Основные теоремы теории вероятностей
Локальная формула Муавра-Лапласа
Дисперсия ДСВ и ее свойства
Дифференциальная функция распределения и ее свойства
Математическое ожидание
Числовые характеристики системы двух случайных величин. Корреляционный момент. Коэффициент корреляции
Понятие и виды статистических гипотез
Особенности статистического анализа количественных и качественных показателей
Определение вариационных рядов. Графическое изображение вариационных рядов
Проверка адекватности модели регрессии
Концепция Data Mining
Понятие и модели дисперсионного анализа
Навигация
Концепция Data Mining
О теории вероятностей
70295
знаков
2
таблицы
1
изображение
42. Концепция Data Mining
Data Mining переводится как "добыча" или "раскопка данных". Нередко рядом с Data Mining встречаются слова "обнаружение знаний в базах данных" (knowledge discovery in databases) и "интеллектуальный анализ данных". Их можно считать синонимами Data Mining. Возникновение всех указанных терминов связано с новым витком в развитии средств и методов обработки данных. Традиционная математическая статистика, долгое время претендовавшая на роль основного инструмента анализа данных, откровенно спасовала перед лицом возникших проблем. Главная причина — концепция усреднения по выборке, приводящая к операциям над фиктивными величинами (типа средней температуры пациентов по больнице, средней высоты дома на улице, состоящей из дворцов и лачуг и т.п.). Методы математической статистики оказались полезными главным образом для проверки заранее сформулированных гипотез (verification-driven data mining) и для “грубого” разведочного анализа, составляющего основу оперативной аналитической обработки данных (online analytical processing, OLAP). В основу современной технологии Data Mining (discovery-driven data mining) положена концепция шаблонов (паттернов), отражающих фрагменты многоаспектных взаимоотношений в данных. Эти шаблоны представляют собой закономерности, свойственные подвыборкам данных, которые могут быть компактно выражены в понятной человеку форме. Поиск шаблонов производится методами, не ограниченными рамками априорных предположений о структуре выборке и виде распределений значений анализируемых показателей.
43. Понятие корреляционной зависимости
При изучении случайных величин в общем случае необходимо рассматривать стохастическую зависимость, когда каждому значению СВ Х может соответствовать одно и более значений СВ Y, причем до опыта нельзя предсказать возможное соответствие. В случае стохастической связи изменение CВY, вследствие изменения СВ Х, можно разбить на 2 компоненты: 1. функциональную, связанную с зависимостью Y от Х, 2. случайную, связанную со случайным характером самих СВ Х и Y. Соотношение м/у функциональной и случайной компонентой определяет силу связи. Отсутствие первой компоненты указывает на независимость СВ Х и Y, отсутствие второй компоненты показывает, что м/у CВ X и Y существует функциональная связь.
Важным частным случаем стохастической зависимость является корреляционная. Корреляционная зависимость м/у переменными величинами – это та функциональная зависимость, которая существует м/у значениями одной из них и групповыми средними другой. (Корреляционные зависимости Y на Х и Х на Y обычно не совпадают). Корреляционная связь чаще всего характеризуется выборочным коэффициентом корреляции r, который характеризует степень линейной функциональной зависимости м/у CB X и Y. Для двух СВ Х и Y коэффициент корреляции имеет => св-ва:
1. -1≤r≤1;
2. если r=+ 1, то м/у СВ Х и Y существует функциональная линейная зависимость;
3. если r=0, то СВ Х и Y некоррелированны, что не означает независимости вообще;
4. если Х и Y образуют систему нормально распределенных СВ, то из их некоррелированности => их независимость.
Коэффициенты корреляции Y на Х и Х на Y совпадают.
Корреляция используется для количественной оценки взаимосвязи двух наборов данных с помощью коэффициента корреляции. Коэффициент корреляции выборки представляет собой ковариацию двух наборов данных, деленную на произведение их стандартных отклонений.
44. Критерий согласия
Проверка гипотезы о предполагаемом законе неизвестного распределения производится так же, как и проверка гипотезы о параметрах распределения, т. е. при помощи специально подобранной случайной величины — критерия согласия.
Критерием согласия называют критерий проверки гипотезы о предполагаемом законе неизвестного распределения.
Имеется несколько критериев согласия: χ2 («хи квадрат») К. Пирсона, Колмогорова, Смирнова и др.
Ограничимся описанием применения критерия Пирсона к проверке гипотезы о нормальном распределении генеральной совокупности (критерий аналогично применяется и для других распределений, в этом состоит его достоинство). С этой целью будем сравнивать эмпирические (наблюдаемые) и теоретические (вычисленные в предположении нормального распределения) частоты. Обычно эмпирические и теоретические частоты различаются.
Случайно ли расхождение частот? Возможно, что расхождение случайно и объясняется малым числом; наблюдений, либо способом их группировки, либо другими причинами. Возможно, что расхождение частот неслучайно (значимо) и объясняется тем, что теоретические частоты вычислены, исходя из неверной гипотезы о нормальном распределении генеральной совокупности. Критерий Пирсона отвечает на поставленный выше вопрос. Правда, как и любой критерий, он не доказывает справедливость гипотезы, а лишь устанавливает, на принятом уровне значимости, ее согласие или несогласие с данными наблюдений.
Итак, пусть по выборке объема п получено эмпирическое распределение:
варианты xl, x1, x2 ... xs,
эмп. частоты ni n1 п2 ... ns.
Допустим, что в предположении нормального распределения генеральной совокупности, вычислены теоретические частоты п. При уровне значимости α, требуется проверить нулевую гипотезу; генеральная совокупность распределена нормально.
В качестве критерия проверки нулевой гипотезы примем случайную величину
![]() (*)
(*)
Эта величина случайная, так как в различных опытах она принимает различные, заранее неизвестные значения. Ясно, что чем меньше различаются эмпирические и теоретические частоты, тем меньше величина критерия (*) и, следовательно, он в известной степени характеризует близость эмпирического и теоретического распределений.
Заметим, что возведением в квадрат разностей частот устраняют возможность взаимного погашения положительных и отрицательных разностей. Делением на n’i достигают уменьшения каждого из слагаемых; в противном случае сумма была бы настолько велика, что приводила бы к отклонению нулевой гипотезы даже и тогда, когда она справедлива. Разумеется, приведенные соображения не являются обоснованием выбранного критерия, а лишь пояснением.
Доказано, что при n→∞ закон распределения случайной величины (*), независимо от того, какому закону распределения подчинена генеральная совокупность, стремится к закону распределения χ2 с k степенями свободы. Поэтому случайная величина (*) обозначена через χ2, а сам критерий называют критерием согласия «хи квадрат».
Число степеней свободы находят по равенству
k=s-1-r
где s — число групп выборки; r — число параметров предполагаемого распределения, которые оценены по данным выборки.
В частности, если предполагаемое распределение — нормальное, то оценивают два параметра (математическое ожидание и среднее квадратическое отклонение) поэтому r=2 и число степеней свободы
k=s-1-r=s-1-2-s-3.
Если, например, предполагают, что генеральная совокупность распределена по закону Пуассона, то оценивают один параметр X, поэтому r=1 и k=s-2.
Поскольку односторонний критерий более «жестко» отвергает нулевую гипотезу, чем двусторонний, построим правостороннюю критическую область, исходя из требования, чтобы вероятность попадания критерия в эту область, в предположении справедливости нулевой гипотезы, была равна принятому уровню значимости α:
![]()
Т.о., правосторонняя критическая область определяется неравенством
![]()
а область принятия нулевой гипотезы — неравенством
![]()
Обозначим значение критерия, вычисленное по данным наблюдений, через χ2набл и сформулируем правило проверки нулевой гипотезы.
Правило. Для того чтобы, при заданном уровне значимости, проверить нулевую гипотезу H0: генеральная совокупность распределена нормально, надо сначала вычислить теоретические частоты, а затем наблюдаемое значение критерия
![]() (**)
(**)
и по таблице критических точек распределения χ2, по заданному уровню значимости α, и числу степеней свободы k=s-3, найти критическую точку χ2 (α; k).
Если χ2набл<χ2кр – нет оснований отвергнуть нулевую гипотезу.
Если χ2набл >χ2кр — нулевую гипотезу отвергают.
Замечание 1. Объем выборки должен быть достаточно велик, во всяком случае не менее 50. Каждая группа должна содержать не менее 5—8 вариант; малочисленные группы следует объединять в одну, суммируя частоты.
Замечание 2. Поскольку возможны ошибки первого и второго рода, в особенности, если согласование теоретических и эмпирических частот «слишком хорошее», следует проявлять осторожность.
Замечание 3. В целях контроля вычислений, формулу (**) преобразуют к виду
![]()
Похожие работы
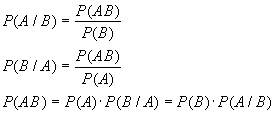
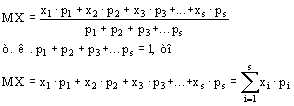
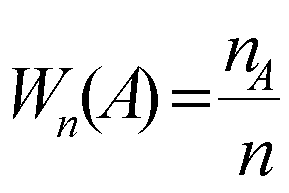
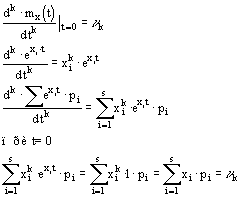
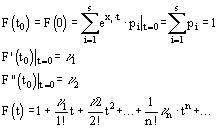
... Доказать: По определению второй смешанной производной. Найдем по двумерной плотности одномерные плотности случайных величин X и Y. Т.к. полученное равенство верно для всех х, то подинтегральные выражение аналогично В математической теории вероятности вводится как базовая формула (1) ибо предлагается, что плотность вероятности как аналитическая функция может не существовать. Но т.к. в нашем ...
... равна 0,515). Конец 19 в. и 1-я половина 20 в. отмечены открытием большого числа статистических закономерностей в физике, химии, биологии и т.п. Возможность применения методов теории вероятностей к изучению статистических закономерностей, относящихся к весьма далёким друг от друга областям науки, основана на том, что вероятности событий всегда удовлетворяют некоторым простым соотношениям, о ...
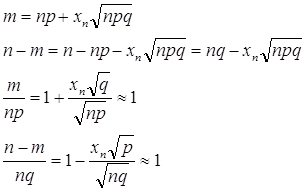
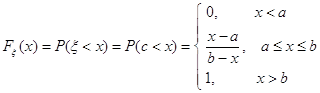
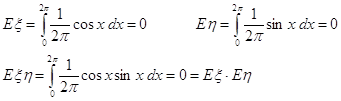
... {ξn (ω )}¥n=1 . Поэтому, во-первых, можно говорить о знакомой из математического анализа (почти) поточечной сходимости последовательностей функций: о сходимости «почти всюду», которую в теории вероятностей называют сходимостью «почти наверное». Определение 46. Говорят, что последовательность с. в. {ξn } сходится почти наверное к с. в. ξ при n ® ¥ , и пишут: ξn ...
... ничего другого, кроме как опять же события и . Действительно, имеем: *=, *=, =, =. Другим примером алгебры событий L является совокупность из четырех событий: . В самом деле: *=,*=,=,. 2.Вероятность. Теория вероятностей изучает случайные события. Это значит, что до определенного момента времени, вообще говоря, нельзя сказать заранее о случайном событии А произойдет это событие или нет. Только ...
0 комментариев