположения) достаточно проста: пользователям не следует знать, в каком физическом месте хранятся данные, наоборот, с логической точки зрения пользователям следовало бы обеспечить такой режим, при котором создается впечатление, что все данные хранятся на их собственном локальном узле.
16.2.5 Независимость от фрагментацииВ системе поддерживается фрагментация данных, если некое хранимое отношение в целях физического хранения можно разделить на части, или "фрагменты". Фрагментация желательна для повышения производительности системы, поскольку данные лучше хранить в том месте, где они наиболее часто используются. При такой организации многие операции будут чисто локальными, что снизит нагрузку на сеть.
Существует два основных типа фрагментации – горизонтальная и вертикальная, которые связаны с реляционными операциями выборки и проекции соответственно. Иначе говоря, фрагментом может быть любое произвольное подчиненное отношение, которое можно вывести из исходного отношения с помощью операций выборки и проекции. При этом следует учесть приведенные ниже допущения.
Предполагается без утраты общности, что все фрагменты данного отношения независимы, т.е. ни один из фрагментов не может быть выведен из других фрагментов либо иметь выборку или проекцию, которая может быть выведена из других фрагментов. (Если есть необходимость сохранить одну и ту же информацию в нескольких разных местах, для этого следует использовать механизм репликации системы.).Проекции не должны допускать потерю информации.
16.2.6 Независимость от репликацииВ системе поддерживается независимость от репликации, если заданное хранимое отношение или заданный фрагмент могут быть представлены несколькими различными копиями, или репликами, хранимыми на нескольких различных узлах.
16.2.7 Обработка распределенных запросов.Вопрос оптимизации более важен для распределенной, нежели для централизованной системы. Основная причина заключается в том, что для выполнения охватывающего несколько узлов запроса существует довольно много способов перемещения данных по сети. В таком случае чрезвычайно важно найти наиболее эффективную стратегию.
16.2.8 Управление распределенными транзакциями.Существует два основных аспекта управления обработкой транзакций, а именно: управление восстановлением и управление параллелизмом, каждому из которых в распределенных системах должно уделяться повышенное внимание.
16.2.9 Независимость от аппаратного обеспечения.Подразумевает возможность работы узлов системы на разном аппаратном обеспечении.
16.2.10 Независимость от операционной системы.Подразумевает возможность работы узлов системы под управлением различных операционных систем.
16.2.11 Независимость от сети.Подразумевает возможность работы узлов системы в гетерогенных сетях, с использованием различного сетевого оборудования
16.2.12 Независимость от СУБД.Эта цель подразумевает использование несколько менее точной формулировки предположения о строгой однородности. В новой форме это предположение означает, что все экземпляры СУБД на различных узлах поддерживают один и тот же интерфейс, хотя они не обязательно должны быть копиями одного и того же программного обеспечения.
16.2.13 Распространение обновленияКак указывалось выше, основной проблемой репликации данных является то, что обновление любого логического объекта должно распространяться на все хранимые копии этого объекта. Трудности возникают из-за того, что некоторый узел, содержащий данный объект, может быть недоступен (например, из-за краха системы или данного узла) именно в момент обновления.
Общая схема устранения этой проблемы (и не единственно возможная в этом случае), называемая схемой первичной копии, будет описана далее.
1. Одна копия каждого реплицируемого объекта называется первичной копией, а все остальные – вторичными.
2. Первичные копии различных объектов находятся на различных узлах (таким образом, эта схема является распределенной).
3. Операции обновления считаются завершенными, если обновлены все первичные копии. В таком случае в некоторый момент времени узел, содержащий такую копию, несет ответственность за распространение операции обновления на вторичные копии.
16.3 Системы типа клиент/серверСистемы клиент/сервер могут рассматриваться как особый случай распределенных систем. Точнее, система клиент/сервер является распределенной системой, в которой одни узлы являются клиентами, а другие – серверами,, все данные хранятся на серверах, все приложения исполняются клиентами, а "места их соединения не скрыты от пользователя" (т.е. не достигается цель независимости от расположения).
Термин "клиент/сервер" относится преимущественно к архитектуре или логике распределения ответственности, поэтому клиент – это приложение, т.е. внешний интерфейс, а сервер – СУБД, т.е. внутренний интерфейс для непосредственной работы с базами данных. Таким образом, система может быть четко разделена на две части с использованием двух разных типов компьютеров. Эта последняя возможность настолько притягательна, что термин "клиент/сервер" стал применяться почти исключительно в случаях, когда клиент и сервер действительно находятся на разных компьютерах.
Реальное распространение архитектуры "клиент-сервер" стало возможным благодаря развитию и широкому внедрению в практику концепции открытых систем.
Основным смыслом подхода открытых систем является упрощение комплексирования вычислительных систем за счет международной и национальной стандартизации аппаратных и программных интерфейсов. Главной побудительной причиной развития концепции открытых систем явились повсеместный переход к использованию локальных компьютерных сетей и те проблемы комплексирования аппаратно-программных средств, которые вызвал этот переход. В связи с бурным развитием технологий глобальных коммуникаций открытые системы приобретают еще большее значение и масштабность.
Ключевой фразой открытых систем, направленной в сторону пользователей, является независимость от конкретного поставщика. Ориентируясь на продукцию компаний, придерживающихся стандартов открытых систем, потребитель, который приобретает любой продукт такой компании, не попадает к ней в рабство. Он может продолжить наращивание мощности своей системы путем приобретения продуктов любой другой компании, соблюдающей стандарты.
16.4 Серверы баз данныхОбычно для обозначения всей СУБД, основанной на архитектуре "клиент-сервер", включая и серверную, и клиентскую части используют термин "сервер баз данных". Такие системы предназначены для хранения и обеспечения доступа к базам данных.
Доступ к базе данных от прикладной программы или пользователя производится путем обращения к клиентской части системы. В качестве основного интерфейса между клиентской и серверной частями выступает язык баз данных SQL.
В типичном на сегодняшний день случае на стороне клиента СУБД работает только такое программное обеспечение, которое не имеет непосредственного доступа к базам данных, а обращается для этого к серверу с использованием языка SQL.
Следует отметить и другие варианты этой основной темы.
Похожие работы
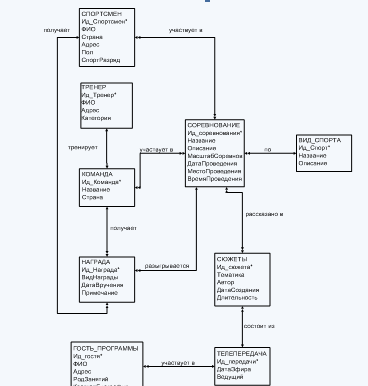
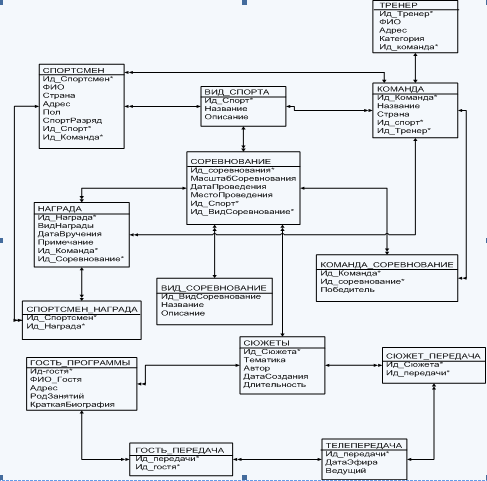
... для предметной области «Спортивная программа» показана на рис.1 Рис.1 – КМД для предметной области «Спортивная программа» Двойная стрелка означает «многие», одинарная стрелка означает «один» во взаимосвязи между объектами. Ключевые атрибуты обозначены *. Описание реляционной модели данных Реляционная модель данных (РМД) представляет БД в виде множества взаимосвязанных отношений, в том ...
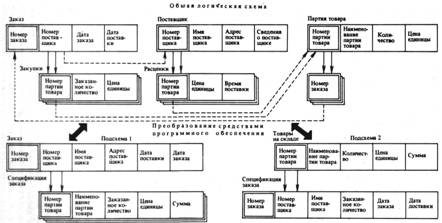
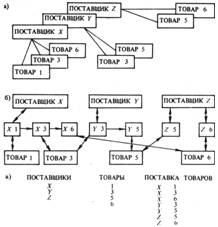
... и прикладных программ (логическая независимость данных) и возможность изменения физического расположения и организации данных без изменения общей логической структуры данных и структур данных прикладных программистов (физическая независимость). Рис. 1 2. Системы управления базами данных Использование систем управления базами данных (СУБД) позволяет исключить из прикладных программ ...

... (в виде связей). В последнее время все большее значение приобретает объектно-ориентированный подход к представлению данных. Физическая организация баз данных Физическая организация данных определяет собой способ непосредственного размещения данных на машинном носителе. В современных прикладных программных средствах этот уровень организации обеспечивается автоматически без вмешательства ...
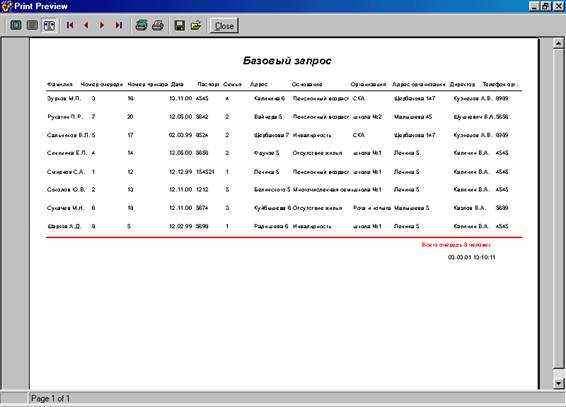
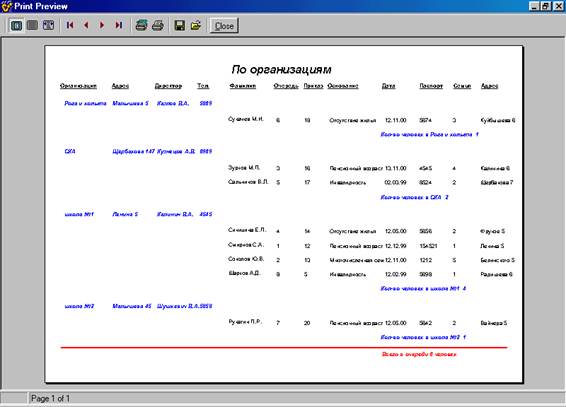
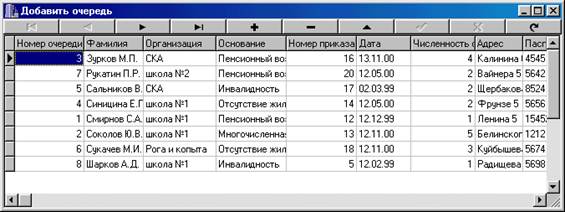
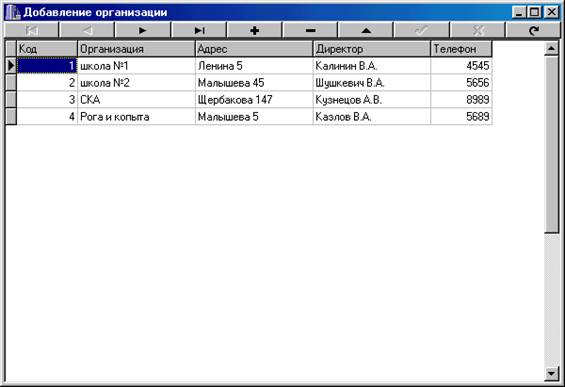
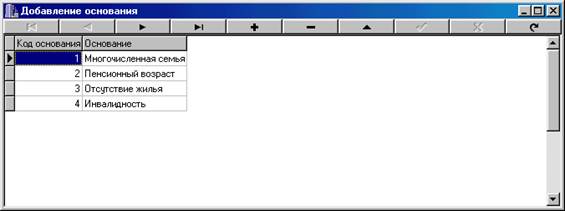
... отчет. Базовый отчет: Отчет по организациям: Программа предназначена для учёта очереди по организациям, а также для предоставления оперативной информации о очереди. К входящей информации относятся: номер очереди, фамилия, организация, основание, номер приказа, дата, численность семьи, адрес , паспорт. Т. е файл: Также Справочник 1 и 2: К выходящей информации в отчёте ...
0 комментариев