Навигация
Связи типа "запись после записи". Команда cj зависит от ci, если
82492
знака
2
таблицы
0
изображений
2. Связи типа "запись после записи". Команда cj зависит от ci, если
обе команды записывают значения в некоторый регистр r
j > i
имеется хотя бы одна команда сk, которая читает значение r, записанное командой ci.
Будем обозначать это отношение как ci![]() cj. Выполнение команды cj должно быть запланировано позже чем ci, если имеет место ci
cj. Выполнение команды cj должно быть запланировано позже чем ci, если имеет место ci![]() cj.
cj.
3. Связи типа "запись после чтения". Команда cj зависит от ci, если существует команда ck, такая что имеет место ck![]() ci и ck
ci и ck![]() cj. Будем обозначать это отношение ci
cj. Будем обозначать это отношение ci![]() cj. Смысл этой зависимости в том, что ci читает некоторый регистр r, записанный ранее командой ck, а cj (j > i) записывает в r другое значение. Если имеет место ci
cj. Смысл этой зависимости в том, что ci читает некоторый регистр r, записанный ранее командой ck, а cj (j > i) записывает в r другое значение. Если имеет место ci![]() cj, то cj может быть выполнена не раньше ci (т.е. одновременно или позднее ci).
cj, то cj может быть выполнена не раньше ci (т.е. одновременно или позднее ci).
Последние два типа связей называют антизависимостями или ложными зависимостями, поскольку они возникают в результате того, что компилятор использует одни и те же регистры для хранения разных значений (или программист использует одни и те же рабочие переменные для хранения различных промежуточных значений).
Рис. 11. Зависимости по данным (a) до распределения регистров, (b) после распределения регистров. После распределения регистров появляются антизависимости WAR (R3=R1+R2,R1=R4-R5) по R1 и WAW(R3=R1+R2,R3=R0-R7) по R3
На рис. 11 представлены примеры зависимостей всех типов и показано, как образуются антизависимости.
Зависимости по данным препятствуют параллельному исполнению команд и их переупорядочению при планировании. В случае, показанном на рис. 11а), возможно параллельное выполнение команд (1,2,4) или (3,4). После распределения регистров (рис. 11б), антизависимости жестко определят порядок выполнения команд – 1), 2), 3), 4). Поэтому важно по возможности избавляться от них. Большинство из перечисленных далее преобразований направлено на снятие антизависимостей по данным внутри областей планирования.
Миграция команд. Если результат команды не используется в данной области, то ее можно переместить в области, которые выполняются реже. Для суперблоков этот метод применяется следующим образом [35]. Если результат операции не используется в суперблоке S, то она может быть удалена из S, при этом ее копии создаются во всех суперблоках, на которые управление может быть передано из S. При этом исключаются суперблоки, в которых результат заведомо не используется. Решение принимается с учетом оценок частот выполнения суперблоков. В результате в S исключаются все зависимости по данным, связанные с этой операцией.
Переименование регистров. Суть этого приема заключается в том, чтобы размещать разные значения в разных регистрах. Разумеется, его практическое применение ограничено числом доступных регистров.
Дублирование индуктивной переменной. Индуктивные переменные это переменные, представляющие собой выражения, линейно зависящие от переменной цикла, например, адресные выражения для доступа к элементам массива. В развернутом цикле при вычислении индуктивных переменных возникают зависимости по данным. В результате оказывается невозможным распараллеливание вычисления индуктивных переменных и доступа к памяти по ним. Положение можно исправить, если завести несколько экземпляров индуктивной переменной (в соответствии с коэффициентом развертки цикла).
Дублирование переменной суммирования. Если в цикле производится суммирование или перемножение выражений, то при развертке цикла можно создать несколько экземпляров переменной суммирования для накопления частичных сумм или произведений [35]. В эпилоге цикла частичные суммы или произведения, соответственно, складываются или перемножаются. Этот прием применим к любой операции, обладающей свойствами коммутативности и ассоциативности.
На рис. 12 показано применение развертки цикла в сочетании с оптимизациями снятия зависимостей - переименованием регистров, дублированием переменной суммирования и индуктивной переменной. Код, полученный непосредственно после развертки, слабо поддается распараллеливанию из-за большого числа зависимостей по данным. В результате снятия зависимостей получается тело цикла, выполнение которого на идеальном процессоре (с неограниченными возможностями параллельного исполнения, без задержек) занимает 2 такта.
Исходный цикл:
s=0;
for (i=0;i<100;i++)
{s=s+a[i];}
Ассемблерный код
r1 = A
r3 = 0
L1: r2 = MEM(r1)
r3 = r3 + r2
r1 = r1 + 4
blt (r1 A+4N) L1
Результат развертки с коэффициентом 3:
r1 = A
r3 = 0
L1: r2 = MEM(r1)
r3 = r2 + r3
r1 = r1 + 4
r2 = MEM(r1)
r3 = r2 + r3
r1 = r1 + 4
r2 = MEM(r1)
r3 = r2 + r3
r1 = r1 + 4
blt (r1 A+4N) L1
Результат снятия зависимостей по данным:
r11 = A ;; Размножение индуктивной
r21 = A + 4 ;; переменной
r31 = A + 8
r3 = 0 ;; Размножение переменной
r23 = 0 ;; суммирования
r33 = 0
L1: r2 = MEM(r11)
r3 = r2 + r3
r11 = r11 + 12
r22 = MEM(r21) ;; Переименование r2 -> r22
r23 = r22 + r23
r21 = r21 + 12
r32 = MEM(r31) ;; Переименование r2 -> r22
r33 = r32 + r33
r31 = r31 + 12
blt (r1 A+4N) L1
r3 = r3 + r23 ;; Сложение частичных сумм
r3 = r3 + r33
Рис. 12. Развертка цикла и снятие зависимостей по данным
Соотношение программного и аппаратного параллелизма
Рассмотренные выше методы оптимизации направлены на усиление программного параллелизма на уровне команд, с тем чтобы максимально использовать имеющиеся в процессоре средства параллельного исполнения. Важный момент, который необходимо учитывать при их практической реализации, - соотношение между фактическим уровнем аппаратного параллелизма целевого процессора и уровнем программного параллелизма. Набор оптимизаций и их параметры (такие как коэффициент развертки) следует соразмерять с аппаратными характеристиками, в первую очередь, с реальными возможностями параллельного исполнения команд и количеством доступных регистров. Например, дублирование переменной суммирования может не иметь смысла, если процессор не способен выполнять одновременно несколько сложений. Развертка цикла может привести к деградации производительности, если регистров недостаточно для размещения всех переменных увеличившегося тела цикла. В этом случае компилятор вынужден размещать переменные в памяти, и использовать дополнительные команды для загрузки их на регистры перед выполнением операций и выгрузки в память при изменении значений, что может свести на нет эффект усиления параллелизма (см. [19], [38]).
Планирование команд
Алгоритмы планирования
После того как области планирования выделены и проведены оптимизации снятия зависимостей по данным, выполняется планирование команд. Считается, что на этом этапе для каждой области известны ее входные (вычисленные ранее) и выходные (используемые вне данной области) объекты.
В ILP-компиляции в основном применяются различные варианты приоритетного (эвристического) списочного планирования (list scheduling). Процесс планирования состоит из трех шагов:
1. Вычисление зависимостей по данным и по управлению между командами в пределах области планирования, которые обычно представляют в виде направленного ациклического графа. Зависимости по управлению препятствуют перемещению команд вокруг точек ветвления. Эти зависимости могут быть в дальнейшем частично сняты, т.е. при планировании команды могут перемещаться выше или ниже точек ветвления (см. далее разд.7.3, 7.4).
2. Вычисление приоритетов команд. Приоритеты определяют, в каком порядке будут планироваться готовые к исполнению команды на шаге 3. Способ вычисления приоритетов отражает эвристики планирования, от которых может существенно зависеть результат. Как правило, применяется эвристика планирования по критическому пути, когда приоритет команды определяется высотой соответствующего узла в графе зависимостей. Команды с совпадающими приоритетами упорядочивают либо произвольным образом, либо по некоторому вторичному признаку. В [31] приводятся результаты исследований нескольких эвристик глобального планирования в древовидных областях:
по глубине команды в графе зависимостей;
по числу выходов из области по всем путям в дереве управления, исходящим из данной команды (exit count). Согласно этой эвристике, наибольший приоритет получают команды, находящиеся в корне дерева.
по частоте выполнения на основе данных профилирования (global weight). Приоритет отдается наиболее часто исполняемым командам, а при равенстве частот команды упорядочиваются по глубине.
по взвешенной частоте выходов (weighted count). В качестве первичного критерия используется частота выполнения, а при равенстве частот - счетчик выходов.
Согласно результатам этой работы, наилучшие результаты в среднем дают эвристики 1) и 3); авторы рекомендуют использовать эвристику частоты исполнения, а если данные профилирования отсутствуют, то сортировать команды по глубине в графе зависимостей.
3. На последней фазе рассматриваются (в порядке своих приоритетов) готовые к исполнению команды и выдаются в выходной поток. Если целевой процессор является VLIW-процессором, то выходной поток состоит из длинных командных слов, каждое из которых может содержать несколько команд входного потока. Различаются следующие способы формирования выходного потока [32]:
Сверху вниз / снизу вверх. В первом случае команда рассматривается после того, как все ее предшественники в графе зависимостей выведены в выходной поток. При планировании снизу вверх команда рассматривается после того как выведены все ее потомки. При глобальном планировании более естественным является метод сверху вниз.
Перебор команд / заполнение командных слов. В первом случае планировщик на каждом шаге выбирает готовую к исполнению команду с максимальным приоритетом и подыскивает для нее подходящее командное слово в выходном потоке, так чтобы удовлетворялись связи по данным и ограничения по ресурсам (функциональным устройствам). Во втором случае планировщик последовательно заполняет командные слова. Среди готовых к исполнению команд подбираются команды, которые можно выполнить параллельно, и помещаются в очередное слово. Затем происходит заполнение следующего слова и т.д. Второй подход, по-видимому, предпочтителен для процессоров, где команда может занимать ресурс в течение нескольких тактов, а также для VLIW-процессоров с нерегулярной структурой командного слова.
Иногда применяют дополнительную эвристику, выбирая из множества готовых к исполнению те команды, которые максимально расширят это множество на следующем шаге (см. [9]).
Интересный альтернативный алгоритм планирования, который предложен в работе [11], используется в системе построения компиляторов [5]. Это переборный алгоритм локального планирования, позволяющий находить наилучший по времени план выполнения. Идея его заключается в следующем. Пусть G=(A,V,E) - смешанный граф, где A - множество вершин (операций линейного участка), V - множество дуг, соответствующих зависимостям по данным, E - множество ненаправленных ребер, таких что [a,b] E, если параллельное исполнение операций a, b невозможно в силу аппаратных ограничений. Из смешанного графа G можно при помощи перебора получить множество ориентированных графов, заменяя каждое из ненаправленных ребер из E на дугу, направленную в ту или другую сторону (если операции a, b невозможно выполнить параллельно, то либо a должна выполниться раньше b, либо наоборот). Каждый ациклический граф, полученный таким образом из G, однозначно определяет план выполнения линейного участка. Среди всех планов выбирается наилучший по времени выполнения.
Время работы алгоритма экспоненциально зависит от длины линейного участка, поэтому автор рекомендует использовать его для оптимизации циклов. Ограничением этого подхода является также предположение о том, что несовместимость команд (невозможность их параллельного исполнения) можно описать в виде бинарного отношения, что не верно, например, если процессор имеет несколько однотипных функциональных устройств. Возможны ситуации, когда, скажем, команды a, b, c несовместимы, хотя любые две из них совместимы.
Координация планирования и распределения регистров
Процедуры планирования и распределения регистров при генерации кода для ILP-процессоров имеют в каком-то смысле конфликтующие цели. Для того чтобы полнее загрузить работой функциональные устройства, планировщик стремится максимально использовать программный параллелизм, а для этого необходимо, чтобы как можно большее число значений находилось на регистрах. Распределитель регистров, напротив, стремится сократить использование регистров, чтобы исключить выталкивание значений в память (а также их сохранение/восстановление при вызовах подпрограмм). Поэтому в компиляторе для ILP-процессора важно обеспечить правильное взаимодействие этих двух механизмов.
Если распределение регистров выполняется до планирования, то это может снизить программный параллелизм из-за введения антизависимостей по данным при переиспользовании регистров. С другой стороны, если планирование выполняется до распределения регистров, то зачастую генерируется код, требующий больше регистров, чем имеется в наличии. В таком случае распределитель регистров вынужден выталкивать часть значений в память и добавлять в программу команды загрузки и выгрузки этих значений, что может привести к деградации выходного кода.
Для решения этой проблемы применяются подходы, включающие повторное планирование, интеграцию обеих процедур или передачу информации между ними.
Повторное планирование. Перед распределением регистров выполняется предварительное планирование. На этом этапе для хранения каждого значения используется уникальный виртуальный регистр, так что отрицательный эффект антизависимостей по данным исключен. Затем проводится распределение регистров и окончательное планирование, во время которого планируется исполнение дополнительных команд, которые могли быть сгенерированы в ходе распределения регистров ([24], [33]).
Распределение регистров с использованием информации, полученной от планировщика. В [57] описывается модификация классического решения задачи распределения регистров методом раскраски графа (см., например, [8]). Задача раскраски формулируется для графа, в котором представлены не только данные об областях жизни значений, но и информация о возможности параллельного исполнения команд (parallel interference graph). Переиспользование регистров по возможности исключается в тех случаях, когда оно влечет ограничение параллелизма. Информация о возможности параллельного исполнения вычисляется планировщиком. Аналогичный подход представлен в [56].
В [21] представлен алгоритм совместного планирования и распределения регистров, где и регистры, и функциональные устройства рассматриваются как ресурсы.
В [25] и [38] предлагаются специальные алгоритмы планирования для развернутых циклов, обеспечивающие контроль числа требуемых регистров, с тем чтобы исключить или минимизировать обмены с памятью.
В компиляторе для архитектуры TriMedia [32] реализован комбинированный подход, где распределение глобальных регистров осуществляется обычным методом раскраски графа, а распределение локальных регистров (для областей жизни, не выходящих за границы линейных участков) осуществляется непосредственно планировщиком, который постоянно отслеживает уровень дефицита регистров (register pressure) и динамически перевычисляет приоритеты команд. Как только уровень дефицита регистров превышает некоторый порог, приоритеты команд пересчитываются таким образом, чтобы преимущество отдавалось командам, выполнение которых приведет к снижению дефицита. При низком уровне дефицита регистров увеличивается приоритет команд, которые открывают новые области жизни, что повышает возможности распараллеливания кода (чем больше значений находится на регистрах, тем больше команд, готовых к исполнению).
При генерации кода для кластерных архитектур возникает проблема минимизации обмена данных между регистровыми файлами разных кластеров. Решение этой проблемы предлагается в [54], где планирование совмещается с назначением кластеров. Аналогичный подход используется в [43].
Глобальное планирование
Преимущество глобального планирования заключается в том, что оно применяется к более крупным фрагментам программы, состоящим из нескольких линейным участкам. В результате появляется возможность более эффективного использования аппаратных средств параллельного исполнения. Для того чтобы это преимущество реально работало, необходимо уметь перемещать команды вокруг точек ветвления. Рассмотрим более подробно соответствующие проблемы и решения.
Перенос команды ниже точки ветвления является частным случаем миграции команд, которая описана выше в разд. 6.2. Более интересен случай переноса команды выше предшествующей точки ветвления. Этот вид переноса может быть полезен по двум причинам:
в предшествующем линейном участке, возможно, имеется свободная позиция в одном из командных слов, куда можно поместить рассматриваемую команду;
если команда имеет задержку (т.е. ее результат можно использовать только по истечению некоторого числа тактов), то выгодно запланировать ее выполнение как можно раньше, в особенности, если она находится на критическом пути.
Перенос команд выше точки ветвления можно назвать упреждающим выполнением (в англоязычной литературе используется термин speculative execution или control speculation), поскольку команда выполняются раньше, чем становится известно, будет ли передано управление в участок, где она изначально находилась.
Рассмотрим ограничения, которые должны соблюдаться при переносе команд выше точки ветвления, на примере (рис. 13).
Рис. 13. Перенос команды C выше точки ветвления B
Перенос команды C выше точки ветвления B (в участок ЛУ1) возможен при соблюдении двух ограничений (см. [30], [35], [48]):
Ограничение 1. Прежнее значение регистра, в который C записывает свой результат, не требуется больше ни одной команде в ЛУ1 или в других участках, куда может быть передано управление из ЛУ1.
Ограничение 2. Команда C не может вызвать прерывание, которое приведет к завершению программы.
Некорректность переноса команды при несоблюдении второго ограничения можно проиллюстрировать на простом примере рис. 14.
Рис. 14. Перенос команды "C=A/B" выше команды ветвления некорректен, так как это приведет к аварийному завершению программы при B=0
Планирование с соблюдением обоих ограничений называют "ограниченной фильтрацией" (restricted percolation). При соблюдении обоих ограничений число команд, перенос которых реально возможен, оказывается невелико, что значительно снижает эффективность глобального планирования. Поэтому важное значение имеют методы, позволяющие снять эти ограничения.
Ограничение 1 можно снять путем переименования регистров - для значения, которое вычисляется в команде C, назначается другой регистр.
Для снятия ограничения 2 необходимы средства аппаратной поддержки, описанные в следующем разделе.
Аппаратная поддержка глобального планирования
Упреждающее выполнение применяется как в динамическом (аппаратном) планировании в суперскалярных процессорах с неупорядоченной выдачей команд, так и в статическом планировании во время компиляции. Здесь будут рассмотрены характерные для EPIC-архитектур аппаратные расширения, которые позволяют планировать упреждающее выполнение команд во время компиляции. Существуют две модели поддержки упреждающего выполнения - модель неограниченной фильтрации (general percolation, см. [35]) и модель защищенного планирования (sentinel scheduling, см. [48]).
Первая модель предполагает наличие в аппаратуре непрерываемых версий всех команд. Если планировщик переносит команду выше точки ветвления, то он использует ее непрерываемую версию. Упреждающее выполнение записей в память не допускается. Исключительные ситуации, если они возникают, игнорируются. Получаемые при этом неправильные результаты могут сказаться на дальнейшем выполнении, например, привести позднее к прерываниям или просто к неверным результатам.
Вторая модель обеспечивает корректность статического планирования с применением упреждающего выполнения и включает следующие аппаратные расширения:
1. В кодировку команд добавляется бит упреждающего выполнения. Если он установлен, то говорят, что команда выполняется в режиме упреждающего выполнения, в котором прерывания не выдаются. Если возникает исключительная ситуация, то в регистре результата устанавливается бит прерывания. То же происходит, если бит прерывания установлен хотя бы в одном из регистров-операндов. При выполнении команд в обычном режиме должны выдаваться прерывания, если хотя бы один из входных регистров имеет установленный бит прерывания (или если исключительная ситуация возникла при выполнении самой команды).
2. К каждому регистру добавляется бит прерывания, который устанавливается при выполнении команд в режиме упреждающего выполнения, если возникает исключительная ситуация, и может быть опрошен при помощи специальной команды check_exception(R). С каждым регистром связывается также поле диагностики, в которое заносится программный адрес возникновения исключительной ситуации. Бит прерывания вместе с полем данных должны сохраняться и восстанавливаться при временном сохранении регистра в памяти.
Похожие работы

... конвейер. 3) поток команд порождает недостаточное количество операций для полной загрузки конвейера [3]. Рассмотрим принципы конвейерной обработки информации на примере пятиступенчатого конвейера, в котором выполнение команды складывается из следующих этапов: IF (Instruction Fetch) - считывание команды в процессор; ID (Instruction Decoding) - декодирование команды; OR (Operand Reading) - ...
... СУБД; можно управлять распределением областей внешней памяти, контролировать доступ пользователей к БД и т.д. в масштабах индивидуальной системы, масштабах ограниченного предприятия или масштабах реальной корпоративной сети. В целом, набор серверных продуктов одиннадцатого выпуска компании Sybase представляет собой основательный, хорошо продуманный комплект инструментов, которые можно ...
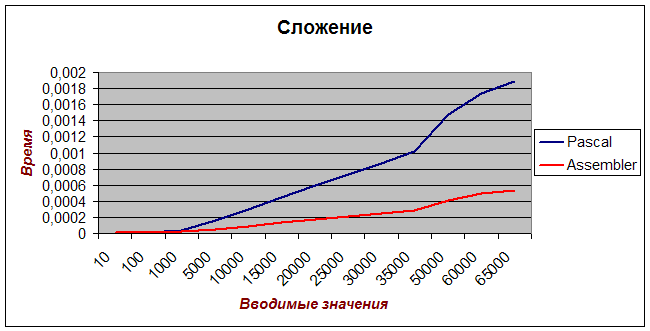
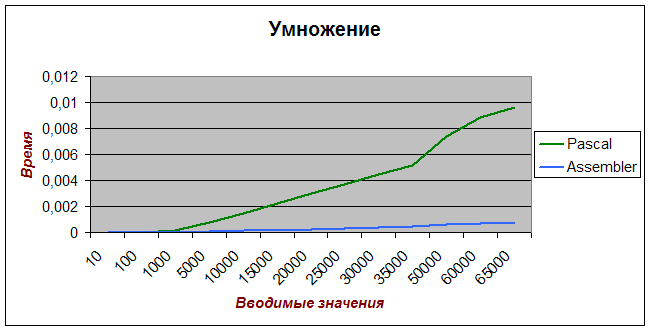
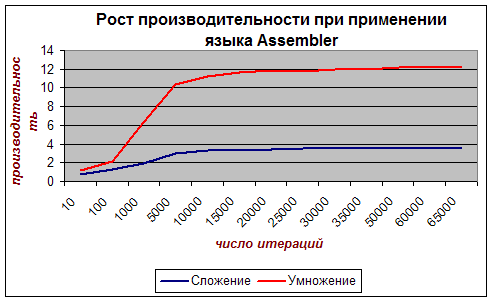
... . Решение: создавать средства для создания программ максимально эффективным способом, обращая внимание на используемые процессором адресации и размещение данных. 2) На быстродействие так же влияет и то, какое напряжение подаётся на микропроцессор. При большом напряжении происходит нагрев процессора. В результате этого основа, на которой размещаются транзисторы, начинает греться и, ...
... ; - показывать, за счет каких структурных особенностей достигается увеличение производительности различных вычислительных систем; с этой точки зрения, классификация может служить моделью для анализа производительности. 1.12 Классификация Дазгупты Одним из последних исследований по классификации архитектур, по-видимому, является работа С. Дазгупты, вышедшая в 1990 году. Автор ...
0 комментариев