Навигация
Модели теории адаптивного резонанса
60598
знаков
0
таблиц
10
изображений
2.3 Модели теории адаптивного резонанса
Напомним, что дилемма стабильности-пластичности является важной особенностью обучения методом соревнования. Как обучать новым явлениям (пластичность) и в то же время сохранить стабильность, чтобы существующие знания не были стерты или разрушены?
Карпентер и Гроссберг, разработавшие модели теории адаптивного резонанса (ART1, ART2 и ARTMAP), сделали попытку решить эту дилемму. Сеть имеет достаточное число выходных элементов, но они не используются до тех пор, пока не возникнет в этом необходимость. Будем говорить, что элемент распределен (не распределен), если он используется (не используется). Обучающий алгоритм корректирует имеющийся прототип категории, только если входной вектор в достаточной степени ему подобен. В этом случае они резонируют. Степень подобия контролируется параметром сходства k, 0<k<1, который связан также с числом категорий. Когда входной вектор недостаточно подобен ни одному существующему прототипу сети, создается новая категория, и с ней связывается нераспределенный элемент со входным вектором в качестве начального значения прототипа. Если не находится нераспределенного элемента, то новый вектор не вызывает реакции сети.
Чтобы проиллюстрировать модель, рассмотрим сеть ART1, которая рассчитана на бинарный (0/1) вход. Упрощенная схема архитектуры ART1 представлена на рис. 7. Она содержит два слоя элементов с полными связями.
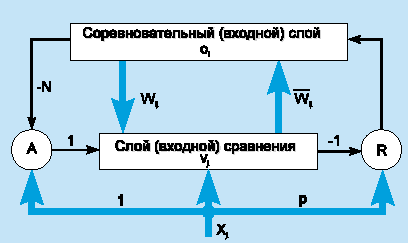
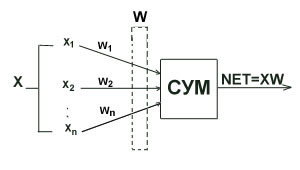
Рис.7 - Архитектура ART1
Направленный сверху вниз весовой вектор wj соответствует элементу j входного слоя, а направленный снизу вверх весовой вектор i связан с выходным элементом i; i является нормализованной версией wi . Векторы wj сохраняют прототипы кластеров. Роль нормализации состоит в том, чтобы предотвратить доминирование векторов с большой длиной над векторами с малой длиной. Сигнал сброса R генерируется только тогда, когда подобие ниже заданного уровня.
Модель ART1 может создать новые категории и отбросить входные примеры, когда сеть исчерпала свою емкость. Однако число обнаруженных сетью категорий чувствительно к параметру сходства.
3. Многослойный персептрон (MLP)
Вероятно, эта архитектура сети используется сейчас наиболее часто. Она была предложена в работе Rumelhart, McClelland (1986) и подробно обсуждается почти во всех учебниках по нейронным сетям. Вкратце этот тип сети был описан выше. Каждый элемент сети строит взвешенную сумму своих входов с поправкой в виде слагаемого и затем пропускает эту величину активации через передаточную функцию, и таким образом получается выходное значение этого элемента. Элементы организованы в послойную топологию с прямой передачей сигнала. Такую сеть легко можно интерпретировать как модель вход-выход, в которой веса и пороговые значения (смещения) являются свободными параметрами модели. Такая сеть может моделировать функцию практически любой степени сложности, причем число слоев и число элементов в каждом слое определяют сложность функции. Определение числа промежуточных слоев и числа элементов в них является важным вопросом при конструировании MLP.
Количество входных и выходных элементов определяется условиями задачи. Сомнения могут возникнуть в отношении того, какие входные значения использовать, а какие нет, - к этому вопросу мы вернемся позже. Сейчас будем предполагать, что входные переменные выбраны интуитивно и что все они являются значимыми. Вопрос же о том, сколько использовать промежуточных слоев и элементов в них, пока совершенно неясен. В качестве начального приближения можно взять один промежуточный слой, а число элементов в нем положить равным полусумме числа входных и выходных элементов. Опять-таки, позже мы обсудим этот вопрос подробнее.
3.1 Обучение многослойного персептрона
После того, как определено число слоев и число элементов в каждом из них, нужно найти значения для весов и порогов сети, которые бы минимизировали ошибку прогноза, выдаваемого сетью. Именно для этого служат алгоритмы обучения. С использованием собранных исторических данных веса и пороговые значения автоматически корректируются с целью минимизировать эту ошибку. По сути, этот процесс представляет собой подгонку модели, которая реализуется сетью, к имеющимся обучающим данным. Ошибка для конкретной конфигурации сети определяется путем прогона через сеть всех имеющихся наблюдений и сравнения реально выдаваемых выходных значений с желаемыми (целевыми) значениями. Все такие разности суммируются в так называемую функцию ошибок, значение которой и есть ошибка сети. В качестве функции ошибок чаще всего берется сумма квадратов ошибок, т.е. когда все ошибки выходных элементов для всех наблюдений возводятся в квадрат и затем суммируются.
В традиционном моделировании (например, линейном моделировании) можно алгоритмически определить конфигурацию модели, дающую абсолютный минимум для указанной ошибки. Цена, которую приходится платить за более широкие (нелинейные) возможности моделирования с помощью нейронных сетей, состоит в том, что, корректируя сеть с целью минимизировать ошибку, мы никогда не можем быть уверены, что нельзя добиться еще меньшей ошибки.
В этих рассмотрениях оказывается очень полезным понятие поверхности ошибок. Каждому из весов и порогов сети (т.е. свободных параметров модели; их общее число обозначим через N) соответствует одно измерение в многомерном пространстве. N+1-е измерение соответствует ошибке сети. Для всевозможных сочетаний весов соответствующую ошибку сети можно изобразить точкой в N+1-мерном пространстве, и все такие точки образуют там некоторую поверхность - поверхность ошибок. Цель обучения нейронной сети состоит в том, чтобы найти на этой многомерной поверхности самую низкую точку.
В случае линейной модели с суммой квадратов в качестве функции ошибок эта поверхность ошибок будет представлять собой параболоид (квадрику) - гладкую поверхность, похожую на часть поверхности сферы, с единственным минимумом. В такой ситуации локализовать этот минимум достаточно просто.
В случае нейронной сети поверхность ошибок имеет гораздо более сложное строение и обладает рядом неприятных свойств, в частности, может иметь локальные минимумы (точки, самые низкие в некоторой своей окрестности, но лежащие выше глобального минимума), плоские участки, седловые точки и длинные узкие овраги.
Аналитическими средствами невозможно определить положение глобального минимума на поверхности ошибок, поэтому обучение нейронной сети по сути дела заключается в исследовании поверхности ошибок. Отталкиваясь от случайной начальной конфигурации весов и порогов (т.е. случайно взятой точки на поверхности ошибок), алгоритм обучения постепенно отыскивает глобальный минимум. Как правило, для этого вычисляется градиент (наклон) поверхности ошибок в данной точке, а затем эта информация используется для продвижения вниз по склону. В конце концов алгоритм останавливается в нижней точке, которая может оказаться всего лишь локальным минимумом (а если повезет - глобальным минимумом).
Похожие работы


... сети, позволяющая реализовать автоматическое изменение числа нейронов в зависимости от потребностей задачи, позволяет не только исследовать, но и контролировать процесс воспитания психологической интуиции искусственных нейронных сетей. - Впервые применена выборочная константа Липшица для оценки необходимой для решения конкретной задачи структуры нейронной сети. Практическая значимость ...
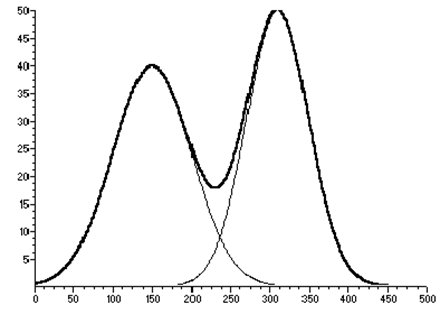
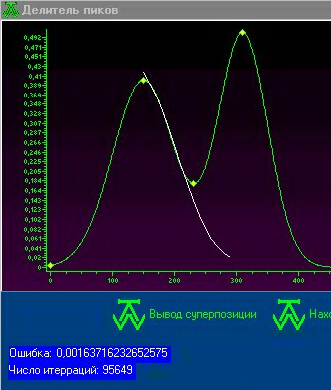
... пика, скрытого из-за суперпозиции с соседним, на основании открытой части пика. Целью данной работы является программная реализация искусственной нейросети, которая обеспечит разделение пиков на хроматограмме. 2 Теоретическое обоснование Поскольку искусственные нейронные сети позволяют аппроксимировать функции, прогнозировать – их можно прекрасно использовать для решения настоящей проблемы: ...
... одном из элективных курсов. Выбор естественно-математического профиля, во-первых, определяется целью введения данного курса в школе (расширение научного мировоззрения) и, во-вторых, сложностью темы в математическом аспекте. Глава 2. Содержание обучения технологии нейронных сетей Авторы данной работы предлагают следующее содержание обучения технологии нейронных сетей. Содержание образования ...

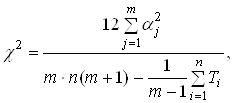
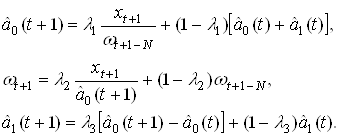
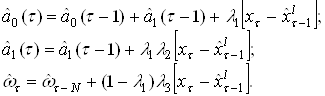
... МП к некритическому экстраполированию результата считается его слабостью. Сети РБФ более чувствительны к «проклятию размерности» и испытывают значительные трудности, когда число входов велико. 5. МОДЕЛИРОВАНИЕ НЕЙРОННЫХ СЕТЕЙ ДЛЯ ПРОГНОЗИРОВАНИЯ СТОИМОСТИ НЕДВИЖИМОСТИ 5.1 Особенности нейросетевого прогнозирования в задаче оценки стоимости недвижимости Использование нейронных сетей можно ...
0 комментариев