Навигация
3.4 Классификация Шнайдера
В 1988 году Л. Шнайдер (L. Snyder) предложил новый подход к описанию архитектур параллельных вычислительных систем, попадающих в класс SIMD систематики Флинна. Основная идея заключается в выделении этапов выборки и непосредственно исполнения в потоках команд и данных. Именно разделение потоков на адреса и их содержимое позволяет описать такие ранее «неудобные» для классификации архитектуры, как компьютеры с длинным командным словом, систолические массивы и целый ряд других.
Пусть S произвольный поток ссылок. Последовательность адресов потока S, обозначаемая Sa, – это последовательность, чей i-й элемент – набор, сформированный из адресов i-х элементов каждой последовательности из S: потока S, обозначаемая Sv, – это последовательность, чей i-й элемент – набор, образованный слиянием наборов значений i-х элементов каждой последовательности из S.
Если Sx – последовательность элементов, где каждый элемент – набор из n чисел, то для обозначения «ширины» последовательности будем пользоваться обозначением: w(Sx) = n.
Каждую пару (I, D) с потоком команд I и потоком данных D будем называть вычислительным шаблоном, а все компьютеры будем разбивать на классы в зависимости от того, какой шаблон они могут исполнить. В самом деле, компьютер может исполнить шаблон (I, D), если он в состоянии:
· выдать w(Ia) адресов команд для одновременной выборки из памяти;
· декодировать и проинтерпретировать одновременно w(Iv) команд;
· выдать одновременно w(Da) адресов операндов и
· выполнить одновременно w(Dv) операций над различными данными.
Если все эти условия выполнены, то компьютер может быть описан следующим образом: Iw(Ia)w(Iv)Dw(Da)w(Dv).
Поэтому описание однопроцессорной машины с фон-неймановской архитектурой будет выглядеть так: I1,1D1,1.
Теперь возьмем две машины из класса SIMD: Goodyear Aerospace MPP и ILLIAC IV, причем не будем принимать во внимание разницу в способах обработки данных отдельными процессорными элементами. Единственный поток команд означает I = 1 для обеих машин. По тем же соображениям, использованным только что для последовательной машины, для потока команд получаем равенство w(Ia) = w(Iv) = 1. Далее, вспомним, что для доступа к операндам устройство управления MPP рассылает один и тот же адрес всем процессорным элементам, поэтому в этой терминологии MPP имеет единственную последовательность в потоке данных, т.е. D = 1. Однако затем выборка данных из памяти и последующая обработка осуществляется в каждом процессорном элементе, поэтому w(Dv)=16384, а вся система MPP может быть описана так: I1,1D1,16384.
В ILLIAC IV устройство управления, так же, как и в MPP, рассылает один и тот же адрес всем процессорным элементам, однако каждый из них может получить свой уникальный адрес, добавляя содержимое локального индексного регистра. Это означает, что D = 64 и в системе присутствуют 64 потока адресов данных, определяющих одиночные потоки операндов, т.е. w(Da) = w(Dv) = 64. Суммируя сказанное, приходим к описанию ILLIAC IV: I1,1D64,64.
Для более четкой классификации Шнайдер вводит три предиката для обозначения значений, которые могут принимать величины w(Ia), w(Iv), w(Da) и w(Dv):
s – предикат «равен 1»;
с – предикат «от 1 до некоторой (небольшой) константы»;
m – предикат «от 1 до произвольно большого конечного числа».
В этих обозначениях, например, фон-неймановская машина принадлежит к классу IssDss. Несмотря на то, что и 'c' и 'm' в принципе не имеют определенной верхней границы, они отражают разные свойства архитектуры компьютера. Описатель 'c' предполагает жесткие ограничения сверху со стороны аппаратуры, и соответствующий параметр не может быть значительно увеличен относительно простыми средствами. Примером может служить число инструкций, упакованных в командном слове VLIW компьютера. С другой стороны, описатель 'm' используется тогда, когда обозначаемая величина может быть легко изменена, т.е. другими словами, компьютер по данному параметру масштабируем. Например, относительная проста в увеличении числа процессорных элементов в системе MPP является основанием для того, чтобы отнести ее к классу IssDsm. Конечно же, различие между 'c' и 'm' в достаточной мере условное и, как правило, порождает массу вопросов. В частности, как описать машину, в которой процессоры связаны через общую шину? С одной стороны, нет никаких принципиальных ограничений на число подключаемых процессоров. Однако каждый дополнительный процессор увеличивает загруженность шины, и при достижении некоторого порога подключение новых процессоров бессмысленно. Как описать такую систему, 'c' или 'm'? Автор оставляет данный вопрос открытым.
На основе указанных предикатов можно выделить следующие классы компьютеров:
· IssDss – фон-неймановские машины;
· IssDsc – фон-неймановские машины, в которых заложена возможность выбирать данные, расположенные с разным смещением относительно одного и того же адреса, над которыми будет выполнена одна и та же операция. Примером могут служить компьютеры, имеющие команды, типа одновременного выполнения двух операций сложения над данными в формате полуслова, расположенными по указанному адресу.
· IssDsm – SIMD компьютеры без возможности получения уникального адреса для данных в каждом процессорном элементе, включающие MPP, Connection Machine 1 так же, как и систолические массивы.
· IssDcc – многомерные SIMD машины – фон-неймановские машины, способные расщеплять поток данных на независимые потоки операндов;
· IssDmm – это SIMD компьютеры, имеющие возможность независимой модификации адресов операндов в каждом процессорном элементе, например, ILLIAC IV и Connection Machine 2.
· IscDcc – вычислительные системы, выбирающие и исполняющие одновременно несколько команд, для доступа к которым используется один адрес. Типичным примером являются компьютеры с длинным командным словом (VLIW).
· IccDcc – многомерные MIMD машины. Фон-неймановские машины, которые могут расщеплять свой цикл выборки / выполнения с целью обработки параллельно нескольких независимых команд.
· ImmDmm – к этому классу относятся все компьютеры типа MIMD.
Достаточно ясно, что не нужно рассматривать все возможные комбинации описателей 's', 'c' и 'm', так как архитектура реальных компьютеров накладывает ряд вполне разумных ограничений. Очевидно, что число адресов w(Sa) не должно превышать числа возвращенных значений w(Sv), которое компьютер может обработать. Отсюда следуют неравенства: w(Ia) <= w(Iv) и w(Da) <= w(Dv). Другим естественным предположением является тот факт, что число выполняемых команд не должно превышать числа обрабатываемых данных: w(Iv) <= w(Dv).
Подводя итог, можно отметить два положительных момента в классификации Шнайдера: более избирательная систематизация SIMD компьютеров и возможность описания нетрадиционных архитектур типа систолических массивов или компьютеров с длинным командным словом. Однако почти все вычислительные системы типа MIMD опять попали в один и тот же класс ImmDmm. Это и не удивительно, так как критерий классификации, основанный лишь на потоках команд и данных без учета распределенности памяти и топологии межпроцессорной связи, слишком слаб для подобных систем.
Похожие работы
... параллельных вычислений и методам синхронизации. Можно выделить четыре основных типа архитектуры систем параллельной обработки: 1) Конвейерная и векторная обработка. Основу конвейерной обработки составляет раздельное выполнение некоторой операции в несколько этапов (за несколько ступеней) с передачей данных одного этапа следующему. Производительность при этом возрастает благодаря тому, ...
... 5k управления ресурсами (программно-аппаратный комплекс) массивно-параллельного компьютера обязана обрабатывать подобные ситуации в обход катастрофического общего рестарта с потерей контекста исполняющихся в данный момент задач. 2.4.1 Массивно-параллельные суперкомпьютеры серии CRY T3 Основанная в 1972 году фирма Cry Research Inc. (сейчас Cry Inc.), прославившаяся разработкой векторного ...
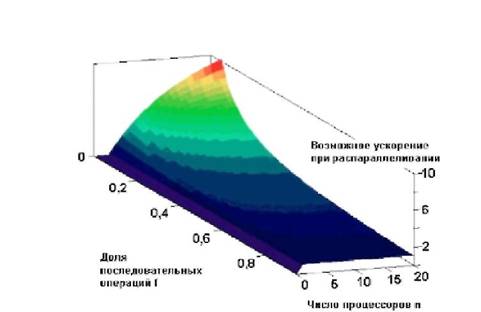
... время наиболее перспективным для конструирования компьютеров с рекордными показателями производительности. Использование параллельных вычислительных систем К сожалению чудеса в жизни редко случаются. Гигантская производительность параллельных компьютеров и супер-ЭВМ с лихвой компенсируется сложностями их использования. Начнем с самых простых вещей. У вас есть программа и доступ, скажем, к 256- ...
... ; - показывать, за счет каких структурных особенностей достигается увеличение производительности различных вычислительных систем; с этой точки зрения, классификация может служить моделью для анализа производительности. 1.12 Классификация Дазгупты Одним из последних исследований по классификации архитектур, по-видимому, является работа С. Дазгупты, вышедшая в 1990 году. Автор ...
0 комментариев