Навигация
4. Разработка сканера
1) Определяем лексемы языка
Табл.1. Лексемы языка
| Обозначение лексемы | Смысл лексемы |
| конст_10 | Десятичная константа |
| конст_16 | Шестнадцатеричная константа (префикс &H) |
| конст_2 | Двоичная константа (префикс &B) |
| ид_р | Идентификатор (integer, double или string) |
| sin | Синус вещественного числа |
| left | Функция работы со строками |
| not | Логическое «НЕ» |
| and | Логическое «И» |
| or | Логическое «ИЛИ» |
| xor | Исключающее «ИЛИ» |
| разделитель | Пробел |
| + | Арифметическая операция сложения |
| - | Арифметическая операция вычитания |
| * | Арифметическая операция умножения |
| mod | Арифметическая операция целочисленное деление |
| ^ | Арифметическая операция возведения в степень |
| оо | Операция отношения (результат – логический) |
| ( | Открывающая скобка |
| ) | Закрывающая скобка |
2) Разрабатываем базу данных сканера
| Табл.2. Таблица одно-литерных | Табл.3. Таблица классов литер | ||||||
| терминальных символов | |||||||
| ТТС1 | KTL | ||||||
| «а» … «z» «A» «C» … «K» «M» … «Z» | Буквы | б | б | 0 | |||
| «B» | 1 | ||||||
| д | 2 | ||||||
| н | 3 | ||||||
| р | 4 | ||||||
| «+» | 5 | ||||||
| «–» | 6 | ||||||
| «*» | 7 | ||||||
| «^» | 8 | ||||||
| «H» | Шестнадцатеричный префикс | «H» | «=» | 9 | |||
| «B» | Двоичный префикс | «B» | «<» | 10 | |||
| «0» «1» | Двоичные цифры | д | «>» | 11 | |||
| «#» | 12 | ||||||
| «2» … «9» | Недвоичные цифры | н | «%» | 13 | |||
| «$» | 14 | ||||||
| «(» | 15 | ||||||
| «» | Разделитель (пробел) | р | «)» | 16 | |||
| «+» | Сложение | «+» | «.» | 17 | |||
| «–» | Вычитание | «–» | «ы» | 18 | |||
| «*» | Умножение | «*» | «H» | 19 | |||
| «^» | Степень | «^» | Табл.4. Таблица типов лексем | ||||
| «<» | Меньше | «<» | |||||
| «>» | Больше | «>» | TLE | ||||
| «=» | Равно | «=» | конст_10 | 0 | |||
| «#» | Суффикс double | «#» | конст_16 | 1 | |||
| «%» | Суффикс integer | «% | конст_2 | 2 | |||
| «$» | Суффикс string | «$» | ид_р | 3 | |||
| «(» | Открывающая скобка | «(» | sin | 4 | |||
| «)» | Закрывающая скобка | «)» | left | 5 | |||
| «.» | Точка | «.» | not | 6 | |||
| Недопустимый символ | х | and | 7 | ||||
| Конец файла | ы | or | 8 | ||||
| xor | 9 | ||||||
| Табл.5. Таблица ключевых слов | equ | 10 | |||||
| разделитель | 11 | ||||||
| ТКС | + | 12 | |||||
| sin | - | 13 | |||||
| left | * | 14 | |||||
| not | mod | 15 | |||||
| and | ^ | 16 | |||||
| or | оо | 17 | |||||
| xor | ( | 18 | |||||
| equ | ) | 19 | |||||
| mod | |||||||
Временные таблицы:
| Табл.6. Таблица идентификаторов | ||||||
| ТИ | ||||||
| Ид | описатели | адр | ||||
| тип | точка | точность | осн | |||
| Табл.7. Таблица констант | ||||||
| ТК |
| |||||
| конст | описатели | |||||
| тип | точка | точность | осн | |||
| Табл.8. Таблица операций и специальных символов | ||||||
|
| ||||||
| ТОС | ||||||
| символ | ||||||
| Табл.9. Таблица стандартных символов | ||||||
| ТСС | ||||||
| TLE | ALE | |||||
3) Каждый тип лексических единиц описываем с помощью автоматной грамматики и для каждой грамматики составляем эквивалентный ей конечный автомат.
· конст_10
S = нD1! дD1.
D1 = нD1! дD1!». «D2! е.
D2 = нD3! дD3.
D3 = нD3! дD3! е.
е = «"! «*»!» –"! «+»! «*»! «/"! «^»!»)"! «=»! «<»! «>».
|
| ||||||
 | |||||||
· конст_2
S = «&«B0.
B0 = «B» B1.
B1 = дB2.
B2 = дB2!». «B3! е.
B3 = дB4.
B4 = дB4! е.
е = «"! «*»!» –"! «+»! «*»! «/"! «^»!»)"! «=»! «<»! «>».
 | ||||||||
| ||||||||
· конст_16
S = «&«B0.
B0 = «H» H1.
H1 = дH1! нH1! «A" H1! «B» H1! «C» H1! «D» H1! «E» H1! «F» H1! е.
е = «"! «*»!» –"! «+»! «*»! «/"! «^»!»)"! «=»! «<»! «>».

· ид_р
S = бА! «B» A! «H» A.
А = бА! нА! дА! «A» A! «B» A! «C» A! «D» A! «E» A! «F» A! «H» A! «%«A2! «&«A2! «$«A2.
A2 = е.
е = «"! «*»!» –"! «+»! «*»! «/"! «^»!»)"! «=»! «<»! «>».
|
 | ||||||||||||
|
|
|
| |||||||||
· sin
S = «s» A4.
A4 = «i» A5.
A5 = «n» A6.
A6 = е4.
е4 = р! «(».
![]()
· left
S = «l» A7.
A7 = «e» A8.
A8 = «f» A9.
A9 = «t» A10.
A10 = е4.
е4 = р! «(».
![]()
![]()
![]()
![]()
· not
S = «n» A11.
A11 = «o» A12.
A12 = «t» A13.
A13 = е4.
е4 = р! «(».
![]()
· and
S = «a» A14.
A14 = «n» A15.
A15 = «d» A16.
A16 = е4.
е4 = р! «(».
![]()
· or
S = «o» A17.
A17 = «r» A18.
A18 = е4.
е4 = р! «(».

· xor
S = «x» A19.
A19 = «o» A20.
A20 = «r» A21.
A21 = е4.
е4 = р! «(».

· equ
S = «e» A22.
A22 = «q» A23.
A23 = «u» A24.
A24 = е4.
е4 = р! «(».

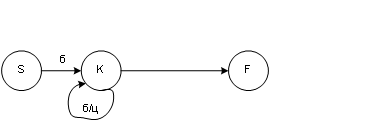
· разделитель
S = рR1.
R1 = рR1! e0
e0 – любой символ из ТТС1
| |||
 | |||
· +
S = «+«U1.
U1 = e3.
e3 = б! «B»! «H»! д! н! р! «&»! «(».

· -
S = «– «U1.
U1 = e3.
e3 = б! «B»! «H»! д! н! р! «&»! «(».

· *
S = «*«U1.
U1 = e3.
e3 = б! «B»! «H»! д! н! р! «&»! «(».

· mod
S = «mod» U1.
U1 = e3.
e3 = б! «B»! «H»! д! н! р! «&»! «(».

S = «^«U1.
U1 = e3.
e3 = б! «B»! «H»! д! н! р! «&»! «(».

· оо
S = «<«O1! «>«O2! «=«O3.
O1 = «>«O4! «=«O4! e3.
O2 = «=«O5! e3.
O4 = e3.
O5 = e3.
O3 = e3.
e3 = б! «B»! «H»! д! н! р! «&»! «(».
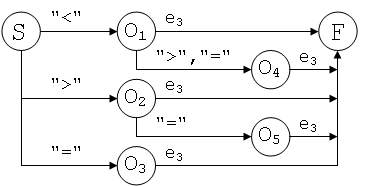
· (
S = «(«K1.
K1 = e2.
e2 = б! «B»! «H»! д! н! р! «+»!» –"! «&»! «(».

· )
S =»)«K2.
K2 = e.
е = «"! «*»!» –"! «+»! «*»! «^»!»)"! «=»! «<»! «>».

4) Описываем использованные в сканере подпрограммы:
end – Процедура окончания работы сканера
podgot – Процедура производит общую подготовку сканера к работе
tip – Процедура устанавливает тип литеры
vkl – Процедура добавляет текущую литеру в текущую лексему
cll – Процедура считывает из файла очередную литеру
zaptab – Процедура проверяет наличие текущей лексемы в таблице ключевых слов
out – Процедура заполняет основные таблицы
6) Пример работы сканера
Исходное выражение:
(sin (2*aa%-&B01)<bb#) and (2+3+4<10) xor &H0
Заполненные в результате работы сканера таблицы:
| Табл.10. Таблица идентификаторов | ||||||||
|
| ||||||||
| ТИ | ||||||||
| ид | описатели | адр | ||||||
| тип | точка | точность | осн | |||||
| Aa% | Integer | 0 | 2 | 10 | 0 | |||
| Bb# | Double | 1 | 16 | 10 | 2 | |||
| Табл.11. Таблица констант | ||||||||
| ТК |
| |||||||
| конст | Описатели | |||||||
| тип | точка | точность | осн | |||||
| 2 | Integer | 0 | 0 | 10 | ||||
| &B01 | Bin | 0 | 0 | 2 | ||||
| 2 | Integer | 0 | 0 | 10 | ||||
| 3 | Integer | 0 | 0 | 10 | ||||
| 4 | Integer | 0 | 0 | 10 | ||||
| 10 | Integer | 0 | 0 | 10 | ||||
| &H0 | Hex | 0 | 0 | 16 | ||||
| Табл.12. Таблица операций и специальных символов | ||||||||
|
| ||||||||
| ТОС | ||||||||
| Символ | ||||||||
| ( | ||||||||
| Sin | ||||||||
| ( | ||||||||
| * | ||||||||
| - | ||||||||
| ) | ||||||||
| < | ||||||||
| ) | ||||||||
| And | ||||||||
| ( | ||||||||
| + | ||||||||
| + | ||||||||
| < | ||||||||
| ) | ||||||||
| Xor | ||||||||
5. Синтаксический анализ выражения, которое использовалось в п. 2
Синтаксический анализ выполняет определенные функции:
1) выделение синтаксической конструкции
2) классификация синтаксической конструкции
3) определение синтаксической ошибки и, возможно, ее нейтрализация
4) в процессе синтаксического анализа формируется некоторая внутренняя форма представления программы.
Метод параллельного предшествования:
Отношение предшествования, используемые в методе параллельного предшествования:
< аналог отношения простого предшествования
= два символа входят в простую фразу
X>1Y, X – последний символ фразы, Y – следует за Х и находится правее соответствующей простой фразы и Y не является первым символом простой фразы.
X><Y, X – последний символ простой фразы, Y – первый символ следующей простой фразы (Y следует за X)
(>1)=(LAST) (=)
(><)=(LAST) (=) FIRST
Входная цепочка представляется в виде очереди, каждый элемент которой имеет два поля: S – символ цепочки и nx – указатель на следующий символ.
В алгоритме используются следующие обозначения:
TL – текущая литера
NTL – номер текущей литеры
PL – предыдущая литера
ST – следующая литера
SL – стек результата
ST2 – стек преобразований
ST.SIZE – размер стека
ST.PUSH – добавить в «голову» стека
ST.POP – взять (удалить) из «головы» стека
ST.RESET – очистить стек.
Блоки 2–4 производят инициализацию очереди (установка в начальное положение)
Блоки 5–6 производится проверка на наличие отношений между символами, если таковых не существует, то ошибка, иначе продолжается анализ
Блоки 7–10 осуществляется поиск простой фразы
Блоки 10–14 осуществляется редукция простой фразы на левую часть G[i]. 1 правило i из грамматики G
Блоки 15–17 осуществляется сохранение результата редукции и переход на следующий элемент
Блок 18 осуществляется проверка на окончание строки
Блоки 19–23 осуществляется проверка на окончание анализа, если анализ окончен, УСПЕХ, иначе сохранение результата и перевод в начало.
Сентенциальная форма:
1)# NOT A% MOD 5 < C# AND M% ^ 6 ^ I% – SIN (&HA09B + B# – C% * D#) + &B1 > 0 #
2)# NOT ИД MOD конст_10 о_ср ИД AND ИД^ конст_10^ ИД – FUNK (конст_16+ ИД- ИД* ИД)+ конст_2 о_ср ИД #
3)# NOT ИД_К MOD ИД_К о_ср ИД_К AND ИД_К^ИДК^ИДК–FUNK (ИД_К+ ИД_К-ИД_К*ИД_К)+ ИД_К о_ср ИД_К #
4)# NOT A_4 MOD A_4 o_cp A_4 AND A_4^ A_4^ A_4 – FUNK (A_4+ A_4 – A_4* A_4)+ A_4 o_cp A_4 #
5)# NOT A_3 MOD A_3 o_cp A_3 AND A_4^ A_^ A_3 – FUNK (A_3 + A_3 – A_3 * A_3)+ A_3 o_cp A_3 #
6)# NOT A_2 MOD A_3 o_cp A_2 AND A_4^ A_3 – FUNK (A_2 + A_2 – A_2 * A_2)+ A_2 o_cp A_2 #
7)# NOT A_2 o_cp A_1 AND A_3 – FUNK (A_1 + A_1 – A_2 * A_1)+ A_1 o_cp A_1 #
8)# NOT A_1 o_cp A_B AND A_2 – FUNK (A_B + A_1 – A_1)+ A_1 o_cp A_B #
9)# NOT A_B o_cp A_B AND A_1 – FUNK (A_B – A_1)+ A_1 o_cp A_B #
10)# NOT ЗНАК AND A_B – FUNK (A_B)+ A_1 o_cp A_B #
11)# Л_3 AND A_B – FUNK (A_B)+ A_1 o_cp A_B #
12)# Л_2 AND A_B – A_4 + A_1 o_cp A_B #
13)# Л_2 AND A_B – A_3 + A_1 o_cp A_B #
14)# Л_2 AND A_B – A_2 + A_1 o_cp A_B #
15)# Л_2 AND A_B – A_1 + A_1 o_cp A_B #
16)# Л_2 AND A_B + A_1 o_cp A_B #
17)# Л_2 AND A_B o_cp A_B #
18)# Л_2 AND ЗНАК #
19) # Л_2 AND Л_3
20) # Л_2 #
21) # Л_1 #
22) # Л_B #
23) #ВЫРАЖЕНИЕ#
Простые фразы:
1) A%, 5, C#, M%, 6, I%, SIN, &HA09B, B#, C%, D#, &B1, >, 0
2) ИД, конст_10, ИД, ИД, конст_10, ИД, конст_16, ИД, ИД, ИД, конст_2, конст_10
3) ИД_К, ИД_К, ИД_К, ИД_К, ИД_К, ИД_К, ИД_К, ИД_К, ИД_К, ИД_К, ИД_К, ИД_К
4) A_4, A_4, A_4, A_4, A_4
5) A_3, A_3, A_4^ A_3, A_3, A_3, A_3, A_3, A_3, A_3
6) A_2 MOD A_3, A_2, A_4^ A_3, A_2, A_2, A_2, A_2, A_2
Похожие работы



... 78 IsNumeric 19 2 ( 22 77 A 21 1 ) 23 78 <> 9 67 0 20 3 and 18 1 A 21 1 > 9 66 0 20 3 ) 23 78 Then 11 11 A 21 1 = 1 65 B 21 2 EndIf 11 11 Text 14 14 . 6 74 Text 16 16 = 1 65 A 21 1 End 10 10 Sub 10 10 Отладка формальной грамматики Отладка грамматики – это процесс преобразования грамматики к виду, удовлетворяющему ...
я правилами вывода, а лишь служат для отражения семантической и синтаксической стороны грамматики. Для наглядного изображения работы программы представлено дерево функционального вызова (рис 1). На нём можно проследить принцип рекурсивного спуска -основной принцип, заложенный в обработку. Он заключается в прохождении дерева от крайней левой до крайней правой вершины дерева. Кроме того, для ...
... и внешнем виде, освобождая время для продуктивной творческой деятельности. Главное преимущество Web-технологий в современных условиях заключается в их простоте и как следствие в повышении эффективности их применения. 2.1. Язык гипертекстовой разметки HTML Популярность Internet во многом вызвана появлением World Wide Web (WWW), так как это первая сетевая технология, которая предоставила ...
... контакты", "Многоязычие в социологическом аспекте". Их исследованием занимаются социолингвистика (социальная лингвистика), возникшая на стыке языкознания и социологии, а также этнолингвистика, этнография речи, стилистика, риторика, прагматика, теория языкового общения, теория массовой коммуникации и т.д. Язык выполняет в обществе следующие социальные функции: коммуникативная / иформативная ( ...
0 комментариев