Возможности контент-анализа и его появление в советской социологии
Контент-анализ в социально-политических исследованиях
Основные процедуры контент-анализа
Описание процедуры исследования
Построение таблиц отношения
Полевой этап исследования
Описание результатов исследования, построение схем
Выводы и заключение
Навигация
Полевой этап исследования
Контент-анализ как метод конкретных политико-социологических исследований
94363
знака
35
таблиц
3
изображения
1. Полевой этап исследования
Каждое социологическое исследование венчается результатом. Но ему предшествует огромная работа, собственно социологическое «поле» - сбор информации, обработка, и только после этого – написание отчета. Чаще всего именно последняя стадия становится известной широкой научной общественности и лишь отдельные фрагменты предшествующей работы попадают в поле ее зрения. Поэтому, на мой взгляд, необходимо остановиться на столь важном и мало освещаемом этапе социологического исследования контент-аналитика.
Сразу хочу оговориться, что моя работа не требует применения некоторых нижеописываемых методик, поскольку я применяю простую программу для подсчета единиц измерения. А речь пойдет о составлении кода и инструкции к нему. Эти документы разрабатываются в тесном взаимодействии со специалистом, который будет осуществлять обработку полученной информации на ЭВМ. Чем в большей степени построение документа, на котором будет фиксироваться исходная информация, будет соответствовать правилам ввода информации в компьютер, а также правилам ее дальнейшей агрегации, тем меньше затрат потребуется на этой стадии.
После составления кода требуется специальная стадия – проверка кода на соотносительность результатов (reliability). Как правило, эта стадия состоит в том, что исследователь предлагает для анализа по данному коду один и тот же текст нескольким кодировщикам и проверяет, однообразно ли они используют код и насколько сходяться их результаты[31]. Другой вариант проверки – повторно дать закодировать этот же текст нескольким кодировщикам по истечении определенного промежутка времени. Цель в данном случае та же: посмотреть на идентичность анализа, так сказать, во времени и в пространстве.
Все необходимые поправки и изменения, которые еще можно будет предусмотреть в коде и в инструкции к нему, следует делать именно на этой стадии. Здесь же происходит коллективное обсуждение реальной кодировки, оттачиваются примеры, которые должна содержать инструкция. Так, в исследовании российской прессы на предмет ее отношения к лидерам и фракциям Госдумы, инструкция содержала примеры конкретных текстов из реальных газет, содержащих разные оценки: «Пока же преимущество в искусстве ведения судебного спора явно на стороне президентско-правительственной команды. Во-первых, она хорошо подобрана и в ней четко распределены роли. Впереди официальные представители – Сергей Шахрай, Юрий Батурин и Олег Кутафин. Все трое – юристы со степенями, хорошо освоившие приемы публичного спора. И психологическая уравновешенность у них тоже на высоте.»[32]- позитивная оценка С. Шахрая, как лидера определенной фракции.
«Кроме Егора Гайдара, предстоящие выборы могут принести большое разочарование и Жириновскому, и его ЛДПР. Некогда мощнейшей партии сегодня симпатизирует лишь 6,6 процента голосов. Очевидно, имиджу Жириновского не помог пролитый в сражении с Б. Немцовым апельсиновый сок. Да и в целом скандальностью наших людей теперь удивить крайне трудно, хотя тяга к ярким личностям остается.»[33] - негативная оценка Жириновского и его фракции.
Эти примеры приведены здесь неслучайно – установки руководителя исследования здесь недостаточно и некоторые кодировщики оценили второй пример как сбалансированную оценку В. Жириновского.
Вот только начало инструкции к данному исследованию: «Кодировщик читает всю газету целиком, чтобы не пропустить упоминание интересующих исследование Субъектов/Объектов анализа, которые перечислены на карточке для кодировки. Кодировка начинается с того, что выписывается дата и номер газетного выпуска и число материалов с упоминаниями. После того, как на отдельном листке выписаны заголовки всех материалов, где встретились эти упоминания, - чтобы не упустить ни одного из них, - приступаем к анализу каждого из этих материалов. Для этого требуется более скрупулезное, внимательное, чем на первой стадии, чтение каждого их этих материалов».И далее подробно объясняется каждая характеристика, даются примеры, объясняются способы фиксации результатов (если обработка результатов ручная) и т.д.
Если пробный анализ покрывает недостаточную степень совпадения (американские авторы допускают в некоторых случаях степень совпадения в 60%), следует выяснить причины – это могут быть как механические ошибки (пропустил, не отметил и т.д.), так и содержательные расхождения – закодировано неправильно. Поэтому пилотажный анализ должен предусмотреть проверку каждого материала.
Кроме того, очень часто в инструкциях кодировщикам используется такое требование-объяснение: «Оценка формируется как с помощью «сильных» оценочных эпитетов, обнаруженных в тексте, так и самим содержанием ситуаций, в связи с которыми появляется в тексте интересующий нас субъект или группа: это могут быть как положительные ситуации, с которыми традиционно, в массовом сознании ассоциируется «благо», так и ситуации, с которыми ассоциируется «зло».
Когда мы говорим, что подсчет частоты появления каждой характеристики будет лишь первичным анализом текстов, мы отнюдь не хотим умалить самоценность количественно выраженных результатов исследования. Наоборот, для социолога, автора исследования, эти результаты – важный этап в работе. Тем мне менее, цифры – это, конечно, не самоцель. Они начинают новую жизнь в комментариях. Наиболее простой путь для комментатора – это найти возможность сравнить полученные им результаты. Здесь встает резонный вопрос: а с чем их сравнивать? В социологической практике применяются различные виды сравнений:
· сравнение характеристик текстов разных каналов
· сравнение характеристик текстов разных средств информации
· сравнение характеристик текста с установками издателя
· сравнение деятельности источника в динамике
· сравнение характеристик текста с данными исследований других составных частей коммуникативной цепи
· сравнение характеристик текста с теоретическими представлениями автора-исследователя
Я же хочу сравнить результаты своего исследования с разработанными Грачевым М.Н. схемами многопартийности[34] и поместить каждую из рассматриваемых мной партий соответственно ее местоположению на семантической шкале. Это будет сделано в следующей главе.
Похожие работы
... -анализа внесли российские и эстонские социологи, особенно А.Н. Алексеев, Ю. Вооглайд, П. Вихалемм, Б.Л. Грушин, Т.М. Дридзе, М. Лауристинь. 2. Контент-анализ как метод анализа документов 2.1 Общая характеристика метода контент-анализа Контент-анализ — это техника сбора информации, производимого на основе систематического выявления соответствующих целям и задачам исследования ...
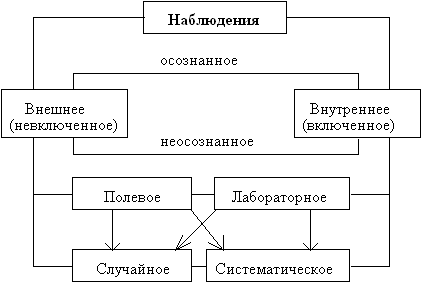
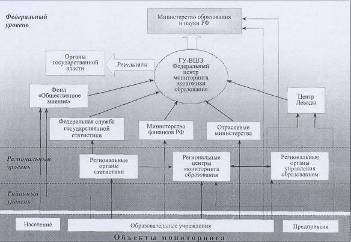
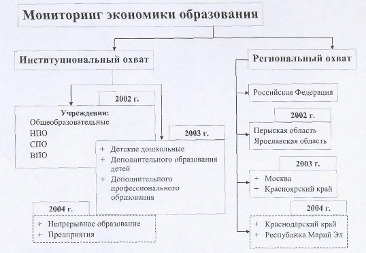
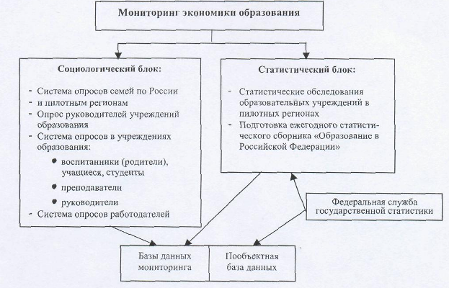
... стороны, за потребителями в лице учащихся (их семей) и работодателей, а с другой стороны, за производителями – образовательными учреждениями. 2. МОНИТОРИНГ ЭКОНОМИКИ ОБРАЗОВАНИЯ КАК МЕТОД НАБЛЮДЕНИЯ В СОЦИОЛОГИЧЕСКОМ ИССЛЕДОВАНИИ 2.1 Цели, задачи, реализация мониторинга экономики образования Оставаясь важнейшей социальной отраслью, обеспечивающей потребности человека в получении знаний, ...
... . Иногда же при сложности отнесения того или иного куска текста к той или иной единице анализа, могут возникать различные интерпретации текста и тогда ошибки возникают из-за недостаточной ясности инструкции кодировщику. Одно же из требований к любой методике анализа содержания состоит в том, чтобы она была составлена так ясно, чтобы разные исследователи, работающие по одной методике, пришли к ...
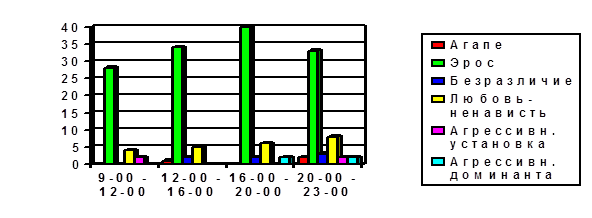
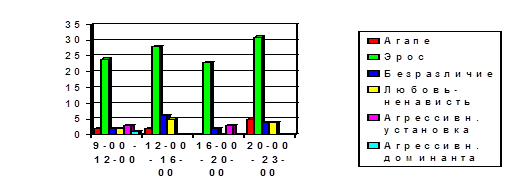
... в сферу педагогических исследований; 5. Контент-анализ не является универсальным средством получения информации и обладает как определенными достоинствами, так и ограничениями; 6. Контент-анализ вещания радиокорпорации «Авторадио» регистрирует ряд тенденций: а) наличие установок по шкале «Любовь-агрессия»; б) наличие установок по шкале «Толерантность – нонтолерантность» в сексуальной сфере, ...
0 комментариев