Навигация
Функция Lex_Repeat_Until
88878
знаков
2
таблицы
23
изображения
3.3.11 Функция Lex_Repeat_Until
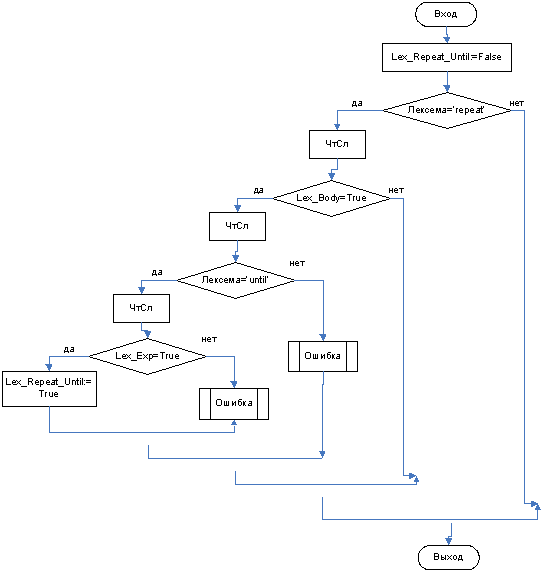
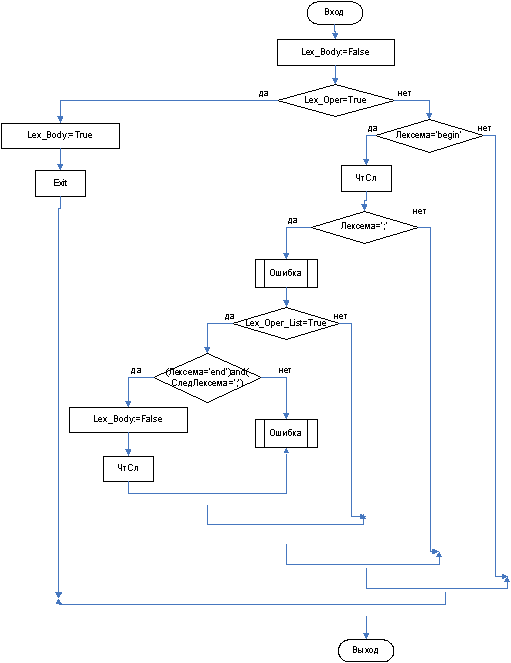
3.3.12 Функция Lex_Body
3.4 Тексты распознающих процедур
function TForm1. Lex_Progr: boolean; // 1. программа
begin
Lex_Progr: =False;
if Code_Tab [i]. Lex='program' then i: =i+1 else // конец блока для PROGRAM
begin
Err_Synt ('Отсутствует служебное слово program, либо в нем ошибка ', i);
Exit;
end;
if Lex_Prog_Name=false then Exit; // начало блока для имени программы
if Code_Tab [i]. Lex='; ' then i: =i+1 else // начало блока для точки с запятой
begin
Err_Synt ('Отсутствует точка с запятой после имени программы', i-1);
Exit;
end;
if Code_Tab [i]. Lex='var' then i: =i+1 else // начало блока для VAR
begin
Err_Synt ('Отсутствует служебное слово var после заголовка программы', i);
Exit;
end;
if Lex_descr_list=false then Exit;
if Code_Tab [i]. Lex='begin' then // начало блока для BEGIN
begin
i: =i+1;
if Code_Tab [i]. Lex='; ' then
begin
Err_Synt ('После begin недопустим символ "; "', i);
Exit;
end;
end else
begin
Err_Synt ('Отсутствует служебное слово begin после описаний переменных', i);
Exit;
end;
if Lex_oper_list=false then Exit;
if Code_Tab [i]. Lex='end' then i: =i+1 else // начало блока для END
begin
Err_Synt ('Отсутствует служебное слово end в конце программы', i);
Exit;
end; // начало блока для точки
if Code_Tab [i]. Lex='. ' then Lex_Progr: =true else if Code_Tab [i]. Lex<>'' then Err_Synt ('После служебного слова END вместо точки находится "'+Code_Tab [i]. Lex+'"', i) else Err_Synt ('Ожидается точка после служебного слова END в конце программы', i-1);
end;
procedure TForm1. Err_Synt (text: string; l: integer);
begin
if Error<>true then
begin
Memo1. Lines [Code_tab [l]. numstr-1]: =Memo1. Lines [Code_tab [l]. numstr-1] +'!!! '+'Error!!! ';
Memo2. Lines [0]: =Memo2. Lines [0] +text;
end;
Error: =true;
Exit;
end;
function TForm1. Lex_Prog_Name: boolean; // 2. имя программы
begin
Lex_Prog_Name: =False;
if (Code_Tab [i]. typ<>'I') and (Code_Tab [i]. Lex<>'; ') then
begin
Err_Synt ('Неправильное имя программы. Ошибочное выражение: "'+Code_Tab [i]. Lex+'"', i);
Exit;
end;
if Code_Tab [i]. Lex='; ' then
begin
Err_Synt ('Отсутствует имя программы после program', i);
Exit;
end;
Lex_Prog_Name: =true;
i: =i+1;
end;
function TForm1. Lex_Descr_List: boolean; // 3. список описаний
begin
Lex_descr_list: =false;
Found: =false;
while Code_Tab [i]. typ='I' do
begin
Found: =true;
if Lex_descr=false then Exit;
if Code_Tab [i]. Lex='; ' then i: =i+1 else
begin
Err_Synt ('Отсутствует точка с запятой после описания переменных ', i-1);
Exit;
end;
end;;
if Found=false then
begin
Err_Synt ('Отсутствует идентификатор в описании ', i);
Exit;
end;
Lex_descr_list: =true;
end;
function TForm1. Lex_descr: boolean; // 4. описание
begin
Lex_descr: =false;
if Lex_name_list=true then
begin
if Code_Tab [i]. Lex=': ' then i: =i+1 else
begin
Err_Synt ('Отсутствует двоеточие перед типом '+Code_Tab [i]. Lex, i);
Exit;
end;
if Lex_type=true then Lex_descr: =true else Exit;
end else Exit;
end;
function TForm1. Lex_name_list: boolean; // 6. список имен
begin
Lex_name_list: =false;
if Code_Tab [i]. typ='I' then i: =i+1 else
begin
Err_Synt ('Ожидается идентификатор ', i);
Exit;
end;
while Code_Tab [i]. Lex=',' do
begin
i: =i+1;
if Code_Tab [i]. Typ='I' then i: =i+1 else
begin
Err_Synt ('Ожидается идентификатор ', i);
Exit;
end;
end;
Lex_name_list: =true;
end;
function TForm1. Lex_type: boolean; // 5. тип
begin
Lex_type: =false;
if (Code_Tab [i]. Lex='integer') then
begin
Lex_type: =true;
i: =i+1
end else
begin
Err_Synt ('Отсутствует тип: integer ', i-1);
Exit;
end;
end;
function TForm1. Lex_oper_list: boolean; // 7. список операторов
begin
Lex_oper_list: =false;
found: =false;
while Lex_oper=true do
begin
Found: =true;
if (Code_Tab [i]. Lex='; ') then i: =i+1 else // Если след. лексема после проверенного оператора ни "; ", ни END, а любая другая лексема.
if Code_Tab [i]. Lex<>'end' then
begin
Err_Synt ('Ожидается точка с запятой после оператора (после лексемы '+Code_Tab [i-1]. Lex+') ', i-1);
Exit;
end;
end;
Lex_oper_list: =true;
if found=false then
begin
Err_Synt ('Не найдены операторы между begin и end', i-1);
Lex_oper_list: =false;
end;
end;
function TForm1. Lex_oper: boolean;
begin
Lex_oper: =false;
if (Lex_assign) or (Lex_repeat_until) then Lex_oper: =true else
if (Code_Tab [i]. Lex='; ') and (Code_Tab [i-1]. Lex='; ') then Lex_oper: =true else // проверяется на пустой оператор, т.е. на ";; ".
if (Code_Tab [i]. Typ='T') and (Code_Tab [i]. Lex<>'end') and (Code_Tab [i]. Lex<>'begin') and (Code_Tab [i]. Lex<>'; ') then Err_Synt ('Лишняя лексема в программе: '+Code_Tab [i]. Lex, i);
end;
function TForm1. Lex_assign: boolean; // 10. присваивание
begin
Lex_assign: =false;
if Code_Tab [i]. typ='I' then
begin
if Code_Tab [i+1]. Lex=': =' then
begin
i: =i+2;
if Lex_Exp=true then Lex_assign: =true else Memo2. Lines [1]: =Memo2. Lines [1] +' в операторе присваивания'
end else Err_Synt ('Ошибка в операторе присваивания', i)
end;
end;
function TForm1. Lex_Exp: boolean; // 11. выражение
begin
Lex_Exp: =false;
if Lex_simple_Exp=true then
begin
if ( (Code_Tab [i]. Lex='=') or (Code_Tab [i]. Lex='>') or (Code_Tab [i]. Lex='<')
or (Code_Tab [i]. Lex='<>') or (Code_Tab [i]. Lex='<=') or (Code_Tab [i]. Lex='>=')) then
begin
i: =i+1;
if Lex_simple_Exp=true then
begin
Lex_Exp: =true;
Exit;
end;
end;
end else Exit;
Lex_Exp: =true; // если простое выражение без знака
end;
function TForm1. Lex_simple_Exp: boolean; // 12. простое выражение
begin
Found: =false;
Lex_simple_Exp: =false;
if Lex_term=true then
begin
Found: =true;
while ( (Code_Tab [i]. Lex='+') or (Code_Tab [i]. Lex='-')) and (Found=true) do
begin
i: =i+1;
if Lex_term=false then
begin
Found: =False;
Err_Synt ('Ожидается константа, идентификатор или выражение ', i-1);
Exit;
end;
end;
if (Code_Tab [i]. Lex=') ') and (Scobka=false) then Err_Synt ('Ожидается открывающаяся скобка в множителе', i)
end;
if Found=true then Lex_simple_Exp: =true;
end;
function TForm1. Lex_Term: boolean; // 13. терм
begin
Found: =false;
Lex_Term: =false;
if Lex_mnozh=true then
begin
Found: =true;
while ( (Code_Tab [i]. Lex='*') or (Code_Tab [i]. Lex='/')) and (Found=true) do
begin
i: =i+1;
if Lex_mnozh=false then Found: =False;
end;
end;
if Found=true then Lex_Term: =true;
end;
function TForm1. Lex_mnozh: boolean; // 14. множитель
begin
Lex_mnozh: =false;
if (Code_Tab [i]. typ='I') or (Code_Tab [i]. typ='C') then
begin
i: =i+1;
Lex_mnozh: =true;
Exit;
end else
begin
if Code_Tab [i]. Lex=' (' then
begin
Scobka: =true;
i: =i+1;
if Lex_simple_Exp=true then
begin
if Code_Tab [i]. Lex=') ' then
begin
i: =i+1;
Lex_mnozh: =true;
end else
begin
Err_Synt ('Ожидается закрывающая скобка в множителе ', i);
Exit;
end;
end;
end else Err_Synt ('Ожидается константа, идентификатор или выражение ', i);
end;
end;
function TForm1. Lex_repeat_until: boolean; // 18. цикл
begin
Lex_repeat_until: =false;
if Code_Tab [i]. Lex='repeat' then
begin
i: =i+1;
if Lex_body=true then begin i: =i+1;
if Code_Tab [i]. Lex='until' then begin i: =i+1;
if Lex_Exp=true then Lex_repeat_until: =true
else Err_Synt ('Ожидается выражение после служебного слова until', i); end
else Err_Synt ('Ожидается служебное слово until', i);
end;
end;
end;
function TForm1. Lex_body: boolean; // 20. тело цикла
begin
Lex_body: =false;
if Lex_oper=true then
begin
Lex_body: =true;
Exit;
end else
if Code_Tab [i]. Lex='begin' then
begin
i: =i+1;
if Code_Tab [i]. Lex='; ' then
begin
Err_Synt ('После begin недопустим символ "; "', i);
Exit;
end;
if Lex_oper_list=true then
begin
if (Code_Tab [i]. Lex='end') and (Code_Tab [i+1]. Lex<>'; ') then
begin
Lex_body: =true;
i: =i+1;
end else Err_Synt ('Ожидается служебное слово end после блока операторов', i-1)
end;
end;
end;
3.5 Результаты тестирования синтаксического анализатора
Тестирование выполнялось на результатах работы лексического анализатора, который работает безошибочно и был протестирован ранее.
| Ошибка | Текст программы | Сообщения от анализатора |
| В объявлении имени программы | prom var15; . . program var15. | Отсутствует служебное слово program или в нём ошибка |
| В описании | program var15; n: integer; . . program var15; var,: integer; . . program var15; var n: integer . . var n integer . . var n:; | Отсутствует служебное слово var после заголовка программы Отсутствует идентификатор в описании Отсутствует точка с запятой после описания переменных Отсутствует двоеточие перед типом integer Отсутствует тип: integer |
| В begin. end | . . begin; . . var n: integer; n: =$+00; . . until n<$-0A; | После begin недопустим символ точка с запятой Отсутствует служебное слово begin после описания переменных Отсутствует служебное слово end в конце программы |
| В имени программы | ... program $+00;. | Неправильное имя программы. Ошибочное выражение: "$+00" |
| В операторе присваивания | ... n: $+00; | Ошибка в операторе присваивания |
| В выражении | ... n: =- (-XII);... | Ожидается константа, идентификатор или выражение |
| В цикле | ... repeat n: =n- (-XII); n<$-0A;. | Ожидается служебное слово until |
| В теле программы | ... n: =$+00. | Ожидается точка с запятой после оператора (после лексемы $+00) |
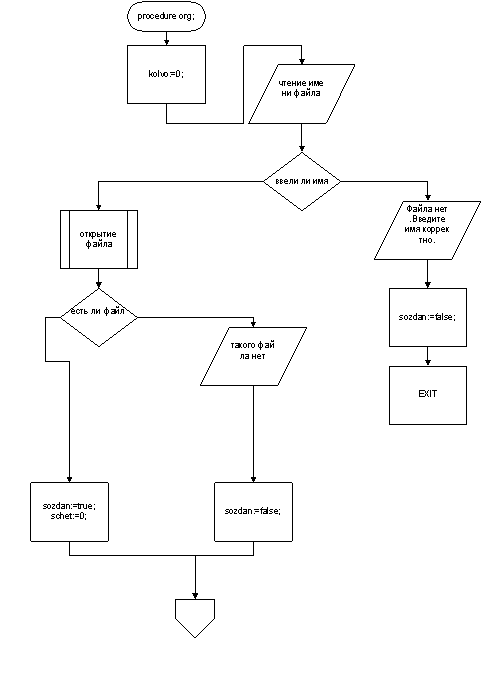
4. Реализация двухфазного компилятора
Главные процедуры лексического и синтаксического анализатора - это, соответственно, процедуры N5. Click и N6. Click главной формы программы. Из них вызываются остальные подпрограммы
Текст исходная программа выводится в окне в верхнем левом углу формы. Если лексический анализ текста (процедура N5. Click) выявил ошибку, то она выводится в окне сообщёний об ошибках и анализ прекращается.
Лексический анализатор выводит на форму таблицы констант, идентификаторов, терминальных символов и кодов лексем в областях вывода StringGrid1, StringGrid2, StringGrid3 и StringGrid4.
После синтаксического анализа переданной таблицы кодов лексем в окне сообщений об ошибках синтаксического анализатора содержатся сообщения от распознающих процедур разного уровня, затронутых обнаруженной ошибкой (см п.3.5)
Ошибок при двухфазном анализе не выявлено, если область вывода лексических ошибок пуста, а для синтаксических - содержит текст "Ошибок нет".
Внешний вид окна программы представлен на рис.7.
4.1 Результаты тестирования двухфазного компилятора
полностью совпадают с результатами тестирования лексического и синтаксического анализатора по отдельности, проведённых последовательно.
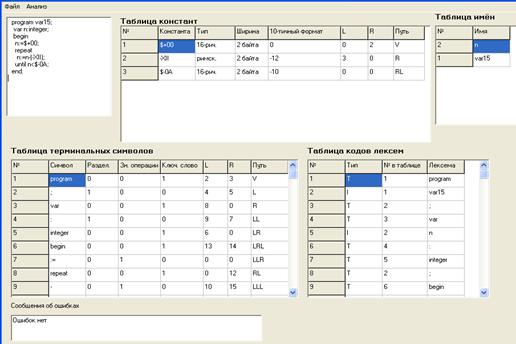
рис.7. Внешний вид окна программы
5. Описание программы
5.1 Общие сведения и функциональное назначение
Данная программа предназначена для лексического и синтаксического анализа небольших (<1 МБ) текстов программ на заданном диалекте подмножества языка Pascal.
Программа написана на языке Delphi в среде разработки Delphi 7.
Программа предназначена для выявления наличия лексических и синтаксических ошибок во входном тексте программы.
5.2 Вызов и загрузка
Запуск файла lex1. exe.
5.3 Входные данные
Исходный текст программы, в текстовом файле ‘вар14. txt’ или в окне ввода исходного текста.
5.4 Выходные данные
Сообщение о первой ошибке, выявленной лексическим анализом, а при отсутствии таковых - вывод сообщения о первой обнаруженной синтаксической ошибке, при отсутствии ошибок - соответствующее сообщение.
5.5 Описание логической структуры программы
5.5.1 Файлы программы
Программа состоит из файлов:
lex. pas
lex. ~dfm
5.5.2 Общее описание работы программы
Основная форма программы - в файле lex. dfm, алгоритм её работы - в файле lex. pas.
Список строк исходного текста программы загружается в массив SA. Процедура Select_lex выполняет выделение из текста лексем. Таблицы констант, идентификаторов, терминальных символов и кодов лексем хранятся в массивах Const_Tab, Id_Tab, Term_Tab и Code_Tab. Распознавателем идентификаторов является функция Ident, 16-ричных констант - функция Const16, логических констант - функция Boolconst. Распознавателем терминальных символов является функция Termin. Если лексема ошибочна, то она заносится в таблицу кодов лексем с типом E и выдаётся сообщение об ошибке (процедура Err_Lex). Все эти подпрограммы вызываются из процедуры TForm1. N5Click (соответствует выбору пункта меню Анализатор/Лексический). В ней производится обнуление всех таблиц, вызов функции выделения лексем и процедуры WriteLex (см. ниже).
Поиск идентификаторов, констант и терминальных символов в соответствующих таблицах производится, соответственно, процедурами Search_Ident, Search_Const и Search_Term, добавление в таблицы - процедурами Add_Ident, Add_Const и Add_Term. Все они вызываются из процедуры WriteLex, входными данными для которой являются результаты распознавания лексем, т.е. типы лексем. Запись в таблицу кодов лексем производится процедурой WriteCode, вывод всех таблиц на экран - процедурой vyvod.
Перевод констант в десятичную форму производится процедурой perevod.
Процедура начала синтаксического анализа N6. Click вызывает процедуру Syntax, которая, в свою очередь, вызывает процедуру Lex_Progr, далее реализуется синтаксический анализ методом рекурсивного спуска.
Текст программы лексическому анализатору передаётся из поля в верхнем правом углу главного окна при выборе пункта меню "Анализ/Лексический", куда он может вводиться с клавиатуры или загружать из файла "вар14. txt" (он обязательно должен находиться в каталоге с программой) при создании формы. Полученный список лексем передаётся синтаксическому анализатору, а найденные им ошибки - в поле в левой части окна.
Список использованной литературы
1. Методические указания к лабораторным работам по СПО.
2. Курс лекций по дисциплине "Системное программное обеспечение".
3. А.Ю. Молчанов "Системное программное обеспечение", СПб, 2003 г.
4. Ю.Г. Карпов "Теория автоматов", СПб, 2002 г.
5. В.В. Фаронов“Delphi. Программирование на языке высокого уровня", Питер, 2004 г.
Приложение: текст программы
unit lex;
interface
uses
Windows, Messages, SysUtils, Variants, Classes, Graphics, Controls, Forms,
Dialogs, Menus, StdCtrls, Grids;
type
TVyh = Record // Тип таблицы кодов лексем
nomer: integer; // Номер
typ: char; // Тип лексемы
Num: integer; // Номер в таблице
Lex: String; // Лексема
numstr: integer; // Номер строки
end;
TTerm = Record // тип таблицы терминальных символов
nomer: integer; // номер
Lex: String; // Лексема
razd: byte; // Разделитель?
oper: byte; // Операция?
slug: byte; // Служебное слово?
Left: integer; // Левая ветвь дерева.
Right: integer; // Правая ветвь дерева.
Way: string;
end;
TConst = Record // Тип таблицы констант
nomer: integer; // Номер
value: string; // Само значение лексемы.
Typ: string; // Тип лексемы
Width: string; // Ширина константы
Val10: string; // 10-тичный формат константы
Left: integer; // Левая ветвь дерева.
Right: integer; // Правая ветвь дерева.
Way: string;
end;
TId = Record // таблица имен
nomer: integer; // номер лексемы
lex: string; // лексема
ssylka: integer; // ссылка на элемент цепочки
end;
TForm1 = class (TForm)
MainMenu1: TMainMenu;
N1: TMenuItem;
N2: TMenuItem;
N3: TMenuItem;
N4: TMenuItem;
N5: TMenuItem;
OpenDialog1: TOpenDialog;
Memo1: TMemo;
N6: TMenuItem;
StringGrid1: TStringGrid;
Label1: TLabel;
StringGrid2: TStringGrid;
Label2: TLabel;
StringGrid3: TStringGrid;
StringGrid4: TStringGrid;
Label3: TLabel;
Label4: TLabel;
Memo2: TMemo;
Label5: TLabel;
procedure N2Click (Sender: TObject);
procedure N3Click (Sender: TObject);
procedure N5Click (Sender: TObject);
procedure vyvod;
procedure Err_lex;
procedure Syntax;
procedure Err_Synt (text: string; l: integer);
function Lex_Progr: boolean;
function Lex_Prog_Name: boolean;
function Lex_Descr_List: boolean;
function Lex_descr: boolean;
function Lex_name_list: boolean;
function Lex_type: boolean;
function Lex_oper_list: boolean;
function Lex_oper: boolean;
function Lex_assign: boolean;
function Lex_Exp: boolean;
function Lex_simple_Exp: boolean;
function Lex_Term: boolean;
function Lex_mnozh: boolean;
function Lex_repeat_until: boolean;
function Lex_body: boolean;
procedure N6Click (Sender: TObject);
private
{ Private declarations }
public
{ Public declarations }
end;
const
MaxNum=100; // Максимальное число лексем
deleter= ['. ',' ',' (',') ','{','}',',','<','>','"','? ','! ','*','&','^', {'%','$',}' [','] ',': ','; ','=','-','+','/', '\',''''] ; // разделители лексем
words: Array [1. .14] of string [7] = ('program','var','then','begin','for','to','do','if','end','repeat','until','real','integer', 'else'); // Массив служебных слов
razdel: Array [1. .8] of char= (',','; ',': ',' (',') ',' [','] ','. '); // массив разделителей
operacii: Array [1. .11] of string [2] = (': =','>=','<=','<>','+','-','/','*','>','<','='); // массив операций
cifra= ['0'. '9'] ; // цифры
bukva= ['A'. 'F'] ;
var
Form1: TForm1;
FA,FName: textfile;
SA: array [1. .100] of string;
SS,Name,Constant: string;
Dlina: integer;
Code_tab: array [1. MaxNum] of TVyh; // Таблица кодов лексем
Term_tab: array [1. MaxNum] of TTerm; // Таблица терминальныз символов
Id_tab: array [1. MaxNum] of TId; // Таблица идентификаторов
Const_tab: array [1. .50] of TConst; // Таблица констант
Lexem,s,typel: string; // Лексема, Текст ошибки, Строка программы, Тип лексемы
i,j,k,l,m,n,y,String_counter,constyes,termyes,hesh, // счетчики циклов и строк
NumLex,{Число лексем}NumId,{Число идентификаторов}NumTerm,{Число терминальных символов}NumConst,{Число различных констант}
NumErr{Число ошибочных лексем}: integer;
Error,Found,Flag,Scobka: boolean; // Флаги
str16: string;
k1,kod: integer;
implementation
uses lex2;
{$R *. dfm}
procedure TForm1. N2Click (Sender: TObject);
var i: integer;
begin
OpenDialog1. Filter: ='*. txt';
if opendialog1. Execute and fileExists (openDialog1. FileName)
then
begin
Assignfile (FA, OpenDialog1. FileName);
Reset (FA);
Memo1. Lines. clear;
i: =1;
while not EOF (FA) do
begin
readln (Fa,SA [i]);
Memo1. Lines. Add (SA [i]);
i: =i+1;
end;
Closefile (FA);
end;
end;
// процедура перевода констант в десятичную форму
procedure perevod (SS: string; var Str16: string);
var ch3,ch4,ch, i: integer;
zn: string;
begin
ch: =0; // для римских констант
if (SS [2] ='X') or (SS [2] ='V') or (SS [2] ='I') then
begin
zn: =SS [1] ;
delete (SS,1,1);
while Length (SS) <>0 do
begin
if SS [1] ='X' then begin ch: =ch+10; delete (SS,1,1); end
else begin
if SS [1] ='V'then begin ch: =ch+5; delete (SS,1,1); end
else begin
if ( (SS [1] ='I') and (SS [2] ='I')) or ( (SS [1] ='I') and (SS [2] ='')) then begin ch: =ch+1; delete (SS,1,1); end
else begin
if (SS [1] ='I') and (SS [2] ='X') then begin ch: =ch+9; delete (SS,1,2); end
else begin
if (SS [1] ='I') and (SS [2] ='V') then begin ch: =ch+4; delete (SS,1,2); end;
end; end; end; end; end;
str16: =zn+IntToStr (ch);
exit;
end;
// для 16-рич. констант
If SS [3] in ['0'. '9']
then
ch3: =StrToInt (SS [3]) *16
else
if SS [3] in ['A'. 'F']
then
begin
ch3: =ord (SS [3]);
case ch3 of
65: ch3: =10*16;
66: ch3: =11*16;
67: ch3: =12*16;
68: ch3: =13*16;
69: ch3: =14*16;
70: ch3: =15*16;
end;
end;
If SS [4] in ['0'. '9']
then
ch4: =StrToInt (SS [4])
else
if SS [4] in ['A'. 'F']
then
begin
ch4: =ord (SS [4]);
case ch4 of
65: ch4: =10;
66: ch4: =11;
67: ch4: =12;
68: ch4: =13;
69: ch4: =14;
70: ch4: =15;
end;
end;
ch: =ch3+ch4;
If (SS [3] ='0') and (SS [4] ='0')
then Str16: =IntToStr (ch)
else Str16: =SS [2] +IntToStr (ch);
end;
procedure TForm1. N3Click (Sender: TObject);
begin
close;
end;
function Select_Lex (S: string; {исх. строка} var Rez: string; {лексема}N: integer {текущая позиция}): integer;
label 1;
begin // функция выбора слов из строки
k: = Length (S);
Rez: ='';
i: =N; // точка продолжения в строке
while (S [i] =' ') and (i<= k) do i: =i+1; // пропуск ' '
while not (S [i] in deleter) and (i<= k) do // накопление лексемы
begin
if s [i] ='$' then
begin
Rez: =s [i] +s [i+1] ;
i: =i+2;
end
else begin
1: Rez: =Rez+s [i] ;
i: =i+1;
end;
end;
if Rez='' then
begin
if (s [i] =': ') then
begin
if (s [i+1] ='=') then // в случае операции из двух символов
begin
Rez: =s [i] +s [i+1] ;
Select_Lex: =i+2;
end
else
begin
Rez: =s [i] ;
Select_Lex: =i+1;
end;
end else
begin
if ( (s [i] ='+') or (s [i] ='-')) and (s [i-1] =' (')
then begin
Rez: =s [i] +s [i+1] ;
i: =i+2;
goto 1;
end
else begin
Rez: =s [i] ;
Select_Lex: =i+1;
end; end;
end else Select_Lex: =i;
end;
procedure Add_Const (Curr_term: integer; str_lex: string); // Процедура добавления идентификаторов в дерево
begin
if NumConst=1 then // Если корень дерева еще не создан, то создаем его.
begin
perevod (str_lex,str16);
Const_tab [NumConst]. value: =str_lex;
Const_tab [NumConst]. nomer: =NumConst;
Const_tab [NumConst]. Val10: =str16;
Const_tab [NumConst]. Left: =0;
Const_tab [NumConst]. Right: =0;
Const_tab [NumConst]. Way: ='V';
Exit;
end;
if (CompareStr (Const_tab [Curr_term]. value,str_lex) >0) then // Если значение текущего узла дерева больше добавляемого
if Const_tab [Curr_term]. Left=0 then // если у этого элемента дерева нет левого указателя, то
begin
perevod (str_lex,str16);
Const_tab [Curr_term]. Left: =NumConst; // Создание левого элемента.
Const_tab [NumConst]. value: =str_lex;
Const_tab [NumConst]. nomer: =NumConst;
Const_tab [NumConst]. Val10: =str16;
Const_tab [NumConst]. Left: =0;
Const_tab [NumConst]. Right: =0;
Const_tab [NumConst]. Way: =Const_tab [NumConst]. Way+'L';
end else begin
Const_tab [NumConst]. Way: =Const_tab [NumConst]. Way+'L';
Add_Const (Const_tab [Curr_term]. Left,str_lex); // Если левый указатель существует, то вызываем уже функцию для левого указателя.
end;
if (CompareStr (Const_tab [Curr_term]. value,str_lex) <0) then // если у этого элемента дерева нет правого указателя, то
if Const_tab [Curr_term]. Right=0 then
begin
perevod (str_lex,str16);
Const_tab [Curr_term]. Right: =NumConst; // Создаем правый элемент.
Const_tab [NumConst]. value: =str_lex;
Const_tab [NumConst]. nomer: =NumConst;
Const_tab [NumConst]. Val10: =str16;
Const_tab [NumConst]. Left: =0;
Const_tab [NumConst]. Right: =0;
Const_tab [NumConst]. Way: =Const_tab [NumConst]. Way+'R';
end else begin
Const_tab [NumConst]. Way: =Const_tab [NumConst]. Way+'R';
Add_Const (Const_tab [Curr_term]. Right,str_lex); // Если правый указатель существует, то вызываем уже функцию для правого указателя.
end;
end;
procedure Add_Term (Curr_term: integer; str_lex: string); // Процедура добавления идентификаторов в дерево
begin
if NumTerm=1 then // Если корень дерева еще не создан, то создаем его.
begin
Term_tab [NumTerm]. lex: =str_lex;
Term_tab [NumTerm]. nomer: =NumTerm;
Term_tab [NumTerm]. Left: =0;
Term_tab [NumTerm]. Right: =0;
Term_tab [NumTerm]. Way: ='V';
Exit;
end;
if (CompareStr (Term_tab [Curr_term]. lex,str_lex) >0) then // Если значение текущего узла дерева больше добавляемого
if Term_tab [Curr_term]. Left=0 then // если у этого элемента дерева нет левого указателя, то
begin
Term_tab [Curr_term]. Left: =NumTerm; // Создание левого элемента.
Term_tab [NumTerm]. lex: =str_lex;
Term_tab [NumTerm]. nomer: =NumTerm;
Term_tab [NumTerm]. Left: =0;
Term_tab [NumTerm]. Right: =0;
Term_tab [NumTerm]. Way: =Term_tab [NumTerm]. Way+'L';
end else begin
Term_tab [NumTerm]. Way: =Term_tab [NumTerm]. Way+'L';
Add_Term (Term_tab [Curr_term]. Left,str_lex); // Если левый указатель существует, то вызываем уже функцию для левого указателя.
end;
if (CompareStr (Term_tab [Curr_term]. lex,str_lex) <0) then // если у этого элемента дерева нет правого указателя, то
if Term_tab [Curr_term]. Right=0 then
begin
Term_tab [Curr_term]. Right: =NumTerm; // Создаем правый элемент.
Term_tab [NumTerm]. lex: =str_lex;
Term_tab [NumTerm]. nomer: =NumTerm;
Term_tab [NumTerm]. Left: =0;
Term_tab [NumTerm]. Right: =0;
Term_tab [NumTerm]. Way: =Term_tab [NumTerm]. Way+'R';
end else begin
Term_tab [NumTerm]. Way: =Term_tab [NumTerm]. Way+'R';
Add_Term (Term_tab [Curr_term]. Right,str_lex); // Если правый указатель существует, то вызываем уже функцию для правого указателя.
end;
end;
procedure Add_Ident (str: string); // процедура добавления константы
var i: integer;
begin
kod: =Length (str) +2;
hesh: =0;
for i: =1 to Length (str) do hesh: =hesh+ord (str [i]); // вычисление хэш
hesh: =round (hesh/kod); // метод деления
while (Id_tab [hesh]. lex<>'') and (hesh<maxnum) do // пока ячейка занята
begin
Id_tab [hesh]. ssylka: =hesh+1;
hesh: =hesh+1;
end;
Id_tab [hesh]. nomer: =Numid; // запись данных
Id_tab [hesh]. lex: =str;
end;
function Search_Ident (str: string): integer; // функция поиска терминала
var i: integer;
label 1;
begin
kod: =Length (str) +2;
hesh: =0;
for i: =1 to Length (str) do hesh: =hesh+ord (str [i]); // вычисление хэш
hesh: =round (hesh/kod);
1: if str=Id_tab [hesh]. lex then Search_Ident: =Id_tab [hesh]. nomer else // поиск идентификатора
begin
if Id_tab [hesh]. ssylka=0 then Search_Ident: =0 else
begin
hesh: =Id_tab [hesh]. ssylka;
goto 1;
end;
end;
end;
procedure Search_Const (Curr_term: integer; str_lex: string); // Процедура поиска лексем в дереве идентификаторов
begin
Constyes: =0; // флаг: найдена ли лексема
if (NumConst<>0) and (str_lex<>'') then
begin
if (CompareStr (Const_tab [Curr_term]. value,str_lex) >0) and (Const_tab [Curr_term]. Left<>0) then
Search_Const (Const_tab [Curr_term]. Left,str_lex); // рекурсивный "спуск по дереву"
if (CompareStr (Const_tab [Curr_term]. value,str_lex) <0) and (Const_tab [Curr_term]. Right<>0) then
Search_Const (Const_tab [Curr_term]. Right,str_lex);
if Const_tab [Curr_term]. value=str_lex then Constyes: =Const_tab [Curr_term]. nomer;
end;
end;
procedure Search_Term (Curr_term: integer; str_lex: string); // Процедура поиска лексем в дереве идентификаторов
begin
Termyes: =0; // флаг: найдена ли лексема
if (NumTerm<>0) and (str_lex<>'') then
begin
if (CompareStr (Term_tab [Curr_term]. lex,str_lex) >0) and (Term_tab [Curr_term]. Left<>0) then
Search_Term (Term_tab [Curr_term]. Left,str_lex); // рекурсивный "спуск по дереву"
if (CompareStr (Term_tab [Curr_term]. lex,str_lex) <0) and (Term_tab [Curr_term]. Right<>0) then
Search_Term (Term_tab [Curr_term]. Right,str_lex);
if Term_tab [Curr_term]. lex=str_lex then Termyes: =Term_tab [Curr_term]. nomer;
end;
end;
// функция распознавания 16-рич. констант
function FConst (str: string): integer;
var
sost: byte;
begin
sost: =0;
if str [1] ='$' then // распознаём символ '$'
begin
sost: =1;
delete (str,1,1);
end
else exit;
if (str [1] ='+') or (str [1] ='-') then // распознаём знак
begin
sost: =2;
delete (str,1,1)
end
else begin sost: =4; exit; end;
if str='' then exit;
while length (str) >0 do begin
if (str [1] in cifra) or (str [1] in bukva)
then sost: =2 // распознаём буквы или цифры
else begin sost: =4; exit;
end;
delete (str,1,1);
end;
sost: =3;
if sost=3 then FConst: =1 else FConst: =-1;
end;
function termin: integer; // распознаватель терминальных символов
begin
termin: =-1;
for k: =1 to 14 do if Words [k] =Lexem then termin: =3;
for k: =1 to 8 do if Razdel [k] =Lexem then termin: =1;
for k: =1 to 11 do if Operacii [k] =Lexem then termin: =2;
end;
function Rome (str: string): integer; // распознаватель римских констант
var sost: byte;
begin
sost: =0;
if (str [1] ='-') or (str [1] ='+')
then begin sost: =12; delete (str,1,1); end;
if str='' then exit;
if str [1] ='X'
then begin sost: =1; delete (str,1,1) end
else begin
if str [1] ='V' then begin sost: =2; delete (str,1,1) end
else begin
if str [1] ='I' then begin sost: =3; delete (str,1,1) end
else begin sost: =4; exit; end; end; end;
while Length (str) <>0 do begin
case sost of
1: if str [1] ='X'
then begin sost: =5; delete (str,1,1) end
else begin
if str [1] ='V' then begin sost: =2; delete (str,1,1) end
else begin
if str [1] ='I' then begin sost: =3; delete (str,1,1) end
else begin sost: =4; exit; end; end; end;
2: if str [1] ='I'
then begin sost: =7; delete (str,1,1) end
else begin sost: =4; exit; end;
3: if str [1] ='X'
then begin sost: =8; delete (str,1,1) end
else begin
if str [1] ='V' then begin sost: =9; delete (str,1,1) end
else begin
if str [1] ='I' then begin sost: =10; delete (str,1,1) end
else begin sost: =4; exit; end; end; end;
4: exit;
5: if str [1] ='X'
then begin sost: =6; delete (str,1,1) end
else begin
if str [1] ='V' then begin sost: =2; delete (str,1,1) end
else begin
if str [1] ='I' then begin sost: =3; delete (str,1,1) end
else begin sost: =4; exit; end; end; end;
6: if str [1] ='V'
then begin sost: =2; delete (str,1,1) end
else begin
if str [1] ='I' then begin sost: =3; delete (str,1,1) end
else begin sost: =4; exit; end; end;
7: if str [1] ='I'
then begin sost: =10; delete (str,1,1) end
else begin sost: =4; exit; end;
8: begin sost: =4; exit; end;
9: begin sost: =4; exit; end;
10: if str [1] ='I'
then begin sost: =11; delete (str,1,1) end
else begin sost: =4; exit; end;
11: begin sost: =4; exit; end;
end;
end;
if (sost=4) or (sost=12) then Rome: =-1 else Rome: =1;
end;
// функция распознавания идентификаторов
function Ident (str: string): integer;
var
sost: byte;
begin
sost: =0; // реализация конечного автомата
if str [1] in ['a'. 'z'] then
begin
sost: =1;
delete (str,1,1)
end
else exit;
while length (str) >0 do begin
if str [1] in ['a'. 'z','0'. '9','_']
then begin sost: =1; delete (str,1,1); end
else begin sost: =3; exit; end;
end;
sost: =2;
if sost=2 then ident: =1 else ident: =-1;
end;
procedure WriteCode (nomer: integer; lex: string; typ: char; num: integer); // запись в таблицу кодов лексем
begin
Code_Tab [NumLex]. nomer: =nomer;
Code_Tab [NumLex]. Lex: =lex;
Code_Tab [NumLex]. typ: =typ;
Code_Tab [NumLex]. Num: =num;
Code_Tab [NumLex]. numstr: =string_counter+1;
end;
procedure WriteLex (typelex: char); // запись лексем в таблицы
begin
case typelex of
'C': begin // если лексема-16-рич. константа
NumLex: =NumLex+1;
Search_Const (1,Lexem);
if Constyes=0 then // если лексема не найдена
begin
NumConst: =NumConst+1;
Add_Const (1,Lexem);
Const_tab [NumConst]. Typ: ='16-рич. ';
Const_tab [Numconst]. Width: ='2 байта';
WriteCode (NumLex,Lexem,'C',NumConst);
end else // если лексема найдена
begin
WriteCode (NumLex,Lexem,'C',Constyes);
end;
end;
'M': begin // если лексема-римская константа
NumLex: =NumLex+1;
Search_Const (1,Lexem);
if Constyes=0 then // если лексема не найдена
begin
NumConst: =NumConst+1;
Add_Const (1,Lexem);
Const_tab [NumConst]. Typ: ='римск. ';
Const_tab [Numconst]. Width: ='2 байта';
WriteCode (NumLex,Lexem,'C',NumConst);
end else // если лексема найдена
begin
WriteCode (NumLex,Lexem,'C',Constyes);
end;
end;
'I': begin // если лексема-идентификатор
NumLex: =NumLex+1;
y: =Search_Ident ({1,}Lexem);
if y=0 then // если лексема не найдена
begin
NumId: =NumId+1;
WriteCode (NumLex,Lexem,'I',NumId);
Add_Ident (Lexem);
end else WriteCode (NumLex,Lexem,'I',y); // если лексема найдена
end;
'K': begin // если лексема-служебное слово
NumLex: =NumLex+1;
Search_Term (1,Lexem);
if Termyes=0 then // если лексема не найдена
begin
NumTerm: =NumTerm+1;
Add_Term (1,Lexem);
Term_tab [Numterm]. razd: =0;
Term_tab [Numterm]. oper: =0;
Term_tab [Numterm]. slug: =1;
WriteCode (NumLex,Lexem,'T',NumTerm);
end else WriteCode (NumLex,Lexem,'T',Termyes); // если лексема найдена
end;
'R': begin // если лексема-разделитель
NumLex: =NumLex+1;
Search_Term (1,Lexem);
if Termyes=0 then // если лексема не найдена
begin
NumTerm: =NumTerm+1;
Add_Term (1,Lexem);
Term_tab [NumTerm]. razd: =1;
Term_tab [NumTerm]. oper: =0;
Term_tab [NumTerm]. slug: =0;
WriteCode (NumLex,Lexem,'T',NumTerm)
end else WriteCode (NumLex,Lexem,'T',Termyes) // если лексема найдена
end;
'O': begin // если лексема-знак операция
NumLex: =NumLex+1;
Search_Term (1,Lexem);
if Termyes=0 then // если лексема не найдена
begin
NumTerm: =NumTerm+1;
Add_Term (1,Lexem);
Term_tab [Numterm]. razd: =0;
Term_tab [Numterm]. oper: =1;
Term_tab [Numterm]. slug: =0;
WriteCode (NumLex,Lexem,'T',NumTerm)
end else WriteCode (NumLex,Lexem,'T',Termyes) // есди лексема найдена
end;
end;
end;
procedure TForm1. N5Click (Sender: TObject);
var i,pip: integer;
begin
for k: =1 to numid do // обнуление таблицы идентификаторов
begin
id_tab [k]. lex: ='0';
id_tab [k]. nomer: =0;
id_tab [i]. ssylka: =0;
end;
for i: =1 to numlex do // обнуление выходной таблицы
begin
Code_Tab [i]. Lex: ='';
Code_Tab [i]. typ: =#0;
Code_Tab [i]. Num: =0;
Code_Tab [i]. nomer: =0;
end;
for i: =0 to numconst do // обнуление таблицы констант
begin
Const_tab [i]. nomer: =0;
Const_tab [i]. value: ='';
Const_tab [i]. Typ: ='';
Const_tab [i]. Width: ='';
Const_tab [i]. Val10: ='';
Const_tab [k]. Left: =0;
Const_tab [k]. Right: =0;
Const_tab [k]. Way: ='';
end;
for i: =1 to numterm do
begin
Term_tab [i]. nomer: =0;
Term_tab [i]. Lex: ='';
Term_tab [i]. razd: =0;
Term_tab [i]. oper: =0;
Term_tab [i]. slug: =0;
Term_tab [k]. Left: =0;
Term_tab [k]. Right: =0;
Term_tab [k]. Way: ='';
end;
// инициализация
NumLex: =0; NumId: =0; NumConst: =0; NumErr: =0; NumTerm: =0;
Error: =false; Found: =false;
i: =0; j: =0; k: =0; y: =0;
String_counter: =0;
Memo2. Lines. Clear;
N6. Enabled: =true;
while string_counter<=Memo1. Lines. Count do // цикл по строкам файла
begin
n: =1;
m: =1;
s: =Form1. Memo1. Lines. Strings [string_counter] ;
for l: =1 to 2 do
while m<=Length (s) do // цикл по строке
begin
n: =m;
m: =Select_Lex (s,Lexem,n);
if (Lexem<>'') and not (Lexem [1] in [#0. #32]) then
begin
if FConst (Lexem) =1 then WriteLex ('C') else // вызов процедуры записи
if Termin=3 then WriteLex ('K') else
if Rome (Lexem) =1 then WriteLex ('M') else
if Ident (Lexem) =1 then WriteLex ('I') else
if Termin=1 then WriteLex ('R') else
if Termin=2 then WriteLex ('O')
else Err_lex;
end;
end;
string_counter: =string_counter+1;
end;
vyvod; // вызов процедуры вывода
end;
procedure TForm1. vyvod; // Вывод результатов
var
f: textfile; // выходной файл
begin
StringGrid1. RowCount: =NumConst+1; // определение числа строк в таблицах
StringGrid2. RowCount: =NumId+1;
StringGrid3. RowCount: =NumTerm+1;
StringGrid4. RowCount: =NumLex+1;
StringGrid1. Cells [0,0]: ='№'; StringGrid1. Cells [1,0]: ='Константа'; StringGrid1. Cells [2,0]: ='Тип';
StringGrid1. Cells [3,0]: ='Ширина'; StringGrid1. Cells [4,0]: ='10-тичный формат';
StringGrid1. Cells [5,0]: ='L'; StringGrid1. Cells [6,0]: ='R';
StringGrid1. Cells [7,0]: ='Путь'; // определение заголовков
for k: =1 to NumConst do // вывод таблицы констант
begin
StringGrid1. cells [0,k]: = Inttostr (Const_Tab [k]. nomer);
StringGrid1. cells [1,k]: = Const_Tab [k]. value;
StringGrid1. cells [2,k]: = Const_Tab [k]. Typ;
StringGrid1. cells [3,k]: = Const_Tab [k]. Width;
StringGrid1. cells [4,k]: = Const_Tab [k]. Val10;
StringGrid1. cells [5,k]: = Inttostr (Const_Tab [k]. Left);
StringGrid1. cells [6,k]: = Inttostr (Const_Tab [k]. Right);
StringGrid1. cells [7,k]: = Const_Tab [k]. Way;
end;
AssignFile (F,'Const. txt'); // запись в файл таблицы констант
Rewrite (F);
for k: =1 to NumConst do
Writeln (F, StringGrid1. cells [0,k] +' '+StringGrid1. cells [1,k] +' '+StringGrid1. cells [2,k] +' '+StringGrid1. cells [3,k]);
CloseFile (F);
StringGrid2. Cells [0,0]: ='№'; StringGrid2. Cells [1,0]: ='Имя'; // определение заголовков
k: =0;
k1: =0;
while k<numid do // вывод таблицы идентификаторов
begin
if Id_tab [k1]. lex<>'' then
begin
StringGrid2. cells [0,k+1]: =IntToStr (Id_tab [k1]. nomer);
StringGrid2. cells [1,k+1]: =Id_Tab [k1]. lex;
k: =k+1;
end;
k1: =k1+1;
end;
AssignFile (F,'Ident. txt'); // запись в файл таблицы констант
Rewrite (F);
for k: =1 to NumId do Writeln (F, StringGrid2. cells [0,k] +' '+StringGrid2. cells [1,k]);
CloseFile (F);
StringGrid3. Cells [0,0]: ='№'; StringGrid3. Cells [1,0]: ='Символ'; StringGrid3. Cells [2,0]: ='Раздел. ';
StringGrid3. Cells [3,0]: ='Зн. операции'; StringGrid3. Cells [4,0]: ='Ключ. слово';
StringGrid3. Cells [5,0]: ='L'; StringGrid3. Cells [6,0]: ='R';
StringGrid3. Cells [7,0]: ='Путь'; // определение заголовков
for k: =1 to NumTerm do // вывод таблицы терминальных символов
begin
StringGrid3. cells [0,k]: = Inttostr (Term_Tab [k]. nomer);
StringGrid3. cells [1,k]: = Term_Tab [k]. lex;
StringGrid3. cells [2,k]: = Inttostr (Term_Tab [k]. razd);
StringGrid3. cells [3,k]: = Inttostr (Term_Tab [k]. oper);
StringGrid3. cells [4,k]: = Inttostr (Term_Tab [k]. slug);
StringGrid3. cells [5,k]: = Inttostr (Term_Tab [k]. Left);
StringGrid3. cells [6,k]: = Inttostr (Term_Tab [k]. Right);
StringGrid3. cells [7,k]: = Term_Tab [k]. Way;
end;
AssignFile (F,'Term. txt'); // запись в файл таблицы терминальных символов
Rewrite (F);
for k: =1 to NumTerm do Writeln (F, StringGrid3. cells [0,k] +' '+StringGrid3. cells [1,k] +' '+StringGrid3. cells [2,k] +' '+StringGrid3. cells [3,k] +' '+StringGrid3. cells [4,k]);
CloseFile (F);
StringGrid4. Cells [0,0]: ='№'; StringGrid4. Cells [1,0]: ='Тип'; StringGrid4. Cells [2,0]: ='№ в таблице'; StringGrid4. Cells [3,0]: ='Лексема'; // определение заголовков
for k: =1 to NumLex do // вывод таблицы кодов лексем
begin
StringGrid4. cells [0,k]: = Inttostr (Code_Tab [k]. nomer);
StringGrid4. cells [1,k]: = Code_Tab [k]. typ;
StringGrid4. cells [2,k]: = Inttostr (Code_Tab [k]. num);
StringGrid4. cells [3,k]: = Code_Tab [k]. lex;
end;
AssignFile (F,'Cod. txt'); // запись в файл выходной таблицы
Rewrite (F);
for k: =1 to NumLex do Writeln (F, StringGrid4. cells [0,k] +' '+StringGrid4. cells [1,k] +' '+StringGrid4. cells [2,k] +' '+StringGrid4. cells [3,k]);
CloseFile (F);
end;
procedure TForm1. Err_Lex; // процедура вывода ошибки в лексеме
begin
Memo2. Lines. Add ('В строке №'+Inttostr (String_counter+1) +' ошибочная лексема '+Lexem);
NumErr: =NumErr+1;
NumLex: =NumLex+1;
Code_Tab [NumLex]. nomer: =NumLex;
Code_Tab [NumLex]. Lex: =Lexem;
Code_Tab [NumLex]. typ: ='E';
Code_Tab [NumLex]. Num: =NumErr;
Exit;
end;
procedure TForm1. N6Click (Sender: TObject);
begin
Syntax;
end;
procedure TForm1. Syntax;
begin
i: =1; // инициализация
Error: =false;
Scobka: =false;
Memo2. Clear;
if (Lex_Progr=true) and (Error<>true) then Memo2. Lines [0]: ='Ошибок нет' else if Memo2. Lines [0] ='' then Memo2. Lines [0]: ='Неизвестная ошибка'
end;
function TForm1. Lex_Progr: boolean; // 1. программа
begin
Lex_Progr: =False;
if Code_Tab [i]. Lex='program' then i: =i+1 else // конец блока для PROGRAM
begin
Err_Synt ('Отсутствует служебное слово program, либо в нем ошибка ', i);
Exit;
end;
if Lex_Prog_Name=false then Exit; // начало блока для имени программы
if Code_Tab [i]. Lex='; ' then i: =i+1 else // начало блока для точки с запятой
begin
Err_Synt ('Отсутствует точка с запятой после имени программы', i-1);
Exit;
end;
if Code_Tab [i]. Lex='var' then i: =i+1 else // начало блока для VAR
begin
Err_Synt ('Отсутствует служебное слово var после заголовка программы', i);
Exit;
end;
if Lex_descr_list=false then Exit;
if Code_Tab [i]. Lex='begin' then // начало блока для BEGIN
begin
i: =i+1;
if Code_Tab [i]. Lex='; ' then
begin
Err_Synt ('После begin недопустим символ "; "', i);
Exit;
end;
end else
begin
Err_Synt ('Отсутствует служебное слово begin после описаний переменных', i);
Exit;
end;
if Lex_oper_list=false then Exit;
if Code_Tab [i]. Lex='end' then i: =i+1 else // начало блока для END
begin
Err_Synt ('Отсутствует служебное слово end в конце программы', i);
Exit;
end; // начало блока для точки
if Code_Tab [i]. Lex='. ' then Lex_Progr: =true else if Code_Tab [i]. Lex<>'' then Err_Synt ('После служебного слова END вместо точки находится "'+Code_Tab [i]. Lex+'"', i) else Err_Synt ('Ожидается точка после служебного слова END в конце программы', i-1);
end;
procedure TForm1. Err_Synt (text: string; l: integer);
begin
if Error<>true then
begin
Memo1. Lines [Code_tab [l]. numstr-1]: =Memo1. Lines [Code_tab [l]. numstr-1] +'!!! '+'Error!!! ';
Memo2. Lines [0]: =Memo2. Lines [0] +text;
end;
Error: =true;
Exit;
end;
function TForm1. Lex_Prog_Name: boolean; // имя программы
begin
Lex_Prog_Name: =False;
if (Code_Tab [i]. typ<>'I') and (Code_Tab [i]. Lex<>'; ') then
begin
Err_Synt ('Неправильное имя программы. Ошибочное выражение: "'+Code_Tab [i]. Lex+'"', i);
Exit;
end;
if Code_Tab [i]. Lex='; ' then
begin
Err_Synt ('Отсутствует имя программы после program', i);
Exit;
end;
Lex_Prog_Name: =true;
i: =i+1;
end;
function TForm1. Lex_Descr_List: boolean; // список описаний
begin
Lex_descr_list: =false;
Found: =false;
while Code_Tab [i]. typ='I' do
begin
Found: =true;
if Lex_descr=false then Exit;
if Code_Tab [i]. Lex='; ' then i: =i+1 else
begin
Err_Synt ('Отсутствует точка с запятой после описания переменных ', i-1);
Exit;
end;
end;;
if Found=false then
begin
Err_Synt ('Отсутствует идентификатор в описании ', i);
Exit;
end;
Lex_descr_list: =true;
end;
function TForm1. Lex_descr: boolean; // описание
begin
Lex_descr: =false;
if Lex_name_list=true then
begin
if Code_Tab [i]. Lex=': ' then i: =i+1 else
begin
Err_Synt ('Отсутствует двоеточие перед типом '+Code_Tab [i]. Lex, i);
Exit;
end;
if Lex_type=true then Lex_descr: =true else Exit;
end else Exit;
end;
function TForm1. Lex_name_list: boolean; // список имен
begin
Lex_name_list: =false;
if Code_Tab [i]. typ='I' then i: =i+1 else
begin
Err_Synt ('Ожидается идентификатор ', i);
Exit;
end;
while Code_Tab [i]. Lex=',' do
begin
i: =i+1;
if Code_Tab [i]. Typ='I' then i: =i+1 else
begin
Err_Synt ('Ожидается идентификатор ', i);
Exit;
end;
end;
Lex_name_list: =true;
end;
function TForm1. Lex_type: boolean; // тип
begin
Lex_type: =false;
if (Code_Tab [i]. Lex='integer') then
begin
Lex_type: =true;
i: =i+1
end else
begin
Err_Synt ('Отсутствует тип: integer ', i-1);
Exit;
end;
end;
function TForm1. Lex_oper_list: boolean; // список операторов
begin
Lex_oper_list: =false;
found: =false;
while Lex_oper=true do
begin
Found: =true;
if (Code_Tab [i]. Lex='; ') then i: =i+1 else // Если след. лексема после проверенного оператора ни "; ", ни END, а любая другая лексема.
if Code_Tab [i]. Lex<>'end' then
begin
Err_Synt ('Ожидается точка с запятой после оператора (после лексемы '+Code_Tab [i-1]. Lex+') ', i-1);
Exit;
end;
end;
Lex_oper_list: =true;
if found=false then
begin
Err_Synt ('Не найдены операторы между begin и end', i-1);
Lex_oper_list: =false;
end;
end;
function TForm1. Lex_oper: boolean;
begin
Lex_oper: =false;
if (Lex_assign) or (Lex_repeat_until) then Lex_oper: =true else
if (Code_Tab [i]. Lex='; ') and (Code_Tab [i-1]. Lex='; ') then Lex_oper: =true else // проверяется на пустой оператор, т.е. на ";; ".
if (Code_Tab [i]. Typ='T') and (Code_Tab [i]. Lex<>'end') and (Code_Tab [i]. Lex<>'begin') and (Code_Tab [i]. Lex<>'; ') then Err_Synt ('Лишняя лексема в программе: '+Code_Tab [i]. Lex, i);
end;
function TForm1. Lex_assign: boolean; // присваивание
begin
Lex_assign: =false;
if Code_Tab [i]. typ='I' then
begin
if Code_Tab [i+1]. Lex=': =' then
begin
i: =i+2;
if Lex_Exp=true then Lex_assign: =true else Memo2. Lines [1]: =Memo2. Lines [1] +' в операторе присваивания'
end else Err_Synt ('Ошибка в операторе присваивания', i)
end;
end;
function TForm1. Lex_Exp: boolean; // выражение
begin
Lex_Exp: =false;
if Lex_simple_Exp=true then
begin
if ( (Code_Tab [i]. Lex='=') or (Code_Tab [i]. Lex='>') or (Code_Tab [i]. Lex='<')
or (Code_Tab [i]. Lex='<>') or (Code_Tab [i]. Lex='<=') or (Code_Tab [i]. Lex='>=')) then
begin
i: =i+1;
if Lex_simple_Exp=true then
begin
Lex_Exp: =true;
Exit;
end;
end;
end else Exit;
Lex_Exp: =true; // если простое выражение без знака
end;
function TForm1. Lex_simple_Exp: boolean; // простое выражение
begin
Found: =false;
Lex_simple_Exp: =false;
if Lex_term=true then
begin
Found: =true;
while ( (Code_Tab [i]. Lex='+') or (Code_Tab [i]. Lex='-')) and (Found=true) do
begin
i: =i+1;
if Lex_term=false then
begin
Found: =False;
Err_Synt ('Ожидается константа, идентификатор или выражение ', i-1);
Exit;
end;
end;
if (Code_Tab [i]. Lex=') ') and (Scobka=false) then Err_Synt ('Ожидается открывающаяся скобка в множителе', i)
end;
if Found=true then Lex_simple_Exp: =true;
end;
function TForm1. Lex_Term: boolean; // терм
begin
Found: =false;
Lex_Term: =false;
if Lex_mnozh=true then
begin
Found: =true;
while ( (Code_Tab [i]. Lex='*') or (Code_Tab [i]. Lex='/')) and (Found=true) do
begin
i: =i+1;
if Lex_mnozh=false then Found: =False;
end;
end;
if Found=true then Lex_Term: =true;
end;
function TForm1. Lex_mnozh: boolean; // множитель
begin
Lex_mnozh: =false;
if (Code_Tab [i]. typ='I') or (Code_Tab [i]. typ='C') then
begin
i: =i+1;
Lex_mnozh: =true;
Exit;
end else
begin
if Code_Tab [i]. Lex=' (' then
begin
Scobka: =true;
i: =i+1;
if Lex_simple_Exp=true then
begin
if Code_Tab [i]. Lex=') ' then
begin
i: =i+1;
Lex_mnozh: =true;
end else
begin
Err_Synt ('Ожидается закрывающая скобка в множителе ', i);
Exit;
end;
end;
end else Err_Synt ('Ожидается константа, идентификатор или выражение ', i);
end;
end;
function TForm1. Lex_repeat_until: boolean; // цикл
begin
Lex_repeat_until: =false;
if Code_Tab [i]. Lex='repeat' then
begin
i: =i+1;
if Lex_body=true then begin i: =i+1;
if Code_Tab [i]. Lex='until' then begin i: =i+1;
if Lex_Exp=true then Lex_repeat_until: =true
else Err_Synt ('Ожидается выражение после служебного слова until', i); end
else Err_Synt ('Ожидается служебное слово until', i);
end;
end;
end;
function TForm1. Lex_body: boolean; // тело цикла
begin
Lex_body: =false;
if Lex_oper=true then
begin
Lex_body: =true;
Exit;
end else
if Code_Tab [i]. Lex='begin' then
begin
i: =i+1;
if Code_Tab [i]. Lex='; ' then
begin
Err_Synt ('После begin недопустим символ "; "', i);
Exit;
end;
if Lex_oper_list=true then
begin
if (Code_Tab [i]. Lex='end') and (Code_Tab [i+1]. Lex<>'; ') then
begin
Lex_body: =true;
i: =i+1;
end else Err_Synt ('Ожидается служебное слово end после блока операторов', i-1)
end;
end;
end;
end.
Похожие работы


... задачи дипломного проекта, необходимость обработки нескольких связанных таблиц, в качестве языка программирования для «Разработки модуля выгрузки данных в текстовом формате комплекса «Налогоплательщик ЮЛ» для государственной налоговой инспекции» был выбран язык программирования FoxPro. 4.4 Описание программы Наименование программы: «Разработка модуля выгрузки данных в текстовом формате ...
... выбрать имя в ListBox’e и нажать кнопку «OK», после чего выбранное имя автоматически отобразиться в окне получателя сообщения. Рис. 1.10. Выбор адресата получателя Поиск компьютеров в локальной сети Приведём пример кода программы, реализующую поиск компьютеров в локальной сети Microsoft. procedure TForm4. Button1Click (Sender: TObject); var Q, BufferSize: DWord; R: THandle; Buf: ^ ...


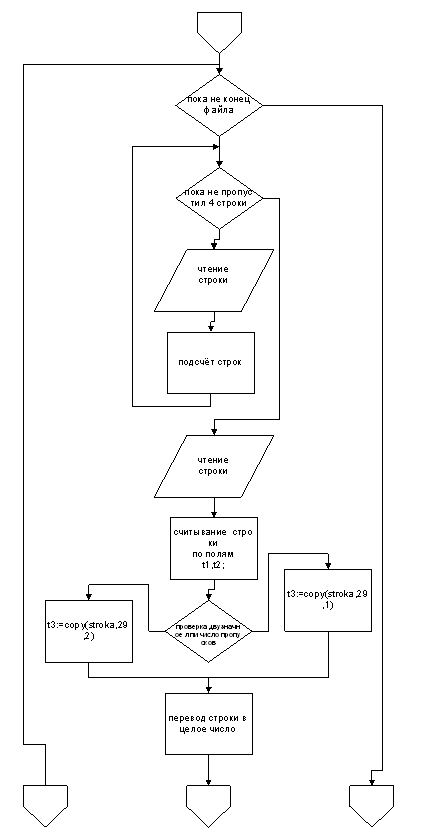
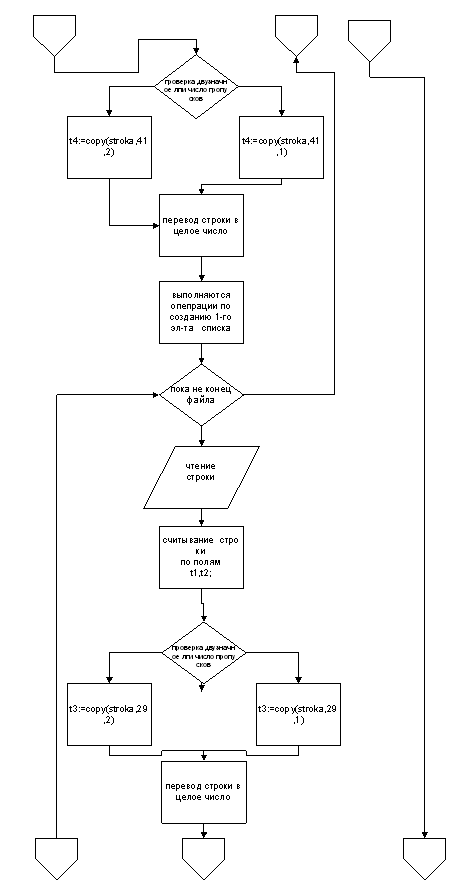
... программы подтвердило, что программа правильно выполняет обработку данных и выдаёт верные результаты. Всё это свидетельствует о работоспособности программы и позволяет сделать вывод о пригодности программы к решению практических задач по обработке экономической информации. Библиографический список 1. Немнюгин С.А. –Turbo Pascal учебник.”Питер”,2001.-496л 2. Фараонов В.В Turbo Pascal 7.0.” ...
... третьих фирм имеют логотип "Featuring Microsoft Visual Basic Technology". Это заставляет задуматься над тем, что же такое BASIC - "стандартный код для начинающих" или "основной язык для основной среды"... ГЛАВА3. разработка программы для расчета показателей финансового состояния предприятия. Для осуществления планирования деятельности любой фирмы на любом этапе работы осуществляются некоторые ...
0 комментариев