Навигация
Назначение и основные характеристики технологий ADO, MIDAS, MTS, CORBA
102741
знак
6
таблиц
12
изображений
1.2.2 Назначение и основные характеристики технологий ADO, MIDAS, MTS, CORBA
Общие понятия. Отличие «тонкого» клиента от «толстого». «Тонким» клиентом обычно называют пользовательское приложение, не содержащее никакой функциональности, и предназначенное только для ввода/вывода информации. Вся обработка данных производится на сервере БД, либо на сервере приложений. Зачастую, такой клиент изначально не содержит вообще никаких возможностей, а подгружает дополнительные модули с сервера, по мере необходимости. Обычно, в качестве «тонкого» клиента, выступают Web броузер + HTML/ASP/Java. «Толстый» клиент содержит всю функциональность и интерфейсную часть в себе, и при любом изменении, требует замены у всех пользователей.
Технология ADO
ADO (Microsoft ActiveX Data Objects) это технология стандартного обращения к реляционным данным от Microsoft. ADO представляет собой высокоуровневый программный интерфейс для доступа к OLE DB-интерфейсам. Он позволяет манипулировать данными с помощью любых OLE DB-провайдеров, как входящих в состав MDAC(Microsoft Data Access Components) некоторых других продуктов Microsoft, так и произведенных сторонними производителями. ADO содержит набор объектов, используемых для соединения с источником данных, для чтения, добавления, удаления и модификации данных.
DAO, ADO, RDO... Все это похоже на какую-то игру слов, где присутствует два ключевых понятия: данные и объекты. (Data Access Objects — объекты доступа к данным, ActiveX Data Objects — ActiveX-объекты работы с данными, Remote Data Objects — объекты удаленных данных.) На самом же деле речь здесь идет о разных технологиях доступа к данным (см. врезку «Сравнение ADO, DAO и RDO»), которые имеют не только разные внутренние механизмы, но и, что, может быть, гораздо важнее для прикладного программиста, разные перспективы на будущее.
DAO и RDO известны уже достаточно давно, и появление двух разных механизмов было связано с необходимостью оптимизации решения двух отдельных задач: доступа к локальным и удаленным базам данных соответственно. Однако естественное развитие вычислительных систем привело к необходимости создания единого механизма, который обеспечил бы единый подход при работе с БД различных классов.
В результате несколько лет назад Microsoft предложила в качестве единого интерфейса для доступа к локальным и удаленным данным новую технологию ADO, которая сегодня является частью архитектуры Microsoft Universal Data Access (MUDA).
ADO Extension for DDL and Security (ADOX) применяется для решения различных задач, недоступных с помощью обычных объектов ADO. Например, используя объекты ADOX, можно извлекать метаданные из баз данных и, следовательно, переносить структуру данных из одной базы данных в другую (в том числе и иного типа). Вторая возможность, предоставляемая этим расширением, — манипулирование сведениями о безопасности. Например, с помощью ADOX можно получать информацию о пользователях базы данных и группах пользователей, а также создавать новых пользователей и группы. ADOX расширяет объектную модель ADO десятью новыми объектами, которые можно использовать как отдельно, так и вместе с другими объектами ADO, в частности можно применять объект ADO Connection для соединения с источником данных и извлекать метаданные из него.
Прежде чем углубляться в детали объектов ADOX, поговорим о том, что такое метаданные. В общем случае метаданные представляют собой описания объектов базы данных (таблиц, полей, индексов, ключей, представлений, хранимых процедур и прочих объектов). В подавляющем большинстве современных СУБД метаданные определяются с помощью языка SQL (Structured Query Language). До появления ADOX единственным программным способом извлечения метаданных из источников данных с помощью ADO был метод OpenSchema объекта ADO Connection. Для создания новых объектов в базе данных применялся язык Data Definition Language (DDL) — подмножество языка SQL, а также объект ADO Command.
Многоуровневые приложения
Разработка распределенных корпоративных систем доступа к данным – одна из наиболее высокотехнологических и динамично развивающихся областей современной индустрии ПО. Именно здесь сосредоточены усилия разработчиков прикладного ПО.
Мощные серверы должны обеспечивать бесперебойный доступ к данным сотен клиентов одновременно. При этом клиентское ПО установлено на разных аппаратных платформах и работает под управлением разных ОС. Пользователи могут находится в корпоративной сети, обращаться к серверу через Internet, intranet или по радиоканалу.
Для создания распределенных систем разработаны подходы на основе ряда технологических решений. Используются технологии COM, OLEnterprise, сокеты TCP\IP, Microsoft Transaction Server, CORBA.
Для работы с корпоративными БД используются многоуровневые приложения, т.к. эффективное взаимодействие с БД многих пользователей может обеспечить только ПО промежуточного уровня. Серверы приложений решают задачи управления запросами клиентов и результатами запросов, разграничения доступа, сохранения целостности данных т.д. Причем и в этой сфере существуют готовые решения на основе вышеперечисленных технологий.
Создание средств разработки корпоративных систем доступа к данным является основным направлением деятельности фирмы Inprise.
В Delphi можно создавать приложения для распределенных систем на основе всех перечисленных подходов. Для этого предназначена специальная технология MIDAS (Multi-tired Distributed Application Service) – Службы многоуровневых распределенных приложений. Она обеспечивает создание приложений для распределенных систем баз данных на основе единого подхода.
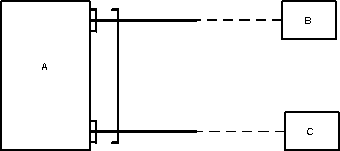
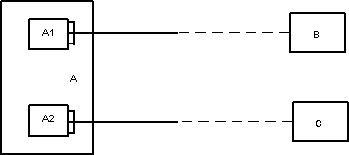
Многоуровневые приложения представляют собой распределенные системы удаленного доступа к данным, которые состоят как минимум их трех логических уровней.
1. Сервер БД, который обеспечивает функционирование используемой приложением БД и непосредственную обработку запросов пользователей. Для создания серверов БД имеются готовые решения, предоставляемые целым рядом компаний. В зависимости от назначения БД, объема, решаемых задач всегда можно подобрать наиболее подходящий вариант.
2. сервер приложений, который составляет так называемое ПО промежуточного слоя. Обычно это специально разработанная программа, которая обеспечивает взаимодействие клиентов с сервером БД. В этой области всегда найдутся проблемы, которые необходимо решать: конфликты доступа к данным, регистрация, управление транзакциями и т.д.поэтому сервер приложений предоставляет минимально необходимый промежуточный уровень. Обычно он называется брокером данных. Серьезные многоуровневые приложения имеют несколько уровней ПО промежуточного слоя. Из наиболее распространенных решаемых задач можно выделить регистрацию пользователей и разграничение доступа, защита от несанкционированного доступа, управление блокировками. Часто промежуточный уровень должен обеспечить доступ к БД клиентов с разными программными и аппаратными платформами.
3. Совокупность клиентских программ или клиентский уровень приложения. В рассматриваемом случае используются «тонкие» (или «слабые») клиенты, которые, в отличие от аналогичных программ в архитектуре клиент/сервер, выполняют только минимальные функции по отображению данных и передаче запросов серверу, а результатов – обратно.
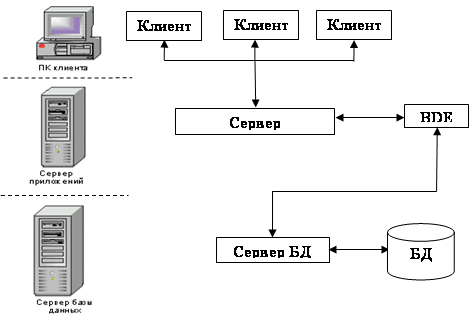
Рис.5. Структура многоуровнего приложения
Технология MIDAS позволила вынести BDE в отдельный уровень – сервер приложений, который обеспечивает взаимодействие множества клиентов с сервером БД. Это стало возможным за счет применения удаленных модулей данных.
Технология MIDAS
Таким образом, мы подошли к важнейшей особенности настоящих многоуровневых приложений – ПО, обеспечивающее взаимодействие клиентов с БД (в нашем случае это BDE), которое требует установки только на одном компьютере – компьютере сервера приложений (рис. 5). В результате клиентские программы избавляются от лишнего программного кода и становятся чрезвычайно простыми в установке (появился даже новый термин – нуль-конфигурация «тонкого» клиента).
MIDAS - это технология Borland для создания многоуровневых приложений баз данных. Применение данной архитектуры позволяет быстро разрабатывать простые в сопровождении и установке, надежные, распределенные БД. Трехуровневое приложение баз данных содержит несколько компонентов (слоев):
а) Слой БД. Хранит данные. Выполняет функции хранения информации, обеспечения целостности и непротиворечивости данных. Пример -локальные (dBase, Paradox) и серверные БД (Oracle, Sybase, MS SQL), текстовые файлы и т.д.
б) Слой бизнес логики (сервер приложений) - это программа, обеспечивающая доступ клиентов к информации. На этом слое вводится понятие сервиса, как некоей услуги, поставляемой клиенту (например, получение данных об остатке денег на счете, как частный случай из реляционной БД). В этом слое реализуются правила и алгоритмы обработки информации, отражающие поведение реального моделируемого объекта (бизнес правила). Например, проверка остатка денег на не отрицательность, перевод денег со счета на счет.
в) Презентационный слой (тонкий клиент). Задача этого слоя, используя сервисы слоя бизнес логики, предоставлять пользователям запрошенную информацию в форме удобной и приятной во всех отношениях. Может быть выполнен в виде традиционного exe файла или в качестве тонкого клиента можно использовать Web броузер.
Применение данной схемы позволяет создать клиентское приложение, которое практически не требует настройки и сопровождения, вся логика работы с БД сосредоточена в среднем слое (сервере приложений). Соответственно при доработке алгоритмов доступа к БД необходимо лишь переустановить сервер приложений.
MIDAS предназначен для обеспечения связи между слоем бизнес логики и презентационным слоем. Он позволяет организовать взаимодействие тонкого клиента с сервером приложений. При этом сервер приложений взаимодействует с реляционной БД (чаще всего данные хранятся именно в этой форме) как и обычные приложения работы с БД, разработанные в Delphi.
Тонкий клиент для конечного пользователя ничем не отличается от обычного (толстого) клиента БД. Разница в том, что толстый клиент через BDE, ADO, компоненты прямого доступа к серверам БД и другие библиотеки работает с БД, а тонкий клиент взаимодействует с сервером приложений, используя MIDAS. Сервер приложений скрывает от клиента детали доступа и обработки БД. На компьютере с тонким клиентом не нужно устанавливать и настраивать BDE, ADO, клиентскую часть сервера БД. Необходимо лишь иметь небольшие по объему dll, которые легко переносить вместе с exe файлом тонкого клиента. В качестве тонкого клиента может использоваться и Web браузер.
В основе MIDAS лежит использование использование объектной модели COM. MIDAS обеспечивает функционирование в рамках единой службы нескольких технологий удаленного доступа к данным, предоставляя единый стандарт обмена данными между сервером и клиентами.
· DCOM – распределенный COM расширение базовой технологии COM, позволяющей клиенту использовать свойства и методы удаленных объектов на сервере. Элементы COM установлены в Windows NT, Windows 98, Windows 95 требует специальной интсалляции допаолнительного ПО.
· Microsoft Transaction Server (MTS) – надстройка над базовой технологией COM, обеспечивающая дополнительные функции при взаимодействии клиента и сервера. Это управление транзакциями, обеспечение безопасности данных. MTS доступна в ОС Windows NT, Windows 98.
· Сокеты являются популярным программным интерфейсом доступа к стеку сетевых протоколов и позволяют создавать распределенные приложения для большинства современных систем, включая соединение через Internet.
· OLEnterprise – разработанное фирмой Borland расширение объектной модели COM, обеспечивающее ряд дополнительных возможностей. С его помощью можно связывать объекты, созданные на разных языках программирования. Соответствующее ПО устанавливается на сервере и клиенте.
· CORBA (Common Object Request Broker Arhitecture – Архитектура Брокера Общих Объектных Запросов) представляет собой специально разработанный стандарт и ПО, обеспечивающее взаимодествие объектов, манипулирующих данными в разных ОС. Основу архитектура составляет ORB (Object Request Broker – Брокер Объектных Запросов), обеспечивающий взаимодействие сервера приложений и клиентов.
В соответствии с технологией MIDAS, многоуровневое приложение должно иметь три составные части:
· Сервер приложений, который должен содержать в качестве основы удаленный модуль данных;
· Клиент, взаимодествие которого с сервером обеспечено спецмальными компонентами и динамической библиотекой DBClient.DLL.
· Брокер данных, который обеспечивает передачу пакетов данных на основе интерфейса IProvider.
Технология MTS
Создавая в Delphi многоуровневые приложения на основе DCOM, разработчики могут расширить их возможности за счет использования дополнительных функций, предоставляемых специализированной системной службой Microsoft Transaction Server (MTS).
MTS может работать с ОС Windows NT, Windows 98. MTS позволяет достаточно гибко управлять режимами выполнения транзакций в системе и поддерживает двухфазное завершение транзакций. Одним из существенных недостатков схемы управления транзакциями СОМ является необходимость явной передачи контекста транзакции в качестве -аргумента при вызове удаленных методов. Такая схема не является ни эффективной, ни гарантирующей от ошибок, особенно при вовлечении в транзакцию большого количества объектов.
Использование MTS дает серверу ряд дополнительных полезных функций:
· При выполнении запросов поддерживаются транзакции;
· Работая с сервером, несколько клиентов могут использовать для доступа к данным одно соединение. Так реализуется совместное использованиеи ресурсов БД.
· Обеспечивая дополнительное разграничение доступа клиентов к интерфейсам.
Для использования возможностей MTS необходимо только иметь установленные динамические библиотеки этой службы на компьютере сервера приложений.
COM+ является слиянием COM- и MTS- моделей программирования, таким образом справедлива формула:
COM + MTS = COM+
Базовая программная модель и того, и другого являются идентичными: разрабатываются компоненты "в процессе", в них выставляются интерфейсы, для обеспечения автоматизации реализуется IDispatch, реализуется код для регистрации, т.е. в рамках новой парадигмы нужно делать то же, что делалось и ранее.
Однако в дополнение к этому появились новые сервисы, значительно расширяющие возможности приложений.
COM был создан как компонентная технология уровня изолированной рабочей станции.
Потом, с реализацией распределенного COM в NT4 (DCOM), эта технология получила развитие в направлении поддержки удаленных обращений к компонентам. MTS создавался для обеспечения работы серверных компонент и устранения некоторых недостатков DCOM. COM+ появился для унификации и объединения COM, DCOM и MTS в согласованную технологию, понятную и удобную для реализации приложений корпоративного уровня.
Технология CORBA
CORBA (Common Request Broker Architecture) — архитектура для построения распределенных объектных приложений. Была предложена некоммерческой организацией — консорциумом OMG (Object Management Group), состоящей из нескольких сотен (!) ведущих компаний из отрасли разработки программного обеспечения (включая таких гигантов, как Microsoft и Borland/Inprise). Первая спецификация CORBA появилась еще в далеком 1991 году.
Целью разработчиков CORBA было создание механизмов межплатформенного взаимодействия приложений в распределенных системах. Можно поразиться дальновидности OMG — ведь в середине — конце 80-х годов XX века распределенные системы не играли той впечатляющей роли в компьютерной индустрии, как сейчас. Кроме того, расширение экспансии Intel и Microsoft ставило под угрозу само наличие разнообразия аппаратно-программных платформ. Тем не менее, в сложившейся обстановке работы были продолжены, причем результаты были настолько успешны, что даже всемогущий Microsoft счел нужным присоединиться к консорциуму разработчиков, чтобы держать руку на пульсе развития новой перспективной технологии.
Как и DCOM, CORBA основывается на коммуникации типа клиент-сервер. Запрашивая сервис, клиент вызывает метод, реализуемый удаленным объектом, действующим в роли сервера. Сервис, предоставляемый объектом, инкапсулируется с помощью интерфейса, определенного на языке IDL. Именно собственный язык IDL является одной из изюминок CORBA. Вообще, существуют три различных языка описаний под одним и тем же названием: OMG IDL (очевидно, используется в CORBA), Microsoft IDL (разработан для технологии DCOM, но в силу двоичного представления объектов не играет в этой технологии ключевой роли) и OSF IDL. Однако, по сравнению с DCOM, CORBA имеет ряд существенных отличий.
Технология CORBA изначально проектировалась для создания распределенных систем. В силу этого сервер объектов и клиентские программы, в отличие от COM/DCOM, в технологии CORBA, как правило, располагаются на разных машинах. Взаимодействие между клиентом и сервером происходит следующим образом. В процессе клиента имеется объект-посредник, именуемый stub (или Client-Side Stab). Он является полномочным представителем сервера и исполняет функции, во многом сходные с функциями объекта Proxy в технологии DCOM. Именно к stub при помощи интерфейса объекта обращается программа-клиент так, как будто stub и являет собой объект. Далее stub перенаправляет запрос клиента к особому объекту, который действует также на машине клиента. Этот объект называется ORB (Object Required Broker, брокер объектных запросов). Получив запрос, ORB формирует широковещательное сообщение во внешнюю сеть. На это сообщение откликается один из объектов Smart Agent, который функционирует на одном из компьютеров сетевого окружения (локальная сеть или Интернет). Smart Agent знает, где расположены соответствующие серверы объектов (фактически это как бы виртуальный сетевой каталог, где зарегистрированы некоторые серверы), и перенаправляет запрос на нужный сервер. На сервере пакет запроса принимает еще один объект ORB, который дешифрует запрос и пересылает его следующему объекту — BOA (Basic Object Adapter, базовый адаптер объектов). Роль объекта BOA заключается в фильтрации, кэшировании запросов и, соответственно, разграничении доступа к объекту сервера. Если запрос пропущен BOA, то он попадает в объект сервера skeleton. При этом в адресном пространстве сервера создается требуемый объект, skeleton помещает аргументы вызова в стек объекта и реализует собственно вызов. Используя объект BOA, skeleton также регистрирует созданный серверный CORBA-объект с помощью Smart Agent, а также сообщает о доступности, факте создания и о готовности объекта принимать запросы клиента. Далее следует обратная связь по описанной цепочке объектов (рис. 4.6).
 <>
<>
Рис. 4.6. Технология CORBA
Как видно из описания, CORBA реализует собой типичную многозвенную (здесь — трехзвенную) архитектуру. В роли Middleware — программного обеспечения промежуточного слоя — здесь выступает объект Smart Agent. Обычно при практической реализации программа, выполняющая Действия Smart Agent, устанавливается на выделенную машину в корпоративной сети или на несколько машин в сети Интернет. При создании серверов они регистрируются на ДОСТУПНЫХ Smart Agent.
ТЕМА 1.3. ВВЕДЕНИЕ В РАБОТУ С УДАЛЕННЫМИ БАЗАМИ ДАННЫХ
Основные понятия. СУБД — Система Управления Базами Данных (DBMS — DataBase Management System). Программа, либо комплекс программ, предназначенных для полнофункциональной работы с данными. Как правило, включает в себя инструменты для создания и изменения структуры хранения наборов данных, а также средства доступа к хранимым данным, с возможностью их чтения, добавления, изменения и удаления. При этом, у большинства СУБД имеется собственный встроенный язык (возможно не один) для работы с данными. Сама база данных (БД) обычно находится просто в файлах закрытого, либо открытого формата.
Отличие «серверной» и «настольной» СУБД. Под настольной (desktop) обычно подразумевается СУБД, которая всегда запускается на компьютере пользователя, хотя сама база данных может находиться в другом месте. В результате несколько копий СУБД могут обращаться к одной базе данных. Серверная (server) СУБД, как правило, запускается в на той же машине (сервере баз данных), где находятся файлы БД. Непосредственно к базе данных обращается лишь один экземпляр СУБД. Пользовательские приложения общаются только с этой СУБД через ее API, независимо от того, работают они на той же машине или на другой. Для многопользовательских баз данных более эффективным и надежным вариантом является серверная СУБД. В ней гораздо быстрее происходит доступ к данным, и значительно проще решаются конфликты между разными пользователями.
Понятие реляционной базы данных. Реляционная (relational) БД отличается способом представления информации, находящейся в ней. Данные в такой базе хранятся в плоских таблицах. Каждая таблица имеет собственный, заранее определенный набор именованных колонок (полей). Поля таблицы обычно соответствуют атрибутам сущностей, которые необходимо хранить в базе. Количество строк (записей) в таблице неограниченно, и каждая запись соответствует отдельной сущности. Каждая таблица должна иметь первичный ключ (ПК) — поле или набор полей, содержимое которых однозначно определяет запись в таблице и отличает ее от других. Связь между двумя таблицами обычно образуется при добавлении в первую таблицу поля, содержащего значение первичного ключа второй таблицы. Реляционные СУБД (РСУБД) предоставляют средства для всевозможных пересечений и объединений любых таблиц, отбора записей по разнообразным условиям, группировки и сортировки результатов.
Реляционная база данных сочетает наглядность представления информации с простотой (относительной) реализации своей концепции и является наиболее популярной структурой для хранения данных на сегодняшний день.
Хранение реляционной БД. Данные в реляционной БД хранятся в плоских таблицах. Каждая таблица имеет собственный, заранее определенный набор именованных колонок (полей). Поля таблицы обычно соответствуют атрибутам сущностей, которые необходимо хранить в базе. Количество строк (записей) в таблице неограниченно, и каждая запись соответствует отдельной сущности.
Отличие записей от друг друга. Записи в таблице отличаются только содержимым их полей. Две записи, в которых все поля одинаковы, считаются идентичными. Каждая таблица должна иметь первичный ключ (ПК) — поле или набор полей, содержимое которых однозначно определяет запись в таблице и отличает ее от других. Отсутствие первичного ключа и наличие идентичных записей в таблице обычно возможно, но крайне нежелательно.
Связывание таблиц между собой. Простейшая связь между двумя таблицами образуется при добавлении в первую таблицу поля, содержащего значение первичного ключа второй таблицы. В общем случае, реляционные БД предоставляют очень гибкий механизм для всевозможных пересечений и объединений любых таблиц, с разнообразными условиями. Для описания множеств, получающихся при пересечении и объединении таблиц, используется специальный математический аппарат — реляционная алгебра.
Понятие «нормализация». Упорядочивание модели БД. Грубо говоря, нормализацией называют процесс выявления отдельных независимых сущностей и вынесения их в отдельные таблицы. При этом, связи с такими таблицами, обычно организуют по их первичному ключу. В результате нормализации, увеличивается гибкость работы с БД. Также, уменьшается содержание дублирующей информации в БД, а это сильно понижает вероятность возникновения ошибок.
Имеет ли значение порядковый номер записи в таблице. Нет. Реляционная алгебра оперирует множествами, в которых порядковый номер элемента не несет никакой смысловой нагрузки. Записи отличатся только содержимым их полей. Две записи, в которых все поля одинаковы, будут абсолютно идентичны в реляционной БД.
Понятие SQL-сервер. Сервер для управления реляционными БД обычно называют SQL-сервером. SQL (Structured Query Language — язык структурированных запросов) является стандартным языком для работы с реляционными БД. Кроме стандартных реляционных операций, этот язык предоставляет возможности для изменений структуры таблиц. Различные варианты SQL используются во всех, как серверных, так и в настольных реляционных СУБД.
Понятие пост-реляционной базы данных. Пост-реляционными, часто называют многомерные базы данных. Данные в многомерных базах, представляются в виде разреженных многомерных массивов, а не плоских таблиц, как в реляционных базах. Для определенных задач, многомерные базы могут давать значительный выигрыш в быстродействии, по сравнению с реляционными. Наиболее известные многомерные СУБД:
· Cache
· Teradata
Разновидности СУБД. Кроме реляционных, объектно-ориентированных и многомерных СУБД, также давно известны иерархические и сетевые базы данных. Данные и связи между ними, в иерархических БД представлены в виде деревьев. Для некоторых задач, такая форма представления данных может оказаться гораздо более эффективной, чем любая другая. В сетевых базах, данные могут быть связаны произвольным образом, но эти связи должны создаваться предварительно, вместе со структурой данных. По сравнению с реляционными БД, сетевая модель может давать выигрыш в быстродействии, при некоторой потере гибкости.
Понятие «сервер баз данных». Под сервером БД обычно подразумевается СУБД, запущенная на той же машине, где находятся файлы БД, и монопольно распоряжающаяся этими файлами. При этом, все пользовательские приложения должны работать с базой только через эту СУБД, используя ее язык запросов.
Понятие «Клиент». Клиентом к БД, обычно называют пользовательское приложение, которое общается с сервером БД. Модель работы, в которой клиент общается непосредственно с сервером, не используя промежуточных приложений, называется архитектурой клиент-сервер.
Как клиент общается с сервером. На пользовательских машинах, обычно устанавливаются специальные программы-шлюзы, которые, через сетевой протокол, обеспечивают связь с сервером БД. Через эти шлюзы, приложения передают запросы серверу и получают результаты. Часто, дополнительно устанавливается библиотека (ODBC, OLE DB и т.п.), предоставляющая приложениям API для работы с сервером БД.
Назначение сервера приложений. Сервер приложений может использоваться для многих целей. Как правило, сервер приложений находится на отдельной машине. На него можно переложить всю функциональность программы, оставив клиенту только интерфейсную часть. Это разгрузит клиента и сервер БД от вычислений. Также, при большом количестве пользователей, можно использовать несколько серверов приложений для распределения нагрузки. А для ускорения доступа к часто используемым таблицам, их обычно кэшируют на сервере приложений.
Объектно-ориентированная СУБД. В объектно-ориентированных БД (ООБД), данные представлены в виде объектов различных классов. Как правило, имеются возможности создавать новые классы, наследовать их от уже имеющихся, задавать произвольные атрибуты и методы для классов. Для доступа к объектам, в каждой ООБД обычно предусматривается свой собственный язык, либо расширение другого языка. Пока еще ООБД недостаточно развиты и не представляют серьезной конкуренции SQL-серверам, хотя и выглядят более предпочтительными для разработчиков. Производители SQL-серверов тоже, в свою очередь, иногда делают попытки соорудить над реляционным ядром сервера объектно-ориентированную надстройку.
Достаточно распространены следующие ООБД: Cache, FastObjects, GemStone/S, Jasmine, ObjectStore, Objectivity/DB, Versant.
Что можно делать при помощи SQL. SQL (Structured Query Language — язык структурированных запросов) является стандартным языком для работы с реляционными БД. Разделяется на две основные части: DDL (Data Definition Language — язык определения данных) и DML (Data Manipulation Language — язык обработки данных). DDL предоставляет средства для создания и изменения структуры хранения данных (БД, таблиц, процедур, типов данных и т.п.). DML предназначен для чтения и изменения данных. Основные операторы DML: select — выборка, insert — вставка, update — изменение, delete — удаление. Также, с помощью SQL, часто реализован доступ к служебным функциям SQL-сервера (заведение пользователей, создание резервных копий БД и т.д.).
Зачем нужны транзакции. Во многих случаях, необходимо проведение группы операций по изменению данных таким образом, чтобы эта группа обладала свойством атомарности (либо вся целиком выполняется, либо вся целиком не выполняется). Такая группа операций называется транзакцией. В SQL-серверах существуют операторы, позволяющие обозначить начало транзакции (begin transaction), ее успешное завершение (commit transaction), либо откат транзакции (rollback transaction).
Журнал транзакций. Любые изменения данных, проведенные внутри транзакции, записываются в специальный журнал транзакций (transaction log). При откате транзакции, данные восстанавливаются в прежнем виде, а записи об изменениях удаляются из журнала транзакций.
Блокировки. При изменении данных внутри транзакции, модифицируемые записи блокируются сервером до окончания этой транзакции. Если какая-нибудь другая транзакция пытается изменить заблокированные записи, то ее выполнение останавливается, пока не будет снята блокировка, то есть, пока не завершится первая транзакция. Некоторые сервера имеют неприятную особенность блокировать данные не отдельными записями, а целыми страницами, которые могут содержать довольно много записей.
Отличие «версионников» от «блокировочников». Классические «блокировочники» не дают возможности разным транзакциям одновременно изменять одни и те же записи, блокируя их на время транзакции. В результате, при попытке изменить заблокированную запись, другая транзакция будет простаивать, пока не завершиться первая. В свою очередь, «версионники» позволяют одновременно модифицировать одни и те же записи, создавая при этом разные версии одной записи.
Почему возникает deadlock. Перекрестная блокировка (deadlock) двух транзакций возникает при изменении одних и тех же записей в разном порядке. Последовательность действий, приводящая к перекрестной блокировке:
1. Транзакция A изменяет запись X. Заблокирована X.
2. Транзакция B изменяет запись Y. Заблокирована Y.
3. Транзакция A пытается изменить запись Y. Остановлена A.
4. Транзакция B пытается изменить запись X. Остановлена B.
Сервер определяет перекрестную блокировку и откатывает одну из транзакций, возвращая ошибку соответствующему соединению. Аминь. Чтобы не выводить ошибку пользователю, обломанное соединение должно молча повторить транзакцию.
Понятие «индексы». Для ускорения операций выборки данных. При поиске полей с определенным значением, сервер вынужден перебирать все записи в таблице. В этом случае, время поиска линейно зависит от размера таблицы. Индекс по полю, обычно представляющий собой бинарное дерево, дает возможность резко сократить время поиска, превратив эту зависимость в логарифмическую. Однако, наличие индексов в таблице, замедляет операции модификации данных.
Необходимость первичного ключа в таблице. Первичный ключ (ПК) — поле или набор полей, содержимое которых однозначно определяет запись в таблице и отличает ее от других. Служит для однозначной идентификации записей и в таблице может быть только один. Обычно, при определении первичного ключа, по нему автоматически создается уникальный индекс.
Что такое триггер. Триггер — процедура, выполняемая сервером автоматически при модификации данных в таблице. В основном, триггеры используются для поддержания целостности дублирующей информации в денормализованной БД.
Можно ли использовать свою функцию в SQL-запросе. Можно, практически во всех современных SQL-серверах. Различия только в синтаксисе определения и вызова функции. Кроме того, некоторые сервера позволяют использовать функции, написанные на других языках (не SQL).
Представление (view) — это запрос на выборку, хранящийся на сервере, как отдельный объект. Так как, результат этого запроса можно рассматривать в качестве таблицы, представление допускается использовать в других запросах, также как любую обычную таблицу.
Материализованное представление хранится на сервере в виде таблицы, которая автоматически обновляется при изменении данных, имеющих отношение к этому представлению.
Хранимые процедуры (SP — Stored Procedure) представляют собой последовательность команд на расширениях SQL, либо на других языках, поддерживаемых сервером. Могут принимать параметры и возвращать значение заданного типа. Часто используются для выполнения операций, напрямую связанных с логикой задачи, для которой проектировалась БД. Иногда, используются вместе с представлениями, для обеспечения безопасности БД (все изменения через SP, все выборки через view).
Типы данных есть в SQL-сервере. Обычно, для полей в таблицах могут использоваться только самые простые типы: числа (целые и дробные), строки (сильно ограниченные по длине), дата (и время), бинарные данные большого размера (для текста, графики и т.п.). В некоторых серверах допускается использование массивов и самодельных структур.
Необходимость внешнего ключа. Внешний ключ (FK — Foreign Key) используется для создания жесткой связи (многие к одному) между двумя таблицами. Внешний ключ задается только в том случае, если в первой таблице есть поле, содержащее значение первичного ключа из второй таблицы. При изменении значения первичного ключа во второй таблице, могут быть изменены все соответствующие значения связанного поля в первой таблице. При удалении записи с определенным первичным ключом из второй таблице, могут быть удалены все записи с соответствующим значением связанного поля в первой таблице. Обычно, при определении внешнего ключа, по нему автоматически создается индекс, который используется в запросах при объединении этих двух таблиц.
Репликацией обычно называют процесс синхронизации данных между несколькими БД. Наиболее развитые SQL-сервера содержат встроенные средства репликации. Для остальных могут быть использованы продукты сторонних фирм. Одностороняя репликация подразумевает изменение данных только в одной базе, с последующей передачей изменений на остальные. Соответственно, довольно проста в реализации и надежна в работе. Двустороняя репликация предоставляет гораздо более мощный инструмент распределенной работы между SQL-серверами. Плата за это — сложность и большая вероятность конфликтов при работе.
Типы SQL серверов и их особенности
Какой тип сервера лучше выбрать? На какой хватит денег.:) Вообще-то это может сильно зависеть от постановки задачи, количества пользователей и прихотей заказчика. Ниже приведена таблица самых распространенных SQL-серверов в порядке (примерно) убывания их возможностей:
| Сервер | Достоинства | Недостатки |
| IBM DB2 Universal Database | Самый навороченный язык запросов, лучший оптимизатор, возможность писать функции на других языках. | Высокая стоимость. |
| Oracle Database | Великое множество дополнительных возможностей. Версионный сервер. | Очень высокая стоимость сервера и поддержки. |
| Microsoft SQL Server | Быстро развивающийся продукт, уже вплотную приближающийся к своим более развитым конкурентам. Средняя стоимость. | Существует только для одной платформы (Win32). |
| IBM Informix Dynamic Server | Довольно развитый быстрый сервер. | — |
| Sybase Adaptive Server Enterprise | Достаточно развитый сервер. Средняя стоимость. | — |
| Sybase Adaptive Server Anywhere | Существует под множество платформ, включая самые экзотичные. Низкая стоимость. | — |
| Borland InterBase | Приличный набор возможностей. Версионный сервер. Бесплатный. | Относительно медленно работает. |
| PostgreSQL | Поддерживает историческую модель. Возможность создавать свои типы данных. Бесплатный. | — |
| MySQL | Быстро работает на простых запросах. Бесплатный. | Очень бедный язык запросов. Мало дополнительных возможностей. |
Похожие работы
... на завершающей проверочной стадии проектирования БД, мы начнем обсуждение вопросов проектирования с рассмотрения причин, которые заставили Кодда создать основы теории нормализации. Универсальное отношение Предположим, что проектирование базы данных "Питание" (рис. 3.2) начинается с выявления атрибутов и подбора данных, образец которых (часть блюд изготовленных и реализованных 1/9/94 г.) показан ...

... позволяют на любом этапе разработки внести изменения в базу данных и модифицировать ее структуру без ущерба для введенных ранее данных. В процессе разработки канонической модели данных предметной области для проектирования реляционной базы данных необходимо выделить информационные объекты (ИО), соответствующие требованиям нормализации данных, и определить связи между ИО с типом отношений один ...
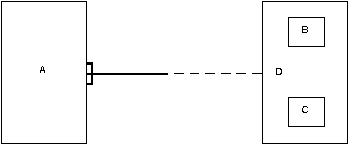
... число разнородных компонентов. В связи с наглядностью представления концептуальных схем баз данных ER-модели получили широкое распространение в системах CASE, поддерживающих автоматизированное проектирование реляционных баз данных. Среди множества разновидностей ER-моделей одна из наиболее развитых применяется в системе CASE фирмы ORACLE. Ее мы и рассмотрим. Более точно, мы сосредоточимся на ...
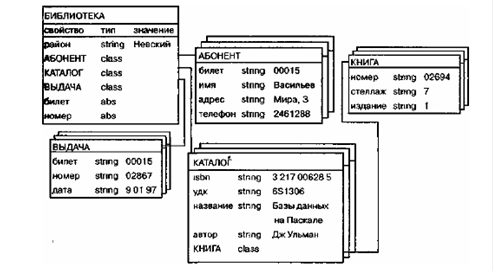
... аномалии связаны с избыточностью (дублированием) данных в БД. Определить дублирование данных в БД, а значит и предсказать возможность возникновения аномалий обновления можно на этапе проектирования структуры базы данных. Одним из наиболее алгоритмически и понятийно простых методов устранения избыточности хранения данных является метод нормальных форм, который основан на анализе функциональных ...
0 комментариев