Навигация
К системе команд добавляется команда для опроса бита прерывания заданного регистра check_exception(R). Если бит установлен, то возникает прерывание
82492
знака
2
таблицы
0
изображений
3. К системе команд добавляется команда для опроса бита прерывания заданного регистра check_exception(R). Если бит установлен, то возникает прерывание.
При наличии перечисленных средств компилятор получает возможность закодировать упреждающее выполнение команды C следующим образом:
в новой позиции команды C (выше точки ветвления) помещается ее вариант с битом упреждающего выполнения;
в прежней позиции команды C помещается команда check_exception, для того чтобы обеспечить прерывание, если оно должно произойти. Если имеется команда, выполняемая в обычном режиме и использующая результат команды C, то команда check_exception не генерируется.
Пример из [48], показанный на рис. 15, демонстрирует применение указанных средств при планировании.
| A: if (r2==0) goto L1 | *B: r1 = mem(r2) |
| B: r1 = mem(r2) | *C: r3 = mem(r4) |
| C: r3 = mem(r4) | *D: r4 = r1+1 |
| D: r4 = r1+1 | *E: r5 = r3*9 |
| E: r5 = r3*9 | A: if (r2==0) goto L1 |
| F: mem(r2+4) = r4 | F: mem(r2+4) = r4 |
| G: check_exception(r5) | |
| a) | b) |
Рис. 15. Планирование команд с упреждающим выполнением: a) исходный код; b) код, полученный в результате планирования. Буквы A-G служат для идентификации команд. Символом * отмечены команды с признаком упреждающего выполнения
На рис. 15 показан код до и после планирования (в предположении, что исключительные ситуации возможны только при обращениях к памяти). Команды F и G обеспечивают проверку исключительных ситуаций, которые могли возникнуть при упреждающем выполнении команд B, C.
Для того чтобы разрешить упреждающее выполнение команд записи в память, предусматривается аппаратное расширение, основанное на введении дополнительных полей в элементы буфера записи в память.
Важным преимуществом модели защищенного планирования является поддержка адекватной диагностики исключительных ситуаций с указанием адреса фактического возникновения, даже если команда-источник выполнялась в упреждающем режиме.
По результатам тестов, приведенным в [48], применение защищенного планирования по сравнению с ограниченной фильтрацией на задачах нечисловой обработки дает существенное ускорение результирующих программ. Например, для процессора с темпом выдачи 8 команд на такт коэффициент ускорения при использовании защищенного планирования был от 18 до 135% (в среднем на 57%) выше, чем при планировании с ограниченной фильтрацией.
Для численных приложений, не содержащих большого числа условных переходов во внутренних циклах (таких как операции над матрицами), разница коэффициентов ускорения оказалась незначительной. Коэффициенты ускорения для этих приложений оказались достаточно высокими уже при ограниченной фильтрации. Для двух численных приложений с значительным количеством условных переходов во внутренних циклах улучшение коэффициента ускорения составило 36-38%.
Другое аппаратное расширение, предназначенное для поддержки глобального планирования - средства условного выполнения команд ([15], [58]). Например, процессор TM1000 [32] позволяет задавать в команде предикатный операнд, в качестве которого может выступать любой из 128 регистров. В зависимости от значения младшего бита этого операнда результат операции будет записан или проигнорирован. Аналогичные возможности поддерживаются в процессоре IA-64 ([36], [60]) и др.
Компилятор может слить условно выполняемый линейный участок с объемлющим участком, заменив составляющие его инструкции условно выполняемыми (рис. 16). В результате зависимости по управлению фактически заменяются зависимостями по данным, которые существенно удобнее с точки зрения планировщика.
c:= вычислить(условие) c:= вычислить(условие) [c] goto then_label [c] B_THEN
B_ELSE [!c] B_ELSE
goto join_label
then_label: B_THEN
join_label: ...
a) b)
Рис. 16. Реализация конструкции "if (условие) then B_THEN else B_ELSE" при помощи условных переходов (a) и условным выполнением (b). Обозначение [c] указывает, что команда будет выполнена только если предикат c имеет значение "истина"
В работе [44] рассматривается метод, позволяющий для заданной иерархии вложенных конструкций if-then-else выбрать оптимальные (по средней скорости выполнения результирующей программы) способы реализации.
Поддержка условного выполнения делает особенно эффективным планирование в древовидных областях [32], [31]. Для каждого линейного участка древовидной области вычисляется предикат, который приписывается всем командам этого участка. В результате исключается большая часть условных переходов и появляется возможность планировать параллельное исполнение различных ветвей дерева.
Метод доминантного параллелизма при планировании в древовидных областях
Недостаток метода "дублирования хвостов" заключаются в генерации избыточного кода. При использовании упреждающего исполнения это приводит к нерациональному расходованию вычислительных ресурсов и может замедлить исполнение. В ряде случаев планировщик способен исключить отрицательные последствия при помощи метода доминантного параллелизма (dominator parallelism) [31]. Если команды из некоторого линейного участка BBi и его копии BBi' можно поднять в доминирующий участок BBk (являющийся общим предком BBi и BBi'), то можно оставить только по одному экземпляру команд. Пример ситуации, когда этот прием применим, показан на рис. 17.
Рис. 17. Доминантный параллелизм. Командy r6=0 из линейного участка BB5 и его копии BB5' можно поднять в BB2 (или BB1) и исключить их дублирование
Планирование по прогнозу значений данных
Упреждающее выполнение команд по прогнозу данных (data speculation) широко применяется в динамическом аппаратном планировании в суперскалярных процессорах. Смысл этого приема заключается в том, что значение объекта используется до того, как оно записано, в предположении, что значение останется прежним. Разумеется, если значение все-таки изменяется, процессор обеспечивает перевычисление команд, выполненных с упреждением. EPIC-архитектуры предоставляют аппаратную поддержку для использования аналогичного механизма при статическом планировании в компиляторе по отношении к объектам, хранящимся в памяти, см. [36] или [60].
... ...
MEM(R0) = R1 R2=MEM(R3)' ; упреждающее
... ; чтение
R2=MEM(R3) ...
R4=R2+R2 MEM(R0)=R1
... check(address(R3)),L1
R4=R2+R2
a) b)
Рис. 18. Перестановка операций чтения и записи с использованием аппаратной поддержки упреждающего чтения
При наличии таких аппаратных средств компилятор получает возможность переупорядочивать команды чтения и записи памяти. Это может быть полезно по нескольким причинам:
как можно раньше выполнить команды считывания из памяти, лежащие на критическом пути;
использовать свободную позицию в командном слове,
исключить задержки, связанные с чтением данных из памяти.
На рис. 18a показан пример последовательности вычислений, содержащий команды записи в память (MEM(R0) = R1) и чтения из памяти (R2=MEM(R3)). Компилятор, вообще говоря, не имеет права запланировать чтение раньше записи, если он не имеет точной информации о том, что команда записи не перепишет считываемое значение.
Аппаратная поддержка упреждающего считывания из памяти может состоять из следующих средств (см. [13], [36]):
имеется команда упреждающего считывания, которая считывает значение по указанному адресу и запоминает этот адрес во внутренней таблице процессора;
при записи в память и при обычном считывании содержимое таблицы проверяется, и если в ней присутствует указанный адрес, то соответствующий элемент таблицы помечается как недействительный (или просто исключается)
имеется команда, позволяющая узнать, не было ли записи по заданному адресу с момента упреждающего считывания по этому адресу; если запись была, то выполнить переход по указанному адресу. Подразумевается, что по этому адресу должен находиться компенсирующий код.
На рис. 18b показан пример перестановки чтения и записи памяти с использованием этих средств. Команда чтения (в упреждающем режиме) помещается до команды записи. На месте прежнего положения команды считывания (до использования результата) помещена команда проверки адреса. Если оказалось, что по этому адресу была произведена запись, то управление передается по метке L1, где размещается сгенерированный компилятором компенсирующий код.
Особенности генерации кода для ЦПОС
Особенности генерации эффективного кода для ЦПОС связаны как с нерегулярностью схем кодирования, так и с другими характерными чертами этих процессоров, такими как наличие специализированных команд, нескольких пространств памяти и др. В этом разделе представлены специфические подходы, применяемые в компиляторах для ЦПОС.
Наиболее важной в контексте компиляции для ЦПОС представляется задача планирования (сжатия) кода. Специфика планирования для VLIW-процессоров с нерегулярными схемами кодирования связана с многочисленными ограничениями на параллельное исполнение команд, из-за которых существенно снижаются возможности использования внутреннего параллелизма программы при генерации кода. В ЦПОС также в меньшей степени представлены аппаратные расширения для поддержки параллелизма - условное выполнение, поддержка упреждающего выполнения. При этом именно для данного класса процессоров, в силу специфики областей применения, генерация оптимального кода имеет особенно важное значение.
В силу перечисленных причин в компиляторах для ЦПОС вместо эвристического глобального планирования более разумным представляется применение алгоритмов для поиска точного оптимального решения в пределах линейных участков.
В [45] приводятся следующие аргументы в пользу локального планирования:
Методы глобального планирования так или иначе опираются на локальные методы, которые сами по себе в контексте компиляции для ЦПОС еще недостаточно изучены и разработаны. Поэтому разумно начать с их детального исследования и оценки.
Популярные глобальные методы разрабатывались для регулярных VLIW-процессоров с высоким уровнем аппаратного параллелизма и проявили свою высокую эффективность для этого класса архитектур, в то время как в ЦПОС уровень параллелизма как правило значительно ниже из-за ограничений кодирования.
В глобальном планировании для сохранения корректности программы в нее приходится добавлять компенсирующий код. Это может привести к существенному увеличению размера программы, что неприемлемо, если объем памяти ограничен.
К этому можно добавить, что:
Преимущества глобального планирования экспериментально подтверждены для программ нечисленного характера; для программ численных расчетов выигрыш от глобального планирования, вероятно, не столь значителен.
Применение глобального планирования наиболее эффективно при наличии аппаратных расширений для его поддержки.
В [45] рассматривается подход к задаче локального планирования для определенного класса ЦПОС, основанный на методах целочисленного линейного программирования (см. [10]) и позволяющий находить кратчайший выходной код для процессора с заданными ограничениями на параллельное исполнение команд. Хотя время нахождения решения экспоненциально зависит от длины линейного участка, по мнению авторов, применение подобных подходов в компиляции для ЦПОС оправдано. Важная положительная черта предлагаемого метода заключается в поддержке вариантов команд - если процессор предоставляет несколько различных типов команд для выполнения одной и той же операции, то при поиске оптимального решения обеспечивается перебор вариантов.
В [23] и [29] также представлены реализации локальной оптимизации кода для ЦПОС на основе методов линейного программирования. В этих реализациях совмещается решение задач распределения регистров, распараллеливания и выбора команд (code selection) с учетом наличия в процессоре составных операций типа A=A+B*C.
Другая проблема, обусловленная нерегулярным характером кодирования, - способ представления ограничений на параллельное исполнение команд в планировщике. Если в регулярных ILP-архитектурах эти ограничения достаточно легко описать и представить в виде общего числа функциональных устройств каждого вида и наборов устройств, занимаемых каждой командой, то для процессоров с нерегулярным кодированием их рациональное представление составляет более сложную задачу. В [59] описывается подход, позволяющий свести нерегулярный набор ограничений к регулярному представлению путем определения набора искусственных аппаратных ресурсов и приписывания соответствующего мультимножества ресурсов каждому виду команд процессора. Недостатком предлагаемой реализации является то, что ее применимость ограничена слишком жесткими предположениями о структуре системы команд.
Характерной особенностью многих ЦПОС является малое число регистров, их специализация или кластерная организация. Это также требует особых подходов при распараллеливании и выборе кода ([16], [43]).
Как показано в [23], применение некоторых оптимизаций, считающихся машиннонезависимыми (таких как свертка констант, исключение общих подвыражений), в контексте компиляций для ЦПОС требует особых подходов с учетом специфики организации командного слова и числа доступных регистров в конкретном целевом процессоре.
Поскольку при программировании для ЦПОС обычно налагаются ограничения на размер кода, то при реорганизациях циклов и встраивании функций необходимо учитывать этот фактор. С этой точки зрения интересна работа [42], где рассматривается методика встраивания функций с контролируемым ростом объема кода. Аналогичные методики могут быть полезны и для преобразований циклов.
Важно понимать, что проблема генерации оптимального кода для ЦПОС не сводится только к задаче сжатия кода с учетом возможностей параллельного исполнения. Хороший компилятор для ЦПОС должен уметь эффективно использовать их архитектурные особенности - решать задачу оптимального размещения программных данных в пространствах памяти [41], поддерживать языковые расширения для указания пространства памяти в декларациях переменных [33], решать задачу выбора кода с учетом имеющегося набора команд в процессорах с системами команд для специальных приложений - Application Specific Instruction Set Processors (ASIP), (см. [16],[17]), выделять циклические буферы, оптимизировать способы адресации при обращениях к памяти (см. [29], [41], [46]) и др.
О роли языковых расширений
В различных реализациях компиляторов с языка Си для ILP-архитектур делаются попытка отразить на уровне входного языка специфику этих процессоров и особенности программирования для них ([14], [33]). Операции над комплексными, векторными, матричными данными, явно выраженные в терминах исходного языка, могут быть непосредственно отражены в эффективные связки команд ILP-процессоров.
Комплексный тип данных зафиксирован в последнем стандарте языка Си [37]:
#include <complex.h>
complex float x, y = 1.0 + 3.0 * I;
Для комплексного типа определен набор обычных операций и библиотечных функций.
Векторные и матричные операции, привлекательные с точки зрения возможности напрямую использовать параллелизм на уровне команд, к сожалению, плохо “встраиваются” в синтаксис языка Си, поскольку имена массивов трактуются как описатели. Поэтому, например, в стандарте ANSI Numerical C, разработанном группой NCEG (Numerical C Extension Group) для численных приложений, введены понятия итератора и оператора суммирования, отражающие семантику матричных операций.
Пример описания и использования итератора:
iter I = N;
A[I] = sin (2 * PI * I / N)
Этот фрагмент программы эквивалентен следующему тексту на стандартном Си:
int i;
for (i = 0); i < N; i++)
{
A[i] = sin (2 * PI * i / N);
}
Пример вычисления произведения матриц с использованием итераторов и операторов суммирования:
iter I=N, J=N, K=N;
A[I][J] = sum (B[I][K] * C[K][J]);
Суммирование здесь производится по итератору K. В общем случае суммирование проводится по всем свободным итераторам, т.е. итераторам, которые не встречаются в том же итераторе вне оператора суммирования.
В работе [33] также предлагаются некоторые другие расширения, отражающие специфику ЦПОС – пространства памяти, циклические буферы.
Положительные стороны такого рода расширений — краткость и естественность исходных текстов, возможность эффективно отобразить высокоуровневые операции в оптимальный для заданной целевой платформы код.
Заключение
Круг вопросов, связанных с генерацией эффективного кода для ILP-архитектур, охватывает проблемы формирования областей планирования, снятия зависимостей по данным и по управлению, алгоритмы планирования (распараллеливания) кода, соотношение между планированием и распределением регистров.
Несмотря на обилие уже разработанных и опробованных подходов, создание эффективного компилятора для ILP-процессора в каждом конкретном случае остается непростой задачей. Сложность проблемы связана отчасти с тем, что эффективность практически всех методик существенно зависит как от аппаратных особенностей процессора (степень параллелизма, количество регистров, поддержка условного и упреждающего исполнения), так и от характера компилируемых программ (планирование в расширенных областях наиболее эффективно для программ управляющего характера; в программах вычислительного характера эффект от их применения менее значителен).
Наиболее сложной, по-видимому, остается проблема генерации эффективного кода для ЦПОС. Для VLIW-процессоров с регулярной организацией командного слова основным препятствием к распараллеливанию команд является недостаточность программного параллелизма, поэтому усилия разработчиков компиляторов для них направлены, в основном, на его повышение (за счет расширения областей планирования и снятия зависимостей по данным и по управлению). При успешном решении этой задачи быстрые алгоритмы эвристического списочного планирования могут давать приемлемые результаты. В ЦПОС, в силу нерегулярности кодирования, распараллеливание команд затрудняется, в первую очередь, многочисленными сложными ограничениями кодирования. Поэтому для них необходимы более сложные и трудоемкие переборные методы, такие как [45] или [29]. В связи с этим особый интерес представляет разработка практичных алгоритмов оптимизированного перебора, позволяющих за разумное время осуществлять распараллеливание достаточно больших участков.
Анализ работ, посвященных оптимизации кода для процессоров с параллелизмом на уровне команд показывает, что для достижения наилучших результатов необходимо применение комплекса оптимизаций, среди которых можно выделить следующие классы.
Преобразования циклов, направленные на усиление программного параллелизма – развертка циклов, слияние и разбивка циклов, конвейеризация циклов.
Преобразования, направленные на ослабление зависимостей по данным – перемещение кода, переименование регистров, дублирование переменных суммирования в циклах и др.
Применение методов глобального планирования потока команд на основе алгоритма списочного планирования.
Использования аппаратных средств поддержки упреждающего выполнения и упреждающего чтения данных.
Совмещение планирования команд и распределения регистров.
Применение локального планирования на основе целочисленного линейного программирования;
Реализация языковых расширений.
При выборе конкретных методов и их параметров необходимо учитывать уровень аппаратного параллелизма и другие особенности целевого процессора, а также характер типичных приложений.
Благодарности
Автор выражает благодарность Виктору Зиновьевичу Шнитману и Андрею Геннадьевичу Шадскому за полезные консультации.
Литература
Ахо А., Сети Р., Ульман Д., Компиляторы: принципы, технологии и инструменты. – М., Издательский дом "Вильямс", 2001.
Ахо А., Ульман Дж. Теория синтаксического анализа, перевода и компиляции, том 2. - М., Мир, 1978.
Балашов В.В., Капитонова А.П., Костенко В.А., Смелянский Р.Л., Ющенко Н.В. Метод и средства оценки времени выполнения оптимизированных программ. - Программирование #5, 2000, c. 52 61.
Вьюкова Н.И., Галатенко В.А., Самборский С.В., Шумаков С.М. Описание VLIW-архитектуры в оптимизирующем постпроцессоре. М.: НИИСИ РАН, 2001.
Дорошенко А.Ю., Куйвашев Д.В. Архитектура модульного кросс компилятора для микропроцессоров с очень длинным командным словом. - Проблемы программирования, 2000 г., N 3-4, с. 122-134 (на укр. языке).
Дорошенко А.Ю., Куйвашев Д.В. Интеллектуализация векторизующих компиляторов для микропроцессоров с длинным командным словом. - Проблемы программирования, 2001 г., N 1-2, с. 138-151 (на укр. языке).
Евстигнеев В.А. Некоторые особенности программного обеспечения ЭВМ с длинным командным словом (обзор). - Программирование, 1991, N 2, стр. 69-80.
Ершов А.П. Введение в теоретическое программирование. - М., Наука, 1977.
Калашников Д.В., Машечкин И.В., Петровский М.И. Планирование потока инструкций для конвейерных архитектур. - Москва, МГУ, Вестник Московского университета, серия 15 (вычислительная математика и кибернетика), N4, 1999, с. 39-44.
Пападимитриу Х., Стайглиц К. Комбинаторная оптимизация. - М., Мир, 1985.
Скворцов С.В. Оптимизация кода для суперскалярных процессоров с использованием дизъюнктивных графов. - Программирование 1996, N 2, стр. 41-52.
Французов Ю.А. Обзор методов распараллеливания кода и программной конвейеризации. - Программировние, 1992, N 3, стр. 16-37.
Шланскер М.С., Рау Б.Р. Явный параллелизм на уровне команд. Открытые Системы, #11-12, 1999.
ADSP-21000 Family. C Tools Manual. - Analog Devices, Inc. http://www.analog.com/publications/documentation/CTools_manual/books.htm
Allen J.R., Kennedy K., Porterfield C., Warren J.D. Conversion of Control Dependence to Data Dependence. Proceedings of the 10th ACM Symposium on Principles of Programming Languages. Jan. 1983, pp. 177-189.
Araujo G., Malik S. Optimal Code Generation for Embedded Memory Non-Homogeneous Register Architectures. - 8th Int. Symp. on System Synthesis (ISSS), 1995, pp. 36-41.
Araujo G., Malik S., Lee M. Using Register-Transfer Paths in Code Generation for Heterogeneous Memory-Register Architectures. - In ACM IEEE Design Automation Conference (DAC), number 33, pp. 591-596, June 1996.
Banerjia S., Havanki W.A., Conte T.M. Treegion Scheduling for Highly Parallel Processors. - Proceedings of the 3rd International Euro-Par Conference (Euro-Par'97, Passau, Germany), pp. 1074-1078, Aug. 1997.
Benitez M. E., Davidson J. W. Target-specific Global Code Improvement: Principles and Applications. - Technical Report CS-94-42, Department of Computer Science, University of Virginia, VA 22903.
Bernstein D., Rodey M. Global Instruction Scheduling for Superscalar Machines. - Proceedings of the SIGPLAN '91 Conference on Programming Language Design and Implementation, pp.241-255, June 1991.
Berson D. A., Gupta R., Soffa M. L. Integrated Instruction Scheduling and Register Allocation Techniques. - In Proc. of the Eleventh International Workshop on Languages and Compilers for Parallel Computing, LNCS, Springer Verlag, Chapel Hill, NC, Aug. 1998.
Bharadwaj J., Menezes K. McKinsey C. Wavefront Scheduling: Path Based Data Representation and Scheduling of Subgraphs. The Journal of Instruction-Level Parallelism, May 2000.
Bruggen T., Ropers A. Optimized Code Generation for Digital Signal Processors. - Institute for Integrated Signal Processing, http://www.ert.rwth-aahen.de/coal .
Chang P. P., Mahlke S. A., Chen W. Y., Warter N. J., Hwu W. W. IMPACT: An architectural framework for multipleinstruction-issue processors," in Proceedings of the 18th International Symposium on Computer Architecture, pp. 266-275, May 1991.
Eichenberger A. E., Davidson E. S., Abraham S. G. Minimizing Register Requirements of a Modulo Schedule via Optimum Stage Scheduling. - International Journal of Parallel Programming, February, 1996.
Eichenberger A. E., Lobo S. M. Efficient Edge Profiling for ILP-Processors. - Proceedings of PACT 98, 12-18 October 1998 in Paris, France..
Fisher J. A. Global code generation for instruction-level parallelism: Trace Scheduling-2. - Tech. Rep. HPL-93-43, Hewlett-Packard Laboratories, June 1993
Fisher J.A. Trace scheduling: A Technique for Global Microcode Compaction. - IEEE Transaction on Computers, vol. 7, pp. 478-490, July 1981.
Gebotys C. H., Gebotys R. J. Complexities In DSP Software Compilation: Performance, Code Size, Power, Retargetability. 1060-3425/98, IEEE, 1998.
Grossman J.P. Compiler and Architectural Techniques for Improving the Effectiveness of VLIW Compilation. – submitted to ICCD 2000.
Havanki W. A., Banerjia S., Conte T. M. Treegion Scheduling for Wide Issue Processors. - Proc. 4th Intl. Symp. on HighPerformance Computer Architecture, Feb. 1998, pp. 266-276.
Hoogerbrugge J., Augusteijn L. Instruction Scheduling for TriMedia. - The Journal of Instruction-Level Parallelism, February 1999
Horst E., Kloosterhius W., Heyden J. A C Compiler for the Embedded R.E.A.L DSP Architecture. - Материал получен с телеконференции comp.dsp.
Hsu P.Y.T., Davidson E.S. Highly Concurrent Scalar Processing. - Proceedings of the 13th Annual International Symposium on Computer Architecture, pp. 386-395. June 1986.
Hwu W.W., Mahlke S.A., Chen W.Y., Chang P.P., Warter N.J., Bringmann R.A., Quelette R.G., Hank R.E., Kiyohara T., Haab G.E., Holm J.G., Lavery D.M. The Superblock: An Effective Technique for VLIW and Superscalar Compilation. - The Journal of Supercomputing, vol. 7, pp. 229-249, May 1993.
IA-64 Application Developer's Architecture Guide. - Intel, May 1999.
ISO/IEC 9899:1999(E). Programming Languages - C. - ISO/IEC, 1999.
Kiyohara T., Gyllenhaal J. C. Code Scheduling for VLIW/ Superscalar Processors with Limited Register Files. Proceedings of the 25th International Symposium on Microarchitecture, Dec. 1992, pp. 197-201.
Leung A., Palem K.V. A fast algorithm for scheduling timeconstrained instructions on processors with ILP. - In The 1998 International Conference on Parallel Architectures and Compilation Techniques (PACT 98), Paris, October, 1998.
Leung A., Palem K.V. Scheduling Time-Constrained Instructions on Pipelined Processors. - Submitted for publication to ACM TOPLAS, 1999.
Leupers R. Code Generation for Embedded Processors. - ISSS 2000, Madrid/Spain, Sept. 2000.
Leupers R. Function Inlining under Code Size Constraints for Embedded Processors. – ICCAD’99, San Jose (USA), Nov 1999.
Leupers R. Instruction Scheduling for Clustered VLIW DSPs. -Proceedings of the 2000 International Conference on Parallel Architectures and Compilation Techniques (PACT'00).
Leupers R. Novel Code Optimization Techniques for DSPs.- 2nd European DSP Education and Research Conference, Paris/France, Sep 1998.
Leupers R., Marwedel P. Time-Constrained Code Compaction for DSPs. - 8th Int. System Synthesis Symposium(ISSS), 1995. Trans. on VLSI Systems, Vol. 5, no. 1, March 1997.
Liao S., Devadas S., Keutzer K., Tjiang S., Wang A. Storage Assignment to decrease code size. – ACM SIGPLAN Conference on Programming Language Design and Implementation (PLDI), pp. 186-195, 1995.
Lin W.-Y., Lee C.G., Chow P. An Optimizing Compiler for the TMS320C25 DSP Chip. - Proceedings of the 5th International Conference on Signal Processing Applications and Technology, pp. I-689I-694, October 1994.
Mahlke S. A., Chen W. Y., Hwu W. W., Rau B. R., Schlansker M. S. Sentinel Scheduling for VLIW and Superscalar Processors. - ASPLOS-V Conference Proceedings, October 1992.
Mahlke S.A., Lin D.C., Chen W.Y., Hank R.E., Bringmann R.A. Effective Compiler Support for Predicated Execution Using the Hyperblock. - Proceedings of the 25th Annual International Workshop on Microprogramming (Portland, Oregon), pp. 45-54, Dec. 1992.
Martin M. M., Roth A., Fischer C. N. Exploiting Dead Value Information. - 30th International Symposium on Microarchitecture, pages 125--135, December 1997.
Moreno J.H. Dynamic Translation of tree-instructions into VLIW. IBM Research Report, 1996.
Motorola DSP96000 User's Manual. - Motorola, Inc., 1990.
Motorola DSP96KCC User's Manual. - Motorola, Inc., 1990.
Ozer E., Banerjia S. Unified Assign and Schedule: A New Approach to Scheduling for Clustered Register File Microarchitectures. - Proceedings of the MICRO-31 - The 31th Annual International Symposiumon Microarchitecture, 1998.
Pai V. S., Adve S. Code Transformation to Improve Memory Parallelism. - The Journal of Instruction-Level Parallelism, May 2000.
Pendry A., Fenwick J. B., Norris J. C. Using SUIF as a Front-end Translator for Register Allocation and Instruction Scheduling Research. - In Second SUIF Compiler Workshop, Stanford, CA, August 1997.
Pinter S. Register Allocation with Instruction Scheduling: a New Approach. - Proceedings of the ACM SIGPLAN '93 Conference on Programming Language Design and Implementation, pages 248-257, 1993.
Pozzi L. Compilation Techniques for Exploiting Instruction Level Parallelism, a Survey. - Milano, Italy, 1998.
Rajagopalan S., Vachharajani M,. Malik S. Handling Irregular ILP Within Conventional VLIW Schedulers Using Artificial Resource Constraints. - CASES'00, November 17-19, 2000, San Jose, California.
Rao S. IA-64 Code Generation. – Electrical and Computer Engineering, June 2000.
Stallman R. Using and Porting GNU CC. - FSF, Boston,
Похожие работы

... конвейер. 3) поток команд порождает недостаточное количество операций для полной загрузки конвейера [3]. Рассмотрим принципы конвейерной обработки информации на примере пятиступенчатого конвейера, в котором выполнение команды складывается из следующих этапов: IF (Instruction Fetch) - считывание команды в процессор; ID (Instruction Decoding) - декодирование команды; OR (Operand Reading) - ...
... СУБД; можно управлять распределением областей внешней памяти, контролировать доступ пользователей к БД и т.д. в масштабах индивидуальной системы, масштабах ограниченного предприятия или масштабах реальной корпоративной сети. В целом, набор серверных продуктов одиннадцатого выпуска компании Sybase представляет собой основательный, хорошо продуманный комплект инструментов, которые можно ...
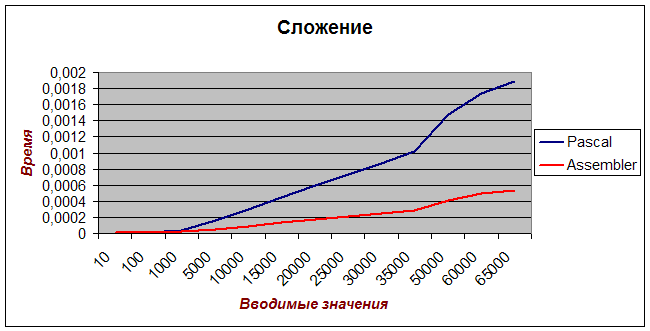
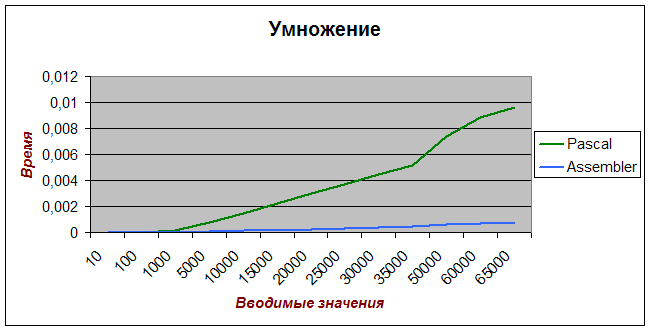
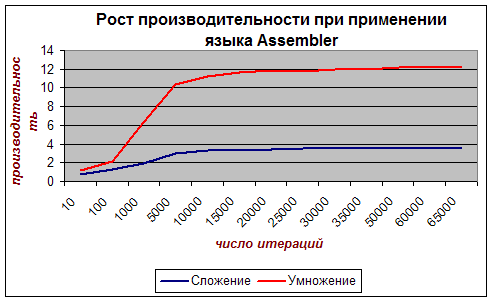
... . Решение: создавать средства для создания программ максимально эффективным способом, обращая внимание на используемые процессором адресации и размещение данных. 2) На быстродействие так же влияет и то, какое напряжение подаётся на микропроцессор. При большом напряжении происходит нагрев процессора. В результате этого основа, на которой размещаются транзисторы, начинает греться и, ...
... ; - показывать, за счет каких структурных особенностей достигается увеличение производительности различных вычислительных систем; с этой точки зрения, классификация может служить моделью для анализа производительности. 1.12 Классификация Дазгупты Одним из последних исследований по классификации архитектур, по-видимому, является работа С. Дазгупты, вышедшая в 1990 году. Автор ...
0 комментариев