Семестр: Отладка разработанного ПО и оформление протоко-
В строке ...SiSj... символы Si и Sj входят в одну и ту
В множество L(U) самых левых символов нетерминального
Пусть между некоторыми двумя символами Si и Sj сущес-
I i 1
Не предусмотрен выход при выполнении условия R > R , так как
Потом повторяется п. 5
Если выполнение шага 4 пpиведет к тому, что значения всех
Перевод инфиксной записи в польскую. Всякий раз, когда в
Когда редуцируется основа XY..Z, тетрады для всех нетер-
Опреанды и операторы
Если сканируемый символ - унарный оператор, то он приме-
А * В + С * D => *, A, B, T1 ┐ тетрады располагаются в
Устраняет недостатки программы,вызванные небрежностью или
Проверяется
непртиворечивость типов получателя и ис-
ДИСПЛЕЙ
Выделение памяти под рамку в процессе трансляции
ОРГАНИЗАЦИЯ ПАМЯТИ ВО ВРЕМЯ ТРАНСЛЯЦИИ
Алгоритм Биледи
Возможные параметры описания переменных и процедур
Навигация
Устраняет недостатки программы,вызванные небрежностью или
Проектирование трансляторов
319724
знака
0
таблиц
0
изображений
1. Устраняет недостатки программы,вызванные небрежностью или
низкой квалификацией программиста.
2. Устраняет излишние вычислеия, неизбежно возникающие в
процессе трансляции даже при самом тщательном написании програм-
мы на языке высокого уровня.
Если транслятор производит оптимизацию программы, необходи-
мо делать специальный проход, переводящий программу с исходного
языка на промежуточный.
Оптимизировать программу, уже протранслированную в коды ма-
шины, трудно по трем причинам: во-первых, единицы действия прог-
раммы в кодах команд слишком мелки, что уже само по себе затруд-
няет анализ, во-вторых, при трансляции входной программы в коды
машины возможна потеря имеющейся в ней информации. Например, за-
сылка промежуточных результатов в разные рабочие ячейки памяти
делает практически невозможной идентификацию одинаковых частей
программы; в-третьих из-за нестандартности форматов различных
элементов языка и рекурсивных конструкций, широко применяемых в
текстах программ.
Строго сформулировать требования, предьявляемые к промежу-
точному языку, трудно.
Однако уже из самого обоснования необходимости промежуточно-
го языка видно, что:
а) операторы языка не должны быть слишком мелкими;
б) символы, идентификаторы и числа должны иметь фиксирован-
ный формат;
в) в строении операторов желательно отсутствие рекурсивности;
г) должна сохраняться вся информация, необходимая для опти-
мизации, которая есть во входном языке;
д) язык должен быть приспособлен к выполнению оптимизирую-
щих преобразований и удобен для последующей трансляции в коды вы-
числительной машины.
Требования пп. "г" и "д" показывают, что разработать еди-
ный универсальный промежуточный язык для трансляции с любого язы-
ка программирования в коды любой ВМ трудно.
Помимо программы на промежуточном языке, состоящей из после-
довательности операторов, необходимы следующие таблицы:
1. Таблицы идентификаторов и констант с обычной информацией
о переменных и константах;
2. Таблица блоков, определяющая номера блоков, их границы,
непосредственно предшествующие и следующие блоки, а также любую
информацию о частоте повторения блока;
3. Таблица последовательности операторов, определяющая ли-
нейную последовательность операторов в блоке. Она содержит после-
довательность указателей операторов mi. Эта таблица необходима,
поскольку один указатель может принадлежать нескольким операторам.
Подстановка и устранение идентичных операторов
Подстановка - это замена переменной или mi - идентификатора
результата заданной или вычисленной константой, причем эта заме-
на производится во время трансляции, а не в процессе решения.
Подстановка является полностью внутриблочной процедурой и
выполняется перед устранением излишних команд.
Сдвиг инвариантных операторов
Сильно связанной областью называется такое множество его уз-
лов, что для любых двух вершин x и y (x != y) существует путь из
x в y.
Оператор инвариантен в сильно связанной области, если его
операнды не зависят от места определения переменных в данной об-
ласти.
Будем рассматривать сильно связанные области Ri, обладающие
следующими свойствами:
1) Ri является сильносвязанной областью, состоящей из мно-
жества блоков, каждый из которых предшетвует сам себе и следует
сам за собой внутри этого множества;
2) Ri != Rj;
3) для каждого i<j или Ri Rj = 0, или Ri Rj = Ri, т.е.
Rj Ri.
Как уже отмечалось, сдвиг инвариантного оператора из тела
цикла сокращает время выполнения программы. Особенность рассмат-
риваемого метода заключается в том, что оператор сдвигается из
блока во всех случаях, когда он может быть сдвинут независимо от
того, находится он внутри цикла или нет. Ухудшение программы
произойти не может.
Замена переменных в операторах условного перехода
В результате сокращения глубины операции рекурсивная прог-
раммная переменая , являющаяся управляющей в операторе условного
перехода, может быть заменена в нем генерируемой переменной t(mi-
идентификаторов).
Процедура замены переменной в операторе условного перехода
заключается в следующем. После сокращения глубины операции во
всех операторах, использующих рекурсивно определяемые програм-
мные переменные I, находят операторы условного перехода, в кото-
рых I является управляющей переменной.
Определение не используется и может быть устранено, если ре-
зультат определения не является операндом ни одного оператора ре-
курсивного определения и результат этого последнего не ис-
пользуется ни в каком другом операторе.
Как только определение устранено, все вычисления, от кото-
рых оно зависит, если они нигде больше не используются, могут
быть устранены.
Вставка псевдоблока
В процессе оптимизации операторы, сдвигаемые из блоков, со-
бираются в псевдоблок. После оптимизации области Rk операторы
псевдоблока должны быть вставлены в программу так, чтобы они вы-
полнялись до (после) выполнения операторов области Ri.
Для того, чтобы операторы псевдоблока выполнялись на всех
входных (выходых) путях области Rk, они должны вставляться во все
блоки, непосредственно предшествующие (следующие) области либо из
псевдоблока должен быть сформирован блок ,который будет вставлен
на все входные (выходные) пути области Rk.
ЛЕКЦИЯ 15
ОПТИМИЗАЦИЯ ПРОГРАММЫ (ПРОДОЛЖЕНИЕ)
Синтез (генерация) выходного текста
Промежуточный код
Промежуточные коды (или обьектные языки) можно проектиро-
вать на различных уровнях. Так, иногда промежуточный код полу-
чают, просто разбивая сложные структуры языка на более удобные
для обращения элементы. Однако можно в качестве промежуточного
кода ( в этом случае его чаще называют обьектным языком ) ис-
пользовать какой-либо обобщенный машинный код, который затем
транслируется в код реальной машины. Получение промежуточного ко-
да возможно до или после распределения памяти. Если это происхо-
дит до распределения памяти, то операндами могут служить иденти-
фикаторы программы ( или их представления после лексического ана-
лиза ) и присваиваемые компилятором идентификаторы, причем в пос-
леднем варианте используются адреса времени прогона.
Одним из видов промежуточного кода являются четверки.
Например, выражение (-a+b)*(c+d) можно представить как чет-
верки следующим образом: -a = 1
1+b = 2
c+d = 3
2*3 = 4
Здесь целые числа соответствуют идентификаторам, присва-
иваемым компилятором. Четверки можно считать промежуточным
кодом высокого уровня. Такой код часто называют трехадресным
- два адреса для операндов ( кроме тех случаев, когда имеют
место унарные операции ) и один для результата. Другой вари-
ант кода - тройки ( двухадресный код ). Каждая тройка состоит
из двух адресов операндов и знака операции. Если сам операнд
является тройкой, то используется ее позиция, что исключает
необходимость иметь в каждой тройке адрес результата.
Выражение a+b+c*d можно представить в виде четверок:
a+b = 1
c*d = 2
1+2 = 3
и в виде троек:
a+b
c*d
1+2
Тройки компактнее четверок, но если в компиляторе есть
фаза оптимизации, которая пресылает операторы промежуточного
кода, их применение затруднительно. Наилучшее решение этой
проблемы - косвенные тройки, т.е. операнд, ссылающийся на ра-
нее вычисленную тройку, должен указывать на элемент таблицы
указателей на тройки, а не на саму эту тройку.
Как тройки, так и четверки можно распространить не толь-
ко на выражения, но и на другие конструкции языка. Например,
присваивание a := b в виде четверки представляется как
a := b = 1
a в виде тройки - как a := b
Аналогично условное предложение
IF a THEN b ELSE c FI
можно считать выражением с тремя операндами, которому требу-
ются четыре адреса как четверке и три - как тройке.
Не менее популярны в качестве промежуточного кода пре-
фиксная и постфиксная нотации. В префиксной нотации каждый
знак операции появляется перед своими опреандами, а в пост-
фиксной - после. В этом и состоит их отличие от обычной ( ин-
фиксной ) нотации, в которой обозначения двухместных операций
появляются между своими операндами. Например, инфиксное выра-
жение a+b в префиксной нотации примет вид + ab , а в пост-
фиксной - вид ab +.
Префиксная нотация известна также как польская запись, а
постфиксная - как обратная польская запись. С помощью этих
нотаций можно записывать более сложные выражения. Например,
выражение (a+b)*(c+d) в префиксной форме записывается следую-
щим образом: *+ab+cd
а в постфиксной так: ab+cd+*
Каждый знак опреации в префиксной нотации ставится не-
посредственно перед своими операндами, а в постфиксной после
них.
В префиксной и постфиксной нотациях скобки уже не требу-
ются, так здесь никогда не возникает сомнений относительно
того, какие операнды принадлежат к тем или иным знакам опера-
ций. В этих нотациях не существует приоритета знаков опера-
ций, хотя при преобразовании инфиксных выражений в префиксные
или постфиксные их приоритет, несомненно, нужно учитывать.
Перегруппировку в результате преобразования
(a+b)*(c+d)
в
ab+cd+*
можно осуществить с помощью стека. Алгоритм такого преобразо-
вания хорошо известен. Это преобразование можно выполнить
также на основании грамматики инфиксных выражений. В данном
случае оно сведется к трем действиям:
1) напечатать идентификатор, когда он встретится при
чтении инфиксного выражения слева направо;
2) поместить в стек знак операции, когда он встретится;
3) когда встретится конец выражения ( или подвыражения ),
выдать на печать тот знак операций, который находится в вер-
шине стека.
Этот метод подобен методу, который применяется для полу-
чения четверок. Префиксные и постфиксные выражения можно так-
же получить из представления выражения в виде бинарного дере-
ва. Чтобы получить представление префиксного выражения, дере-
во обходят сверху в порядке, определенном Кнутом:
посещение корня;
обход левого поддерева сверху;
обход правого поддерева сверху,
что дает
+*+abcd
Для получения постфиксного представления дерево обходят
снизу. По Кнуту это выглядит так:
обход левого поддерева снизу;
обход правого поддерева снизу;
посещение корня.
В результате имеем: ab+c*d+
Далее будем рассуждать в терминах промежуточного языка (
или обьектного ), состоящего из команд вида
тип-команды параметры
Тип-команды может быть, например, вызовом стандартного
обозначения операции, тогда параметрами могут быть имя знака
операции, адреса опреандов и адрес результата. Например,
STANDOP II+,A,B,C
Здесь II+ обозначает сложение двух целых чисел, а A, B,
C cлужат во время прогона адресами двух операндов и результа-
та. Для того чтобы в промежуточном коде можно было воспользо-
ваться адресами во время прогона, распределение памяти к это-
му времени должно быть уже закончено. При распределении памя-
ти необходимо знать, какой обьем памяти занимает целое, ве-
щественное и другие значения на той машине, для которой выда-
ется обьектный код. Это означает, что промежуточный код не
является в строгом смысле интерфецсом между не зависящей и
зависящей от машины частями компилятора. Тем не менее если
речь идет о переводе фронтальной части компилятора ( т.е.
части, транслирующей исходный код в промежуточный ) с одной
машины на другую, то единственное, что здесь может потребо-
ваться, - это изменение нескольких констант.
Промежуточный код пишется на относительно низком уровне.
Он аналогичен коду, использованному для реализации Алгола 68.
Обычно выдвигается условие, чтобы промежуточный код отражал
структуру реализуемого языка.
Промежуточный код напоминает префиксную нотацию в том
смысле, что знак операции всегда предшествует своим операн-
дам. Но он имеет менее общий характер, так как сами операнды
не могут быть префиксными выражениями. При получении промежу-
точного кода для хранения адресов операндов до тех пор, пока
не будет напечатан знак операции, используется стек. Посколь-
ку знак операции можно установит ( во многих языках ) лишь
после того, как станут известны его опреанды, стек служит
также для хранения каждого знака операции на то время, пока
не определены оба операнда.
Адрес на время прогона обычно соотносится со стеком, и
каждый такой адрес можно представить тройкой вида
( тип-адреса, номер блока, смещение ).
Тип-адреса может быть прямым или косвенным ( т.е. адрес
может содержать значение или указатель на значение ) и ссы-
латься на рабочий стек или стек идентификаторов. Он может
быть также литералом или константой. Номер блока позволяет
найти номер уровня блока в таблице блоков, что обеспечивает
доступ к конкретной рамке стека через диспдей. В сдучае лите-
рала или константы номер блока не используется. Смещение (
для адреса стека ) показывает смещение значения конкретной
рамки по отношению к началу стека идентификаторов или рабоче-
го стека. Если тип-адрес представляет собой литерал, то сме-
щение выражается самим значением, а если тип-адреса - конс-
танта, то смещение нужно найти в таблице констант по заданно-
му им адресу. В том случае, когда в каждой рамке стека рабо-
чий стек помещается сразу же над стеком идентификаторов, сме-
щения адресов рабочего стека по отношению к началу рамки мож-
но рассчитывать, как только станет известным размер стека
идентификаторов для конкретной рамки ( т.е. во время прохода,
следующего за проходом, при котором происходит распределение
памяти ).
Адреса во время прогона для идентификаторов определяются
в процессе распределения памяти и хранятся в таблице символов
вместе с информацией о типе и т.п.
Кроме рассмотренных, существуют и другие команды проме-
жуточного кода ( ICI по Бранкару ):
SETLABEL L1
для установки метки и
ASSIGN type, add1, add2
для присваивания. Тип необходим как параметр, чтобы опреде-
лить размер значения, переписываемого из add1 в add2. В Алго-
ле 68 может потребоваться просмотр типа ( вида ) при трансля-
ции этой команды в фактический код машины, если значения бу-
дут содержать динамические части, поэтому во время генерации
машинного кода нужна таблица видов.
Структуры данных для генерации кода
Как упоминалось выше, для хранения адресов операндов на
то время, пока их нельзя будет выдать как параметры ICI, не-
обходим стек значений. В этом стеке, который Бранкар называет
нижним стеком, можно хранить также и другую информацию. Нап-
ример, значение может быть связано со своими
а) адресом времени прогона;
б) типом;
в) областью действия,
помимо той информации, которая имеет значение для диагности-
ки. Это - статическая информация, так как ( по крайней мере,
для большинства языков ) ее можно получить во время компиля-
ции. Так, при компиляции может быть известно если не факти-
ческое значение, то во всяком случае адрес целого числа.
При трансляции А + В первыми помещаются в нижний стек
статические свойства А. Любой элемент нижнего стека можно
представить в виде структуры, имеющей поле для каждой из сво-
их статических характеристик. В случае идентификаторов стати-
ческие характеристики находятся из таблицы символов. Затем в
стек знаков операции помещается знак операции +, и в нижний
стек добавляются статические характеристики В. Знак операции
берется из стека знаков операций, а его два операнда - из
нижнего стека. Типыоперандов используются для идентификации
знака операции, после чего генерируется код. И наконец, в
нижний стек помещаются статические характеристики результата.
Этот процесс можно распространить и на более сложные вы-
ражения, например нп те, которые генерируются грамматикой с
правилами
EXP -> TERM |
EXP + TERM |
EXP - TERM
TERM -> FACT |
TERM * FACT |
TERM / FACT
FACT -> constant |
identifier |
(EXP)
После чтения идентификатора или константы, знака опера-
ции и второго операнда необходимо выполнить следующие дейс-
твия:
А1. Послечтения идентификатора или константы ( т.е. лис-
та синтаксического дерева ) поместить в нижний стек
соответствующие статические характеристики.
А2. После чтения оператора поместить символ операции в
стек знаков операций.
А3. После чтения правого операнда ( который может быть
выражением ) извлечь из стеков знак операции и его два опе-
ранда, генерировать соответствующий код, так как знак опера-
ции идентифицирован, и поместить в стек статические характе-
ристики результата. Тип результата становится известным во
время идентификации знака операции, например сложение двух
целых чисел всегда дает целое число.
При включении в грамматику этих действий она примет сле-
дующий вид:
EXP -> TERM
EXP+<A2>TERM<A3>
EXP-<A2>TERM<A3>
TERM -> FACT
TERM*<A2>FACT<A3>
TERM/<A2>FACT<A3>
FACT -> constant<A1>
identifier<A1>
(EXP)
Нижний стек частично используется для передачи информа-
ции о типе вверх по синтаксическому дереву. Рассмотрим син-
таксическое дерево, соответствующее выражению:
+
^
/ \
/ \
/ \
* / \ *
/\ /\
/ \ / \
/ \ / \
a b x y
a * b + x * y
Если значения a и b имеют тип целого, а х и у - тип ве-
щественного значения, компилятор может заключить,
воспользовавшись информацией нижнего стека, что "+" в вершине
дерева представляет сложение целого и вещественного значений.
Мы можем переписать выражение, расставив действия А1, А2 и А3
в том порядке, в каком они будут вызываться при трансляции
этого выражения:
а<A1>*<A2>b<A1><A3>+<A2>x<A1>*<A2>y<A1><A3><A3>
Действие А3 соответствует применению знака операции. Из
изложенного выше вытекает, что каждый вызов А3 соответствует
тому месту, где появился бы знак операции в постфиксной фор-
ме. Стек знаков опреаций, по существу, служит для формирова-
ния постфиксной нотации. Поэтому последовательность действий
при трансляции данного выражения должна быть следующей:
А1. Поместить статические характеристики а в нижний
стек.
А2. Поместить знак "*" в стек знаков операций.
А1. Поместить статические характеристики b в нижний
стек.
А3. Извлечь статические характеристики a и b из ниж-
него стека и знак "*" из стека знаков операций, генерировать
код для умножения двух целых чисел, поместить статические ха-
рактеристики результата в нижний стек; тип результата - целый.
А2. Поместить знак "+" в стек знаков операций.
А1. Поместить статические характеристики х в нижний
стек.
А2. Поместить знак "*" в стек знаков операций.
А1. Поместить статические характеристики у в нижний
стек.
А3. Извлечь статические характеристики х и у из ниж-
него стека и знак "*" из стека знаков операций, генерировать
код для умножения двух целых чисел, поместить статические ха-
рактеристики результата в нижний стек; тип результата - ве-
щественный.
А3. Извлечь два верхних элемента из нижнего стека и знак
"+" из стека знаков операций, генерировать код для сложения
целого и вещественного значений, поместить статические харак-
теристики результата в нижний стек; тип результата - вещест-
венный.
Действия А1, А2, А3 и вышеприведенную грамматику легко
расширить, что позволит использовать
а) большее число уровней приоритета для знаков операций;
б) унарные знаки операций.
Другие случаи употребления нижнего стека рассматриваются
в следующем разделе.
Нижний стек обеспечивает передачу информации вверх по
синтаксическому дереву. Для передачи же информации вниз по
дереву применяется так называемый верхний стек. Значение в
него помещается всякий раз, когда во время генерации кода
происходит вход в такую конструкцию, как присваивание или
описание идентификатора. При выходе из этой конструкции зна-
чение из стека удаляется. Следовательно, генератор кода может
заключить, например, что компилируемое выражение находится
справа от знака присваивания; эта информация способствует оп-
тимизации.
Еще одной структурой данных, которая требуется во время
генерации кода, является таблица блоков.
╔══════════╦═══════════╦═══════════════════╦═════════════════╗
║ Блок ║ Уровень ║ Размер стека ║ Размер рабочего ║
║ ║ блока ║ идентификаторов ║ ║
╠══════════╬═══════════╬═══════════════════╬═════════════════╣
║ 1 ║ 1 ║ 14 ║ 16 ║
║ 2 ║ 2 ║ 12 ║ 11 ║
║ 3 ║ 2 ║ 21 ║ 13 ║
║ 4 ║ 3 ║ 4 ║ 9 ║
║ 5 ║ 2 ║ 6 ║ 12 ║
╚══════════╩═══════════╩═══════════════════╩═════════════════╝
В этой таблице есть запись для каждого блока программы,
и эту запись можно рассматривать как структуру, имеющуюю по-
ля, которые соответствуют номеру уровня блока, размеру стати-
ческого стека идентификаторов, размеру статического рабочего
стека и т.д. Такую таблицу можно заполнять во время прохода,
генерирующего код, и с ее помощью в следующем проходе вычис-
лять смещения адресов рабочего стека по отношению к текущей
рамке стека.
Таким образом, во время генерации кода используются сле-
дующие основные структуры данных: нижний стек, верхний стек,
стек знаков операций, таблица блоков и, кроме того, таблица
видов и таблица символов из предыдущих проходов.
Генерация команд
По существу, на этом этапе происходит перевод внутреннего
представления исходной программы на автокод или на машинный
язык.
Возможны три формы об'ектного кода: абсолютные команды, по-
мещенные в фиксированные ячейки; программа на автокоде; програма
на языке машины, предтавленная образами карт и записанная во
вторичную память.
Рассмотрим выражение (A + B) + (X + Y)
Очевидный способ его вычисления в терминах машинного языка
таков:
1. загрузить А в сумматор;
2. прибавить B к сумматору;
3. записать результат A+B во временную рабочую ячейку;
4. загрузить X в сумматор; 5. прибавить Y к сумматору;
6. прибавить временный результат A+B к X+Y в сумматоре.
Каждому из трех сложений предшествует своя последователь-
ность команд загрузки и записи.
Чтобы построить код генератор хранит некоторую информацию о
том, что будет происходить в период исполнения генерируемого им
кода.
При разработке генератора кода первый шаг заключается в
том, что чтобы определить, как будет организована память машины
в перид исполнения скомпилированной прграммы. Предлагаемое расп-
ределение памяти показано на рисунке
----------------------
! Программа !
----------------------
! Константы !
----------------------
! Подпрограммный !
! стек !
----------------------
! Промежуточные !
! результаты !
----------------------
! Хранимые результаты!
----------------------
! Переменные !
----------------------
Область ПРОГРАММА содержит команды об'ектной программы.
ПОДПРОГРАММНЫЙ СТЕК используется для хранения адресов возврата
подпрограмм. Область ХРАНИМЫЕ РЕЗУЛЬТАТЫ используется для хране-
ния результатов атома ХРАНЕНИЕ в FOR-операторах. В областях
КОНСТАНТЫ и ПЕРЕМЕННЫЕ хранятся соответственно значения констант
и переменных.
Область ВРЕМЕННЫЕ РЕЗУЛЬТАТЫ используется для хранения про-
межуточных результатов.
Генератор кода использует табличные эдементы для хранения
информации о параметрах атомов. Каждый табдичный элемент имеет
поле ВИД, указывающее вид об'екта, описываемого этим элементом,
а также одно или два других поля. Поле ВИД содержит одно из сле-
дующих пяти значений: КОНСТАНТА, ПЕРЕМЕННАЯ, ПРОМЕЖУТОЧНЫЙ РЕ-
ЗУЛЬТАТ, ХРАНИМЫЙ РЕЗУЛЬТАТ или МЕТКА.
Мы предполагаем, что генератор кода содержит процедуру, на-
зываемую ГЕН, которая строит двоичное представление генерируемой
команды. ГЕН вызывается с двумя параметрами: кодом операции и
указателем на табличный элемент, соответствующий полю адреса ге-
нерируемой команды. Процедура ГЕН выполняет следующие действия:
1. Формируется двоичный код, соответствующий первому
параметру процедуры ГЕН.
2. Формируется двоичный код, соответствующий второму
параметру процедуры ГЕН.
3. Двоичный код, образующий сгенерированную команду,
помещается в ячейку, соответствующую текущему зна-
чению СЧЕТКОМ.
4. СЧЕТКОМ увеличивается и сравнивается с ГРАНКОМ.
Здесь СЧЕТКОМ и ГРАНКОМ - переменные периода компиляции.
Генерация кода для некоторых типичных конструктов
Покажем, как генерируеися код для некоторых конструктов,
типичных для языков программирования высокого уровня.
I. Присваивания
В соответствии с терминологией Алгола 68 присвамвание
имеет вид
destination := source
Смысл его состоит в том, что значение, соответствующее
источнику, присваивается значению, которое является адресом
( или именем ), заданным получателем. Например, в
p := x + y
значение "х+у" присваивается р.
Допустим, что статические характеристики источника и по-
лучателя уже находятся в вершине нижнего стека. Опишем дейс-
твия, выполняемые во время компиляции для осуществления прис-
ваивания. Прежде всего из нижнего стека удаляются два верхних
элемента, после чего происходит следующее:
Похожие работы
... работы. В ходе работы над дипломным проектом разработан транслятор. Проблема создания такого транслятора является очень актуальной, т.к. многим пользователям САПР необходимо доступ к технической документацию, которую удобнее хранить на удаленных серверах в формате HTML. Поэтому степень положительного эффекта от выполнения дипломного проекта научно-исследовательского характера 1=6.5. В ...

... направления, активно развиваемого сейчас в разных коллективах и странах. Отталкиваясь от трансформационной модели смешанных вычислений и от своих работ в области трансляции и оптимизации программ, Ершов определяет концепцию трансформационной машины. Трансформационная машина есть абстрактное вычислительное устройство, выполняющее программы в некотором "сверхязыке", действиями которого являются ...
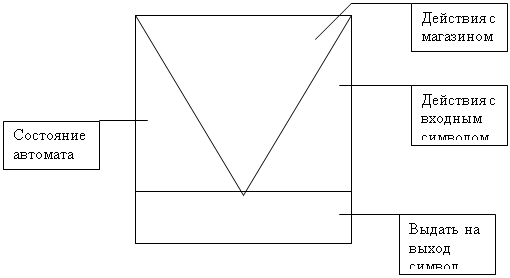
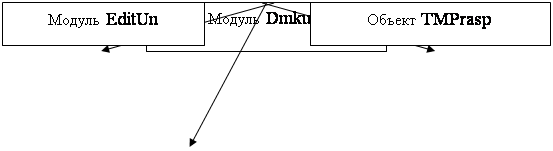
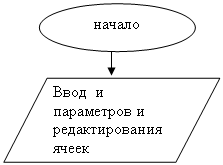
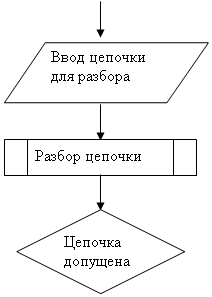
... 166, 16 Mb RAM, Windows 95 Вывод В ходе разработки курсового проекта я ближе ознакомился с теорией МП- трансляторов, научился писать программы - конструкторы для построения МП – транслятора по его параметрам с последующей проверкой задаваемых цепочек, закрепил знания по системному программированию. Разрабатывая программу, я научился применять знания дискретной математике, что облегчает ...
... позволяет связывать твёрдотельные модели, сборки или чертежи, созданные с помощью SolidWorks 97, с файлами других приложений, что значительно расширяет возможности автоматизации процесса проектирования. С помощью технологии OLE можно использовать информацию, полученную в других приложениях Windows, для управления моделями и чертежами SolidWorks. Например, размеры модели могут быть рассчитаны в ...
0 комментариев