Навигация
Обзор методов оптимизации кода для процессоров с поддержкой параллелизма на уровне команд
82492
знака
2
таблицы
0
изображений
Шумаков С.М.
ВведениеПроцессоры, способные одновременно и независимо выполнять несколько команд, обладают исключительно высоким потенциалом производительности и находят все более широкое применение. О процессорах такого типа говорят, что они поддерживают параллелизм на уровне команд (Instruction Level Parallelism, ILP). Далее для краткости они будут называться ILP-процессорами. Класс ILP-процессоров включает суперскалярные процессоры и процессоры с очень длинным командным словом (Very Large Instruction Word, VLIW), к числу которых относятся, в частности, многие модели цифровых процессоров обработки сигналов (ЦПОС).
Важное преимущество ILP по сравнению с параллелизмом многопроцессорных архитектур заключается в том, что программный параллелизм на уровне команд извлекается (аппаратурой или компилятором) автоматически, без дополнительных усилий со стороны прикладных программистов, в то время как использование параллелизма многопроцессорных архитектур подразумевает переписывание приложений.
Для реального использования высокой производительности ILP-процессоров необходимы компиляторы с языков высокого уровня, способные генерировать эффективный код. Применение одних лишь традиционных методов оптимизации кода оказывается совершенно недостаточным. Например, согласно [3] или [41], типичный компилятор для ЦПОС (поддерживающий только традиционные оптимизации) генерирует код, который по времени выполнения может уступать оптимальному в 5-10 и более раз.
В течение последних лет прилагаются значительные усилия по разработке специальных методов оптимизации программ для ILP-процессоров, направленных на выявление и расширение программного параллелизма на уровне команд. Настоящая работа содержит обзор таких методов.
В разделе 2 дается краткий обзор ILP-процессоров и их основных характеристик. Раздел 3 посвящен критериям оптимизации кода для ILP-процессоров. В разделе 4 представлена примерная схема работы компилятора, характеризуются основные задачи, связанные с оптимизацией кода для ILP-процессоров. В разделе 5 дается обзор способов формирования областей (фрагментов компилируемой программы), в рамках которых возможно эффективное распараллеливание. В разделе 6 описываются методы оптимизации, направленные на усиление внутреннего программного параллелизма в рамках выделенных областей. В разделе 7 рассматриваются методы распараллеливания кода в предварительно выделенных областях. Раздел 8 посвящен специфике оптимизации кода для ЦПОС. В разделе 9 приводится информация о языковых расширениях и их роли в увеличении эффективности процессоров. В заключении (раздел 10) представлены некоторые из актуальных нерешенных до настоящего время проблем оптимизации кода для ILP-процессоров.
ILP-платформыОбщие свойства ILP-процессоров - способность одновременно и независимо выполнять несколько операций и наличие нескольких функциональных устройств различных типов, таких как, например, устройство обмена с памятью, арифметическое устройство и др. В выполнении каждой команды участвует определенный набор функциональных устройств. Процессор может выполнять команды c1, ..., cn одновременно, если:
процессор имеет достаточно функциональных устройств для их совместного выполнения.
ни одна из команд ci не использует в качестве входных операндов результаты других команд c1, ..., cn;
ILP-процессоры могут различаться многими характеристиками, которые существенны с точки зрения применимости и эффективности рассматриваемых далее методов оптимизации. Данный раздел содержит краткий обзор типов ILP-процессоров и их свойств.
Одним из исторически первых видов процессорного параллелизма был конвейерный параллелизм, основанный на том, что выполнение команды разбивалось на этапы, на каждом из которых использовались определенные функциональные устройства (рис. 1). Средства конвейеризации обеспечивали совмещенный режим выполнения команд, когда эти команды оказывались независимыми друг от друга. При этом разработчики стремились добиться того, чтобы среднее количество тактов на выполнение команд в конвейере равнялось 1, т.е. чтобы темп выдачи команд составлял одну команду на такт.
Пусть исполнение команды состоит из 3-х этапов
по 1 процессорному такту на каждый:
1) чтение команды из памяти (Ч);
2) декодирование (Д);
3) исполнение (И).
| Последовательное исполнение команд | |||||||||
| Этапы | Ч1 | Д1 | И1 | Ч2 | Д2 | И2 | Ч3 | Д3 | И3 |
| Такты | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| Конвейерное исполнение команд | |||||||||
| Устройство чтения: | Ч1 | Ч2 | Ч3 | Ч4 | Ч5 | Ч6 | Ч7 | ||
| Устройство декодирования: | Д1 | Д2 | Д3 | Д4 | Д5 | Д6 | Д7 | ||
| Устройство исполнения: | И1 | И2 | И3 | И4 | И5 | И6 | И7 | ||
| Такты | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| Конвейерное суперскалярное исполнение команд | |||||||||
| Устройство чтения 1: | Ч1 | Ч2 | Ч3 | Ч4 | Ч5 | Ч6 | Ч7 | ||
| Устройство декодирования 1: | Д1 | Д2 | Д3 | Д4 | Д5 | Д6 | Д7 | ||
| Устройство исполнения 1: | И1 | И2 | И3 | И4 | И5 | И6 | И7 | ||
| Устройство чтения 2: | Ч1 | Ч2 | Ч3 | Ч4 | Ч5 | Ч6 | Ч7 | ||
| Устройство декодирования 2: | Д1 | Д2 | Д3 | Д4 | Д5 | Д6 | Д7 | ||
| Устройство исполнения 2: | И1 | И2 | И3 | И4 | И5 | И6 | И7 | ||
| Такты | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
Рис. 1. Последовательное и параллельное исполнение команд
Естественным развитием средств конвейерной обработки явились процессоры с множественной выдачей команд на исполнение (multiple issue processors) - суперскалярные и VLIW-процессоры. Суперскалярный процессор исполняет обычный последовательный код, но может выбирать в нем и выдавать на выполнение одновременно несколько команд - не более n, где n - темп выдачи команд данного процессора. Различаются суперскалярные процессоры с упорядоченной и неупорядоченной выдачей команд на исполнение. Процессор первого типа выдает команды на исполнение в точности в том порядке, в котором они закодированы в программе. На каждом такте на исполнение выдается от 1 до n очередных команд с учетом возможности их параллельного исполнения. Процессор второго типа анализирует команды в пределах некоторого "окна" - текущего фрагмента входной программы - выбирая в нем для выдачи на исполнение от 1 до n команд с учетом связей по данным и возможности параллельного исполнения.
При разработке суперскалярных процессоров обычно преследуют цель обеспечить бинарную совместимость с предшествующими поколениями (скалярными или суперскалярными) данного модельного ряда процессоров (см. [51]). Суперскалярный процессор выполняет (без перекомпиляции) программный код для предшествующей модели, обеспечивая более высокую производительность.
VLIW-процессоры отличаются от суперскалярных тем, что код для них организован в виде последовательности очень длинных командных слов, каждое из которых содержит несколько команд (операций). Забота о корректном заполнении командных слов возлагается на компилятор (или программиста, пишущего на ассемблере). VLIW-процессоры в целом производительнее суперскалярных, поскольку не тратят время на динамический анализ зависимостей по данным и функциональным устройствам во время выполнения программы. Однако реальная эффективность выполнения программы целиком зависит от качества кода, сгенерированного компилятором.
Следует отметить, что и для суперскалярных процессоров применение ILP-оптимизаций при компиляции дает существенное повышение производительности (см. [55], [58]). Повышению эффективности исполнения на суперскалярных ЭВМ может способствовать также встраивание избыточной информации о программе, доступной во время компиляции и позволяющей процессору динамически производить дополнительные оптимизации. Пример применения этого подхода можно найти в [50].
VLIW-процессор способен работать с большей эффективностью, чем суперскалярный, поскольку у него нет необходимости заниматься динамическим анализом кода. Суперскалярный процессор, тем не менее, превосходит его в качестве планирования команд, поскольку имеет больше информации. Так, при статическом анализе невозможно предсказать случаи непопадания в кэш при чтении из памяти, из-за чего при выполнении возможны простои, в то время как динамический планировщик в этом случае может запустить другие готовые к исполнению команды. Компилятор не имеет права поменять местами команду чтения из памяти с последующей командой записи в память, поскольку адрес записи, возможно, совпадает с адресом чтения. Динамическому планировщику эти адреса уже известны, следовательно, он обладает большей свободой переупорядочения команд. Еще одно преимущество суперскалярных процессоров заключается в поддержке механизма предсказания ветвлений (branch prediction) и выполнения по прогнозу ветвления (control speculation). Аппаратура выбирает направление ветвления исходя из частоты предыдущих ветвлений в этой точке и с упреждением исполняет команды из более вероятной ветви. Это дает ускорение, если прогноз был верен. При неверном прогнозе аппаратура аннулирует результаты упреждающих вычислений.
Концепция явного параллелизма на уровне команд (EPIC - Explicitly Parallel Instruction Computing) возникла из стремления объединить преимущества двух типов архитектур. Идеология EPIC заключается в том, чтобы, с одной стороны, полностью возложить составление плана выполнения команд на компилятор, с другой стороны, предоставить необходимые аппаратные средства, позволяющие при статическом планировании на стадии компиляции использовать механизмы, подобные тем, которые применяются при динамическом планировании в суперскалярных архитектурах (см. [13]).
В разд. 7.4 и 7.6 рассматриваются некоторые характерные для EPIC-архитектур аппаратные средства
поддержка упреждающего выполнения команд на основе прогноза направления ветвления (control speculation);
поддержка выполнения по прогнозу данных (data speculation);
поддержка условного выполнения (predicated execution)
и их использование при статическом планировании.
С точки зрения применимости различных методов оптимизации существенно различие между VLIW-процессорами с регулярной и нерегулярной организацией командного слова. Последние отличаются тем, что на параллельно исполняемые инструкции налагаются дополнительные ограничения. В частности, для параллельно исполняемой инструкции могут допускаться в качестве операндов не все сочетания регистров или не все способы адресации, которые возможны в такой же инструкции, если параллельно с ней не закодированы другие инструкции. Такие особенности характерны, в частности, для цифровых процессоров обработки сигналов, где, в целях ускорения выборки команд, а также для сокращения общего размера кода и энергопотребления, проектировщики стремятся минимизировать длину командного слова и используют для этого нерегулярные способы кодирования. Нерегулярная организация командного слова (см. например, [52]) и связанные с ней ограничения параллелизма исполнения, называемые ограничениями кодирования, существенно усложняют задачу генерации эффективного кода при компиляции ([41],[59]).
Еще одна разновидность ILP-архитектур - кластерные архитектуры, где функциональные устройства поделены на группы (кластеры), и с каждым кластером связан набор локальных регистров, недоступных для функциональных устройств других кластеров (см. [54]). На рис. 2 изображен пример кластерной архитектуры.
Рис. 2. Кластерная архитектура
Специфическая проблема, возникающая при генерации кода для кластерных архитектур - минимизация обменов данных между регистровыми файлами разных кластеров.
Критерии оптимизации кодаПодходы, используемые при оптимизации кода, могут существенно зависеть от критериев оптимизации. Обычно рассматривают три критерия или их комбинации с некоторыми приоритетами:
минимизация времени выполнения программы;
минимизация размера кода;
минимизация энергопотребления.
Последний критерий существен при компиляции приложений для встроенных автономных систем. Размер кода, как правило, имеет второстепенное значение. Далее в основном будет рассматриваться критерий минимизации времени выполнения с учетом возможных ограничений на размер кода.
Локальные методы оптимизации, применяемые в пределах линейных участков, обычно направлены на сокращение одновременно и времени выполнения, и размера кода. Методы реорганизации кода (такие как развертка циклов, встраивание функций и др. - см. разд., 6.1, 6.3), направлены на ускорение работы компилируемой программы ценой увеличения размера выходного кода.
Возможны и другие, более специальные критерии и ограничения. Например, в работах [39] и [40] рассматривается метод планирования инструкций в условиях, когда для некоторых из них заданы начальные и/или конечные времена Tmini, Tmaxi, так что инструкция i должна сработать не позднее момента Tmaxi и не ранее момента Tmini. Подобные ограничения характерны для систем реального времени, где определенные действия должны совершаться в пределах заданных временных интервалов.
Фактор скорости компиляции, по мнению многих авторов ([41], [45], [58] и др.), для ILP-процессоров следует считать второстепенным. В особенности это справедливо в контексте компиляции для ЦПОС. С одной стороны, генерация оптимального кода для них существенно затрудняется из-за ограничений параллельного исполнения, с другой стороны, эффективность результирующего кода для них имеет гораздо более важное значение, чем скорость компиляции.
Круг проблем, связанных с оптимизацией кода для ILP-процессоров
Прежде чем перейти к рассмотрению основных задач, относящихся к ILP-оптимизации, рассмотрим в общих чертах схему работы компилятора, которая представлена на рис. 3 (см., например, [5],[6]). Компилятор для ILP-процессора объединяет в себе стандартные механизмы компиляции, имеющие смысл для всех целевых платформ, и специализированные методы анализа и оптимизации, направленные на выявление, усиление и использование параллелизма на уровне команд.
Рис. 3. Примерная схема компиляции; постпроцессирование – необязательный этап
На первом этапе проводится лексический, синтаксический и семантический анализ программы на входном языке и строится ее промежуточное представление.
В качестве промежуточного представления может использоваться, например, список, элементы которого соответствуют элементарным инструкциям реальной или гипотетической машины. Элементы промежуточного представления содержат информацию об операндах инструкции, о ее связях с другими инструкциями и т.п. В качестве элементов могут фигурировать также вспомогательные сущности, например, отметки о начале и конце циклов, метки и т.п.
Затем проводятся оптимизации в терминах промежуточного представления. Примеры стандартных оптимизаций, поддерживаемых большинством современных компиляторов, - удаление избыточного кода, свертка константных вычислений, выделение общих подвыражений, вынесение инвариантных вычислений из циклов, понижение мощности операций и др. [61]. В ILP-компиляции особое внимание уделяется методам усиления программного параллелизма в телах циклов, которые подробно рассматриваются в разд. 6.
В контексте ILP наибольший интерес представляет оптимизирующее преобразование, называемое планированием. В ходе планирования последовательность команд, сформированная традиционными методами компиляции, переупорядочивается, и команды группируются таким образом, чтобы обеспечить максимально быстрое параллельное исполнение. При этом учитываются связи между командами по данным и по управлению, а также аппаратные возможности параллельного исполнения команд. В применении к компиляции для VLIW-процессоров данное преобразование кода называют также распараллеливанием (code parallelization) или сжатием (code compaction).
Оптимизированное промежуточное представление преобразуется в ассемблерный код.
Применяются также (см. [47]) оптимизации на уровне ассемблерного кода (постпроцессирование). В ходе постпроцессирования кода, сгенерированного при помощи универсального компилятора, выполняются машинно-зависимые оптимизации. Такой подход позволяет ускорить создание оптимизирующего компилятора для нестандартной целевой платформы.
Существенной характеристикой большинства реализаций, как промышленных, так и экспериментальных, является настраиваемость компонентов компилятора на свойства и систему команд целевого процессора.
Перечислим коротко основные методы анализа, реорганизации и оптимизации кода, применяемые в ILP-компиляторах. Более подробно они рассматриваются в последующих разделах.
1. Выделение областей планирования. Область планирования - это фрагмент или множество фрагментов программы, в пределах которых применяется алгоритм планирования. В простейшем случае в качестве таких областей используются линейные участки в смысле [1] или [4] - последовательности команд, содержащие не более одной метки (в начале) и не более одной команды перехода (в конце). Однако в пределах линейного участка не всегда можно найти достаточно команд, способных исполняться параллельно. Поэтому разработчики компиляторов стремятся выделить более крупные области планирования, объединяющие несколько линейных участков. Различные типы областей планирования рассматриваются в разделе 5.
2. Реорганизации кода, направленные на удлинение линейных участков и расширение областей планирования - преобразования циклов, встраивание функций и др., см. разделы 6.1, 6.2.
3. Усиление параллелизма в пределах выделенных областей. Поскольку параллельное исполнение инструкций возможно только при условии их независимости по данным, то в пределах областей проводятся реорганизации кода, направленные на частичное снятие зависимостей по данным между инструкциями - переименование регистров, исключение индуктивных переменных в циклах и др. Наиболее эффективны эти реорганизации в применении к телам развернутых циклов. Эти вопросы рассматриваются в разделе 6.3.
4. Планирование команд в пределах выделенных областей. Различают методы локального планирования (в пределах линейных участков) и глобальное планирование (в пределах расширенных областей), где применяется перемещение команд между линейными участками с использованием аппаратных и программных средств для сохранения корректности программы. Планированию команд посвящен раздел 7.
Области планированияВ традиционных компиляторах планирование, как правило, осуществляется в пределах линейных участков [2]. Однако для ILP-процессоров такой подход может приводить к потерям производительности. Характерная частота переходов в программах нечисленных приложений, например, составляет примерно 20%, т.е. средняя длина линейного участка - 5 команд. С учетом связей по данным, которые вероятнее всего присутствуют между этими командами, степень естественного программного параллелизма оказывается невысокой. Для того чтобы привести степень программного параллелизма в соответствие с уровнем имеющегося аппаратного параллелизма, в компиляторах для ILP-процессоров реализуют планирование в рамках более широких областей кода, объединяющих несколько линейных участков, так что инструкции могут в результате перемещаться из одного участка в другие. При этом обычно стремятся максимально ускорить выполнение вдоль наиболее часто исполняемых ветвей программы. Надо заметить, что подавляющая часть из доступных экспериментальных результатов, подтверждающих преимущества глобального планирования по сравнению с локальным, относятся к приложениям нечисленного характера. Эффективность глобального планирования в компиляции численных приложений требует дополнительных исследований.
Для того чтобы перемещения инструкций между линейными участками были корректны, применяются определенные приемы, ограничения и аппаратные средства, которые рассматриваются в разд. 7.3, 7.4. В этом разделе будут рассмотрены типы областей, для которых выработаны эффективные методы планирования, а также способы построения областей.
Введем два понятия, которые используются в определениях областей: точка слияния - команда, на которую управление может прийти более чем из одного места; точка ветвления - команда условной передачи управления.
Область планирования состоит из одного или более линейных участков, которые в исходной программе могут быть расположены последовательно или произвольно. Области различаются по структуре своего потока управления и по способу формирования. Наиболее известные типы областей - суперблоки, трассы, гиперблоки, древовидные области и регионы - имеют два общих признака: ациклический граф управления и один головной участок, из которого достижимы все остальные.
Ниже перечислены типы областей и их основные характеристики:
Суперблок [30], [35]
может содержать только одну точку слияния - точку входа в начале головного линейного участка;
имеет прямолинейный граф управления. Команды ветвления могут передавать управление в другие суперблоки, но не на команды того же суперблока.
Трасса [27], [28], [30] отличается от суперблока тем, что может содержать более одной точки слияния.
Гиперблок [49] - суперблок, который может включать условно исполняемые участки. Метод гиперблоков эффективен для процессоров, поддерживающих условное выполнение.
Древовидная область (treegion) [18], [31], [32], [34], имеет древовидный граф управления и включает не более одной точки слияния (в начале головного участка). Древовидные области могут формироваться путем реорганизации входной программы; при этом также могут использоваться данные профилирования.
Регион [20], [22] - область с произвольным ациклическим графом управления. Отличительная черта метода регионов - поддержка вложенных регионов (например, внутренних циклов). Метод регионов применяется, в частности, в компиляторе для IA-64 [22], где его реализация существенно опирается на аппаратные средства поддержки параллелизма.
Одна из идей, на которой основываются методы глобального планирования, заключается в том, что код можно реорганизовать таким образом, чтобы сократить время выполнения вдоль одних путей за счет замедления вдоль других. Если решения принимаются в пользу ускорения наиболее частых путей, то за счет этого можно достичь сокращения времени выполнения программы в целом. Такой подход может быть неприемлем в приложениях реального времени, где возможны ограничения на время выполнения вдоль любого, даже самого редкого пути исполнения [58].
При формировании областей используются данные профилирования по частоте выполнения переходов, что делает актуальной задачу эффективного получения данных профилирования. В работе [26] предлагается экономный метод профилирования передач управления для ILP-процессоров. Метод не требует аппаратной поддержки и основан на добавлении минимального необходимого числа дополнительных линейных участков, содержащих зондирующий код для регистрации передач управления. Зондирующий код организуется таким образом, чтобы при выполнении обеспечивалось его максимальное распараллеливание.
Рассмотрим более подробно способы формирования двух типов областей - суперблоков и древовидных областей.
СуперблокиПонятие суперблока соответствует определению расширенного линейного участка. Расширенный линейный участок есть последовательность линейных участков B1 ... Bk, такая что для 1 i < k Bi - единственный предшественник Bi+1. Отличительная черта суперблоков заключается в способах их формирования. С учетом данных профилирования, точки слияния в исходной программе удаляются путем создания копий соответствующих участков. При этом стремятся выделить суперблоки, расположенные вдоль трасс - наиболее часто исполняемых путей на графе управления. Пример формирования суперблока из [35] приведен на рис. 4.
Рис. 4. Формирование суперблоков на основе данных профилирования
На рис. 4а показан граф управления для программного фрагмента, составляющего тело цикла, с указанием частот выполнения участков и переходов между ними. Из этой схемы видно, что наиболее часто выполнение следует вдоль пути A B E F. Поэтому принимается решение сформировать три суперблока: {A,B,E,F}, {C}, {D}. Для этого необходимо исключить точку слияния в F. На рис. 4б показано, как это достигается путем добавления копии F (F'). Этот прием называют "дублированием хвостов" (tail duplication). В конечном счете, из исходного программного фрагмента создается 4 суперблока: {A,B,E,F}, {C}, {D}, {F'}.
Древовидные областиФормирование древовидных областей проводится в два этапа. Сначала на основе статического анализа в графе управления выделяются имеющиеся древовидные участки. Далее, если доступны данные профилирования, выделенные участки искусственно наращивают методом "дублирования хвостов". При этом стремятся объединить участки вдоль наиболее часто исполняемых путей.
Рис. 5. Древовидная область
На рис. 5 приведен пример из [32], где показано наращивание первоначально выделенной области. Исходный программный фрагмент состоит из двух древовидных областей (а). Если исполнение преимущественно следует вдоль A B D E, то желательно реорганизовать код, чтобы путь A B D E попал в общую область, и планировщик мог максимально использовать параллелизм на этом отрезке. На рис. 5b и рис. 5c показаны два этапа такого преобразования. Сначала создается копия D' участка D и формируется область, включающая путь A B D. Затем создается копия E' участка E и формируется область, включающая пути A B D E и A C D' E', а также область, состоящая из одного участка F.
Данные профилирования могут использоваться также на этапе планирования в древовидных областях, для того чтобы обеспечить максимально быстрое выполнение (и исключить задержки) преимущественно вдоль часто исполняемых путей.
Для того чтобы ограничить объем результирующей программы, при принятии решений о "дублировании хвостов", помимо данных профилирования, применяются и другие эвристики (см. [31]):
допустимый общий коэффициент расширения не должен превышать некоторой заранее заданной величины;
число путей исполнения в каждой древовидной области не должно превышать заданной величины;
если число предшественников участка в графе управления больше заданной величины, то дублирование участка не производится.
Аналогичные эвристики используются и при формировании областей других типов.
В [7] можно найти описание метода проникающего планирования (percolation scheduling), предполагающего глобальное переупорядочение кода для выявления параллелизма на уровне тела функции.
Усиление параллелизма в пределах областей планированияБольшинство из рассматриваемых в этом разделе методов применимы в той или иной степени ко всем типам ILP-процессоров и видам областей планирования.
Преобразования циклов
Преобразования циклов, применяемые в ILP-компиляции, подробно рассмотрены в [35] и [58]. К ним относятся: развертка циклов, слияние и разбивка циклов, подгонка циклов, конвейеризация циклов. Все они имеют смысл независимо от наличия параллелизма в целевом процессоре, поскольку позволяют уменьшить общее число проверок завершения цикла и операций перехода. В компиляции для ILPпроцессоров они приобретают дополнительную значимость, поскольку позволяют усилить программный параллелизм в теле цикла.
В примерах, иллюстрирующих смысл преобразований, использован язык Си, реально же они применяются на уровне промежуточного представления.
Развертка цикла (loop unrolling). Суть этого преобразования заключается в том, что тело цикла дублируется n раз, а число повторений соответственно сокращается во столько же раз (рис. 6). Число n называется коэффициентом развертки цикла.
for (i=0;i<100;i++) for (i=0;i<100;i=i+4) {
{a[i]=a[i]+c;} a[i]=a[i]+c;
==> a[i+1]=a[i+1]+c;
a[i+2]=a[i+2]+c;
a[i+3]=a[i+3]+c;}
Рис. 6. Развертка циклов
В контексте ILP-компиляции он приобретает большее значение, поскольку позволяет использовать параллелизм команд, относящихся к разным итерациям цикла. Наиболее эффективно его применение в сочетании с другими преобразованиями, направленными на усиление параллелизма (см. рис. 12).
Слияние циклов (loop fusion). Два расположенных последовательно цикла можно слить, если они имеют одинаковое число итераций и отсутствуют зависимости по данным, препятствующие объединению. Если тела сливаемых циклов не зависят друг от друга (рис. 7), появляется возможность спланировать параллельное выполнение команд, относящихся к разным циклам.
for (i=0;i<100;i++) for (i=0;i<100;i++) {
b[i]=b[i]+c; ==> b[i]=b[i]+c;
for (j=0;j<100;j++) a[i]=a[i]*2;
a[j]=a[j]*2; }
Рис. 7. Слияние циклов
Если граничные значения переменных двух циклов различаются, но ненамного, то применяют слияние с предварительной подгонкой одного из циклов.
Подгонка цикла (loop peeling). Подгонка цикла заключается в изменении граничных значений переменной цикла. Обычно подгонка применяется для того чтобы можно было выполнить слияние (рис. 8) или развертку цикла (если число итераций не кратно коэффициенту развертки).
for (i=0;i<100;i++) for (i=0;i<100;i++) {
b[i]=b[i+2]+c; ==> b[i]=b[i+2]+c;
for (j=0;j<102;j++) a[i]=a[i]*2;}
a[j]=a[j]*2; a[100]=a[100]*2;
a[101]=a[101]*2;
Рис. 8. Слияние циклов с подгонкой одного из них
Программная конвейеризация цикла (software pipelining). Идея конвейеризации цикла заключается в том, что выполнение команд, относящихся к последующим итерациям, начинается раньше, чем завершается выполнение предшествующих итераций. Конвейеризация применима в тех случаях, когда тело цикла можно разбить на группы команд, не зависящих друг от друга на разных итерациях.
На рис. 9 показан пример конвейеризации цикла. Команды, относящиеся к одной итерации исходного цикла, не могут выполняться параллельно в силу зависимостей по данным. Тело результирующего цикла составлено из команд, относящихся к трем смежным итерациям (i, i+1, i+2) и не зависящих друг от друга, так что их выполнение может быть спланировано параллельно. Число итераций, участвующих в конвейерном выполнении цикла, называется глубиной конвейеризацией (по аналогии с аппаратной конвейеризацией). Число итераций конвейеризованного цикла сокращается на n-1, где n - глубина конвейеризации, а в пролог и эпилог выносятся команды, относящиеся к начальным и завершающим итерациям исходного цикла.
a[0]=b[0]+2;
a[1]=b[1]+2;
d[0]=a[0]/n;
for (i=0;i<100;i++){ for (i=0;i<98;i++){
a[i]=b[i]+2; f[i]=d[i]+a[i];
d[i]=a[i]/n; ==> d[i+1]=a[i+1]/n;
f[i]=d[i]+a[i];} a[a+2]=b[i+2]+2;}
d[99]=a[99]/n;
f[98]=d[98]+a[98];
f[99]=d[99]+a[99]];
Рис. 9. Конвейеризация цикла
Конвейеризация, как и развертывание цикла, создает возможности для параллельного выполнения команд из разных итераций, но обладает тем преимуществом, что не увеличивает размер тела цикла.
Обзор методов конвейеризации циклов можно найти в работах [7], [12].
Разбивка циклов (loop distribution). В некоторых случаях может иметь смысл преобразование, обратное слиянию и называемое разбивкой циклов. Это целесообразно, например, если тело цикла слишком длинное, и имеющееся число регистров недостаточно для размещения всех используемых в теле цикла переменных. В этом случае часть промежуточных значений приходится временно выгружать в память, а перед использованием в вычислениях загружать на регистры (в англоязычной литературе этот процесс обозначают термином register spilling). Благодаря разбивке цикла можно избежать дефицита регистров и выталкивания значений в память.
В примере, показанном на рис. 10, вторая команда не может быть выполнена параллельно с первой в силу зависимости по данным. В результате разбивки создаются циклы с более короткими телами и меньшим числом зависимостей по данным.
for (i=0;i<100;i++){ for (i=0;i<100;i++)
b[i]=b[i-1]+c; ==> b[i]=b[i-1]+c;
a[i]=b[i]+2;} for (i=0;i<100;i++)
a[i]=b[i]+2;
Рис. 10. Разбивка циклов
Встраивание функций
Встраивание функций широко применяется как метод оптимизации и в традиционных технологиях компиляции, поскольку при этом экономится время, затрачиваемое на передачу параметров, выполнение пролога и эпилога. В контексте ILP-компиляции этот подход имеет дополнительное преимущество, поскольку он позволяет спрямлять пути исполнения, создавая более длинные линейные участки и дополнительные возможности для распараллеливания кода.
Снятие зависимостей по данным
Алгоритмы планирования команд, используемые практически во всех компиляторах (см. разделы 7.1 и 8), работают с тремя видами зависимостей (или связей) по данным между командами (см., например, [58] или [45]). Здесь будут рассмотрены только зависимости по обращениям к регистрам; о зависимостях по обращениям к памяти см. разд. 7.6.
Пусть имеется некоторая последовательность команд c1, ..., cn, подлежащих планированию. Планировщик может изменять порядок выполнения команд, не нарушая их частичной упорядоченности, которая определяется перечисленными далее зависимостями по данным. (При глобальном планировании планировщик также должен учитывать связи по управлению, препятствующие перемещению команд через точки ветвления; подробнее об этом см. разделы 7.3, 7.4).
1. Связи типа "чтение после записи". Команда cj зависит от ci, если ci записывает значение в некоторый регистр r, а cj читает это значение. Будем обозначать это отношение как ci![]() cj.
cj.
Зависимости этого типа называются истинными, поскольку они отражают объективные связи по данным между операциями, реализующими компилируемую программу: выполнение cj должно планироваться позже, чем выполнение ci. Как правило, избавиться от них нельзя, однако существуют приемы, позволяющие сделать это в некоторых специальных случаях: дублирование переменной суммирования и индуктивных переменных, рассматриваемые далее в этом разделе.
Похожие работы

... конвейер. 3) поток команд порождает недостаточное количество операций для полной загрузки конвейера [3]. Рассмотрим принципы конвейерной обработки информации на примере пятиступенчатого конвейера, в котором выполнение команды складывается из следующих этапов: IF (Instruction Fetch) - считывание команды в процессор; ID (Instruction Decoding) - декодирование команды; OR (Operand Reading) - ...
... СУБД; можно управлять распределением областей внешней памяти, контролировать доступ пользователей к БД и т.д. в масштабах индивидуальной системы, масштабах ограниченного предприятия или масштабах реальной корпоративной сети. В целом, набор серверных продуктов одиннадцатого выпуска компании Sybase представляет собой основательный, хорошо продуманный комплект инструментов, которые можно ...
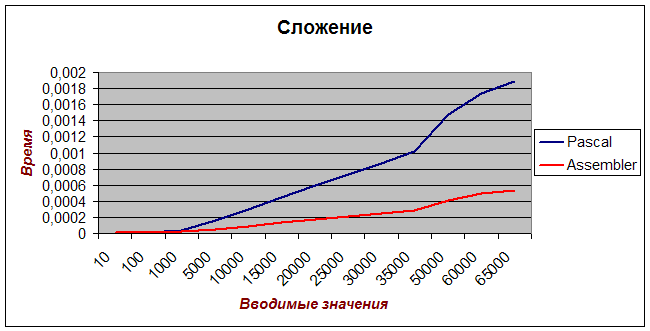
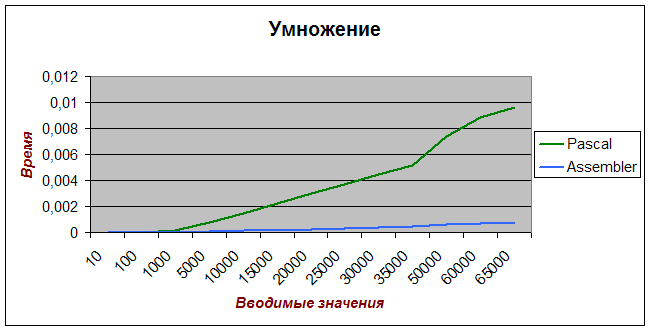
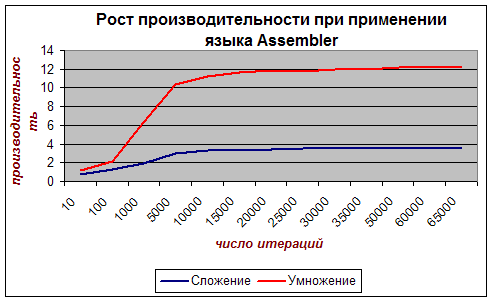
... . Решение: создавать средства для создания программ максимально эффективным способом, обращая внимание на используемые процессором адресации и размещение данных. 2) На быстродействие так же влияет и то, какое напряжение подаётся на микропроцессор. При большом напряжении происходит нагрев процессора. В результате этого основа, на которой размещаются транзисторы, начинает греться и, ...
... ; - показывать, за счет каких структурных особенностей достигается увеличение производительности различных вычислительных систем; с этой точки зрения, классификация может служить моделью для анализа производительности. 1.12 Классификация Дазгупты Одним из последних исследований по классификации архитектур, по-видимому, является работа С. Дазгупты, вышедшая в 1990 году. Автор ...
0 комментариев