Навигация
Формирование тактовых импульсов
29162
знака
1
таблица
11
изображений
2.3 Формирование тактовых импульсов
Тактировать микроконтроллер можно несколькими способами: использовать внешний тактирующий сигнал, либо подключать внешний кварцевый резонатор или RC-цепочку, либо использовать встроенный генератор с внутренней RC- цепочкой. Всё зависит от той задачи, которую мы решаем.
Использование встроенного RC-генератора с внутренней время задающей RC-цепочкой является наиболее экономичным решением, так как при этом не требуется никаких внешних компонентов.
Внутренний RC-генератора микроконтроллеров семейства мега может работать на нескольких фиксированных частотах.
Частота работы внутреннего RC-генератора определяется значениями битов CKSEL3-0 согласно табл.3.
В разрабатываемом устройстве высокая частота, а соответственно и высокая скорость работы не нужна, поэтому вполне достаточно будет выбрать частоту тактирования равную 4.0 МГц.
2.4 Организация сброса
В данном случае нет смысла использовать отдельную кнопку сброса, сброс будет осуществляться по включению питания либо по внешнему сигналу сброса от устройства управления. При включении устройства подаётся питание на контроллер и автоматически осуществляется сброс, при выключении устройства, просто снимается питание с контроллера.
Для предотвращения сбоев работы контролера и выполнения программы при скачке напряжения, используем встроенную схему сброса при снижении питания BOD, которая отслеживает напряжение питания. Если работа этой схемы разрешена, то при снижении питания ниже некоторого уровня она переводит контроллер в состояние сброса. Когда напряжение вновь увеличится до порогового значения, запускается таймер задержки сброса. После формирования задержки tTOUT внутренний сигнал сброса снимается и происходит запуск микроконтроллера.
Включением/выключением схемы BOD управляет конфигурационная ячейка BODEN. Для разрешения работы схемы эта ячейка должна быть запрограммирована в «0». Порог срабатывания VBOT определяется состоянием конфигурационной ячейки BODLEVEL, при «1» порог срабатывания 2.7 В, при «0» порог 4 В.
Для уменьшения вероятности ложных срабатываний порог напряжения переключения схемы имеет гистерезис, равный 50 мВ. Кроме того, срабатывание схемы BOD происходит только в том случае, если период провала больше 2 мкс.
Задание длительности задержки сброса tTOUT определяется значением конфигурационных ячеек, и включает в себя две составляющих: ts – выход на рабочий режим и стабилизация частоты тактового генератора, tr – для установки напряжения питания. При использовании встроенного RC-генератора с внутренней RC-цепочкой при включённой схеме BOD, биты конфигурации SUT1-0 установлены в значение «00», при этом ts= 6 тактов, tr –соответственно не используется.
2.5 Схема включения микроконтроллера
В микроконтроллере AT mega16 используется напряжение 5 В, подаваемое на вход VCC. Вход AREF используется для подключения внешнего фильтрующего конденсатора для повышения помехозащищенности.
3. ПРОЕКТИРОВАНИЕ ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ МИКРОКОНТРОЛЛЕРА
3.1 Алгоритм работы устройства
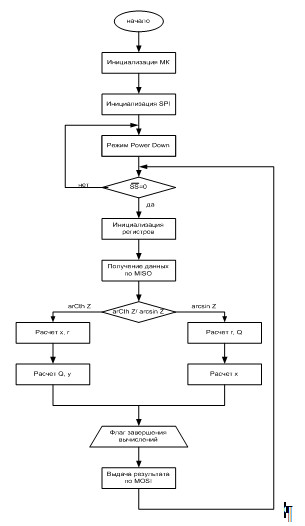
Рис.3.1 - Алгоритм работы устройства
Описание алгоритма программы микроконтроллера:
1. Подача напряжения питания на устройство, автоматически происходит сброс и запуск внутреннего генератора тактовых импульсов;
2. Инициализация режимов работы контролера и его внутренних устройств (портов, интерфейсов и т.д.);
3. Переход в энергосберегающий режим ожидания Power Down;
4. Ожидание прерывания INT1, выводящего контролер из спящего режима;
5. При приходе сигнала SS происходит загрузка регистров SPI и прием данных по MISO от УКС.
6. Анализ полученных данных. Если получена команда 1 – запуск вычисления функции arcth Z, если получена команда 2 – функции arcsin Z.
7. Начало вычисления заданной функции:
1 этап вычислений - расчет ri , Xi (для функции arcth Z) или ri , Qi (для функции arcsin Z);
2 этап вычислений – расчет Yi , Qi или Xi
8. Установка флага завершения вычислений;
9. Выдача результата по MOSI;
10. Ожидание прерывания либо INT0 переводящего в спящий режим контроллер, либо INT1 запускающего следующий расчёт.
3.2 Разработка программного обеспечения
Листинг программы на языке C++ для микроконтроллера ATmega16:
//== Библиотеки ========================================
#include <mega16.h>
#include <delay.h>
#include "ctype.h"
#include "stdlib.h"
//== Global Variables =====================================
#define TRUE 1
#define FALSE 0
#define COM1 0x01//команда начала вычислении arCthZ
#define COM2 0x02 //команда начала вычислении arcsinZ
#define GICRMask 0xC0 //разрешение прерываний Int0 Int1
#define MCUCRMask 0xCF //спящий режим POWER Down прерывания по низкому уровню
#define nMCUCRMask 0x0F //запрет режима POWER Down
// биты для настройки SPI
#define MOSI 5 //выходный данные передаются по 5 биту порта В
#define SCK 7 // импульсы синхронизации передаются по 7 биту порта В
#define SS 4 //бит упарвляющий передачей данных
#define SPIE 7 //разрешение прерываний по SPI
#define SPE 6 // включение SPI
#define MSTR 4 //МК в режиме мастер
#define SPR0 0 // делитель на 16
#define CLRBIT(ADDR,BIT) (ADDR&=~(1<<BIT))
#define SETBIT(ADDR,BIT) (ADDR|=(1<<BIT))
unsigned char com;//переменная для хранения полученной команды
unsigned char DATA[4];//массив данных, в котором хранится полученное значение Z
unsigned char DATA_SEND[4];//массив данных, в котором хранится результат вычислений
unsigned char DDR_SPI; //переменная для настройки работы порта В
unsigned char SPIF = 0;//флаг завершения передачи/приема данных по SPI
unsigned char FlagInt1 = 0//флаг получения прерывания INT1 – вывод МК из спящего режима
unsigned char FlagInt0 = 0;//флаг получения прерывания INT0 – перевод МК в спящий режим
unsigned char FlagCalcReady = 0; //флаг завершения вычислений
//== Const =============================================
// Table of 2^(-i) ---------------------------------------------
float dva[15]={0.5,0.25,0.125,0.0625,0.03125,0.015625,
0.0078125,0.00390625,0.001953125,0.0009765625,
0.00048828125,0.000244140625, 0.0001220703125, 0.00006103515625,
0.00003051758125};
// Table of Arth -------------------------------------------------
loat ath[13]={ 0.5493061,0.2554128,0.1256572,0.0625816,0.0312602,0.0156263,
0.0078127,0.0039063, 0.0019531,0.0009766,0.0004883,0.0002441,
0.0001221 };
float log1[13]={0.5849625, 0.3219281,0.169925, 0.0874628, 0.0443941, 0.0223678,
0.0112273, 0.0056245, 0.0028150, 0.0014082, 0.0007043, 0.0003522,
0.0001761};
float log2[13]={1, 0.4150375, 0.1926451, 0.0931094, 0.0458037, 0.0227201, 0.0113153,
0.0056466, 0.0028205, 0.0014096, 0.0007046, 0.0003523, 0.0001761};
//=====================================================
void GlobalInitialize(void)
{
#asm ("cli");
DDRB = DDR_SPI;
PORTB = 0xD0;
DDRD = 0x00; //PortD as input
PORTD = 0x0C; //подключение резисторов подтяжки к выводам PD2, PD3
GICR=GICRMask;
MCUCR=nMCUCRMask;
#asm ("sei");
}
//=====================================================
void Init_SPI_SLAVE(void)
{
//настройка интерфейса в режим подчиненный
DDR_SPI=(1<<MOSI); //формируем маску для порта В: передача битов по MOSI
//прием по MISO, тактовый сигнал и сигнал выбора МС на ввод
SPCR |= (1 << SPIE); //разрешение прерывания по SPI
SPCR |= (1 << SPE); //включение интерфейса
}
//== функция приема сообщений ============================
void SPI_SlaveReceive(void)
{
unsigned char i;
for(i=0; i<1; i++)
{
while(!(SPSR & (1<<SPIF))); //ждем завершения передачи 1-го байта
com = SPDR;
SPIF = FALSE;
}
for(i=1; i<5; i++)
{
while(!SPIF); //ждем завершения передачи байта
DATA[i-1] = SPDR;
SPIF = FALSE;
}
}
//== функция передачи данных =============================
void SPI_SlaveSend(void)
{
unsigned char i;
for (i = 0; i<4; i++)
{
SPDR = DATA_SEND[3-i]; //сохр данный в регистре данных SPI
while(!SPIF); //ждем завершения передачи
SPIF = FALSE; //установка флага завершения передачи в 0
}
FlagCalcReady = 0;
}
//====преобразования данных в формат с плавающей запятой =======
float char_to_Float(void)
{
float tmp=0;
float a=255;
tmp = (DATA[3]*a);//преобразование целой части
tmp=tmp+DATA[2];
tmp=tmp+(DATA[1]/a);//преобразование дробной части
tmp=tmp +(DATA[0]/a/a);
return tmp;
}
//=====================================================
void Float_to_char(float tmp)
{
int data_tmp=0;
data_tmp=(int)tmp;
DATA_SEND[3]=data_tmp>>8;
DATA_SEND[2]=data_tmp;
data_tmp=(int)((tmp-data_tmp)*65025);
DATA_SEND[1]=data_tmp>>8;
DATA_SEND[0]=data_tmp;
}
//=====================================================
float arCth(float Z)
{
float aCh;
float X0=1.45235,X1=0,Y0=0,Y1=0,Q0=0,Q1=0;
unsigned char i,n;
for(n=1;n<=26;n++)//число итераций 26
{
i = 1 +((n-1)>>1);
if ((Z-Q0)>=0) //определение знака итерации
{
Q1=Q0 + ath[i-1]; //вычисление Z
X1=X0 + Y0*dva[i-1]; //вычисление Xi=arcthZ
Y1=Y0 + X0*dva[i-1]; //вычисление Yi=sh(arChZ)
}
else
{
Q1=Q0 - ath[i-1]; //вычисление Z
X1=X0 - Y0*dva[i-1];//вычисление Xi=arcthZ
Y1=Y0 - X0*dva[i-1]; //вычисление Yi=sh(arChZ)
}
//сохранение предыдущих значений
Q0=Q1;
X0=X1;
Y0=Y1;
}
aCh = Q1;
FlagCalcReady = 1;
return aCh;
}
//=====================================================
float arcsinZ (float Z)
{
float as;
float X0=1.0, X1=0.0, Q0=0.0, Q1=0.0;
unsigned char i,n;
for(n=1;n<=26;n++)
{
i = 1 + ((n-1)>>1);
if ((Z-Q0)>=0) //определение знака итерации
{
Q1=Q0 + log1[i]; //вычисление угла
X1=X0 + X0*dva[i]; //вычисление Xi
}
else
{
Q1=Q0 - log2[i]; //вычисление Z
X1=X0 - X0*dva[i]; //вычисление Xi
}
Q0=Q1;
X0=X1;
}
as = X1;
FlagCalcReady =1;
return as;
}
//=====================================================
void main(void)
{
unsigned char nSS; //сигнал выбора микросхемы
float Z, ans;
Init_SPI_SLAVE(); //инициализация SPI
GlobalInitialize(); //настройка портов ввода-вывода
while(1)
{
if (FlagInt0) //обработка прерывания Инт0
{
FlagInt0=0;
MCUCR=MCUCRMask; //разрешение включения спящего режима
#asm ("SLEEP");} //переход в спящий режим
}
if (FlagInt1)
{
FlagInt1=0;
nSS = PORTB & 0x10; //маска для выделения бита PORTB4
if (nSS == 0)
{
SPI_SlaveReceive();
if (com == COM1)
{
Z = char_to_Float();
ans = arCth(Z);
}
if (com == COM2)
{
Z = char_to_Float();
ans = arcsin (Z );
}
}
if (FlagCalcReady)
{
Float_to_char(ans);
SPI_SlaveSend();
}
}
}
//=interrupt==============================================
interrupt [EXT_INT0] void INT0_interrupt(void) //обработка прерывания Int0
{
FlagInt0 = 1; //установка флага
}
interrupt [EXT_INT1] void INT1_interrupt(void) //обработка прерывания Int1
{
FlagInt1 = 1; //установка флага
MCUCR=nMCUCRMask; //запрет спящего режима
}
4. АНАЛИЗ РАБОТОСПОСОБНОСТИ ПРОГРАММЫ
Откомпилировав написанную программу в CodeVision, проанализируем её работу в симуляторе AVRStudio4.
В пошаговом режиме будем тестировать программу, подавая в нужные моменты на входы контроллера соответствующие сигналы. По имеющимся в отладчике часам определим время получения одного значения.
На рис.4.3 показаны результаты вычислений функции arch при получении следующей посылки: com = 0x01, Z = 1.7997576 (после преобразования посылки в формат с плавающей запятой). В результате вычислений получено: arch Z = 1,1927513. Истинное значение составляет arch Z = 1,1927565. Погрешность составляет:![]() , что находится в пределах заданной.
, что находится в пределах заданной.
Ниже отображены результаты вычислений пр получении другой посылки от УКС. В ней com = 0x02, Z = 1.0468 (после преобразования посылки в формат с плавающей запятой). В результате вычислений получено: arcsinZ = 2,0657325. Истинное значение составляет arcsinZ = 2,06594. Погрешность составляет:![]() , что находится в пределах заданной.
, что находится в пределах заданной.
По значению переменной StopWatch можно подсчитать время всего преобразования:
T=7141,5 мкс, что составляет 7,1 мс и вполне удовлетворяет техническому заданию.
Заключение
В данной работе был промоделирован и реализован процессор CORDIC. Данный процессор способен выполнять вычисление различных элементарных функций, таких как тригонометрические, логарифмические и другие. Однако в данном случае стояла задача реализовать только функции arCth Z и arcsinZ.
Вычисление заданной функции устройство выполняет в соответствии с техническим заданием с заданной точностью и в течении заданного периода времени.
Структурная схема, разработанная в этой работе, конечно, не единственно возможная и, тем более, не максимально производительная. Но на ее примере можно усвоить основные принципы построения специализированных цифровых вычислительных систем, таких как процессор CORDIC.
Данное устройство является универсальным и может быть использовано в любом комплексном устройстве. Для согласования работы данного устройства с ведущим устройством не возникает никаких сложностей, так как оно может работать асинхронно, принимать и генерировать прерывания.
Похожие работы
... элементов, глобальное пространство имен, а также лавинообразную первоначальную загрузку сети. Таким образом ОСРВ SPOX имеет необходимые механизмы для создания отказоустойчивой распределенной операционной системы реального времени, концепция построения которой описана в главе 2. 4.3 Аппаратно-зависимые компоненты ОСРВ Модули маршрутизации, реконфигурации, голосования реализованы как аппаратно- ...
... ; - показывать, за счет каких структурных особенностей достигается увеличение производительности различных вычислительных систем; с этой точки зрения, классификация может служить моделью для анализа производительности. 1.12 Классификация Дазгупты Одним из последних исследований по классификации архитектур, по-видимому, является работа С. Дазгупты, вышедшая в 1990 году. Автор ...
... БД, куда по необходимости могут заноситься и логические представления (взаимосвязи) (внешние модели). До загрузки среды БД желательно реализовать её экспериментальный прототип, или построить её модель. На основе прототипа можно получить приемлемую оценку эксплуатационных характеристик БД, в том числе заранее спрогнозировать увеличение увеличение объёма БД и числа её функций. Применение полной БД ...
... преодолеть присущие архитектуре х86 ограничения (различная длина инструкций). В случае использования инструкций различной длины, чипы 4-го поколения могут одновременно обрабатывать 1 команду, процессоры 5-го поколения (Pentium) - 2 команды. И только микропроцессор AMD5k86 способен обрабатывать до 4 инструкций за такт. Использование раздельного КЭШа инструкций и данных (объем КЭШа инструкций ...
0 комментариев