Навигация
Принципы управления и распределения оперативной памяти
48910
знаков
4
таблицы
3
изображения
1.2 Принципы управления и распределения оперативной памяти
Основной ресурс системы, распределением которого занимается ОС - это оперативная память (ОП). Поэтому организация памяти оказывает большое влияние на структуру и возможности ОС.
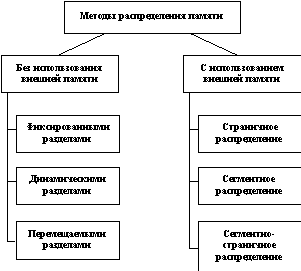
Используемые в операционных системах алгоритмы распределения ОП многообразны. Причинами этого многообразия являются:
· многоуровневая структура памяти (регистровая, оперативная, внешняя)
· стремление обеспечить пользователя характеристиками, отличными от реальных (виртуальная память)
· необходимость согласования распределения ОП с распределением центрального процессора
Самый простой случай управления памятью - ситуация, когда диспетчер памяти отсутствует, и в системе может быть загружена только одна программа. Именно в таком режиме работают CP/M и RT-11 SJ (Single-Job, однозадачная).
В этих системах программы загружаются с фиксированного адреса PROG_START. В CP/M это 0x100; в RT-11 - 01000. В адресах от 0 до начала программы находятся вектора прерываний, а в RT-11 - также и стек программы. В этом случае управление памятью со стороны системы состоит в том, что загрузчик проверяет, поместится ли загружаемый модуль в пространство от PROG_START до SYS_START. Если объем памяти, который использует программа, не будет меняться во время ее исполнения, то на этом все управление и заканчивается.
Однако программа может использовать динамическое управление памятью, например функцию malloc(). В этом случае уже код malloc() должен следить за тем, чтобы не залезть в системные адреса. Как правило, динамическая память начинает размещаться с адреса PROG_END = PROG_START + PROG_SIZE. PROG_SIZE в данном случае обозначает полный размер программы, то есть размер ее кода, статических данных и области, выделенной под стек.
Функция malloc() поддерживает некоторую структуру данных, следящую за тем, какие блоки памяти из уже выделенных были освобождены. При каждом новом запросе она сначала ищет блок подходящего размера в своей структуре данных и, только когда этот поиск завершится неудачей, откусывает новый блок памяти у системы. Для этого используется переменная, которая в библиотеке языка C называется brklevel. Изначально эта переменная равна PROG_END, ее значение увеличивается при выделении новых блоков, но в некоторых случаях может и уменьшаться. Это происходит, когда программа освобождает блок, который заканчивается на текущем значении brklevel.
Потребности отдельных программ в ресурсе памяти в процессе обработки могут меняться, что заранее, до запуска программы, не может быть учтено. В связи с этим необходимо распределять память динамически непосредственно в ходе вычислительного процесса, т.е. осуществлять динамическое распределение памяти.
Алгоритмы динамического упpавления памятьюДинамическое распределение памяти (его еще иногда называют управлением кучей (pool или heap)) представляет собой нетривиальную проблему. Действительно, активное использование функций malloc/free может привести к тому, что вся доступная память будет разбита на блоки маленького размера, и попытка выделения большого блока завершится неудачей, даже если сумма длин маленьких блоков намного больше требуемой. Это явление называется фрагментацией памяти. Кроме того, большое количество блоков требует длительного поиска.
В зависимости от решаемой задачи используются различные алгоритмы поиска свободных блоков памяти. Действительно, программа может требовать множество блоков одинакового размера, или нескольких фиксированных размеров. Это сильно облегчает решение проблемы фрагментации и поиска. Возможны ситуации, когда блоки освобождаются в порядке, обратном тому, в котором они выделялись. Это позволяет свести выделение памяти к стековой структуре. Возможны ситуации, когда некоторые из занятых блоков можно переместить по памяти. Так, например, функцию realloc() в ранних реализациях системы UNIX можно было использовать именно для этой цели.
В стандартных библиотеках языков высокого уровня, таких как malloc/free/realloc в C, new/dispose в Pascal и т.д., как правило, используются алгоритмы, рассчитанные на худший случай: программа требует блоки случайного размера в случайном порядке и освобождает их также случайным образом.
Возможны алгоритмы распределения памяти двух типов: когда размер блока является характеристикой самого блока, и когда его сообщают отдельно при освобождении. К первому типу относится malloc/free, ко второму - GetMem/FreeMem в Turbo Pascal. В первом случае с каждым блоком ассоциируется некоторый дескриптор, который содержит длину этого блока и еще информацию. Этот дескриптор может храниться отдельно от блока, или быть его заголовком. Иногда дескриптор состоит из двух меток - в начале блока и в его конце. Для чего это может быть полезно, будет рассказано ниже.
Обычно все свободные блоки памяти объединяются в двунаправленный связанный список. Список должен быть двунаправленным для того, чтобы из него в любой момент можно было извлечь любой блок. Впрочем, если все действия по извлечению блока производятся после поиска, то можно слегка усложнить пpоцедуpу поиска и всегда сохранять указатель на пpедыдущий блок. Это pешает пpоблему извлечения и можно огpаничиться однонапpавленным списком. Беда только в том, что многие алгоpитмы пpи объединении свободных блоков извлекают их из списка в соответствии с адpесом, поэтому для таких алгоpитмов двунапpавленный список необходим.
Поиск в списке может вестись двумя способами: до нахождения первого подходящего (first fit) блока или до блока, размер которого ближе всего к заданному - наиболее подходящего (best fit). Для нахождения наиболее подходящего мы обязаны просматривать весь список, в то время как первый подходящий может оказаться в любом месте, и среднее время поиска будет меньше.
Кроме того, в общем случае best fit увеличивает фрагментацию памяти. Действительно, если мы нашли блок с размером больше заданного, мы должны отделить «хвост» и пометить его как новый свободный блок. Понятно, что в случае best fit средний размер этого хвоста будет маленьким, и мы в итоге получим большое количество мелких блоков, которые невозможно объединить, так как пространство между ними занято.
При использовании first fit с линейным двунаправленным списком возникает специфическая проблема. Если каждый раз просматривать список с одного и того же места, то большие блоки, расположенные ближе к началу, будут чаще удаляться. Соответственно, мелкие блоки будут иметь тенденцию скапливаться в начале списка, что увеличит среднее время поиска. Простой способ борьбы с этим явлением состоит в том, чтобы просматривать список то в одном направлении, то в другом. Более радикальный и еще более простой метод состоит в том, что список делается кольцевым, и поиск каждый начинается с того места, где мы остановились в прошлый раз. В это же место добавляются освободившиеся блоки.
В ситуациях, когда размещаются блоки нескольких фиксированных размеров, алгоритмы best fit оказываются лучше. Однако библиотеки распределения памяти рассчитывают на худший случай, и в них обычно используются алгоритмы first fit.
В случае работы с блоками нескольких фиксированных размеров напрашивается такое решение: создать для каждого типоразмера свой список.
Интересный вариант этого подхода для случая, когда различные размеры являются степенями числа 2, как 512 байт, 1Кбайт, 2Кбайта и т.д., называется алгоритмом близнецов. Он состоит в том, что мы ищем блок требуемого размера в соответствующем списке. Если этот список пуст, мы берем список блоков вдвое большего размера. Получив блок большего размера, мы делим его пополам. Ненужную половину мы помещаем в соответствующий список свободных блоков. Одно из преимуществ этого метода состоит в простоте объединения блоков при их освобождении. Действительно, адрес блока-близнеца получается простым инвертированием соответствующего бита в адресе нашего блока. Нужно только проверить, свободен ли этот близнец. Если он свободен, то мы объединяем братьев в блок вдвое большего размера, и т.д.
Алгоритм близнецов значительно снижает фрагментацию памяти и резко ускоряет поиск блоков. Наиболее важным преимуществом этого подхода является то, что даже в наихудшем случае время поиска не превышает. Это делает алгоритм близнецов труднозаменимым для ситуаций, когда необходимо гарантированное время реакции - например, для задач реального времени. Часто этот алгоритм или его варианты используются для выделения памяти внутри ядра ОС. Например, функция kmalloc, используемая в ядре ОС Linux, основана именно на алгоритме близнецов.
Разработчик программы динамического распределения памяти обязан решить еще одну важную проблему, а именно - объединение свободных блоков. Наилучшим из известных универсальных алгоритмов динамического распределения памяти является алгоритм парных меток с объединением свободных блоков в двунаправленный кольцевой список и поиском по принципу first fit. Этот алгоритм обеспечивает приемлемую производительность почти для всех стратегий распределения памяти, используемых в прикладных программах. Такой алгоритм используется практически во всех реализациях стандартной библиотеки языка C и во многих других ситуациях. Другие известные алгоритмы либо просто хуже, чем этот, либо проявляют свои преимущества только в специальных случаях.
К основным недостаткам этого алгоритма относится отсутствие верхней границы времени поиска подходящего блока, что делает его неприемлемым для задач реального времени.
Некоторые системы программирования используют специальный метод освобождения динамической памяти, называемый сборкой мусора. Этот метод состоит в том, что ненужные блоки памяти не освобождаются явным образом. Вместо этого используется некоторый более или менее изощренный алгоритм, следящий за тем, какие блоки еще нужны, а какие - уже нет.
Самый простой метод- отличать используемые блоки от ненужных - считать, что блок, на который есть ссылка, нужен, а блок, на который ни одной ссылки не осталось - не нужен. Для этого к каждому блоку присоединяют дескриптор, в котором подсчитывают количество ссылок на него. Каждая передача указателя на этот блок приводит к увеличению счетчика ссылок на 1, а каждое уничтожение объекта, содержавшего указатель - к уменьшению.
Все остальные методы сборки мусора так или иначе сводятся к поддержанию базы данных о том, какие объекты на кого ссылаются. Использование такой техники возможно практически только в интерпретируемых языках типа Lisp или Prolog, где с каждой операцией можно ассоциировать неограниченно большое количество действий.
Многозадачная или многопрограммная ОС также должны использовать тот или иной алгоритм размещения памяти. Такие алгоритмы могут быть похожи на работу malloc. Однако режим работы ОС может вносить существенные упрощения в алгоритм.
Так, например, пpоцедуpа управления памятью MS DOS рассчитана на случай, когда программы выгружаются из памяти только в порядке, обратном тому, в каком они туда загружались. Это позволяет свести управление памятью к стековой дисциплине.
Каждой программе в MS DOS отводится блок памяти. С каждым таким блоком ассоциирован дескриптор, называемый MCB - Memory Control Block. Этот дескриптор содержит размер блока, идентификатор программы, которой принадлежит этот блок и признак того, является ли данный блок последним в цепочке. Нужно отметить, что программе всегда принадлежит несколько блоков, но это уже несущественные детали. Другая малосущественная деталь та, что размер сегментов и их адреса отсчитываются в параграфах размером 16 байт. После запуска.com-файл получает сегмент размером 64К, а.exe - всю доступную память. Обычно.exe-модули сразу после запуска освобождают ненужную им память и устанавливают brklevel на конец своего сегмента, а потом увеличивают brklevel и наращивают сегмент по мере необходимости. Естественно, что наращивать сегмент можно только за счет следующего за ним в цепочке MCB, и MS DOS разрешит делать это только в случае, если этот сегмент не принадлежит никакой программе.
При запуске программы DOS берет последний сегмент в цепочке, и загружает туда программу, если этот сегмент достаточно велик. Если он недостаточно велик, DOS «говорит» Not enough memory и отказывается загружать программу.
При завершении программы DOS освобождает все блоки, принадлежавшие программе. При этом соседние блоки объединяются. Пока программы, действительно, завершаются в порядке, обратном тому, в котором они запускались, - все вполне нормально. Другое дело, что в реальной жизни возможны отклонения от этой схемы.
Например, неявно предполагается, что TSR-программы (Terminate, but Stay Resident) никогда не пытаются завершиться. Другой пример - отладчики обычно загружают программу в обход обычной DOS-овской функции LOAD & EXECUTE, а при завершении отлаживаемой программы сами освобождают память из-под нее.
В системах с динамической сборкой первые две проблемы не так остры, потому что память выделяется и освобождается небольшими кусочками, по блоку на каждый объектный модуль, поэтому код программы обычно не занимает непрерывного пространства. Соответственно, такие системы часто разрешают и данным программы занимать несмежные области памяти.
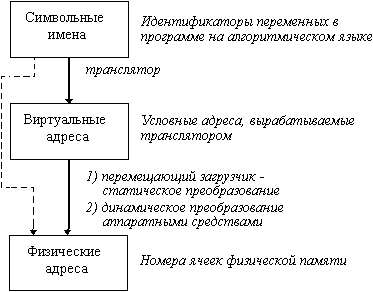
Для достижения гибкого динамического распределения памяти, устранения ее фрагментации, а также создания значительных удобств для программирования в современных ОС широко используется виртуальная память. При этом на всех этапах подготовки программ, включая загрузку в оперативную память, программа представляется в виртуальных адресах и лишь при самом исполнении машиной команды производится преобразование виртуальных адресов в адреса действующей памяти (в так называемые физические адреса). Это преобразование составляет содержание динамического распределения памяти.
Объем виртуального адресного пространства может даже превосходить всю доступную реальную память на ЭВМ. Содержимое виртуальной памяти, неиспользуемой программой, хранится на некотором внешнем устройстве (внешней памяти). По необходимости части этой виртуальной памяти отображаются в реальную память. Ни о внешней памяти, ни о ее отображении в реальную память программа ничего не знает. Она написана так, как будто бы виртуальная память существует в действительности (рис. 2.).
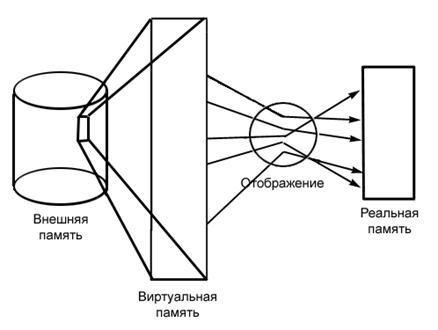
Рис.2. Основная концепция виртуальной памяти
При страничной организации основная память делится на блоки фиксированного размера, обычно называемые рамка страниц. Каждая программа пользователя делится на блоки сответствующего размера, называемые страницами. Страницы организуются в логическом адресном пространстве, а рамки cтраниц - в физическом. Поскольку страницы и рамки страниц имеют различные идентификаторы, возникают интересные ситуации, касающиеся взаимосвязи между логическим адресным пространством (ЛАП) и физическим адресным пространством ФАП).
Похожие работы
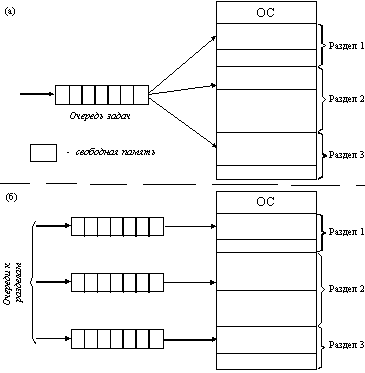
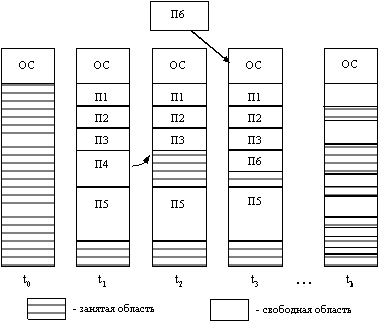
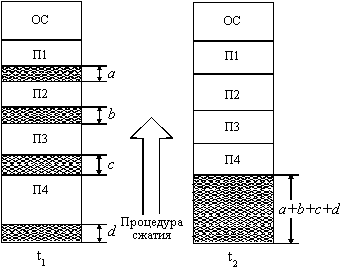
... задачи П4 место загружается задача П6, поступившая в момент t3. Рис. 2.10. Распределение памяти динамическими разделами Задачами операционной системы при реализации данного метода управления памятью является: ведение таблиц свободных и занятых областей, в которых указываются начальные адреса и размеры участков памяти, при поступлении новой задачи - анализ запроса, просмотр ...
... адресов ячеек памяти —весь объем памяти делится на два или несколько банков. Двойные слова с последовательными адресами располагаются в разных банках. Во время считывания информации из оперативной памяти за один цикл можно организовать параллельное извлечение информации из разных блоков, что уменьшает количество циклов ожидания. Преимущество систем с интерливингом проявляется при ...





... подобные. Также интересно будет следить за борьбой Intel и AMD на рынке процессоров Изучение цен и спроса на оперативную память за последний год Исследование проводилось в городе Владивостоке. В качестве объектов исследования были выбраны модули оперативной памяти, имеющиеся в свободной продаже на рынке. Было определено пять основных типов RAM микросхем (SDRAM DIMM 32 MB <PC-100>, ...


... . Это нормально, если на стороне клиента используется маломощная рабочая станция. Но если клиентский компьютер обладает достаточной мощностью, то часто возникает желание возложить на него больше функций управления базами данных, разгрузив сервер, который является узким местом всей системы. Что собственно говоря и обусловило появление двух- и трехуровневых (звенных) систем. 3.2 Два уровня или ...
0 комментариев