Навигация
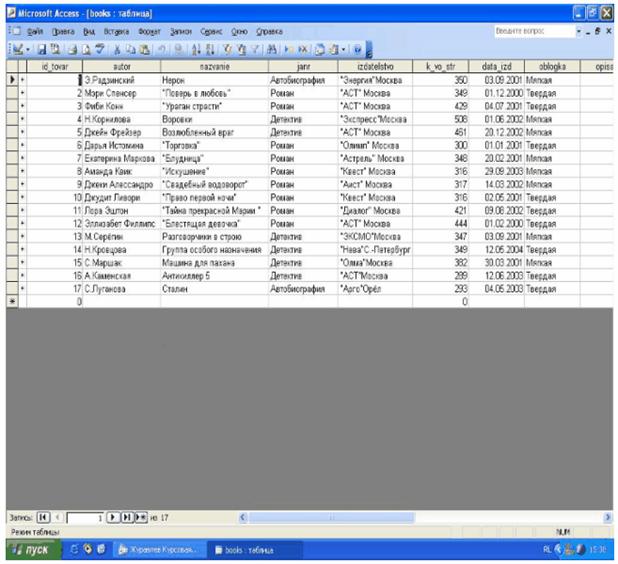
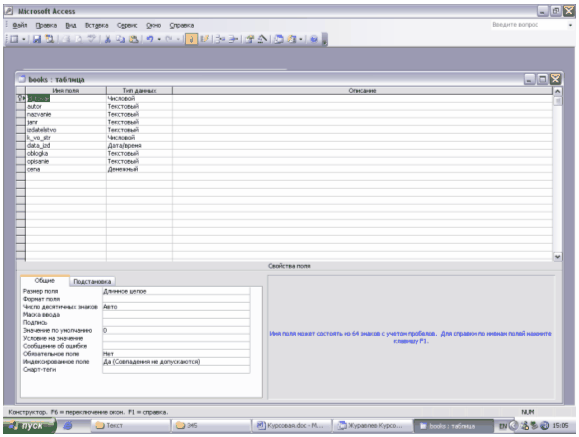
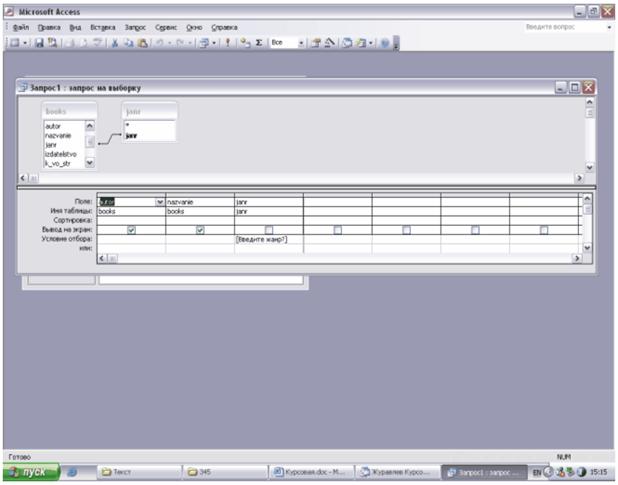
Проектирование баз и хранилищ данных
74648
знаков
0
таблиц
6
изображений
Теория баз данных — сравнительно молодая область знаний Возраст ее составляет немногим более 30 лет. Однако изменился ритм времени, оно уже не бежит, а летит, и мы вынуждены подчиняться ему во всем. И действительно, современный мир информационных технологий трудно представить себе без использования баз данных. Практически все системы в той или иной степени связаны с функциями долговременного хранения и обработки информации. Фактически информация становится фактором, определяющим эффективность любой сферы деятельности. Увеличились информационные потоки и повысились требования к скорости обработки данных, и теперь уже большинство операций не может быть выполнено вручную, они требуют применения наиболее перспективных компьютерных технологий. Любые административные решения требуют четкой и точной оценки текущей ситуации и возможных перспектив ее изменения. И если раньше в оценке ситуации участвовало несколько десятков факторов, которые могли быть вычислены вручную, то теперь таких факторов сотни и сотни тысяч, и ситуация меняется не в течение года, а через несколько минут, а обоснованность принимаемых решений требуется большая, потому что и реакция на неправильные решения более серьезная, более быстрая и более мощная, чем раньше. И, конечно, обойтись без информационной модели производства, хранимой в базе данных, в этом случае невозможно.
Тема 1. Введение. История развития баз данныхВ истории вычислительной техники можно проследить развитие двух основных областей ее использования. Первая область — применение вычислительной техники для выполнения численных расчетов, которые слишком долго или вообще невозможно производить вручную. Развитие этой области способствовало интенсификации методов численного решения сложных математических задач, появлению языков программирования, ориентированных на удобную запись численных алгоритмов, становлению обратной связи с разработчиками новых архитектур ЭВМ. Характерной особенностью данной области применения вычислительной техники является наличие сложных алгоритмов обработки, которые применяются к простым по структуре данным, объем которых сравнительно невелик.
Вторая область — это использование средств вычислительной техники в автоматических или автоматизированных информационных системах. Информационная система представляет собой программно-аппаратный комплекс, обеспечивающий выполнение следующих функций:
· надежное хранение информации в памяти компьютера;
· выполнение специфических для данного приложения преобразований информации и вычислений;
· предоставление пользователям удобного и легко осваиваемого интерфейса.
Обычно такие системы имеют дело с большими объемами информации, имеющей достаточно сложную структуру. Классическими примерами информационных систем являются банковские системы, автоматизированные системы управления предприятиями, системы резервирования авиационных и железнодорожных билетов, мест в гостиницах и т.д.
Вторая область использования вычислительной техники возникла несколько позже первой. Это связано с тем, что на заре вычислительной техники возможности компьютеров по хранению информации были очень ограниченными. Говорить о надежном и долговременном хранении информации можно только при наличии запоминающих устройств, сохраняющих информацию после выключения электрического питания. Оперативная (основная) память компьютеров этим свойством обычно не обладает. В первых компьютерах использовались два вида устройств внешней памяти — магнитные ленты и барабаны. Емкость магнитных лент была достаточно велика, но по своей физической природе они обеспечивали последовательный доступ к данным. Магнитные же барабаны (они ближе всего к современным магнитным дискам с фиксированными головками) давали возможность произвольного доступа к данным, но имели ограниченный объем хранимой информации.
Эти ограничения не являлись слишком существенными для чисто численных расчетов, Даже если программа должна обработать (или произвести) большой объем информации, при программировании можно продумать расположение этой информации во внешней памяти (например, на последовательной магнитной ленте), обеспечивающее эффективное выполнение этой программы. Однако в информационных системах совокупность взаимосвязанных информационных объектов фактически отражает модель объектов реального мира. А потребность пользователей в информации, адекватно отражающей состояние реальных объектов, требует сравнительно быстрой реакции системы на их запросы. И в этом случае наличие сравнительно медленных устройств хранения данных, к которым относятся магнитные ленты и барабаны, было недостаточным.
Можно предположить, что именно требования нечисловых приложений вызвали появление съемных магнитных дисков с подвижными головками, что явилось революцией в истории вычислительной техники. Эти устройства внешней памяти обладали существенно большей емкостью, чем магнитные барабаны, обеспечивали удовлетворительную скорость доступа к данным в режиме произвольной выборки, а возможность смены дискового пакета на устройстве позволяла иметь практически неограниченный архив данных.
С появлением магнитных дисков началась история систем управления данными во внешней памяти. До этого каждая прикладная программа, которой требовалось хранить данные во внешней памяти, сама определяла расположение каждой порции данных на магнитной ленте или барабане и выполняла обмены между оперативной памятью и устройствами внешней памяти с помощью программно-аппаратных средств низкого уровня (машинных команд или вызовов соответствующих программ операционной системы). Такой режим работы не позволяет или очень затрудняет поддержание на одном внешнем носителе нескольких архивов долговременно хранимой информации. Кроме того, каждой прикладной программе приходилось решать проблемы именования частей данных и структуризации данных во внешней памяти.
Файлы и файловые системыВажным шагом в развитии именно информационных систем явился переход к использованию централизованных систем управления файлами. С точки зрения прикладной программы, файл — это именованная область внешней памяти, и которую можно записывать и из которой можно считывать данные. Правила именования файлов, способ доступа к данным, хранящимся в файле, и структура этих данных зависят от конкретной системы управления файлами и, возможно, от типа файла. Система управления файлами берет на себя распределение внешней памяти, отображение имен файлов в соответствующие адреса во внешней памяти и обеспечение доступа к данным.
Такие системы иногда называются файловыми. Несмотря на относительную простоту организации, файловые системы имеют ряд недостатков:
1. Избыточность данных. Файловые системы характеризуются значительной избыточностью, поскольку нередко для решения различных задач управления используются одни и одни и те же данные, размещенные в разных файлах. Из-за дублирования данных в разных файлах память на внешних запоминающих устройствах используется неэкономно, информация одного и одного и того же объекта управления распределяется между многими файлами. При этом довольно тяжело представить общую информационную модель предметной области.
2. Несогласованность данных. Учитывая, что одна и одна и та же информация может размещаться в разных файлах, технологически тяжело проследить за внесением изменений одновременно во все файлы. Из-за этого может возникнуть несогласованность данных, когда одно и одно и то же поле в разных файлах может иметь разные значения.
3. Зависимость структур данных и прикладных программ. При файловой организации логическая и физическая структуры файла должны соответствовать их описанию в прикладной программе. Прикладная программа должна быть модифицирована при любом изменении логической или физической структуры файла. Поскольку изменения в одной программе часто требуют внесения изменений в другие информационно-связанные программы, то иногда проще создать новую программу, чем вносить изменения в старую. Поэтому этот недостаток файловых систем приводит к значительному увеличению стоимости сопровождения программных средств. Иногда стоимость сопровождения программных средств может достигать близко 70 % стоимости их разработки.
Пользователи видят файл как линейную последовательность записей и могут выполнить над ним ряд стандартных операций:
· создать файл (требуемого типа и размера);
· открыть ранее созданный файл;
· прочитать из файла некоторую запись (текущую, следующую, предыдущую, первую, последнюю);
· записать в файл на место текущей записи новую, добавить новую запись в конец файла.
В разных файловых системах эти операции могли несколько отличаться, но общий смысл их был именно таким. Главное, что следует отметить, это то, что структура записи файла была известна только программе, которая с ним работала, система управления файлами не знала ее. И поэтому для того, чтобы извлечь некоторую информацию из файла, необходимо было точно знать структуру записи файла с точностью до бита. Каждая программа, работающая с файлом, должна была иметь у себя внутри структуру данных, соответствующую структуре этого файла. Поэтому при изменении структуры файла требовалось изменять структуру программы, а это требовало новой компиляции, то есть процесса перевода программы в исполняемые машинные коды. Такая ситуации характеризовалась как зависимость программ от данных. Для информационных систем характерным является наличие большого числа различных пользователей (программ), каждый из которых имеет свои специфические алгоритмы обработки информации, хранящейся в одних и тех же файлах. Изменение структуры файла, которое было необходимо для одной программы, требовало исправления и перекомпиляции и дополнительной отладки всех остальных программ, работающих с этим же файлом. Это было первым существенным недостатком файловых систем, который явился толчком к созданию новых систем хранения и управления информацией.
Для иллюстрации обратимся к примеру, приведенному в книге: У.Девис, Операционные системы, М., Мир, 1980:
«Несколько лет назад почтовое ведомство (из лучших побуждений) пришло к решению, что все адреса должны обязательно включать почтовый индекс. Во многих вычислительных центрах это, казалось бы, незначительное изменение привело к ужасным последствиям. Добавление к адресу нового поля, содержащего шесть символов, означало необходимость внесения изменений в каждую программу, использующую данные этой задачи в соответствии с изменившейся суммарной длиной полей. Тот факт, что какой-то программе для выполнения ее функций не требуется знания почтового индекса, во внимание не принимался: если в некоторой программе содержалось обращение к новой, более длинной записи, то в такую программу вносились изменения, обеспечивающие дополнительное место в памяти.
В условиях автоматизированного управления централизованной базой данных все такие изменения связаны с функциями управляющей программы базы данных. Программы, не использующие значения почтового индекса, не нуждаются в модификации - в них, как и прежде, в соответствии с запросами посылаются те же элементы данных. В таких случаях внесенное изменение неощутимо. Модифицировать необходимо только те программы, которые пользуются новым элементом данных».
Далее, поскольку файловые системы являются общим хранилищем файлов, принадлежащих, вообще говоря, разным пользователям, системы управления файлами должны обеспечивать авторизацию доступа к файлам. В общем виде подход состоит в том, что по отношению к каждому зарегистрированному пользователю данной вычислительной системы для каждого существующего файла указываются действия, которые разрешены или запрещены данному пользователю. В большинстве современных систем управления файлами применяется подход к защите файлов, впервые реализованный в ОС UNIX. В этой ОС каждому зарегистрированному пользователю соответствует пара целочисленных идентификаторов: идентификатор группы, к которой относится этот пользователь, и его собственный идентификатор в группе. При каждом файле хранится полный идентификатор пользователя, который создал этот файл, и фиксируется, какие действия с файлом может производить его создатель, какие действия с файлом доступны для других пользователей той же группы и что могут делать с файлом пользователи других групп. Администрирование режимом доступа к файлу в основном выполняется его создателем-владельцем, Для множества файлов, отражающих информационную модель одной предметной области, такой децентрализованный принцип управления доступом вызывал дополнительные трудности. И отсутствие централизованных методов управления доступом к информации послужило еще одной причиной разработки СУБД.
Следующей причиной стала необходимость обеспечения эффективной параллельной работы многих пользователей с одними и теми же файлами. В общем случае системы управления файлами обеспечивали режим многопользовательского доступа, Если операционная система поддерживает многопользовательский режим, вполне реальна ситуация, когда два или более пользователя одновременно пытаются работать с одним и тем же файлом. Если все пользователи собираются только читать файл, ничего страшного не произойдет. Но если хотя бы один из них будет изменять файл, для корректной работы этих пользователей требуется взаимная синхронизация их действий по отношению к файлу.
В системах управления файлами обычно применялся следующий подход. В операции открытия файла (первой и обязательной операции, с которой должен начинаться сеанс работы с файлом) среди прочих параметров указывался режим работы (чтение или изменение). Если к моменту выполнения этой операции некоторым пользовательским процессом PR1 файл был уже открыт другим процессом PR2 в режиме изменения, то и зависимости от особенностей системы процессу PR1 либо сообщались и невозможности открытия файла, либо он блокировался до тех пор, пока в процессе PR2 не выполнялась операция закрытия файла.
При подобном способе организации одновременная работа нескольких пользователей, связанная с модификацией данных в файле, либо вообще не реализовывалась, либо была очень замедлена.
Эти недостатки послужили тем толчком, который заставил разработчиков информационных систем предложить новый подход к управлению информацией. Этот подход был реализован в рамках новых программных систем, названных впоследствии Системами Управления Базами Данных (СУБД), а сами хранилища информации, которые работали под управлением данных систем, назывались базами или банками данных (БД и БнД).
Первый этап — базы данных на больших ЭВМИстория развития СУБД насчитывает более 30 лет. В 1968 году была введена в эксплуатацию первая промышленная СУБД система IMS фирмы IBM. В 1975 году появился первый стандарт ассоциации по языкам систем обработки данных — Conference of Data System Languages (CODASYL), который определил ряд фундаментальных понятий в теории систем баз данных, которые и до сих пор являются основополагающими для сетевой модели данных.
В дальнейшее развитие теории баз данных большой вклад был сделан американским математиком Э. Ф. Коддом, который является создателем реляционной модели данных. В 1981 году Э. Ф. Кодд получил за создание реляционной модели и реляционной алгебры престижную премию Тьюринга Американской ассоциации по вычислительной технике.
Менее двух десятков лет прошло с этого момента, но стремительное развитие вычислительной техники, изменение ее принципиальной роли в жизни общества, обрушившийся бум персональных ЭВМ и, наконец, появление мощных рабочих станций и сетей ЭВМ повлияло также и на развитие технологии баз данных. Можно выделить четыре этапа в развитии данного направления в обработке данных. Однако необходимо заметить, что все же нет жестких временных ограничений в этих этапах: они плавно переходят один в другой и даже сосуществуют параллельно, но, тем не менее, выделение этих этапов позволит более четко охарактеризовать отдельные стадии развития технологии баз данных, подчеркнуть особенности, специфичные для конкретного этапа.
Первый этап развития СУБД связан с организацией баз данных на больших машинах типа IBM 360/370, ЕС-ЭВМ и мини-ЭВМ типа PDP11 (фирмы Digital Equipment Corporation — DEC), разных моделях HP (фирмы Hewlett Packard).
Базы данных хранились во внешней памяти центральной ЭВМ, пользователями этих баз данных были задачи, запускаемые в основном в пакетном режиме. Интерактивный режим доступа обеспечивался с помощью консольных терминалов, которые не обладали собственными вычислительными ресурсами (процессором, внешней памятью) и служили только устройствами ввода-вывода для центральной ЭВМ. Программы доступа к БД писались на различных языках и запускались как обычные числовые программы. Мощные операционные системы обеспечивали возможность условно параллельного выполнения всего множества задач. Эти системы можно было отнести к системам распределенного доступа, потому что база данных была централизованной, хранилась на устройствах внешней памяти одной центральной ЭВМ, а доступ к ней поддерживался от многих пользователей-задач.
Особенности этого этапа развития выражаются в следующем:
Ø Все СУБД базируются на мощных мультипрограммных операционных системах (MVS, SVM, RTE, OSRV, RSX, UNIX), поэтому в основном поддерживается работа с централизованной базой данных в режиме распределенного доступа.
Ø Функции управления распределением ресурсов в основном осуществляются операционной системой (ОС).
Ø Поддерживаются языки низкого уровня манипулирования данными, ориентированные на навигационные методы доступа к данным.
Ø Значительная роль отводится администрированию данных.
Ø Проводятся серьезные работы по обоснованию и формализации реляционной модели данных, и была создана первая система (System R), реализующая идеологию реляционной модели данных.
Ø Проводятся теоретические работы по оптимизации запросов и управлению распределенным доступом к централизованной БД, было введено понятие транзакции.
Ø Результаты научных исследований открыто обсуждаются в печати, идет мощный поток общедоступных публикаций, касающихся всех аспектов теории и практики баз данных, и результаты теоретических исследований активно внедряются в коммерческие СУБД.
Появляются первые языки высокого уровня для работы с реляционной моделью данных. Однако отсутствуют стандарты для этих первых языков.
Второй этап - эпоха персональных компьютеровПерсональные компьютеры стремительно ворвались в нашу жизнь и буквально перевернули наше представление о месте и роли вычислительной техники в жизни общества. Теперь компьютеры стали ближе и доступнее каждому пользователю. Исчез благоговейный страх рядовых пользователей перед непонятными и сложными языками программирования. Появилось множество программ, предназначенных для работы неподготовленных пользователей. Эти программы были просты в использовании и интуитивно понятны: это, прежде всего, различные редакторы текстов, электронные таблицы и другие. Простыми и понятными стали операции копирования файлов и перенос информации с одного компьютера на другой, распечатка текстов, таблиц и других документов. Системные программисты были отодвинуты на торой план. Каждый пользователь мог себя почувствовать полным хозяином этого мощного и удобного устройства, позволяющего автоматизировать многие аспекты деятельности. И, конечно, это сказалось и на работе с базами данных. Появились программы, которые назывались системами управления базами данных и позволяли хранить значительные объемы информации, они имели удобный интерфейс для заполнения данных, встроенные средства для генерации различных отчетов. Эти программы позволяли автоматизировать многие учетные функции, которые раньше велись вручную. Постоянное снижение цен на персональные компьютеры сделало их доступными не только для организаций и фирм, но и для отдельных пользователей. Компьютеры стали инструментом для ведения документации и собственных учетных функций. Это все сыграло как положительную, так и отрицательную роль в области развития баз данных. Кажущаяся простота и доступность персональных компьютеров и их программного обеспечения породила множество дилетантов. Эти разработчики, считая себя знатоками, стали проектировать недолговечные базы данных, которые не учитывали многих особенностей объектов реального мира. Много было создано систем-однодневок, которые не отвечали законам развития и взаимосвязи реальных объектов. Однако доступность персональных компьютеров заставила пользователей из многих областей знаний, которые ранее не применяли вычислительную технику в своей деятельности, обратиться к ним. И спрос на развитые удобные программы обработки данных заставлял поставщиков программного обеспечения поставлять все новые системы, которые принято называть настольными (desktop) СУБД. Значительная конкуренция среди поставщиков заставляла совершенствовать эти системы, предлагая новые возможности, улучшая интерфейс и быстродействие систем, снижая их стоимость. Наличие на рынке большого числа СУБД, выполняющих сходные функции, потребовало разработки методов экспорта-импорта данных для этих систем и открытия форматов хранения данных.
Но и в этот период появлялись любители, которые вопреки здравому смыслу разрабатывали собственные СУБД, используя стандартные языки программирования. Это был тупиковый вариант, потому что дальнейшее развитие показало, что перенести данные из нестандартных форматов в новые СУБД было гораздо труднее, а в некоторых случаях требовало таких трудозатрат, что легче было бы все разработать заново, но данные все равно надо было переносить на новую более перспективную СУБД. И это тоже было результатом недооценки тех функций, которые должна была выполнять СУБД.
Особенности этого этапа следующие:
Ø Все СУБД были рассчитаны на создание БД в основном с монопольным доступом. И это понятно. Компьютер персональный, он не был подсоединен к сети, и база данных на нем создавалась для работы одного пользователя. В редких случаях предполагалась последовательная работа нескольких пользователей, например, сначала оператор, который вводил бухгалтерские документы, а потом главбух, который определял проводки, соответствующие первичным документам.
Ø Большинство СУБД имели развитый и удобный пользовательский интерфейс, В большинстве существовал интерактивный режим работы с БД, как в рамках описания БД, так и в рамках проектирования запросов. Кроме того, большинство СУБД предлагали развитый и удобный инструментарии для разработки готовых приложений без программирования. Инструментальная среда состояла из готовых элементов приложения в виде шаблонов экранных форм, отчетов, этикеток (Labels), графических конструкторов запросов, которые достаточно просто могли быть собраны в единый комплекс.
Ø Во всех настольных СУБД поддерживался только внешний уровень представления реляционной модели, то есть только внешний табличный вид структур данных.
Ø При наличии высокоуровневых языков манипулирования данными типа реляционной алгебры и SQL в настольных СУБД поддерживались низкоуровневые языки манипулирования данными на уровне отдельных строк таблиц.
Ø В настольных СУБД отсутствовали средства поддержки ссылочной и структурной целостности базы данных. Эти функции должны были выполнять приложения, однако скудость средств разработки приложений иногда не позволяла это сделать, и в этом случае эти функции должны были выполняться пользователем, требуя от него дополнительного контроля при вводе и изменении информации, хранящейся в БД.
Ø Наличие монопольного режима работы фактически привело к вырождению функций администрирования БД и в связи с этим — к отсутствию инструментальных средств администрирования БД.
Ø И, наконец, последняя и в настоящий момент весьма положительная особенность — это сравнительно скромные требования к аппаратному обеспечению со стороны настольных СУБД. Вполне работоспособные приложения, разработанные, например, на Clipper, работали на PC 286.
В принципе, их даже трудно назвать полноценными СУБД. Яркие представители этого семейства это очень широко использовавшиеся до недавнего времени СУБД dBase (dBase III+, dBase IV), FoxPro, Clipper, Paradox.
Третий этап - распределенные базы данныхХорошо известно, что история развивается по спирали, поэтому после процесса «персонализации» начался обратный процесс — интеграция. Множится количество локальных сетей, все больше информации передастся между компьютерами, остро встает задача согласованности данных, хранящихся и обрабатывающихся в разных местах, но логически друг с другом связанных, возникают задачи, связанные с параллельной обработкой транзакций — последовательностей операций над БД, переводящих ее из одного непротиворечивого состояния в другое непротиворечивое состояние. Успешное решение этих задач приводит к появлению распределенных баз данных, сохраняющих все преимущества настольных СУБД и в то же время позволяющих организовать параллельную обработку информации и поддержку целостности БД.
Особенности данного этапа:
Ø Практически все современные СУБД обеспечивают поддержку полной реляционной модели, а именно:
· структурной целостности — допустимыми являются только данные, представленные в виде отношений реляционной модели;
· языковой целостности, то есть языков манипулирования данными высокого уровня (в основном SQL);
· ссылочной целостности — контроля за соблюдением ссылочной целостности в течение всего времени функционирования системы, и гарантий невозможности со стороны СУБД нарушить эти ограничения.
Ø Большинство современных СУБД рассчитаны на многоплатформенную архитектуру, то есть они могут работать на компьютерах с разной архитектурой и под разными операционными системами, при этом для пользователей доступ к данным, управляемым СУБД, на разных платформах практически неразличим.
Ø Необходимость поддержки многопользовательской работы с базой данных и возможность децентрализованного храпения данных потребовали развития средств администрирования БД с реализацией общей концепции средств защиты данных.
Ø Потребность в новых реализациях вызвала создание серьезных теоретических трудов по оптимизации реализации распределенных БД и работе с распределенными транзакциями и запросами с внедрением полученных результатов в коммерческие СУБД.
Ø Для того чтобы не потерять клиентов, которые ранее работали на настольных СУБД, практически все современные СУБД имеют средства подключения клиентских приложений, разработанных с использованием настольных СУБД, и средства экспорта данных из форматов настольных СУБД второго этапа развития.
К этому этапу можно отнести разработку ряда стандартов в рамках языков описания и манипулирования данными (SQL89, SQL92, SQL99) и технологий по обмену данными между различными СУБД, к которым можно отнести и протокол ODBC (Open DataBase Connectivity), предложенный фирмой Microsoft.
Именно к этому этапу можно отнести начало работ, связанных с концепцией объектно-ориентированных БД — ООБД. Представителями СУБД, относящимся ко второму этапу, можно считать MS Access 97 и все современные серверы баз данных Огас1е7.3, 0гас1е 8.4, MS SQL 6.5, MS SQL 7.0, System 10, System 11, Informix, DB2, SQL Base и другие современные серверы баз данных, которых в настоящий момент насчитывается несколько десятков.
Четвертый этап - перспективы развития систем управления базами данныхЭтот этап характеризуется появлением новой технологии доступа к данным — интранет. Основное отличие этого подхода от технологии клиент-сервер состоит в том, что отпадает необходимость использования специализированного клиентского программного обеспечения. Для работы с удаленной базой данных используется стандартный броузер Internet, например Microsoft Internet Explorer или Netscape Navigator, и для конечного пользователя процесс обращения к данным происходит аналогично скольжению по Всемирной Паутине. При этом встроенный в загружаемые пользователем HTML-страницы код, написанный обычно на языках Java, Java-script, Perl и других, отслеживает все действия пользователя и транслирует их в низкоуровневые SQL-запросы к базе данных, выполняя, таким образом, ту работу, которой в технологии клиент-сервер занимается клиентская программа. Удобство данного подхода привело к тому, что он стал использоваться не только для удаленного доступа к базам данных, но и для пользователей локальной сети предприятия. Простые задачи обработки данных, не связанные со сложными алгоритмами, требующими согласованного изменения данных во многих взаимосвязанных объектах, достаточно просто и эффективно могут быть построены по данной архитектуре. В этом случае для подключения нового пользователя к возможности использовать данную задачу не требуется установка дополнительного клиентского программного обеспечения. Однако алгоритмически сложные задачи рекомендуется реализовывать в архитектуре «клиент-сервер» с разработкой специального клиентского программного обеспечения.
У каждого из вышеперечисленных подходов к работе с данными есть свои достоинства и свои недостатки, которые и определяют область применения того или иного метода, и в настоящее время все подходы широко используются.
Тема 2. Основные понятия и определенияСовременные авторы часто употребляют термины – «банк данных» и «база данных» как синонимы, однако в общеотраслевых руководящих материалах по созданию банков данных Государственного комитета по науке и технике (ГКНТ), изданных в 1982 г., эти понятия различаются. Там приводятся следующие определения банка данных, базы данных и СУБД:
Банк данных (БнД) — это система специальным образом организованных данных — баз данных, программных, технических, языковых, организационно-методических средств, предназначенных для обеспечения централизованного накопления и коллективного многоцелевого использования данных.
База данных (БД) — именованная совокупность данных, отражающая состояние объектов и их отношений и рассматриваемой предметной области.
Под предметной областью понимают один или несколько объектов управления (или определенные их части), информация которых моделируется с помощью БД и используется для решения различных функциональных задач.
Система управления базами данных (СУБД) — совокупность языковых и программных средств, предназначенных для создания, ведения и совместного использования БД многими пользователями. В ней можно выделить:
- ядро СУБД, которое обеспечивает организацию ввода, обработки и хранения данных,
- компоненты, которые обеспечивают отладку системы, средства тестирования,
- утилиты, которые обеспечивают выполнение вспомогательных функций (например, ведение журнала статистики работы системы и др.).
Очень важной задачей СУБД является обеспечение независимости данных. Практически одна и одна и та же СУБД может быть использована для ведения абсолютно разных файлов, которые используются для решения разноплановых, не связанных между собою задач управления. Все функции СУБД можно объединить в такие группы:
1. Управление данными. Задачами управления данных является подготовка данных и их контроль, внесение данных в базу, структуризация данных, обеспечение целостности, секретности данных.
2. Доступ к данным. Поиск и селекция данных, преобразование данных в форму, удобную для дальнейшего использования.
3. Организация и ведение связи с пользователем. Ведение диалога, выдача диагностических сообщений об ошибках в работе по БД и т.д.
Для обработки запросов к БД разрабатывают программы, которые составляют прикладное программное обеспечение. Программы, с помощью которых пользователи работают с базой данных, называются приложениями. В общем случае с одной базой данных могут работать множество различных приложений. Например, если база данных моделирует некоторое предприятие, то для работы с ней может быть создано приложение, которое обслуживает подсистему учета кадров, другое приложение может быть посвящено работе подсистемы расчета заработной платы сотрудников, третье приложение работает как подсистема складского учета, четвертое приложение посвящено планированию производственного процесса. При рассмотрении приложений, работающих с одной базой данных, предполагается, что они могут работать параллельно и независимо друг от друга, и именно СУБД призвана обеспечить работу множества приложений с единой базой данных таким образом, чтобы каждое из них выполнялось корректно, но учитывало все изменения в базе данных, вносимые другими приложениями.
Языковые средства банка данныхЯзыковые средства СУБД, необходимые для описания данных, организации общения и выполнения процедур поиска и различных преобразований данных. Классификация языковых средств БнД, показанная на рис. 2.2, разработана американским комитетом CODASYL по проектированию и созданию БД.
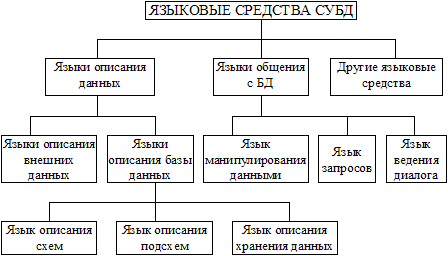
Рис.2.2. Схема классификации языковых средств БнД
Схема имеет общий характер и ориентирована на различные СУБД. Однако не каждая СУБД, которая сейчас используется на практике и распространена на рынке программных продуктов, имеет весь набор указанных языковых средств.
Язык описания данных (DDL - Data Definition Language), предназначен для описания данных на разных уровнях абстракции: внешнем, логическом и внутреннем. Исходя из предложений CODASYL, языки описания данных на логическом (концептуальном) и внутреннем уровнях независимые и разные. Однако в большинстве промышленных СУБД языки не делится на два отдельных языка описания логической и физической организации данных, а существует единый язык, которая еще называется языком описания схем. В известных и широко используемых на практике СУБД семьи dBASE применяется единый язык описания данных. Он предназначен для представления данных на логическом и физическом уровнях. Этот язык имеет свой синтаксис: например, имя файла не должно превышать восьми символов, а имя поля - десяти; при этом каждое имя может начинаться с буквы, поля календарной даты обозначаются символом D (DATA), символьные поля — С (CHARACTER), числовые — N (NUMERIC), логические — L (LOGICAL), примечаний — М (MEMO).
Описание всех имен, типов и размеров полей сохраняется в памяти вместе с данными; эти структуры в случае необходимости можно просмотреть и исправить. Если логический и физический уровни отделены, то в состав СУБД может входить язык описания сохранения данных. В некоторых СУБД используется еще язык описания подсхем, который нужен для описания части БД, которая отражает информационные потребности отдельного пользователя или прикладной программы. В составе СУБД типа dBASE такой язык не используется.
Язык описания данных на внешнем уровне используется для описания требований пользователей и прикладных программ и создания инфологической модели БД. Этот язык не имеет ничего общего с языками программирования. Так, языковым средством, которое используются для инфологического моделирования, является обычный естественный язык или его подмножество, а также язык графов и матриц.
Язык манипулирования данными (DML - Data Manipulation Language) используется для обработки данных, их преобразований и написания программ. DML может быть базовым или автономным.
Базовый язык DML — это один из традиционных языков программирования (BASIC, C, FORTRAN и др.). Системы, которые используют базовый язык, называют открытыми. Использование базовых языков как языков описания данных сужает круг лиц, которые могут непосредственно обращаться к БД, поскольку для этого нужно знать язык программирования. В таких случаях для упрощения общения конечных пользователей с БД предполагается язык ведения диалога, который значительно проще для овладения, чем язык программирования.
Автономный язык DML — это собственный язык СУБД, который дает возможность выполнять различные операции с данными. Системы с собственным языком называют закрытыми.
В современных СУБД для упрощения процедур поиска данных в БД предусмотрен язык запросов. Наиболее распространенными языками запросов являются SQL и QBE.
Язык запросов SQL (Structured Query Language - структурированный язык запросов) был создан фирмой IBM в рамках работы над проектом построения системы управления реляционными базами данных в начале 70-х годов. Американский национальный институт стандартов (ANSI) положил этот язык в основу стандарта языков реляционных баз данных, принятого Международной организацией стандартов (ISO). Ядром существующего стандарта SQL-86, которые часто называют SQL-2 или SQL-92, являются функции, реализованные практически во всех известных коммерческих реализациях языка, а полный стандарт вмещает такие усовершенствования, которые некоторые разработчики будут должны еще реализовать.
Кроме стандарта SQL-86 существует коммерческий стандарт языка SQL, разработанный консорциумом производителей баз данных SQL Access Group. Эта группа создала такой вариант языка, который используется большинством систем и дает возможность им «понимать» одна другую.
Был разработан стандартный интерфейс языка CLI (Common Language Interface) для всех основных вариантов языка SQL. Этот интерфейс, формализованный фирмой Microsoft, получил название ODBC (Open DataBase Connectivity — открытый доступ к данным). ODBC — это интерфейс доступа к данным, которые сохраняются под управлением разных СУБД. ODBC имеет целый набор драйверов, с помощью которых одна СУБД может работать с данными других систем. Архитектура ODBC изображена на рис 2.3.
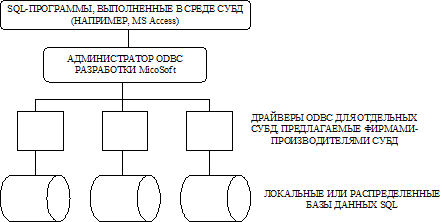
Рис. 2.3. Архитектура ODBC
Язык запросов QBE (Query By Example) — это реализация запросов по образцу в виде таблиц. Для определения запроса к БД пользователь должен заполнить предоставленную системой таблицу QBE и определить в ней критерии поиска и выбора данных.
Пользователи банков данныхКак любой программно-организационно-технический комплекс, банк данных существует во времени и в пространстве. Он имеет определенные стадии своего развития:
1. Проектирование.
2. Реализация.
3. Эксплуатация.
4. Модернизация и развитие.
5. Полная реорганизация.
На каждом этапе своего существования с банком данных связаны разные категории пользователей.
Определим основные категории пользователей и их роль в функционировании банка данных:
- Конечные пользователи. Это основная категория пользователей, в интересах которых и создается банк данных, В зависимости от особенностей создаваемого банка данных круг его конечных пользователей может существенно различаться. Это могут быть случайные пользователи, обращающиеся к БД время от времени за получением некоторой информации, а могут быть регулярные пользователи. В качестве случайных пользователей могут рассматриваться, например, возможные клиенты вашей фирмы, просматривающие каталог вашей продукции или услуг с обобщенным или подробным описанием того и другого. Регулярными пользователями могут быть ваши сотрудники, работающие со специально разработанными для них программами, которые обеспечивают автоматизацию их деятельности при выполнении своих должностных обязанностей. Например, менеджер, планирующий работу сервисного отдела компьютерной фирмы, имеет в своем распоряжении программу, которая помогает ему планировать и распределять текущие заказы, контролировать ход их выполнения, заказывать на складе необходимые комплектующие для новых заказов. Главный принцип состоит в том, что от конечных пользователей не должно требоваться каких-либо специальных знании в области вычислительной техники и языковых средств.
- Администраторы банка данных. Это группа пользователей, которая на начальной стадии разработки банка данных отвечает за его оптимальную организацию с точки зрения одновременной работы множества конечных пользователей, на стадии эксплуатации отвечает за корректность работы данного банка информации и многопользовательском режиме. На стадии развития и реорганизации эта группа пользователей отвечает за возможность корректной реорганизации банка без изменения или прекращения его текущей эксплуатации.
- Разработчики и администраторы приложений. Это группа пользователей, которая функционирует во время проектирования, создания и реорганизации банка данных. Администраторы приложений координируют работу разработчиков при разработке конкретного приложения или группы приложений, объединенных в функциональную подсистему. Разработчики конкретных приложений работают с той частью информации из базы данных, которая требуется для конкретного приложения.
Не в каждом банке данных могут быть выделены все тины пользователей. Мы уже знаем, что при разработке информационных систем с использованием настольных СУБД администратор банка данных, администратор приложении и разработчик часто существовали в одном лице. Однако при построении современных сложных корпоративных баз данных, которые используются для автоматизации всех или большей части бизнес-процессов в крупной фирме или корпорации, могут существовать и группы администраторов приложений, и отделы разработчиков. Наиболее сложные обязанности возложены на группу администратора БД.
Рассмотрим их более подробно. В составе группы администратора БД должны быть:
· системные аналитики;
· проектировщики структур данных и внешнего по отношению к банку данных информационного обеспечения;
· проектировщики технологических процессов обработки данных;
· системные и прикладные программисты:
· операторы и специалисты по техническому обслуживанию.
Если речь идет о коммерческом банке данных, то важную роль здесь играют специалисты по маркетингу.
Основные функции группы администратора БД1. Анализ предметной области: описание предметной области, выявление ограничений целостности, определение статуса (доступности, секретности) информации, определение потребностей пользователей, определение соответствия «данные - пользователь», определение объемно-временных характеристик обработки данных.
2. Проектирование структуры БД: определение состава и структуры файлов БД и связей между ними, выбор методов упорядочения данных и методов доступа к информации, описание БД на языке описания данных (ЯОД).
3. Задание ограничений целостности при описании структуры БД и процедур обработки БД:
- задание декларативных ограничений целостности, присущих предметной области;
- определение динамических ограничений целостности, присущих предметной области в процессе изменения информации, хранящейся в БД;
- определение ограничений целостности, вызванных структурой БД;
- разработка процедур обеспечения целостности БД при вводе и корректировке данных;
- определение ограничений целостности при параллельной работе пользователей в многопользовательском режиме.
4. Первоначальная загрузка и ведение БД:
- разработка технологии первоначальной загрузки БД, которая будет отличаться от процедуры модификации и дополнения данными при штатном использовании базы данных;
- разработка технологии проверки соответствия введенных данных реальному состоянию предметной области. База данных моделирует реальные объекты некоторой предметной области и взаимосвязи между ними, и на момент начала штатной эксплуатации эта модель должна полностью соответствовать состоянию объектов предметной области на данный момент времени;
- в соответствии с разработанной технологией первоначальной загрузки может понадобиться проектирование системы первоначального ввода данных.
5. Защита данных:
- определение системы паролей, принципов регистрации пользователей, создание групп пользователей, обладающих одинаковыми правами доступа к данным;
- разработка принципов защиты конкретных данных и объектов проектирования;
- разработка специализированных методов кодирования информации при ее циркуляции в локальной и глобальной информационных сетях;
- разработка средств фиксации доступа к данным и попыток нарушения системы зашиты;
- тестирование системы защиты;
- исследование случаев нарушения системы защиты и развитие динамических методов защиты информации в БД.
6. Обеспечение восстановления БД:
- разработка организационных средств архивирования и принципов восстановления БД;
- разработка дополнительных программных средств и технологических процессов восстановления БД после сбоев.
7. Анализ обращений пользователей БД: сбор статистики по характеру запросов, по времени их выполнения, по требуемым выходным документам
8. Анализ эффективности функционирования БД:
- анализ показателей функционирования БД;
- планирование реструктуризации (изменение структуры) БД и реорганизации БнД.
9. Работа с конечными пользователями:
- сбор информации об изменении предметной области;
- сбор информации об оценке работы БД;
- обучение пользователей, консультирование пользователей;
- разработка необходимой методической и учебной документации по работе конечных пользователей.
10. Подготовка и поддержание системных средств:
- анализ существующих на рынке программных средств и анализ возможности и необходимости их использования в рамках БД;
- разработка требуемых организационных и программно-технических мероприятий по развитию БД;
- проверка работоспособности закупаемых программных средств перед подключением их к БД;
- курирование подключения новых программных средств к БД.
11. Организационно-методическая работа по проектированию БД:
- выбор или создание методики проектирования БД;
- определение целей и направления развития системы в целом;
- планирование этапов развития БД;
- разработка общих словарей-справочников проекта БД и концептуальной модели;
- стыковка внешних моделей разрабатываемых приложений;
- курирование подключения нового приложения к действующей БД;
- обеспечение возможности комплексной отладки множества приложений, взаимодействующих с одной БД.
Архитектура базы данных. Физическая и логическая независимостьТерминология в СУБД, да и сами термины «база данных» и «банк данных» частично заимствованы из финансовой деятельности. Это заимствование — не случайно и объясняется тем, что работа с информацией и pa6oтa с денежными массами во многом схожи, поскольку и там и там отсутствует персонификация объекта обработки: две банкноты достоинством в сто рублей столь же неотличимы и взаимозаменяемы, как два одинаковых байта (естественно, за исключением серийных номеров). Вы можете положить деньги на некоторый счет и предоставить возможность вашим родственникам или коллегам использовать их для иных целей. Вы можете поручить банку оплачивать ваши расходы с вашего счета или получить их наличными о другом банке, и это будут уже другие денежные купюры, но их ценность будет эквивалентна той, которую вы имели, когда клали их на ваш счет.
В процессе научных исследований, посвященных тому, как именно должна быть устроена СУБД, предлагались различные способы реализации. Самым жизнеспособным из них оказалась предложенная американским комитетом по стандартизации ANSI (American National Standards Institute) трехуровневая система организации БД, изображенная на рис. 2.1:
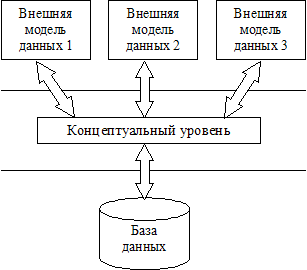
Рис. 2.1. Трехуровневая модель системы управления базой данных, предложенная ANSI
1. Уровень внешних моделей — самый верхний уровень, где каждая модель имеет свое «видение» данных. Этот уровень определяет точку зрения на БД отдельных приложений. Каждое приложение видит и обрабатывает только те данные, которые необходимы именно этому приложению. Например, система распределения работ использует сведения о квалификации сотрудника, но ее не интересуют сведения об окладе, домашнем адресе и телефоне сотрудника, и наоборот, именно эти сведения используются в подсистеме отдела кадров.
2. Концептуальный уровень — центральное управляющее звено, здесь база данных представлена в наиболее общем виде, который объединяет данные, используемые всеми приложениями, работающими с данной базой данных. Фактически концептуальный уровень отражает обобщенную модель предметной области (объектов реального мира), для которой создавалась база данных. Как любая модель, концептуальная модель отражает только существенные, с точки зрения обработки, особенности объектов реального мира.
Похожие работы

... подчеркнуть их существенное отличие от БД, используемых для реализации ХД. Средства анализа. Приложения для конечного пользователя, включая средства принятия решений, средства OLAP и другие специализированные средства анализа, прогноза и представления данных. 3 Базы и хранилища данных Ни для кого не секрет, что одним из основных факторов успеха в бизнесе и управлении является скорость и ...
... на модели данных, реализованные в различных СУБД. Наибольшую популярность получили CASE-системы для реляционных СУБД с SQL-моделями данных, а DD/D переименовался в CASE-репозиторий проектируемой ИС. На этом пути возникло два основных направления развития CASE-систем и технологий проектирования: CASE-системы для проектирования собственно БД (или т. н. Upper-CASE) и интегрированные инструменты, ...
... хранилищ данных. Но, несмотря на то что хранилища обладают общими свойствами, разные типы хранилищ имеют свои индивидуальные особенности. 3. Технологии управления информацией Для работы с хранилищем данных используются СУБД, к которым предъявляются специальные требования. Поскольку в ходе обсуждения проблем хранилищ данных эти требования либо уже обсуждались, либо присутствие их в перечне и ...
... кварталов... повернуть направо...". (Аналогично больший или меньший уровень детализации запроса приходится создавать пользователю в разных СУБД, не имеющих языка SQL.) Появление теории реляционных баз данных и предложенного Коддом языка запросов "alpha", основанного на реляционном исчислении [2, 3], инициировало разработку ряда языков запросов, которые можно отнести к двум классам: 1. ...
0 комментариев