Навигация
2. Информационный поиск
Движущей силой современного общества являются интеллектуально-информационные ресурсы, т. е. знания и информация. Где их найти? Достаточно условно накопление интеллектуально-информационных ресурсов разделить на две задачи:
- поиск информации;
- добыча знаний.
С поиском информации нам приходится сталкиваться практически во всех компьютерных и Интернет-приложениях. Для этих целей используются встроенные в офисные пакеты и бизнес-приложения поисковые механизмы, средства группирования и сортировки данных. Поисковые машины Интернета (например, AltaVista, Google, HotBot, АПОРТ, Яndex, МЕТА и другие) с помощью специальных роботов позволяют по запросам пользователей находить различную информацию в киберпространстве. Аналогичные средства имеются и на большинстве сайтов, позволяя их посетителям "разобраться" в имеющихся информационных ресурсах.
Как правило, поисковые механизмы скрыты от пользователей и не требуют знания логики их работы. Пользователям нужно ввести слова и некоторые символы-заменители, которых можно узнать из справочной системы программы или поисковой машины Интернета, в поле "Поиск", "Найти", "Пошук, "Search" и т. д.
На достаточно больших Интернет-ресурсах используются системы реферирования. Искусство реферирования (составления аннотаций) обеспечивает извлечение наиболее важных или характерных фрагментов из одного или многих источников информации. Для этих целей можно применять такие инструменты, как функция AutoSumma-rize в Microsoft Office, системы IBM Intelligent Text Miner, Oracle Context и Inxight Summarizer (компонент поисковой машины AltaVista), хотя они и имеют некоторые ограничения. Они применимы только для текстов.
Для поиска нужной информации в текстах применяется несколько технологий.
Технология автоматического анализа текста на основе ассоциативно-статистической модели обеспечивает повышение качества векторных моделей, представляющих текст набором составляющих слов, за счет коррелированности появления слов в тексте с помощью семантических связей.
Технология автоматического анализа текста положена в основу таких программных продуктов, как Russian Context Optimizer и Oracle InterMedia. Здесь интеллектуальная обработка текста (тематическая классификация, аннотирование) сочетается с поисковыми возможностями, доступными при работе с реляционными базами данных. Большинство возможностей InterMedia оказывается доступно в полной мере лишь для английского языка и в меньшей мере еще для ряда европейских и восточно-азиатских языков.
Адаптацию технологий Oracle к русскоязычным базам данных выполнила российская компания Гарант-Парк-Интернет, которая выпускает продукт Russian Context Optimizer (RCO). Используемое в RCO лингвистическое обеспечение позволяет приводить к нормальной форме все грамматические формы слов русского языка, сводить воедино различные части речи, а также отождествлять близкие по смыслу словосочетания.
Визуализация информационных массивов в Интернете обеспечивает удобное представление для пользователя найденной информации. Для этих целей используются тематические сети TopNet и самоорганизующиеся тематические карты TopSOM.
Для поиска информации в хранилищах данных используются механизмы OLAP-систем, позволяющие получать кубы и их срезы.
3. Добыча знаний
Получить информацию не всегда означает получить знания. Специалисты выделяют три стратегии получения знаний:
- приобретение знаний (способ автоматизированного наполнения базы знаний);
- извлечение знаний (процедура взаимодействия с источником знаний);
- обнаружение знаний в базах данных, (knowledge discovery in databases - KDD) - процесс получения из "сырых" данных потенциально полезной информации.
Благодаря быстрому развитию хранилищ данных, в которых данные предметно ориентированы, интегрированы и хранятся в хронологической последовательности, обнаружение знаний в базах данных вышло на первый план. KDD предполагает накопление "сырых" данных, их отбор, подготовку, преобразование, поиск закономерностей и их обобщение, тем самым превращая информацию (данные) в знания.
Аналитические инструменты, обеспечивающие добычу знаний, относят к области технологий Data Mining (раскопки данных). В их основу положена концепция шаблонов и зависимостей, отражающих многоаспектные связи в данных. Нетривиальность разыскиваемых шаблонов позволяет отражать неочевидные закономерности в данных, составляющие так называемые скрытые знания.
4. Классификация систем Data Mining
Сегодня ведется много споров о том, какие системы относить к Data Mining. В той или иной степени к Data Mining можно отнести системы, поддерживающие алгоритмическое обеспечение, описанное ниже.
Статистические пакеты. В современных статистических пакетах, наряду с классическим методиками (корреляционный, регрессионный, факторный анализ), имеют место и элементы Data Mining (http://isl.cemi.rssi.ru). Серьезный недостаток статистических пакетов, ограничивающий их применение в Data Mining, - это статистическая парадигма, построенная на усредненных характеристиках выборки, которые не всегда подходят при исследовании реальных сложных жизненных явлений.
В качестве примеров наиболее распространенных статистических пакетов можно назвать SAS, SPSS, STATGRAPICS, STATISTICA, STADIA, цена которых составляет от $1000 до $15000.
Нейронные сети.
Это большой класс систем, архитектура которых имеет некую аналогию с построением нервной ткани из нейронов. На нейроны самого нижнего слоя подаются значения входных параметров, на основе которых нужно принимать какие-то решения или прогнозировать развитие ситуации. Эти значения рассматриваются как сигналы, передающиеся в следующий слой, ослабляясь или усиливаясь в зависимости от числовых значений (весов), приписываемых межнейронным связям. В результате на выходе нейрона самого верхнего слоя вырабатывается некоторое значение, которое рассматривается как реакция всей сети на значения входных параметров. Основным недостатком нейросетевой парадигмы является необходимость иметь очень большой объем обучающей выборки. К нейросетевым системам относятся BrainMaker, NeuroShell, OWL, thought (Cognos) и SENN Sales (Siemens Nixdorf). Стоимость их довольно значительна ($1500-8000).
CBR-системы.
Для того, чтобы сделать прогноз на будущее или выбрать правильное решение, CBR-системы (case based reasoning) находят в прошлом близкие аналоги имеющей место ситуации и выбирают тот же ответ, который был для них правильным. Основным недостатком этих систем считается то, что они вообще не создают каких-либо моделей или правил, обобщающих предыдущий опыт. К ним относятся KATE tools (Acknosoft), Pattern Recognition Workbench (США).
Деревья решений.
Эти системы создают иерархическую структуру классифицирующих правил типа "ЕСЛИ... ТО..." (if-then), имеющую вид дерева. Популярность подхода связана с наглядностью и понятностью, но деревья решений принципиально не способны находить оптимальные, или лучшие (наиболее полные и точные), правила в данных. Они реализуют простой принцип последовательного просмотра признаков, создавая лишь иллюзию логического вывода. Наиболее известными системами на основе дерева решений являются See5/C5.0 (RuleQuest), Clementine (Integral Solutions), SIPINA (University of Lyon), IDIS (Information Discovery, KnowledgeSeeker (ANGOSS).
Эволюционное программирование.
Российская разработка PolyAnalyst позволяет строить гипотезы о виде зависимости целевой переменной от других переменных в виде программ на некотором внутреннем языке программирования. В системе "выращивается" несколько генетических линий программ, которые "конкурируют" между собой в точности выражения искомой зависимости. Специальный модуль системы PolyAnalyst переводит найденные зависимости с внутреннего языка системы на понятный пользователю язык (математические формулы, таблицы и пр.). Кстати, с помощью этой системы делаются попытки управления портфелем ГКО-ОФЗ. Модель, рассчитанная системой PolyAnalyst, выполняющей периодический пересчет формул индексов привлекательности разных бумаг, импортируется в систему торгов SmartBroker.
Ограниченный перебор.
Эти алгоритмы вычисляют частоты комбинаций простых логических событий в подгруппах данных. Наиболее ярким современным представителем этого подхода является система WizWhy (WizSoff).
Похожие работы
... последовательные ступени обработки сырья, либо играющих вспомогательную роль одна по отношению к другой. И в случае межотраслевых объединений тресты представляют собой комбинаты. ГЛАВА 2. «МЯГКИЕ» ФОРМЫ ОБЪЕДИНЕНИЙ. 2.1. КОНСОРЦИУМ Консорциум — временный союз хозяйственно независимых фирм, целью которого могут быть разные ...
... кредиты иностранных центральных и частных банков, а также МВФ. Использование заемных ресурсов связано с выполнением определенных требований кредитора. 3.3 Политика управления валютными резервами в кратко- и среднесрочном периоде и ее эффект Важную роль в развитии международных экономических отношений Молдовы играет финансовое регулирование внешнеэкономических связей через формирование и ...

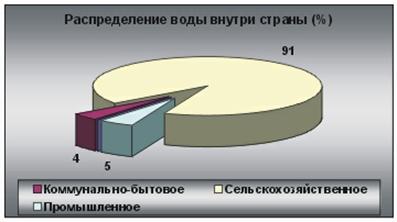
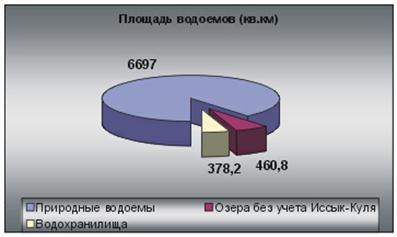
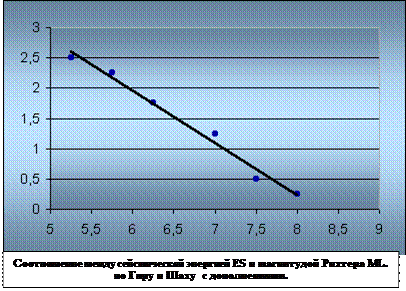

... предыдущего чрезмерного стравления, в восстановлении будут преобладать разновидности сорняков. Глава 3. Проблемы горных территорий и возможные способы их решения. Природные и антропогенные катаклизмы. Природные катаклизмы в горах представляют результат геотектонической природы гор и их экологических характеристик. Однако катаклизмы зачастую вызываются деятельностью человека. Перед ...
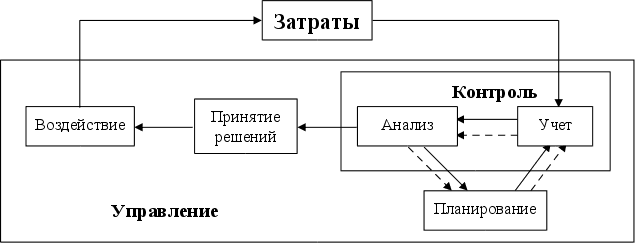



... по ГХК "Краснолиманская Показатели 1999 2000 Отклонение, пунктов Отклонение, % 1. Рентабельность капитала 2. Рентабельность основного капитала 3. Рентабельность производства 4. Рентабельность продаж 26,4 33,3 43,8 30,5 28,1 36,5 48,6 32,7 +1,7 +3,2 +4,8 +2,2 +6,4 +9,6 +11,0 +7,2 2.3 Управление затратами на ...
0 комментариев