Навигация
Назначение и основные методы индексации
70070
знаков
3
таблицы
0
изображений
5 Назначение и основные методы индексации.
Задача создания вектора документа называется индексированием.
Методы автоматического индексирования. Задачи этих методов – построить векторы документов {(tik , wik)}. Исходные данные – массив документов. Нужно выделить те термины, которые раскрывают текст документа tik и присвоить вес wik.
Методы:
1. Частотный метод – по каждому термину, входящему в документ подсчитывается частота вхождения терминов в документ fik, i – номер документа, k – термин. Эта частота абсолютная. Затем документы упорядочиваются в соответствии с возрастанием или убыванием частоты.
Если термин имеет большую частоту, то это, скорее всего общеупотребительный термин, не раскрывающий конкретную предметную область (будет много документов).
Если термин имеет малую частоту, то он существенно отражает содержание, даже если его включить в дескрипторы (ключевые слова), то он , скорее всего будет использоваться в холостую. Поэтому эти 2 простейших документа исключают из списка.
Терминам с большей частотой присваивают меньший вес, с меньшей частотой – больший вес.
2. Использование соотношения “ сигнал – шум “. Здесь исключается ещё одна частота: суммарная или общая частота появления термина k в наборе из n документов и рассчитывается:
Fk = сумма (i=1 – n) fik
Шум k –го символа рассчитывается:
Nk = сумма(i=1 – n) fik / Fk * log (Fk / fik)
Сигнал k – го символа:
Sk = log Fk – Nk
Шум является максимальным, если термин имеет равномерное распределение в n документах. Шум является минимальным и равномерным, когда термин имеет неравномерное распределение, например, когда он встречается только в одном документе, с частотой Fk, тогда:
Nk = сумма (i=1 – n) fik / Fk * log Fk / fik = 0, в этом случае сигнал имеет максимальное значение:
Sk = log Fk – Nk = log Fk
С учётом этих параметров, для определения веса используется отношение сигнала к шуму k –го термина:
Sk / Nk. Чем больше это отношение, тем больший вес
Назначается. Строится однозначная таблица.
1.Использование распределения частоты термина (уклонения).
Уклонение рассчитывается:
U = (сумм (fik – fk)) / (n-1)
Fk – средняя частота термина k в наборе из n документов.
Fk = Fk / n
Для оценки веса термина используется не уклонение, а формула Fk* U/ fk
Чем больше это отношение, тем больший вес назначается термину.
2.Параметры, основанные на способности термина различать документы набора. Исходные данные – набор из n документов и множество S коэффициентов подобия всех пар документов из множества n: { S ( Di , Dj ) }. Эти коэффициенты подобия рассчитываются на основании векторов документов. Способ расчета разный, а принцип: S ( Di , Dj ) = 1, если вектора идентичны.
S ( Di , Dj ) = 0 , если в векторах нет ни одного общего документа.
По S рассчитывают средний коэффициент подобия:S = C * сумм (i= 1 – n) S ( Di , Dj ), С – коэффициент усреднения, может быть любым, в частности C = 1 / n.
Далее из векторов документов удаляют некоторый k – й термин и рассчитывают средний коэффициент по парного подобия, но с удалённым k –м термином: Sk( т.е. в векторах документа не участвуют веса k –го термина). Если Sk возрастает относительно S, то термину k присваивается положительный вес. Чем больше эта разница, тем больший вес присваивается
11.Методы индексирования, основанные на положении термина в тексте.Подходы:
1.В индексационные термины включаются те, которые встречаются в названиях документов, названиях глав, разделов и т.д.
2.Составляются списки значимых для некоторой предметной области слов. Т.е. составляется глоссарий по некоторой предметной области.
3.Методы увеличения полноты. Часто бывает необходимо выдать наибольшее число релевантных документов из массива. В этом случае необходимо к используемым индексационным терминам добавить дополнительные, чтобы расширить область поиска.
1)1-й подход к решению этой задачи: использование терминов заместителей из словаря синонимов, который называют тезариусом, в котором термины сгруппированы в классы.
2)Метод ассоциативного индексирования. Основан на использовании матрицы ассоциируемости терминов, которая задаёт для каждой пары терминов показатель ассоциируемости. Абсолютная запись этого ПА между терминами j и k:
f ( j ; k ) = сумм ( i=1 – n ) fij * fjk – частота совместного использования f ( j ; k ) = сумм ( i=1 – n ) fij * fjk / (сумм ( i=1 – n ) fij ^ 2+ сумм ( i=1 – n ) fjk ^ 2 - сумм ( i=1 – n ) fij * fjk - для расчёта относительного значения этого показателя. fij,k – частота появления термина j или k в i – м документе. 0 <= f ( j ; k ) <= 1. Если f ( j ; k ) = 0, то термины совсем не ассоциируются, если f ( j ; k ) = 1, то полностью ассоциируемы.
12.Постановка задачи увеличения полноты при поиске в текстовой базе данных и основные методы ее решения.Методы увеличения полноты. Часто бывает необходимо выдать наибольшее число релевантных документов из массива. В этом случае необходимо к используемым индексационным терминам добавить дополнительные, чтобы расширить область поиска.
1)1-й подход к решению этой задачи: использование терминов заместителей из словаря синонимов, который называют тезариусом, в котором термины сгруппированы в классы.
2)Метод ассоциативного индексирования. Основан на использовании матрицы ассоциируемости терминов, которая задаёт для каждой пары терминов показатель ассоциируемости. Абсолютная запись этого ПА между терминами j и k:
f ( j ; k ) = сумм ( i=1 – n ) fij * fjk – частота совместного использования f ( j ; k ) = сумм ( i=1 – n ) fij * fjk / (сумм ( i=1 – n ) fij ^ 2+ сумм ( i=1 – n ) fjk ^ 2 – сумм ( i=1 – n ) fij * fjk - для расчёта относительного значения этого показателя. fij,k – частота появления термина j или k в i – м документе. 0 <= f ( j ; k ) <= 1.
Если f ( j ; k ) = 0, то термины совсем не ассоциируются, если f ( j ; k ) = 1, то полностью ассоциируемы.
Второй способ: используются матрицы для расширения поиска: вводится некоторое пороговое значение коэффициента ассоциируемости (СКА), выше которого коэффициенты приравниваются к единице, а ниже к 0.
13.Метод ассоциативного индексирования в задаче увеличения полноты поиска.Основан на использовании матрицы ассоциируемости терминов, которая задаёт для каждой пары терминов показатель ассоциируемости. Абсолютная запись этого ПА между терминами j и k:
f ( j ; k ) = сумм ( i=1 – n ) fij * fjk – частота совместного использования f ( j ; k ) = сумм ( i=1 – n ) fij * fjk / (сумм ( i=1 – n ) fij ^ 2+ сумм ( i=1 – n ) fjk ^ 2 - сумм ( i=1 – n ) fij * fjk - для расчёта относительного значения этого показателя. fij,k – частота появления термина j или k в i – м документе. 0 <= f ( j ; k ) <= 1.
Если f ( j ; k ) = 0, то термины совсем не ассоциируются, если f ( j ; k ) = 1, то полностью ассоциируемы.
Второй способ: используются матрицы для расширения поиска: вводится некоторое пороговое значение коэффициента ассоциируемости (СКА), выше которого коэффициенты приравниваются к единице, а ниже к 0.
14.Метод вероятностного индексирования в задаче увеличения полноты поиска.Суть: наличие в документе некоторых терминов Т1, Т2, …, Тi позволяет с некоторой вероятностью Р отнести эти документы к классу документов Ск и присвоить вектору документов идентификатор этого класса, т.е. дополнительный термин. Причём указанная вероятность Р для этого “приписывания” должна быть больше некоторого порогового значения.
Вероятность Р записывается: Р(Т1, Т2, …, Тi , Ск) – вероятность того, что при наличии терминов Тi, документ будет принадлежать классу Ск. Р(Т1, Т2, Тi, Ск) = а * р(Ск) * р(Т1, Ск) * (Т2, Ск) * … * (Тi, Ск)
Коэффициент а подбирается таким образом, чтобы выполнялось условие: сумма(к=1, m) Р(Т1, Т2, …, Тi , Ск) = 1 – т.е. чтобы выполнялась полная группа событий. Документ, содержащий термин Т1, Т2, …, Тi обязательно должен принадлежать одному из классов Ск.
m – число классов документов нашего массива.
Р(Ск) – вероятность класса Ск. Эта вероятность рассчитывается как частота, в числителе – число документов, находящихся в классе Ск, в знаменателе – общее число документов во всех m классах.
Р(Тj, Ск) – дробь, в числителе – общее число появления термина Тj в документах класса Ск, в знаменателе – общее число появления всех терминов в документах класса Ск.
15.Постановка задачи улучшения точности поиска в текстовой базе данных и основные методы ее решения.Задача - как можно точнее получать нужные документы.
2 способа:
а). Использование наиболее узких терминов.
б). Использование словосочетаний для индексирования документов. Для определения словосочетаний используются статистический и лингвистический подходы.
Статистический подход (СП):
В соответствии со СП словосочетание – такая комбинация терминов, частота совместного появления которых в массивах документов велика относительно частот появления отдельных терминов этого словосочетания. Связность терминов определяется коэффициентом связности:
Сik = Fkj / ( Fk * Fj ) * N – это связность 2-х терминов, хотя может быть и больше (до 4-х).
Fk , Fj – частные частоты терминов k и j. Вопрос 15(окончание).
Fkj – частота совместного появления терминов.
N – число слов в массиве.
После расчёта этих значений и коэффициента связности (КС) в словосочетании отбирают такие термины, для которых Сjк и Fkj больше порогового значения, которое устанавливается эмпирически. Пороговые значения: Сjк >= 20 и Fkj >= 3.
Если эти характеристики для термов, включённых в словосочетание поддерживаются, то получаются хорошие выборки.
Недостаток:
не учитывается порядок слов в словосочетаниях;
метод позволяет считать идентичными даже словосочетания с одинаковым порядком следования термина.
Лингвистические методы – используют упрощённые синтаксические разборы предложений, причём, как правило, предложений из заголовков текстов.
Алгоритм анализа упрощённых фраз:
Образуются предводительные словосочетания путём проставления скобок перед предлогами, числительными, неопределёнными местоимениями и т.д.
Устанавливаются связи справа и/или слева от слов, выделенных в первом пункте между различными структурами.
Из структуры исключаются количественные числительные, вспомогательные глаголы, местоимения и т.д. Остаются лишь индексационные словосочетания. В результате должны остаться связи или комбинации вида: сущ. – сущ. (прил. - прил.).
Пример: (Some investigations)(in computer science)(which can lead)(to the creation)(of artificial intelligence). В результате имеем:
Computer science - >investigations -> artificial intelligence -> creation.
16.Статистический метод образования словосочетаний в задаче улучшения точности поиска в текстовой базе данных.В соответствии со СП словосочетание – такая комбинация терминов, частота совместного появления которых в массивах документов велика относительно частот появления отдельных терминов этого словосочетания. Связность терминов определяется коэффициентом связности:
Сik = Fkj / ( Fk * Fj ) * N – это связность 2-х терминов, хотя может быть и больше (до 4-х).
Fk , Fj – частные частоты терминов k и j.
Fkj – частота совместного появления терминов.
N – число слов в массиве.
После расчёта этих значений и коэффициента связности (КС) в словосочетании отбирают такие термины, для которых Сjк и Fkj больше порогового значения, которое устанавливается эмпирически. Пороговые значения: Сjк >= 20 и Fkj >= 3.
Если эти характеристики для термов, включённых в словосочетание поддерживаются, то получаются хорошие выборки.
Недостаток:
не учитывается порядок слов в словосочетаниях;
метод позволяет считать идентичными даже словосочетания с одинаковым порядком следования термина.
17.Лингвистический метод образования словосочетаний в задаче улучшения точности поиска в текстовой базе данных.Лингвистические методы – используют упрощённые синтаксические разборы предложений, причём, как правило, предложений из заголовков текстов.
Алгоритм анализа упрощённых фраз:
Образуются предварительные словосочетания путём проставления скобок перед предлогами, числительными, неопределёнными местоимениями и т.д.
Устанавливаются связи справа и/или слева от слов, выделенных в первом пункте между различными структурами.
Из структуры исключаются количественные числительные, вспомогательные глаголы, местоимения и т.д. Остаются лишь индексационные словосочетания. В результате должны остаться связи или комбинации вида: сущ. – сущ. (прил. - прил.).
Пример: (Some investigations)(in computer science)(which can lead)(to the creation)(of artificial intelligence). В результате имеем:
Computer science - >investigations -> artificial intelligence -> creation.
18.Задача автоматического реферирования текстов и методы ее решения.Задача создания рефератов – задача выявления списка документов и краткое его представление.
Исходные данные:
массив исходных данных;
готовые вектора документов (т.е. уже должна быть решена задача создания векторов {tik , wik}).
Методы для автореферирования:
Расчётный – определяются веса словосочетаний, содержащих 2 значимых термина из вектора документа.
w = 1 / 2t * wi1 * wi2 – вес словосочетания из 2-х терминов .
wi1 и w i2 - веса 1-го и 2-го термина из вектора.
t – количество слов в тексте между терминами ti1 и t i2, которые не являются значимыми.
Далее по тексту определяется значимое предложение. Это такое предложение, которое содержит большое число значимых групп. После расчёта значимости предложений, они упорядочиваются и для реферирования выбираются наиболее значимые. Далее наиболее значимые предложения упорядочиваются так, как они шли в тексте, чтобы не потерять логику.
Позиционный метод. Включает в себя следующие не альтернативные шаги:
Наиболее значимые предложения, которые либо начинают, либо заканчивают абзац или раздел.
Исключаются вопросительные предложения, несмотря на их положение в абзаце.
К значимым относятся предложения, содержащие слова – подсказки. Например: “ данная (слово-подсказка) работа выполнена по такому – то плану и т.д.”
Из значимых исключаются те предложения, в которых есть ссылки на рисунки, таблицы, цитаты и т.д.
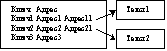
![]()
![]()
 19.Цепочечные текстовые файлы.
19.Цепочечные текстовые файлы.
К самой БД добавляется справочник, который имеет следующую структуру:
Ключ – значимое слово, характеризующее тот или иной документ. Рядом пишется адресная ссылка на тот текстовый файл, который имеет данный ключ в качестве значимого термина. И к этой подстроке добавляются собственно текстовые файлы.
Цепочечная модель: сколько индексных терминов в тексте выделено столько и должно быть ссылок.
Преимущества:
Максимальная длина поиска определяется самой длинной цепочкой;
Новые записи (тексты) можно ставить в начало цепи, что упрощает её корректировку.
Недостатки:
Цепи могут быть длинными, если некоторые ключи используются довольно часто;
Необходимость выделения памяти для хранения адресных ссылок в самих текстах;
Если справочник очень велик, он значительно усложняет работу с текстами и требует организации дополнительного доступа к себе самому.
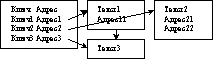
20.Инвертированные текстовые файлы.Получаются из цепочечных файлов, когда в справочник включаются адресные ссылки на все тексты, имеющие соответствующий ключ в качестве индексационного термина.
Недостаток: переменное число адресов в справочнике.
Достоинство: быстрый поиск релевантных документов, так как их адреса находятся сразу в справочнике, обработку которого можно организовать в оперативной памяти.
21.Рассредоточенные текстовые файлы.Весь массив документов разбивается на группы файлов, ключевые термины которых связаны некоторым математическим соотношением. Тогда поиск в справочнике заменяется вычислительной процедурой, которая называется хешированием, рандомизацией или перемешиванием.
Здесь нет справочника, а существует вычислительная процедура, т.е. блок, называемый блоком рандомизации, который по ключу (поисковому термину) на основании вычислительной процедуры определяет адрес, по которому находится текст.
Ключ адрес этот участок
{ключ} памяти
называется
бакетом
В этой области памяти находится несколько текстов, каждый из которых характеризуется по своему в векторе документов. Т.е. адрес получается по вычислительной процедуре.
Преимущества:
Быстрый вычисляемый доступ;
Из-за отсутствия справочника экономится память.
Недостатки:
Сложность при выборе метода хеширования;
Применяется для коротких векторов запросов, когда в поиске участвует немного слов;
Изменения векторов документов порождает сложность в ведении файлов.
![]() Вопрос 27(окончание).
Вопрос 27(окончание).
Похожие работы
... = πR2, L = 2πR). 28) Критерии выбора конфигурации персонального компьютера. Зав. кафедрой -------------------------------------------------- Экзаменационный билет по предмету ИНФОРМАТИКА. РАСШИРЕННЫЙ КУРС Билет № 9 29) Что называется связью «один к одному»? Определите тип связи между объектами предметной области Институт: ...
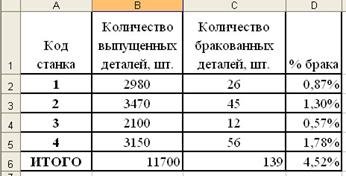
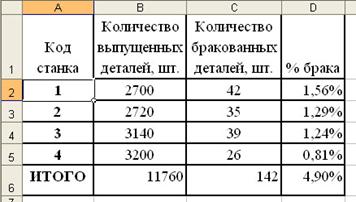
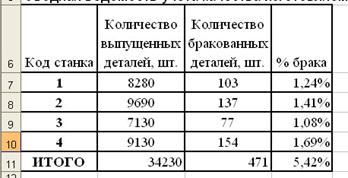
... рост производительности труда в других отраслях народного хозяйства. В настоящее время около 50% всех рабочих мест в мире поддерживается средствами обработки информации. Информатика как фундаментальная наука занимается разработкой методологии создания информационного обеспечения процессов управления любыми объектами на базе компьютерных информационных систем. В Европе можно выделить следующие ...
... корпуса молодых специалистов по новой юридической специальности- «правовая информатика». В настоящее время правовую информатику можно рассматривать как перспективное и быстро прогрессирующее направление научных исследований , которое имеет собственный предмет , задачи и методы исследований . Восприятие юристами положений и выводов информатики должно происходить через призму юридических ...
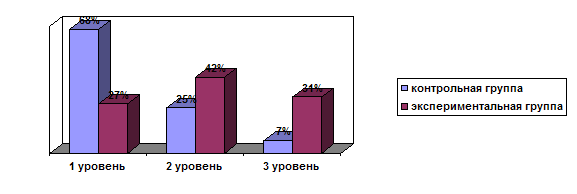
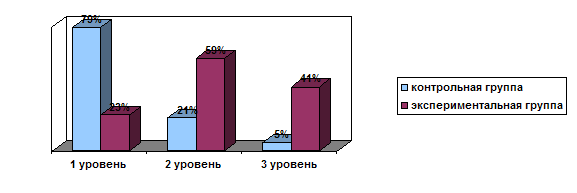
... учебного процесса методической подготовки будущего учителя. Основное содержание исследования отражено в следующих публикациях автора: I. Монографии: 1. Абдуразаков М.М. Совершенствования содержания подготовки будущего учителя информатики в условиях информатизации образования. –Махачкала: ДГПУ, 2006. –190 с. 12 п.л. 2. Гаджиев Г.М., Абдуразаков М.М. Технология преподавания информатики. – ...
0 комментариев