Обозначение "SL-Enhanced" y пpоцессоpов Intel 486
Первые процессоры фирмы Intel
Процессор 80486
Работа с Microsoft Word for Windows 6.1 в среде
Windows
Процессор Pentium Pro
Значения тестов для некоторых чипов фирмы Intel
Процессоры семейства AMD5k86
Материнские платы для AMD5k86
Процессоры Cyrix
Процессоры Mips
Процессоры Motorola
МГц Intel
C&T Intel Cyrix Cyrix
Сравнительный анализ
Навигация
Процессоры Mips
Микропроцессоры для пользователей
112838
знаков
3
таблицы
0
изображений
4.7. Процессоры Mips.
Mips процессор R1000 унаследовал свой суперскалярный дизайн от R8000, который предназначался для рынка суперкомпьютеров научного назначения. Hо R1000 ориентирован на массовые задачи. Использование в R1000 динамического планирования команд, которое ослабляет зависимость от перекомпиляции ПО, написанного для более старых процессоров, стало возможным благодаря тесным связям Mips со своим партнером Silicon Graphics, имеющим богатейший тыл в виде сложных графических приложений.
R1000 первый однокристалльный процессор от Mips. Для предотвращения остановок конвейера в нем использовано динамическое предсказание переходов, с четырьмя уровнями условного исполнения, с использованием переименования регистров, гаранитирующего что результаты не будут передаваться в реальные регистры до тех пор, пока неясность по команде перехода не будет снята. Процессор поддерживает "теневую карту" отображения своих регистров переименования. В случае неверного предсказания адреса перехода он просто восстанавливает эту карту отображения, но не выполняет фактической очистки регистров и "промывки" буферов, экономя таким образом один такт.
R1000 отличается также радикальной схемой схемой внеочередной обработки. Порядок следования команд в точном соответствии с программой сохраняется на трех первых ступенях конвейера, но затем поток разветвляется на три очереди (где команды дожидаются обработки на целочисленном АЛУ, блоке вычислений с плавающей точкой и блоке загрузки/записи). Эти очереди уже обслуживаются по мере освобождения того или иного ресурса.
Предполагаемая производительность R1000, выполненного по КМОП-технологии с нормами 0.35 микрон должна достичь 300 по SPECint92 и по SPECfp92.
Программный порядок в конце концов восстанавливается так, что самая "старая" команда покидает обработку первой. Аппаратная поддержка исполнения в стиле out-of-order дает большие преимущества конечному пользователю, так как коды, написанные под старые скалярные процессоры Mips (например, R4000), начинают работать на полной скорости и не требуют перекомпиляции. Хотя потенциально процессор R1000 способен выдавать по пять команд на исполнение в каждом такте, он выбирает и возвращает только четыре, не успевая закончить пятую в том же такте.
Одно из двух устройств для вычисления двойной точности с плавающей точкой занято сложениями, а другое умножениями/делениями и извлечением квадратного корня. Hа кристалле R1000 реализован также интерфейс внешней шины, позволяющий связывать в кластер до четырех процессоров без дополнительной логики обрамления.
4.8. Процессоры Hewlett-Packard.
Hewlett-Packard процессор PA-8000. Компания Hewlett-Packard одной из первых освоила RISC-технологию, выйдя еще в 1986 году со своим первым 32-разрядным процессором PA-RISC. Практически все выпускаемые процессоры PA-RISC используются в рабочих станциях HP серии 9000. В период с 1991 по 1993 (перед появлением систем на базе PowerPC) HP отгрузила достаточно много таких машин, став крупнейшим продавцом RISC-чипов в долларовом выражении.
С целью пропаганды своих микропроцессоров среди других производителей систем компания HP стала организатором организации Precision RISC Organization (PRO). А в 1994 году компания взорвала бомбу, объединившись с Intel для создания новой архитектуры. Это поставило под сомнение будущее PRO.
PA-8000 это 64-разрядный, четырехканальный суперскалярный процессор с радикальной схемой неупорядоченного исполнения программ. В составе кристалла десять функциональных блоков, включая два целочисленных АЛУ, два блока для сдвига целых чисел, два блока multiply/accumulate (MAC) для чисел с плавающей запятой, два блока деления/извлечения квадратного корня для чисел с плавающей запятой и два блока загрузки/записи. Блоки МАС имеют трехтактовую задержку и при полной загрузке конвейера на обработке одинарной точности обеспечивают производительность 4 FLOPS за такт. Блоки деления дают 17-тактовую задержку и не конвейеризированы, но они могут работать одновременно с блоками МАС.
В PA-8000 использован буфер переупорядочивания команд (IRB) глубиной 56 команд, позволяющий "просматривать"программу на следующие 56 команд вперед в поисках таких четырех команд, которые можно выполнить параллельно. IRB фактически состоит из двух 28-слотовых буферов. Буфер АЛУ содержит команды для целочисленного блока и блока плавающей точки, а буфер памяти - команды загрузки/записи.
Как только команда попадает в слот IRB, аппаратура просматривает все команды, отправленные на функциональные блоки, чтобы найти среди них такую, которая является источником операндов для команды, находящейся в слоте. Команда в слоте запускается только после того, как будет распределена на исполнение последняя команда, которая сдерживала ее. Каждый из буферов IRB может выдавать по две команды в каждом такте, и в любом случае выдается самая "старая" команда в буфере. Поскольку PA-8000 использует переименование регистров и возвращает результаты выполнения команд из IRB в порядке их следования по программе, тем самым поддерживается точная модель обработки исключительных ситуаций.
HP проектировала РА-8000 специально для задач коммерческой обработки данных и сложных вычислений, типа генной инженерии, в которых объем данных настолько велик, что они не умещаются ни в один из мыслимых внутрикристалльных кэшей. Вот почему, РА-8000 полагается на внешние первичные кэши команд и данных. Слоты в третьем 28-слотовом буфере, который называется буфером переупорядочивания адресов (Adress-Recorder Buffer - ARB), один к одному ассоциированы со слотами в буфере памяти IRB. В АРВ содержатся виртуальные и физические адреса всех выданных команд загрузки/записи. Кроме того, АРВ допускает выполнение загрузок и записей в произвольном порядке, но с сохранением согласованности и сглаживанием влияния задержки, связанной с адресацией внешних кэшей.
Похожие работы
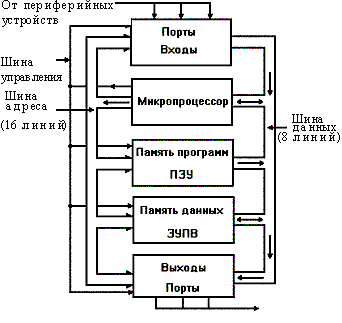
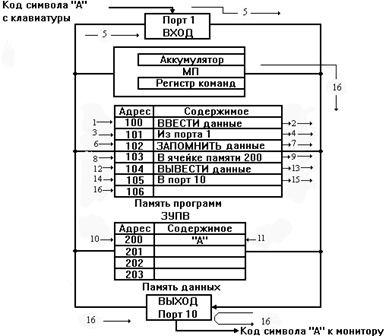

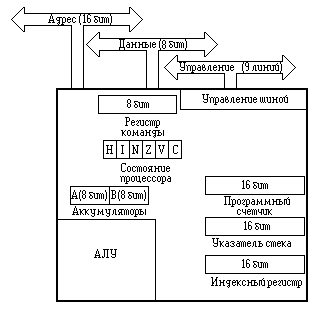
... микропроцессора, которые явно отражаются в программах и должны быть учтены при разработке схем и программ функционирования системы. Такие характеристики определяются понятием архитектуры микропроцессора. 1.2 Понятие архитектуры микропроцессора Архитектура типичной небольшой вычислительной системы на основе микроЭВМ показана на рис. 1. Такая микроЭВМ содержит все 5 основных блоков цифровой ...
... ) ФАКУЛЬТЕТ ЭЛЕКТРОНИКИ И ПРИБОРОСТРОЕНИЯ КАФЕДРА КЭС группа Э-92 ДАТА ЗАЩИТЫ апреля 1997 г. Отзыв на дипломную работу студента гр.Э-92 Сорокина Ю.В. “Разработка программы контроллера автоматически связываемых объектов для управления конструкторской документацией в среде Windows 95/NT”. Широкое использование вычислительной техники в народном хозяйстве требует увеличения производства и ...
... . Некоторые характеристики транспьютеров фирмы INMOS : разрядность - 32, скорость обработки данных - 40 Мбайт/с, адресуемое пространство - 4 Гбайт. Общий обзор структур,характеристик и архитектур 32-разрядных микропроцессоров. Cтруктуры различных типов МП могут существенно различаться, однако с точки зрения пользователя наиболее важными параметрами являются архитектура, адресное пространство ...
... системы. Тем самым появилась возможность объединения высокой производительности микропроцессора с внутренней тактовой частотой 50(66) МГц и эффективной по стоимости 25/33-мегагерцовой системной платой. Новые микропроцессоры по прежнему включали в себя центральный процессор, математический сопроцессор и кэш-память на 8 Кбайт. Компьютеры, поставляемые на базе микропроцессоров i486DX2, работают ...
0 комментариев