Журнализация
Каждый потомок имеет только одного предка;
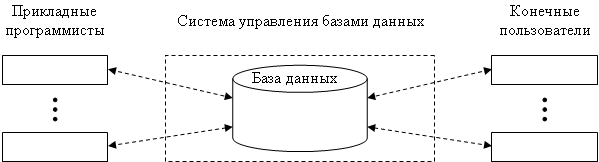
Типичное разделение функций между клиентами и серверами
Значение должно быть как можно меньше
Просканировать таблицу поставщиков P, каждый раз выполняя подзапрос с новым значением номера поставщика, взятым из таблицы P
Гиперкубов (все хранимые в базе данных ячейки должны иметь одинаковую размерность, то есть находиться в максимально полном базисе измерений) и
Другое расширение связано с созданием отдельных таблиц фактов для всех возможных сочетаний уровней обобщения различных измерений
Навигация
Просканировать таблицу поставщиков P, каждый раз выполняя подзапрос с новым значением номера поставщика, взятым из таблицы P
Базы данных и информационные технологии
237727
знаков
39
таблиц
0
изображений
1. Просканировать таблицу поставщиков P, каждый раз выполняя подзапрос с новым значением номера поставщика, взятым из таблицы P.
2. В результат запроса включить только те строки из таблицы поставщиков, для которых вложенный подзапрос вернул непустое множество строк.
Замечание. В отличие от двух предыдущих примеров, вложенный подзапрос содержит параметр (внешнюю ссылку), передаваемый из основного запроса - номер поставщика P.PNUM. Такие подзапросы называются коррелируемыми (correlated). Внешняя ссылка может принимать различные значения для каждой строки-кандидата, оцениваемого с помощью подзапроса, поэтому подзапрос должен выполняться заново для каждой строки, отбираемой в основном запросе. Такие подзапросы характерны для предиката EXIST, но могут быть использованы и в других подзапросах.
Замечание. Может показаться, что запросы, содержащие коррелируемые подзапросы будут выполняться медленнее, чем запросы с некоррелируемыми подзапросами. На самом деле это не так, т.к. то, как пользователь, сформулировал запрос, не определяет, как этот запрос будет выполняться. Язык SQL является непроцедурным, а декларативным. Это значит, что пользователь, формулирующий запрос, просто описывает, каким должен быть результат запроса, а как этот результат будет получен - за это отвечает сама СУБД.
Пример 28. Использование предиката NOT EXIST. Получить список поставщиков, не поставляющих деталь номер 2:
SELECT *
FROM P
WHERE NOT EXIST
(SELECT *
FROM PD
WHERE
PD.PNUM = P.PNUM AND
PD.DNUM = 2);
Замечание. Также как и в предыдущем примере, здесь используется коррелируемый подзапрос. Отличие в том, что в основном запросе будут отобраны те строки из таблицы поставщиков, для которых вложенный подзапрос не выдаст ни одной строки.
Пример 29. Получить имена поставщиков, поставляющих все детали:
SELECT DISTINCT PNAME
FROM P
WHERE NOT EXIST
(SELECT *
FROM D
WHERE NOT EXIST
(SELECT *
FROM PD
WHERE
PD.DNUM = D.DNUM AND
PD.PNUM = P.PNUM));
Замечание. Данный запрос содержит два вложенных подзапроса и реализует реляционную операцию деления отношений.
Самый внутренний подзапрос параметризован двумя параметрами (D.DNUM, P.PNUM) и имеет следующий смысл: отобрать все строки, содержащие данные о поставках поставщика с номером PNUM детали с номером DNUM. Отрицание NOT EXIST говорит о том, что данный поставщик не поставляет данную деталь. Внешний к нему подзапрос, сам являющийся вложенным и параметризованным параметром P.PNUM, имеет смысл: отобрать список деталей, которые не поставляются поставщиком PNUM. Отрицание NOT EXIST говорит о том, что для поставщика с номером PNUM не должно быть деталей, которые не поставлялись бы этим поставщиком. Это в точности означает, что во внешнем запросе отбираются только поставщики, поставляющие все детали.
Использование объединения, пересечения и разностиПример 30. Получить имена поставщиков, имеющих статус, больший 3 или поставляющих хотя бы одну деталь номер 2 (объединение двух подзапросов - ключевое слово UNION):
SELECT P.PNAME
FROM P
WHERE P.STATUS > 3
UNION
SELECT P.PNAME
FROM P, PD
WHERE P.PNUM = PD.PNUM AND
PD.DNUM = 2;
Замечание. Результатирующие таблицы объединяемых запросов должны быть совместимы, т.е. иметь одинаковое количество столбцов и одинаковые типы столбцов в порядке их перечисления. Не требуется, чтобы объединяемые таблицы имели бы одинаковые имена колонок. Это отличает операцию объединения запросов в SQL от операции объединения в реляционной алгебре. Наименования колонок в результатирующем запросе будут автоматически взяты из результата первого запроса в объединении.
Пример 31. Получить имена поставщиков, имеющих статус, больший 3 и одновременно поставляющих хотя бы одну деталь номер 2 (пересечение двух подзапросов - ключевое слово INTERSECT):
SELECT P.PNAME
FROM P
WHERE P.STATUS > 3
INTERSECT
SELECT P.PNAME
FROM P, PD
WHERE P.PNUM = PD.PNUM AND
PD.DNUM = 2;
Пример 32. Получить имена поставщиков, имеющих статус, больший 3, за исключением тех, кто поставляет хотя бы одну деталь номер 2 (разность двух подзапросов - ключевое слово EXCEPT):
SELECT P.PNAME
FROM P
WHERE P.STATUS > 3
EXCEPT
SELECT P.PNAME
FROM P, PD
WHERE P.PNUM = PD.PNUM AND
PD.DNUM = 2; Синтаксис оператора выборки данных (SELECT) BNF-нотация
Опишем синтаксис оператора выборки данных (оператора SELECT) более точно. При описании синтаксиса операторов обычно используются условные обозначения, известные как стандартные формы Бэкуса-Наура (BNF).
В BNF обозначениях используются следующие элементы:
· Символ "::=" означает равенство по определению. Слева от знака стоит определяемое понятие, справа - собственно определение понятия.
· Ключевые слова записываются прописными буквами. Они зарезервированы и составляют часть оператора.
· Метки-заполнители конкретных значений элементов и переменных записываются курсивом.
· Необязательные элементы оператора заключены в квадратные скобки [].
· Вертикальная черта | указывает на то, что все предшествующие ей элементы списка являются необязательными и могут быть заменены любым другим элементом списка после этой черты.
· Фигурные скобки {} указывают на то, что все находящееся внутри них является единым целым.
· Троеточие "…" означает, что предшествующая часть оператора может быть повторена любое количество раз.
· Многоточие, внутри которого находится запятая ".,.." указывает, что предшествующая часть оператора, состоящая из нескольких элементов, разделенных запятыми, может иметь произвольное число повторений. Запятую нельзя ставить после последнего элемента. Замечание: данное соглашение не входит в стандарт BNF, но позволяет более точно описать синтаксис операторов SQL.
· Круглые скобки являются элементом оператора.
Синтаксис оператора выборкиВ довольно сильно упрощенном виде оператор выборки данных имеет следующий синтаксис (для некоторых элементов мы дадим не BNF-определения, а словесное описание):
Оператор выборки:= Табличное выражение [ORDER BY {{Имя столбца-результата [ASC | DESC]} | {Положительное целое [ASC | DESC]}}.,..];
Табличное выражение ::= Select-выражение [ {UNION | INTERSECT | EXCEPT} [ALL] {Select-выражение | TABLE Имя таблицы | Конструктор значений таблицы} ]
Select-выражение ::= SELECT [ALL | DISTINCT] {{{Скалярное выражение | Функция агрегирования | Select-выражение} [AS Имя столбца]}.,..} | {{Имя таблицы|Имя корреляции}.*} | * FROM { {Имя таблицы [AS] [Имя корреляции] [(Имя столбца.,..)]} | {Select-выражение [AS] Имя корреляции [(Имя столбца.,..)]} | Соединенная таблица }.,.. [WHERE Условное выражение] [GROUP BY {[{Имя таблицы|Имя корреляции}.]Имя столбца}.,..] [HAVING Условное выражение]
Замечание. Select-выражение в разделе SELECT, используемое в качестве значения для отбираемого столбца, должно возвращать таблицу, состоящую из одной строки и одного столбца, т.е. скалярное выражение.
Замечание. Условное выражение в разделе WHERE должно вычисляться для каждой строки, являющейся кандидатом в результатирующее множество строк. В этом условном выражении можно использовать подзапросы. Синтаксис условных выражений, допустимых в разделе WHERE рассматривается ниже.
Замечание. Раздел HAVING содержит условное выражение, вычисляемое для каждой группы, определяемой списком группировки в разделе GROUP BY. Это условное выражение может содержать функции агрегирования, вычисляемые для каждой группы. Условное выражение, сформулированное в разделе WHERE, может быть перенесено в раздел HAVING. Перенос условий из раздела HAVING в раздел WHERE невозможен, если условное выражение содержит агрегатные функции. Перенос условий из раздела WHERE в раздел HAVING является плохим стилем программирования - эти разделы предназначены для различных по смыслу условий (условия для строк и условия для групп строк).
Замечание. Если в разделе SELECT присутствуют агрегатные функции, то они вычисляются по-разному в зависимости от наличия раздела GROUP BY. Если раздел GROUP BY отсутствует, то результат запроса возвращает не более одной строки. Агрегатные функции вычисляются по всем строкам, удовлетворяющим условному выражению в разделе WHERE. Если раздел GROUP BY присутствует, то агрегатные функции вычисляются по отдельности для каждой группы, определенной в разделе GROUP BY.
Скалярное выражение - в качестве скалярных выражений в разделе SELECT могут выступать либо имена столбцов таблиц, входящих в раздел FROM, либо простые функции, возвращающие скалярные значения.
Функция агрегирования:= COUNT (*) | { {COUNT | MAX | MIN | SUM | AVG} ([ALL | DISTINCT] Скалярное выражение) }
Конструктор значений таблицы ::= VALUES Конструктор значений строки.,..
Конструктор значений строки:= Элемент конструктора | (Элемент конструктора.,..) | Select-выражение
Замечание. Select-выражение, используемое в конструкторе значений строки, обязано возвращать ровно одну строку.
Элемент конструктора:= Выражение для вычисления значения | NULL | DEFAULT
Синтаксис соединенных таблицВ разделе FROM оператора SELECT можно использовать соединенные таблицы. Пусть в результате некоторых операций мы получаем таблицы A и B. Такими операциями могут быть, например, оператор SELECT или другая соединенная таблица. Тогда синтаксис соединенной таблицы имеет следующий вид:
Соединенная таблица ::= Перекрестное соединение | Естественное соединение | Соединение посредством предиката | Соединение посредством имен столбцов | Соединение объединения
Тип соединения ::= INNER | LEFT [OUTER] | RIGTH [OUTER] | FULL [OUTER]
Перекрестное соединение ::= Таблица А CROSS JOIN Таблица В
Естественное соединение ::= Таблица А [NATURAL] [Тип соединения] JOIN Таблица В
Соединение посредством предиката ::= Таблица А [Тип соединения] JOIN Таблица В ON Предикат
Соединение посредством имен столбцов ::= Таблица А [Тип соединения] JOIN Таблица В USING (Имя столбца.,..)
Соединение объединения ::= Таблица А UNION JOIN Таблица В
Опишем используемые термины.
CROSS JOIN - Перекрестное соединение возвращает просто декартово произведение таблиц. Такое соединение в разделе FROM может быть заменено списком таблиц через запятую.
NATURAL JOIN - Естественное соединение производится по всем столбцам таблиц А и В, имеющим одинаковые имена. В результатирующую таблицу одинаковые столбцы вставляются только один раз.
JOIN … ON - Соединение посредством предиката соединяет строки таблиц А и В посредством указанного предиката.
JOIN … USING - Соединение посредством имен столбцов соединяет отношения подобно естественному соединению по тем общим столбцам таблиц А и Б, которые указаны в списке USING.
OUTER - Ключевое слово OUTER (внешний) не является обязательными, оно не используется ни в каких операциях с данными.
INNER - Тип соединения "внутреннее". Внутренний тип соединения используется по умолчанию, когда тип явно не задан. В таблицах А и В соединяются только те строки, для которых найдено совпадение.
LEFT (OUTER) - Тип соединения "левое (внешнее)". Левое соединение таблиц А и В включает в себя все строки из левой таблицы А и те строки из правой таблицы В, для которых обнаружено совпадение. Для строк из таблицы А, для которых не найдено соответствия в таблице В, в столбцы, извлекаемые из таблицы В, заносятся значения NULL.
RIGHT (OUTER) - Тип соединения "правое (внешнее)". Правое соединение таблиц А и В включает в себя все строки из правой таблицы В и те строки из левой таблицы А, для которых обнаружено совпадение. Для строк из таблицы В, для которых не найдено соответствия в таблице А, в столбцы, извлекаемые из таблицы А заносятся значения NULL.
FULL (OUTER) - Тип соединения "полное (внешнее)". Это комбинация левого и правого соединений. В полное соединение включаются все строки из обеих таблиц. Для совпадающих строк поля заполняются реальными значениями, для несовпадающих строк поля заполняются в соответствии с правилами левого и правого соединений.
UNION JOIN - Соединение объединения является обратным по отношению к внутреннему соединению. Оно включает только те строки из таблиц А и В, для которых не найдено совпадений. В них используются значения NULL для столбцов, полученных из другой таблицы. Если взять полное внешнее соединение и удалить из него строки, полученные в результате внутреннего соединения, то получится соединение объединения.
Использование соединенных таблиц часто облегчает восприятие оператора SELECT, особенно, когда используется естественное соединение. Если не использовать соединенные таблицы, то при выборе данных из нескольких таблиц необходимо явно указывать условия соединения в разделе WHERE. Если при этом пользователь указывает сложные критерии отбора строк, то в разделе WHERE смешиваются семантически различные понятия - как условия связи таблиц, так и условия отбора строк (см. примеры 13, 14, 15 данной главы).
Синтаксис условных выражений раздела WHEREУсловное выражение, используемое в разделе WHERE оператора SELECT должно вычисляться для каждой строки-кандидата, отбираемой оператором SELECT. Условное выражение может возвращать одно из трех значений истинности: TRUE, FALSE или UNKNOUN. Строка-кандидат отбирается в результатирующее множество строк только в том случае, если для нее условное выражение вернуло значение TRUE.
Условные выражения имеют следующий синтаксис (в целях упрощения изложения приведены не все возможные предикаты):
Условное выражение ::= [ ( ] [NOT] {Предикат сравнения | Предикат between | Предикат in | Предикат like | Предикат null | Предикат количественного сравнения | Предикат exist | Предикат unique | Предикат match | Предикат overlaps} [{AND | OR} Условное выражение] [ ) ] [IS [NOT] {TRUE | FALSE | UNKNOWN}]
Предикат сравнения ::= Конструктор значений строки {= | < | > | <= | >= | <>} Конструктор значений строки
Пример 33. Сравнение поля таблицы и скалярного значения:
POSTAV.VOLUME > 100
Пример 34. Сравнение двух сконструированных строк:
(PD.PNUM, PD.DNUM) = (1, 25)
Этот пример эквивалентен условному выражению
PD.PNUM = 1 AND PD.DNUM = 25
Предикат between ::= Конструктор значений строки [NOT] BETWEEN Конструктор значений строки AND Конструктор значений строки
Пример 35. PD.VOLUME BETWEEN 10 AND 100
Предикат in ::= Конструктор значений строки [NOT] IN {(Select-выражение) | (Выражение для вычисления значения.,..)}
Пример 36.
P.PNUM IN (SELECT PD.PNUM FROM PD WHERE PD.DNUM=2)
Пример 37.
P.PNUM IN (1, 2, 3, 5)
Предикат like ::= Выражение для вычисления значения строки-поиска [NOT] LIKE Выражение для вычисления значения строки-шаблона [ESCAPE Символ]
Замечание. Предикат LIKE производит поиск строки-поиска в строке-шаблоне. В строке-шаблоне разрешается использовать два трафаретных символа:
· Символ подчеркивания "_" может использоваться вместо любого единичного символа в строке-поиска,
· Символ процента "%" может заменять набор любых символов в строке-поиска (число символов в наборе может быть от 0 и более).
Предикат null ::= Конструктор значений строки IS [NOT] NULL
Замечание. Предикат NULL применяется специально для проверки, не равно ли проверяемое выражение null-значению.
Предикат количественного сравнения ::= Конструктор значений строки {= | < | > | <= | >= | <>} {ANY | SOME | ALL} (Select-выражение)
Замечание. Кванторы ANY и SOME являются синонимами и полностью взаимозаменяемы.
Замечание. Если указан один из кванторов ANY и SOME, то предикат количественного сравнения возвращает TRUE, если сравниваемое значение совпадает хотя бы с одним значением, возвращаемом в подзапросе (select-выражении).
Замечание. Если указан квантор ALL, то предикат количественного сравнения возвращает TRUE, если сравниваемое значение совпадает с каждым значением, возвращаемом в подзапросе (select-выражении).
Пример 38.
P.PNUM = SOME (SELECT PD.PNUM FROM PD WHERE PD.DNUM=2)
Предикат exist ::= EXIST (Select-выражение)
Замечание. Предикат EXIST возвращает значение TRUE, если результат подзапроса (select-выражения) не пуст.
Предикат unique ::= UNIQUE (Select-выражение)
Замечание. Предикат UNIQUE возвращает TRUE, если в результате подзапроса (select-выражения) нет совпадающих строк.
Предикат match ::= Конструктор значений строки MATCH [UNIQUE] [PARTIAL | FULL] (Select-выражение)
Замечание. Предикат MATCH проверяет, будет ли значение, определенное в конструкторе строки совпадать со значением любой строки, полученной в результате подзапроса.
Предикат overlaps ::= Конструктор значений строки OVERLAPS Конструктор значений строки
Замечание. Предикат OVERLAPS, является специализированным предикатом, позволяющем определить, будет ли указанный период времени перекрывать другой период времени.
Порядок выполнения оператора SELECTДля того чтобы понять, как получается результат выполнения оператора SELECT, рассмотрим концептуальную схему его выполнения. Эта схема является именно концептуальной, т.к. гарантируется, что результат будет таким, как если бы он выполнялся шаг за шагом в соответствии с этой схемой. На самом деле, реально результат получается более изощренными алгоритмами, которыми "владеет" конкретная СУБД.
Стадия 1. Выполнение одиночного оператора SELECTЕсли в операторе присутствуют ключевые слова UNION, EXCEPT и INTERSECT, то запрос разбивается на несколько независимых запросов, каждый из которых выполняется отдельно:
Шаг 1 (FROM). Вычисляется прямое декартовое произведение всех таблиц, указанных в обязательном разделе FROM. В результате шага 1 получаем таблицу A.
Шаг 2 (WHERE). Если в операторе SELECT присутствует раздел WHERE, то сканируется таблица A, полученная при выполнении шага 1. При этом для каждой строки из таблицы A вычисляется условное выражение, приведенное в разделе WHERE. Только те строки, для которых условное выражение возвращает значение TRUE, включаются в результат. Если раздел WHERE опущен, то сразу переходим к шагу 3. Если в условном выражении участвуют вложенные подзапросы, то они вычисляются в соответствии с данной концептуальной схемой. В результате шага 2 получаем таблицу B.
Шаг 3 (GROUP BY). Если в операторе SELECT присутствует раздел GROUP BY, то строки таблицы B, полученной на втором шаге, группируются в соответствии со списком группировки, приведенным в разделе GROUP BY. Если раздел GROUP BY опущен, то сразу переходим к шагу 4. В результате шага 3 получаем таблицу С.
Шаг 4 (HAVING). Если в операторе SELECT присутствует раздел HAVING, то группы, не удовлетворяющие условному выражению, приведенному в разделе HAVING, исключаются. Если раздел HAVING опущен, то сразу переходим к шагу 5. В результате шага 4 получаем таблицу D.
Шаг 5 (SELECT). Каждая группа, полученная на шаге 4, генерирует одну строку результата следующим образом. Вычисляются все скалярные выражения, указанные в разделе SELECT. По правилам использования раздела GROUP BY, такие скалярные выражения должны быть одинаковыми для всех строк внутри каждой группы. Для каждой группы вычисляются значения агрегатных функций, приведенных в разделе SELECT. Если раздел GROUP BY отсутствовал, но в разделе SELECT есть агрегатные функции, то считается, что имеется всего одна группа. Если нет ни раздела GROUP BY, ни агрегатных функций, то считается, что имеется столько групп, сколько строк отобрано к данному моменту. В результате шага 5 получаем таблицу E, содержащую столько колонок, сколько элементов приведено в разделе SELECT и столько строк, сколько отобрано групп.
Стадия 2. Выполнение операций UNION, EXCEPT, INTERSECTЕсли в операторе SELECT присутствовали ключевые слова UNION, EXCEPT и INTERSECT, то таблицы, полученные в результате выполнения 1-й стадии, объединяются, вычитаются или пересекаются.
Стадия 3. Упорядочение результатаЕсли в операторе SELECT присутствует раздел ORDER BY, то строки полученной на предыдущих шагах таблицы упорядочиваются в соответствии со списком упорядочения, приведенном в разделе ORDER BY.
Как на самом деле выполняется оператор SELECTЕсли внимательно рассмотреть приведенный выше концептуальный алгоритм вычисления результата оператора SELECT, то сразу понятно, что выполнять его непосредственно в таком виде чрезвычайно накладно. Даже на самом первом шаге, когда вычисляется декартово произведение таблиц, приведенных в разделе FROM, может получиться таблица огромных размеров, причем практически большинство строк и колонок из нее будет отброшено на следующих шагах.
На самом деле в РСУБД имеется оптимизатор, функцией которого является нахождение такого оптимального алгоритма выполнения запроса, который гарантирует получение правильного результата.
Схематично работу оптимизатора можно представить в виде последовательности нескольких шагов:
Шаг 1 (Синтаксический анализ). Поступивший запрос подвергается синтаксическому анализу. На этом шаге определяется, правильно ли вообще (с точки зрения синтаксиса SQL) сформулирован запрос. В ходе синтаксического анализа вырабатывается некоторое внутренне представление запроса, используемое на последующих шагах.
Шаг 2 (Преобразование в каноническую форму). Запрос во внутреннем представлении подвергается преобразованию в некоторую каноническую форму. При преобразовании к канонической форме используются как синтаксические, так и семантические преобразования. Синтаксические преобразования (например, приведения логических выражений к конъюнктивной или дизъюнктивной нормальной форме, замена выражений "x AND NOT x" на "FALSE", и т.п.) позволяют получить новое внутренне представление запроса, синтаксически эквивалентное исходному, но стандартное в некотором смысле. Семантические преобразования используют дополнительные знания, которыми владеет система, например, ограничения целостности. В результате семантических преобразований получается запрос, синтаксически не эквивалентный исходному, но дающий тот же самый результат.
Шаг 3 (Генерация планов выполнения запроса и выбор оптимального плана). На этом шаге оптимизатор генерирует множество возможных планов выполнения запроса. Каждый план строится как комбинация низкоуровневых процедур доступа к данным из таблиц, методам соединения таблиц. Из всех сгенерированных планов выбирается план, обладающий минимальной стоимостью. При этом анализируются данные о наличии индексов у таблиц, статистических данных о распределении значений в таблицах, и т.п. Стоимость плана это, как правило, сумма стоимостей выполнения отдельных низкоуровневых процедур, которые используются для его выполнения. В стоимость выполнения отдельной процедуры могут входить оценки количества обращений к дискам, степень загруженности процессора и другие параметры.
Шаг 4. (Выполнение плана запроса). На этом шаге план, выбранный на предыдущем шаге, передается на реальное выполнение.
Во многом качество конкретной СУБД определяется качеством ее оптимизатора. Хороший оптимизатор может повысить скорость выполнения запроса на несколько порядков. Качество оптимизатора определяется тем, какие методы преобразований он может использовать, какой статистической и иной информацией о таблицах он располагает, какие методы для оценки стоимости выполнения плана он знает.
Реализация реляционной алгебры средствами оператора SELECT (Реляционная полнота SQL)Для того, чтобы показать, что язык SQL является реляционно полным, нужно показать, что любой реляционный оператор может быть выражен средствами SQL. На самом деле достаточно показать, что средствами SQL можно выразить любой из примитивных реляционных операторов.
Оператор декартового произведенияРеляционная алгебра: ![]()
Оператор SQL:
SELECT A.Поле1, A.Поле2, …, B.Поле1, B.Поле2, …
FROM A, B;
или
SELECT A.Поле1, A.Поле2, …, B.Поле1, B.Поле2, …
FROM A CROSS JOIN B; Оператор проекции
Реляционная алгебра: ![]()
Оператор SQL:
SELECT DISTINCT X, Y, …, Z
FROM A; Оператор выборки
Реляционная алгебра: ![]() ,
,
Оператор SQL:
SELECT *
FROM A
WHERE c; Оператор объединения
Реляционная алгебра: ![]()
Оператор SQL:
SELECT *
FROM A
UNION
SELECT *
FROM B; Оператор вычитания
Реляционная алгебра: ![]()
Оператор SQL:
SELECT *
FROM A
EXCEPT
SELECT *
FROM B
Реляционный оператор переименования RENAME выражается при помощи ключевого слова AS в списке отбираемых полей оператора SELECT. Таким образом, язык SQL является реляционно полным.
Остальные операторы реляционной алгебры (соединение, пересечение, деление) выражаются через примитивные, следовательно, могут быть выражены операторами SQL. Тем не менее, для практических целей приведем их.
Оператор соединенияРеляционная алгебра: ![]()
Оператор SQL:
SELECT A.Поле1, A.Поле2, …, B.Поле1, B.Поле2, …
FROM A, B
WHERE c;
или
SELECT A.Поле1, A.Поле2, …, B.Поле1, B.Поле2, …
FROM A CROSS JOIN B
WHERE c; Оператор пересечения
Реляционная алгебра: ![]()
Оператор SQL:
SELECT *
FROM A
INTERSECT
SELECT *
FROM B; Оператор деления
Реляционная алгебра: ![]()
Оператор SQL:
SELECT DISTINCT A.X
FROM A
WHERE NOT EXIST
(SELECT *
FROM B
WHERE NOT EXIST
(SELECT *
FROM A A1
WHERE
A1.X = A.X AND
A1.Y = B.Y));
Замечание. Оператор SQL, реализующий деление отношений трудно запомнить, поэтому дадим пример эквивалентного преобразования выражений, представляющих суть запроса.
Пусть отношение A содержит данные о поставках деталей, отношение B содержит список всех деталей, которые могут поставляться. Атрибут X является номером поставщика, атрибут Y является номером детали.
Разделить отношение A на отношение B означает в данном примере "отобрать номера поставщиков, которые поставляют все детали".
Преобразуем текст выражения:
"Отобрать номера поставщиков, которые поставляют все детали" эквивалентно
"Отобрать те номера поставщиков из таблицы A, для которых не существует непоставляемых деталей в таблице B" эквивалентно
"Отобрать те номера поставщиков из таблицы A, для которых не существует тех номеров деталей из таблицы B, которые не поставляются этим поставщиком" эквивалентно
"Отобрать те номера поставщиков из таблицы A, для которых не существует тех номеров деталей из таблицы B, для которых не существует записей о поставках в таблице A для этого поставщика и этой детали".
Последнее выражение дословно переводится на язык SQL. При переводе выражения на язык SQL нужно учесть, что во внутреннем подзапросе таблица A должна быть переименована, для того чтобы отличать ее от экземпляра этой же таблицы, используемой во внешнем запросе.
ВыводыФактически стандартным языком доступа к базам данных в настоящее время стал язык SQL (Structured Query Language).
Язык SQL оперирует терминами, несколько отличающимися от терминов реляционной теории, например, вместо "отношений" используются "таблицы", вместо "кортежей" - "строки", вместо "атрибутов" - "колонки" или "столбцы".
Стандарт языка SQL, хотя и основан на реляционной теории, но во многих местах отходит он нее.
Основу языка SQL составляют операторы, условно разбитые не несколько групп по выполняемым функциям:
· Операторы DDL (Data Definition Language) - операторы определения объектов базы данных.
· Операторы DML (Data Manipulation Language) - операторы манипулирования данными.
· Операторы защиты и управления данными, и др.
Одним из основных операторов DML является оператор SELECT, позволяющий извлекать данные из таблиц и получать ответы на различные запросы. Оператор SELECT содержит в себе все возможности реляционной алгебры. Это означает, что любой оператор реляционной алгебры может быть выражен при помощи подходящего оператора SELECT. Этим доказывается реляционная полнота языка SQL.
Различают концептуальную схему выполнения оператора SELECT и фактическую схему его выполнения. Концептуальная схема описывает, в какой логической последовательности должны выполняться операции, чтобы получить результат. При реальном выполнении оператора SELECT на первый план выступает достижение максимальной скорости выполнения запроса. Для этого используется оптимизатор, который, анализируя различные планы выполнения запроса, выбирает наилучший из них.
Лекция 6. Современные направления исследований и разработок баз данных
Концепция хранилища данных определяет процесс сбора, отсеивания, предварительной обработки и накопления данных с целью
· долговременного хранения данных (1);
· предоставления результирующей информации пользователям в удобной форме для статистического анализа и создания аналитических отчетов (2).
Концепция OLAP - концепция комплексного многомерного анализа данных, накопленных в хранилище. Теоретически средства OLAP можно применять и непосредственно к оперативным данным или их точным копиям (чтобы не мешать оперативным пользователям). Но в этом случае мы рискуем наступить на свои грабли, поскольку беремся анализировать оперативные данные, которые напрямую для анализа непригодны.
Замечание: термин OLAP очень популярен в настоящее время и OLAP-системой зачастую называют любую DSS-систему, основанную на концепции хранилищ данных и обеспечивающих малое время выполнение (On-Line) аналитических запросов, не зависимо от того, используется ли многомерный анализ данных. Что не совсем верно.
Концепция хранилища данных
Какова побудительная причина появление концепции хранилищ данных?
Казалось бы, зачем строить хранилища данных - ведь они содержат заведомо избыточную информацию, которая и так имеется в базах или файлах оперативных систем? Ответить можно кратко: анализировать данные оперативных систем напрямую невозможно или очень затруднительно. Это объясняется рядом причинами, в том числе
· разрозненностью данных (OLTP-системы, текстовые отчеты, xls-файлы);
· хранением их в форматах различных СУБД и в разных узлах корпоративной сети.
Но даже если на предприятии все данные хранятся на центральном сервере БД (что бывает крайне редко), аналитик почти наверняка не разберется в их сложных, подчас запутанных структурах.
Есть и еще одна причина, оправдывающая появление отдельного хранилища - сложные аналитические запросы к оперативной информации тормозят текущую работу компании, надолго блокируя таблицы и захватывая ресурсы сервера.
Можно констатировать, что практически в любой организации сложилась парадоксальная ситуация: - информация вроде бы, где-то и есть, её даже слишком много, но она неструктурированна, несогласованна, разрознена, не всегда достоверна, её практически невозможно найти и получить. В результате можно говорить об отсутствие информации при наличии и даже избытке.
Для того, чтобы извлекать полезную информацию из данных, они должны быть организованы способом, отличным от принятого в OLTP-системах Почему?
1. В OLTP-системах используются нормализованные таблицы базы данных. Нормализация эффективна, если отношения часто перестраиваются (вставка,. . .), но дает отрицательный эффект в случае операции выборки (особенно в случае сложных запросов). А в DSS-системах только операции выборки, и данные редко меняются, поэтому данные целесообразно хранить в виде слабо нормализованных отношений, содержащих заранее вычисленные основные итоговые данные. Большая избыточность и связанные с ней проблемы тут не страшны, т.к. обновление происходит только в момент загрузки новой порции данных. При этом происходит как добавление новых данных, так и пересчет итогов.
2. Выполнение некоторых аналитических запросов требует хронологической упорядоченности данных. Реляционная модель не предполагает существования порядка записей в таблицах.
3. В случае аналитических запросов чаще используются не детальные, а обобщенные (агрегированные данные).
В результате данные, применяемые для анализа, стали выделять в отдельные специальные базы данных, впоследствии получивших название хранилищ данных (Data Warehouse).
Хранилище данных (определение Билла Инмона(Bill Inmon)) - предметно-ориентированный, интегрированный, привязанный ко времени и неизменяемый набор данных, предназначенный для поддержки принятия решений. Базовые требования к хранилищу данных:
· Ориентация на предметную область. Хранилище должно разрабатываться с учетом специфики предметной области (клиенты, товары, продажи), а не прикладных областей деятельности (выписка счетов, контроль запасов, продажа товаров).
· Интегрированность и внутренняя непротиворечивость. Поскольку данные в хранилище поступают из разных источников (OLTP-системы, архивы и пр.), необходимо привести их к единому формату (дата: 5 января, 5.01,:). В процессе загрузки хранилища должна быть обеспечена, очистка и согласованность данных.
· Привязка ко времени. Учет хронологии достигается введением атрибутов "Дата" и "Время". Упорядочение по этим атрибутам позволяет сократить время выполнения аналитических запросов.
· Неизменяемость. Данные не обновляются в оперативном режиме, а лишь регулярно пополняются из систем оперативной обработки по заданной дисциплине.
· Поддержка высокой скорости получения данных из хранилища.
· Возможность получения и сравнения так называемых срезов данных (slice and dice);
· Полнота и достоверность хранимых данных;
· Поддержка качественного процесса пополнения данных.
OLAP-технология
Термин OLAP был предложен в 1993 г. Эдвардом Коддом (E. Codd - автор реляционной модели данных) По Коду OLAP-технология - это технология комплексного динамического синтеза, анализа и консолидации больших объемов многомерных данных. Он же сформулировал 12 принципов OLAP, которые позже были переработано в так называемый тест FASMI:
· Fast (быстрый) - предоставление пользователю результатов анализа за приемлемое время (обычно не более 5 с), пусть даже ценой менее детального анализа;
· Analysis (анализ) - возможность осуществления любого логического и статистического анализа, характерного для данного приложения, и его сохранения в доступном для конечного пользователя виде;
· Shared (разделяемой) - многопользовательский доступ к данным с поддержкой соответствующих механизмов блокировок и средств авторизованного доступа;
· Multidimensional (многомерной) - многомерное концептуальное представление данных, включая полную поддержку для иерархий и множественных иерархий (ключевое требование OLAP);
· Information (информации) - возможность обращаться к любой нужной информации независимо от ее объема и места хранения.
![]()
OLAP-технология представляет для анализа данные в виде многомерных (и, следовательно, нереляционных) наборов данных, называемых многомерными кубами (гиперкуб, метакуб, кубом фактов), оси которого содержат параметры, а ячейки - зависящие от них агрегатные данные
При том гиперкуб является концептуальной логической моделью организации данных, а не физической реализацией их хранения, поскольку храниться такие данные могут и в реляционных таблицах ("реляционные БД были, есть и будут наиболее подходящей технологией для хранения корпорационных данных" - E. Codd).
По Кодду, многомерное концептуальное представление (multi-dimensional conceptual view) представляет собой множественную перспективу, состоящую из нескольких независимых измерений, вдоль которых могут быть проанализированы определенные совокупности данных. Одновременный анализ по нескольким измерениям определяется как многомерный анализ. Осями многомерной системы координат служат основные атрибуты анализируемого бизнес-процесса (то, по чему ведется анализ). Например, для продаж это могут быть тип товара, регион, тип покупателя. В качестве одного из измерений используется время. На пересечениях осей - измерений (dimensions) - находятся данные, количественно характеризующие процесс - меры (measures): суммы и иные агрегатные функции (min, max, avg, дисперсия, ср. отклонение и пр.). Каждое измерение включает направления консолидации данных, состоящие из серии последовательных уровней обобщения (уровней иерархии), где каждый вышестоящий уровень соответствует большей степени агрегации данных по соответствующему измерению (различные уровни их детализации). В этом случае становится возможным произвольный выбор желаемого уровня детализации информации по каждому из измерений.
Благодаря такой модели данных пользователи могут формулировать сложные запросы, генерировать отчеты, получать подмножества данных.
Пример. Трехмерный куб, где в качестве фактов использованы суммы продаж, а в качестве измерений - время, товар и магазин, определенных на разных уровнях группировки: товары группируются по категориям, магазины - по странам, а данные о времени совершения операций - по месяцам.
Значения, "откладываемые" вдоль измерений, называются членами или метками (members). Метки используются в операциях манипулирования измерениями.
Метки могут объединяться в иерархии, состоящие из одного или нескольких уровней детализации (levels). Например, метки измерения "Магазин" (Store) естественно объединяются в иерархию с уровнями:
В соответствии с уровнями иерархии вычисляются агрегатные значения, например объем продаж для USA (уровень "Country") или для штата California (уровень "State"). В одном измерении можно реализовать более одной иерархии - скажем, для времени: {Год, Квартал, Месяц, День} и {Год, Неделя, День}.
Поскольку в рассмотренном примере в общем случае в каждой стране может быть несколько городов, а в городе - несколько клиентов, можно говорить об иерархиях значений в измерении - регион. В этом случае на первом уровне иерархии располагаются страны, на втором - города, а на третьем - клиенты.
Иерархии могут быть сбалансированными (balanced), как, например, иерархия, представленная выше (такова же иерархии, основанные на данных типа "дата-время"), и несбалансированными (unbalanced). Типичный пример несбалансированной иерархии - иерархия типа "начальник-подчиненный".
Иногда для таких иерархий используется термин Parent-child hierarchy.
Существуют также иерархии, занимающие промежуточное положение между сбалансированными и несбалансированными (они обозначаются термином ragged - "неровный"). Обычно они содержат такие члены, логические "родители" которых находятся не на непосредственно вышестоящем уровне (например, в географической иерархии есть уровни Country, City и State, но при этом в наборе данных имеются страны, не имеющие штатов или регионов между уровнями Country и City).
Аналитические OLAP-операции:
· Сечение. При выполнении операции сечения формируется подмножество гиперкуба, в котором значение одного или более измерений фиксировано (значение параметров для фиксированного, например, месяца).
· Вращение (rolling). Операция вращения изменяет порядок представления измерений, обеспечивая представление метакуба в более удобной для восприятия форме.
· Консолидация (rolling up). Включает такие обобщающие операции, как простое суммирование значений (свертка) или расчет с использованием сложных вычислений, включающих другие связанные данные. Например, показателю для отдельных компаний могут быть просто просуммированы с целью получения показателей для каждого города, а показатели для городов могут быть "свернуты" до показателей по отдельным странам.
· Операция спуска (drill doun). Операция, обратная консолидации, которая включает отображение подробных сведений для рассматриваемых консолидированных данных.
· Разбиение с поворотом (slicing and dicing). Позволяет получить представление данных с разных точек зрения. Например, один срез данных о доходах может содержать все сведения о доходах от продаж товаров указанного типа по каждому городу. Другой срез может представлять данные о доходах отдельной компании в каждом из городов.
Поддержка многомерной модели данных и выполнение многомерного анализа данных осуществляются отдельным приложением или процессом, называемым OLAP-сервером. Клиентские приложения могут запрашивать требуемое многомерное представление и в ответ получать те или иные данные. При этом OLAP-серверы могут хранить многомерные данные разными способами
Модели хранилища данных
Обеспечивая многомерное концептуальное представление со стороны пользовательского интерфейса к исходной базе данных, все продукты OLAP делятся на несколько классов по типу исходной БД. Многомерный гиперкуб, используемый в OLAP-технологии, может быть реализован в рамках реляционной модели или существовать как отдельная база данных специальной многомерной структуры. В зависимости от этого принято различать многомерный (MOLAP) и реляционный (ROLAP) подходы к построению хранилища данных.
MOLAP (Multidimensional OLAP)
В MOLAP-модели многомерное представление данных реализуется физически. В специализированных СУБД, основанных на многомерном представлении данных, данные организованы не в форме реляционных таблиц, а в виде упорядоченных многомерных массивов:
Похожие работы




... и в то же время мощного математического аппарата, опирающегося главным образом на теорию множеств и математическую логику и обеспечивающего теоретический базис реляционного подхода к организации баз данных; 3. возможность ненавигационного манипулирования данными без необходимости знания конкретной физической организации баз данных во внешней памяти. Однако реляционные системы далеко не ...
... функционирования. На данный момент существует достаточно большое количество разновидностей информационных систем. Классификация информационных систем обычно осуществляется на основе каких-либо выделенных признаков. Например, с точки зрения управленческого уровня, на котором осуществляется использование ИС, принято делить корпоративные ИС на следующие виды: 1. ИС для обеспечения текущих бизнес- ...
... : - между потребностями современного информационного общества в качественно новых членах, обладающих творческим мышлением и владеющих информационными технологиями и ограниченными возможностями современной школы в этом направлении; - между совершенствованием содержательной основы информационных технологий обучения и отсутствием научно-обоснованных исследований по данной проблеме. Информационные ...
... . Такая стратегия характерна для крупных организаций. Таким образом, каждая организация, учреждение, фирма проходит свой собственный путь с целью совершенствования документационного обеспечения управления на базе внедрения новых информационных технологий. Для мелких и средних предприятий целесообразен первый подход. Он является в настоящее время наиболее распространенным. В крупных организациях с ...
0 комментариев