Навигация
Пример решения задачи дискриминантным анализом в системе STATISTICA
24301
знак
8
таблиц
7
изображений
3.2 Пример решения задачи дискриминантным анализом в системе STATISTICA
Исходя из данных по 10 странам (рис. 3.1), которые были выбраны и отнесены к соответствующим группам экспертным методом (по уровню медицинского обслуживания), необходимо по ряду показателей классифицировать еще две страны: Молдавия и Украина.
Исходными показателями послужили:
Х1 – Количество человек, приходящихся на одного врача;
Х2 – Смертность на 1000 человек;
Х3 – ВВП, рассчитанный по паритету покупательной способности на душу населения (млн. $);
Х4 – Расходы на здравоохранение на душу населения ($).
Уровень медицинского обслуживания стран подразделяется на:
- высокий;
- средний (удовлетворительный);
- низкий.
|
| Кол-во чел. на 1 врача | Расх. на здрав. | ВВП | Смертность | Класс |
| Азербайджан | 256 | 99 | 3000 | 9,6 | низкий |
| Армения | 198 | 152 | 3000 | 9,7 | низкий |
| Белоруссия | 222 | 157 | 7500 | 14 | высокий |
| Грузия | 182 | 152 | 4600 | 14,6 | удовлетворительный |
| Казахстан | 265 | 154 | 5000 | 10,6 | удовлетворительный |
| Киргизия | 301 | 118 | 2700 | 9,1 | низкий |
| Россия | 235 | 159 | 7700 | 13,9 | высокий |
| Таджикистан | 439 | 100 | 1140 | 8,6 | низкий |
| Туркмения | 320 | 125 | 4300 | 9 | удовлетворительный |
| Узбекистан | 299 | 116 | 2400 | 8 | низкий |
Рис. 3.1
Используя вкладку анализ, далее многомерный разведочный анализ, необходимо выбрать дискриминантный анализ. На экране появится панель модуля дискриминантный анализ, в котором вкладка переменные позволяет выбрать группирующую и независимые переменные. В данном случае группирующая переменная 5 (класс), а независимыми переменными выступят 1-4 (кол-во человек на 1 врача; расходы на здравоохранение; ВВП на душу населения; смертность).
В ходе вычислений системой получены результаты:
Вывод результатов показывает:
- число переменных в модели – 4;
- значение лямбды Уилкса – 0,0086739;
- приближенное значение F – статистики, связанной с лямбдой Уилкса – 9,737242;
- уровень значимости F – критерия для значения 9,737242.
Значение статистики Уилкса лежит в интервале [0,1]. Значения статистики Уилкса, лежащие около 0, свидетельствуют о хорошей дискриминации, а значения, лежащие около 1, свидетельствуют о плохой дискриминации. По данным показателя значение лямбды Уилкса, равного 0,0086739 и по значению F – критерия равного 9,737242, можно сделать вывод, что данная классификация корректная.
В качестве проверки корректности обучающих выборок необходимо посмотреть результаты матрицы классификации (рис. 3.2).
| Матрица классификации . Строки: наблюдаемые классы Столбцы: предсказанные классы | ||||
|
| Процент | низкий | высокий | удовлетв |
| низкий | 100,0000 | 5 | 0 | 0 |
| высокий | 100,0000 | 0 | 2 | 0 |
| удовлетв | 100,0000 | 0 | 0 | 3 |
| Всего | 100,0000 | 5 | 2 | 3 |
Рис. 3.2
Из матрицы классификации можно сделать вывод, что объекты были правильно отнесены экспертным способом к выделенным группам. Если есть объекты, неправильно отнесенные к соответствующим группам, можно посмотреть классификацию наблюдений (рис.3.3).
| Классификация наблюдений. Неправильные классификации отмечены * | ||||
|
| Наблюд. | 1 | 2 | 3 |
| Азербайджан | низкий | низкий | удовлетв | высокий |
| Армения | низкий | низкий | удовлетв | высокий |
| Белоруссия | высокий | высокий | низкий | удовлетв |
| Грузия | удовлетв | удовлетв | низкий | высокий |
| Казахстан | удовлетв | удовлетв | низкий | высокий |
| Киргизия | низкий | низкий | удовлетв | высокий |
| Россия | высокий | высокий | низкий | удовлетв |
| Таджикистан | низкий | низкий | удовлетв | высокий |
| Туркмения | удовлетв | удовлетв | низкий | высокий |
| Узбекистан | низкий | низкий | удовлетв | высокий |
Рис. 3.3
В таблице классификации наблюдений, некорректно отнесенные объекты помечаются звездочкой (*). Таким образом, задача получения корректных обучающих выборок состоит в том, чтобы исключить из обучающих выборок те объекты, которые по своим показателям не соответствуют большинству объектов, образующих однородную группу.
В результате проведенного анализа общий коэффициент корректности обучающих выборок должен быть равен 100% (рис. 3.2).
На основе полученных обучающих выборок можно проводить повторную классификацию тех объектов, которые не попали в обучающие выборки, и любых других объектов, подлежащих группировке.
Для этого необходимо в окне диалогового окна результаты анализа дискриминантных функций нажать кнопку функции классификации. Появится окно (рис. 3.4), из которого можно выписать классификационные функции для каждого класса.
| Функции классификации | |||
|
| низкий | высокий | удовлетв |
| Кол-во чел на 1 врача | 1,455 | 2,35 | 1,834 |
| Расх на здрав | 1,455 | 1,98 | 1,718 |
| ВВП | 0,116 | 0,20 | 0,153 |
| Смертность | 29,066 | 46,93 | 36,637 |
| Конст-та | -576,414 | -1526,02 | -921,497 |
Рис. 3.4
Таблица 3
Классификационные функции для каждого класса
| Низкий класс | = -576,414+1,455*кол-во чел на 1 врача+1,455*расх на здра+0,116*ВВП+29,066*смертность |
| Высокий класс | =-1526,02+2,35*кол-во чел на 1 врача+1,98*расх на здрав+0,20*ВВП+46,93*смертность |
| Удовлетворительный класс | =-921,497+1,834*кол-во чел на 1 врача+1,718*расх на здра+0,153*ВВП+36,637*смертность |
С помощью этих функций можно будет в дальнейшем классифицировать новые случаи. Новые случаи будут относиться к тому классу, для которого классифицированное значение будет максимальное.
Необходимо определить принадлежность стран Молдавия и Украина, подставив значения соответствующих показателей в формулы (Таблица 4).
Таблица 4
| Страна | Кол-во человек на 1 врача | Расходы на здравоохранение | ВВП на душу населения | Смертность | Высокий | Низкий | Удовлетворительный | Класс |
| Молдавия | 251 | 143 | 2500 | 12,6 | 438,29 | 653,09 | 628,64 | Низкий |
| Украина | 224 | 131 | 3850 | 16,4 | 880,23 | 863,39 | 904,27 | Удовл. |
ЗАКЛЮЧЕНИЕ
В данной курсовой работе был рассмотрен такой метод многомерного статистического анализа как дискриминантный. В дискриминантном анализе изучены: основные понятия, цели и задачи дискриминантного анализа. А также определение числа и вида дискриминирующих функций, и классификация объектов с помощью функции расстояния.
Для данного метода приведены примеры решения задач с использованием ППП STATISTICA.
СПИСОК ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ
1. Баранова, Т.А. Многомерные статистические методы. Корреляционный анализ. [Текст]: Метод. указания / Иван. гос. хим.-технол. ун-т. / Т.А. Баранова. – Иваново, 9 - 40 с.
2. Буреева, Н.Н. Многомерный статистический анализ с использованием ППП “STATISTICA” [Текст] / Н.Н. Буреева. - Нижний Новгород, 2007. -112с.
3. Дубров, А.М. Многомерные статистические методы и основы эконометрики. [Текст]: Учебное пособие / А.М. Дубров. - М.: МЭСИ, 2008.- 79 с.
4. Калинина, В.Н. Введение в многомерный статистический анализ [Текст]: Учебное пособие / В.Н. Калинина.- ГУУ. – М., 2010. – 66 с.
Похожие работы

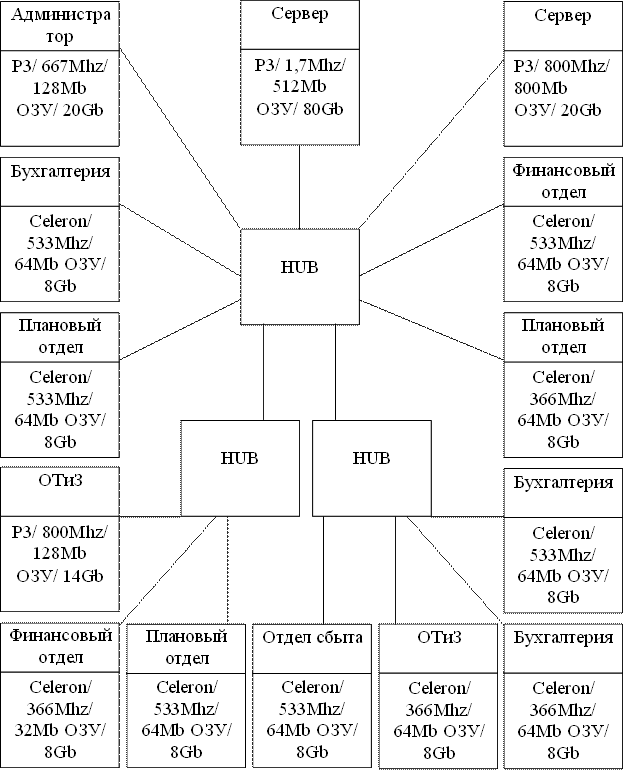
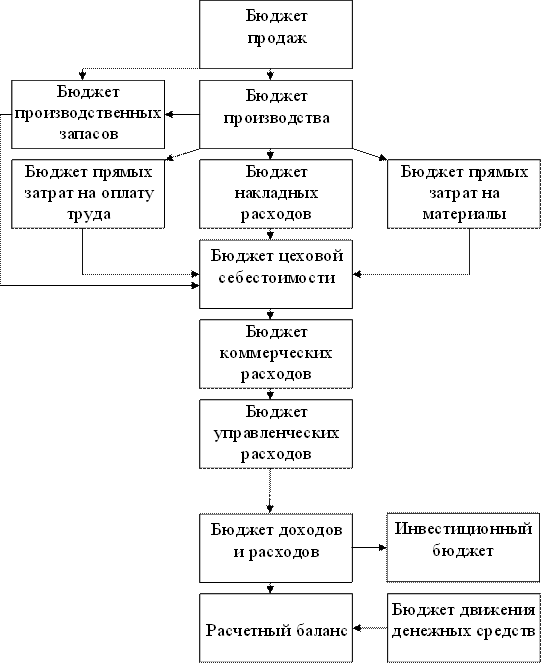
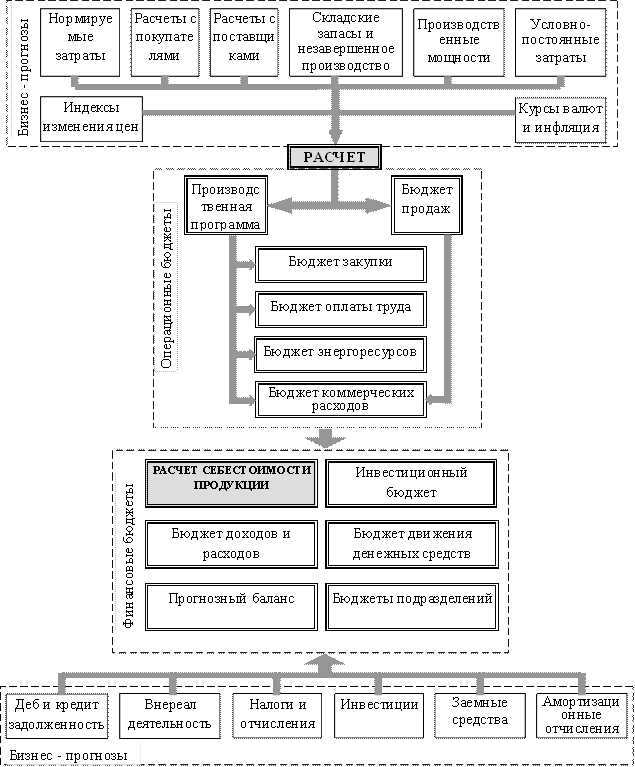
... период подготовки планов. Еще одна категория систем, используемых для бюджетирования - корпоративные системы управления (ERP-системы). ERP (Enterprise Resource Planning) - автоматизация и оптимизация внутренних бизнес-процессов, планирование как материальных, так и финансовых ресурсов в масштабе предприятия; - используется для описания компонентов "производство", "логистика", "финансы". ERP- ...
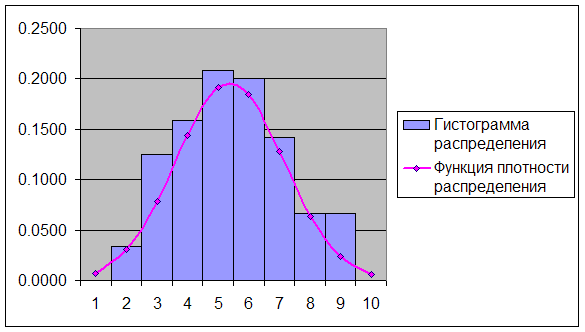
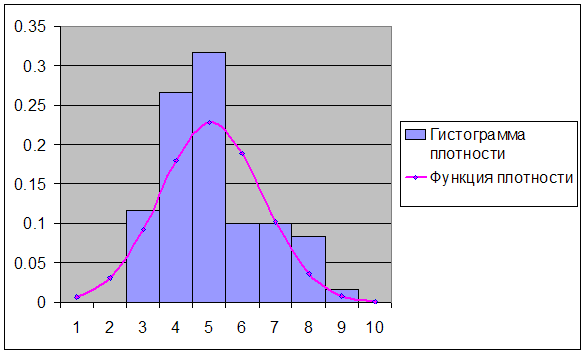
... критических точек распределения ([1], стр. 465), по уровню значимости =0,05 и числу степеней свободы 8-3=5 находим Т.к. , экспериментальные данные не противоречат гипотезе и о нормальном распределении случайной величины . Для случайной величины : Используя предполагаемый закон распределения, вычислим теоретические частоты по формуле , где - объем выборки, - шаг (разность между ...
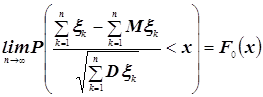
... проверить знания студента из первой части курса, которая излагается в первых четырёх модулях. Во вторых вопросах билета проверяются знания классической предельной проблемы теории вероятностей и математической статистики, которые излагаются в следующих пяти модулях. 1. Вероятностная модель с не более чем счётным числом элементарных исходов. Пример: испытания с равновозможными исходами. 2. ...
... взаимосвязи и взаимодействие подразделений с аналогичными функциями на разных уровнях единой организационной и управленческой структуры. Такая структура создает упорядоченность и организованность системы таможенных органов при выполнении возложенных на них функций. Рассмотрим современную организационную структуру таможенных органов. ГТК России имеет дифференцированную и разветвленную структуру. ...
0 комментариев