Навигация
4.1.2 Индексы
Индексы – одно из самых мощных средств, доступных разработчику базы данных. Индекс – это вспомогательная структура, позволяющая повышать производительность запросов за счет снижения количества операций ввода-вывода, необходимых для поиска запрошенных данных; т.е. индекс позволяет системе Microsoft SQL Server 2000 находить данные, используя меньшее число операций ввода-вывода, чем при поиске данных путем доступа только к таблице базы данных. Если для поиска строки данных вы используете индекс таблицы базы данных, SQL Server может быстро определить, где хранятся эти данные и сразу считать эти данные. Таким образом, индексы таблиц базы данных во многом похожи на индексы (алфавитные указатели) в книгах: в обоих случаях обеспечивается быстрый доступ к большим объемам информации.
В зависимости от типа индекса он хранится вместе с данными или отдельно от данных. В системах без индексов весь поиск данных должен выполняться путем сканирования таблиц. При сканировании таблиц приходится читать все данные и сравнивать их с запрашиваемыми данными. Обычно стараются обойтись без сканирования таблиц – из-за количества операций ввода-вывода, которое для этого требуется: сканирование больших таблиц может занимать длительный период времени и требовать использования большого количества системных ресурсов. Используя индекс, вы можете кардинально снизить количество операций ввода-вывода, ускорив доступ к данным и освободив системные ресурсы для других операций.
Структура индексов ориентирована на быстрый возврат результирующих наборов. SQL Server поддерживает два типа индексов: кластерные и некластерные. Индексы могут быть созданы для одного или нескольких столбцов таблицы или представления. Индексированные таблицы поддерживаются всеми редакциями SQL Server 2000, а индексированные представления — только SQL Server Enterprise Edition и SQL Server Developer Edition. Интенсивность использования системных ресурсов и производительность при поиске данных зависит от свойств индекса. Оптимизатор запросов использует индекс, если это позволяет повысить производительность запроса.
В SQL Server индекс помогает механизму БД найти нужную запись.Индекс БД формируется из значений одного или нескольких столбцов таблицы (которые в этом случае называются ключом индекса) и указателей на соответствующие записи таблицы. При исполнении запроса с ключом индекса оптимизатор запросов использует индекс для поиска записей, соответствующих запросу.
Как уже говорилось выше, существует два типа индексов: кластерные и некластерные. Структура обоих типов - В-дерево. На листовом уровне В-дерева кластерный индекс содержит записи таблицы, а некластерный — указатели на записи. Если на таблице построен кластерный индекс, то некластерный можно использовать при поиске данных как вспомогательный. В большинстве случаев для таблицы сначала следует создавать кластерный индекс, а затем — один или несколько некластерных.
У таблицы или представления должен быть только один кластерный индекс, так как ключ кластерного индекса физически упорядочивает таблицу или представление. Этот тип индексов особенно эффективен при исполнении запросов, поскольку записи (или страницы данных) хранятся на листовом уровне В-дерева. Порядком сортировки и местом хранения кластерный индекс напоминает словарь с его алфавитным порядком сортировки слов и наличием определений после каждого слова.
При создании ограничения primary key в таблице, где еще нет кластерного индекса, SQL Server использует для создания ключа кластерного индекса столбец с первичным ключом таблицы. Если в таблице уже есть кластерный индекс, то для столбца с ограничением primary key создается некластерный индекс. Столбец с первичным ключом полезен для индекса, поскольку в нем содержатся гарантированно уникальные значения. В этом случае размер В-дерева меньше, чем при использовании избыточных значений, и стало быть структуры для поиска работают более эффективно.
Для таблицы или представления можно создать до 250 некластерных индексов или 249 некластерных и 1 кластерный. Прежде чем создавать некластерные индексы для представления, необходимо создать уникальный кластерный индекс. Однако это ограничение не относится к таблицам. Некластерный индекс напоминает предметный указатель книги, где у каждого элемента проставлена соответствующая страница. Базы данных используют некластерный индекс для поиска записей, соответствующих запросу. Если в таблице нет кластерного индекса, таблица является неупорядоченной и называется кучей. Некластерный индекс, созданный для кучи, содержит указатели на записи таблицы. Каждый элемент страницы индекса содержит идентификатор строки {row ID,RID) — указатель на табличную строку в куче, содержащий номер страницы, номер файла и номер ячейки. При наличии кластерного индекса страницы некластерного индекса содержат ключи кластерного индекса, а не R1D. Указатель индекса (как RID, так и ключ индекса) называется закладкой.
Но поскольку индекс создается в отсортированном порядке, любые изменения в данных могут приводить к дополнительной нагрузке на систему. Например, если вставка приводит к созданию новой строки индекса, которую нужно поместить в узел-лист, который уже заполнен до конца, то SQL Server должен создать место для новой строки индекса. Он выполняет эту задачу, перемещая приблизительно половину строк узла-листа на другую страницу. Это перемещение данных называется расщеплением страницы. Расщепление страницы на одном уровне дерева может приводить к каскадным расщеплениям на более высоких уровнях. Расщепления страниц можно избежать путем соответствующей настройки коэффициента заполнения.
Похожие работы
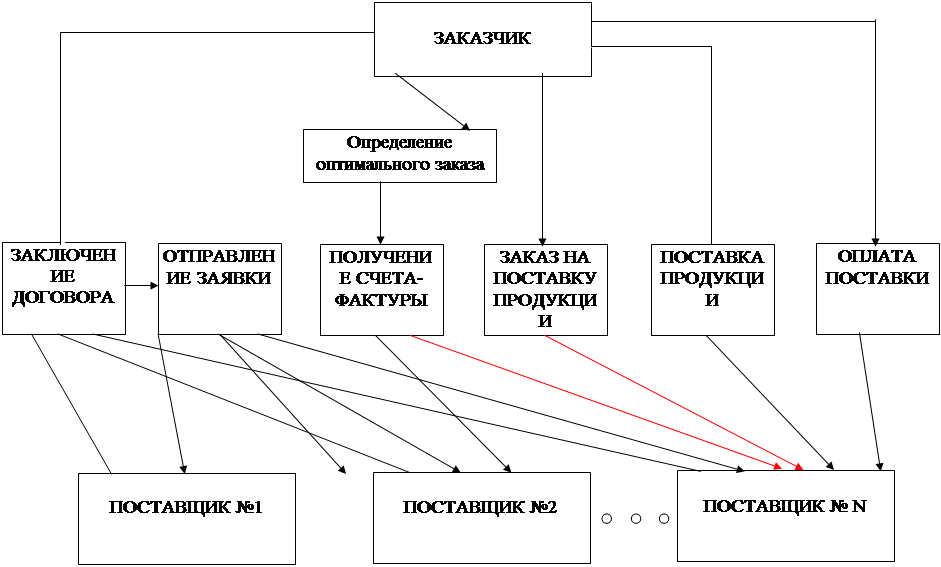
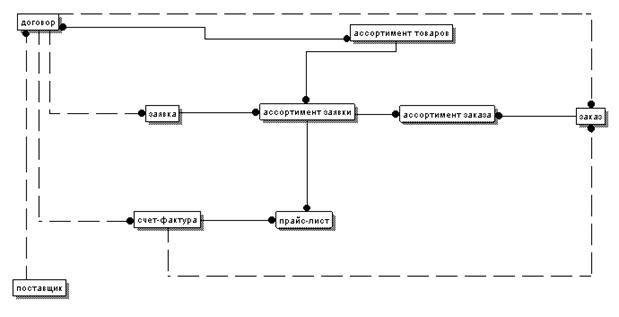



... БД). Логическая модель данных представлена в виде ER-диаграмы на рис. 2.2. Рис 2.2 ER-диаграмма модели данных АСИС “Учет поставок” 3. Проектирование алгоритмов справочно-информационной системы учета и контроля поставок на предприятие. Алгоритмизация в самом общем виде может быть определена как процесс направленного действия проектировщика (группы ...
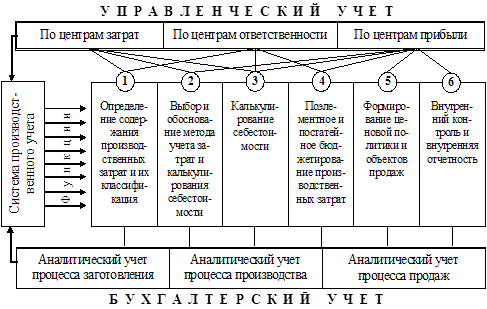
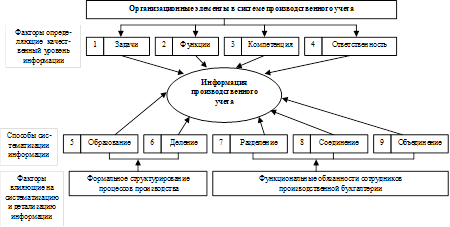
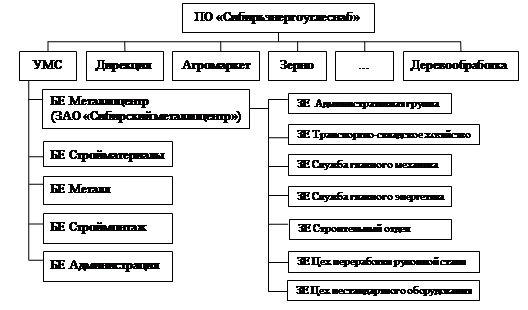
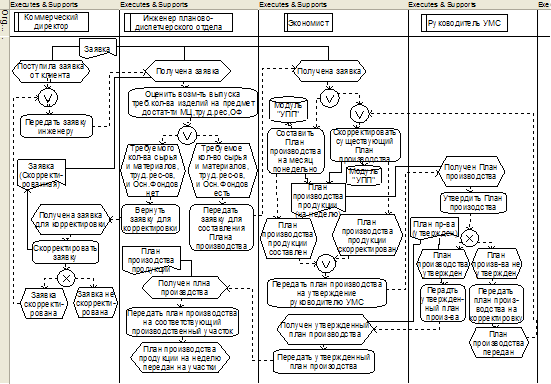
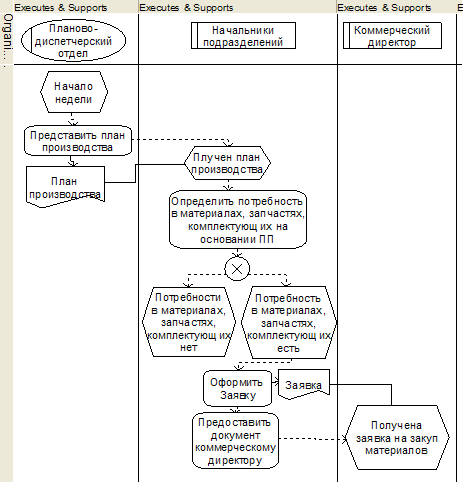
... ; - контроль соответствия фактических и плановых данных об объеме производства; - анализ отклонений фактических данных от установленных плановых показателей. 3. Автоматизированная система учета производственного процесса металлоцентра 3.1 Программно-технические средства общего назначения Основным программным обеспечением всех, без исключений, компьютеров ИС является операционная ...
0 комментариев