Навигация
4.2 Формат результатов
В качестве результата анализатор предоставляет дерево контекстов с дополнительной информацией, размещенной в вершинах:
список зависимостей между витками каждого с векторами расстояний, группированные по переменным, обращения к которым создали эти зависимости,
список массивов, используемых оператором, а также, если элементы массива использовались линейным образом, то параметры соответствующей арифметической прогрессии
Также в узлах накапливается профилировочная информация, которая может быть полезной при принятии решений о распараллеливании:
количество выполнений поддерева с корнем в данном узле,
общее время выполнения поддерева с корнем в данном узле,
среднее, минимальное и максимально время однократного выполнения поддерева с корнем в данном узле.
Кроме того, анализатор сохраняет информацию обо всех зарегистрированных переменных. Список массивов, используемых в операторе – это лишь ссылки на элементы списка всех массивов, по которым можно получить дополнительную информацию.
Для работы с этой информацией была реализована специальная библиотека. Анализатор использует эту библиотеку для создания дерева контекстов и наполнения его информацией. Другие модули системы автоматизации распараллеливания могут использовать библиотеку для чтения сохраненных результатов анализа.
Основу библиотеки работы с результатами составляет класс ContextNode, представляющий вершину дерева контекстов. В этом классе предусмотрены методы для:
добавления непосредственных потомков,
навигации по дереву контекстов: переход к родительской вершине, к потомкам, к следующей вершине на том же уровне,
получения и изменения идентификационной информации о вершине: Sage-номер, тип вершины, номер строки исходного файла программы,
получения и изменения информации о зависимостях по данным, сохраненных в данной вершине,
получения и изменения профилировочной информации,
сохранения информации в файл и загрузки информации из файла.
Для хранения зависимостей в библиотеке предусмотрены классы:
Dependence – класс, представляющий одну зависимость, содержащий вектор расстояния,
DependenceStore – класс, предназначенный для хранения всех зависимостей одного типа.
Информация о массивах, используемых в программе, представляется классами CArrays и CArrayData. Класс CArrayData содержит информацию об одном массиве:
имя массива, номер строки, в котором он был определен,
Sage-номер или внутренний идентификатор массива для динамических массивов,
число измерений массива и размеры каждого измерения,
размер одного элемента массива.
При сохранении в файл данные записываются в формате XML. Удобство данного формата состоит в том, что он имеет древовидную структуру и, кроме того, является текстовым форматом, а потому может быть непосредственно прочитан человеком. Следует также отметить, что существуют простые и удобные библиотеки для работы с XML.
Конкретное представление дерева контекстов в виде XML несущественно. Предполагается, что все модули, требующие для работы результаты анализа, будут использовать предназначенную для этого библиотеку.
4.3 Внутреннее устройство анализатора
Внутренняя структура анализатора показана на Рисунке 2.
Ядро является основной частью динамического анализатора. Фактически, ядро – это реализация алгоритмов, описанных в разделе 3.2, использующая блок внешнего интерфейса для получения информации о ходе выполнения программы, а остальные блоки как структуры данных для хранения информации.
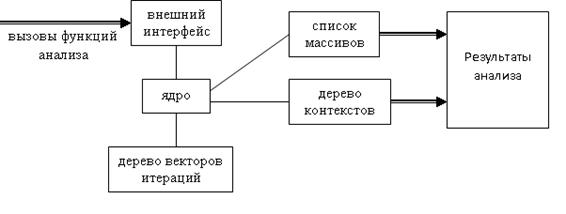
Рисунок 2 Внутренняя структура анализатора
Ядро анализатора использует внутренний интерфейс, основные операции которого соответствуют операциям интерфейса анализатора, описанным в разделе 4.1. Имеются, тем не менее, незначительные отличия, обусловленные соображениями удобства и простоты. Блок внешнего интерфейса необходим для преобразования вызовов функций анализа в вызовы интерфейса ядра. Исторически такое преобразование было необходимо в связи с тем, что первая версия анализатора была реализована на основе интерфейса отладчика системы DVM [6]. Этот отладчик предназначен для проверки корректности DVM-программы посредством моделирования ее параллельного выполнения, а также посредством накопления и сравнения трасс при ее последовательном и параллельном выполнении. В его интерфейс входят базовые функции, необходимые динамическому анализатору: чтение и запись значений переменных, начало и завершение циклов, начало итераций циклов. Поэтому до появления специального инструментатора было возможно использовать инструментатор, предназначенный для отладчика DVM. В данный момент наличие блока внешнего интерфейса позволяет при необходимости изменять интерфейс анализатора, не затрагивая основную часть библиотеки.
Дерево контекстов и список массивов – это части библиотеки работы с результатами анализа. Анализатор использует их для хранения информации во время выполнения программы и сохранения результатов по окончании анализа. Другие модули системы автоматизации распараллеливания смогут воспользоваться той же библиотекой для чтения сохраненных результатов. Дополнительно анализатор создает дерево векторов итераций – структуру данных, представляющую цепочки векторов итераций для операторов программы. Все цепочки, возникающие при анализе, организуются в дерево по следующему принципу: каждый элемент цепочки соответствует переходу на один уровень вниз по дереву, при этом одинаковым началам цепочек соответствуют одинаковые пути от корня по дереву. Тогда одинаковые цепочки векторов итераций представляются одним узлом в дереве. Виртуальная точка доступа при этом представляется просто как пара ссылок на соответствующие узлы в дереве контекстов и дереве векторов итераций. Дерево векторов итераций не сохраняется, поскольку после вычисления расстояний зависимостей векторы итераций уже не нужны.
В начале и при завершении работы анализатор производит специальные действия. При выполнении команды инициализации ядро ищет результаты предыдущего запуска анализатора и в случае успеха загружает ранее полученные дерево контекстов и список массивов. В этом случае результаты нового запуска добавляются к уже имеющимся результатам, что необходимо при наличии нескольких тестов. Когда анализатор получает команду завершения, содержимое дерева контекстов и списка массивов сохраняется в файл.
4.4 Результаты тестирования
Тестирование анализатора проводилось на программах, реализующих решение уравнения Пуассона в трехмерном пространстве классическими итерационными методами: методом Якоби, методом последовательной верхней релаксации (SOR), методом красно-черного упорядочения (RedBlack), а также на программе, реализующей решение системы линейный алгебраических уравнений методом Гаусса.
Основные показатели производительности показаны на Таблице 1. В методах Якоби, SOR и RedBlack использовалась матрица размера 16x16x8. В методе Гаусса решалась система размера 100x100.
Таблица 1 – Показатели производительности
| Метод | Время выполнения, сек | Используемая память, Kb | ||
| без анализатора | с анализатором | без анализатора | с анализатором | |
| Якоби | 0,05 | 4,73 | 924 | 58136 |
| SOR | 0,05 | 2,23 | 908 | 25096 |
| RedBlack | 0,05 | 5,52 | 908 | 65752 |
| Гаусс | 0,04 | 6,45 | 980 | 51756 |
Из приведенных результатов следует, что текущая реализация динамического анализатора замедляет работу программы в 100 и более раз, используя при этом в десятки раз больший объем памяти. Это ограничивает возможности применения анализатора, поскольку для того, чтобы время анализа оставалось в разумных пределах, необходимо сильно уменьшать размерность решаемой задачи.
Следует отметить, что на данный момент не было сделано попыток оптимизации анализатора. Поэтому полученные результаты нельзя считать окончательными, и следует считать указанием на необходимость дальнейшей работы по улучшению метода динамического анализа.
5. Заключение
Подведем некоторые итоги данной работы. Динамический анализ зависимостей по данным обладает рядом преимуществ по сравнению с традиционными статическими методами анализа. Поскольку анализ производится во время выполнения программы, доступна вся информация о производимых доступах в память. Это позволяет получить абсолютно точную информацию о зависимостях по данным независимо от сложности индексных выражений массивов, наличия косвенной индексации или указателей.
Основным недостатком данного метода является отсутствие гарантии того, что все возможные зависимости по данным обнаружены. Это означает, что для проведения анализа необходимо наличие набора тестов, достаточно полно покрывающего различные варианты поведения программы. Кроме того, существенные затраты ресурсов анализатором при каждом запуске программы на выполнение заставляют уменьшать размерность задач для анализа, что, быть может, не всегда возможно.
В рамках данной работы один из методов динамического анализа был реализован в виде библиотеки на языке С++ (около 2500 строк исходного кода). Проведено тестирование анализатора на наборе программ на языке Си, представляющих собой реализации классических итерационных методов (Якоби, SOR, RedBlack) и метода Гаусса. Тем самым показана возможность применения динамического анализа для поиска зависимостей в программах, требующих распараллеливания.
6. Литература
1. ParaWise. The Computer Aided Parallelization Toolkit [HTML, PDF] (http://www.parallelsp.com).
2. Проект V-Ray [HTML] (http://parallel.ru/v-ray).
3. Jacobson T., Stubbendieck G. Dependency Analysis of FOR-Loop Structures for Automatic Parallelization of C Code [PDF] (http://www.css.edu/depts/cis/mics_2003/MICS2003_Papers/Jacobson.PDF).
4. Karkowski I., Corporaal H. Overcoming the Limitations of the Traditional Loop Parallelization // Journal of Future Generation Computer Systems. 1998. № 13. P. 407-416.
5. Petersen P.M. Evaluation of Programs and Parallelizing Compilers Using Dynamic Analysis Techniques. Champaign, IL, USA: University of Illinois at Urbana-Champaign, 1993. 164 p.
6. DVM-система [HTML] (http://www.keldysh.ru/dvm).
Похожие работы


... для хранения директив FortranDVM, формирование которых осуществляет блок распределения вычислений и данных, и методы для их вставки, а также реализован экспорт этих комментариев в файл. 3.3 Алгоритмы Реализованные в дипломной работе классы блока статического построения расширенного графа управления программы и вспомогательных структур данных содержат большое число членов-методов, решающих ...


... из-за динамической подзагрузки программы из файловой системы) и отлаживать его производительность по той же методике, которая была описана выше применительно к программе целиком. 5. Средство анализа эффективности MPI программ 5.1 Постановка задачи В системе DVM существуют развитые средства анализа эффективности выполнения параллельной DVM-программы. Эти средства являются более мощными, ...
... лишь контекстным анализом. Как было отмечено в [12], применение глубокого статического анализа программ может позволить существенно снизить количество ложных срабатываний и повысить точность обнаружения уязвимостей защиты. 4.3. Использование методов анализа потоков данных для решения задачи обнаружения уязвимостей В отделе компиляторных технологий по контракту с фирмой Nortel Networks ...
... практичных алгоритмов оптимизированного перебора, позволяющих за разумное время осуществлять распараллеливание достаточно больших участков. Анализ работ, посвященных оптимизации кода для процессоров с параллелизмом на уровне команд показывает, что для достижения наилучших результатов необходимо применение комплекса оптимизаций, среди которых можно выделить следующие классы. Преобразования циклов ...
0 комментариев