Навигация
3.2 Классификация Фенга
В 1972 году Т. Фенг предложил классифицировать вычислительные системы на основе двух простых характеристик. Первая – число бит n в машинном слове, обрабатываемых параллельно при выполнении машинных инструкций. Практически во всех современных компьютерах это число совпадает с длиной машинного слова. Вторая характеристика равна числу слов m, обрабатываемых одновременно данной вычислительной системой. Немного изменив терминологию, функционирование любого компьютера можно представить как параллельную обработку n битовых слоев, на каждом из которых независимо преобразуются m бит. Опираясь на такую интерпретацию, вторую характеристику обычно называют шириной битового слоя.
Если рассмотреть предельные верхние значения данных характеристик, то каждую вычислительную систему C можно описать парой чисел (n, m) и представить точкой на плоскости в системе координат длина слова – ширина битового слоя. Площадь прямоугольника со сторонами n и m определяет интегральную характеристику потенциала параллельности P архитектуры и носит название максимальной степени параллелизма вычислительной системы: P(C)=mn. По существу, данное значение есть ничто иное, как пиковая производительность, выраженная в других единицах. В период появления данной классификации, а это начало 70-х годов, еще казалось возможным перенести понятие пиковой производительности как универсального средства сравнения и описания потенциальных возможностей компьютеров с традиционных последовательных машин на параллельные. Понимание того факта, что пиковая производительность сама по себе не столь важна, пришло позднее, и данный подход отражает, естественно, степень осмысления специфики параллельных вычислений того времени.
Рассмотрим компьютер Advanced Scientific Computer фирмы Texas Instruments (TI ASC). В основном режиме он работает с 64-х разрядным словом, причем все разряды обрабатываются параллельно. Арифметико-логическое устройство имеет четыре одновременно работающих конвейера, содержащих по восемь ступеней. Такая организация дает 4x8=32 бита в каждом битовом слое, и значит компьютер TI ASC может быть представлен в виде (64,32).
На основе введенных понятий все вычислительные системы в зависимости от способа обработки информации, заложенного в их архитектуру, можно разделить на четыре класса.
· Разрядно-последовательные пословно-последовательные (n=m=1). В каждый момент времени такие компьютеры обрабатывают только один двоичный разряд. Представителем данного класса служит давняя система MINIMA с естественным описанием (1,1).
· Разрядно-параллельные пословно-последовательные (n>1, m=1). Большинство классических последовательных компьютеров, так же как и многие вычислительные системы, эксплуатируемые до сих пор, принадлежит к данному классу: IBM 701 с описанием (36,1), PDP-11 (16,1), IBM 360/50 и VAX 11/780 – обе с описанием (32,1).
· Разрядно-последовательные пословно-параллельные (n = 1, m > 1). Как правило вычислительные системы данного класса состоят из большого числа одноразрядных процессорных элементов, каждый из которых может независимо от остальных обрабатывать свои данные. Типичными примерами служат STARAN (1, 256) и MPP (1,16384) фирмы Goodyear Aerospace, прототип известной системы ILLIAC IV компьютер SOLOMON (1, 1024) и ICL DAP (1, 4096).
· Разрядно-параллельные пословно-параллельные (n > 1, m > 1). Большая часть существующих параллельных вычислительных систем, обрабатывая одновременно mn двоичных разрядов, принадлежит именно к этому классу: ILLIAC IV (64, 64), TI ASC (64, 32), C.mmp (16, 16), CDC 6600 (60, 10), BBN Butterfly GP1000 (32, 256).
Недостатки предложенной классификации достаточно очевидны и связаны со способом вычисления ширины битового слоя m. По существу Фенг не делает никакого различия между процессорными матрицами, векторно-конвейерными и многопроцессорными системами. Не делается акцент на том, за счет чего компьютер может одновременно обрабатывать более одного слова: множественности функциональных устройств, их конвейерности или же какого-то числа независимых процессоров. Если в системе N независимых процессоров имеют каждый по F конвейерных функциональных устройств с длиной конвейера L, то для вычисления ширины битового слоя надо просто найти произведение данных характеристик. Конечно же, опираясь на данную классификацию, достаточно трудно (а иногда и невозможно) осознать специфику той или иной вычислительной системы. Однако достоинством является введение единой числовой метрики для всех типов компьютеров, которая вместе с описанием потенциала вычислительных возможностей конкретной архитектуры позволяет сравнить любые два компьютера между собой.
3.3 Классификация Хокни
Р. Хокни – известный английский специалист в области параллельных вычислительных систем, разработал свой подход к классификации, введенной им для систематизации компьютеров, попадающих в класс MIMD по систематике Флинна.
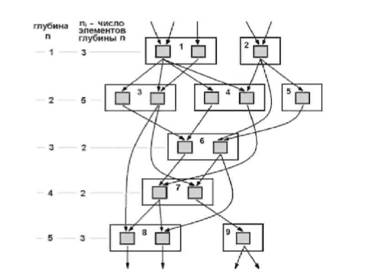
Как отмечалось выше (см. классификацию Флинна), класс MIMD чрезвычайно широк, причем наряду с большим числом компьютеров он объединяет и целое множество различных типов архитектур. Хокни, пытаясь систематизировать архитектуры внутри этого класса, получил иерархическую структуру, представленную на рисунке:
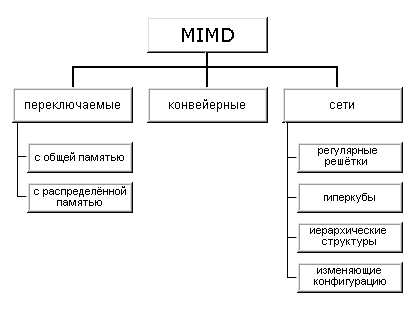
Основная идея классификации состоит в следующем. Множественный поток команд может быть обработан двумя способами: либо одним конвейерным устройством обработки, работающем в режиме разделения времени для отдельных потоков, либо каждый поток обрабатывается своим собственным устройством. Первая возможность используется в MIMD компьютерах, которые автор называет конвейерными (например, процессорные модули в Denelcor HEP). Архитектуры, использующие вторую возможность, в свою очередь опять делятся на два класса:
· MIMD компьютеры, в которых возможна прямая связь каждого процессора с каждым, реализуемая с помощью переключателя;
· MIMD компьютеры, в которых прямая связь каждого процессора возможна только с ближайшими соседями по сети, а взаимодействие удаленных процессоров поддерживается специальной системой маршрутизации через процессоры-посредники.
Далее, среди MIMD машин с переключателем Хокни выделяет те, в которых вся память распределена среди процессоров как их локальная память (например, PASM, PRINGLE). В этом случае общение самих процессоров реализуется с помощью очень сложного переключателя, составляющего значительную часть компьютера. Такие машины носят название MIMD машин с распределенной памятью. Если память это разделяемый ресурс, доступный всем процессорам через переключатель, то такие MIMD являются системами с общей памятью (CRAY X-MP, BBN Butterfly). В соответствии с типом переключателей можно проводить классификацию и далее: простой переключатель, многокаскадный переключатель, общая шина.
Многие современные вычислительные системы имеют как общую разделяемую память, так и распределенную локальную. Такие системы автор рассматривает как гибридные MIMD c переключателем.
При рассмотрении MIMD машин с сетевой структурой считается, что все они имеют распределенную память, а дальнейшая классификация проводится в соответствии с топологией сети: звездообразная сеть (lCAP), регулярные решетки разной размерности (Intel Paragon, CRAY T3D), гиперкубы (NCube, Intel iPCS), сети с иерархической структурой, такой, как деревья, пирамиды, кластеры (Cm*, CEDAR) и, наконец, сети, изменяющие свою конфигурацию.
Заметим, что если архитектура компьютера спроектирована с использованием нескольких сетей с различной топологией, то, по всей видимости, по аналогии с гибридными MIMD с переключателями, их стоит назвать гибридными сетевыми MIMD, а использующие идеи разных классов – просто гибридными MIMD. Типичным представителем последней группы, в частности, является компьютер Connection Machine 2, имеющим на внешнем уровне топологию гиперкуба, каждый узел которого является кластером процессоров с полной связью.
Похожие работы
... параллельных вычислений и методам синхронизации. Можно выделить четыре основных типа архитектуры систем параллельной обработки: 1) Конвейерная и векторная обработка. Основу конвейерной обработки составляет раздельное выполнение некоторой операции в несколько этапов (за несколько ступеней) с передачей данных одного этапа следующему. Производительность при этом возрастает благодаря тому, ...
... 5k управления ресурсами (программно-аппаратный комплекс) массивно-параллельного компьютера обязана обрабатывать подобные ситуации в обход катастрофического общего рестарта с потерей контекста исполняющихся в данный момент задач. 2.4.1 Массивно-параллельные суперкомпьютеры серии CRY T3 Основанная в 1972 году фирма Cry Research Inc. (сейчас Cry Inc.), прославившаяся разработкой векторного ...
... время наиболее перспективным для конструирования компьютеров с рекордными показателями производительности. Использование параллельных вычислительных систем К сожалению чудеса в жизни редко случаются. Гигантская производительность параллельных компьютеров и супер-ЭВМ с лихвой компенсируется сложностями их использования. Начнем с самых простых вещей. У вас есть программа и доступ, скажем, к 256- ...
... ; - показывать, за счет каких структурных особенностей достигается увеличение производительности различных вычислительных систем; с этой точки зрения, классификация может служить моделью для анализа производительности. 1.12 Классификация Дазгупты Одним из последних исследований по классификации архитектур, по-видимому, является работа С. Дазгупты, вышедшая в 1990 году. Автор ...
0 комментариев