Журнализация
Каждый потомок имеет только одного предка;
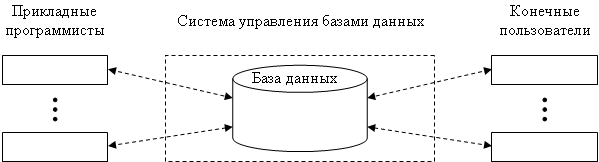
Типичное разделение функций между клиентами и серверами
Значение должно быть как можно меньше
Просканировать таблицу поставщиков P, каждый раз выполняя подзапрос с новым значением номера поставщика, взятым из таблицы P
Гиперкубов (все хранимые в базе данных ячейки должны иметь одинаковую размерность, то есть находиться в максимально полном базисе измерений) и
Другое расширение связано с созданием отдельных таблиц фактов для всех возможных сочетаний уровней обобщения различных измерений
Навигация
Типичное разделение функций между клиентами и серверами
Базы данных и информационные технологии
237727
знаков
39
таблиц
0
изображений
2. Типичное разделение функций между клиентами и серверами
В типичном на сегодняшний день случае на стороне клиента СУБД работает только такое программное обеспечение, которое не имеет непосредственного доступа к базам данных, а обращается для этого к серверу с использованием языка SQL.
Из предыдущих рассуждений видно, что требования к аппаратуре и программному обеспечению клиентских и серверных компьютеров различаются в зависимости от вида использования системы.
Если разделение между клиентом и сервером достаточно жесткое (как в большинстве современных СУБД), то пользователям, работающим на рабочих станциях или персональных компьютерах, абсолютно все равно, какая аппаратура и операционная система работают на сервере, лишь бы он справлялся с возникающим потоком запросов.
Но если могут возникнуть потребности перераспределения функций между клиентом и сервером, то уже совсем не все равно, какие операционные системы используются.
Трехуровневая модель технологии «клиент-сервер»
Она является расширением двухуровневой модели и в нее вводится дополнительный элемент – посредник между клиентом и сервером. Таким посредником является сервер приложений. В такой модели клиенту отводятся те же функции. Сервер базы данных занимается исключительно функциями создания и ведения базы данных, поддержания ее целостности, восстановления базы после сбоев и т.д. Сервер приложений выполняет общие функции клиентов, работа с каталогами, обмен сообщениями и т.д.
Основные объекты структуры базы данных SQL-сервера
К основным объектам базы данных SQL Server относятся объекты, представленные в таблице:
| Tables | Таблицы базы данных, в которых хранятся собственно данные |
| Views | Просмотры (виртуальные таблицы) для отображения данных из таблиц |
| Indexes | Индексы – дополнительные структуры, призванные повысить производительность работы с данными |
| Keys | Ключи – один из видов ограничений целостности данных |
| Constraints | Ограничение целостности – объекты для обеспечения логической целостности данных |
| Roles | Роли, позволяющие объединять пользователей в группы |
Приведем краткий обзор основных объектов баз данных.
Таблицы
Все данные в SQL содержатся в объектах, называемых таблицами. Таблицы представляют собой совокупность каких-либо сведений об объектах, явлениях, процессах реального мира. Никакие другие объекты не хранят данные, но они могут обращаться к данным в таблице.
Представления. Представлениями (просмотрами) называют виртуальные таблицы, содержимое которых определяется запросом. Подобно реальным таблицам, представления содержат именованные столбцы и строки с данными. Для конечных пользователей представление выглядит как таблица, но в действительности оно не содержит данных, а лишь представляет данные, расположенные в одной или нескольких таблицах. Информация, которую видит пользователь через представление, не сохраняется в базе данных как самостоятельный объект.
Индексы
Индекс – структура, связанная с таблицей или представлением и предназначенная для ускорения поиска информации в них. Индекс определяется для одного или нескольких столбцов, называемых индексированными столбцами. Он содержит отсортированные значения индексированного столбца или столбцов со ссылками на соответствующую строку исходной таблицы или представления. Повышение производительности достигается за счет сортировки данных. Использование индексов может существенно повысить производительность поиска, однако для хранения индексов необходимо дополнительное пространство в базе данных.
Индексы – это наборы уникальных значений для некоторой таблицы с соответствующими ссылками на данные. Расположенные в самой таблице, они являются удобным внутренним механизмом системы SQL-сервера, с помощью которого осуществляется доступ к данным наиболее оптимальным способом. В среде SQL Server реализованы эффективные алгоритмы поиска нужного значения в строго определенной последовательности данных. Ускорение поиска достигается именно за счет того, что данные представляются упорядоченными (хотя физически, в зависимости от типа индекса, они могут храниться в соответствии с очередностью их добавления в таблицу). К настоящему времени разработаны эффективные математические алгоритмы поиска данных в упорядоченной последовательности. Создание индекса. Если выборка данных из таблицы требует значительного времени, это означает, что для нее необходимо создать индекс. Индексы могут существенно повысить производительность выполнения операций поиска и выборки данных. При выборе столбца для индекса следует проанализировать, какие типы запросов чаще всего выполняются пользователями и какие столбцы являются ключевыми, т.е. задающими критерии выборки данных, например, порядок сортировки.
В среде SQL Server реализовано несколько типов индексов:
· кластерные индексы;
· некластерные индексы;
· уникальные индексы.
Некластерный индекс
Некластерные индексы – наиболее типичные представители семейства индексов. В отличие от кластерных, они не перестраивают физическую структуру таблицы, а лишь организуют ссылки на соответствующие строки.
Для идентификации нужной строки в таблице некластерный индекс организует специальные указатели, включающие в себя:
· информацию об идентификационном номере файла, в котором хранится строка;
· идентификационный номер страницы соответствующих данных;
· номер искомой строки на соответствующей странице;
· содержимое столбца.
В большинстве случаев следует ограничиваться 4-5 индексами.
Кластерный индекс
Принципиальным отличием кластерного индекса от индексов других типов является то, что при его определении в таблице физическое расположение данных перестраивается в соответствии со структурой индекса. Логическая структура таблицы в этом случае представляет собой скорее словарь, чем индекс. Данные в словаре физически упорядочены, например по алфавиту.
Кластерные индексы могут дать существенное увеличение производительности поиска данных даже по сравнению с обычными индексами. Увеличение производительности особенно заметно при работе с последовательными данными. Если в таблице определен некластерный индекс, то сервер должен сначала обратиться к индексу, а затем найти нужную строку в таблице. При использовании кластерных индексов следующая порция данных располагается сразу после найденных ранее данных. Благодаря этому отпадают лишние операции, связанные с обращением к индексу и новым поиском нужной строки в таблице.
Естественно, в таблице может быть определен только один кластерный индекс. В качестве такового следует выбирать наиболее часто используемые столбцы. При этом стоит следовать общим рекомендациям создания индексов и не индексировать слишком длинные столбцы.
Кластерный индекс может включать несколько столбцов. Однако количество таких столбцов рекомендуется по возможности свести к минимуму.
Необходимо избегать создания кластерного индекса для часто изменяемых столбцов, поскольку сервер должен будет выполнять физическое перемещение всех данных в таблице, чтобы они находились в упорядоченном состоянии, как того требует кластерный индекс. Для интенсивно изменяемых столбцов лучше подходит некластерный индекс.
При создании в таблице первичного ключа сервер автоматически создает для него кластерный индекс, если его не существовало ранее или если при определении ключа не был явно указан другой тип индекса.
Когда же в таблице определен еще и некластерный индекс, то его указатель ссылается не на физическое положение строки в базе данных, а на соответствующий элемент кластерного индекса, описывающего эту строку, что позволяет не перестраивать структуру некластерных индексов всякий раз, когда кластерный индекс меняет физический порядок строк в таблице.
Уникальный индекс
Уникальность значений в индексируемом столбце гарантируют уникальные индексы. При их наличии сервер не разрешит вставить новое или изменить существующее значение таким образом, чтобы в результате этой операции в столбце появились два одинаковых значения.
Уникальный индекс является своеобразной надстройкой и может быть реализован как для кластерного, так и для некластерного индекса. В одной таблице может существовать один уникальный кластерный и множество уникальных некластерных индексов.
Уникальные индексы следует определять только тогда, когда это действительно необходимо. Для обеспечения целостности данных в столбце можно определить ограничение целостности, а не прибегать к уникальным индексам. Их использование только для обеспечения целостности данных является неоправданной тратой пространства в базе данных. Кроме того, на их поддержание тратится и процессорное время.
Средства языка SQL предлагают несколько способов определения индекса:
· автоматическое создание индекса при создании первичного ключа;
· автоматическое создание индекса при определении ограничения целостности;
· создание индекса с помощью команды.
Имя индекса должно быть уникальным в пределах таблицы, а сам индекс создается исключительно для таблицы текущей базы данных.
Ограничения целостности
Ограничения целостности – механизм, обеспечивающий автоматический контроль соответствия данных установленным условиям (или ограничениям). К ограничениям целостности относятся: ограничение на значение NULL, ограничение первичного ключа и ограничение внешнего ключа.
2. Типы данных языка SQL, с помощью которых можно определять данные в таблицеВ языке SQL имеется шесть скалярных типов данных, определенных стандартом. Их краткое описание представлено в таблице.
Символьные данные
Символьные данные состоят из последовательности символов, входящих в определенный создателями набор символов.
При определении столбца с символьным типом данных параметр длина применяется для указания максимального количества символов, которые могут быть помещены в данный столбец (по умолчанию принимается значение 1).
Для хранения символьной информации используются символьные типы данных, к которым относятся CHAR (длина) и VARCHAR (длина).Хранение символьных данных большого объема (до 2 Гб) осуществляется при помощи текстовых типов данных TEXT.
Битовые данные
Битовый тип данных используется для определения битовых строк, т.е. последовательности двоичных цифр (битов). Тип данных BIT позволяет хранить один бит, который принимает значения 0 или 1.
Точные числа Тип точных числовых данных применяется для определения чисел, которые имеют точное представление, т.е. числа состоят из цифр, необязательной десятичной точки и необязательного символа знака. Данные точного числового типа определяются точностью и длиной дробной части. Точность задает общее количество значащих десятичных цифр числа, в которое входит длина как целой части, так и дробной, но без учета самой десятичной точки. Масштаб указывает количество дробных десятичных разрядов числа.
К целочисленным типам данных относятся INT (INTEGER), SMALLINT, TININT, BIGINT. Для хранения данных целочисленного типа используется, соответственно, 4 байта (диапазон от -231 до 231-1), 2 байта (диапазон от -215 до 215-1), 1 байт (диапазон от 0 до 255) или 8 байт (диапазон от -263 до 263-1). Объекты и выражения целочисленного типа могут применяться в любых математических операциях.
Типы NUMERIC и DECIMAL предназначены для хранения чисел в десятичном формате. По умолчанию длина дробной части равна нулю, а принимаемая по умолчанию точность зависит от реализации. Тип INTEGER (INT) используется для хранения больших положительных или отрицательных целых чисел. Тип SMALLINT – для хранения небольших положительных или отрицательных целых чисел; в этом случае расход внешней памяти существенно сокращается.
Округленные числа
Тип округленных чисел применяется для описания данных, которые нельзя точно представить в компьютере, в частности действительных чисел. Округленные числа или числа с плавающей точкой представляются в научной нотации, при которой число записывается с помощью мантиссы, умноженной на определенную степень десяти (порядок), например: 10Е3, +5.2Е6, -0.2Е-4. Точность типов REAL и FLOAT зависит от конкретной реализации.
Числа, в составе которых есть десятичная точка, называются нецелочисленными. Нецелочисленные данные разделяются на два типа – десятичные и приблизительные.
К десятичным типам данных относятся типы DECIMAL [(точность[,масштаб])] или DEC и NUMERIC [(точность[,масштаб])]. Типы данных DECIMAL и NUMERIC позволяют самостоятельно определить формат точности числа с плавающей запятой. Параметр точность указывает максимальное количество цифр вводимых данных этого типа (до и после десятичной точки в сумме), а параметр масштаб – максимальное количество цифр, расположенных после десятичной точки. В обычном режиме сервер позволяет вводить не более 28 цифр, используемых в типах DECIMAL и NUMERIC (от 2 до 17 байт).
К приблизительным типам данных относятся FLOAT (точность до 15 цифр, 8 байт) и REAL (точность до 7 цифр, 4 байта). Эти типы представляют данные в формате с плавающей запятой, т.е. для представления чисел используется мантисса и порядок, что обеспечивает одинаковую точность вычислений независимо от того, насколько мало или велико значение.
Дата и время Тип данных «дата/время» используется для определения моментов времени с некоторой установленной точностью.
Для хранения информации о дате и времени предназначены такие типы данных, как DATETIME и SMALLDATETIME, использующие для представления даты и времени 8 и 4 байта соответственно.
Тип данных DATETIME используется для совместного хранения даты и времени: хранения календарных дат, включающих поля YEAR (год), MONTH (месяц) и DAY (день) и хранения отметок времени, включающих поля HOUR (часы), MINUTE (минуты) и SECOND (секунды). Данные типа INTERVAL используются для представления периодов времени.
Финансовые типы данных
Типы данных MONEY и SMALLMONEY делают возможным хранение информации денежного типа; они обеспечивают точность значений до 4 знаков после запятой и используют 8 и 4 байта соответственно.
Работа с внешними данными с помощью технологии ODBC
Важнейшим этапом в построении приложения клиент-сервер является установка связи клиентского приложения с источником данных, находящимся на сервере БД. В настоящий момент различные средства разработки используют несколько технологий обеспечения доступа к данным. Общепризнанным стандартом является технология ODBC.
ODBC – Open Database Connectivity – открытый доступ к данным – это общее определение языка и набор протоколов. ODBC позволяет клиентскому приложению, например, Access или Visual FoxPro, работать с командами и функциями, поддерживаемыми сервером.
ODBC находится как бы посредине между приложением, использующем данные, и самими данными, хранящимися на сервере, которые мы не можем обработать напрямую в приложении, и используется как средство коммуникации между двумя сторонами технологии – клиентом и сервером.
Для использования ODBC с целью получения данных в сети вам необходимы средства коммуникации между машиной, на которой находятся данные, и машиной, где они будут просматриваться, модифицироваться и обрабатываться.
Канал связи между машинами устанавливается один раз и может быть использован много раз для разработки различных приложений по работе с одной и той же базой. При создании соединения возможны следующие варианты: создание файлового соединения (все настройки канала связи сохраняются в виде отдельного файла и могут переноситься с одной машины на другую); создание машинного соединения (все настройки канала связи записываются в реестр операционной системы). Создание канала связи состоит из нескольких этапов:
– выбор драйвера СУБД, с которой будет выполняться связь (MS SQL Server),
– выбор сервера, с которым осуществляется связь с указанием имени этой машины (имя сервера в сети, если речь идет о локальной сети, и IP-адрес, если речь идет об удаленном доступе к серверу);
– выбор базы данных, с которой устанавливается связь, так как на сервере может храниться большое количество баз.
Для определения связи используется специальная программа – Администратор ODBC, и драйверы, которые могут работать как с приложением, так и с данными на сервере.
Для MS SQL Server используются ODBC драйверы, разработанные Microsoft.
Одна из главных целей создания ODBC - скрыть сложность соединения с сервером и по мере возможности автоматизировать выполнение многочисленных процедур, связанных с получением данных.
Лекция 4. Фрактальные методы сжатия больших объемов данных
1. Фракталы и история возникновения метода фрактального сжатияВ декабре 1992 года, перед самым Рождеством, компания Microsoft выпустила свой новый компакт-диск Microsoft Encarta. С тех пор эта мультимедиа-энциклопедия, содержащая информацию о животных, цветах, деревьях и живописных местах, не покидает списки наиболее популярных энциклопедий на компакт-дисках. В недавнем опросе Microsoft Encarta опять заняла первое место, опередив ближайшего конкурента - Комптоновскую мультимедиа-энциклопедию. Причина подобной популярности кроется в удобстве использования, высоком качестве статей и, главное, в большом количестве материалов. На диск записано 7 часов звука, 100 анимационных роликов, примерно 800 масштабируемых карт, а также 7000.качественных фотографий. И все это - на одном диске! Напомним, что обычный компакт-диск в 650 Мбайт без использования компрессии может содержать либо 56 минут качественного звука, либо 1 час видео разрешения с разрешением 320х200 в формате MPEG-1, либо 700 полноцветных изображений размером 640х480. Чтобы разместить больше информации, необходимы достаточно эффективные алгоритмы архивации. Мы не будем останавливаться на методах архивации для видео и звука. Речь пойдет о новом перспективном алгоритме - фрактальном сжатии графической информации.
Понятия «фрактал» и «фрактальная геометрия» (fractus – состоящий из фрагментов, лат.) были предложены математиком Б. Мандельбротом в 1975 г. для обозначения нерегулярных, но самоподобных структур. Рождение фрактальной геометрии обычно связывают с выходом в 1977 году книги Б. Мандельброта "Фрактальная геометрия природы". Одна из основных идей книги заключалась в том, что средствами традиционной геометрии (то есть используя линии и поверхности), чрезвычайно сложно представить природные объекты. Фрактальная геометрия задает их очень просто.
Определение фрактала, данное Мандельбротом, звучит так: "Фракталом называется структура, состоящая из частей, которые в каком-то смысле подобны целому"
Одним из основных свойств фракталов является самоподобие. В самом простом случае небольшая часть фрактала содержит информацию о всём фрактале. Фракталы, эти красивые образы динамических систем, ранее использовались в машинной графике в основном для построения изображений неба, листьев, гор, травы. Красивое и, что важнее, достоверно имитирующее природный объект изображение могло быть задано всего несколькими коэффициентами.
Существует большое разнообразие фракталов. Потенциально наиболее полезным видом фракталов являются фракталы на основе системы итеративных функций (Iterated Function System – IFS). Метод IFS применительно к построению фрактальных изображений, изобретённый большим их знатоком Майклом Барнсли (Michael Barnsley) и его коллегами из Технологического института шт. Джорджия (Georgia Institute of Technology), базируется на самоподобии элементов изображения и заключается в моделировании рисунка несколькими меньшими фрагментами его самого. Специальные уравнения позволяют переносить, поворачивать и изменять масштаб участков изображения; таким образом, эти участки служат компоновочными блоками остальной части картины.
Одним из наиболее поразительных (и знаменитых) IFS-изображений является чёрный папоротник, в котором каждый лист в действительности представляет собой миниатюрный вариант самого папоротника (см. рис.). Несмотря на то, что картинка создана компьютером методом аффинных преобразований, папоротник выглядит совершенно как настоящий. Выдвинуто предположение, что природа при кодировании генетической структуры растений и деревьев пользуется чем-то близким к методу IFS-фракталов.
IFS-фракталы имеют одно вполне реальное и полезное применение: с их помощью можно сжимать большие растровые изображения до долей их нормальных размеров. Этот утверждение следует из теоремы Банаха о сжимающих преобразованиях (также известной как Collage Theorem) и является результатом работы исследователя Технологического института шт. Джорджия Майкла Барнсли в области IFS. Вооружившись этим выводом, он ушёл из института, запатентовал свое открытие и основал компанию Iterated Systems Incorporated. О своём достижении он рассказал миру в журнале Byte за январь 1988 г. Однако там отсутствовали какие-либо сведения о решении обратной задачи: как по заданному изображению найти аффинные преобразования. К тому моменту у этой задачи не было даже намёка на решение. В статье Барнсли было показано несколько реалистичных фрактальных изображений, но все они были созданы вручную.
В идеале хотелось бы уметь находить для любого изображения систему аффинных преобразований (IFSM), воспроизводящую изображение с заданной точностью. Однако решение находилось немного в стороне. Первым нашёл его именно студент Барнсли, Арно Жакан (Arnaud Jacquin). Предложенный метод получил название «Система итерируемых кусочно-определённых функций» (Partitioned Iterated Function System – PIFS). Согласно этой схеме, отдельные части изображения подобны не всему изображению, а только его частям.
2. Математические основы фрактального сжатияФрактальные методы сжатия позволяют сжать информацию в 10 000 раз. Все известные программы фрактальной компрессии базируются на алгоритме Джеквина – сотрудника Барнсли, который в 1992 году при защите диссертации описал практический алгоритм фрактального сжатия. Несомненным достоинством работы было то, что вмешательство человека в процесс сжатия удалось полностью исключить.
Рассмотрим механизм фрактального сжатия данных. Фрактальная архивация основана на том, что с помощью коэффициентов системы итерируемых функций изображение представляется в более компактной форме. Прежде чем рассматривать процесс архивации, разберем, как IFS строит изображение. Строго говоря, IFS - это набор трехмерных аффинных преобразований, переводящих одно изображение в другое. Преобразованию подвергаются точки в трехмерном пространстве (x координата, у координата, яркость). Наиболее наглядно этот процесс продемонстрировал сам Барнсли в своей книге "Фрактальное сжатие изображения". В ней введено понятие Фотокопировальной Машины, состоящей из экрана, на котором изображена исходная картинка, и системы линз, проецирующих изображение на другой экран. Каждая линза проецирует часть исходного изображения. Расставляя линзы и меняя их характеристики, можно управлять получаемым изображением. На линзы накладывается требование они должны уменьшать в размерах проектируемую часть изображения. Кроме того, они могут менять яркость фрагмента и проецируют не круги, а области с произвольной границей. Одна шаг Машины состоит в построении с помощью проецирования по исходному изображению нового. Утверждается, что на некотором шаге изображение перестанет изменяться. Оно будет зависеть только от расположения и характеристик линз и не будет зависеть от исходной картинки. Это изображение называется неподвижной точкой или аттрактором данной IFS. Collage Theorem гарантирует наличие ровно одной неподвижной точки для каждой IFS. Поскольку отображение линз является сжимающим, каждая линза в явном виде задает самоподобные области в нашем изображении. Благодаря самоподобию мы получаем сложную структуру изображения при любом увеличении. Наиболее известны два изображения, полученных с помощью IFS треугольник Серпинского и папоротник Барнсли Первое задается тремя, а второе - питью аффинными преобразованиями (или, в нашей терминологии, линзами). Каждое преобразование задается буквально считанными байтами, в то время, как изображение, построенное с их помощью, может занимать и несколько мегабайт. Становится понятно, как работает архиватор, и почему ему требуется так много времени. Фактически, фрактальная компрессия - это поиск самоподобных областей в изображении и определение для них параметров аффинных преобразований. В худшем случае, если не будет применяться оптимизирующий алгоритм, потребуется перебор и сравнение всех возможных фрагментов изображения разного размера. Даже для небольших изображений при учете дискретности мы получим астрономическое число перебираемых вариантов. Даже резкое сужение классов преобразований, например, за счет масштабирования только в определенное число раз, не позволит добиться приемлемого времени. Кроме того, при этом теряется качество изображения. Подавляющее большинство исследований в области фрактальной компрессии сейчас направлены на уменьшение времени архивации, необходимого для получения качественного изображения.
Итак, рассмотрим математическое обоснование возможности фрактального сжатия.
Есть отображение ![]() , где
, где ![]() – множество всех возможных изображений. W является объединением отображений wi:
– множество всех возможных изображений. W является объединением отображений wi:
|
| (1) |
где R – изображение, а di – какие-то (возможно, перекрывающиеся) области изображения D. Каждое преобразование wi переводит di в ri. Таким образом:
|
| (2) |
Такие отображения называются сжимающими, и для них справедливо следующее утверждение:
Если к какому-то изображению F0 мы начнём многократно применять отображение W таким образом, что
|
| (5) |
то в пределе, при i, стремящемся к бесконечности, мы получим одно и то же изображение вне зависимости от того, какое изображение мы взяли в качестве F0:
|
| (6) |
Это конечное изображение F называют аттрактором, или неподвижной точкой отображения W. Также известно, что если преобразования wi являются сжимающими, то их объединение W тоже является сжимающим.
3. Типовая схема фрактального сжатияС учётом вышесказанного, схема компрессии выглядит так: изображение R разбивают на кусочки ri, называемые ранговыми областями. Далее для каждой области ri находят область di и преобразование wi такие, что выполняются следующие условия:
1. di по размерам больше ri.
2. wi (ri) имеет ту же форму, размеры и положение, что и ri.
3. Коэффициент u преобразования wi должен быть меньше единицы.
Похожие работы




... и в то же время мощного математического аппарата, опирающегося главным образом на теорию множеств и математическую логику и обеспечивающего теоретический базис реляционного подхода к организации баз данных; 3. возможность ненавигационного манипулирования данными без необходимости знания конкретной физической организации баз данных во внешней памяти. Однако реляционные системы далеко не ...
... функционирования. На данный момент существует достаточно большое количество разновидностей информационных систем. Классификация информационных систем обычно осуществляется на основе каких-либо выделенных признаков. Например, с точки зрения управленческого уровня, на котором осуществляется использование ИС, принято делить корпоративные ИС на следующие виды: 1. ИС для обеспечения текущих бизнес- ...
... : - между потребностями современного информационного общества в качественно новых членах, обладающих творческим мышлением и владеющих информационными технологиями и ограниченными возможностями современной школы в этом направлении; - между совершенствованием содержательной основы информационных технологий обучения и отсутствием научно-обоснованных исследований по данной проблеме. Информационные ...
... . Такая стратегия характерна для крупных организаций. Таким образом, каждая организация, учреждение, фирма проходит свой собственный путь с целью совершенствования документационного обеспечения управления на базе внедрения новых информационных технологий. Для мелких и средних предприятий целесообразен первый подход. Он является в настоящее время наиболее распространенным. В крупных организациях с ...
0 комментариев