Навигация
ПОКАЗНИКИ НАДІЙНОСТІ ТА ВІДМОВОСТІЙКОСТІ
29418
знаков
0
таблиц
0
изображений
2.3 ПОКАЗНИКИ НАДІЙНОСТІ ТА ВІДМОВОСТІЙКОСТІ
Найважливішою характеристикою транспортної магістральної мережі є надійність - здатність правильно функціонувати протягом тривалого періоду часу. Ця властивість має три складових: власне надійність, готовність і зручність обслуговування.
Підвищення надійності полягає в запобіганні несправностям, відмовам і збоям за рахунок застосування електронних схем і компонентів з високим ступенем інтеграції, зниження рівня перешкод, полегшених режимів роботи схем, забезпечення теплових режимів їх роботи, а також за рахунок вдосконалення методів збірки апаратури. Надійність вимірюється інтенсивністю відмов і середнім часом напрацювання на відмову. Надійність мереж як розподілених систем багато в чому визначається надійністю кабельних систем і комутаційної апаратури - роз'ємів, кросових панелей, комутаційних шаф і т.п., що забезпечують власне електричну або оптичну зв'язність окремих вузлів між собою.
Підвищення готовності передбачає придушення в певних межах впливу відмов і збоїв на роботу системи за допомогою засобів контролю і корекції помилок, а також засобів автоматичного відновлення циркуляції інформації в мережі після виявлення несправності. Підвищення готовності є боротьбою за зниження часу простою системи.
Критерієм оцінки готовності є коефіцієнт готовності, який може інтерпретуватися, як вірогідність знаходження системи в працездатному стані. Коефіцієнт готовності обчислюється як відношення середнього часу напрацювання на відмову до суми цієї ж величини і середнього часу відновлення. Системи з високою готовністю називають також відмовостійкими.
Основним способом підвищення готовності є надмірність, на основі якої реалізуються різні варіанти відмовостійкої архітектури. Обчислювальні мережі включають велику кількість елементів різних типів, і для забезпечення відмовостійкості необхідна надмірність по кожному з ключових елементів мережі. Якщо розглядати мережу тільки як транспортну систему, то надмірність повинна існувати для всіх магістральних маршрутів мережі, тобто маршрутів, що є загальними для великої кількості клієнтів мережі. Такими маршрутами зазвичай є маршрути до корпоративних серверів - серверів баз даних, Web-серверів, поштових серверів і т.п. Тому для організації відмовостійкої роботи всі елементи мережі, через які проходять такі маршрути, повинні бути зарезервовані: повинні бути резервні кабельні зв'язки, якими можна скористатися при відмові одного з основних кабелів, всі комунікаційні пристрої на магістральних шляхах повинні або самі бути реалізовані по відмовостійкій схемі з резервуванням всіх основних своїх компонентів, або для кожного комунікаційного пристрою повинен бути резервний аналогічний пристрій.
Перехід з основного зв'язку на резервний або з основного пристрою на резервний може відбуватися як в автоматичному режимі, так і вручну, за участю адміністратора. Очевидно, що автоматичний перехід підвищує коефіцієнт готовності системи, оскільки час простою мережі в цьому випадку буде істотно менший, ніж при втручанні людини. Для виконання автоматичних процедур реконфігурації необхідно мати в мережі інтелектуальні комунікаційні пристрої, а також централізовану систему управління, що допомагає пристроям розпізнавати відмови в мережі і адекватно на них реагувати.
Високий ступінь готовності мережі можна забезпечити у тому випадку, коли процедури тестування працездатності елементів мережі і переходу на резервні елементи вбудовані в комунікаційні протоколи. Прикладом такого типу протоколів може служити протокол FDDI, в якому постійно тестуються фізичні зв'язки між вузлами і концентраторами мережі, а у разі їх відмови виконується автоматична реконфігурація зв'язків за рахунок вторинного резервного кільця. Існують і спеціальні протоколи, що підтримують відмовостійкість мережі, наприклад, протокол SpanningTree, що виконує автоматичний перехід на резервні зв'язки в мережі, побудованій на основі мостів і комутаторів.
Існують різні градації відмовостійких комп'ютерних систем, до яких відносяться і обчислювальні мережі. Приведемо декілька загальноприйнятих визначень:
• висока готовність (highavailability) - характеризує системи, що виконані за звичайною комп'ютерною технологією, використовують надмірні апаратні і програмні засоби і відновлення, що допускають час, в інтервалі від 2 до 20 хвилин;
• стійкість до відмов (faulttolerance) - характеристика таких систем, які мають в гарячому резерві надмірну апаратуру для всіх функціональних блоків, включаючи процесори, джерела живлення, підсистеми введення/висновку, підсистеми дискової пам'яті, причому час відновлення при відмові не перевищує однієї секунди;
• безперервна готовність (continuousavailability) - це властивість систем, які також забезпечують час відновлення в межах однієї секунди, але на відміну від систем стійких до відмов, системи безперервної готовності усувають не тільки простої, що виникли в результаті відмов, але і планові простої, пов'язані з модернізацією або обслуговуванням системи. Всі ці роботи проводяться в режимі online. Додатковою вимогою до систем безперервної готовності є відсутність деградації, тобто система повинна підтримувати постійний рівень функціональних можливостей і продуктивності незалежно від виникнення відмов.
Оскільки мережі обслуговують одночасно велику кількість користувачів, то при розрахунку коефіцієнта готовності необхідно враховувати цю обставину. Коефіцієнт готовності мережі повинен відповідати довшому часу, протягом якого мережа виконувала з належною якістю свої функції для всіх користувачів. Очевидно, що у великих мережах дуже важко забезпечити значення коефіцієнта готовності, близькі до одиниці.
Між показниками продуктивності і надійності мережі існує тісний зв'язок. Ненадійна робота мережі дуже часто призводить до істотного зниження її продуктивності. Це пояснюється тим, що збої і відмови каналів зв'язку і комунікаційного устаткування приводять до втрати або спотворення деякої частини пакетів, внаслідок чого комунікаційні протоколи вимушені організовувати повторну передачу загублених даних. Оскільки, для прикладу, в локальних мережах відновленням загублених даних займаються як правило протоколи транспортного або прикладного рівня, шо працюють з тайм-аутами в декілька десятків секунд, то втрати продуктивності внаслідок низької надійності мережі можуть складати сотні відсотків.
3. ІНСТРУМЕНТИ МОНІТОРИНГУ І АНАЛІЗУ МЕРЕЖІ
Все різноманіття засобів, вживаних для моніторингу і аналізу обчислювальних мереж, можна розділити на декілька великих класів:
Системи управління мережею (NetworkManagementSystems) централізовані програмні системи, які збирають дані про стан вузлів і комунікаційних пристроїв мережі, а також дані про трафік, циркулюючий в мережі. Ці системи не тільки здійснюють моніторинг і аналіз мережі, але і виконують в автоматичному або напівавтоматичному режимі дії по управлінню мережею - включення і відключення портів пристроїв, зміна параметрів мостів адресних таблиць мостів, комутаторів і маршрутизаторів і т.п. Прикладами систем управління можуть служити популярні системи HPOpenView, SunNetManager, IBMNetView.
Засоби управління системою (SystemManagement). Засоби управління системою часто виконують функції, аналогічні функціям систем управління, але по відношенню до інших об'єктів. У першому випадку об'єктом управління є програмне і апаратне забезпечення комп'ютерів мережі, а в другому - комунікаційне устаткування. Разом з тим, деякі функції цих двох видів систем управління можуть дублюватися, наприклад, засоби управління системою можуть виконувати простий аналіз мережевого трафіку.
Вбудовані системи діагностики і управління
• (Embeddedsystems). Ці системи виконуються у вигляді програмно-апаратних модулів, що встановлюються в комунікаційне устаткування, а також у вигляді програмних модулів, вбудованих в операційні системи. Вони виконують функції діагностики і управління тільки одним пристроєм, і в цьому їх основна відмінність від централізованих систем управління. Прикладом засобів цього класу може служити модуль управління концентратором Distrebuted 5000, що реалізовує функції автосегментації портів при виявленні несправностей, приписування портів внутрішнім сегментам концентратора і деякі інші. Як правило, вбудовані модулі управління "за сумісництвом" виконують роль SNMP-агентів, що поставляють дані про стан пристрої для систем управління.
• Аналізатори протоколів (Protocolanalyzers). Є програмними або апаратно-програмними системами, які обмежуються на відміну від систем управління лише функціями моніторингу і аналізу трафіку в мережах. Хороший аналізатор протоколів може захоплювати і декодувати пакети великої кількості протоколів, вживаних в мережах, - звичайні декілька десятків. Аналізатори протоколів дозволяють встановити деякі логічні умови для захоплення окремих пакетів і виконують повне декодування захоплених пакетів, тобто показують в зручній для фахівця формі вкладеність пакетів протоколів різних рівнів один в одного з розшифровкою змісту окремих полів кожного пакету.
Устаткування для діагностики і сертифікації кабельних систем.
Умовно це устаткування можна поділити на чотири основні групи: мережеві монітори, прилади для сертифікації кабельних систем, кабельні сканери і тестери (мультиметри).
• Мережеві монітори (звані також мережевими аналізаторами) призначені для тестування кабелів різних категорій. Слід розрізняти мережеві монітори і аналізатори протоколів. Мережеві монітори збирають дані тільки про статистичні показники трафіку - середню інтенсивність загального трафіку мережі, середній інтенсивності потоку пакетів з певним типом помилки і т.п.
• Призначення пристроїв для сертифікації кабельних систем, безпосередньо виходить з їх назви. Сертифікація виконується відповідно до вимог одного з міжнародних стандартів на кабельні системи.
• Кабельні сканери використовуються для діагностики мідних кабельних систем.
• Тестери призначені для перевірки кабелів на відсутність фізичного розриву.
• Експертні системи. Цей вид систем акумулює людські знання про виявлення причин аномальної роботи мереж і можливі способи приведення мережі в працездатний стан. Експертні системи часто реалізуються у вигляді окремих підсистем різних засобів моніторингу і аналізу мереж: систем управління мережами, аналізаторів протоколів, мережевих аналізаторів. Простим варіантом експертної системи є контекстно-залежна help-система. Складніші експертні системи є так звані бази знань, що володіють елементами штучного інтелекту. Прикладом такої системи є експертна система, вбудована в систему управління Spectrum компанії Cabletron.
• Багатофункціональні пристрої аналізу і діагностики. Останніми роками, у зв'язку з повсюдним розповсюдженням локальних мереж виникла необхідність розробки недорогих портативних приладів, що суміщають функції декількох пристроїв: аналізаторів протоколів, кабельних сканерів і, навіть, деяких можливостей ПЗ мережевого управління. Як приклад такого роду пристроїв можна привести Compas компанії MicrotestInc. або 675 LANMeter компании FlukeCorp.
Похожие работы


... збір даних про організацію, який полягає в пошуку всіх відомостей, які хакер може зібрати про комп'ютерну систему, що атакується. Мається на увазі інформація, що містить звіт про комп'ютерну мережу організації. На хакреських сайтах можна знайти файли з результатами сканування широкого діапазону телефонних номерів. У цих файлах можна знайти безліч відомостей про телефони різних організацій з вказі ...
... іжності мережі. Найбільш прийнятним в плані простоти алгоритмізації операторним перетворенням матриці, шо відповідає умові самоприв'язки елемента до структури матриці, є піднесення її до степеня. Матриця в загальному випадку описує певний простір, просторову множину, в даному випадку виміру N. Далі визначимо, що саме описує вхідна матриця суміжності. Оскільки матриця представляє собою логічну ...
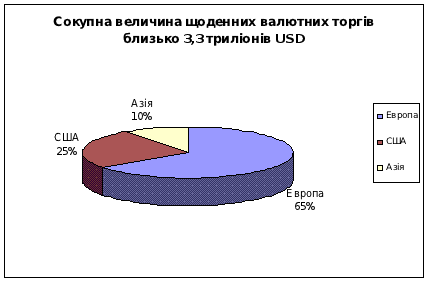
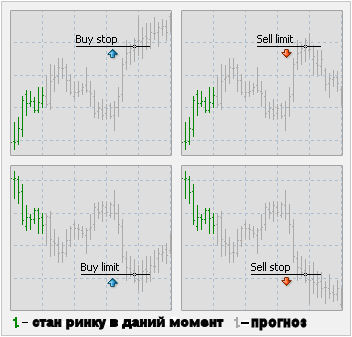
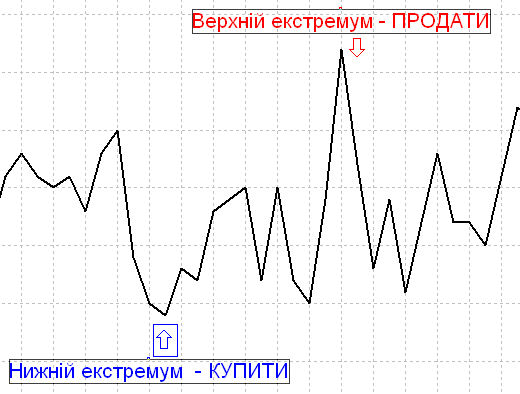
... є функція X(f). Якщо замість змінної f використовується змінна w, то наведене вище рівняння набуває вигляду (2.6) 3. ОПИС І РОЗРОБКА НОВОГО МАТЕМАТИЧНОГО МЕТОДУ ПРОГНОЗУВАННЯ КРОС-КУРСІВ 3.1 Математична постановка задачі Розгляд графіка будь якої валюти показує, що він являє собою суму синусоїд з різним періодом (рис. 3.1). Рис. 3.1. – Співвідношення хвильоподібності крос-курсу з синусої ...

... ї потужності. У разі зменшення значення функції при деяких параметрах частоти та кількості каналів можна зробити висновок про збільшення впливу завад - збільшення відношення сигнал шум. оптична транспортна інфокомунікаційна мережа Спектральна функція передачі енергії тракту - енергетичний коефіцієнт передачі у такій інтерпретації є фактично функцією перехресних завад - перерозподілу енергії у ...
0 комментариев