Навигация
Advanced Dynamic Execution
31442
знака
3
таблицы
19
изображений
1.2 Advanced Dynamic Execution
Целью ряда ухищрений в архитектуре Pentium 4, под общим названием Advanced Dynamic Execution, как раз и является минимизация простоя процессора при неправильном предсказании переходов и увеличение вероятности правильных предсказаний. Для этого Intel улучшил блок выборки инструкций для внеочередного выполнения и повысил правильность предсказания переходов. Правда, для этого алгоритмы предсказания переходов были доработаны минимально, основным же средством для достижения цели было выбрано увеличение размеров буферов, с которыми работают соответствующие блоки процессора.![]() Так, для выборки следующей инструкции для исполнения используется теперь окно величиной в 126 команд против 42 команд у процессора Pentium III. Буфер же, в котором сохраняются адреса выполненных переходов и на основании которого процессор предсказывает будущие переходы, теперь увеличен до 4 Кбайт, в то время как у Pentium III его размер составлял всего 512 байт.
Так, для выборки следующей инструкции для исполнения используется теперь окно величиной в 126 команд против 42 команд у процессора Pentium III. Буфер же, в котором сохраняются адреса выполненных переходов и на основании которого процессор предсказывает будущие переходы, теперь увеличен до 4 Кбайт, в то время как у Pentium III его размер составлял всего 512 байт.![]() Результатом этого, а также благодаря небольшой доработке алгоритма, вероятность правильного предсказания переходов была улучшена по сравнению с Pentium III на 33%. Это – очень хороший показатель, поскольку теперь Pentium 4 предсказывает переходы правильно в 90-95% случаев.
Результатом этого, а также благодаря небольшой доработке алгоритма, вероятность правильного предсказания переходов была улучшена по сравнению с Pentium III на 33%. Это – очень хороший показатель, поскольку теперь Pentium 4 предсказывает переходы правильно в 90-95% случаев.
1.3 Trace Cache
Вместо обычного L1 кеша, который в Pentium III был разделен на область инструкций и область данных в Pentium 4 применен новый подход. Инструкции в L1 кэше не сохраняются, он предназначен теперь только для данных. Для кэширования инструкций теперь используется Trace Cache, однако по сравнению с обычным L1-кешем он имеет много преимуществ, направленных опять же на минимизацию простоев процессора при выполнении неправильных предсказаний переходов.![]() Первое, и основное – в Trace Cache сохраняются уже декодированные инструкции. Это значит, что в нем хранятся не классические x86 инструкции, а так называемые микрокоманды, более простые операции которыми непосредственно оперирует процессорное ядро. Сохранение в Trace Cache микроопераций позволяет избежать повторного декодирования x86 инструкций при повторном выполнении того же участка программы или при неправильном предсказании переходов.
Первое, и основное – в Trace Cache сохраняются уже декодированные инструкции. Это значит, что в нем хранятся не классические x86 инструкции, а так называемые микрокоманды, более простые операции которыми непосредственно оперирует процессорное ядро. Сохранение в Trace Cache микроопераций позволяет избежать повторного декодирования x86 инструкций при повторном выполнении того же участка программы или при неправильном предсказании переходов.
Второе преимущество Trace Cache заключается в том, что микрооперации в нем сохраняются именно в том порядке, в каком они выполняются. Правда, правильный порядок определяется опять же на основании предсказания переходов, однако вероятность того, что переходы предсказываются неправильно, достаточно мала для того, чтобы отказаться от очевидного выигрыша, получаемого путем отказа от повторных декодирований и предсказаний переходов.
Intel не раскрывает размеров своего Trace Cache в килобайтах, однако, известно что в нем может быть сохранено до 12000 микроопераций.
1.4 Rapid Execute Engine
Наиболее простая часть современного процессора – это ALU (арифметико-логическое устройство). Благодаря этому факту, Intel счел возможным увеличить его тактовую частоту внутри Pentium 4 вдвое по отношению к самому процессору. Таким образом, например, в 1.4 ГГц Pentium 4 ALU работает на частоте 2.8 ГГц.
В ALU исполняются простые целочисленные инструкции, поэтому, производительность нового процессора при операциях с целыми числами должна быть очень высокой. Однако, на производительности Pentium 4 при операциях с вещественными числами, MMX или SSE двукратное ускорение ALU никак не сказывается.![]() Таким образом, латентность ALU существенно снижается. В частности, на выполнение одной инструкции типа add Pentium 4 1.4 ГГц тратил всего 0.35нс, в то время как выполнение этой команды у Pentium III 1 ГГц занимает 1 нс.
Таким образом, латентность ALU существенно снижается. В частности, на выполнение одной инструкции типа add Pentium 4 1.4 ГГц тратил всего 0.35нс, в то время как выполнение этой команды у Pentium III 1 ГГц занимает 1 нс.
1.5 SSE2
Реализовав в своем процессоре Athlon новый конвейерный FPU, AMD очень сильно обогнала интеловский Pentium III в производительности при операциях с вещественными числами. Однако, Intel в своем Pentium 4 не стал сосредотачиваться на совершенствовании своего FPU, а просто увеличил возможности блока SSE. В результате, в Pentium 4 имеет место расширенный набор команд SSE2, в котором к имеющемуся набору из 70 инструкций было добавлено еще 144. Такое решение – результат NetBurst идеологии, основной целью которой является увеличение скорости работы с потоками данных.![]() Инструкции SSE позволяли оперировать с восемью 128-битными регистрами XMM0..XMM7, в которых хранились по четыре вещественных числа одинарной точности. При этом все SSE операции проводились одновременно над четверками чисел, в результате чего специально оптимизированные программы, в которых производилось большое количество однотипных вычислений (а к ним, помимо обработки потоков данных в какой-то мере относятся и 3D-игры), получали существенный прирост в производительности.
Инструкции SSE позволяли оперировать с восемью 128-битными регистрами XMM0..XMM7, в которых хранились по четыре вещественных числа одинарной точности. При этом все SSE операции проводились одновременно над четверками чисел, в результате чего специально оптимизированные программы, в которых производилось большое количество однотипных вычислений (а к ним, помимо обработки потоков данных в какой-то мере относятся и 3D-игры), получали существенный прирост в производительности.
SSE2 же оперирует с теми же самыми регистрами и обратно совместим с SSE процессора Pentium III. А столь впечатляющее расширение набора команд вызвано тем, что теперь операции со 128-битными регистрами могут выполняться не только как с четверками вещественных чисел двойной точности, но и как с парами вещественных чисел двойной точности, с шестнадцатью однобайтовыми целыми, с восемью короткими двухбайтовыми целыми, с четырьмя четырехбайтовыми целыми, с двумя восьмибайтовыми целыми или с 16 байтовыми целыми. То есть, теперь SSE2 представляя собой симбиоз MMX и SSE и позволяет работать с любыми типами данных, влезающими в 128-битные регистры.
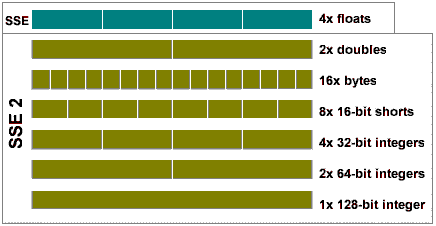
Таким образом, SSE2 гораздо более гибок, позволяя добиваться впечатляющего прироста в производительности. Однако, использование нового набора команд требует специальной оптимизации программ, поэтому ждать его внедрения сразу после выхода нового процессора не стоит. Со временем же, SSE2 имеет достаточно большие перспективы. Поэтому, даже AMD собирается реализовать SSE2 в своем новом семействе процессоров Hammer.
Старые же программы, не использующие SSE2, а полагающиеся на обычный арифметический сопроцессор, никакого прироста в производительности при использовании Pentium 4 не получат. Более того, несмотря на то, что что Intel говорит о том, что блок FPU в Pentium 4 был слегка усовершенствован, время, необходимое на выполнение обычных операций с вещественными числами возросло по сравнению с Pentium III в среднем на 2 такта.
Похожие работы
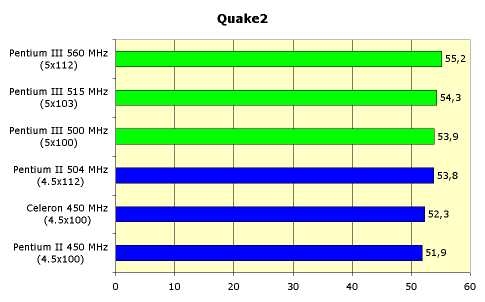
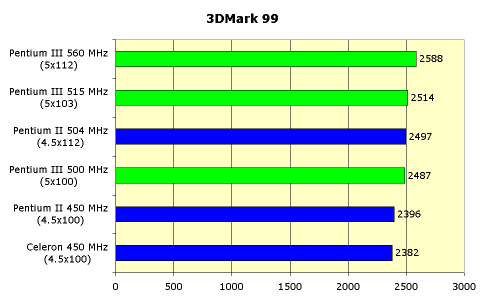
... потокового доступа к памяти. Однако эти изменения не дают никаких особых преимуществ в производительности, а носят скорее косметический характер. Мы же озаботимся вопросом практического функционирования процессора Intel Pentium III. Во-первых, необходимо иметь в виду, что для запуска системы на новом процессоре новая системная плата не требуется. Нужна всего-навсего обновленная версия BIOS, ...


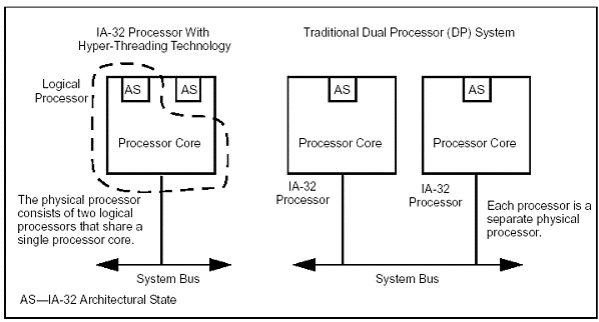
... , к радости всего прогрессивного человечества, Intel выпустила новый Pentium 4, производительность которого еще выше чем у предыдущего Pentium 4, и дело тут не только в лишних двухстах мегагерцах, а и в новой технологии под названием – Hyper-Threading Технология Hyper-Threading с теоретической точки зрения выглядит весьма неплохо и соответствует реалиям сегодняшнего дня. Уже довольно редко можно ...
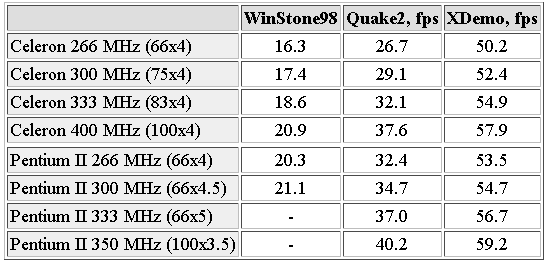
... . Это событие должно быть приурочено к появлению двух новых процессоров - 350MHz и 400MHz Pentium II, ожидаемые цены на которые -- $610 и $810, соответственно. Pentium II 350MHz и 400MHz будут первыми процессорами от Intel, работающие с внешней шинной частотой 100MHz. Нетрудно заметить, что ожидаемая начальная цена на 350MHz и 400MHz версии Pentium II ниже примерно на $120 и $170, соответственно, ...
... возможным отвержением из-за нарушения последовательности инструкций – промахов в предсказании. На конечном этапе порядок инструкций и результатов их выполнения восстанавливается до первоначального. Новейшей разработкой Intel в технологии корпусов микропроцессоров является картридж с односторонним контактом (Single Edge Contact - S.E.C.). При использовании этой технологии, ядро процессора ...
0 комментариев