Навигация
Выбор способа реализации транслятора
84334
знака
30
таблиц
0
изображений
1.3 Выбор способа реализации транслятора.
Первым очевидным элементом, присутствующим во всех таких ОС, является компилятор языка “С”, на котором, собственно, и написана операционная система “UNIX”. Но язык “С” является достаточно сложным языком и не все пользователи знакомы с ним. В тоже время, в ОС “UNIX” существуют другие средства написания программ: это генераторы программ LEX и YACC. Описание их команд настолько просто и логично, что позволяет вносить коррективы в существующую программу не имея специальной подготовки, и, возможно, даже не будучи знакомым с описанием этих средств, имея только текст исходной программы.
Заключение.
Выявлена необходимость создания программы транслятора, так как существующие на данный момент программы не удовлетворяет предъявляемым требованиям. В качестве конечного формата выбран гипертекстовый формат HTML, как наиболее полно соответствующий нашим целям, широко распространенный и простой в использовании. В качестве средства создания программ выбраны генераторы программ Lex и Yacc благодаря легкости освоения и полной переносимости программ, написанных на их основе, в среде UNIX.
2. Проектирование транслятораПроектирование программы транслятора с использованием генераторов программ Lex и Yacc имеет свои особенности, независящие от конкретных форматов, с которыми будет работать разрабатываемый транслятор.
Разработав общий маршрут проектирования на основе этих средств программирования, можно впоследствии проектировать подобные задачи быстро и без лишних затрат.
2.1 Схема разработки транслятора.Сначала с помощью генератора программ Lex строится лексический анализатор. В задачу лексического анализатора входит полное поглощение входного файла (потока) и передача в синтаксический анализатор найденных лексем, а также некоторых необходимых данных. Например, может быть найдена некоторая лексема NUMBER, а в качестве данных будет передано числовое значение найденного числа или цифры, либо возможна ситуация при которой в качестве лексемы выбирается команда, а данные, сопутствующие этой команде, передаются не как лексемы, а каким-либо другим путем.
Затем строится синтаксический анализатор с помощью генератора программ YACC. В синтаксическом анализаторе описываются правила, с помощью которых будет происходить преобразование текста. Правила опираются на полученные из лексического анализатора лексемы.
Кроме того, возможно, что в формате, в который происходит преобразование, могут требоваться какие-либо элементы, не зависящие от текста, например, заголовок формата и команды, завершающие текст. Эти элементы должны быть вставлены либо на этапе синтаксического анализа, и процедура их вставки будет частью синтаксического анализатора, либо они будут вставляться головной программой, которая и будет вызывать программу синтаксического анализа.
Компиляция модулей (лексического анализатора, синтаксического анализатора и головной программы) происходит в следующем порядке:
Спецификация синтаксического анализатора с помощью генератора программ Yacc преобразуется в программу на языке C. При этом создается файл с описанием лексем, обрабатываемых синтаксическим анализатором.
Спецификация лексического анализатора с помощью генератора программ Lex преобразуется в программу на языке C. Имена лексем определяются в подключаемом файле, полученном на предыдущем этапе.
Компилируется с помощью компилятора языка C головная программа, вызывающая синтаксический анализатор. При компиляции подключаются лексический анализатор и синтаксический анализатор (программы на языке C). Компиляция происходит с использованием стандартных библиотек.
2.2 Принципы построения лексических анализаторов.Лексический анализатор выполняет первую стадию трансляции - читает строки транслируемого текста, выделяет лексемы и передает их на дальнейшие стадии трансляции (грамматический разбор, синтаксический анализ).
Основным элементом лексического анализатора являются правила. Правила – это расширенные регулярные выражения и действия. Действия могут быть записаны как с помощью команд «языка» Lex, так и на языке C. Регулярные выражения – это описания возможных наборов символов из входного потока, называемые в дальнейшем лексемами.
Лексический анализатор распознает тип каждой лексемы и соответствующим образом помечает ее. Лексический анализатор должен не только выделить лексему, но и выполнить некоторые преобразования. Например, если лексема - число, то его необходимо перевести во внутреннюю форму записи.
Хотя лексический анализ по своей идее прост, тем не менее эта фаза работы транслятора часто занимает больше времени, чем любая другая. Частично это происходит из-за необходимости просматривать и анализировать исходный текст символ за символом. Иногда даже бывает необходимо вернуть прочитанный символ во входной поток с тем, чтобы повторить просмотр и анализ. Происходит это потому, что часто бывает трудно определить, где проходят границы лексемы. Например, могут существовать две лексемы: “make” и “makefile”. При анализе входного потока символов может быть выделена лексема “make”, хотя правильно было бы выделить лексему “makefile”. Единственный способ преодолеть это затруднение - просмотр полученной цепочки символов назад и вперед. В нашем примере при выделении лексемы “make” мы должны просмотреть следующий поступающий символ и, если он будет символом "f", то вполне возможно, что поступает лексема “makefile”.
Вообще говоря, в общем случае программы лексического анализа, построенные с помощью генератора программ Lex, всегда просматривают входной поток вперед. При этом из входного потока выбирается лексема, соответствующая правилам, с наибольшей длиной. Это несколько замедляет работу, но помогает избежать ошибок.
Также в общем случае предполагается, что лексема может находиться в любом месте входного потока. Но при этом предусмотрены способы учитывать контекст. Во первых, для этого применяются так называемые «состояния» лексического анализатора. Переход в состояние осуществляется при срабатывании какого либо правила по специальной команде. Исходным состоянием анализатора является состояние «0». Возможна ситуация, когда одно и тоже правило может выполняться в нескольких состояниях. Во вторых, существует оператор определения контекста: «/». Например, выражение «ab/cd» удовлетворяет строке ab только в том случае, если за ней следует cd.
Кроме того, в Lex существуют инструменты, использующие просмотр вперед и назад: в правиле при определении лексемы могут использоваться спецсимволы «^» и «$», говорящие, что лексема должна находится в начале строки или в конце. Последний, на самом деле, является частным случаем оператора «/», так как для определения конца строки используется выражение
\”\n”
При использовании лексического анализатора совместно с синтаксическим, от лексического анализатора требуется полное поглощение входного потока и передача в синтаксический анализатор найденных лексем и данных, им соответствующих. Для того, чтобы весь входной поток был полностью поглощен и в конечный файл не попали необработанные фрагменты входного формата, лексемы, содержащиеся в спецификации лексического анализатора должны полностью описывать все возможные наборы символов.
Для передачи данных из лексического анализатора в синтаксический существует несколько путей. Наиболее простым является метод передачи данных при помощи глобальных переменных – текстовой yytext и числовой yylval.
Для упрощения написания спецификаций можно применять так называемые «подстановки». Какой-либо часто используемый шаблон описывается и сопоставляется с некоторым именем. В дальнейшем это имя можно использовать в правилах вместо данного шаблона. При этом, если возникнет необходимость изменения шаблона, не надо будет искать вхождения шаблона на протяжении всей спецификации – достаточно будет изменить шаблон в определении подстановки.
2.3 Грамматики.Принципы построения грамматических анализаторов.
Спецификация Yacc (грамматика) описывается как набор правил в виде, близком к форме Бэкуса Наура (БНФ). Каждое правило описывает грамматическую конструкцию, называемую нетерминальным символом, и сопоставляет ей имя. С точки зрения грамматического разбора правила рассматриваются как правила вывода (подстановки). Грамматические правила описываются в терминах некоторых исходных конструкций, которые называются лексическими единицами, или лексемами. Как правило, имена сопоставляются лексемам, соответствующим классам объектов, конкретное значение которых не существенно для целей грамматического анализа.
Прежде, чем говорить о конкретных принципах построения синтаксических анализаторов с использованием генератора программ Yacc, необходимо разобраться в том, какие грамматики существуют и чем они отличаются.
Прежде всего стоит отметить, что различают два основных типа грамматик: контекстно-зависимые и контекстно-независимые.
Если порождающее правило имеет следующий вид:
A ::= ,
где A – нетерминальный символ, а - терминальный или нетерминальный, то порождающее правило называется контекстно-зависимым, то есть замена нетерминального символа A на последовательность может иметь место только в контекстах и . Соответственно, и грамматика, содержащая подобное правило, называется контекстно-зависимой.
Если порождающее правило имеет вид:
A ::= ,
то есть, если левая часть порождающего правила состоит из одного нетерминального символа, который в итоге (через ряд промежуточных шагов) может заменяться на последовательность , стоящую в правой части, независимо от контекста, в котором этот нетерминальный символ встречается, то такое правило и, соответственно, грамматика называются контекстно-независимыми (или контекстно-свободными).
Контекстно независимые грамматики более универсальны. Для разработки универсальных принципов проектирования трансляторов следует использовать их, так как они позволяют обработать практически любой входной язык.
Контекстно-свободные грамматики.
Существует несколько основополагающих терминов в теории грамматик. Нетерминальный символ (нетерминал) – описываемые элементы. Например, при определении языков программирования нетерминалами служат , и т.п. В контекстно-свободной грамматике может быть любое конечное число нетерминалов.
Слова из словаря языка играют роль терминальных символов (терминалов). Контекстно-свободная грамматика может также содержать любое конечное число терминалов. В языках программирования терминалами являются фактически используемые в них слова и символы: «do», «else», «+» и т.п.
Правила грамматики иногда называются продукциями и в общем виде выглядят так:
Один_нетерминал любая конечная цепочка из терминалов и нетерминалов.
При этом цепочка справа от стрелки может быть и пустой. Например,
Иногда подобные правила называют эпсилон правилами. Контекстно-свободная грамматика может содержать любое конечное множество продукций. В качестве иллюстрации опять приведем пример из описания языка программирования. Продукция тогда выглядит так:
IF THEN
Один из нетерминалов выделен как начальный нетерминал или начальный символ, с которого должны начинаться выводы цепочек языка. Для языков программирования таким нетерминалом может быть, например, . Обычно начальный символ обозначают .
Итак, контекстно-свободная грамматика будет задаваться:
конечным множеством нетерминалов;
конечным множеством терминалов, которое не пересекается с множеством нетерминалов;
конечным множеством правил вида , где A – нетерминал, а - цепочка терминалов и нетерминалов (возможно, пустая); нетерминал называется левой частью правила, а - правой частью;
одним нетерминальным символом, выделенным в качестве начального.
Если множество правил приводится без специального указания множества терминальных и нетерминальных символов, то предполагается, что грамматика содержит в точности те терминалы и нетерминалы, которые встречаются в правилах.
Для описания грамматик очень часто используют способ записи, получивший название формы Бэкуса-Науэра или БНФ. Здесь символ заменяется символом ::=, за которым может следовать любое число правых частей, разделенных вертикальной чертой |. Здесь также нетерминалы заключаются в угловые скобки.
Правила грамматики используют для того, чтобы задавать способы подстановки или замены цепочек. Подстановка осуществляется путем замены некоторого нетерминала в какой-нибудь заданной цепочке терминалов и нетерминалов на правую часть правила, левой частью которого является этот нетерминал. Иногда говорят, что в таком случае правило применяется к нетерминалу цепочки.
Последовательность некоторых подстановок называется выводом. Каждая цепочка, встречающаяся в выводе, называется промежуточной цепочкой этого вывода.
Множество терминальных цепочек, которые можно вывести из начального символа грамматики, называется языком. Говорят, что язык определяется, грамматикой, порождается ею или выводится в ней. Язык, порождаемый контекстно-свободной грамматикой, также называется контекстно-свободным языком.
В случае, когда на каждом шаге подстановок заменяется самый левый нетерминальный символ, такой вывод называется левосторонним или левым выводом. Для каждого дерева существует единственный левый вывод, так как благодаря условию выбора самого левого нетерминала место каждой подстановки устанавливается единственным образом. Аналогично, для дерева существует единственный правосторонний или правый вывод, который получается если заменять всегда самый правый нетерминал.
Описать дерево вывода цепочки контекстно-свободного языка проще на примере.
Пусть дана следующая грамматика (начальный нетерминал ):
1. ac
2.
3. c
4. b
5. b
6. a
Пусть дана цепочка: ac, тогда вывод будет выглядеть следующим образом:
(1) ==> ac (2) ==> abc (3) ==> acbc (4) ==> acabc (5) ==> acabc (6) ==> acabac (7).
Теперь для каждой из семи пронумерованных цепочек можно построить дерево.
| (1) |
| (2) | |
| a c |
| (3) | |
| a c | |
| b |
| (4) | |
| a c | |
| b | |
| c |
| (5) | |
| a c | |
| b | |
| c | |
| a |
| (6) | |
| a c | |
| b | |
| c | |
| a |
| (7) | |
| a c | |
| b a | |
| c | |
| a |
Окончательный вариант дерева называется деревом вывода терминальной цепочки acabac.
Когда одна цепочка может иметь несколько деревьев вывода, говорят, что соответствующая грамматика неоднозначна.
Таким образом, резюмируя вышесказанное, можно подытожить:
Каждой цепочке, выводимой в данной контекстно-свободной грамматике, соответствует одно или несколько деревьев вывода.
Каждому дереву соответствует один или более выводов.
Каждому дереву соответствует единственный правый и единственный левый выводы.
Если каждой цепочке, выводимой в данной контекстно-свободной грамматике, соответствует единственное дерево вывода, эта грамматика называется однозначной; в противном случае ее называют неоднозначной.
Если правая часть каждого правила грамматики содержит не более одного нетерминала, причем этот нетерминал является самым правым символом правой части, грамматика называется праволинейной.
Нетерминалы, которые не порождают ни одной терминальной цепочки, называются бесплодными или мертвыми. Они могут быть исключены из грамматики со всеми правилами, в которые входят.
Нетерминалы, которые не появляются ни в одной цепочке, выводимой из начального символа, называются недостижимыми нетерминалами.
Нетерминалы, которые бесплодны или недостижимы, называются бесполезными. При составлении грамматик велика вероятность появления бесполезных нетерминалов и загромождение грамматик лишними правилами. Для поиска подобных нетерминалов существует конкретная процедура, разбитая на две части: обнаружение бесплодных нетерминалов и обнаружение недостижимых нетерминалов. Сначала нужно выполнить процедуру для бесплодных нетерминалов, так как при их удалении из грамматик другие нетерминалы могут стать недостижимыми.
Терминальный символ называется продуктивным (или живым), если из него выводится какая-нибудь терминальная цепочка, то есть если он не является бесплодным нетерминалом. Процедура обнаружения бесплодных нетерминалов основана на следующем свойстве продуктивных символов: Если все символы правой части правила продуктивны, то продуктивен и символ, стоящий в ее левой части.
Символ называется достижимым в грамматике, если он может появиться в какой-нибудь цепочке, выводимой из начального нетерминала, то есть если он не является недостижимым. Процедура обнаружения недостижимых символов грамматики основана на следующем свойстве достижимых символов:
Если нетерминал в левой части правила является достижимым, то достижимы и все символы правой части этого правила.
Теперь, исходя из вышеописанных свойств грамматик, можно сформулировать принципы построения синтаксического анализатора.
Во-первых, должно существовать правило, описывающее любой входной поток, который может быть обработан анализатором. Для большинства текстов таким правилом может быть следующее:
text: text string
Такое правило описывает входной поток рекурсивно как набор строк, образующих текст. В некоторых форматах (например, таких, как RTF) начальным правилом было бы
text: text word
Следует различать обработку команд и обработку непосредственно содержащегося текста. В большинстве случаев команды производят некоторое действие, а текст подлежит выводу в существующих условиях.
Команды могут располагаться как в определенных местах потока (в определенном контексте), так и быть расположены среди текстовых строк. В любом случае, команды каким-либо образом отличаются от текстовых строк. Зарезервированных слов в текстовых форматах не бывает, обычно для выделения команд применяются те или иные спецсимволы.
Команды могут иметь аргументы, описание аргументов также подчиняется определенным правилам.
Можно сказать, что такие элементы, как команды, аргументы, текстовые и пустые строки представляют собой лексемы - минимальный объект, которым оперирует анализатор при синтаксическом анализе.
Следует заметить, что использование в качестве построителя лексического анализатора генератора программ Lex, а в качестве построителя синтаксического анализатора генератора программ Yacc удобно еще и потому, что эти инструменты создавались с учетом возможности их совместного использования и имеют удобные способы совмещения.
Заключение.
Рассмотрены общие принципы проектирования трансляторов текстовых форматов. Разобраны принципы создания лексических анализаторов. Исследованы грамматики и разобраны общие принципы построения синтаксических анализаторов. Лексические и синтаксические анализаторы удобно строить именно с помощью генераторов программ Lex и Yacc, так как они создавались для совместной работы.
3. Технология реализации транслятора с помощью генераторов программ Lex и Yacc.При построении транслятора сначала строится лексический анализатор и происходит его отладка. На этом этапе лексемы определяются, но передачи их куда-либо не происходит. После отладки (когда есть уверенность, что тексты на лексическом уровне обрабатываются достаточно полно) в правила лексического анализатора добавляется возврат лексем командой return(). Естественно, что на этом этапе лексический анализатор самостоятельно может принять из потока и обработать не более одной лексемы. Начинается построение синтаксического анализатора, который каждый раз для получения лексемы вызывает лексический анализатор. Затем также происходит отладка анализаторов. Окончательным этапом является создание головной программы и отладка взаимодействия всех частей транслятора.
3.1 Определение лексем, встречающихся в формате nroffПрежде всего, в формате nroff можно выделить четыре группы лексем: текст, команды, аргументы команд и переменные.
Команды всегда находятся в начале строки и начинаются с точки. Все команды состоят из одной или двух букв латинского алфавита. Команды могут иметь один или несколько аргументов.
Аргументы команд следуют через один или несколько пробелов (или табуляций) после команды. Аргумент может быть числом со знаком или без знака, символом или строкой. После аргумента могут следовать пробельные символы.
Переменные могут располагаться в любом месте текста. Все переменные сначала объявляются при помощи специальной команды.
Текстовые строки выводятся сплошным потоком, то есть если текст располагается на нескольких строках, но между ними нет команды перевода строки в формате nroff, то этот текст, по возможности, будет выведен без перевода строк.
Если строка не содержит никаких символов (кроме конца строки), то происходит вывод пустой строки и выдается команда перевода строки.
Состояния, имеющиеся в формате nroff.
| Состояние | Описание | Переходы |
| 0 | Начальное состояние | Возможен переход в состояние приема команды или текста. |
| TEXT | Состояние приема текста | После приема одной текстовой строки происходит переход в начальное состояние. |
| COMMAND | Состояние приема команд | После приема команды происходит переход в состояние приема аргумента. |
| COMARG | Состояние приема аргумента команды | Вне зависимости от того, был принят аргумент или нет, происходит переход в начальное состояние. |
Основные лексемы, встречающиеся в формате nroff.
| Лексема | Значение |
| TEXTSTR | Строка текста |
| EMPTYSTR | Пустая строка |
| FONT | Команды управления |
| SIZE | шрифтами |
| ADJUST | Команды управления |
| NOADJUST | расположением |
| SCENTER | текста |
| IN | Команды управления |
| TIN | отступами |
| SUNDERLINE | Команды управления |
| UNDERLINE | видом |
| BOLD | текста |
| BREAKLINE | Команды вывода |
| SPACE | символов разрыва строк и |
| LINESPACE | пробельных символов |
| UNKNOW | Все неизвестные команды |
| EXIT | Команда прекращения обработки текста |
| DARG | Аргументы |
| CARG | команд |
| SARG |
Лексический анализатор разбирает входной поток следующим образом:
В начальном состоянии считывается первый символ из потока.
Если символ является точкой, то анализатор переходит в состояние ожидания команды.
Иначе предполагается, что взят первый символ из текстовой строки. Анализатор переходит в состояние приема текста, причем при последующем действии взятые из потока данные будут добавлены к символу, находящемуся в буфере – так обеспечивается целостность текста.
Если же символ взять не удалось - была встречена пустая строка – то синтаксическому анализатору передается лексема, означающая пустую строку.
В состоянии приема текста строка из потока принимается целиком, до символа конца строки. Лексический анализатор возвращает синтаксическому анализатору лексему, означающую текст, предварительно перейдя в начальное состояние.
В состоянии приема команды из потока принимается две латинских буквы, за которыми могут следовать один или более пробелов.
В соответствии с полученными символами выбирается лексема и передается синтаксическому анализатору.
Если полученные символы не подходят под шаблон ни одной из команд, то команда объявляется неизвестной. Перед возвращением лексемы в синтаксический анализатор, лексический анализатор переходит в состояние ожидания аргумента команды.
Предполагается, что аргументы команд могут быть трех типов – слово (например, название шрифта у команды .ft); символьный (например, тип выравнивания у команды .ad) или числовой (например, количество строк у команды .br). После определения лексемы, лексический анализатор переходит в начальное состояние и передает лексему синтаксическому анализатору.
Следует учитывать, что лексический анализатор, построенный с помощью генератора программ Lex, принимая символы, берет их не по порядку следования правил, а выбирает правило, удовлетворяющее наибольшей длине принимаемой строки. Поэтому лексический анализатор определит аргумент как символьный только в случае, если он действительно содержит только один символ.
В противоположном случае аргумент определяется как слово.
Если аргумент состоит из одной и более цифр, то он передается как число.
3.2 Описание грамматических правил преобразования из формата nroff в формат HTML.В нашем случае наиболее общим правилом является описание входного файла как списка списков строк. Строки могут быть двух типов - команды и текст. Команды могут иметь аргумент либо не иметь аргумента. Текст может быть текстовой строкой и пустой строкой. Такие элементы, как команды, аргументы, текстовые и пустые строки представляют собой лексемы - минимальный объект, которым оперирует анализатор при синтаксическом анализе.
Если синтаксический анализатор получает от лексического анализатора лексему "текст", то он выводит в выходной поток содержимое буфера yytext, используя для этого специально определенную функцию textout().
Если получена лексема "пустая строка", то в выходной поток выводится тэг HTML
при помощи функции breakline().
Если получена лексема, соответствующая одной из команд, то, возможно, запрашивается лексема аргумента и выполняются необходимые операции.
Так как во всех командах аргумент является вторым элементом правила, то для доступа к его значению всегда используется псевдопеременная $2.
Обработка большинства команд приводит к тому, что в выходной поток записывается открывающий тэг, возможно с теми или иными аргументами. Так как формат HTML требует закрытия тэга до его повторного открытия, то для контроля закрытия предусмотрены переменные-триггеры. Они принимают значение, равное единице, при выводе в выходной поток открывающего тэга и каждый раз перед выводом нового открывающего тэга проводится проверка на включение триггера. Если триггер включен, то перед выводом стартового тэга будет выведен закрывающий тэг.
В формате nroff принята такая система команд, при которой у большинства команд аргументом является количество строк, на которые будет распространятся действие этой команды. В HTML же область действия команды определяется местоположением открывающего и закрывающего тэгов. Для того, что бы определить место вывода закрывающего тэга, введены переменные-счетчики. В момент получения команды им присваивается значение аргумента, и затем оно уменьшается при выводе в выходной поток очередной порции текста. При достижении счетчиком значения "ноль", в выходной поток выводится закрывающий тэг. Если значение счетчика меньше нуля, то это значит, что он сейчас неактивен.
При выводе текста функцией textout() происходит анализ на содержание в тексте переменных. Если переменные найдены, то происходит подстановка их значений в выводимый текст.
Для вывода
в выходной
поток тэга
- команда перевода
строки – применяется
специальная
функция breakline().
Необходимость
такого шага
обусловлена
тем, что в nroff существует
команда ".ls",
которая определяет,
сколько пустых
строк выводится
по команде
".br" (аналогом
которой является
тег
). При поступлении
лексемы, соответствующей
команде ".ls"
значение ее
аргумента
присваивается
переменной
LS, которая определяет
сколько раз
подряд выведется
тэг
в выходной
файл.
Замена шрифтов осуществляется при помощи функции fontchange(). В качестве аргумента ей передается имя шрифта, используемого в исходном документе. Имя шрифта, на который будет заменен данный шрифт определяется по специально созданной таблице, хранящейся во внешнем файле. В случае, если замена не определена, подставляется шрифт по умолчанию.
Особо надо оговорить обработку команды nroff ".ex". При получении лексемы, соответствующей этой команде, синтаксический анализатор завершает свою работу, возвращая в головную функцию значение "0", свидетельствующее о нормальном завершении работы.
3.3 Соответствие между командами форматовnroff и HTML.
Точного соответствия между текстовым форматом nroff и гипертекстовым форматом HTML нет.
Главным отличием является то, что формат HTML ориентирован на использование его в локальных или глобальных сетях, а формат nroff - на использование только для чтения документов.
Формат HTML поддерживает больше видов форматирования текстов, гипертекстовые ссылки, включение в текст графики, запуск внешних программ и многое другое.
Формат nroff подразумевает постраничный вывод на экран, а формат HTML - вывод сплошным потоком с возможностью последующей прокрутки окна просмотра.
Так как нас интересует, прежде всего, преобразование команд формата nroff в команды формата HTML, то имеет смысл рассмотреть команды исходного формата и определить, какие команды им будут соответствовать в конечном формате:
| nroff | HTML | Описание |
| Комментарии | ||
| \” | Комментарий | |
| Команды для управления шрифтом | ||
| .bd | Жирный шрифт | |
| .ul | Подчеркивание | |
| .ft font_name | Устанавливает шрифт | |
| .ps n | Устанавливает размер символа | |
| nroff | HTML | Описание |
| Команды управления текстом | ||
| .br | | Следующая строка |
| .ce | Центрирование | |
| .ad x | Выравнивание текста | |
| .na | Нет управления текстом | |
| .sp | Пустое пространство | |
В HTML не поддерживаются следующие команды, имеющиеся в формате nroff:
| nroff | Описание |
| Команды управления страницами | |
| .bp | начать новую страницу |
| .pl | установить длину страницы |
| .pn | установить номер страницы |
| .ll | длина строки |
Для вывода текста в виде, максимально близко к исходному, в конечном формате иногда необходимо использовать не одну команду, а комбинацию команд:
| Nroff | HTML | Описание |
| .rt |
………
………
вертикальный возврат для столбцов .nfПри создании документа в формате HTML необходимо вставлять обязательные тэги:
| HTML | Комментарий |
| Признак HTML-документа. Весь текст, помещенный между этими тэгами обрабатывается в соответствии с форматом HTML. Закрывающий тэг служит признаком конца документа и выводится при нахождении команды nroff .ex | |
| Область заголовка HTML-документа, служит для формирования общей структуры документа. | |
| Заголовок HTML-документа. Вставляется имя конвертируемого файла. | |
| Заключает в себе гипертекст, который, собственно и выводится в окне броузера. | |
| Гиперссылка. Этими тэгами обрамляются ссылки на другие документы. Предполагается, что они располагаются в том же каталоге, что и открытый документ и имена файлов имеют расширение .html | |
| Элемент для создания базового адреса для ссылок. Если документы и программа транслятор находятся в разных каталогах, то это тэг определяет местонахождение каталога с документами. |
Отладка происходит в два этапа – отладка лексического анализатора и отладка системы из лексического и синтаксического анализаторов.
Для отладки используется метод пошагового просмотра работы анализаторов. Для этого создан специальный оператор (посредством команды #define языка С), выводящий сообщение о состоянии анализатора (имя обрабатываемой лексемы и состояние различных переменных).
При отладки лексического анализатора возможно использование тестовых пакетов – текстов в формате nroff, а также интерактивное тестирование, когда анализатор принимает информацию из стандартного ввода (с клавиатуры) и выдает результаты на стандартный вывод (экран монитора).
Для проверки правильности написания правил синтаксического анализатора генератор программ Yacc на этапе тестирования запускается с ключом d по которому создается файл с деревом разбора.
Заключение.Создана программа-транслятор из формата nroff в гипертекстовый формат HTML.
Программа выводит пустые обязательные теги формата HTML и преобразует текст из формата nroff в формат HTML. Полностью поддерживается стандартный набор команд формата nroff. Реализована большая часть команд различных пакетов макросов, наиболее полно реализован пакет макросов “man”.
Порядок работы с программой-транслятором ut4all таков: на вход программы подается текстовый файл в формате nroff, а на выходе получаем текстовый файл в формате HTML. Имена текстовых файлов передаются в качестве аргумента, причем первым аргументом является имя входного файла, а вторым – имя выходного. В случае отсутствия одного или обоих аргументов в качестве входного и выходного потоков используются стандартные потоки. Если входного файла не существует, то выдается сообщение об ошибке, если не существует выходного файла, то он создается.
Сообщения об ошибках направляются в стандартный поток ошибок.
4. Экономическое обоснование разработки НИОКР. 4.1 Расчет затрат времени на разработку транслятора.4.1.1. Для начала необходимо определить продолжительность создания транслятора. Определим весь перечень работ по всем этапам разработки информационной системы.
Этапы создания транслятора:
| Этап 1: | Техническое задание. |
| Получение задания, его обработка, а также согласование задания и его деталей с консультантом. | |
| Этап 2: | Техническое предложение. |
| Изучение ОС Unix и ее компонент – lex, yacc. | |
| Этап 3: | Эскизное проектирование. |
| Изучение подходов к написанию трансляторов. | |
| Этап 4: | Техническое проектирование. |
| Разработка алгоритмов решения задачи. | |
| Этап 5: | Рабочий проект. |
| Разработка структуры программного обеспечения. | |
| Этап 6: | Изготовление опытного образца. |
| Непосредственно программирование. | |
| Этап 7: | Испытание опытного образца. |
| Отладка программы | |
| Этап 8: | Оформление документации. |
| Оформление документации. | |
По формуле 1.1 рассчитывается ожидаемое время выполнения каждой работы .
(1.1) , где
- минимальная продолжительность работы, т.е. время, необходимое для выполнения работы при наиболее благоприятном стечении обстоятельств (час, дни, недели и т.д. );
- максимальная продолжительность работы т.е. время, необходимое для выполнения работы при наиболее неблагоприятном стечении обстоятельств (час, дни, недели и т.д. )
Для определения возможного разброса ожидаемого времени определяется дисперсия (рассеивание)
(1.2)
Составим таблицу значений по каждой работе каждого этапа:
Таблица 1.1.
Этапы | , дн | , дн | , дн | |
| 1 | 5 | 10 | 7 | 1 |
| 2 | 40 | 50 | 44 | 4 |
| 3 | 4 | 5 | 4,4 | 0,04 |
| 4 | 5 | 8 | 6,2 | 0,36 |
| 5 | 4 | 6 | 4,8 | 0,16 |
| 6 | 50 | 60 | 54 | 4 |
| 7 | 17 | 21 | 18,6 | 0,64 |
| 8 | 6 | 7 | 6,4 | 0,04 |
| Всего | 131 | 167 | 145,4 |
Исполнитель для всех этапов один, т.е. возможно только последовательное выполнение всех работ.
4.2 Расчет стоимости основных фондов, используемых для разработки транслятора.Первоначальная (балансовая) стоимость складывается из всех затрат, связанных с приобретением, сооружением и строительством основных производственных фондов.
К основным фондам при разработке транслятора можно отнести то оборудование, на котором выполнялась данная разработка:
Таблица 2.1
| Оборудование | Стоимость в $ | |
| Компьютер | Процессор | 150 |
| Материнская плата | 120 | |
| Оперативная память | 160 | |
| Видеокарта | 35 | |
| Модем | 165 | |
| Винчестер | 200 | |
| CD-rom | 110 | |
| Дисковод | 25 | |
| Корпус | 36 | |
| Клавиатура | 12 | |
| Мышь | 7 | |
| Принтер | 300 | |
| Монитор | 480 | |
Первоначальная (балансовая) стоимость основных фондов в соответствии с данными, приведенными в таблице 2.1, составит 1800$ или 50400 рублей (по курсу 1$ 28 руб. – на апрель 2000 г.).
Первоначальная (остаточная) стоимость характеризует оценку основных производственных фондов по первоначальной (балансовой) стоимости за минусом общей суммы амортизационных отчислений на данный момент.
Общую сумму амортизационных отчислений на время начала выполнения дипломного проекта определим по формуле:
K*Ha*t
A = (2.1)
Фд
где
K - первоначальная балансовая стоимость основных фондов, руб.;
Ha- норма годовых амортизационных отчислений, % (таблица 2.2.);
t - реально использованное машинное время, час.;
Фд - действительный фонд времени работы оборудования за год, час.
Таблица 2.2
Нормы амортизационных отчислений по отдельным видам спец. оборудования (% от балансовой стоимости).
НАИМЕНОВАНИЕ ОБОРУДОВАНИЯ | Норма амортизационных отчислений |
| Физико-термическое оборудование для производства изделий микроэлектроники и полупроводниковых приборов | 28.2 |
| Контрольно-измерительное и испытательно-тренировочное оборудование для производства электронной техники | 27.5 |
| Оборудование для измерения электрофизических параметров полупроводниковых приборов | 27.3 |
| Оборудование для механической обработки полупроводниковых материалов | 23.9 |
| Вакуумное технологическое оборудование для нанесения тонких пленок | 24.3 |
| Оборудование для производства фотошаблонов | 23.4 |
| Сборочное оборудование для производства полупроводниковых и электровакуумных приборов | 23.8 |
| Электронные генераторы, стабилизированные источники питания, тиристорные выпрямители, регуляторы напряжения | 15.5 |
| Прочее спецтехнологическое оборудование для производства изделий электронной техники | 13.1 |
| Контрольно-измерительная и испытательная аппаратура связи, сигнализации и блокировки: | |
| Переносная | 14.2 |
| Стационарная | 8.5 |
| Лабораторное оборудование и приборы | 20.0 |
| Электронные цифровые вычислительные машины общего назначения, специализированные и управляющие | 12.0 |
Сумма амортизационных отчислений составит:
50400* 0.12* 1000
A = 2360 = 2563 руб.
Первоначальная (остаточная) стоимость составит:
45000 - 2563 = 42437 руб.
4.3 Расчет затрат на разработку транслятора.4.3.1. Расчет затрат на разработку транслятора.
Таблица 3.1
| Материальные ресурсы | Цена, руб. |
| Книги | |
| "LINUX" | 120 |
| HTML | 15 |
| DEMOS32 | 50 |
| Программное обеспечение | |
| ОС Windows 95 | 625 |
| OS LINUX | 190 |
Суммарные затраты составляют 1000 руб.
Похожие работы
... органов обоснованны, он вступает в процесс и поддерживает обвинение. Поэтому так важно всегда держать наготове подтверждающие документы, касающиеся приобретения и использования имеющегося программного обеспечения. Это могут быть лицензии, регистрационные карточки и сертификаты на ПО, регламенты и инструкции о порядке его приобретения, учета и использования. В таком случае проверяющие, скорее ...
... с приглашением по запросу (в машинной графике)required parameter обязательный параметрrequired space обязательный пробел (в системах подготовки текстов)requirements specification 1. техническое задание 2. описание требований к программному средствуrerun перезапуск, повторный запускreschedule переупорядочивать очередь (о диспетчере операционной системы)reschedule interval период переупорядочения ...


... этому представлен данный дипломный проект, который является первым в своем роде в г. Астрахани. В данном дипломном проекте рассматривается проблема построения локальной корпоративной сети звукового обеспечения интеллектуального здания на основе технологии Fast Ethernet для Областного центра детского и юношеского творчества г. Астрахани. Целью дипломного проекта является организация локальной ...
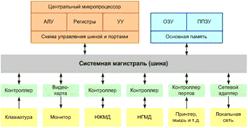
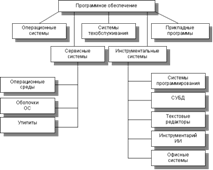


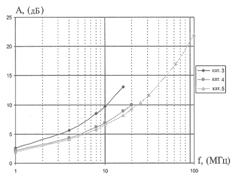
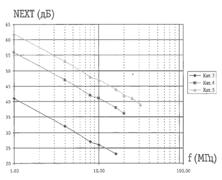
... ЛВС, тополи, структура, сетевое оборудование и программное обеспечение ЛВС представлены в Приложении А. 2 ПРАКТИЧЕСКАЯ РЕАЛИЗАЦИЯ ПОДБОРА ПРОГРАММНО-ТЕХНИЧЕСКОГО КОМПЛЕКСА ЛВС ДЛЯ АВТОМАТИЗАЦИИ РАБОТЫ БУХГАЛТЕРИИ АОЗТ «ДОНЕЦКОЕ ПУСКО-НАЛАДОЧНОЕ УПРАВЛЕНИЕ № 414 «ДОНБАСЭЛЕКТРОМОНТАЖ» 2.1 Административные, технические и программные характеристики АОЗТ «Донецкое пуско-наладочное управление № ...
0 комментариев