Навигация
1024 Мб ОЗУ
Компилятор Borland Delphi Enterprise, version 6.0 (Build 6.163)
Фрагмент кода тестируемой программы приведем в листинге 7.
|

Понятно, что такой замер времени даст нам весьма расплывчатые результаты, так как напрямую зависит от характеристик и загрузки процессора. Поэтому во время проведения эксперимента, отключались все сторонние и фоновые приложения, которые не влияют на работу программы. При запуске одной и той же задачи мы можем получить разное время, поэтому совершается несколько запусков, из которых выбирается наилучший результат.
2.2. Результаты и анализ эксперимента.Эксперимент проводился для четырех алгоритмов – представителей классов алгоритмов. Так как все алгоритмы ставились в одинаковые условия, то можно провести их сравнительный анализ. Заметим, что данный анализ применим только для данных параметров поиска, и при иных условиях может отличаться.
Результаты эксперимента занесем в таблицу (Табл. 3).
| Алгоритм | Время выполнения | ||
| Длина ≤10 | Длина ≤100 | Длина ≤250 | |
| Послед. поиск | 15 | 93 | 234 |
| Алгоритм Рабина (Хеш – сумма кодов) | 15 | 63 | 93 |
| КМП | 5 | 30 | 50 |
| БМ | 31 | 31 | 32 |
Как и предполагалось, алгоритм Бойера – Мура справился с экспериментальной задачей быстрее остальных. Следует, однако, заметить, что его эффективность растет лишь с увеличением длины строки и, соответственно, длины образца. Так при длине строки меньшей или равной 10 символов, он показал себя хуже, чем последовательный поиск. Аналогичные результаты показывает и алгоритм КМП, как для коротких, так и для длинных слов. Его можно использовать как универсальный, когда неизвестны длины строки и образца.
Алгоритм Рабина, при его схожести с последовательным работает быстрее, а его простота и малые трудозатраты на реализацию, делают его привлекательным для использования в неспециальных программах.
Наихудший результат показал алгоритм последовательного поиска. Как предполагалось лишь при небольшом увеличении длины строки, он работает в разы медленнее остальных алгоритмов.
В данный эксперимент не включен алгоритм поиска с помощью конечного автомата, т.к. мы используем алфавит, состоящий из 66 букв русского алфавита, и построенный автомат был бы слишком громоздок. Эффективность этого алгоритма возрастает при малом количестве букв в алфавите.
Заключение.
Мы рассмотрели различные алгоритмы поиска подстроки в строке, сделали их анализ. Результаты можно представить в таблице (Табл. 4).
| Алгоритм | Время на пред. обработку | Среднее время поиска | Худшее время поиска | Затраты памяти | Время работы (мс) при длине строки ≤250 | Примечания |
| Алгоритмы основанные на алгоритме последовательного поиска | ||||||
| Алгоритм прямого поиска | Нет | O((m-n+1)*n+1)/2 | O((m-n+1)*n+1) | Нет | 234 | Mалые трудозатраты на программу, малая эффективность. |
| Алгоритм Рабина | Нет | O(m+n) | O((m-n+1)*n+1) | Нет | 93 | |
| Алгоритм Кнута-Морриса-Пратта | ||||||
| КМП | O(m) | O(n+m) | O(n+m) | O(m) | 31 | Универсальный алгоритм, если неизвестна длина образца |
| Алгоритм Бойера-Мура | ||||||
| БМ | O(m+s) | O(n+m) | O(n*m) | O(m+s) | 32 | Алгоритмы этой группы наиболее эффективны в обычных ситуациях. Быстродействие повышается при увеличении образца или алфавита. |
Исходя из полученных результатов, видно, что алгоритм Бойера – Мура является ведущим по всем параметрам, казалось бы, найден самый эффективный алгоритм. Но, как показывает эксперимент, алгоритм Кнута – Мориса - Пратта, превосходит алгоритм БМ на небольших длинах образца. Поэтому я не могу сделать вывод, что какой-то из алгоритмов является самым оптимальным. Каждый алгоритм позволяет эффективно действовать лишь для своего класса задач, об этом еще говорят различные узконаправленные улучшения. Алгоритм поиска подстроки в строке следует выбирать только после точной постановки задачи, которые должна выполнять программа.
Сделав такой вывод, мы выполнили цель данной работы, т.к. для различных классов задач был выделен свой эффективный алгоритм.
Библиографический список.
1). Kurtz, St. Fundamental Algorithms For A Declarative Pattern Matching System [Текст]. – Bielefeld:. Universität Bielefeld, 1995. – 238 с.
2). Lecro, T. Exact string matching algorithms [Электронный ресурс]. Режим доступа http://algolist.manual.ru/
3). Ахметов И. Поиск подстрок с помощью конечных автоматов [Текст]: Курсовая работа.- С-П государственный университет информационных технологий, механики и оптики.
4). Ахо, Альфред Структура данных и алгоритмы [Текст]. – М.: Издательский дом «Вильямс», 2000. - 384 с.
5). Белоусов А. Дискретная математика [Текст]. – М.: Издательство МГТУ им. Н.Э. Баумана, 2001. – 744 с.
6). Брайан, К. Практика программирования [Текст].- СПб:. Невский диалект, 2001. - 381 с.
7). Вирт, Н. Алгоритмы и структуры данных [Текст].– М:. Мир, 1989. – 360 с.
8). Гилл, Арт. Введение в теорию конечных автоматов [Текст]. – М., 1966. - 272 с.
9). Глушаков С. Программирование Web – страниц [Текст]. – М.: ООО «Издательство АСТ», 2003. – 387 с.
10). Кнут, Д. Искусство программирования на ЭВМ [Текст]: Том 3. – М:. Мир, 1978. – 356 с.
11). Матрос Д. Элементы абстрактной и компьютерной алгебры: Учеб. пособие для студ. педвузов [Текст]. – М.: Издательский центр «Академия», 2004. – 240 с.
12). Успенский В. Теория алгоритмов: основные открытия и приложения [Текст]. – М.: Наука, 1987. – 288 с.
13). Шень, А. Программирование: теоремы и задачи [Текст]. – М.: Московский центр непрерывного математического образования, 1995.
14). Кормен, Т. Алгоритмы: построение и анализ [Текст]/ Т. Кормен, Ч. Лейзерсон, Р. Ривест - М.: МЦНМО, 2002. М.: МЦНМО, 2002.
Похожие работы
... - код не совпадает, сравнение не проводим. QWERYTEWEQWERTY FS = 25 - [E] + [Y] = 25 - 3 + 6 = 28 - код совпадает, полное сравнение совпадает. Ура! Текст программы: Program FSISHF; {поиск подстроки в строке} Const NStr = 30000; NSub = 3000; Var FStr : array[1..NStr] of char; FSub : array[1..NSub] of char; {substring} FSum, NSum : longint; {Контрольная сумма} Spec, Work : word; ...
... (Robert S. Boyer) и Муром (J. Strother Moore), считается наиболее быстрым среди алгоритмов общего назначения, предназначенных для поиска подстроки в строке. Прежде чем рассмотреть работу этого алгоритма, уточним некоторые термины. Под строкой мы будем понимать всю последовательность символов текста. Собственно говоря, речь не обязательно должна идти именно о тексте. В общем случае строка – это ...
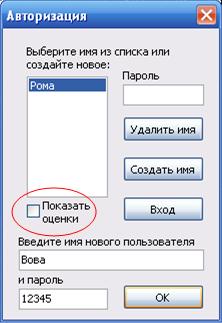
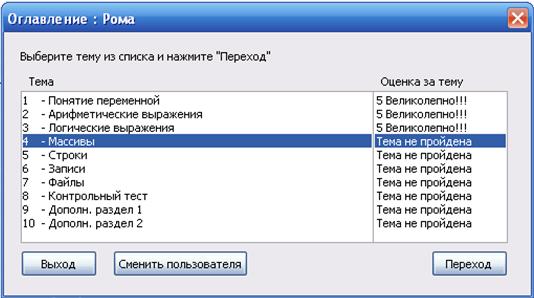
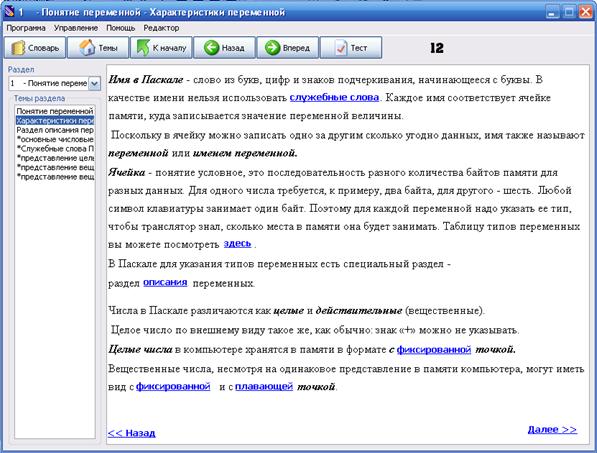
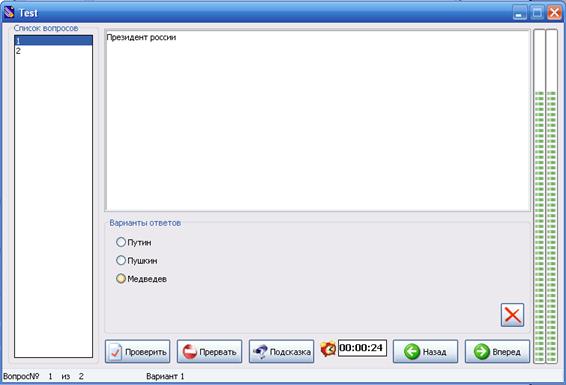
... какой либо ситуации - Определить результат действия программы. На основании сделанных выводов решено создать дополнительное обучающее средство в виде обучающей программы, поддерживающей индивидуальное изучение всех вопросов темы, а также, дополнительные сведения о типах данных. Кроме того, в программу будет встроен блок самоконтроля, поддерживающий проверку усвоения каждой изучаемой ...

... шкалы оценка пертинентности // НТИ. Сер. 2.- 1992.-№5.-С.19-27 Кноп К. Поиск в Интернете как хроническое заболевание // Мир Internet. - 2002. - N 10. - С. 33-35 Конжаев А. Стратегия информационного поиска // http://www.msiu.ru. Попов С. Поиск информации и принятие решения // НТИ. Сер.2.-2001.-№1.-С.1-4 Степанов В.К Русскоязычные поисковые механизмы в Интернет // ComputerWorld Россия.-1997.-N11 ...
0 комментариев