Навигация
2.5. Описание алгоритма
Идеи, высказанные в разделе 2.4, могут быть использованы для создания очень небольшого и сжатого алгоритма вычисления обратного логарифма функции правдоподобия, его градиента и величин, входящих в выражение для информационной матрицы Фишера.
Пусть ![]() определяет
собой вектор
параметров,
по которым
функция правдоподобия
должна быть
продифференцирована.
Для вычисления
определяет
собой вектор
параметров,
по которым
функция правдоподобия
должна быть
продифференцирована.
Для вычисления
 ,
для каждого
i, мы преобразуем
уравнение
изменения
параметров
наблюдающей
модели следующим
образом:
,
для каждого
i, мы преобразуем
уравнение
изменения
параметров
наблюдающей
модели следующим
образом:
М1: Заменим (2.1.10) на
 ,
,
где первые два
столбца повторяются
для каждого
![]() .
.
М2: Вычислить
для каждого
![]() :
:
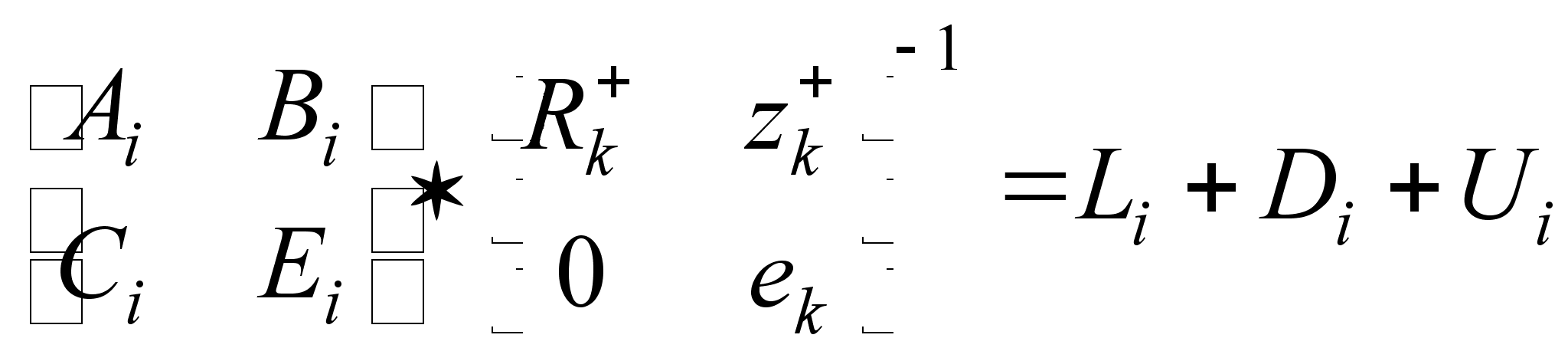
М3: Вычислить
для каждого
![]() :
:
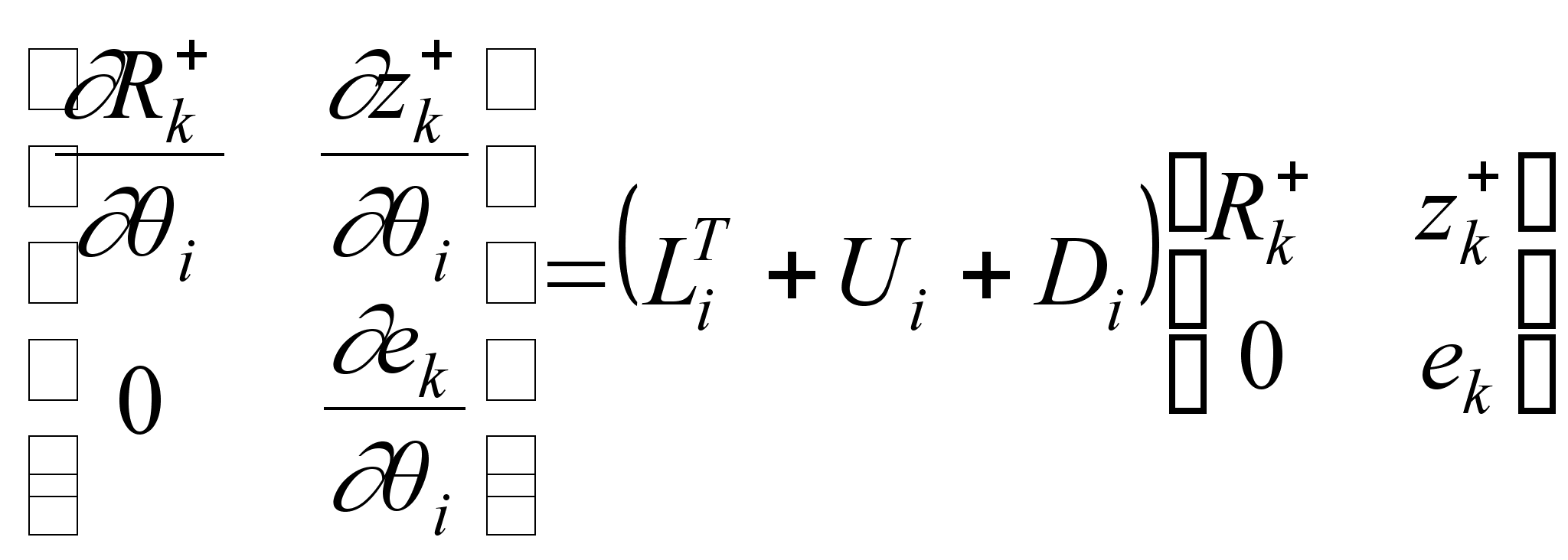
Заметим, что на шаге М2, матрица, которая должна быть обращена верхнетреугольная. Следовательно, результат обращения может быть получен с помощью метода обратной подстановки.
Метод раздела
2.4, для нахождения
величин
 ,
мы не можем
применить
напрямую к
уравнению
предсказания
состояния
(2.1.13), т.к. матрица,
которая должна
быть приведена
к треугольному
виду неквадратная,
следовательно,
необратимая.
Однако этот
алгоритм может
быть применен
при работе с
подматрицами.
,
мы не можем
применить
напрямую к
уравнению
предсказания
состояния
(2.1.13), т.к. матрица,
которая должна
быть приведена
к треугольному
виду неквадратная,
следовательно,
необратимая.
Однако этот
алгоритм может
быть применен
при работе с
подматрицами.
Т1: Заменим (2.1.13) следующим соотношением:

где первые два
столбца повторяются
для каждого
![]() и
и ![]() ,
как в (2.1.13)
,
как в (2.1.13)
Т2: Вычислить
для каждого
![]() :
:
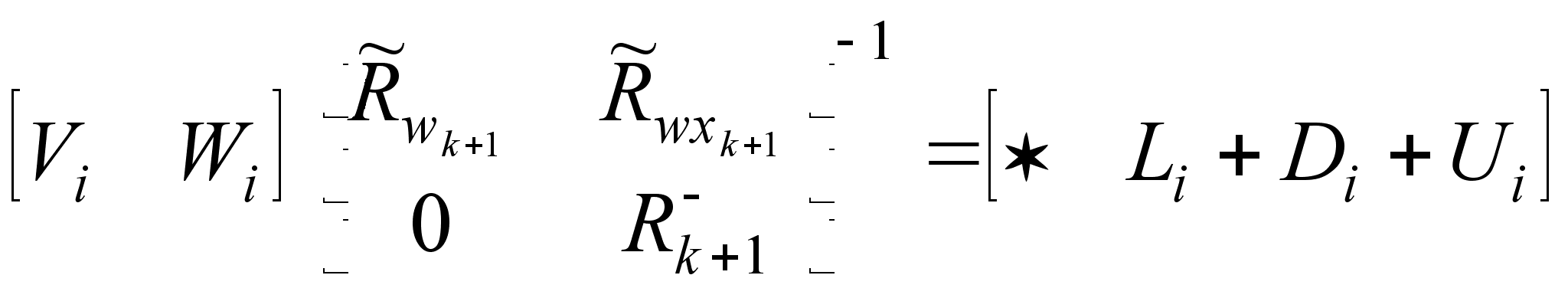
здесь * - обозначение для первых q столбцов, не представляющих для нас интереса.
Т3: Вычислить
для каждого
![]() :
:


Соотношение
для ![]() определяется
дифференцированием
уравнения:
определяется
дифференцированием
уравнения:
![]()

и заменой производной
![]() ,
используя
(2.4.4), значением
вычисленным
на шаге Т1. Заметим
также, что
,
используя
(2.4.4), значением
вычисленным
на шаге Т1. Заметим
также, что ![]() ,
необходимое
для этого последнего
уравнения,
легко вычисляется,
т.к.
,
необходимое
для этого последнего
уравнения,
легко вычисляется,
т.к.
![]()
где ![]() - верхнетреугольная.
- верхнетреугольная.
Но самое интересное,
что значения
![]() ,
необходимые
для вычисления
матрицы Фишера,
вычисляются
автоматически
на шаге М3.
,
необходимые
для вычисления
матрицы Фишера,
вычисляются
автоматически
на шаге М3.
25
3. Эксперименты
Факт сходимости алгоритма максимального правдоподобия к оптимальным значениям параметров теоретически является недоказанным, поэтому в качестве основного метода исследования будем считать вычислительные эксперименты.
Модель, используемая в экспериментах, имеет следующий вид:
![]()
![]() ,
,
где матрица перехода из состояния в состояние
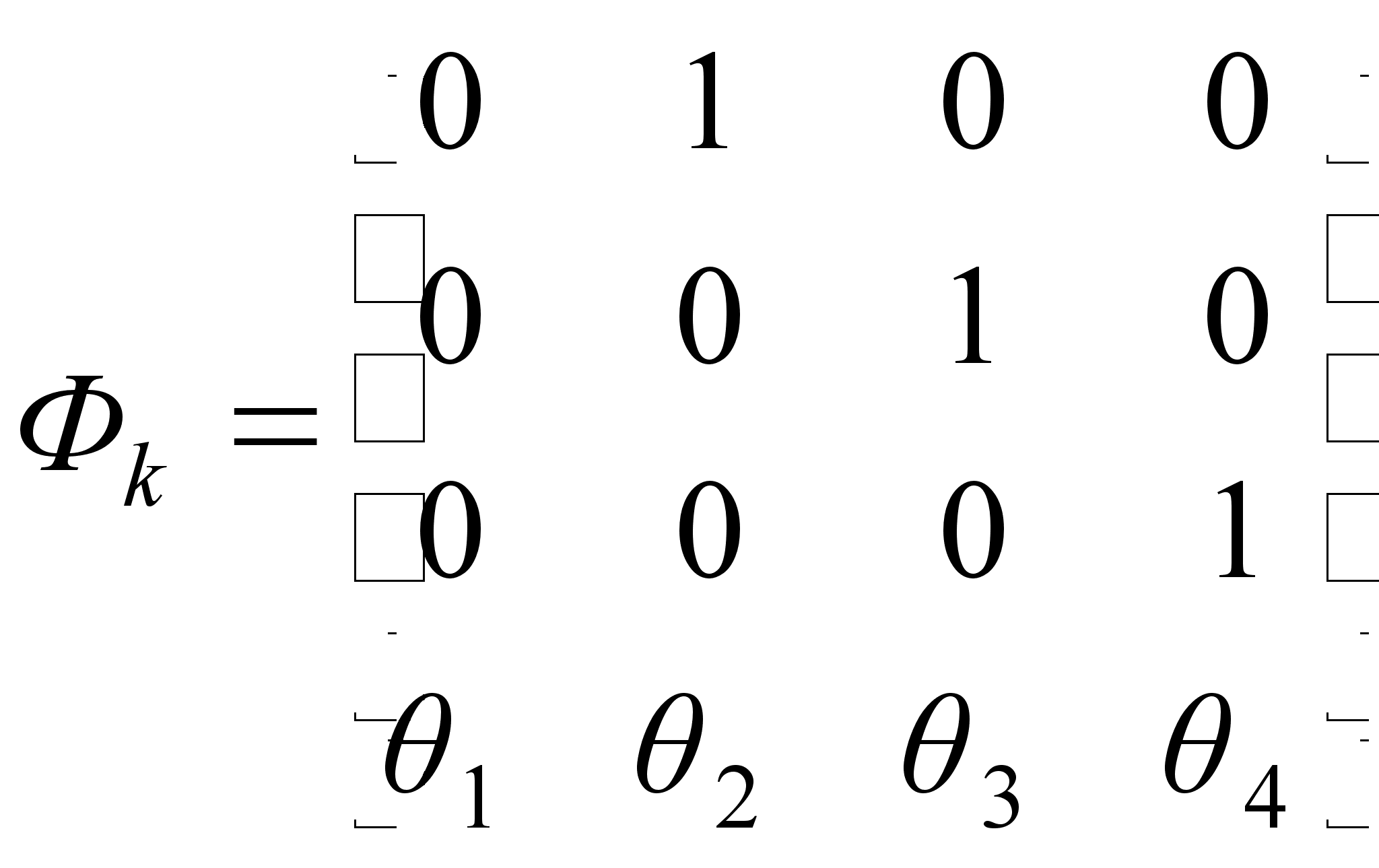 ,
,
оцениваемые
параметры ![]() имеют следующие
истинные значения
имеют следующие
истинные значения
![]()
![]() ,
,
матрица наблюдений
![]() ,
,
![]() и
и ![]() – случайные
процессы,
представляющие
собой белый
гауссовый шум
с характеристиками
– случайные
процессы,
представляющие
собой белый
гауссовый шум
с характеристиками
![]() ,
,
![]() ,
,
начальная точка

Сходимость метода
Проведем эксперименты
на сходимость
метода максимального
правдоподобия
с использованием
ККИФ, используя
различные
алгоритмы
минимизации,
представленные
в разделе 1.3. При
этом будем
варьировать
количество
и расположение
оцениваемых
параметров
в матрице перехода
из состояния
в состояние
![]() ,
которая является
устойчивой,
а модель –
наблюдаемой
(вообще, наблюдаемость
является необходимым
условием
идентифицируемости
параметров
системы).
,
которая является
устойчивой,
а модель –
наблюдаемой
(вообще, наблюдаемость
является необходимым
условием
идентифицируемости
параметров
системы).
Неизвестен один параметр ![]() .
.
н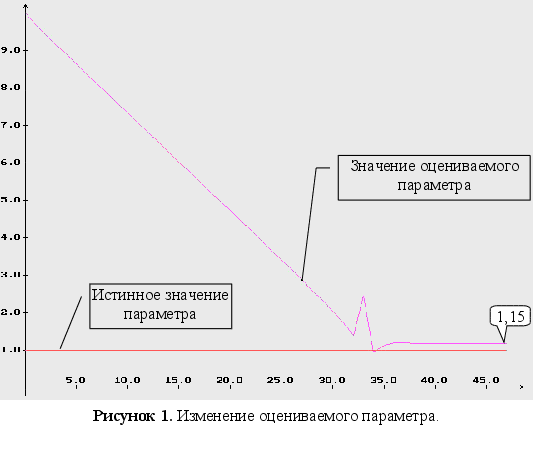
ачальные
условия для
оцениваемого
параметра : ![]()
градиентный метод
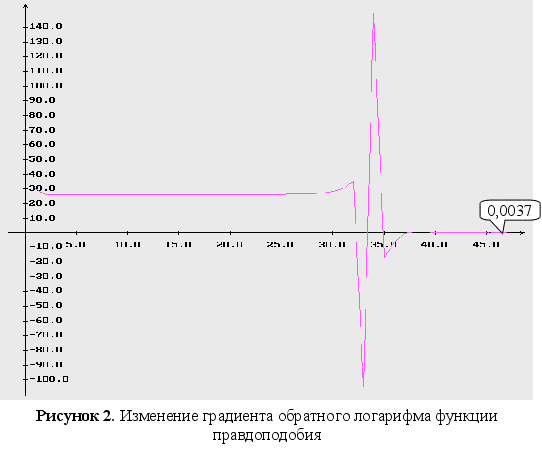

м

етод Ньютона
м
етод сопряженных направлений



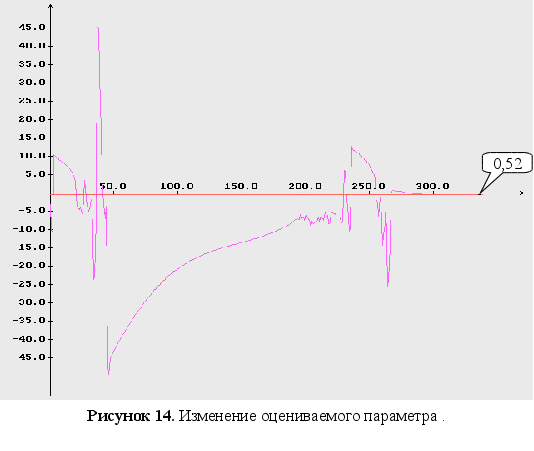
Неизвестны два параметра ![]() .
.
н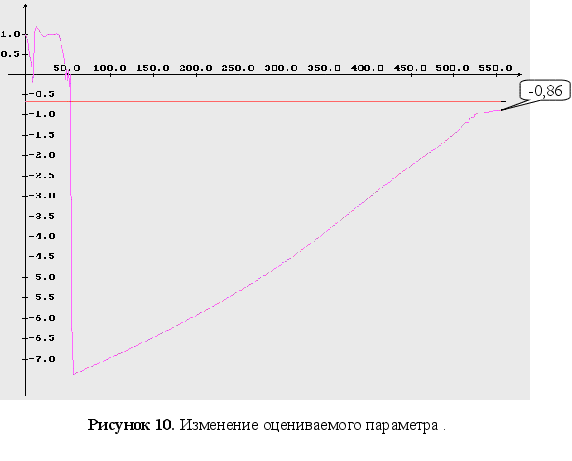
ачальные
условия для
оцениваемого
параметра : ![]()
г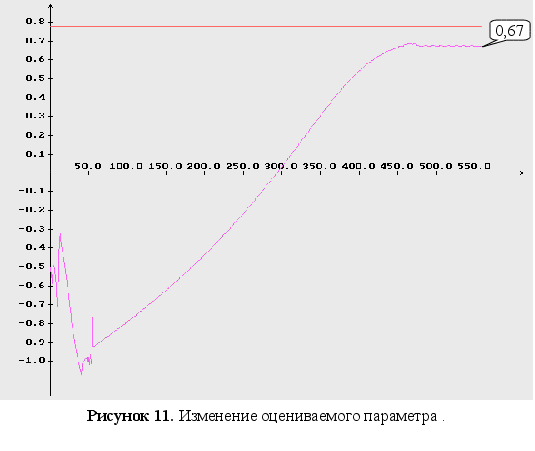
радиентный метод


метод Ньютона


метод сопряженных направлений
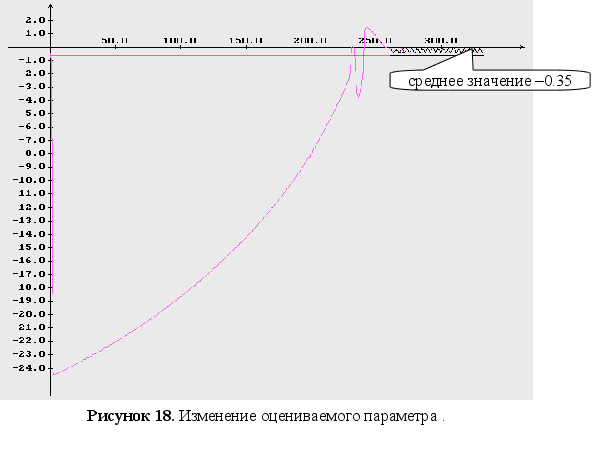
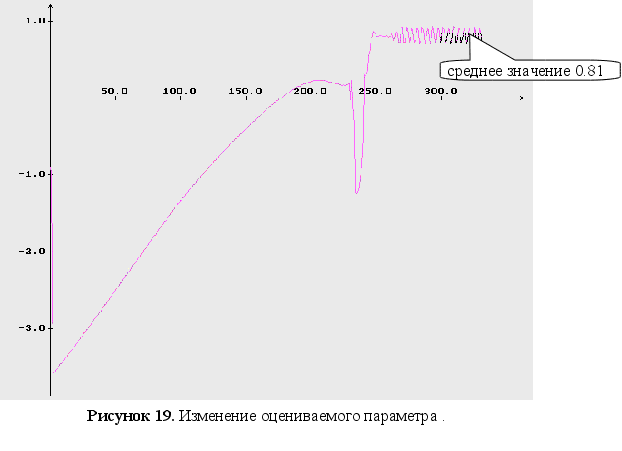
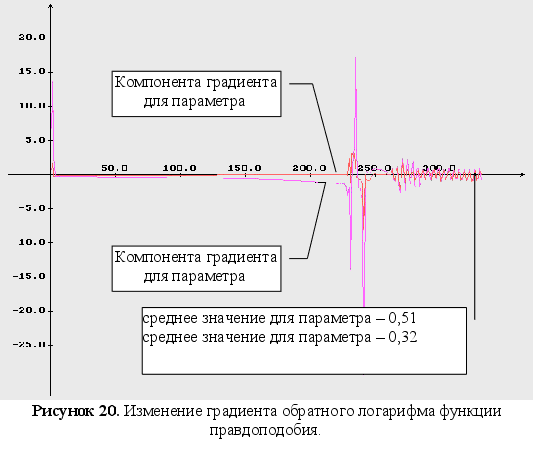
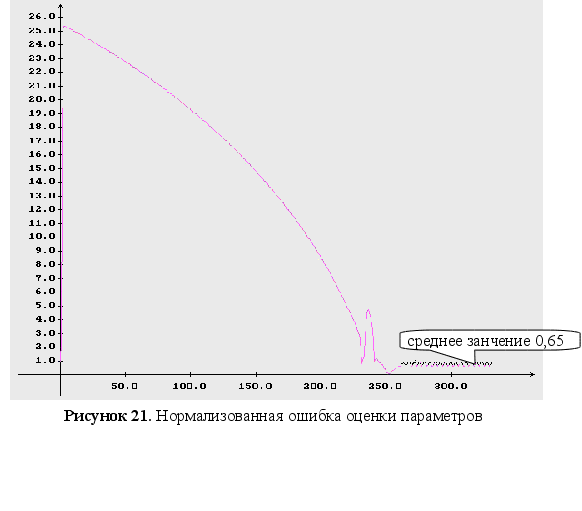
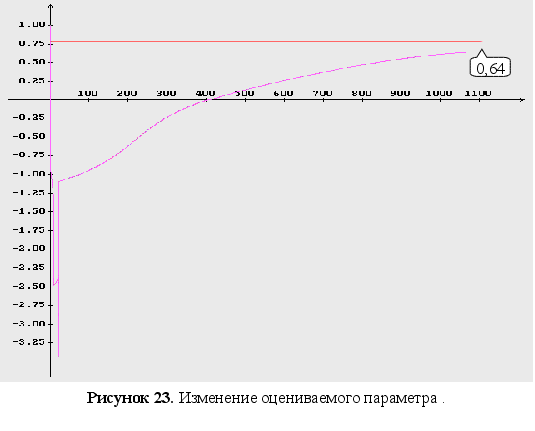
Неизвестны три параметра ![]() .
.
начальные
условия для
оцениваемого
параметра : ![]()
г
радиентный метод



м
етод Ньютона

![]()


метод сопряженных направлений

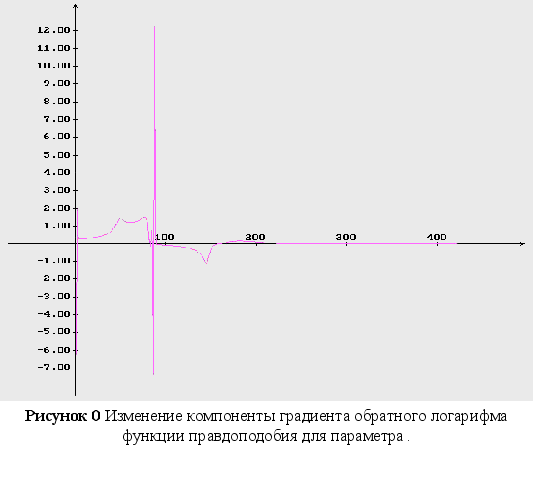
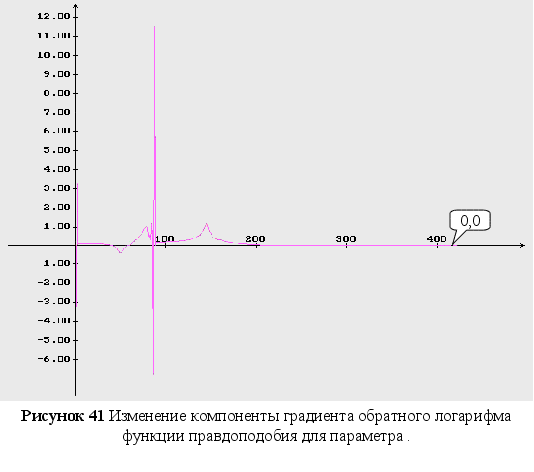
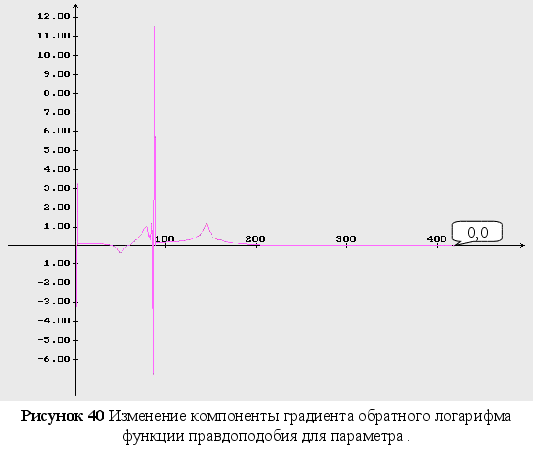
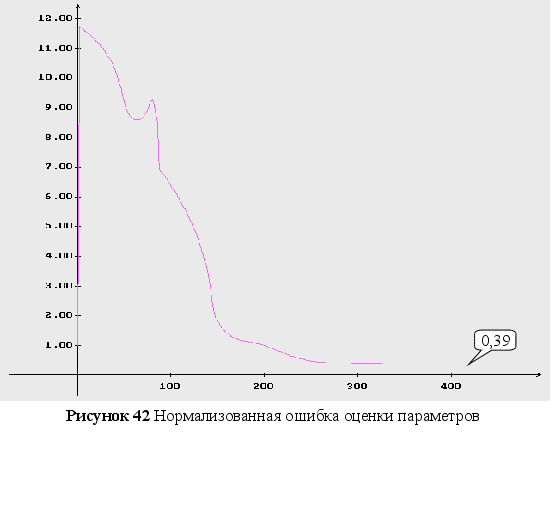
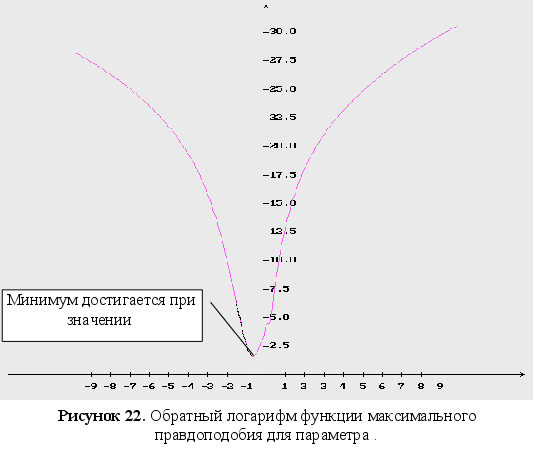
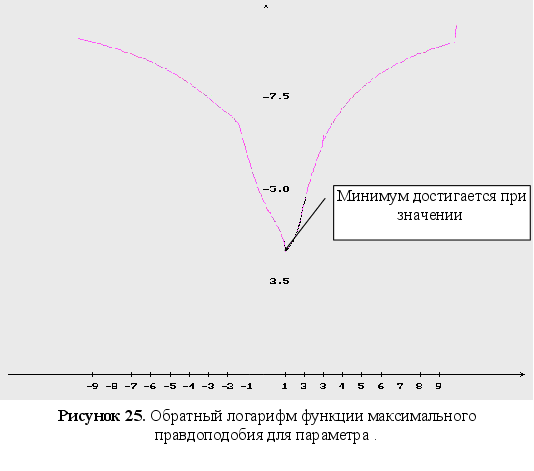
Обратный логарифм функции максимального правдоподобия
В данном разделе будут представлены графики обратного логарифма функции максимального правдоподобия для оцениваемых параметров, при условии того, что другие параметры имеют свои истинные значения.


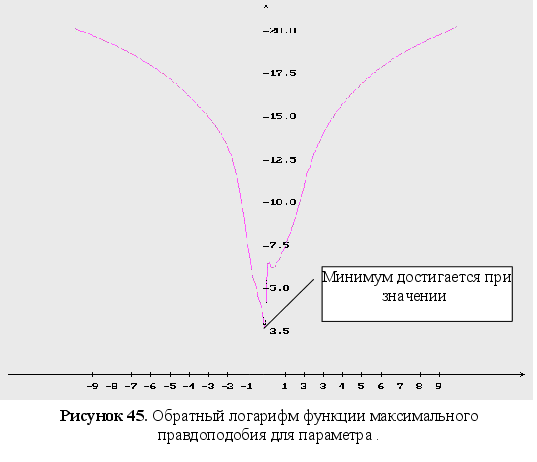
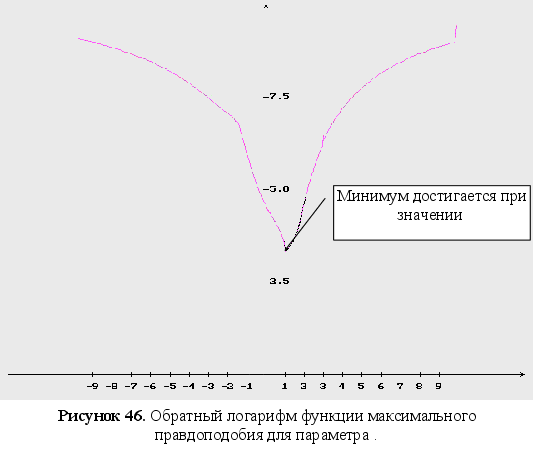
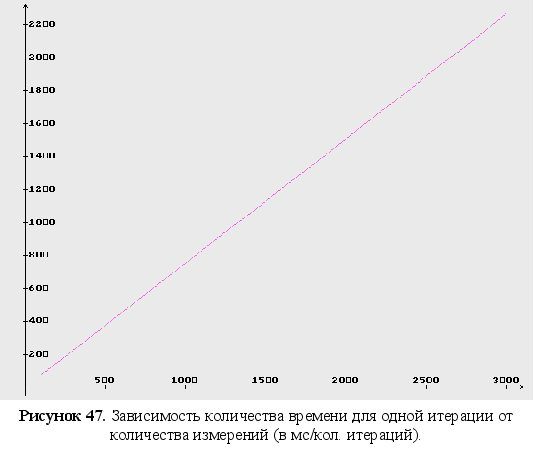
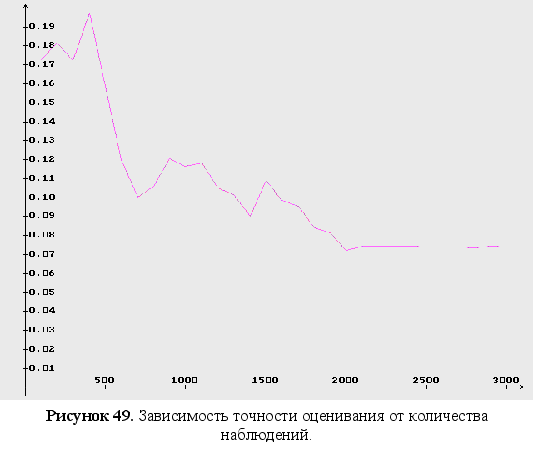
Представление других зависимостей


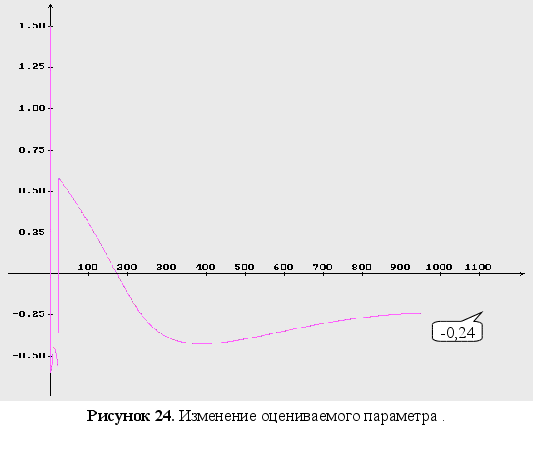
Выводы
После проведения серии вычислительных экспериментов были получены следующие результаты:
Как видно из графиков (Рис. 43-44), минимум обратного логарифма функции максимального правдоподобия по параметрам является не единственным, и как следствие этого возникают ситуации, когда методы минимизации сходятся не к истинному значению оцениваемых параметров. Так же стоит заметить, что график функционала, при больших отклонениях от истинных значениях параметров, идет практически параллельно горизонтальной оси координат. Из выше сказанного можно сделать вывод, что выбор начального приближения для параметров может оказать существенное влияние как на сходимость алгоритмов, так и на истинность полученных оценок.
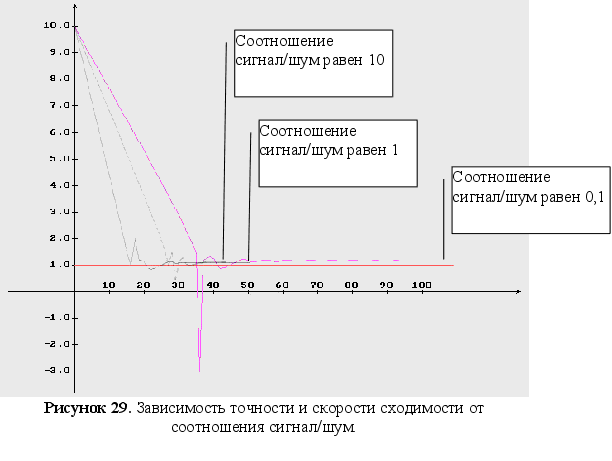
На оценки параметров особенно сильное влияние оказывает наблюдаемость динамической системы объекта (наблюдаемость динамической системы является необходимым условием сходимости методов параметрической идентификации), а также соотношение сигнал/шум (с ростом соотношения точность оценок увеличивается).
Из исследованных алгоритмов наилучшей сходимостью обладает метод сопряженных направлений, а более точным является метод Ньютона, при этом он тоже обладает достаточно хорошей сходимостью. Поэтому предпочтительней использовать метод Ньютона, т.к. при использовании ККИФ матрица вторых производных функционала (в нашем случае это информационная матрица Фишера) вычисляется естественным путем из выходных данных.
Установлено, что в общем случае скорость сходимости с ростом размерности вектора параметров и количества наблюдений сильно падает, однако с увеличением количества входных данных растет точность оценок параметров. Но рост точности приостанавливается при количестве наблюдений более 2500. Поэтому следует искать компромисс между скоростью и точностью.
Метод является достаточно сложным в вычислительном отношении, поскольку метод максимального правдоподобия с использованием ККИФ требует больших объемов вычислений: для перемножения, обращения, ортогональных преобразований матриц.
Заключение
В данном дипломном проекте была проведена следующая работа:
Теоретически проанализирован алгоритм параметрической идентификации основанный на методе максимального правдоподобия с использованием квадратно-корневых информационных фильтров с различными методами минимизации функционала качества.
Данный алгоритм и методы минимизации программно реализованы на ЭВМ.
Поставлены эксперименты на выявление основных преимуществ и недостатков выше описанного метода.
Поставлены эксперименты на выявление наилучшего методами минимизации функционала качества при использовании алгоритма идентификации.
Получены результаты поставленных экспериментов и на их основе сделаны выводы.
Список используемой литературы
Эйкхофф П. ”Основы идентификации систем управления. Оценивание параметров и состояния” М.”Мир”, 1975
Bierman G.J. ”Factorization methods for discrete sequential estimation.” N.-Y. Acad.Press, 1977
Bierman G.J., Belzer M.R., Vandergraft J.S., Porter D.W. ”Maximum likelihood estimation using square root information filters” IEEE Transactions on automatic control, Vol. 35, No. 12, December 1990, p. 1293-1298
Дж. Саридис ”Самоорганизующиеся стохастические системы управления” М. ”Наука”, 1980
Дж. Медич ”Статистические оптимальные линейные оценки и управление”
Валисьев Ф.П. ”Численные методы решения экстремальных задач” М. ”Наука”, 1988
53
Доклад
Задача идентификации формулируется следующим образом: по результатам наблюдений над входными и выходными переменными системы должна быть построена оптимальная в некотором смысле модель, т.е. формализованное представление этой системы.
В зависимости от априорной информации об объекте управления различают задачи идентификации в узком и широком смысле. Задача идентификации в узком смысле состоит в оценивании параметров и состояния системы по результатам наблюдений над входными и выходными переменными, полученными в условиях функционирования объекта. При этом известна структура системы и задан класс моделей, к которому данный объект относится. Априорная информация об объекте достаточно велика.
Априорная информация об объекте при идентификации в широком смысле отсутствует или очень бедная, поэтому приходится предварительно решать большое число дополнительных задач, такие как выбор структуры системы и задание класса моделей, оценивание линейности объекта и действующих переменных, оценивание степени и формы влияния входных переменных на выходные и др.
Целью данной дипломной работы является исследование нового метода параметрической идентификации основанного на синтезе метода максимального правдоподобия и метода квадратно-корневого информационного фильтра, а также сравнение методов минимизации, использованных для минимизации выбранного функционала, с точки зрения сходимости, вычислительной точности, сложности, а также реализация данного метода на ЭВМ.
Описание диплома
Задача оценивания
может быть
сформулирована
как задача
нахождения
наибольшего
(наименьшего)
значения некоторого
функционала.
Но т.к. значения
параметров
непосредственному
наблюдению
не доступны,
то критерием
выбора оптимума
должен быть
функционал
от выходных
значений.
Примером такого функционала
может служить
либо функция
правдоподобия,
либо ее логарифм.
Т.е. если ![]() -
это выход объекта,
-
это выход объекта,
![]() -соответствующий
выход модели
и, также когда,
невязки ошибок
предсказания
-соответствующий
выход модели
и, также когда,
невязки ошибок
предсказания
![]() являются независимыми
и имеют гауссовское
совместное
распределение
с нулевым средним
и матрицами
ковариаций
являются независимыми
и имеют гауссовское
совместное
распределение
с нулевым средним
и матрицами
ковариаций
![]() ,
тогда выражение
для обратного
логарифма
функции максимального
правдоподобия
имеет следующий
вид:
,
тогда выражение
для обратного
логарифма
функции максимального
правдоподобия
имеет следующий
вид:
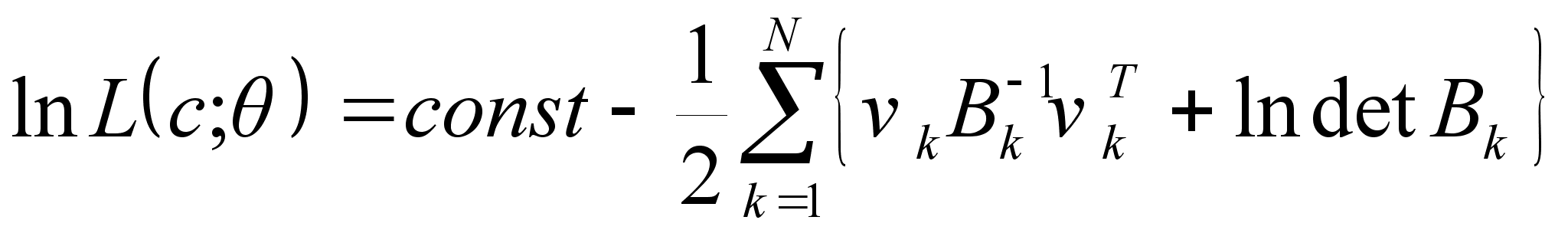 (1)
(1)
Тогда критерием выбора оптимума выберем выражение (2), которая является функцией многих переменных и для ее минимизации будем использовать наиболее известные и часто применяемые методы минимизации функций многих переменных: градиентный метод, метод Ньютона, метод сопряженных направлений.
Оценкой максимального
правдоподобия
является такое
значение оцениваемых
параметров
![]() ,
которое максимизирует
вероятность
события, при
котором наблюдения,
сгенерированные
с подстановкой
оцениваемых
параметров,
совпадают с
действительными
значениями
наблюдений
,
которое максимизирует
вероятность
события, при
котором наблюдения,
сгенерированные
с подстановкой
оцениваемых
параметров,
совпадают с
действительными
значениями
наблюдений
![]() .
Эта процедура
эквивалентна
минимизации
обратного
логарифма
функции плотности
условной вероятности
невязок, представленный
в формуле (2).
.
Эта процедура
эквивалентна
минимизации
обратного
логарифма
функции плотности
условной вероятности
невязок, представленный
в формуле (2).
Вычисление оценки максимального правдоподобия может быть итеративно выполнено при помощи характеристического уравнения, которое включает в себя градиент обратного логарифма функции правдоподобия и информационную матрицу Фишера, если используется метод Ньютона для минимизации функционала. Вычисления функции правдоподобия и информационной матрицы Фишера требуют применения фильтра Калмана (а также его производных для каждого параметра оценивания), который, как известно, не обладает достаточной устойчивостью. Поэтому для вычисления оценки максимального правдоподобия итеративным образом использовался ККИФ, т.к. данный метод позволяет избежать численной неустойчивости, являющейся результатом вычислительных погрешностей, поскольку вместо матриц ковариаций ошибки оценок на этапах экстраполяции и обработки измерений, по своей природе положительно определенных, ККИФ оперирует с их квадратными корнями. А это значит, что вычисления квадратного корня равносильно счету с двойной точностью для ковариации ошибок и, кроме того, устраняется опасность утраты матрицей ковариаций свойства положительно определенности. Недостатком данного метода является присутствие операций извлечения квадратного корня.
Для
эффективного
вычисления
оценки максимального
правдоподобия
при использовании
ККИФ, величины,
входящие в
выражение для
![]() (2)
и его градиента,
непосредственно
выражаются
либо через
выходные значения
КИИФ, либо легко
находятся путем
решения треугольных
систем.
(2)
и его градиента,
непосредственно
выражаются
либо через
выходные значения
КИИФ, либо легко
находятся путем
решения треугольных
систем.
Эксперименты
Факт сходимости алгоритма максимального правдоподобия к оптимальным значениям параметров теоретически является недоказанным, поэтому в качестве основного метода исследования будем считать вычислительные эксперименты.
Стоит заметить, что метод является достаточно сложным в вычислительном отношении, поскольку метод максимального правдоподобия с использованием ККИФ требует больших объемов вычислений: для перемножения, обращения, ортогональных преобразований матриц и поэтому для проведения экспериментов данный метод был реализован на ЭВМ.
Модель, используемая в экспериментах, представленных на графиках, имеет следующий вид:……
В
данной дипломной
работе проведены
эксперименты
на сходимость
метода максимального
правдоподобия,
используя
различные
алгоритмы
минимизации.
При этом варьировалось
количество
и расположение
оцениваемых
параметров
в матрице перехода
из состояния
в состояние
![]() ,
которая, в данной
случае, является
устойчивой,
а модель –
наблюдаемой
(на рисунках
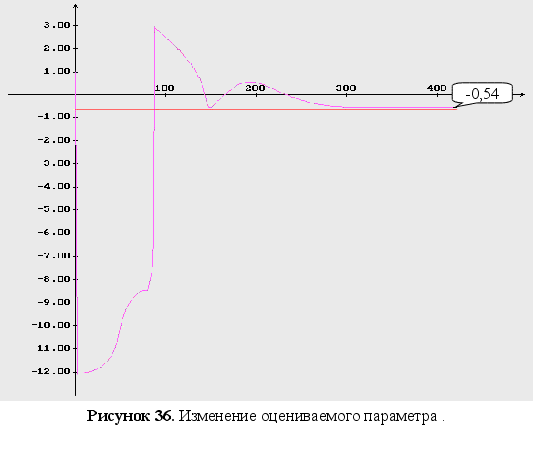
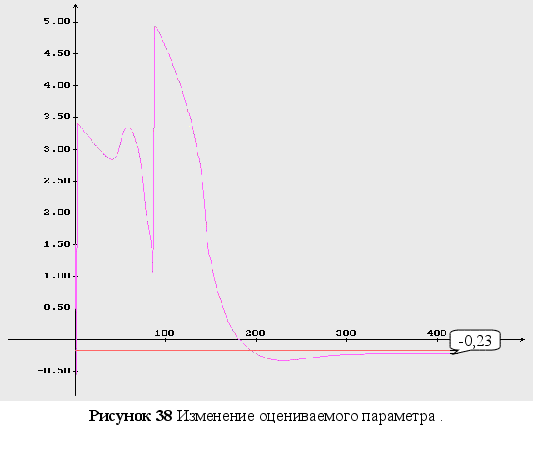
1-3 представлены
изменения
оцениваемых
параметров,
используя при
минимизации
функционала
градиентный
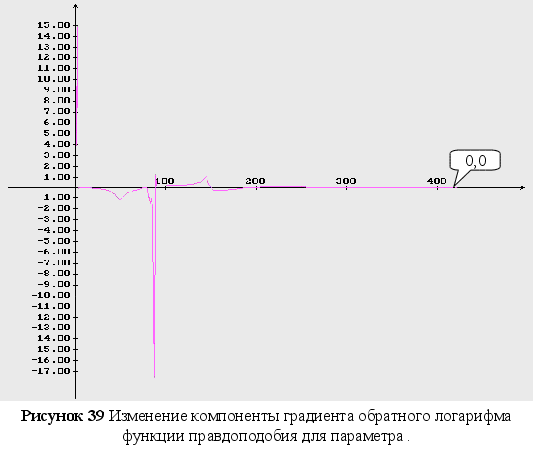
метод; на рисунках
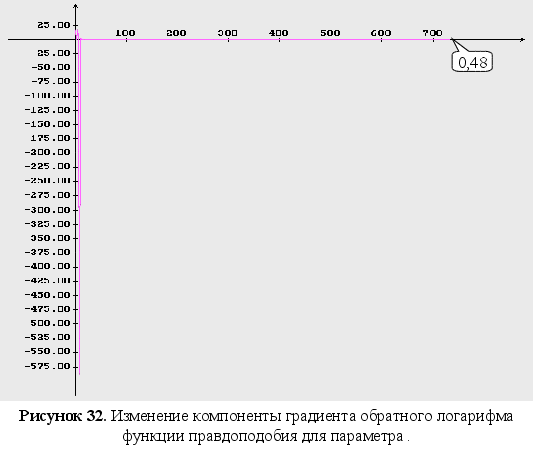
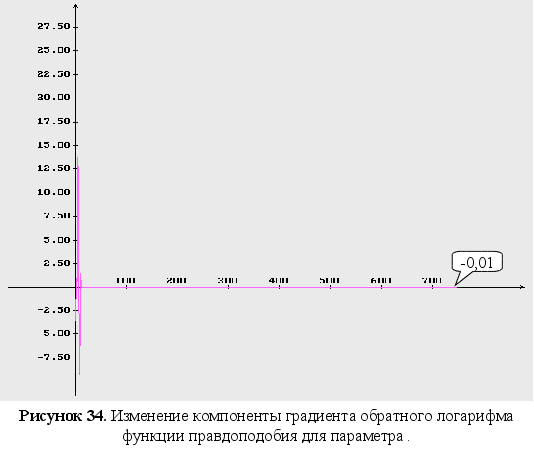
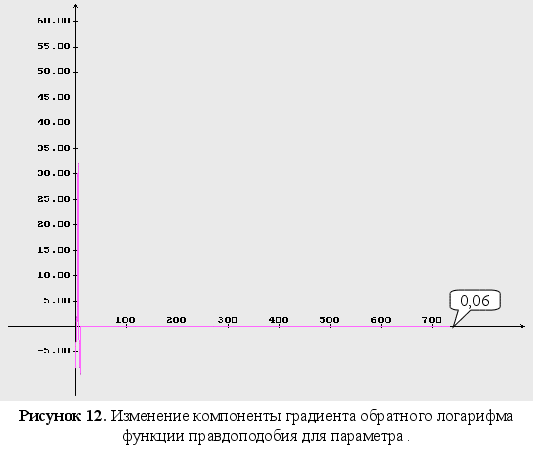
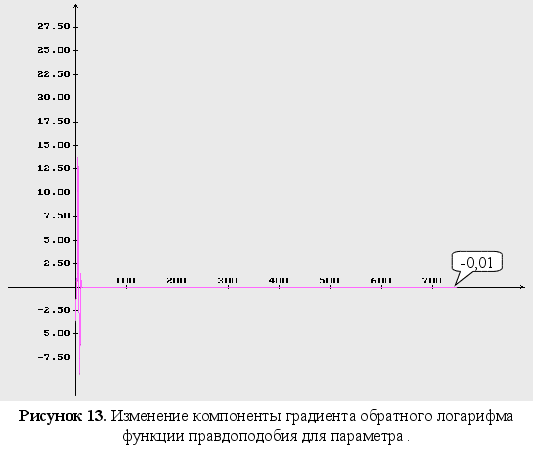
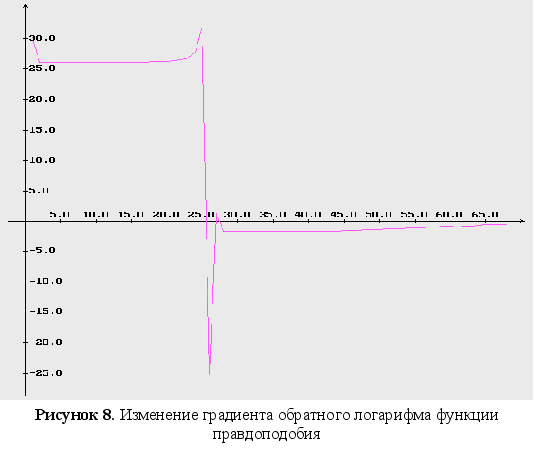
4-6 – изменение
компонент
градиента
обратного
логарифма
функции правдоподобия;
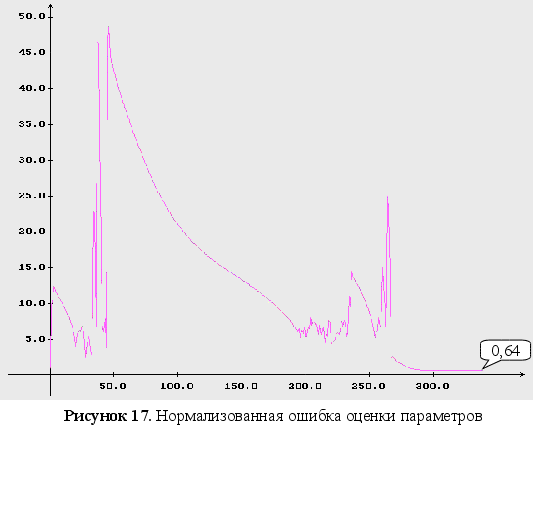
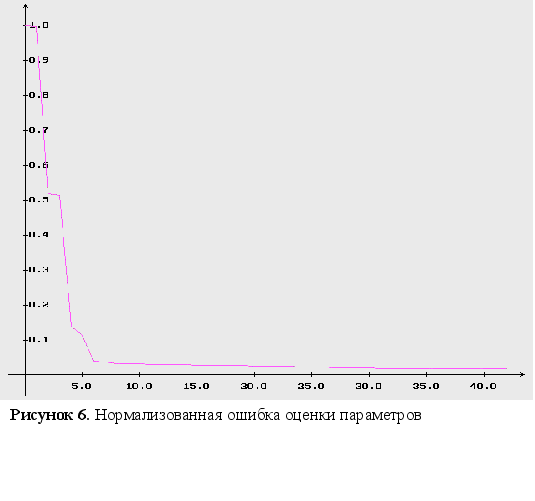
на рисунке 7 –
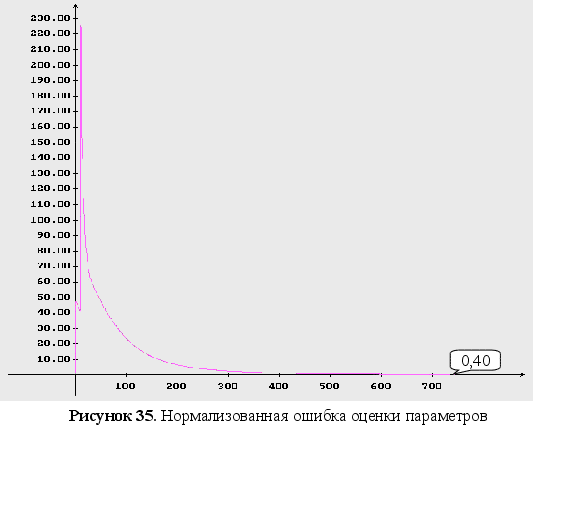
нормализованная
ошибка оценки
параметров;
на рисунках
6-21 – соответствующие
графики для
других методов
минимизации).
Также проведены
эксперименты
на выявление
зависимости
количества
времени для
одной итерации
от количества
измерений
(рисунок 26), количества
времени для
одной итерации
от размерности
вектора оцениваемых
параметров
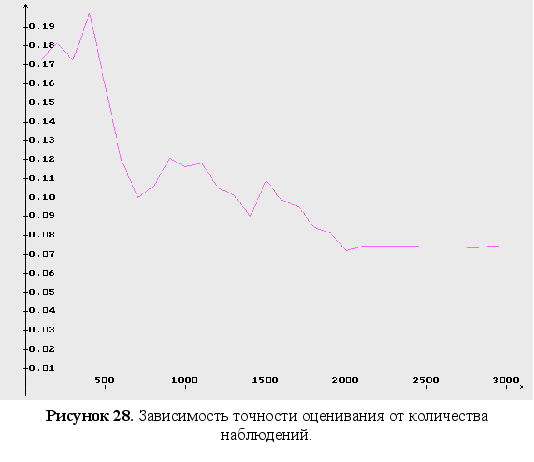
(рисунок 27), точности
оценивания
от количества
наблюдений
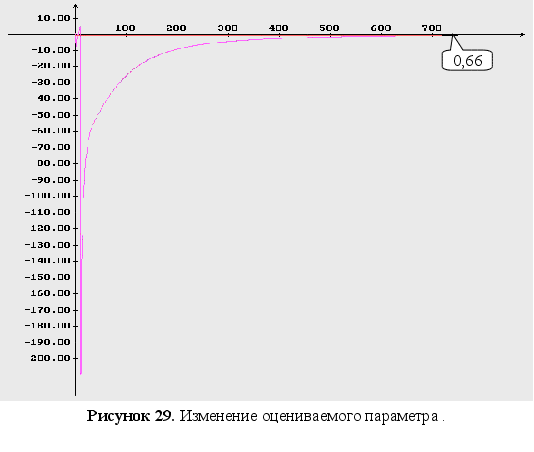
(рисунок 28), на
выявления
влияния соотношения
сигнал/шум на
точность оценивания
(рисунок 29). На
рисунках 22-25
представлена
зависимость
обратного
логарифма
функции максимального
правдоподобия
от параметров.
,
которая, в данной
случае, является
устойчивой,
а модель –
наблюдаемой
(на рисунках
1-3 представлены
изменения
оцениваемых
параметров,
используя при
минимизации
функционала
градиентный
метод; на рисунках
4-6 – изменение
компонент
градиента
обратного
логарифма
функции правдоподобия;
на рисунке 7 –
нормализованная
ошибка оценки
параметров;
на рисунках
6-21 – соответствующие
графики для
других методов
минимизации).
Также проведены
эксперименты
на выявление
зависимости
количества
времени для
одной итерации
от количества
измерений
(рисунок 26), количества
времени для
одной итерации
от размерности
вектора оцениваемых
параметров
(рисунок 27), точности
оценивания
от количества
наблюдений
(рисунок 28), на
выявления
влияния соотношения
сигнал/шум на
точность оценивания
(рисунок 29). На
рисунках 22-25
представлена
зависимость
обратного
логарифма
функции максимального
правдоподобия
от параметров.
Выводы
После проведения серии вычислительных экспериментов были получены следующие результаты:
Как видно из графиков для обратного логарифма функции максимального правдоподобия по параметрам, минимум функции является не единственным, и как следствие этого возникают ситуации, когда методы минимизации сходятся не к истинному значению оцениваемых параметров. Так же стоит заметить, что график функционала, при больших отклонениях от истинных значениях параметров, идет практически параллельно горизонтальной оси координат. Из выше сказанного можно сделать вывод, что выбор начального приближения для параметров может оказать существенное влияние как на сходимость алгоритмов, так и на истинность полученных оценок.
На оценки параметров особенно сильное влияние оказывает наблюдаемость динамической системы объекта (наблюдаемость динамической системы является необходимым условием сходимости методов параметрической идентификации), а также соотношение сигнал/шум, причем с ростом соотношения точность оценок увеличивается.
Из исследованных алгоритмов наилучшей сходимостью обладает метод сопряженных направлений, а более точным является метод Ньютона, при этом он тоже обладает достаточно хорошей сходимостью. Поэтому предпочтительней использовать метод Ньютона, т.к. при использовании ККИФ матрица вторых производных функционала (в нашем случае это информационная матрица Фишера) вычисляется естественным путем из выходных данных.
Установлено, что в общем случае скорость сходимости с ростом размерности вектора параметров и количества наблюдений сильно падает, однако с увеличением количества входных данных растет точность оценок параметров. Но существует некоторый предел, при котором рост точности приостанавливается (при количестве наблюдений более 2500). Поэтому следует искать компромисс между скоростью и точностью.
3
Иллюстративный материал к дипломной работе
Формулы
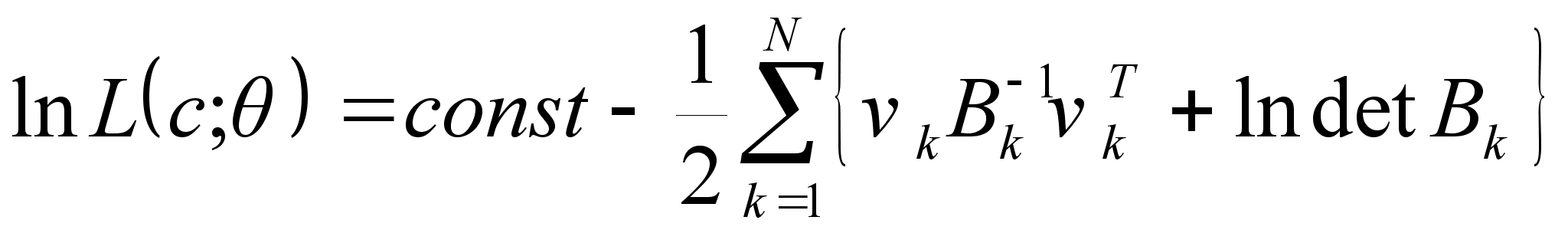 (1)
(1)
 (2)
(2)
Модель, используемая в экспериментах
Модель, используемая в экспериментах, представленных на графиках, имеет следующий вид:
![]()
![]() ,
,
где матрица перехода из состояния в состояние
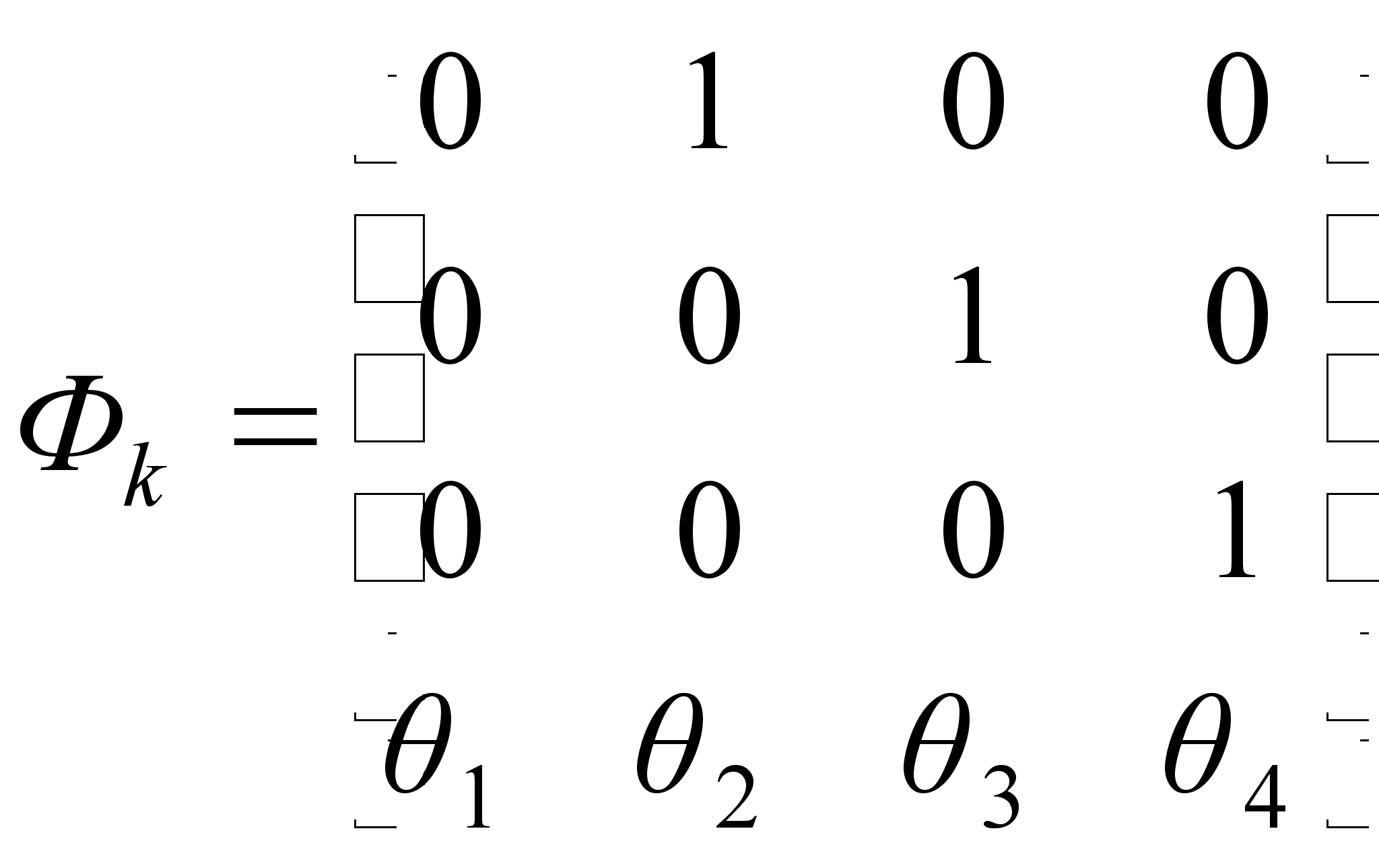 ,
,
оцениваемые
параметры ![]() имеют следующие
истинные значения
имеют следующие
истинные значения
![]()
![]() ,
,
матрица наблюдений
![]() ,
,
![]() и
и ![]() – случайные
процессы,
представляющие
собой белый
гауссовый шум
с характеристиками
– случайные
процессы,
представляющие
собой белый
гауссовый шум
с характеристиками
![]() ,
,
![]() ,
,
начальная точка
Графики
Неизвестны
три параметра
![]() .
.
начальные
условия для
оцениваемого
параметра : ![]()
г

радиентный метод
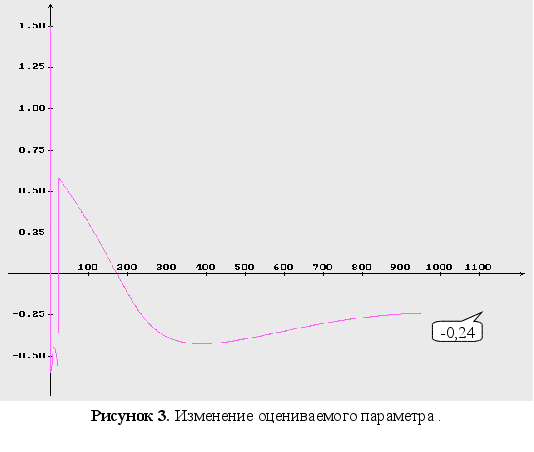
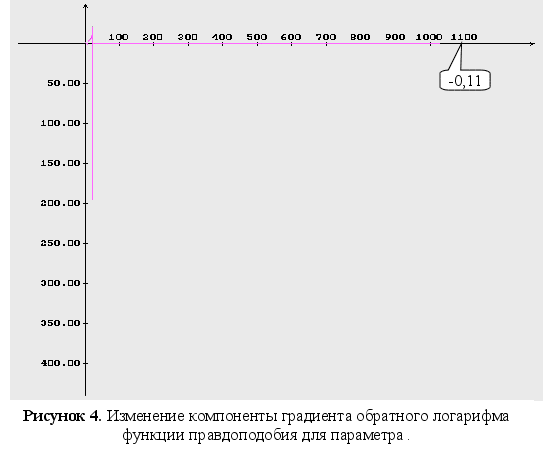

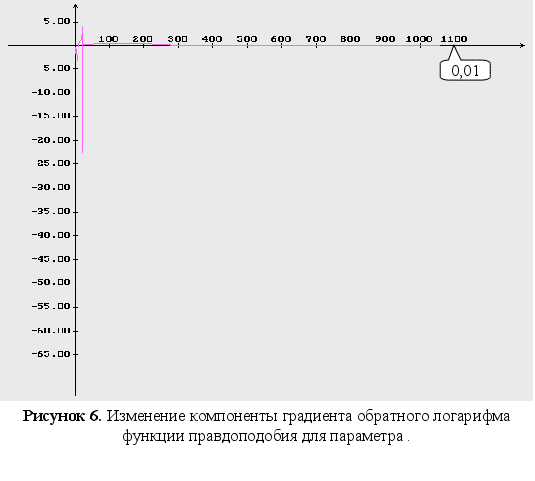
м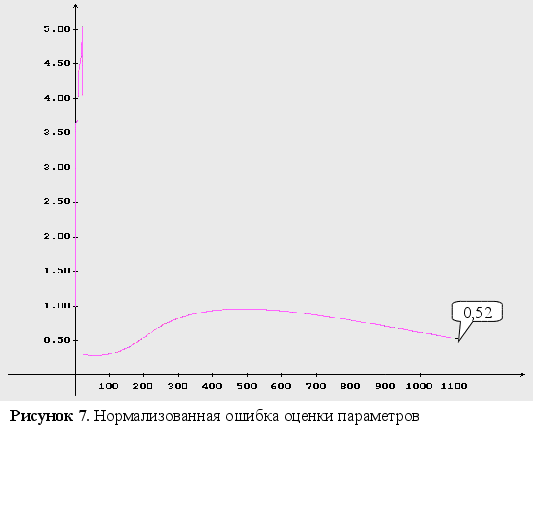
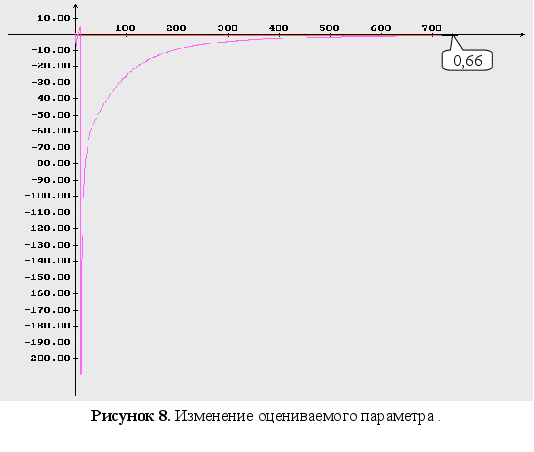
етод Ньютона

![]()
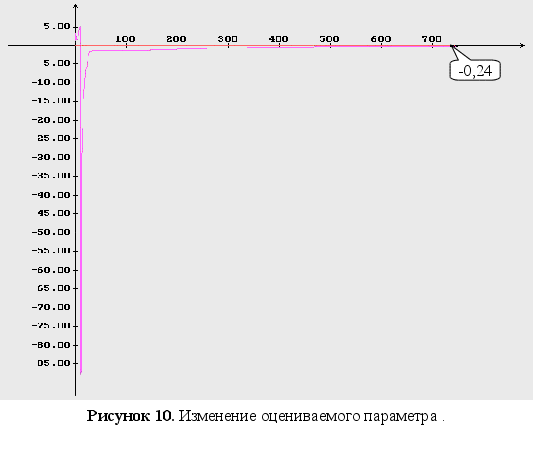


метод сопряженных направлений
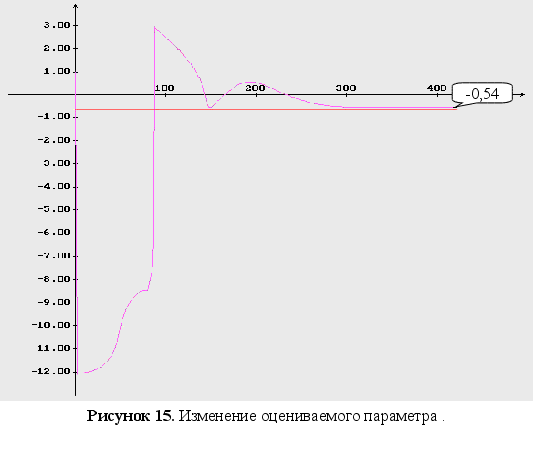

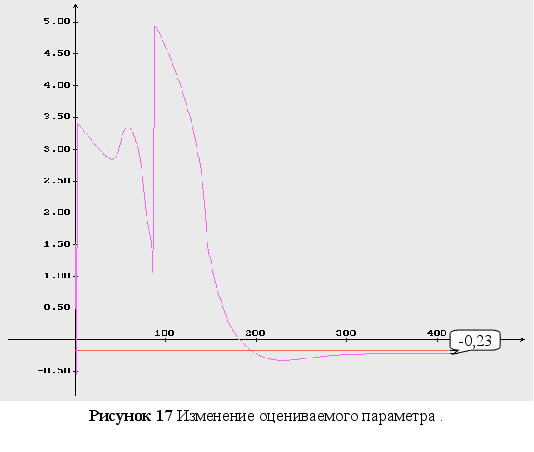

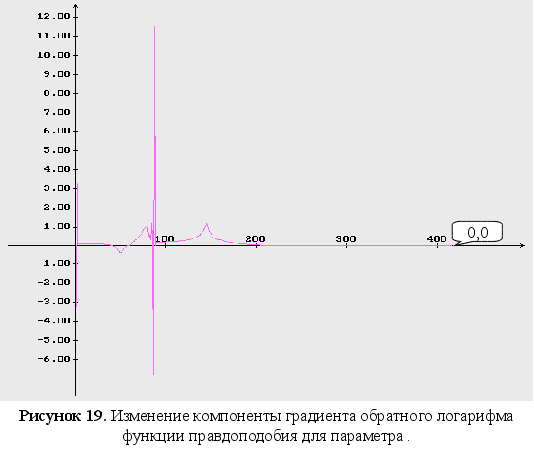
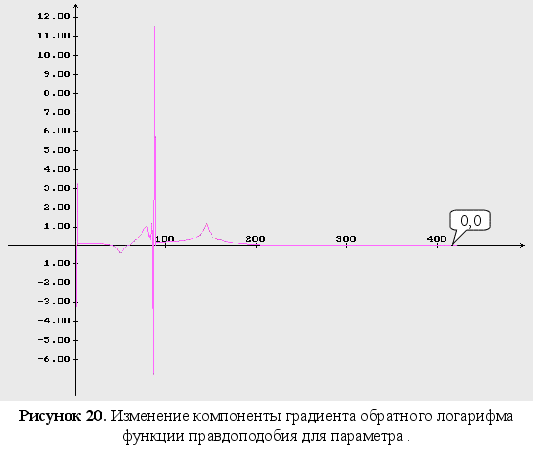
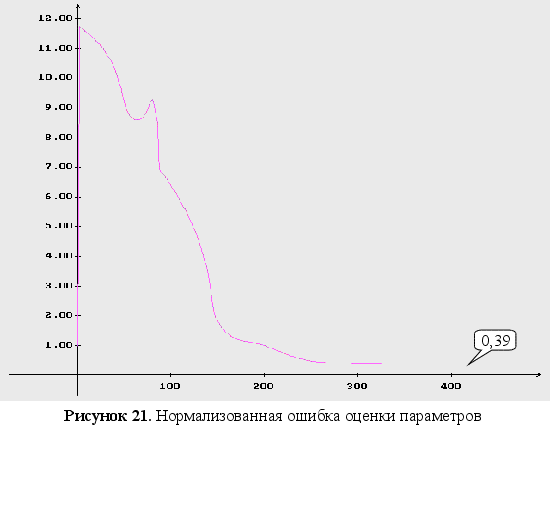
Обратный логарифм функции максимального правдоподобия


Представление других зависимостей


17
Министерство среднего и профессионального образования
Ульяновский Государственный Университет
Факультет механико-математический
Кафедра Математической Кибернетики и Информатики
Иллюстративный материал к дипломной работе
на тему
Адаптивное параметрическое оценивание квадратно-корневым информационным алгоритмом.
Выполнил:
студент гр. ПМ-52
Кудрявцев М.Ю.
УЛЬЯНОВСК
1998 г.
Министерство среднего и профессионального образования
Ульяновский Государственный Университет
Факультет механико-математический
Кафедра Математической Кибернетики и Информатики
Работа допущена к защите
Зав. кафедрой д.т.н., проф. Семушин И.В.
_____________________
_____________________
Дипломная работа
Адаптивное параметрическое оценивание квадратно-корневыми информационными алгоритмами.
Специальность: 01.02 – Прикладная математика.
Проект выполнил студент гр. ПМ-52 _______________ Кудрявцев М.Ю.
Руководитель: зав. кафедрой МКИ _______________ д.т.н., проф. Семушин И.В.
Рецензент: зав. кафедрой ПМ ________________ д.ф.-м.н. Бутов А.А.
УЛЬЯНОВСК
1998 г.
Отзыв
научного руководителя
на дипломную работу М.Ю. Кудрявцева
Тема работы ”Адаптивное параметрическое оценивание квадратно-корневым информационным алгоритмом” продиктована необходимостью проведения широкого спектра исследований по сравнительным оценкам различных подходов к проблеме идентификации моделей систем.
Новизна и привлекательность рассматриваемого подхода обусловлены соединением в нем известного критерия максимума правдоподобия с алгоритмом квадратно-коневого информационного фильтра. Последний отличается высокой численной устойчивостью к погрешностям вычислений и к случаям плохой обусловленности схемы наблюдений. Однако факт совпадения оценок максимального правдоподобия с параметрами оптимального фильтра в общем случае не доказан. Этим объясняется актуальность экспериментальных исследований, устанавливающих условия, в которых данный критерий и соответствующий алгоритм идентификации могут считаться практически пригодными. М.Кудрявцев проанализировал заданный алгоритм, отличающийся сложным и разнообразным математическим аппаратом, сочетающим методы математической статистики, оптимального оценивания и матричных вычислений. Он обосновал вычислительные компактные схемы, включая вычисление обратного логарифма функции правдоподобия, его градиента по параметру неопределенности и информационной матрицы Фишера, и разработал необходимые программы.
Основательность и настойчивость позволили М.Кудрявцеву выполнить эту работу без лишней торопливости, с глубоким пониманием существа вопроса и доведением всего исследования до наглядных экспериментальных результатов. Работа демонстрирует высокую подготовку ее автора по специальности ”Прикладная математика”, его способности к проведению самостоятельных исследований и заслуживает отличной оценки.
Д.т.н., профессор И.В. Семушин
Рецензия дипломной работы
студента гр. ПМ-52 УлГУ Кудрявцева М.Ю.
по теме
”Адаптивное параметрическое оценивание квадратно-корневым информационным алгоритмом”
В данной работе рассмотрен метод параметрической идентификации основанный на синтезе метода максимального правдоподобия и квадратно-корневого информационного фильтра. Дипломная работа включает подробный обзор, теоретический анализ методов и компьютерное моделирование. Основное внимание в работе уделено численным экспериментам, включающим построение и реализацию алгоритма на основе общего метода квадратно-корневой информационной фильтрации. Работа включает все необходимые элементы, удовлетворяет всем требованиям, предъявляемым к дипломным работам по специальности ”Прикладная математика” и заслуживает оценки ”отлично”.
Д.ф.–м.н., профессор А.А. Бутов
Эксперименты
Сходимость метода:
![]()
![]()
 ,
,
![]()
![]() ,
,
![]() ,
,
![]() ,
,
![]() ,
,

Н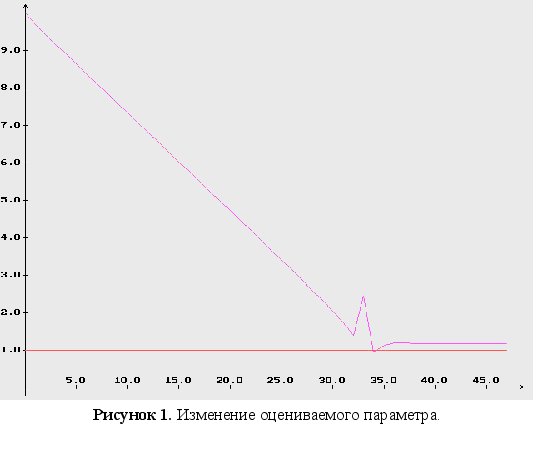
еизвестен один параметр ![]() .
.
н
ачальные
условия: ![]()




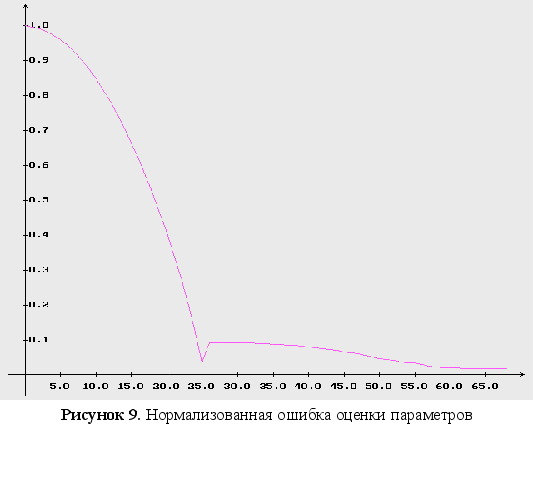
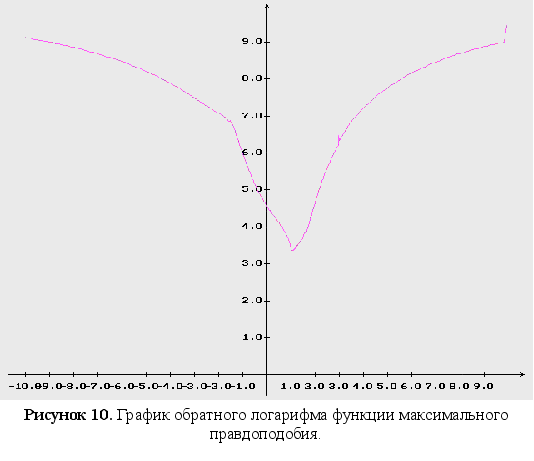
8
Введение
Спектральный анализ - это один из методов обработки сигналов, который позволяет охарактеризовать частотный состав измеряемого сигнала. Преобразование Фурье является математической основой, которая связывает временной или пространственный сигнал (или же некоторую модель этого сигнала) с его представлением в частотной области.
К обработке сигналов в реальном масштабе времени относятся задачи анализа аудио, речевых, мультимедийных сигналов, в которых помимо трудностей, связанных непосредственно с анализом спектрального содержания и дальнейшей классификацией последовательности отсчетов (как в задаче распознавания речи) или изменения формы спектра - фильтрации в частотной области (в основном относится к мультимедийным сигналам), возникает проблема управления потоком данных в современных вычислительных системах. Реальность накладывает отпечаток как на сами вычислительные алгоритмы, так и на результаты экспериментов, поднимая вопросы, с которыми не сталкиваешься при обработке всей доступной информации.
При обработке сигналов обычно приходится решать задачи двух типов - задачу обнаружения и задачу оценивания. При обнаружении нужно дать ответ на вопрос, наблюдаем ли в данное время некоторый сигнал с априорно известными параметрами. Оценивание - это задача измерения значений параметров, описывающих сигнал [1].
Сигнал часто зашумлен, на него могут накладываться мешающие сигналы. Поэтому для упрощения указанных задач сигнал обычно разлагают по базисным составляющим пространства сигналов. Для многих приложений наибольший интерес представляют периодические сигналы. Вполне естественно, что используются Sin и Cos. Такое разложение можно выполнить с помощью классического преобразования Фурье.
При обработке сигналов конечной длительности возникают интересные и взаимозависимые вопросы, которые необходимо учитывать в ходе гармонического анализа. Конечность интервала наблюдения влияет на обнаружимость тонов в присутствии сильных шумов, на разрешимость тонов меняющейся частоты и на точность оценок параметров всех вышеупомянутых сигналов.
Постановка проблем, формулировка задач
На настоящее время существует большое количество алгоритмов и групп алгоритмов, которые так или иначе решают основную задачу спектрального анализа: оценивание спектральной плотности мощности, с тем чтобы по полученному результату судить о характере обрабатываемого сигнала .Основной вклад сделан такими исследователями как : Голд Б. (Gold B.), Рабинер Л. (Rabiner L.R.) , Бартлетт M. (Bartlett M.S.) Однако каждый из алгоритмов имеет свою область приложения. Например, градиентные адаптивные авторегрессионные методы не могут быть применены к обработке данных с быстро меняющимся во времени спектром. Классические методы имеют широкую область применения, но проигрывают авторегрессионным и методах, основанных на собственных значениях, по качеству оценивания. Но в реальном масштабе времени использование последних затруднено из-за вычислительной сложности.
Более того, применение каждого из методов обычно требует выбора значений параметров (выбор окна данных и корреляционного окна в классических методах, порядка модели в авторегрессионном алгоритме и алгоритме линейного предсказания, предполагаемого числа собственных векторов в пространстве шума в метода Писаренко) и правильный выбор требует экспериментальных результатов с каждым классом алгоритмов.
Таким образом, имеется следующая задача :
На основе существующих алгоритмов проанализировать возможность применения как к последовательной обработке сигналов в реальном времени, так и к блочной обработке и оценить качество получаемых результатов
Из вышесказанного можно сформулировать следующие подзадачи:
I. теоретическое и практическое исследование алгоритмов блочной обработки
II. анализ классических алгоритмов блочной обработки всей последовательности в части применения окон данных и корреляционных окон
анализ алгоритмов обработки сигналов в реальном масштабе времени
Существует несколько проблем, специфичных для обработки сигналов в реальном времени:
· Необходимость в «одновременном» выполнении следующих основных этапов обработки данных:
Непосредственное получение последовательности входных данных (цифровые отсчеты аудио-сигнала, речевого сигнала).
Обработка получаемых отсчетов сигнала.
Представление обработанной информации
Возможность контролировать процесс обработки информации
· Ограничение длительности интервала выборки поступающих данных вычислительными ресурсами
· Ограничение длительности интервала выборки характером сигнала
Если первая проблема очевидна в рамках обработки данных в реальном времени, то вторая и третья проблемы требуют осмысления причин этих ограничений.
К сформулированным выше задачам добавляются :
задача построения схемы управления обработкой данных в реальном времени, основанной, в силу первой проблемы, на параллельных вычислениях и протоколах взаимодействия и синхронизации;
экспериментальный анализ по второй проблеме, то есть исследование влияния вычислительных ресурсов и методов оцифровки данных на максимально допустимую длину интервала выборки;
анализ длительности, исходя из характера сигнала.
Из постановки основной задачи вытекает необходимость в проведении большого количества экспериментов. Экспериментальные входные данные формируются следующим образом
·
для задачи
анализа алгоритмов
блочной обработки
всей последовательности
отсчетов формируются
дискретизированные
отсчеты данных
тест-сигнала
из суммы комплексных
синусоид и
аддитивных
окрашенных
шумовых процессов,
сформированные
посредством
пропускания
белого шума
через фильтр
с частотной
характеристикой
типа приподнятого
косинуса или
окна Хэмминга.
Таким образом,
в этом случае
эксперимент
определяется
набором ![]() ,
где
,
где ![]() -
последовательность
комплексных
синусоид с
амплитудами
-
последовательность
комплексных
синусоид с
амплитудами
![]() дБ и частотами
дБ и частотами
![]() Гц,
а
Гц,
а ![]() - последовательность
шумовых процессов
с параметрами
:
центральная
частота
- последовательность
шумовых процессов
с параметрами
:
центральная
частота ![]() Гц., динамический
диапазон
перекрываемых
частот
Гц., динамический
диапазон
перекрываемых
частот ![]() Гц.,
мощность шума
Гц.,
мощность шума ![]() дБ.
дБ.
· для анализа классических алгоритмов блочной обработки всей последовательности в части применения окон данных и корреляционных окон эксперимент и подсчет основных характеристик окон производится над дискретизированными отсчетами соответствующих функций.
· для анализа алгоритмов обработки сигналов в реальном масштабе времени данными являются аудио и речевой сигналы.
Выходными данными экспериментов являются :
· для задачи анализа алгоритмов блочной обработки всей последовательности отсчетов :
1.) оценка спектральной плотности мощности , полученная с помощью того или иного метода спектрального анализа, по которой можно судить о качестве применяемого метода, сравнивая истинную спектральную плотность мощности сформированного сигнала с полученной оценкой
2.) вычислительные и временные затраты метода
· для анализа окон данных и корреляционных окон - расчетные основные характеристики такие как : максимальный уровень боковых лепестков, эквивалентная ширина полосы, ширина полосы по уровню половинной мощности, степень корреляции и т.д..
· для анализа сигналов в реальном масштабе времени : спектральная плотность мощности (функция, зависящая в этом эксперименте также и от времени). Для оценки составляющих в спектре сигнала в данный момент времени.
Из ... Теоретический анализ существующих алгоритмов спектрального анализа.
Спектральная оценка, получаемая по конечной записи данных, характеризует некоторое предположение относительно той истинной спектральной функции, которая была бы получена, если бы в нашем распоряжении имелась запись данных бесконечной длины. Именно поэтому поведение и характеристики спектральных оценок должны описываться с помощью статистических терминов. Общепринятыми статистическими критериями качества оценки являются ее смещение и дисперсия.
Из формального определения спектра, следует, что спектр является некоторой функцией одних лишь статистик второго порядка, относительно которых в свою очередь предполагается, что они остаются неизменными, или стационарными во времени. Следовательно, такой спектр не передает полной статистической информации об анализируемом случайном процессе, а значит, дополнительная информация может содержаться в статистиках третьего и более высокого порядка. Кроме того, многие обычные сигналы, которые приходится анализировать на практике, не являются стационарными. Однако короткие сегменты данных, получаемые из более длинной записи данных, можно считать локально стационарными. Анализируя изменения спектральных оценок от одного такого сегмента к другому, можно затем составить представление и об изменяющихся во времени статистиках сигналов, то есть нестационарных.
Определение: Непрерывно-временным преобразованием Фурье называется функция

Определение: Обратное преобразование Фурье определяется выражением
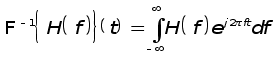
Дискретное преобразование Фурье
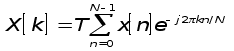
 ,
где
,
где ![]()
Спектральная Плотность Мощности


Хотя выборочный спектр не является состоятельной оценкой истинной спектральной плотности мощности, эта оценка может быть использована если выполнять некоторого рода усреднение или сглаживания. На использовании этой оценки основан классический периодограммый метод определения спектральной плотности мощности.
Дальше идут методы ..... 1,2,3,4,.... вместе с экспериментальным анализом алгоритмов спектрального анализа.
Особенности реализации
Для реализации алгоритмов был реализован язык проектирования алгоритмов, включающий в себя средства межзадачного обмена данными, то есть построение распределенных по процессам вычислительных алгоритмов, определенные части которого исполняются параллельно несколькими процессам. Дальнейшим развитием этого подхода является построение сетевых распределенных схем алгоритмов. Существует большое количество приложений этого подхода.
Заключение
В данной работе :
Tеоретически проанализированы методы спектрального анализа, а также возможность применения этих методов в современных вычислительных системах для обработки данных в реальном масштабе времени.
Получены результаты поставленных экспериментов и на их основе выбран наиболее подходящий метод оценивания спектральной плотности мощности в аддитивной смеси комплексных синусоид и окрашенного стационарного шумового процесса.
Дано описание и выполнена реализация схемы управления процессом обработки данных в реальном времени, использующая преимущества параллельной архитектуры вычислительных систем.
Cформулирован ряд требований по вычислительным ресурсам при реальной обработке сделан анализ длины выборки данных при различном представлении входного сигнала.
Получены результаты по эксперименту вычисления характеристик окон и на их основе выбрано оптимальное решение в каждом эксперименте по оцениванию спектральной плотности мощности тест-сигнала.
Выводы
Введение.
Проблема идентификации линейной динамической системы заключается в создании модели процесса по его наблюдаемым входным и выходным сигналам в детерминистской или стохастической обстановке. Процесс идентификации включает в себя две независимые процедуры, а именно, структурную идентификацию и идентификацию параметров.
Когда неизвестны структура объекта и соответствующие физические законы, которым подчиняется его поведение, проводятся эксперименты, направленные на выявление структуры объекта и законов его поведения методами структурной идентификации. В случае, когда известна структура объекта (т.е. существует модель характеризующая его свойства), а неизвестными являются некоторые его характеристики, описываемые конечномерным вектором, последние определяются методами параметрической идентификации.
Постановка задачи
Целью данной дипломной работы является исследование нового метода параметрической идентификации основанного на синтезе метода максимального правдоподобия и метода квадратно-корневого информационного фильтра (ККИФ), сравнение его с другими существующими алгоритмами с точки зрения вычислительной точности, быстродействия и сложности, а также реализация данного метода на ЭВМ.
Метод
Как известно, оценкой максимального правдоподобия является значение оцениваемых параметров, которое максимизирует вероятность события, при котором наблюдения, сгенерированные с подстановкой оцениваемых параметров, совпадают с действительными значениями наблюдений. Вычисление оценки максимального правдоподобия может быть итеративно выполнено при помощи характеристического уравнения, которое включает в себя градиент обратного логарифма функции правдоподобия и информационную матрицу Фишера. Вычисления функции правдоподобия и информационной матрицы Фишера требуют применения фильтра Калмана (а также его производных для каждого параметра оценивания), который, как известно, не обладает достаточной устойчивостью. Бирман, занимавшийся построением численно устойчивых алгоритмов фильтрации, предложил для вычисления оценки максимального правдоподобия итеративным образом использовать квадратно-корневой информационный фильтр. В отличие от традиционного фильтра Калмана, ККИФ позволяет избежать численной неустойчивости, являющейся результатом вычислительных погрешностей, поскольку вместо ковариации ошибки оценок на этапах экстраполяции и обработки измерений, по своей природе положительно определенных, ККИФ оперирует с их квадратными корнями. Это значит, что вычисление квадратного корня равносильно счету с двойной точностью ковариации ошибок, кроме того устраняется опасность утраты матрицей ковариаций свойства положительно определенности. Недостатком данного метода является присутствие операций извлечения квадратного корня.
Таким образом, вычисление оценки максимального правдоподобия может быть осуществлено итеративно по следующей формуле:
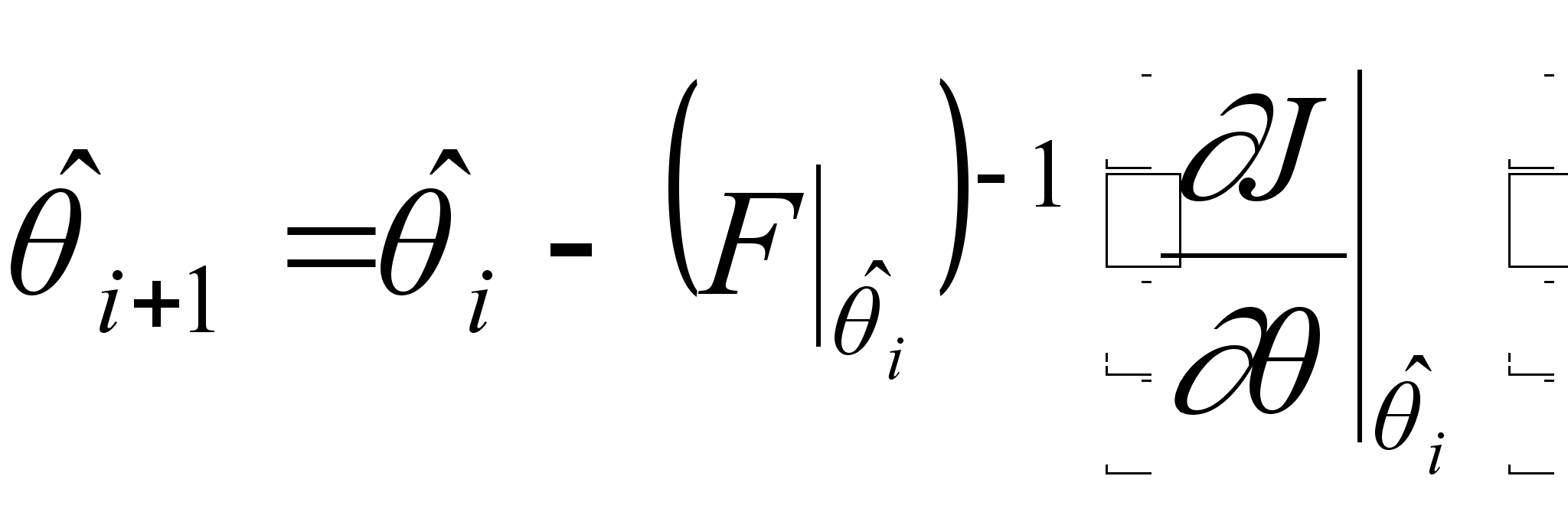 (1)
(1)
где ![]() - конечномерный
вектор оцениваемых
параметров;
- конечномерный
вектор оцениваемых
параметров;
![]() - индекс, определяющий
номер итерации;
- индекс, определяющий
номер итерации;
![]() - информационная
матрица Фишера;
- информационная
матрица Фишера;
![]() - градиент функции
максимального
правдоподобия.
- градиент функции
максимального
правдоподобия.
Стоит заметить,
что итеративные
алгоритмы,
подобные (1), в
среднем сходятся
за меньшее
число шагов,
чем те алгоритмы,
которые включают
в себя только
вычисления
![]() .
С другой стороны,
алгоритмы,
содержащие
.
С другой стороны,
алгоритмы,
содержащие
![]() и
и
![]() ,
требуют больше
вычислений
на каждом шаге.
,
требуют больше
вычислений
на каждом шаге.
Для эффективного
вычисления
градиента
функции максимального
правдоподобия
при использовании
ККИФ в фильтрации
данных, величины,
входящие в
выражение для
![]() ,
представляются
непосредственно
через величины,
значения которых
вычисляются
ККИФ-ом. При
этом, если заменить
ожидаемые
значения переменных
измеренными,
то матрица
Фишера также
вычисляется
через значения
получаемых
ККИФ-ом. Но что
самое интересное,
так это то, что
в случае использования
фильтра Калмана
для вычисления
градиента,
необходимо
запустить
дифференцирующий
фильтр Калмана
для каждого
из параметров
,
представляются
непосредственно
через величины,
значения которых
вычисляются
ККИФ-ом. При
этом, если заменить
ожидаемые
значения переменных
измеренными,
то матрица
Фишера также
вычисляется
через значения
получаемых
ККИФ-ом. Но что
самое интересное,
так это то, что
в случае использования
фильтра Калмана
для вычисления
градиента,
необходимо
запустить
дифференцирующий
фильтр Калмана
для каждого
из параметров
![]() .
В схеме же ККИФ
этот ”набор”
фильтров заменяется
расширенными
массивами
данных, к которым
и применяются
ортогональные
преобразования.
.
В схеме же ККИФ
этот ”набор”
фильтров заменяется
расширенными
массивами
данных, к которым
и применяются
ортогональные
преобразования.
Заметим, что нахождение оценки максимального правдоподобия эквивалентно минимизации обратного логарифма функции правдоподобия, тогда критерием для метода является выражение:
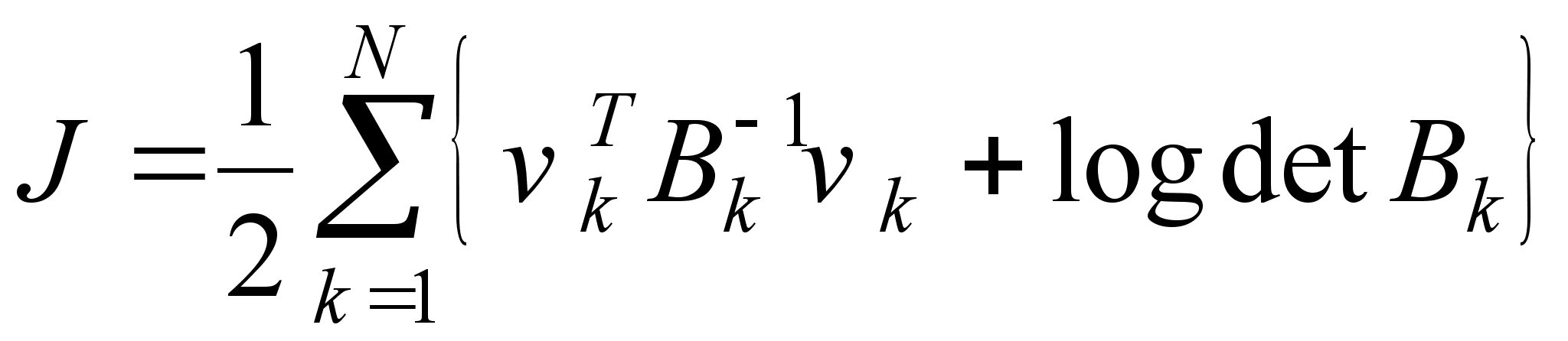 (2)
(2)
где ![]() - невязка,
- невязка, ![]() - остаточная
ковариация
(т.е. ковариация
невязок), подразумевается,
что значения
невязок
- остаточная
ковариация
(т.е. ковариация
невязок), подразумевается,
что значения
невязок ![]() в каждый момент
времени
в каждый момент
времени ![]() независимы.
Независимость
же невязок
обеспечивается
при оптимальном
фильтре, т.е.
при точно известных
значениях
параметра
независимы.
Независимость
же невязок
обеспечивается
при оптимальном
фильтре, т.е.
при точно известных
значениях
параметра ![]() .
Из этого предположения
следует, что
начальные
значения для
параметра
должны быть
достаточно
близкими к
истинным его
значениям.
.
Из этого предположения
следует, что
начальные
значения для
параметра
должны быть
достаточно
близкими к
истинным его
значениям.
Выводы
Факт сходимости алгоритма максимального правдоподобия к оптимальным значениям параметров теоретически является недоказанным, поэтому в качестве основного метода исследования будем считать вычислительные эксперименты.
В рамках данного дипломного проекта были проведены следующие эксперименты:
Выявление зависимости точности оценивания от количества измерений.
Выявление зависимость точности оценивания от начальных условий для оцениваемых параметров.
Выявление зависимости времени оценивания от размерности задачи.
Проверка на сходимость метода с полностью наблюдаемой и ненаблюдаемой моделью системы.
Сравнение точности оценивания данного метода с другими существующими методами.
Сравнение времени оценивания данного метода с другими существующими методами.
После проведения серии вычислительных экспериментов были получены следующие результаты:
Вышеописанный метод требует значительного количества времени для одной итерации по сравнению с другими методами параметрической идентификации, поскольку требуется вычисление градиента обратного логарифма функции правдоподобия и информационной матрицы Фишера. Данный факт показывает, что метод является достаточно сложным в вычислительном отношении.
Сходимость метода в значительной степени зависит от устойчивости матрицы перехода из состояния в состояние, от наблюдаемости динамической системы объекта, а также от количества оцениваемых параметров (наблюдаемость динамической системы является необходимым условием сходимости методов параметрической идентификации).
Метод критичен к начальным оценкам параметров.
Заключение
В данном дипломном проекте была проведена следующая работа:
Теоретически проанализирован алгоритм параметрической идентификации основанный на методе максимального правдоподобия с использованием квадратно-корневых информационных фильтров.
Данный метод программно реализован на ЭВМ.
Для проведения сравнительных экспериментов программно реализованы другие известные методы параметрической идентификации.
Поставлены эксперименты на выявление основных преимуществ и недостатков выше описанного метода по сравнению с другими реализованными методами.
Получены результаты поставленных экспериментов и на их основе сделаны выводы.
4
0 комментариев