Навигация
Создание структуры базы данных - Create BD1 (BD1 – имя базы данных, в общем случае произвольное). Появляется экран шаблон для ввода полей
44106
знаков
1
таблица
0
изображений
2. Создание структуры базы данных - Create BD1 (BD1 – имя базы данных, в общем случае произвольное). Появляется экран шаблон для ввода полей.
После задания последнего поля создание структуры базы завершается выходом на OK. Появляется запрос - Будете вводить данные - нажимая клавишу Y, переходим в режим ввода данных, в котором, собственно и осуществляется ввод информации.
Ввод информации в базу данных.
На экране появляется структура базы с именами полей заданной длины. Теперь после перехода на русский регистр вводятся данные. Переход с поля на поле клавишей Enter или стрелками, возврат к предыдущей записи - PgUp, к последующей -PgDn.
Для выхода из режима после ввода всех данных - Ctrl-End.
Выход из базы Quit. Вход в существующую базу - Use BD1 (активизация БД).
Вывод информации.
Clear очистка экрана. Для вывода информации используются команды List и Display. Первая команда выводит на экран все записи, вторая только одну, на которой стоит указатель записей, эта запись называется текущей. Понятие указателя записей очень важно не только при использовании команды Display, но и для ряда других команд. Для установки указателя записи существуют специальные команды
GO TOP -перемещение указателя на первую запись
GO BOTTOM - на последнюю
5 Enter - на пятую запись
Если после этой команды дать команду Display - будет показана пятая запись
SKIP +2 - перемещение указателя на две записи вперед
SKIP -2 - на две записи назад
DISPLAY ALL -выдача всех записей поэкранно
GO 4 Enter DISPLAY REST -выдача записей, начиная с четвертой (текущей)
Выполнение команды LIST может быть инициировано клавишей F3,а команды DISPLAY клавишей F8.
LIST AVT просмотр всех фамилий в поле авторов
LIST AVT,NAZV просмотр фамилий авторов и названий книг
LIST RECORD 2 просмотр второй записи
Чтобы командное окно не мешало просмотру его можно передвинуть нажав клавиши CTRL+F7 и изменить его размеры клавишами CTRL+F8 (можно использовать мышь)
LIST FOR GOD<1992 выводятся все поля для записей, удовлетворяющих условию
LIST NAZV FOR GOD<1992 выводится только поле названий для книг, изданных до 1992 года
Условия могут быть сложными, использующими логические отношения NOT,AND,OR в этой же приоритетности они и исполняются, если используются одновременно в одной команде.
LIST FOR (STEL=112).AND.(VOZVR<D)выдаются книги, расположенные на стеллаже 112 с просроченным возвратом. Здесь использованы числовое поле стеллажа и поле даты.
При использовании логических операций с полями даты необходимо предварительно определить переменную типа даты следующим образом
D=CTOD('03.11.96') и затем уже работать с этой переменной.
LIST AVT FOR (GOD>1990).OR.(NAL=’ЕСТЬ’)Здесь использовано символьное поле, оно заключается в кавычки.
Логические условия заключаются в точки.
Символьная запись в кавычках должна быть задана точно теми же символами, которыми эта запись задана в базе. (ПК сравнивает коды символов, поэтому русские и латинские буквы одного написания для ПК разные символы, аналогично различаются строчные и прописные буквы.
LIST FOR POLZOV='Орлов' выдаются книги, выданные Орлову.
LIST AVT,NAZV FOR NAL='ЕСТЬ' выводятся поля авторов и названий для книг, имеющихся в наличии.
Последовательный поиск записи по условию осуществляется командой LOCATE.
LOCATE FOR STEL=114 выдается номер одной первой найденной записи. Просмотр найденной записи осуществляется командой DISPLAY. Следует обратить внимание, что действие команды начинается с перемещения указателя записи на первую запись и в процессе поиска указатель записи перемещается по базе данных. После нахождения заданной записи указатель оказывается на этой записи. Таким образом, команда работает с указателем записи самостоятельно и, задавая после нее другую какую-нибудь команду, нужно это учитывать. В частности, задавая для продолжения поиска команду CONTINUE, нужно понимать, что поиск продолжается с сохранением заданных условий от той записи, на которой остановился поиск. Если заданные условия не найдены, то указатель записи оказывается в конце базы и команда DISPLAY информации не дает.
Если в процессе поиска необходимо сменить условия, то, чтобы не начинать поиск с начала базы, если это не нужно, а база большая, следует использовать команду LOCATE REST FOR STEL=115 - поиск будет продолжен от текущей записи с новыми условиями. Поиск может осуществляться и по сочетанию нескольких условий:
LOCATE FOR STEL=114 .AND. NAL=’ЕСТЬ’, опять выдается только номер первой записи, удоалетворяющей этому условию.
Если мы не располагаем точной информацией о поисковом признаке, т.е. не уверены абсолютно точно как записаны данные, то можно организовать приближенный поиск:
LIST AVT FOR LIKE ('Ka*',AVT) - будут выданы все фамилии авторов, начинающиеся на Ка. При этом, конечно, будет выдана и лишняя информация, но зато и нужная, которую при точном поиске обнаружить бы не удалось. В опции LIKE символы * и ? могут употребляться в любых сочетаниях. Может использоваться также команда типа BROWSE FIELD AVT FOR LIKE (‘Ka*’,AVT)
Корректировка данных.
Для изменения, дополнения или удаления записей используется режим APPEND. После этой команды система переходит в режим редактирования записей, при этом автоматически в конец базы добавляется пустая запись, на которую и устанавливается указатель записей. В эту пустую запись можно вводить новую дополнительную информацию. Для перехода к предыдущим записям - PgUp. Перейдя к нужной записи можно ее отредактировать обычным образом. Для удаления записи ее нужно предварительно пометить. Пометка к удалению - команда CTRL+T. У помеченной записи слева появляются метки в виде точек, однако запись при этом не удаляется. Восстановление помеченной к удалению записи (отмена удаления) осуществляется повторной командой CTRL+T.
Удаление отмеченных записей производится командой PACK после выхода из режима редактирования. Выход из режима APPEND командой CTRL+END. Пометить запись для удаления можно и не входя в режим APPEND командой DELETE RECORD 3 - третья запись оказывается помеченной или просто DELETE, помечена текущая запись.
Завершение удаления командой PACK.
Снятие пометок к удалению - команда RECALL, без параметров действует только на текущую запись.
Пример. RECALL ALL -снятие всех пометок.
USE BD1GO 5 переход к пятой записи
SKIP-3 возврат ко второй записи
DELETE NEXT 3 пометка к удалению 2,3,4 записей
RECALL RECORD 4 снятие пометки с записи 4
PACK удаление записей с возвратом указателя записей на первую запись.
В больших базах команда PACK работает медленно, поэтому используется редко. Чтобы помеченные записи не мешались, их делают невидимыми командой SET DELETED ON, в этом случае запись будет появляться только при прямом обращении к ней (GO 20) -тогда эта помеченная запись проявится.
Задав последовательность команд
USE BD1
APPEND FROM BDD1
мы к открытой базе BD1 добавим содержимое другой базы BDD1, конечно при этом все базы должны существовать и поля у них должны быть одинаковыми.
Не в режиме редактирования, а в командном, можно вставить новую запись между уже имеющимися. Для этого указатель записи устанавливается на нужную запись и она становится текущей. Для вставки после текущей записи используется команда INSERT BLANK,
для вставки перед текущей записью - команда INSERT BEFORE BLANK.
Изменение записей командой REPLACEКомандой REPLACE осуществляется модификация записей в базе, т.е. замена одного понятия другим, а не дописывание или изменение отдельных символов, как это делается в режиме APPEND.
Команда без параметров действует только на текущую запись.
Пример. 3 ENTER REPLACE NAL WITH 'ЕСТЬ' - установлена третья запись, и в поле наличие сделана запись о том, что книга возвращена.
REPLACE ALL GOD WITH 1880 - все записи в поле GOD заменяются на 1880.
REPLACE STEL WITH 222 FOR STEL=112 - все книги со стеллажа 112 переставлены на стеллаж 222. Изменяются все записи, для которых номер стеллажа 112.
Практически только командой REPLACE в FoxPro можно изменять значения полей файла БД. В этом смысле она эквивалентна знаку равенства в операции присваивания для переменных в алгоритмических языках.
Буквально фраза <поле> with <выражение> соответствует оператору присвоения <поле>=<выражение>.
Пример использования команды.
Бригаде дана премия 20% от выработки каждого, у кого выработка более 100р, а бригадиру еще 500р. Нужно изменить поле выработки (VIR), т.е. начислить премию к зарплате.
У бригадира табельный номер 98.
USE BRIGADAREPLACE VIR WITH VIR*1.2 FOR VIR>100
REPLACE VIR WITH VIR+500 FOR TAB=98
Можно ввести специальное понятие вычисляемого поля по аналогии с тем, как это делается в электронных таблицах.
Пусть есть в базе поля COST(цена) и QUANT(количество), в этих полях есть записи. Есть пустое поле COST_PART(цена партии).
Заполнить это пустое вычисляемое поле можно так
REPLACE ALL COST_PART WITH COST*QUANT
BROWSE ОКНОЯвляется мощным средством редактирования, просмотра и управления данными. В режиме Browse записи можно редактировать, дополнять и помечать к удалению. Допускается создавать т.н. вычисляемые поля. Эти поля фактически не являются полями базы данных, но могут быть их функциями и отображаются на экране наравне с настоящими полями.
Такой режим соответствует работе с электронными таблицами.
Вычисляемые поля не могут редактироваться и запоминаться в БД.
Для введения вычисляемого поля при вызове режима BROWSE, указывается какую информацию заносить в это поле. Эта информация будет индицироваться в режиме BROWSE, но после выхода из режима она исчезает и если затем просмотреть записи БД, то вычисляемое поле окажется пустым.
Пример: Пусть в базе есть поля COST - стоимость единицы товара и MINIM - минимальная партия поставки. Сформируем вычисляемое поле Стоимость минимальной партии - MIN_COST.
Входим в режим BROWSE:
BROWSE MIN_COST=COST*MINIM – формируется и индицируется вычисляемое поле. По умолчанию в режиме BROWSE отображаются все поля БД. Однако, можно уменьшить количество выводимых полей, задавая их поименно:
BROWSE FIELDS COST,MINIM,MIN_COST=COST*MINIMВ качестве заголовков по умолчанию отображаются имена полей. Однако, есть возможность задавать произвольные заголовки:
BROWSE FIELDS COST:H=’цена’,MINIM:H=’мин. партия’,
MIN_COST=COST*MINIM:H=’мин.цена’
Если заголовок не нужен вообще, следует в качестве заголовка использовать пробел («).Можно использовать также условие-фильтр при вхождении в режим. Например выдать товары с ценой менее 2 тыс.$: BROWSE FOR COST<2000
Для сохранения заданного режима работы BROWSE после выхода из него предварительно задается команда SET RESOURCE ON тогда команда BROWSE LAST вызывает последнюю версию режима BROWSE. Если SET RESOURCE OFF, то последняя конфигурация не сохраняется и опция LAST никак не действует, а команда BROWSE LAST срабатывает просто как команда BROWSE.
Работая в режиме BROWSE, можно клавишей F10 перейти в верхнее меню, войти в меню BROWSE и там:
опция GRID OFF/ON -установить или убрать вертикальные разделители между полями, MOVE FIELD - позволяет менять местами поля в BROWSE окне, SIZE FIELD - позволяет менять видимые размеры (ширину) выделенного поля.
Клавишами CTRL+F2 можно осуществить перевод маркера из BROWSE окна в окно команд.
Изменение структуры базы данных.
Изменение структуры базы данных, т.е. введение новых полей, изменение или изъятие имеющихся осуществляется в режиме MODIFY STRUCTURE. На экране при этом появляются существующие поля, их названия и параметры. Изменения в существующих полях осуществляется обычным посимвольным редактированием. Для вставки нового поля перед текущим полем маркер передвигается в крайнюю левую позицию (нажим ENTER вызывает появление стрелок ) и в этой позиции нажимается клавиша INSERT. Появляется поле с именем NEWFIELD, которому затем обычным редактированием можно задать любое другое имя. Для уничтожения существующего поля маркер в той же крайней левой позиции и клавиша DELETE.
Выход из режима через OK.
Просмотр структуры осуществляется командой LIST STRUCTURE
Структура новой базы может быть создана из структуры уже имеющейся командами
COPY STRUCTURE TO DB2
COPY STRUCTURE TO DB2 FIELDS AVT,NAZV
т.е. формирование новой базы с полным или частичным набором полей.
Копирование баз данныхМожно создавать новые базы данных, копируя не только структуру, но и сами данные.
USE BD1 COPY TO BDD - скопируется вся база COPY TO BDD1 FIELD AVT - скопируются все записи в поле AVTCOPY TO BDD2 FOR GOD=1992 - все записи по всем полям где год издания 1992
COPY TO BDD3 FIELD AVT FOR GOD=1992 COPY TO BDD4 FIELD AVT FOR GOD=1992.AND.NAL=’есть’Таким образом можно создавать частичные базы данных для желаемых полей с заданными условиями.
ФильтрЧастичные базы данных можно создавать также с помощью фильтра. Фильтр - это способ ограничения для просмотра больших баз данных. После введения фильтра из большой базы выводится только информация , удовлетворяющая заданным в фильтре условиям, а остальной как бы не существует, хотя на самом деле сама база никаким изменениям не подвергается.
SET FILTER TO GOD>1990 LISTБудет выдана информация только по книгам, выпущенным после 1990г.
Если после включения фильтра дать команду COPY TO BDD то будет создана новая база, в которую войдут только книги, выпущенные после 1990г.
Действие фильтра отменяется при выходе из БД, например, при переходе к другой БД - USE BDD1.
Отменяется также заданием команды SET FILTER TO без указания условий. Установленный фильтр начинает действовать только в случае, если после команды SET FILTER TO <условия> произведено хоть какое-то перемещение указателя записей в файле БД (например, дана команда LIST, перемещающая этот указатель) При задании фильтра возможны логические условия
SET FILTER TO STEL>112.AND.GOD>1990Заданный фильтр отменяется также заданием другого фильтра
SET FILTER TO STEL>112
Сортировка базы данныхБаза данных для облегчения пользования ею может быть упорядочена по заданному закону, например, по алфавиту в поле авторов или по возрастанию или убыванию года издания или другим информационным признакам данных.Но упорядоченная база при этом создается как новая, т.е. каждая сортировка требует создания новой базы, следовательно каждая сортировка влечет за собой требования к месту размещения этой новой базы. Когда база маленькая об этом можно не думать, а если база большая, то количество признаков упорядочивания ограничивается объемами дисковой памяти компьютера.
Примеры:
USE BD1SORT TO BD2 ON AVT база BD2 отсортирована по алфавиту авторов
SORT TO BD3 ON AVT/D обратная сортировка по алфавиту
SORT TO BD4 ON STEL по номеру стеллажа в возрастающем порядке
SORPT TO BD5 ON STEL/D в убывающем порядке
SORT TO BD6 ON VOZVR по дате возврата в порядке возрастания
Сортировка по нескольким полям:
SORT TO BD7 ON STEL,NOM/D по возрастанию номера стеллажа, а внутри каждого стеллажа в порядке убывания номера ячейки.
Сортировка базы позволяет ускорить в большой базе поиск нужной информации.
Индексирование баз данныхВажнейшим элементом любой системы управления базами данных является наличие средств ускоренного поиска данных, поскольку поиск - самая распространенная операция в системах обработки данных. Этот механизм реализуется введением т.н. индексных файлов. Они имеют расширение IDX.
Индексирование БД вводится для ускорения операции поиска данных. Для этой же цели можно применять сортировку БД по нужному поисковому ключу, но каждая сортировка создает новую БД размером с исходную. Реальные БД имеют большой размер и многократная их сортировка оказывается технически нереализуемой.
Индексные файлы занимают принципиально меньший объем, поэтому для больших БД необходима именно индексация, поскольку в неупорядоченной базе поиск длится долго, а сортировка невозможна из-за ограничений в дисковой памяти. Если файл проиндексирован, команды DISPLAY,BROWSE,SKIP,REPLACE и все другие, связанные с движением в файле базы данных, перемещают указатель записей в соответствии с индексом, а не с физическим порядком расположения записей. В частности, команды GO TOP и GO BOTTOM устанавливают указатель записей не на первую и последнюю физические записи, а на начальную и конечную записи индексного файла соответственно. Один файл БД может быть проиндексирован по нескольким полям и иметь любое число индексов. Такие файлы не содержат сами записи, а содержат только указание на порядок их расположения в файле БД для того поля, по которому осуществлена индексация. Например, при индексации поля авторов в алфавитном порядке в индексном файле будут содержаться записи такого типа 1 - 3 справа номера записей в файле БД в поле AVT,
2 - 1 слева номера записей в индексном файле
3 - 5 для поля AVT и аналогично для других полей.
Размер индексного файла сравним с объемом дискового пространства, занимаемого полем базы данных, по которому было произведено индексирование. Т.о. если база проиндексирована по всем полям, суммарный размер всех индексных файлов будет близок к размеру всей БД. При наличии многих индексов замедляются операции ввода и редактирования БД, т.к. при дополнении БД новой записью автоматически должны быть отредактированы все индексные файлы.
Индексирование выполняется следующей командойINDEX ON <выражение> TO <IDX-файл> [COMPACT] [ADDITIVE]
Предпоследняя опция создает компактный индексный файл, поэтому ею всегда надо пользоваться, это ускоряет поиск. Последняя опция обеспечивает сохранность уже созданных индексных файлов при открытии новых. По умолчанию вновь создаваемые индексы закрывают ранее открытые индексы для текущей БД.
Индексированная база из текущей создается :
USE BD1INDEX ON AVT TO BD2 - из базы BD1 создана индексированная по фамилиям база BD2 с расширением .IDX
Можно сделать ограниченную индексацию
INDEX ON AVT TO BD3 FOR STEL=112
После создания индексированной базой можно пользоваться след. образом: при открытии базы:
USE BD1 INDEX BD2 или
USE BD1
SET INDEX TO BD2
При корректировке записей БД индексированные файлы автоматически изменяются, поэтому при активизации БД нужно указывать все имеющиеся уже созданные индексированные файлы:
SET INDEX TO BD2,BD3 и т.д. сколько есть файлов .IDX
Отмена индексации: SET INDEX TO или SET ORDER TO 0
Активным является только первый из указанных индексов. По нему индексируется база. Переключиться на другой индекс можно командой SET ORDER TO N - где N порядковый номер индексированного файла в последнем списке (SET INDEX TO ...). Можно сделать иначе - заново задать команду SET INDEX TO ... где нужный индекс должен быть у первого в списке индексного файла.
В индексированном файле быстрый поиск нужной записи может осуществляться командой
SEEK 'Попов' для строкового поля
SEEK 25 для числового
SEEK D где D=ctod('22.03.94') для даты
После каждой команды SEEK нужно дать команду DISPLAY для индикации результатов поиска. Пример.
USE BDINDEX ON AVT TO BD1
INDEX ON VOZVR TO BD2
INDEX ON GOD TO BD3
USE BD INDEX BD1
SEEK ‘Попов’, DISPLAY
USE BD INDEX BD2, D=CTOD(‘22.03.94’), SEEK D, DISPLAY
USE BD INDEX BD3, SEEK 1992, DISPLAY
Если все индексные файлы не были перечислены при открытии базы, а она была изменена, нужно произвести переиндексацию командой
REINDEX предварительно задав командой SET INDEX TO ...
все индексные файлы, подлежащие переиндексации.
Команда SEEK <выражение> применяет специальный алгоритм ускоренного поиска, в котором база просматривается не сплошь, а в соответствии с информацией, содержащейся в индексном файле.
При наличии индекса сначала именно в нем, а не в самой базе ведется поиск номера записи с указанным в команде SEEK значением выражения в индексном поле. При этом поиск в индексе выполняется не последовательно, а скачками (т.н. двоичный поиск), что позволяет быстро локализовать номер нужной записи. Команда SEEK находит только одну первую запись и устанавливает на нее указатель записи.
Сочетанием команды SEEK с командой SET NEAR ON может быть осуществлен приближенный поиск, если точное значение искомого признака неизвестно. Пример.
USE BD, INDEX ON GOD TO BD1 COMPACT, SET NEAR ON, SEEK 1980, BROWSEВ результате поиска указатель записи установится на числе, ближайшем к заданному. Войдя в режим BROWSE и оглядев ближайшие записи, легко обнаружить интересующую, поскольку в индексированной базе все записи упорядочены по годам и искомый год находится рядом.
Команда SEEK является аналогом команды LOCATE для последовательного поиска. Однако команде продолжения поиска CONTINUE нет индексного аналога. Причина здесь очевидна. После того как командой SEEK найдена первая нужная запись, розыск остальных записей, удовлетворяющих ключу поиска, является тривиальным. Следующая такая запись (если есть) находится в индексированном файле непосредственно ниже найденной, и переход на нее может быть выполнен просто командой SKIP.
Похожие работы
... -педагогическая или научно-техническая проблема, являющаяся новым научным вкладом в теорию определенной области знаний (педагогику, технику и другие). 4. ПРАКТИЧЕСКИЕ РЕКОМЕНДАЦИИ ДЛЯ ВЫПОЛНЕНИЯ ВЫПУСКНОЙ КВАЛИФИКАЦИОННОЙ РАБОТЫ БАКАЛАВРА ФИЗИКО-МАТЕМАТИЧЕСКОГО ОБРАЗОВАНИЯ ПРОФИЛЬ ИНФОРМАТИКА 4.1. Положение о выпускной квалификационной работе бакалавра физико-математического образования: ...
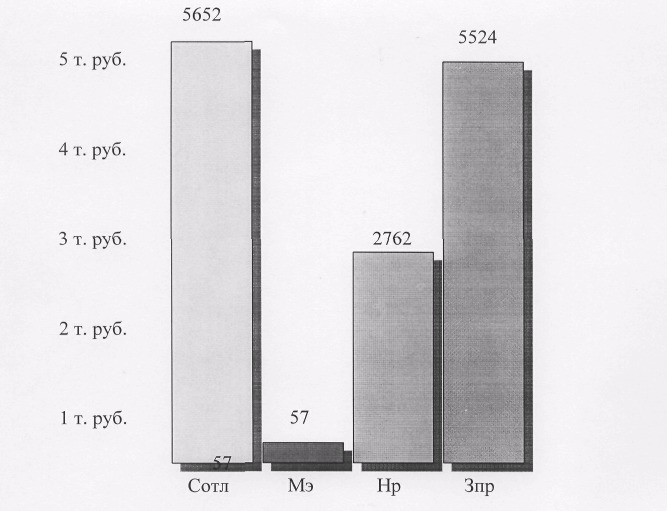
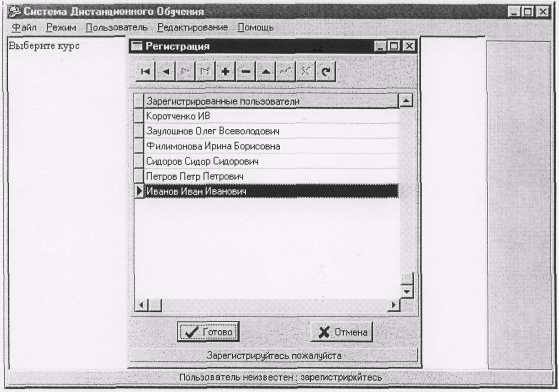
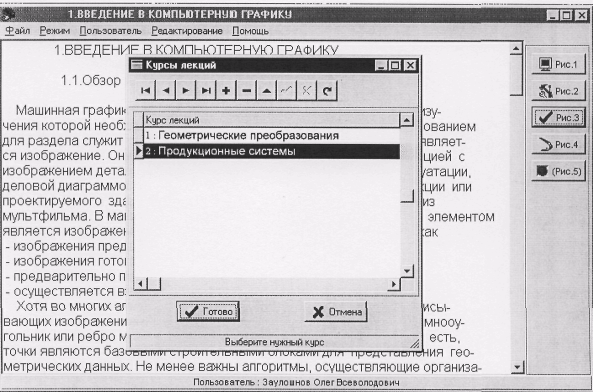
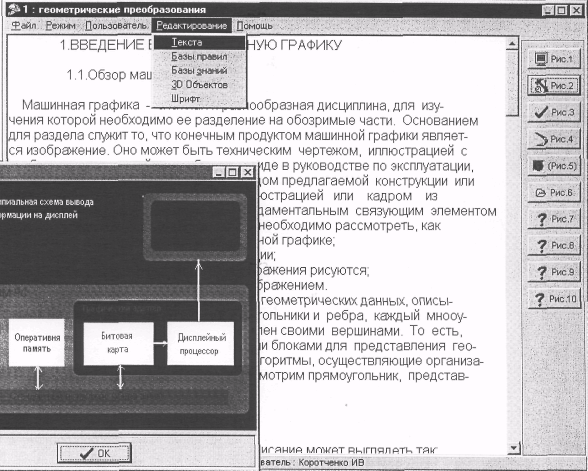
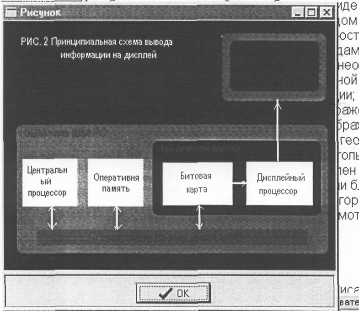
... . 00147-01 9001-1 расширении количества примитивов расширяется список возможных дисциплин, которые могут быть заложены в систему. Разрабатываемая система предназначается для дисциплин "Компьютерная графика" и "Системы искусственного интеллекта", а также для близких с ними дисциплин. Использование одного и того же набора примитивов для создания курсов по указанным дисциплинам приведет к ...
... ). Качественная разработка и постоянное совершенствование нормативной и учебно-методической документации – это составная часть создания оптимального комплексного учебно-методического обеспечения образовательного процесса по учебным дисциплинам. Важно, чтобы вся эта документация была не формальным набором документов, а действенным инструментом повышения результативности образовательного процесса ...
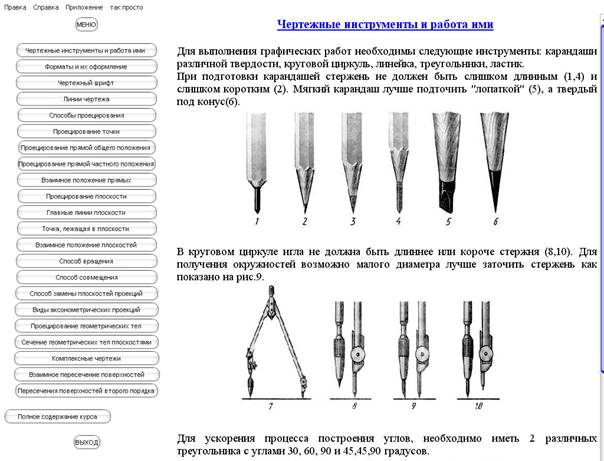
... при определенных условиях значительно повысить эффективность обучения. Глава II. Техническая составляющая проектирования и разработки ЭУК 2.1 Анализ предметной области дисциплины Данный обучающий модуль электронный учебный курс по дисциплине «Начертательная геометрия, инженерная графика» разработан для студентов Института профессионального образования и информационных технологий ...
0 комментариев