Семестр: Отладка разработанного ПО и оформление протоко-
В строке ...SiSj... символы Si и Sj входят в одну и ту
В множество L(U) самых левых символов нетерминального
Пусть между некоторыми двумя символами Si и Sj сущес-
I i 1
Не предусмотрен выход при выполнении условия R > R , так как
Потом повторяется п. 5
Если выполнение шага 4 пpиведет к тому, что значения всех
Перевод инфиксной записи в польскую. Всякий раз, когда в
Когда редуцируется основа XY..Z, тетрады для всех нетер-
Опреанды и операторы
Если сканируемый символ - унарный оператор, то он приме-
А * В + С * D => *, A, B, T1 ┐ тетрады располагаются в
Устраняет недостатки программы,вызванные небрежностью или
Проверяется
непртиворечивость типов получателя и ис-
ДИСПЛЕЙ
Выделение памяти под рамку в процессе трансляции
ОРГАНИЗАЦИЯ ПАМЯТИ ВО ВРЕМЯ ТРАНСЛЯЦИИ
Алгоритм Биледи
Возможные параметры описания переменных и процедур
Навигация
ОРГАНИЗАЦИЯ ПАМЯТИ ВО ВРЕМЯ ТРАНСЛЯЦИИ
Проектирование трансляторов
319724
знака
0
таблиц
0
изображений
3. ОРГАНИЗАЦИЯ ПАМЯТИ ВО ВРЕМЯ ТРАНСЛЯЦИИ
3.1 Проблемы распределения памяти
Распределение памяти для определенных программистом перемен-
ных в языках высокого уровня обычно бывает простым. Часто ло-
кальные переменные размещаются в памяти непосредственно после
соответствующей программной единицы. Однако для современных ЭВМ и
ОС, требующих разделения неизменяемой и изменяемой частей прог-
раммы, возникает необходимость помещать локальные переменные в
отдельные области памяти.
Основные проблемы возникают тогда, когда нужно распределить
память для временных переменных, т.е. промежуточных результатов,
потребность в которых появляется при компиляции. Эти переменные
определяются не в программе на входном языке, а компилятором. Ре-
шение о том, сколько для них требуется памяти и как ее распреде-
лить, полностью зависит от компилятора. Поэтому нужен алгоритм
как можно более эффективного размещения в памяти этих переменных.
Здесь под эффективностью обычно понимается стремление минимизиро-
вать объем используемой памяти.
Распределение памяти становится нетривиальной задачей в том
случае, когда у ЭВМ существует более чем один уровень памяти.
У многих машин имеются ограниченные наборы быстрых регис-
тров, которые отличаются от основной памяти либо более быстрым
доступом, либо иными, более удобными свойствами. Эффективное ис-
пользование этих регистров является задачей компилятора, и нужны
алгоритмы оптимального размещения переменных в быстрых регистрах.
3.2 Распределение памяти для временных переменных
Алгоритмы генерации команд не касаются распределения памяти
для временных переменных. Можно считать, что эти алгоритмы берут
новое имя переменной из бесконечного множества неиспользованных
имен каждый раз, когда, согласно алгоритму, требуется новая вре-
менная переменная. Алгоритм распределения памяти должен размес-
тить эти переменные в памяти так, чтобы потребовалось мини-
мальное число ячеек памяти.
ИНТЕРВАЛОМ для переменной называется отрезок времени между
начальным определением этой переменной и ее последним использова-
нием. Очевидно, переменные, интервалы для которых совсем не свя-
заны, могут быть совмещены в памяти.
Рассмотрим набор переменных V1, V2, V3, ..., Vn. Для каждой
переменной Vi определена команда ST Vi, которая присваивает этой
переменной начальное значение и означает начало интервала для Vi.
Определяется также команда U Vi, которая означает очередное
использование этой переменной. Последняя команда этого вида, ис-
пользующая Vi, означает конец интервала для Vi. Команда U будет
применяться для обозначения таких команд, как ADD, SUB и т.д.
Для вычисления значения выражения (a+b*c)/(f*g-(d+e)/(h+k))
генератор команд по дереву разбора сформировал следующую последо-
вательность машинных команд:
L h
ADD k
ST V1
L d
ADD e
DIV V1
ST V2
L f
MPY g
SUB V2
ST V3
L b
MPY c
ADD a
DIV V3
Имена V1, V2 и V3 были взяты из множества неиспользованных
имен. Алгоритм распределения памяти, который мы хотим определить,
должен показать, что фактически эти три переменные могут быть по-
мещены в одну и ту же ячейку памяти T1.
Поскольку этот алгоритм распределения памяти касается опре-
деленных частей последовательности, можно написать
ST V1
U V1
ST V2
U V2
ST V3
U V3
Так как последнее использование каждой переменной встречает-
ся до определения следующей переменной, то легко видеть, что дос-
таточно одной ячейки памяти.
Предположим, что имеется стек неиспользованных ячеек памяти
[T1, T2, T3, ...]. Предположим далее, что каждый раз, когда нуж-
на ячейка, она берется из вершины стека и что сразу после послед-
него использования какой-либо переменной отведенная для нее ячей-
ка возвращается в стек. Тогда алгоритм распределения памяти для
временных переменных проще всего описать следующим образом.
Последовательность команд просматривается НАЧИНАЯ С КОНЦА, В
ОБРАТНОМ ПОРЯДКЕ. Если встречается команда вида U Vi и при этом
для переменной Vi еще не отведена ячейка памяти, то из вершины
стека берется свободная ячейка, ставится в соответствие перемен-
ной Vi и производится замена символа Vi в данной команде на ад-
рес соответствующей ячейки памяти. Такая же замена производится и
в том случае, когда ячейка памяти для переменной Vi уже отведена
ранее. Если встречается команда ST Vi и для переменной Vi еще не
отведена ячейка памяти, то это означает либо ошибку, либо избы-
точность данной команды, так как подразумевается, что переменная
вычисляется без дальнейшего использования. Если для переменной Vi
ранее отведена ячейка памяти, то производится замена символа Vi в
данной команде на адрес соответствующей ячейки памяти и, пос-
кольку это первое обращение к переменной Vi, соответствующая
ячейка в данный момент может быть возвращена в стек свободной па-
мяти, так как для Vi она больше не понадобится.
Данциг и Рейнольдс показали, что этот алгоритм оптимален,
хотя он и не единственный возможный оптимальный алгоритм.
Например, рассмотрим последовательность
(1) ST V1
(2) ST V2
(3) U V2
(4) U V1
(5) ST V3
(6) U V1
(7) U V3
(8) ST V4
(9) U V3
(10) U V4
и предположим, что стек свободной памяти есть [T1, T2, T3].
Начинаем просмотр последовательности с конца; команда (10) поме-
щает переменную V4 в ячейку T1, команда (9) отводит для перемен-
ной V3 ячейку T2, после этого стек остается в виде [T3]. Команда
(8) освобождает ячейку T1, после этого стек принимает вид [T1,
T3]. Команда (6) помещает V1 в ячейку T1. Подобным же образом ко-
манда (5) освобождает ячейку T2; затем эта ячейка отводится ко-
мандой (3) переменной V2. В результате получается последова-
тельность
(1) ST T1
(2) ST T2
(3) U T2
(4) U T1
(5) ST T2
(6) U T1
(7) U T2
(8) ST T1
(9) U T2
(10) U T1
Этот алгоритм находит интервал для каждой переменной, ис-
пользуя первое появление этой переменной при обратном посмотре
для определения конца интервала, а соответствующую команду ST для
определения начала интервала. Больше от алгоритма ничего не тре-
буется.
Предложенный алгоритм может быть изменен так, чтобы выраба-
тывать ту же информацию путем прямого просмотра последовательнос-
ти команд. При прямом просмотре каждая команда ST определяет
по-прежнему начало интервала. Если для каждой переменной подсчи-
тано число ее использований, то можно найти и последнее использо-
вание любой переменной, так что конец соответствующего интервала
становится известным.
Другой вариант состоит в том, чтобы находить конец интерва-
ла способом, описанным для обратного просмотра, но фактически
осуществлять прямой просмотр. Это достигается образованием цепоч-
ки всех обращений к данной переменной в порядке их появления при
просмотре. С каждой переменной Vi связываются три ячейки, содер-
жащие Fi, Li и Ri. Значение Fi является номером команды ST для
переменной Vi в последовательности команд. Значение Li является
номером команды последнего обращения к переменной Vi. Поэтому ин-
тервал для Vi имеет вид (Fi,Li). Значение Ri является адресом
ячейки, отведенной для переменной Vi, и обычно первоначально ус-
танавливается равным нулю.
Если при просмотре последовательности команд встречается ко-
манда ST Vi, то это вызывает установку значений Fi и Li, равных
номеру этой команды в последовательности. Если встречается коман-
да U Vi, то Vi заменяется в ней на Li, а Li становится равным но-
меру этой команды. Для предыдущего примера переменные Fi и Li
принимают конечные значения:
F1=1 L1=6
F2=2 L2=3
F3=5 L3=9
F4=8 L4=10
а команды принимают вид
(1) ST 0
(2) ST 0
(3) U 2
(4) U 1
(5) ST 0
(6) U 4
(7) U 5
(8) ST 0
(9) U 7
(10) U 8
После завершения просмотра последовательности значение Li
указывает конец цепочки всех обращений к переменной Vi. Каждая
команда содержит в адресной части номер предыдущей команды из той
же цепочки. Если для переменной Vi отведена ячейка в памяти, то
не представляет труда подняться по соответствующей цепочке, заме-
няя адресные части команд на адрес ячейки, отведенной для Vi.
Итак, интервал для каждой переменной определяется парой чисел
(Fi,Li). Теперь можно просмотреть эти пары, чтобы распределить
память для всех переменных. Если Fi=Li, то соответствующая коман-
да ST является избыточной, как отмечалось раньше.
Интервалы просматриваются в порядке возрастания Fi. В нашем
примере переменные уже перенумерованы в этом порядке. Обычно ал-
горитм генерирования команд может быть согласован с алгоритмом
распределения памяти так, чтобы такая нумерация переменных всег-
да имела место. Для этого только требуется, чтобы порядок, в ко-
тором имена переменных впервые появляются в последовательности
команд, совпадал с порядком мест, отведенных в векторах для соот-
ветствующих ячеек Fi и Li. В нашем примере переменная V1 должна
быть определена до переменной V2 и т.д.
При просмотре интервалов в порядке возрастания значений Fi
первая переменная помещается в ячейку T1. Для каждого очередного
интервала (Fj,Lj) исследуются АКТИВНЫЕ интервалы, для которых па-
мять уже распределена, с тем чтобы выяснить, существует ли такой
интервал (Fi,Li), что Li<Fj. Если такой интервал существует, то
переменная Vj помещается в ту же ячейку памяти, что и переменная
Vi, а интервал (Fi,Li) отмечается как НЕАКТИВНЫЙ. Таким образом,
на каждом этапе активные интервалы определяют текущие переменные,
которые размещены в ячейках памяти, а также определяют моменты,
когда эти ячейки освобождаются. Если не существует активного ин-
тервала со значением Li<Fj, то нужно взять из стека новую ячейку
и отвести ее для Vj.
В нашем примере для V1 была бы отведена ячейка T1. Так как
L1>F2, то для V2 нужна новая ячейка, и поэтому для V2 была бы от-
ведена ячейка T2. С другой стороны, L2<F3, так что можно помес-
тить V3 в ту же ячейку памяти, что и V2 (т.е. в ячейку T2).
Интервал для V2 теперь отмечается как неактивный. Так как L1<F4,
то переменная V4 тоже помещается в ячейку T1.
Похожие работы
... работы. В ходе работы над дипломным проектом разработан транслятор. Проблема создания такого транслятора является очень актуальной, т.к. многим пользователям САПР необходимо доступ к технической документацию, которую удобнее хранить на удаленных серверах в формате HTML. Поэтому степень положительного эффекта от выполнения дипломного проекта научно-исследовательского характера 1=6.5. В ...

... направления, активно развиваемого сейчас в разных коллективах и странах. Отталкиваясь от трансформационной модели смешанных вычислений и от своих работ в области трансляции и оптимизации программ, Ершов определяет концепцию трансформационной машины. Трансформационная машина есть абстрактное вычислительное устройство, выполняющее программы в некотором "сверхязыке", действиями которого являются ...
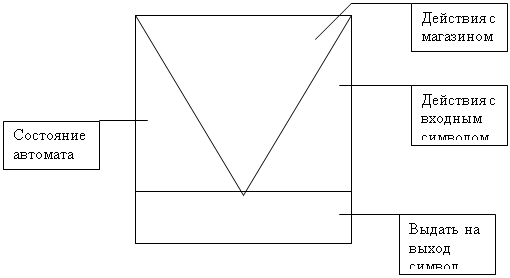
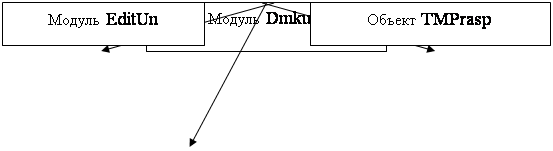
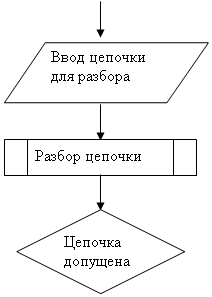
... 166, 16 Mb RAM, Windows 95 Вывод В ходе разработки курсового проекта я ближе ознакомился с теорией МП- трансляторов, научился писать программы - конструкторы для построения МП – транслятора по его параметрам с последующей проверкой задаваемых цепочек, закрепил знания по системному программированию. Разрабатывая программу, я научился применять знания дискретной математике, что облегчает ...
... позволяет связывать твёрдотельные модели, сборки или чертежи, созданные с помощью SolidWorks 97, с файлами других приложений, что значительно расширяет возможности автоматизации процесса проектирования. С помощью технологии OLE можно использовать информацию, полученную в других приложениях Windows, для управления моделями и чертежами SolidWorks. Например, размеры модели могут быть рассчитаны в ...
0 комментариев