Значение суммы (sem_val + sem_op) станет больше либо равно нулю
Команды, которые реализованы в виде отдельных файлов. Это те команды, которые можно модифицировать или добавлять новые
На каждой из машин работает своя операционная система (этот признак отличает ММВК от многопроцессорного вычислительного комплекса)
Навигация
Значение суммы (sem_val + sem_op) станет больше либо равно нулю
Interprocess Communication
88065
знаков
11
таблиц
4
изображения
1. Значение суммы (sem_val + sem_op) станет больше либо равно нулю.
2. Пришел какой-то сигнал. (Значение semop в этом случае будет равно -1).
Если код операции semop равен нулю, то процесс будет ожидать обнуления семафора. Если мы обратились к функции semop с нулевым кодом операции, а к этому моменту значение семафора стало равным нулю, то никакого ожидания не происходит.
Рассмотрим третий параметр - флаги. Если третий параметр равен нулю, то это означает, что флаги не используются. Флагов имеется большое количество в т.ч. IPC_NOWAIT (при этом флаге во всех тех случаях, когда мы говорили, что процесс будет ожидать, он не будет ожидать).
Обращаю ваше внимание, что за одно обращение к функции semop можно передать n структур и соответственно выполнить действия с n семафорами из этого массива. Если в этой последовательности будут присутствовать две разных операции с одни семафором, то скорее всего, выполнится последняя.
Функция управления массивом семафоров.
int semctl(int id, int sem_num, int cmd, union sem_buf arg);
Первый параметр - идентификатор, второй - номер семафора в массиве, с которым мы будем выполнять команду cmd из третьего параметра. Последний параметр - некоторое объединение типа sembuf.
Команды могут быть традиционные (IPC_RMID), и кроме них есть другие команды, и среди них IPC_SET, которая устанавливает значение семафора, при этом значение передается через объединение arg. При установке семафора этой функцией, задержек, которые определяют основной смысл работы семафора, не будет.
Вот те функции, которые предназначены для работы с семафорами. Пример работы с семафорами рассмотрим на следующей лекции.
Лекция №19
Мы остановились на средствах синхронизации доступа к разделяемым ресурсам - на семафорах. Мы говорили о том, что семафоры - это тот формализм, который изначально был предложен ученым в области компьютерных наук Дейкстрой, поэтому часто в литературе их называют семафорами Дейкстры. Семафор - это есть некоторая переменная и над ней определены операции P и V. Одна позволяет увеличивать значение семафора, другая - уменьшать. Причем с этими изменениями связаны возможности блокировки процесса и разблокировки процесса. Обратим внимание, что речь идет о неразделяемых операциях, то есть тех операциях, которые не могут быть прерваны, если начались. То есть не может быть так, чтобы во время выполнения P или V пришло прерывание, и система передала управление другому процессу. Это принципиально. Поэтому семафоры можно реализовывать программно, но при этом мы должны понимать, что эта реализация не совсем корректна, так как
1) программа пишется человеком, а прерывается аппаратурой, отсюда возможно нарушение неразделяемости;
2) в развитых вычислительных системах, которые поддерживают многопроцессорную обработку или обработку разделяемых ресурсов в рамках одного процесса, предусмотрены семафорные команды, которые фактически реализовывают операции P и V. Это важно.
Мы говорили о реализации семафоров в Unix в системе IPC и о том, что эта система позволяет создать разделяемый ресурс “массив семафоров”, соответственно, как и к любому разделяемому ресурсу, к этому массиву может быть обеспечен доступ со стороны различных процессов, обладающих нужными правами и ключом к данному ресурсу.
Каждый элемент массива - семафор. Для управления работой семафора есть функции:
A. semop, которая позволяет реализовывать операции P и V над одним или несколькими семафорами;
B. segctl - управление ресурсом. Под управлением здесь понимается три вещи:
1. - получение информации о состоянии семафора;
2. - возможность создания некоторого режима работы семафора, уничтожение семафора;
3. - изменение значения семафора (под изменением значения здесь понимается установление начальных значений, чтобы использовать в дальнейшем семафоры, как семафоры, а не ящички для передачи значений, другие изменения - только с помощью semop);
Давайте приведем пример, которым попытаемся проиллюстрировать использование семафоров на практике.
Наша программа будет оперировать с разделяемой памятью.
1 процесс - создает ресурсы “разделяемая память” и “семафоры”, далее он начинает принимать строки со стандартного ввода и записывает их в разделяемую память.
2 процесс - читает строки из разделяемой памяти.
Таким образом мы имеем критический участок в момент, когда один процесс еще не дописал строку, а другой ее уже читает. Поэтому следует установить некоторые синхронизации и задержки.
Следует отметить, что, как и все программы, которые мы приводим, эта программа не совершенна. Но не потому, что мы не можем ее написать (в крайнем случае можно попросить своих аспирантов или студентов), а потому, что совершенная программа будет занимать слишком много места, и мы сознательно делаем некоторые упрощения. Об этих упрощениях мы постараемся упоминать.
1й процесс:
#include <stdio.h>
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/sem.h>
int main(void)
{ key_t key;
int semid, shmid;
struct sembuf sops;
char *shmaddr;
char str[256];
key = ftok(“/usr/mash/exmpl”,’S’); /* создаем уникальный ключ */
semid = semget(key,1,0666 | IPC_CREAT); /* создаем один семафор с определенными правами доступа */
shmid = shmget(key,256, 0666 | IPC_CREAT); /*создаем разделяемую память на 256 элементов */
shmaddr = shmat(shmid, NULL, 0); /* подключаемся к разделу памяти, в shaddr - указатель на буфер с разделяемой памятью*/
semctl(semid,0,IPC_SET, (union semun) 0); /*инициализируем семафор со значением 0 */
sops.sem_num = 0; sops.sem_flg = 0;
/* запуск бесконечного цикла */
while(1) { printf(“Введите строку:”);
if ((str = gets(str)) == NULL) break;
sops.sem_op=0; /* ожидание обнуления семафора */
semop(semid, &sops, 1);
strcpy(shmaddr, str); /* копируем строку в разд. память */
sops.sem_op=3; /* увеличение семафора на 3 */
semop(semid, &sops, 1);
}
shmaddr[0]=’Q’; /* укажем 2ому процессу на то, */
sops.sem_op=3; /* что пора завершаться */
semop(semid, &sops, 1);
sops.sem_op = 0; /* ждем, пока обнулится семафор */
semop(semid, &sops, 1);
shmdt(shmaddr); /* отключаемся от разд. памяти */
semctl(semid, 0, IPC_RMID, (union semun) 0); /* убиваем семафор */
shmctl(shmid, IPC_RMID, NULL); /* уничтожаем разделяемую память */
exit(0);
}
2й процесс:
/* здесь нам надо корректно определить существование ресурса, если он есть - подключиться, если нет - сделать что-то еще, но как раз этого мы делать не будем */
#include <stdio.h>
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/sem.h>
int main(void)
{ key_t key; int semid;
struct sembuf sops;
char *shmaddr;
char st=0;
/* далее аналогично предыдущему процессу - инициализации ресурсов */
semid = semget(key,1,0666 | IPC_CREAT);
shmid = shmget(key,256, 0666 | IPC_CREAT);
shmaddr = shmat(shmid, NULL, 0);
sops.sem_num = 0; sops.sem_flg = 0;
/* запускаем цикл */
while(st!=’Q’) {
printf(“Ждем открытия семафора \n”);
/* ожидание положительного значения семафора */
sops.sem_op=-2;
semop(semid, &sops, 1);
/* будем ожидать, пока “значение семафора”+”значение sem_op” не перевалит за 0, то есть если придет “3”, то “3-2=1” */
/* теперь значение семафора равно 1 */
st = shmaddr[0];
{ /*критическая секция - работа с разделяемой памятью - в этот момент первый процесс к разделяемой памяти доступа не имеет*/}
/*после работы - закроем семафор*/
sem.sem_op=-1;
semop(semid, &sops, 1);
/* вернувшись в начало цикла мы опять будем ждать, пока значение семафора не станет больше нуля */
}
shmdt(shmaddr); /* освобождаем разделяемую память и выходим */
exit(0);
}
Это программа, состоящая из двух процессов, синхронно работающих с разделяемой памятью. Понятно, что при наличии интереса можно работать и с сообщениями.
На этом мы заканчиваем большую и достаточно важную тему организации взаимодействия процессов в системе.
Наша самоцель - не изучение тех средств, которые предоставляет Unix, а изучение принципов, которые предоставляет система для решения тех или иных задач, так как другие ОС предоставляют аналогичные или похожие средства управления процессами.
Системы программирования.
Система программирования - это комплекс программных средств, обеспечивающих поддержку технологий проектирования, кодирования, тестирования и отладки, называется системой программирования
Этап проектированияБыло сказано, что на сегодняшний день достаточно сложно, а практически невозможно создавать программное обеспечение без этапа проектирования, такого же долгого, нудного и детального периода, который проходит во время проектирования любого технического объекта. Следует понять, что те программы, которые пишутся студентами в качестве практических и дипломных задач не являются по сути дела программами - это игрушки, так как их сложность невелика, объемы незначительны и такого рода программы можно писать слегка. Реальные же программы так не создаются, так же, как и не создаются сложные технические объекты. Никто никогда не может себе представить, чтобы какая-нибудь авиационная компания продекларировала создание нового самолета и дала команду своим заводам слепить лайнер с такими-то параметрами. Так не бывает. Каждый из элементов такого объекта, как самолет, проходит сложный этап проектирования.
Например, фирма Боинг подняла в воздух самолет “Боинг-777”, замечательность этого факта заключается в том, что самолет взлетел без предварительной продувки в аэродинамической трубе. Это означает, что весь самолет был спроектирован и промоделирован на программных моделях, и это проектирование и моделирование было настолько четким и правильным, что позволило сразу же поднять самолет в воздух. Для справки - продувка самолета в аэродинамической трубе стоит сумасшедшие деньги.
Примерно та же ситуация происходит при создании сложных современных программных систем. В начале 80х гг была начата СОИ (стратегическая оборонная инициатива), ее идея была в том, чтобы создать сложной технической системы, которая бы в автоматическом режиме установила контроль за пусковыми установками СССР и стран Варшавского блока, и в случае фиксации старта с наших позиций какого-то непродекларированного объекта автоматически начиналась война. То есть запускались бы средства уничтожения данного объекта и средства для ответных действий. Реально тот департамент вооруженных сил, который занимался этим проектом, испытал ряд кризисов в связи с тем, что ведущие специалисты в области программного обеспечения отказывались участвовать в реализации этого проекта из-за невозможности корректно его спроектировать, потому что система обладала гигантским потоком входных данных, на основе которых должны были быть приняты однозначные решения, ответственность за которые оценить весьма сложно. На самом деле эта проблема подтолкнула к развитию с одной стороны - языков программирования, которые обладали надежностью, в частности, язык Ада, одной из целью которого было создание безошибочного ПО. В таких языках накладывались ограничения на места, где наиболее вероятно возникновение ошибки (межмодульные интерфейсы; выражения, где присутствуют разные типы данных и т.п.) Заметим, что язык C не удовлетворяет требованиям безопасности. С другой стороны - к детальному проектированию, которое бы позволяло некоторым формальным образом описывать создаваемый проект и работать с проектом в части его детализации. Причем, переход от детализации к кодированию не имел бы четкой границы. Понятно, что это есть некоторая задача не сегодняшнего, а завтрашнего дня, но реально разработчики программ находятся на пути создания таких средств, которые позволили бы совместить проектирование и кодирование. Сегодняшние системы программирования, которые строятся на объектно-ориентированном подходе, частично решают эту проблему.
Следующая проблема проектирования. Мы продекларировали модули, объявили их взаимосвязи, как-то описали семантику модулей (это тоже проблема). Но никто не даст гарантии, что этот проект правилен. Для решения этой проблемы используется моделирование программных систем. То есть, когда вместе с построением проекта, который декларирует все интерфейсы, функциональность и прочее, мы можем каким-то образом промоделировать работу всей или частей создаваемой системы. Реально при создании больших программных систем на сегодняшний день нет единых инструментариев для таких действий. Каждые из существующих систем имеют разные подходы. Иногда эти подходы (как и у нас, так и за рубежом) достаточно архаичны.
Но тем не менее следует понимать, что период проектирования есть очень важный момент.
КодированиеЕсли составлен нормальный проект, то с кодированием проблем нет. Но следует обратить внимание на то, что специалист в программировании это не тот, кто быстро пишет на С, а тот, кто хорошо и подробно сможет спроектировать задачу. При современном развитии инструментальных средств закодировать сможет любой школьник, а спроектировать систему - это и есть профессиональная задача людей, занимающихся программированием - выбрать инструментальные средства, составить проект, промоделировать решение.
Основной компонент системы кодирования - язык программирования. В голове каждого программиста лежит иерархия языков программирования - от машинного кода и ассемблера до универсальных языков программирования (FORTRAN, Algol, Pascal, C и т.д.), специализированных языков (SQL, HTML, Java и т.д.)
Мы имеем ЯП и программу, которая написана в нотации этого языка. Система программирования обеспечивает перевод исходной программы в объектный язык. Этот процесс перевода называется трансляцией. Объектный язык может быть как некоторым языком программирования высокого уровня (трансляция), так и машинный язык (компиляция). Мы можем говорить о трансляторах-компиляторах и трансляторах-интерпретаторах.
Компилятор - это транслятор, переводящий текст программы в машинный код.
Интерпретатор - это транслятор, который обычно совмещает процесс перевода и выполнения программы (компилятор сначала переводит программу, а только затем ее можно выполнить). Он, грубо говоря, выполняет каждую строчку, при этом машинный код не генерируется, а происходит обращение к некоторой стандартной библиотеке программ интерпретатора. Если результат работы компилятора - код программы на машинном языке, то результат работы транслятора - последовательность обращений к функциям интерпретации. При этом, также как и при компиляции, когда создается оттранслированная программа, у нас тоже может быть создана программа, но в этом интепретируемом коде (последовательности обращений к функциям интерпретации).
Понятна разница - компиляторы более эффективны, так как в интерпретаторах невозможна оптимизация и постоянные вызовы функций также не эффективны. Но интерпретаторы более удобны за счет того, что при интерпретации возможно включать в функции интерпретации множество сервисных средств: отладки, возможность интеграции интерпретатора и языкового редактора (компиляция это делать не позволяет).
На сегодняшний день каждый из методов - и компиляция и интерпретация занимают свои определенные ниши.
Лекция №20
На прошлой лекции мы начали рассматривать системы программирования. На самом деле эта тема может быть основанием целого курса, потому что эта тема включает в себя все то, что может быть в современной науке о компьютерах - это и хорошие практические решения, и разработанные, реально применяемые, теоретические решения, и многое другое. Мы говорили, что система программирования - это комплекс программ, обеспечивающий жизненный цикл программы в системе. Жизненный цикл создаваемого программного обеспечения содержит следующие этапы:
* проектирование
* кодирование
* тестирование
* отладка
Мы с вами говорили о важности этапа проектирования, о том что программный продукт представляет из себя сложнейший объект, имеющий огромное число связей между своими компонентами. Пропустить этап проектирования нельзя. Для проектирования программных систем, необходимы специализированные средства, которые позволили бы (в идеале) описывать проект некоторым формальным образом, и последовательно уточняя его, приводить формальное описание проекта в реальный код программы.
Мы говорили, что важным этапом проектирования, является этап моделирования системы, т.е. тот этап, когда мы берем внешние нагрузки, которые могут поступать на систему, приписываем свойству потока событий, связанных с этими внешними нагрузками, определенный статистический закон, и рассматриваем предположительное поведение системы при такой эмуляции внешней среды. Понятно, что без этапа моделирования тоже трудно создать какой-либо программный продукт.
Этап кодирования
Мы также говорили, что важной частью системы программирования являются средства кодирования. Этап кодирования в жизненном цикле программы традиционно (и обычно не правильно) однозначно связывается с понятием системы программирования. Очень многие, когда начинают говорить о системе программирования, подразумевают под этим транслятор языка программирования. Хотелось бы этими лекциями вам показать, что система программирования - это нечто существенно более широкое, чем транслятор. Все компоненты одинаково необходимы.
Транслятор - это программа, которая переводит программу в нотации одного языка, в нотацию другого языка. Компилятор - это транслятор, который переводит программу из нотации одного языка в нотацию машинного языка. Машинным языком может быть либо код конкретной машины, либо объектный код. Трансляторы могут быть интерпретаторами, т.е. совмещать анализ исходной программы с ее выполнением. Результатом работы интерпретатора является не машинный код, а последовательность обращений к библиотеке функций интерпретатора. Интерпретатор, в отличие от транслятора, может выбирать одну за одной инструкции и сразу их выполнять. При интерпретации (в отличие от трансляции или компиляции), может быть начато выполнение программы которая имеет синтаксические ошибки.
Кросс-трансляторы. Если рассматривать системы трансляции, то есть еще один вид трансляторов - кросс-трансляторы (и кросс-компиляторы). Кросс транслятор работает на некотором типе вычислительной системы, которая называется инструментальная ЭВМ. Инструментальная ЭВМ может характеризоваться своей архитектурой и/или операционным окружением, которое функционирует на ней. Кросс-транслятор обеспечивает перевод программы, записанной в нотации некоторого языка, в код вычислительной системы, отличной от инструментальной ЭВМ. Та вычислительная система, для которой генерируется код, называется объектной ЭВМ, и соответственно, тот код, который мы получаем, называется объектным кодом (это не тоже, что объектный модуль). Например, компьютеру, который управляет двигательной установкой самолета, совершенно не нужно иметь операционную среду, которая обеспечит работу пользователя по разработке программ для него. Ему совершенно не нужно иметь средства редактирования текста, трансляции и т.д., потому что у него одна функция - управлять двигательной установкой. На этом компьютере будет работать операционная система реального времени. Для создания программ для такого рода компьютеров и используются системы кросс-программирования и кросс-трансляторы. На обычной машине типа PC может быть размещен транслятор, который будет генерировать код для заданного компьютера.
|
|
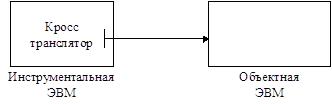
На самом деле, бывают ситуации, когда тип объектной машины совпадает с типом инструментальной машины, но отличаются операционные среды, которые функционируют на данных машинах. В этом случае также нужна система кросс-программирования.
Кросс-трансляторы также нужны разработчикам новых машин, которые хотят параллельно с ее появлением создать программное обеспечение, которое будет работать на этой машине.
Обработка модульной программы. С точки зрения этапа кодирования можно рассмотреть последовательность обработки программы более крупноблочно, чем с точки зрения трансляции. Мы с вами говорили на начальных лекциях о том что современные языки программирования поддерживают модульность (программа представляется в виде группы модулей и взаимосвязь между этими модулями осуществляется за счет соответствующих объявлений в них). Давайте посмотрим, что происходит на этапе обработки программы, написанной на одном из модульных языков.
|
|
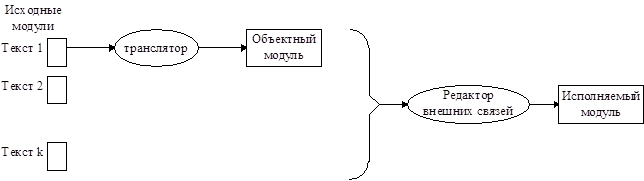
Пусть есть некоторая группа модулей и есть соответствующие этим модулям тексты программ, на языках, используемых для программирования. Языковыми средствами определены связи между модулями.
Первый этап, который происходит - это этап трансляции (либо компиляции) каждого из модулей. После трансляции модуля в виде исходного текста мы получаем объектный модуль - это есть машинно-ориентированное представление программы, в котором присутствуют фрагменты программы в машинном коде, а также информация о необходимых внешних связях (ссылки на объекты в других модулях). Информация о необходимых внешних связях (помимо информации о местонахождении внешних объектов) также включает в себя ссылки на те места машинного кода, которые пытаются использовать адреса внешних объектов, т.е. на те недообработанные команды, которые нельзя обработать из-за того, что при трансляции модуля еще не известно где какие объекты находятся. Т.е. объектный модуль - это машинное представление программного кода, в котором еще не разрешены внешние связи. Объектный модуль может содержать дополнительную информацию (например, информацию, необходимую для отладки - таблицы имен и т.д.).
Для каждого из исходных модулей мы получим объектный модуль. После этого все объектные модули, которые составляют нашу программу, а также модули требуемых библиотек функций, поступают на вход редактору внешних связей. Редактор внешних связей моделирует размещение объектных модулей в оперативной памяти и разрешает все связи между ними. В итоге мы получаем исполняемый модуль, который может быть запущен как процесс. Иногда трансляторы в качестве результата трансляции выдают модуль на ассемблере соответствующей машины.
В эту же схему также часто добавляется этап оптимизации программы, причем оптимизация может происходить до этапа трансляции (т.е. в терминах исходного языка) или/и после трансляции (в терминах машинного кода). Например до трансляции можно вычислить все константные подвыражения и т.д. Для машин типа PC этап оптимизации может быть не столь важен, потому что этот вопрос обычно разрешается покупкой какого-нибудь более быстрого компонента, но есть класс машин (mainframe), для которых этот этап необходим.
Давайте посмотрим на проблему кодирования с другой стороны. Мы посмотрим как устроен этап трансляции.
Каждый транслятор при обработке программы выполняет следующие действия.
I. Лексический анализ.
II. Синтаксический анализ.
III. Семантический анализ и генерация кода.
Лексический анализ. Лексический анализатор производит анализ исходного текста на предмет правильности записи лексических единиц входного языка. Затем он переводит программу из нотации исходного текста в нотацию лексем.
Лексические единицы - это минимальные конструкции, которые могут быть продекларированы языком. К лексическим единицам относятся:
à идентификаторы
à ключевые слова
à код операции
à разделители
à константы
Вещественные константы в некоторых трансляторах могут представляться в виде группы лексических единиц, каждая из которых является целочисленной константой.
После этого исходная программа переводится в вид лексем. Лексема - это некоторая конструкция, содержащая два значения - тип лексемы и номер лексемы.
| Тип лексемы | № лексемы |
Тип лексемы - это код, который говорит о том, что данная лексема принадлежит одной из обозначенных нами групп. к примеру лексема может быть ключевым словом, тогда в поле типа будет стоять соответствующий номер. Номер лексемы уточняет конкретное значение этой лексемы. Если, к примеру, было ключевое слово begin, то номер лексемы будет содержать число, соответствующее ключевому слову begin. Если тип лексемы - идентификатор, то номер лексемы будет номером идентификатора в таблице имен которую создаст лексический анализатор. Если тип лексемы - константа, то номер лексемы тоже будет ссылкой на таблицу с константами.
После лексического анализатора мы получаем компактную программу, в которой нет уже ничего лишнего (пробелов, комментариев, и т.д.). Вся программа составлена в виде таких лексем, и поэтому она более компактна и проста.
Синтаксический анализ. Программа в виде лексем поступает на вход синтаксическому анализатору, который осуществляет проверку программы на предмет правильности с точки зрения синтаксических правил. Результатом работы синтаксического анализатора является либо информация о том, что в программе имеются синтаксические ошибки и указание координат этих ошибок и их диагностика, либо представление программы в некотором промежуточном виде. Этим промежуточным видом может быть, предположим, бесскобочная запись, либо запись в виде деревьев (хотя одно однозначно сводится к другому). Это промежуточное представление, которое является синтаксически и лексически правильной программой, поступает на вход семантическому анализатору.
Семантический анализ. Семантика - это все то, что не описывается синтаксисом и лексикой языка. К примеру, лексикой и синтаксисом языка сложно описать то, что нехорошо передавать управление в тело цикла не через начало цикла. Выявление таких ошибок - одна из функций семантического анализа. при этом семантический анализатор ставит в соответствие синтаксически и семантически правильным конструкциям объектный код, т.е. происходит генерация кода.
Система программирования и трансляции - очень наукоемкая область программного обеспечения. Организация трансляторов - это было первое применение теоретических достижений науки, которые заключались в следующем. За счет возможности использования тех или иных грамматик (наборов формальных правил построения лексических конструкций и синтаксических правил), можно разделить программную реализацию лексических и синтаксических анализаторов на два компонента. Первый компонент - это программа, которая в общем случае ничего не знает о том языке, который она будет анализировать. Второй компонент - это набор данных, представляющий из себя формальное описание свойств языка, который мы анализируем. Совмещение этих двух компонентов, позволяет автоматизировать процесс построения лексических и синтаксических анализаторов, а также генераторов кода, для различных языков программирования. Современные системы программирования в своем составе имеют средства автоматизации построения компиляторов. Для ОС UNIX есть пакет LEX - пакет генерации лексических анализаторов, и есть пакет YACC - для генерации синтаксических анализаторов. Это все достигается за счет возможности формализации свойств языка, и использования этого формального описания, как параметров для тех или иных инструментальных средств.
Проходы трансляторов. Мы с вами посмотрели на транслятор с точки зрения функциональных этапов. Но очень часто мы слышим об однопроходных трансляторах, двухпроходных, трехпроходных, и т.д. С проблемой трансляции связано понятие "проход". Проход - это полный просмотр некоторого представления исходного текста программы.
Есть трансляторы однопроходные. Это означает, что транслятор просматривает исходный текст от начала и до конца, и к концу просмотра (в случае правильности программы) он получает объектный модуль.
Если мы посмотрим Си-компилятор, с которым вы работаете, то скорее всего он двухпроходный. Первый проход - это работа препроцессора. После первого прохода появляется чистая Си-программа без всяких препроцессорных команд. На Втором проходе происходит лексический, синтаксический и семантический анализ, и в итоге вы получаете объектную программу в виде ассемблера.
Количество проходов в некоторых трансляторах связано с количеством этапов, т.е. бывают реализации, для которых удобно сделать отдельный проход для лексического анализа, отдельный проход для синтаксического анализа и отдельный проход для семантического анализа. Если транслятор многопроходный, то возникает проблема сохранения промежуточной нотации программы между проходами.
Make-файл. К этой же проблеме кодирования относится средство поддержки разработки программных проектов. Одним из популярных средств, ориентированных на работу одного или нескольких программистов, является т.н. make-средство. Название происходит от соответствующей команды ОС UNIX. C make-командой связан т.н. make-файл, в котором построчно указываются взаимосвязи всевозможных файлов, получаемых при трансляции, редактировании связей, и т.д., и те действия, которые надо выполнить, если эти взаимосвязи нарушаются. В частности можно сказать, что некоторый исполняемый файл зависит от группы объектных файлов, и если эта связь нарушена, то надо выполнить команду редактирования связей (link ...). Что значит нарушение зависимости и что значит связь? Make-команда проверяет существование этих объектных файлов. Если они существуют, то времена их создания должны быть более ранние, чем время создания исполняемого файла. В том случае, если это правило будет нарушено (а это проверяет make-команда), то будет запущен редактор связей (link), который заново создаст исполняемый файл. Тем самым такое средство позволяет нам работать с программой, состоящей из большого количества модулей, и не заботиться о том, соответствует ли в данный момент времени исполняемый файл набору объектных файлов или не соответствует (можно просто запустить make-файл).
Make-файлы могут содержать большое количество такого рода строчек, которые таким образом свяжут не только объектные и исполняемые файлы, но и каждый из исходных файлов с соответствующим объектным файлом, и т.д. Т.е. суть такова, что после работы не надо каждый раз для каждого файла запускать компилятор, редактор связей, а можно просто запустить make-файл, а он уже сам определит и выберет те файлы, которые нужно корректировать, и выполнит необходимые действия. На самом деле такими средствами сейчас обладают почти все системы программирования.
Система контроля версий. Если make-файл - это система, предназначенная для одного программиста, в лучшем случае, для нескольких программистов, то если у нас существует большой коллектив, который делает большой программный проект, то используется т.н. система контроля версий, которая позволяет организовывать корректную работу больших коллективов людей над одним и тем же проектом, которая основана на возможности декларации версий и осуществлении контроля за этими версиями.
Этапы тестирования и отладки
Тестирование - это поиск ситуации, в которой программный продукт не работает. При этом используются наборы тестов, определяющих внешнюю нагрузку на программный продукт. Можно сказать, что программа оттестирована на определенном наборе тестов. Утверждение, что программа оттестирована вообще в общем случае некорректно.
Отладка - это процесс поиска, локализации и исправления ошибки. Отладка осуществляется, когда мы имеем программную систему, и знаем, что она не работает на каком-то из тестов.
Проблемы тестирования и отладки - это есть проблемы крайней важности. По оценкам, на тестирование и отладку затрачивается порядка 30% времени разработки проекта. Сложность тестирования и отладки зависит от качества проектирования и кодирования. Тестирования зачастую выполнить сложно и часто для тестирования используются модельные нагрузки, например мы тестируем бортовую сеть самолета, что-то мы сможем сделать на земле, а что-то так или иначе делается уже на реальном полете, когда собираются данные и фиксируется работает система или не работает.
Лекция №21
Тема, которую мы с вами начнем рассматривать будет короткой и простой, и мы обозначим основные болевые точки. Детали и подробности вы должны изучить сами.
Командный язык ОС UNIX CSHELL (CSH)Для многих пользователей программного обеспечения основным и единственным свойством, на которое обращает внимание пользователь, является не внутреннее устройство системы, а тот интерфейс, который предоставляется системой пользователю. Почти каждая система имеет средства интерактивного взаимодействия с пользователем, т.е. средства, которые позволяют в той или иной форме вводить запросы на выполнение действий. С этой точки зрения UNIX поддерживает возможность работы с произвольным количеством интерпретаторов команд. В файле /etc/passwd/ одно из полей, относящихся к данному пользователю, содержит полное имя интерпретатора команд, который должен быть запущен при входе пользователя в систему. В общем случае, при входе пользователя в систему может быть запущена абсолютно любая программа.
Традиционными интерпретаторами команд в системе UNIX являются SH, CSH и BASH. Давайте рассмотрим на концептуальном уровне что такое СSH (в принципе все интерпретаторы команд похожи друг на друга и являются некоторым расширением SH).
Интерпретатор команд определяет структуру вводимой команды. Команда (для CSH) - это последовательность символов, заканчивающаяся некоторым кодом, и которая состоит из слов. Слова - это последовательности символов, не содержащих разделители. Разделители - это набор фиксированных символов, в частности привычным для нас разделителем является пробел. Кроме пробела разделителями служат запятые, знаки < >, и т.д. Каждый из этих разделителей имеет свою интерпретацию. В частности, символ "|" означает создание конвейера. Например команда ls|more позволит избежать быстрый вывод текста на экран и за экран, и позволит пролистать его.
Система UNIX поддерживает набор специальных символов, которые называются метасимволами. Метасимволы обычно встречаются в словах команды и интерпретируются по заранее определенным правилам. Метасимволов существует много, в частности среди них есть знакомые нам * и ?. Команда rm * удалит все файлы не начинающиеся с точки в текущем каталоге. ? означает, что на месте этого символа может быть один любой знак. Метасимволы могут быть парными. Например внутри квадратных скобок указывается альтернативная группа, предположим, [abc] означает, что вместо этой квадратной скобки может быть один из перечисленных в ней символов (любую цифру можно задать так [0-9]).
CSH позволяет объединять команды. Для этого также используются метасимволы. Если внутри круглых скобок перечислены некоторые команды, то запустится еще один интерпретатор, который выполнит эту последовательность команд. Например команда (cd /etc; ls -la|grep pas) сменит каталог и осуществит поиск в этом каталоге строки pas.
В чем разнится между тем, выполнилась ли эта команда в интерпретаторе с которым мы работаем, или если был запущен еще один интерпретатор. Разница в том что, в этом случае не изменится текущий каталог, несмотря на то, что выполнилась команда смены каталога.
Имеется возможность объединять команды с использованием {}. Все команды, перечисленные в фигурных скобках будут запущены слева направо, но при этом на стандартный вывод будет положена объединенная последовательность стандартных выводов всех команд. {more t.b; more t.c}>tt.b - в файле tt.b окажется стандартный вывод одной команды, а затем стандартный вывод другой, эта команда без фигурных скобок поместила бы туда стандартный вывод только второй команды.
Интерпретатор команд имеет набор встроенных команд. Все команды подразделяются на два типа:
Похожие работы
... с приглашением по запросу (в машинной графике)required parameter обязательный параметрrequired space обязательный пробел (в системах подготовки текстов)requirements specification 1. техническое задание 2. описание требований к программному средствуrerun перезапуск, повторный запускreschedule переупорядочивать очередь (о диспетчере операционной системы)reschedule interval период переупорядочения ...
... ориентированы на 32 разрядные шинные архитектуры компьютеров с процессорами 80386, 80486 или Pentium. Фирма Novell также подготовила варианты сетевой ОС NetWare, предназначенные для работы под управлением многозадачных, многопользовательских операционных систем OS/2 и UNIX. Версию 3.12 ОС NetWare можно приобрести для 20, 100 или 250 пользователей, а версия 4.0 имеет возможность поддержки до 1000 ...
... было очень своевременным. Оно ознаменовало рождение операционной системы, распространяемой с открытыми исходными кодами. Р. Столлман, конечно, прав, когда настаивает на том, что операционная система Linux должна называться GNU/Linux. Но так уж сложилось, что название ядра стало служить названием всей операционной системы, и мы в этой книге будем поступать так же. 3 Основные характеристики ОС ...

... при создании и отличают ее до сих пор. Более того, несмотря на старания господина Гейтса, ситуация такова, что он повторяет те программные интерфейсы, которые используются для взаимодействия управления процессами, а не фирмы разработчики UNIX-ов повторяют те интерфейсы, которые появились в Windows. Первенство операционной системы UNIX очевидно. Мы говорили о том, что процесс в UNIX-е - это есть ...
0 комментариев