Семестр: Отладка разработанного ПО и оформление протоко-
В строке ...SiSj... символы Si и Sj входят в одну и ту
В множество L(U) самых левых символов нетерминального
Пусть между некоторыми двумя символами Si и Sj сущес-
I i 1
Не предусмотрен выход при выполнении условия R > R , так как
Потом повторяется п. 5
Если выполнение шага 4 пpиведет к тому, что значения всех
Перевод инфиксной записи в польскую. Всякий раз, когда в
Когда редуцируется основа XY..Z, тетрады для всех нетер-
Опреанды и операторы
Если сканируемый символ - унарный оператор, то он приме-
А * В + С * D => *, A, B, T1 ┐ тетрады располагаются в
Устраняет недостатки программы,вызванные небрежностью или
Проверяется
непртиворечивость типов получателя и ис-
ДИСПЛЕЙ
Выделение памяти под рамку в процессе трансляции
ОРГАНИЗАЦИЯ ПАМЯТИ ВО ВРЕМЯ ТРАНСЛЯЦИИ
Алгоритм Биледи
Возможные параметры описания переменных и процедур
Навигация
Когда редуцируется основа XY..Z, тетрады для всех нетер-
Проектирование трансляторов
319724
знака
0
таблиц
0
изображений
1. Когда редуцируется основа XY..Z, тетрады для всех нетер-
миналов, которые есть в основе, уже сгенерированы. Чтобы вста-
вить между ними дополнительные тетрады, следует изменить синтак-
сис в соответствии с требуемой семантикой.
2. Показано, как используется семантика, связанная с симво-
лом, для запоминания информации, которая потребуется позже. Оче-
видно, что можно допустить любое количество вложенных друг в дру-
га условных операторов, если на некоторых стадиях разбора иметь
произвольное число символов <условие>. С каждым из них будет свя-
зано свое <условие>.JUMP значение в семантическом стеке. Стеко-
вый механизм обеспечивает автоматическое сохранение каждой такой
компоненты отдельно.
Метки и переходы
Метка I определяется следущим образом:
<инстр1>::=I:<инстр2>,где
I - нетерминал, обозначающий идентификатор.
Метке I нужно присвоить адрес начала <инстр2>. Чтобы это
можно было сделать, изменим синтаксис таким образом:
<инстр1>::=<опред.метки><инстр2>
<опред.метки>::=I:
Имея ввиду, что в программе ссылаться на метку можно раньше,
чем она определялась, составим следущую семантическую программу:
<опред.метки>::=I;
LOOKUPDEC(I.NAME,P);- поиск описания метки с именем NAME среди иден-
IF P=0 THEN тификаторов. Если его нет(возвращается Р=0),то
BEGIN занести новый элемент с именем NAME в ST.
INSERT(I.NAME,P); Присвоить ему тип LABEL.
P.TYPE:=LABEL;
END
ELSE BEGIN
CHECKTYPE(P,LABEL); Cравнивает тип в ST (P.TYPE) с типом LABEL
IF P.DECLARED=1 THEN Проверяет не повторное ли это определение
ERROR (3) Печать ошибки
END
P.DECLARED:=1; Если нет, то установить признак метка опре-
P.ADRESS:=NEXTQUAD; делена и занести значение в поле ADRESS
Замечание:
1.сли Р-указатель на элемент ST, то для ссылки на его атрибуты
достаточно написать P.ADRESS и т.д. 2.Используем следущие атри-
буты(поля ST):
-TYPE (0=UNSIGNED;1=REAL;2=INT;3=BOOLEAN;4=LABEL)
-TYPE1 (1=простая перем.,2=имя массива,3=перем. с индексом)
-TEMPORARY (1=временная перем.,0-нет)
-DECLARED (0=неопределена,1=определена)
-ADBEWS Номер помеченной тетрады или адрес другого элемента ST
-NUMBER Размерность массива
Т.к. правило <инстр1>::=<опред.метки><инстр2> редуцируется
после генерации тетрад <инстр2>, то с ним не связывается никакой
дополнительной семантики ZB: инструкция GOTO в Фортране ис-
пользует подпрограмму просмотра всей ST (LOOKUP) ,т.к. метки ин-
струкций не должны повторяться.
<инстр>::=GOTO I
LOOKUP(I.NAME,P);
IF P=0 THEN
BEGIN INSERT(I.NAME,P);
P.TYPE:=LABEL;
P.DECLARED:=0;
END
ELSE CHECKTYPE(P,LABEL);
ENTER(BRL,P,0,0);
Подпрограмма CHECKTYPE(P,LABEL) сравнивает тип элемента ST,
на который указывает P с LABEL. В случае несовпадения печатается
сообщение об ошибке и ABORT.
3.Переменные и выражения
<пер>::=I|I(<список выр>)
<список выр>::=выр|<списоквыр>,<выр>
<пер>:=I -тетрад не генерирует
LOOKUP(I.NAME,P); поиск идентификатора
IF P=0 THEN ERROR(4);
<пер>.ENTRY:=P; связать с <пер> адрес найденного в ST элемента
В фортране если Р=0 нужно с помощью процедуры INSERT внести
идентифика тор в ST и установить TYPE равнымREAL или INT в зави-
симости от первой буквы идентификатора.
При обработке переменной с индексом I (<список выр>) необхо-
димо:
-сформировать тетрады для вычисления всех индексных выражений;
-вычислить адрес элемента массива, используя известный нам ме-
тод.
Чтобы вычислить VARPART необходимо преобразовать синтаксис
<инд>::=I(<выр>|<инд>,<выр> <пер>::=<инд>)
Программа для <инд>::=I(<выр> должна найти идентификатор
массива, сгенерировать тетрады для VARPART:=<выр> и связать с
<инд> адрес элемента ST для d1. <инд>::=I(<выр> LOOKUP(I.NAME,P);
-поиск идентификатора IF P=0 OR P.TYPE !=2 -он должен быть в ST и
иметь тип ARRAY.
THEN ERROR(5)
<инд>.COUNT:=P.NUMBER-1;-подсчет количества индексов
<инд>.ARR:=P; -запомнить адрес описателя массива
<инд>.ENTRY:=P+1; -занести в ENTRY адрес элемента ST для d1
GENERATETEMP(P); -генерация временной перем. типа INT для VARPART
P.TYPE:=INTEGER; -запомнить ее адрес
<инд>.ENTRY2:=P; -генерация тетрад для преобразования типа, если
CONVERTRI(<выр>.ENTRY); они нужны
P:=<выр>.ENTRY;
ENTER(:=,P,,<инд>.ENTRY2); -генерация тетрады занесения первого
индекса в VARPART
Подпрограмма GENERATETEMP(P) заносит в ST элемент для вре-
менной переменной, а адрес этого нового элемента возвращает в P.
Подпрограмма CONVERTRI(P)проверяет тип P-го элемента ST. Если тип
- INT, то ничего не делается, если REAL, то с помощью
GENERATETEMP заводится новая временная переменная типа INT и ге-
нерируется CVRI-тетрада для преобразования заданной переменной в
тип INT и занесения результата в новую временную переменную. Ука-
затель на временную переменную в ST остается в P. Если тип тип
Р-го элемента не INT и не REAL, то выдается сообщение об ошибке.
Перечислим семантическую информацию (в стеках), связанную с
<инд>:
1.<инд>.ENTRY -адрес элемента ST для d1(для di,если сгенери-
рован код i-го индексного выражения)
2.<инд>.ENTRY2 -адрес элемента ST для VARPART
3.<инд>.COUNT -[размерность - i], если сгенерирован код для
i-го индексного выражения
4.<инд>.ARR -адрес описателя имени массива в ST
Теперь для правила <инд1>::=<инд2>,<выр> надо сгенерировать
код, реализующий формулу VARPART:=VARPART*d1+<выр>, если это
второе по счету индексное выражение.
<инд1>::=<инд2>,<выр>
<инд1>.COUNT:=<инд2>.COUNT-1; -подсчет индексов
<инд1>.ARR:=<инд2>.ARR; -эапомнить тип элемента
<инд1>.ENTRY:=<инд2>.ENTRY+1;-в <инд1>.ENTRY занесли ук-ль на эл-тST для di
P1:=<инд2>.ENTRY2; -в P1 и в ENTRY2 адреса элемента ST для VARPART
<инд1>.ENTRY2:=P1;
ENTER(*,P1,<инд>.ENTRY,P1); -генерация тетрады VARPART=VARPART*di
P:=<выр>.ENTRY; -генерация тетрад преобразования R->I(если надо)
ENTER(+,P!,P,P!); -генерация тетрады VARPART=VARPART+индекс
Заметим, что мы всегда имеем дело не с самим выражением, а с
указателем на элемент ST, описывающий результат вычисления этого
выражения. Для правила <пер>::=<инд>) надо проверить (при компи-
ляции) количество индексных выражений и построить элемент STс
описанием элемента массива.
<пер>::=<инд>)
IF <инд>.COUNT!=0
THEN ERROR(6);
GENERATETEMP(P); -генерирование временной переменной для описателя
P.TYPE1%=3; элемента массива
P.TYPE:=<инд>.ARR.TYPE; -занести тип1,адресс эл-та ST дляVARPART,
P.ADRESS:=<инд>.ENTRY2; адрес эл-та ST, содержащего имя массива
P.NUMBER:=<инд>.ARR.NUMBER;
Трансляция описаний массивов
1) В польской записи описание массива
ARRAY A [L1:U1,...Ln:Un] можно представить в виде
L1U1...LnUn A ADEC
2) Для тетрад в виде
BOUNDS L1,U1
...
BOUNDS Ln,Un
ADEC A
Операция ADEC выполняет при семантической обработке следу-
щие действия:
-заносит запись о каждом массиве в ST;
-выделяет для каждого массива две ячейки:одну для хранеия
адреса начала массива, другую - для хранения адреса допвектора;
-формирует в обьектной программе (при генерации кода) коман-
ды, обеспечивающие перед входом в блок:
-вычисление компонент допвектора;
-вычисление адреса хранения массива;
-вычисление адреса хранения допвектора;
-занесение этих адресов в соответствующие ячейки.
Для массивов с постоянными границами компоненты допвектора
вычисляются в ходе трансляции и помещаются среди констант. Чтобы
отличить переменные граничные пары от постоянных нужно ввести до-
полнительный анализ операндов ADEC, являющихся граничными парами.
Допвектора могут располагаться вслед за парой ячеек, выделенной
последнему массиву или среди констант(для массива с постоянными
границами.
ЛЕКЦИЯ 12
СТРУКТУРЫ ДАННЫХ И ОРГАНИЗАЦИЯ ПАМЯТИ
Некоторые применяемые языки требуют динамического распреде-
ления памяти; блоки оперативной памяти при этом выделяются произ-
вольно, а затем освобождаются. Область данных - это блок ОП, вы-
деленный для данных.
Области данных могут принадлежать также к статическому клас-
су. Статическая область данных имеет постоянное число ячеек, а
динамическая область данных не всегда присутствует во время счета.
Если вызов процедуры происходит рекурсивно, то существует
несколько областей данных в ОП, каждая для отдельного вызова про-
цедуры.
Если компилятор знает все характеристики переменных во вре-
мени, то он может сгенерировать полностью команды обращеиня к пе-
ременным, основываясь на этих характеристиках.
Память выделяется компилятором не только для переменных, но
и для описателей, содержащих атрибуты, определяемые во время сче-
та. Этот описатель заполняется и изменяется во время счета. Типы
данных исходной программы должны быть отображены на типы данных
машины. Целые переменные содержатся обычно в одном слове.
Информационные таблицы
При анализе программы из описаний, заголовков процедур, цик-
лов и т.д. извлекается информация и сохраняется для последующего
использования. Эта информация обнаруживается в отдельных точках
программы и организуется так, чтобы к ней можно было обратиться
из любой части компилятора. В каждом компиляторе в той или иной
форме используется таблица символов. Это таблица идентификаторов,
встречающихся в программе, вместе с их атрибутами.
При разборке компилятора невозможно определить вид и содер-
жание информации, которую следует собирать, до тех пор, пока не
будут достаточно обстоятельно продуманы команды обьектной прог-
раммы для каждой инструкции исходной программы и сама синтезирую-
щая часть компилятора.
При проверке правильности семантики и генерации кода тре-
буются знания характеристики идентификатора. Эти характеристики
выясняются из описания и накапливаются в таблице символов. Наип-
ростейшая таблица символов для каждого элемента имеет поле аргу-
мента и значения. Аргументами таблицы являются символы или иден-
тификаторы, а значениями - их характеристики. Так как число ли-
тер в идентификаторе непостоянно, в аргументе часто помещают сим-
волы вместо самого идентификатора. Это позволяет сохранить фикси-
рованный размер аргумента. Идентификаторы хранятся в специальном
списке строк.
При проходе исходной программы через компилятор при встрече
конструкции описания происходит запись идентификатора исходной
программы в таблицу символов вместе с его атрибутами. В результа-
те дальнейшего чтения исходной программы, в компиляторе при на-
хождении любого идентификатора программа обращается к таблице
символов и ищет в ней данный идентификатор. Если идентификатор не
обнаружен, то выдается сообщение, что данный идентификатор не оп-
ределен. Если же он обнаружен, то производится сравнение данного
идентификатора с записанным в таблице символов и производятся
необходимые преобразования.
При работе с таблицей символов нужно разработать правила ор-
ганизации и обращения к таблице символов. Таблицы символов могут
быть как упорядоченными, так и неупорядоченными.
При упорядоченном списке элементов наиболее результативным
является бинарный или логарифмический поиск. Иногда один и тот же
идентификатор может быть описан и использован много раз в различ-
ных блоках и процедурах, и каждое такое описание должно быть
единственным. Соответственно нужно разделять таблицу симводов.
При этом устанавливается правило нахождения соответствующего
идентификатора. Оно состоит в следующем: сначала просматривается
текущий блок, затем обьемлющий блок и т.д., до тех пор, пока не
будет найдено описание данного идентификатора.
При осуществлении поиска все элементы таблицы хранятся для
каждого блока в смежных ячейках и используется список блоков.
Информация об идентификаторе хранится в той части таблицы,
которую мы определили как "значение".
Таблица символов состоит из 5-ти различных списков:
- список меток;
- список арифметических констант;
- список имен общих блоков,имен подпрограмм и имен перемен-
ных;
- список общих блоков;
- список имен подпрограмм.
Элементы всех этих списков помещаются в одной и той же таб-
лице; первые два байта каждого элемента используются для ссылки
на следующий элемент в том же списке.
ЛЕКЦИЯ 13
ВНУТРЕННИЕ ФОРМЫ ИСХОДНОЙ ПРОГРАММЫ
Ввиду сложности реальных языков программирования и предъяв-
ления повышенных требований к эффективности самого процесса ком-
пиляции и к готовым программам, разработчики вынуждены проектиро-
вать многопроходные компиляторы. При этом для связи между прохо-
дами, необходимы внутренние (промежуточные) формы исходной прог-
раммы. В большинстве внутренних форм, операторы располагаются в
том порядке, в котором они должны выполняться, что означает пос-
ледующий анализ и итерацию об'ектного кода. (Эти внутренние пред-
ставления можно использовать для интерпретации).
Внутренняя форма является более развернутым представлением
исходной программы, к которой предъявлялись требования лаконич-
ности и краткости. Более подробное представление обеспечивает
проведение глубокого анализа и оптимизации программ.
Как правило, в одном компиляторе для разных синтаксических
единиц (выражений, условных операторов, операторов присваивания и
т.д.) используются разные, наиболее подходящие с точки зрения
разработчика, внутренние формы.
Похожие работы
... работы. В ходе работы над дипломным проектом разработан транслятор. Проблема создания такого транслятора является очень актуальной, т.к. многим пользователям САПР необходимо доступ к технической документацию, которую удобнее хранить на удаленных серверах в формате HTML. Поэтому степень положительного эффекта от выполнения дипломного проекта научно-исследовательского характера 1=6.5. В ...

... направления, активно развиваемого сейчас в разных коллективах и странах. Отталкиваясь от трансформационной модели смешанных вычислений и от своих работ в области трансляции и оптимизации программ, Ершов определяет концепцию трансформационной машины. Трансформационная машина есть абстрактное вычислительное устройство, выполняющее программы в некотором "сверхязыке", действиями которого являются ...
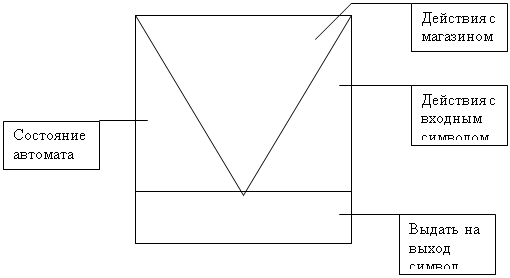
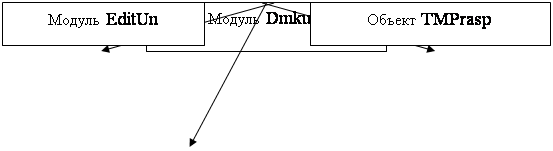
... 166, 16 Mb RAM, Windows 95 Вывод В ходе разработки курсового проекта я ближе ознакомился с теорией МП- трансляторов, научился писать программы - конструкторы для построения МП – транслятора по его параметрам с последующей проверкой задаваемых цепочек, закрепил знания по системному программированию. Разрабатывая программу, я научился применять знания дискретной математике, что облегчает ...
... позволяет связывать твёрдотельные модели, сборки или чертежи, созданные с помощью SolidWorks 97, с файлами других приложений, что значительно расширяет возможности автоматизации процесса проектирования. С помощью технологии OLE можно использовать информацию, полученную в других приложениях Windows, для управления моделями и чертежами SolidWorks. Например, размеры модели могут быть рассчитаны в ...
0 комментариев