Навигация
Физический уровень — собственно данные, расположенные в файлах или в страничных структурах, расположенных на внешних носителях информации
74648
знаков
0
таблиц
6
изображений
3. Физический уровень — собственно данные, расположенные в файлах или в страничных структурах, расположенных на внешних носителях информации.
Эта архитектура позволяет обеспечить логическую (между уровнями 1 и 2) и физическую (между уровнями 2 и 3) независимость при работе с данными. Логическая независимость предполагает возможность изменения одного приложения без корректировки других приложений, работающих с этой же базой данных. Физическая независимость предполагает возможность переноса хранимой информации с одних носителей на другие при сохранении работоспособности всех приложений, работающих с данной базой данных. Это именно то, чего не хватало при использовании файловых систем. Выделение концептуального уровня позволило разработать аппарат централизованного управления базой данных.
Классификация банков данныхБанки данных — это очень сложная система, которую можно классифицировать по целому спектру признаков, касающихся как банка в целом, так и отдельных его компонентов.
По назначению БнД бывают:
- информационно-поисковые;
- специализированные по отдельным областям науки и техники;
- банки данных АСУ для организационно-экономической информации;
- банки данных для систем автоматизации научных исследований и производственных испытаний;
- банки данных для систем автоматизированного проектирования.
По архитектуре поддерживаемой вычислительной среды БнД бывают централизованными (интегрированными) и распределенными.
По виду информации, которая сохраняется, банки делятся на банки данных, банки документов и банки знаний.
По языку общения пользователя с БД различают системы с базовым языком (открытые системы) и с собственным языком (закрытые системы).
В открытых системах языковым средством общения с БД один из языков программирования, например C, Pascal. В таких системах для общения с БД нужен посредник, то есть программист, который владеет избранным языком программирования.
Закрытые системы имеют собственный язык общения. Он, как правило, намного проще, чем язык программирования. Поэтому в таких системах не нужен посредник-программист для общения с БД. Сами пользователи, которые имеют соответствующую подготовку, смогут работать с БД.
Одними из основополагающих в концепции баз данных являются обобщенные категории «данные» и «модель данных».
Понятие «данные» в концепции баз данных — это набор конкретных значений, параметров, характеризующих объект, условие, ситуацию или любые другие факторы. Примеры данных: Петров Николай Степанович, $30 и т. д. Данные не обладают определенной структурой, данные становятся информацией тогда, когда пользователь задает им определенную структуру, то есть, осознает их смысловое содержание. Поэтому центральным понятием в области баз данных является понятие модели. Не существует однозначного определения этого термина, у разных авторов эта абстракция определяется с некоторыми различиями, но, тем не менее, можно выделить нечто общее в этих определениях-
Модель данных — это некоторая абстракция, которая, будучи приложима к конкретным данным, позволяет пользователям и разработчикам трактовать их уже как информацию, то есть сведения, содержащие не только данные, но и взаимосвязь между ними.
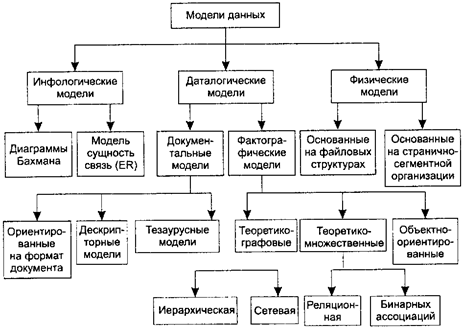
Рис. 2.4. Классификация моделей данных
На рис. 2.4 представлена классификация моделей данных.
В соответствии с рассмотренной ранее трехуровневой архитектурой мы сталкиваемся с понятием модели данных по отношению к каждому уровню. И действительно, физическая модель данных оперирует категориями, касающимися организации внешней памяти и структур хранения, используемых в данной операционной среде. В настоящий момент в качестве физических моделей используются различные методы размещения данных, основанные на файловых структурах: это организация файлов прямого и последовательного доступа, индексных файлов и инвертированных файлов, файлов, использующих различные методы хеширования, взаимосвязанных файлов. Кроме того, современные СУБД широко используют страничную организацию данных. Физические модели данных, основанные на страничной организации, являются наиболее перспективными.
Наибольший интерес вызывают модели данных, используемые на концептуальном уровне. По отношению к ним внешние модели называются подсхемами и используют те же абстрактные категории, что и концептуальные модели данных.
Кроме трех рассмотренных уровней абстракции при проектировании БД существует еще один уровень, предшествующий им. Модель этого уровня должна выражать информацию о предметной области в виде, независимом от используемой СУБД. Эти модели называются инфологическими, или семантическими, и отражают в естественной и удобной для разработчиков и других пользователей форме информационно-логический уровень абстрагирования, связанный с фиксацией и описанием объектов предметной области, их свойств и их взаимосвязей.
Инфологические модели данных используются на ранних стадиях проектирования для описания структур данных в процессе разработки приложения, а даталогические модели уже поддерживаются конкретной СУБД.
Документальные модели данных соответствуют представлению о слабоструктурированной информации, ориентированной в основном на свободные форматы документов, текстов на естественном языке.
Модели, основанные на языках разметки документов, связаны, прежде всего, со стандартным общим языком разметки — SGML (Standard Generalized Markup Language), который был утвержден ISO в качестве стандарта еще в 80-х годах. Этот язык предназначен для создания других языков разметки, он определяет допустимый набор тегов (ссылок), их атрибуты и внутреннюю структуру документа. Контроль за правильностью использования тегов осуществляется при помощи специального набора правил, называемых DTD-описаниями. которые используются программой клиента при разборе документа. Для каждого класса документов определяется свой набор правил, описывающих грамматику соответствующего языка разметки. С помощью SGML можно описывать структурированные данные, организовывать информацию, содержащуюся в документах, представлять эту информацию в некотором стандартизованном формате. Но ввиду некоторой своей сложности SGML использовался в основном для описания синтаксиса других языков (наиболее известным из которых является HTML), и немногие приложения работали с SGML-документами напрямую.
Гораздо более простой и удобный, чем SGML, язык HTML позволяет определять оформление элементов документа и имеет некий ограниченный набор инструкций — тегов, при помощи которых осуществляется процесс разметки. Инструкции HTML в первую очередь предназначены для управления процессом вывода содержимого документа на экране программы-клиента и определяют этим самым способ представления документа, но не его структуру. В качестве элемента гипертекстовой базы данных, описываемой HTML. используется текстовый файл, который может легко передаваться по сети с использованием протокола HTTP. Эта особенность, а также то, что HTML является открытым стандартом, и огромное количество пользователей имеет возможность применять возможности этого языка для оформления своих документов, безусловно, повлияли на рост популярности HTML и сделали его сегодня главным механизмом представления информации в Internet.
Однако HTML сегодня уже не удовлетворяет в полной мере требованиям, предъявляемым современными разработчиками к языкам подобного рода. И ему на смену был предложен новый язык гипертекстовой разметки, мощный, гибкий и, одновременно с этим, удобный язык XML. В чем же заключаются его достоинства?
XML (Extensible Markup Language) — это язык разметки, описывающий целый класс объектов данных, называемых XML-докумснтами. Он используется в качестве средства для описания грамматики других языков и контроля за правильностью составления документов. То есть сам по себе XML не содержит никаких тегов, предназначенных для разметки, он просто определяет порядок их создания.
Тезаурусные модели основаны на принципе организации словарей, содержат определенные языковые конструкции и принципы их взаимодействия в заданной грамматике. Эти модели эффективно используются в системах-переводчиках, особенно многоязыковых переводчиках. Принцип хранения информации в этих системах и подчиняется тезаурусным моделям.
Дескрипторные модели — самые простые из документальных моделей, они широко использовались на ранних стадиях использования документальных баз данных. В этих моделях каждому документу соответствовал дескриптор — описатель. Этот дескриптор имел жесткую структуру и описывал документ в соответствии с теми характеристиками, которые требуются для работы с документами в разрабатываемой документальной БД. Например, для БД, содержащей описание патентов, дескриптор содержал название области, к которой относился патент, номер патента, дату выдачи патента и еще ряд ключевых параметров, которые заполнялись для каждого патента. Обработка информации в таких базах данных велась исключительно по дескрипторам, то есть по тем параметрам, которые характеризовали патент, а не по самому тексту патента.
Глава 3. Проектирование баз данных Этапы проектирования баз данныхСоздание и внедрение в практику современных информационных систем автоматизированных баз данных выдвигает новые задачи проектирования, которые невозможно решать традиционными приемами и методами. Большое внимание необходимо уделять вопросам проектирования баз данных. От того, насколько успешно будет спроектирована база данных, зависит эффективность функционирования системы в целом, ее жизнеспособность и возможность расширения и дальнейшего развития. Поэтому вопрос проектирования баз данных выделяют как отдельное, самостоятельное направление работ при разработке информационных систем.
Проектирование баз данных — это итерационный, многоэтапный процесс принятия обоснованных решений в процессе анализа информационной модели предметной области, требований к данным со стороны прикладных программистов и пользователей, синтеза логических и физических структур данных, анализа и обоснования выбора программных и аппаратных средств. Этапы проектирования баз данных связаны с многоуровневой организацией данных. Рассматривая вопрос проектирования баз данных, будем придерживаться такого многоуровневого представления данных: внешнего, инфологического, логического (даталогического) и внутреннего.
Такое представление уровней данных не единственное. Существуют и другие варианты многоуровневого представления данных. Так, в соответствии с предложениями исследовательской группы по системам управления данными Американского национального института стандартов ANSI/X3/SPARC, а также CODASYL (Conference on Data Systems Languages), как правило, выделяется три уровня представления данных:
внешний уровень (с точки зрения конечного пользователя и прикладного программиста),
концептуальный уровень (с точки зрения СУБД),
внутренний уровень (с точки зрения системного программиста).
В соответствии с этой концепцией внешний уровень это часть (подмножество) концептуальной модели, необходимая для реализации какого-либо запроса или прикладной программы. То есть, если концептуальная модель выступает как схема, поддерживаемая конкретной СУБД, то внешний уровень — это некоторая совокупность подсхем, необходимых для реализации конкретной прикладной программы или запроса пользователя.
Существует также другая точка зрения, в соответствии с которой под внешним уровнем понимают более общие понятия, связанные с изучением и анализом информационных потоков предметной области и их структуризацией. Некоторые авторы вводят вспомогательный уровень (промежуточный между внешним и даталогическим уровнями), который называется инфологическим. Он может выступать как самостоятельный или быть составной частью внешнего уровня. Такая концепция более целесообразна с точки зрения понимания процесса проектирования БД.
Поэтому будем рассматривать инфологический уровень как самостоятельный уровень представления данных. Внешний уровень в этом случае выступает как отдельный этап проектирования, на котором изучается все внемашинное информационное обеспечение, то есть формы документирования и представления данных, а также внешняя среда, в которой будет функционировать банк данных с точки зрения методов фиксации, сбора и передачи информации в базу данных.
При проектировании БД на внешнем уровне необходимо изучить функционирование объекта управления, для которого проектируется БД, всю первичную и выходную документацию с точки зрения определения того, какие именно данные необходимо сохранять в базе данных. Внешний уровень это, как правило, словесное описание входных и выходных сообщений, а также данных, которые целесообразно сохранять в БД. Описание внешнего уровня не исключает наличия элементов дублирования, избыточности и несогласованности данных. Поэтому для устранения этих аномалий и противоречий внешнего описания данных выполняется инфологическое проектирование. Инфологическая модель является средством структуризации предметной области и понимания концепции семантики данных. Инфологическую модель можно рассматривать в основном как средство документирования и структурирования формы представления информационных потребностей, которая обеспечивает непротиворечивое общение пользователей и разработчиков системы.
Все внешние представления интегрируются на инфологическом уровне, где формируется инфологическая (каноническая) модель данных, которая не является простой суммой внешних представлений данных.
Инфологический уровень представляет собой информационно-логическую модель (ИЛМ) предметной области, из которой исключена избыточность данных и отображены информационные особенности объекта управление без учета особенностей и специфики конкретной СУБД. То есть инфологическое представление данных ориентированно преимущественно на человека, который проектирует или использует базу данных.
Логический (концептуальный) уровень построен с учетом специфики и особенностей конкретной СУБД. Этот уровень представления данных ориентирован больше на компьютерную обработку и на программистов, которые занимаются ее разработкой. На этом уровне формируется концептуальная модель данных, то есть специальным способом структурированная модель предметной области, которая отвечает особенностям и ограничениям выбранной СУБД. Модель логического уровня, поддерживаемую средствами конкретной СУБД, называют еще даталогической.
Инфологическая и даталогическая модели, которые отображают модель одной предметной области, зависимы между собой. Инфологическая модель может легко трансформироваться в даталогическую модель.
Внутренний уровень связан с физическим размещением данных в памяти ЭВМ. На этом уровне формируется физическая модель БД, которая включает структуры сохранения данных в памяти ЭВМ, в т.ч. описание форматов записей, порядок их логического или физического приведения в порядок, размещение по типам устройств, а также характеристики и пути доступа к данным.
От параметров физической модели зависят такие характеристики функционирования БД: объем памяти и время реакции системы. Физические параметры БД можно изменять в процессе ее эксплуатации с целью повышения эффективности функционирование системы. Изменение физических параметров не предопределяет необходимости изменения инфологической и даталогической моделей.
Схема взаимосвязи уровней представления данных в БД изображена на рис. 4.1. В соответствии с этими уровнями проектируется БД. Проектирование БД— это сложный и трудоемкий процесс, который требует привлечения многих высококвалифицированных специалистов. От того, насколько квалифицированно спроектирована БД, зависят производительность информационной системы и полнота обеспечения функциональных потребностей пользователей и прикладных программ. Неудачно спроектированная БД может усложнить процесс разработки прикладного программного обеспечения, обусловить необходимость использования более сложной логики, которая, в свою очередь, увеличит время реакции системы, а в дальнейшем может привести к необходимости перепроектирования логической модели БД. Реструктуризация или внесение изменений в логическую модель БД это очень нежелательный процесс, поскольку он является причиной необходимости модификации или даже перепрограммирование отдельных задач.
Все работы, которые выполняются на каждом этапе проектирования, должны интегрироваться со словарем данных. Каждый этап проектирования рассматривается как определенная последовательность итеративных процедур, в результате которых формируется определенная модель БД.
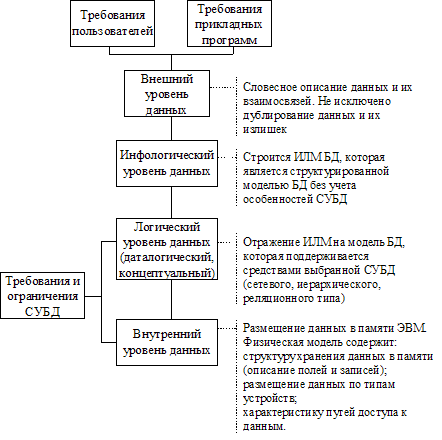
Рис. 4.1. Схема взаимосвязи уровней представление данных в БД
Внешний уровень — подготовительный этап инфологического проектированияЦелью проектирования на внешнем уровне является разработка внемашинного информационного обеспечения, которое включает систему входной (первичной) документации, характеризующую определенную предметную область, систему классификации и кодирования технико-экономической информации, а также перечень соответствующих выходных сообщений, которые нужно формировать с помощью БнД.
Существуют два подхода к проектированию баз данных на внешнем уровне: «от предметной области» и «от запроса». Подход «от предметной области» состоит в том, что формируется внешнее информационное обеспечение всей предметной области без учета потребностей пользователей и прикладных программ. Иногда этот подход называют еще объектным или непроцессным.
При подходе «от запроса» основным источником информации о предметной области есть изучение запросов пользователей и потребностей прикладных программ. Этот подход также называется процессным или функциональным. При таком подходе БД проектируется для выполнения текущих задач управления без учета возможности расширение системы и возникновение новых задач управление.
Преимущество подхода «от предметной области» это его объективность, системность при отображении ПО и стойкость информационной модели, возможность реализации большого количества прикладных программ и запросов, в том числе незапланированных при создании БД. Недостатком этого подхода является значительный объем работ, которые необходимо выполнить при определении информации. подлежащей хранению в БД, что, соответственно, усложняет и увеличивает срок разработки проекта.
Функциональный подход ориентирован на реализацию текущих требований пользователей и прикладных программ без учета перспектив развития системы. При его использовании могут возникнуть сложности в агрегации требований разных пользователей и прикладных программ. Тем не менее, при таком подходе значительно уменьшается трудоемкость проектирования, и поэтому возможно создать систему с высокими эксплуатационными характеристиками.
Однако взятый в отдельности любой из этих методов не может дать достаточно информации для проектирования рациональной структуры БД. Поэтому при проектировании БД целесообразно совместно использовать эти два подхода. Если схематично представить процесс проектирования БД на внешнем уровне, то он состоит из таких работ.
1. Определение функциональных задач предметной области, которые подлежат автоматизированному решению. Поскольку основной целью создания БД есть обеспечение информацией функций обработки данных, то, прежде всего, необходимо изучить все функции предметной области (объекта управления), для которой разрабатывается база данных, и проанализировать их особенности. Функции и функциональные особенности объекта управление необходимо изучать в неразрывной связи с изучением функциональных требований к данным со стороны будущих пользователей информационной системы. Изучение и анализ предусматривают выявление информационных потребностей и определения информационных потоков. Эти работы можно выполнять обследованием предметной области и анкетированием ее сотрудников. Результатом такого изучения может быть перечень функциональных задач, которые должны решаться автоматизированным способом с использованием БД.
2. Изучение и анализ оперативных первичных документов. Изучив функции и определив перечень функциональных задач, которые подлежат автоматизированному решению, переходят к изучению оперативных документов, которые используются на входе каждой задачи или их комплекса. Изучив и проанализировав все оперативные документы (как внешние, так и внутренние), которые используются на входе каждой задачи, определяют, какие реквизиты этих документов нужно сохранять в БД.
3. Изучение нормативно-справочных документов. На третьем шаге изучают и анализируют всю нормативно-справочную документацию. К такой документации принадлежат различные классификаторы, сметы, договоры, нормативы, законодательные акты по налоговой политике, плановая документация и т.п. Распределение и отдельный анализ оперативной и нормативно-справочной информации обусловлены технологически. В базы данных различаются технологии создания и ведения файлов условно-постоянной информации, размещенной в нормативно-справочной документации, и файлов оперативной информации.
4. Изучение процессов преобразования входных сообщений в выходные. Прежде всего, изучаются все выходные сообщения, которые выдаются на печать или на экран и сохраняются в виде выходных массивов на МД. Это необходимо для того, чтобы определить, которые из атрибутов входных сообщений нужно сохранять в БД для получения выходных сообщений. Кроме того, на этом этапе определяются те показатели, которые получают во время решения задачи в результате выполнения определенных вычислений. По каждому расчетному показателю следует определить алгоритм его формирования и убедиться в том, что этот показатель можно получить на основе атрибутов оперативной и нормативно-справочной информации, которые были определены на втором и третьем шагах. Если определенных данных не хватает для полного выполнения расчетов, необходимо возвратиться назад, провести дополнительное исследование и определить, где и каким способом можно получить атрибуты, которых не хватает.
Кроме того, нужно определиться, какие из расчетных показателей целесообразно сохранять в БД. Показатели, полученные расчетным путем, как правило, в БД не сохраняются. Исключением являются случаи, когда расчетный показатель нужно использовать для решения других задач или для данной задачи, но в следующие календарные периоды.
При проведении проектных работ на внешнем уровне надо учитывать то, что для выполнения определенных функций в БД необходимо сохранять дополнительные данные, которые не отображены в документах (данные календаря, статистические данные и т.п.). Обобщенная схема процесса изучения документов и данных при проектировании на внешнем уровне изображена на рис. 4.2.
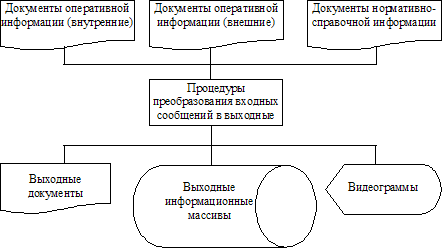
Рис.4.2. Обобщенная схема процесса проектирование на внешнем уровне
Такое изучение необходимо провести по каждой функциональной задаче или их комплексу, которые будут решаться с помощью БД.
Результатом проектирования на внешнем уровне будет перечень атрибутов (реквизитов) оперативной и условно-постоянной информации, которые необходимо хранить в БД, с указанием источников их получения и формы представления. Однако этот перечень не исключает возможности существования в нем избыточности, дублирования, несогласованности и других недостатков. Поэтому на этом процесс не заканчивается, а осуществляется переход к этапу инфологического проектирования.
Составные части инфологической моделиОсновными составными элементами инфологической модели являются сущности (информационные объекты), связи между ними и их атрибуты (свойства).
Сущность – любой различимый объект (объект, который мы можем отличить от другого), информацию о котором необходимо хранить в базе данных. Сущностями могут быть люди, места, самолеты, рейсы, вкус, цвет и т.д. Необходимо различать такие понятия, как тип сущности и экземпляр сущности. Понятие тип сущности относится к набору однородных личностей, предметов, событий или идей, выступающих как целое. Экземпляр сущности относится к конкретной вещи в наборе. Например, типом сущности может быть ГОРОД, а экземпляром – Москва, Киев и т.д.
Атрибут – поименованная характеристика сущности. Его наименование должно быть уникальным для конкретного типа сущности, но может быть одинаковым для различного типа сущностей (например, ЦВЕТ может быть определен для многих сущностей: СОБАКА, АВТОМОБИЛЬ, ДЫМ и т.д.). Атрибуты используются для определения того, какая информация должна быть собрана о сущности. Примерами атрибутов для сущности АВТОМОБИЛЬ являются ТИП, МАРКА, НОМЕРНОЙ ЗНАК, ЦВЕТ и т.д. Здесь также существует различие между типом и экземпляром. Тип атрибута ЦВЕТ имеет много экземпляров или значений: Красный, Синий, Банановый, Белая ночь и т.д., однако, каждому экземпляру сущности присваивается только одно значение атрибута.
Абсолютное различие между типами сущностей и атрибутами отсутствует. Атрибут является таковым только в связи с типом сущности. В другом контексте атрибут может выступать как самостоятельная сущность. Например, для автомобильного завода цвет – это только атрибут продукта производства, а для лакокрасочной фабрики цвет – тип сущности.
Ключ – минимальный набор атрибутов, по значениям которых можно однозначно найти требуемый экземпляр сущности. Минимальность означает, что исключение из набора любого атрибута не позволяет идентифицировать сущность по оставшимся. Для сущности Расписание ключом является атрибут Номер_рейса или набор: Пункт_отправления, Время_вылета и Пункт_назначения (при условии, что из пункта в пункт вылетает в каждый момент времени один самолет).
Связь – ассоциирование двух или более сущностей. Если бы назначением базы данных было только хранение отдельных, не связанных между собой данных, то ее структура могла бы быть очень простой. Однако одно из основных требований к организации базы данных – это обеспечение возможности отыскания одних сущностей по значениям других, для чего необходимо установить между ними определенные связи. А так как в реальных базах данных нередко содержатся сотни или даже тысячи сущностей, то теоретически между ними может быть установлено более миллиона связей. Наличие такого множества связей и определяет сложность инфологических моделей.
Требования и подходы к инфологическому проектированиюЦелью инфологического проектирования есть создание структурированной информационной модели ПО, для которой будет разрабатываться БД. При проектировании на инфологическом уровне создается информационно-логическая модель (ИЛМ), которая должна отвечать таким требованиям:
- обеспечение наиболее естественных для человека способов сбора и представления той информации, которую предполагается хранить в создаваемой базе данных;
- корректность схемы БД, то есть адекватное отображение моделированной ПО;
- простота и удобство использования на следующих этапах проектирования, то есть ИЛМ может легко отображаться на модели БД, которые поддерживаются известными СУБД (сетевые, иерархические, реляционные и др.);
- ИЛМ должна быть описана языком, понятным проектировщикам БД, программистам, администратору и будущим пользователям.
Суть инфологического моделирования состоит в выделении сущностей (информационных объектов ПО), которые подлежат хранению в БД, а также в определении характеристик (атрибутов) объектов и взаимосвязей между ними.
Существует два подхода к инфологическому проектированию: анализ объектов и синтез атрибутов. Подход, который базируется на анализе объектов, называется нисходящим, а на синтезе атрибутов — восходящим.
Похожие работы

... подчеркнуть их существенное отличие от БД, используемых для реализации ХД. Средства анализа. Приложения для конечного пользователя, включая средства принятия решений, средства OLAP и другие специализированные средства анализа, прогноза и представления данных. 3 Базы и хранилища данных Ни для кого не секрет, что одним из основных факторов успеха в бизнесе и управлении является скорость и ...
... на модели данных, реализованные в различных СУБД. Наибольшую популярность получили CASE-системы для реляционных СУБД с SQL-моделями данных, а DD/D переименовался в CASE-репозиторий проектируемой ИС. На этом пути возникло два основных направления развития CASE-систем и технологий проектирования: CASE-системы для проектирования собственно БД (или т. н. Upper-CASE) и интегрированные инструменты, ...
... хранилищ данных. Но, несмотря на то что хранилища обладают общими свойствами, разные типы хранилищ имеют свои индивидуальные особенности. 3. Технологии управления информацией Для работы с хранилищем данных используются СУБД, к которым предъявляются специальные требования. Поскольку в ходе обсуждения проблем хранилищ данных эти требования либо уже обсуждались, либо присутствие их в перечне и ...
... кварталов... повернуть направо...". (Аналогично больший или меньший уровень детализации запроса приходится создавать пользователю в разных СУБД, не имеющих языка SQL.) Появление теории реляционных баз данных и предложенного Коддом языка запросов "alpha", основанного на реляционном исчислении [2, 3], инициировало разработку ряда языков запросов, которые можно отнести к двум классам: 1. ...
0 комментариев