Навигация
1 ПОСТАНОВКА ЗАДАЧИ
Необходимо разработать систему сжатия речи, обеспечивающую сжатие речи до уровня 2400 бит/с и ниже с помощью алгоритмов векторного квантования. Предусмотреть несколько ступеней сжатия. Обеспечить работу системы в двух режимах: дикторо-зависимом и дикторо-независимом. Реализовать систему в пакете MATLAB и подсистему декодирования в реальном времени с помощью ЦПОС TMS320C7711/5402.
2 ОПИСАНИЕ СУЩЕСТВУЮЩИХ МЕТОДОВ СЖАТИЯ РЕЧИ
Многие методы сжатия речевых сигналов основаны на линейном предсказании речи. В частности, линейное предсказание используется при сжатии речи по методу АДИКМ. Стандарт G726, определяющий алгоритмы АДИКМ, устанавливает для данного типа сжатия речевых сигналов нижнюю скорость передачи 16 Кбит/с .
Дальнейшее снижение скорости передачи возможно при использовании схем анализ-синтез речи, учитывающих особенности цифровой модели формирования речи. Применяют два варианта таких схем – без обратной связи и с обратной связью.
На рисунке 2.1 (а) приведена схема сжатия речи без обратной связи, основанная на анализе по методу линейного предсказания и синтезе речевого сигнала. Здесь речевой сигнал s[n] разбивается на сегменты длительностью 20-39 мс. На каждом из сегментов с помощью устройства оценивания (УО) определяются коэффициенты линейного инверсного фильтра-анализа Ф1 десятого порядка. Кроме этого, на этапе сжатия с помощью выделения основного тона (ОТ) и анализатора тон-шум (Т-Ш) определяются соответствующие параметры функции возбуждения. В кодере выполняется кодирование коэффициентов фильтра и параметров функции возбуждения, которые затем передаются по каналу связи или сохраняются в памяти.
В восстанавливающем устройстве (рисунок 2.1 а) сначала происходит декодирование коэффициентов фильтра и параметров функции возбуждения, а затем выполняется синтез речевого сигнала S^[n]. Для этого в зависимости от значения признака тон-шум (ТШ) на вход фильтра-синтеза Ф2 подается сигнал либо с выхода генератора тона (ГТ), либо с выхода генератора шума (ГШ). В технике связи устройство, выполняющее сжатие и восстановление речевых сигналов по приведенной схеме, называют вокодером. Для кодирования периода основного тона используют 6 бит, для коэффициентов усиления - 5 бит, для признака тон/шум – 1 бит, для коэффициента усиления – 5 бит, для коэффициентов линейного предсказания – 8-10 бит. С учетом того, что для каждого сегмента речи оценивается 10 коэффициентов предсказания, получим 97-117 бит на один сегмент. Скорость передачи при длительности сегмента 30 мс составит примерно 3000 бит/секунду.
В системе, изображенной на рисунке 2.1 б), параметры возбуждения (частота основного тона, признак тон/шум, форма сигнала возбуждения) формируются без учета их влияния на качество синтезированной речи, поэтому восстановленная речь как механическая и не обеспечивает узнаваемости голоса.
а)
|
|
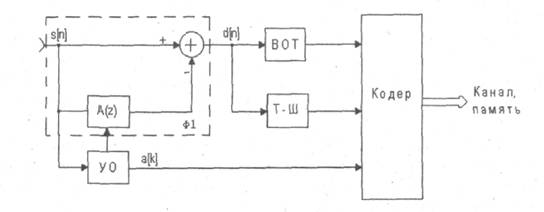
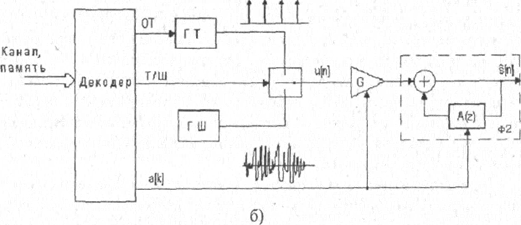
Рисунок 2.1 - Сжатие речевых сигналов в схеме без обратных связей
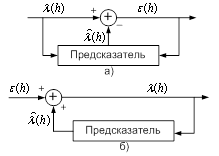
Для повышения натуральности речи используется схема анализа-синтеза с обратной связью (рисунок 2.2). В этой схеме возбуждающая последовательность формируется путем минимизации ошибки восстановления речевого сигнала, т.е. разности между исходным речевым сигналом s[n] и восстановленным сигналом S[n]. Восстановленный речевой сигнал формируется с помощью фильтров Ф1 и Ф2, на вход которых подается сигнал с выхода генератора функции возбуждения (ФВ). Фильтр Ф1 учитывает квазипериодические свойства вокализованных участков речи, а фильтр Ф2 моделирует формантную структуру речи. Инверсный фильтр, соответствующий фильтру Ф1, является фильтром долговременного предсказания, а инверсный фильтр, соответствующий фильтру Ф2, называется фильтром кратковременного предсказания.
Фильтр долговременного предсказания описывается передаточной функцией
PL(z) = 1- AL(z), (2.1)
где AL(z)-az^-t и t - задержка, соответствующая периоду основного тона, равная 20-150 интервалам дискретизации. Если на вход фильтра долговременного предсказания подать сигнал ошибки кратковременного предсказания dK[n], то в соответствии с (2.1) ошибка долговременного предсказания dД{[n] будет равна:
dД[n] = dK[n] - adK[n-T] (2.2)

Рисунок 2.2 - Сжатие речевых сигналов в схеме анализ-синтез
Данная ошибка по своим свойствам близка к белому шуму с нормальным законом распределения. Это упрощает формирование сигнала возбуждения, так как при синтезе последовательности S[n] ошибка долговременного предсказания выступает в роли сигнала возбуждения.
Фильтр с передаточной функцией W(z) (рисунок 2.2) позволяет учесть особенности слухового восприятия человека. Для человека шум наименее заметен в частотных полосах сигнала с большими значениями спектральной плотности. Этот эффект называют маскировкой. Фильтр W(z) учитывает эффект маскировки и придает ошибке восстановления различный вес в разных частотных диапазонах. Вес выбирается так, чтобы ошибка восстановления маскировалась в полосах речевого сигнала с высокой энергией.
Принцип работы схемы, изображенной на рисунке 2.2, состоит в выборе функции возбуждения (ФВ), минимизирующей квадрат ошибки (МКО) восстановления.
Существует несколько различных способов формирования функции возбуждения: многоимпульсное, регулярно-импульсное и векторное (кодовое) возбуждение. Соответствующие алгоритмы представляют много-импульсное (MLPC), регулярно-импульсное (RPE-LPC) и линейное предсказание с кодовым возбуждением (code excited linear prediction - CELP). MLPC использует функцию возбуждения, состоящую из множества нерегулярных импульсов, положение и амплитуда которых выбирается так, чтобы минимизировать ошибку восстановления. Алгоритм RPE-LPC является разновидностью MLPC, когда импульсы имеют регулярную расстановку. В этом случае оптимизируется амплитуда и относительное положение всей последовательности импульсов в пределах сегмента речи. CELP представляет способ, который основывается на векторном квантований. В соответствии с этим способом из кодовой книги возбуждающих последовательностей выбирается квазислучайный вектор, который минимизирует квадрат ошибки восстановления. Кодовая книга используется как на этапе сжатия речевого сигнала, так и на этапе его восстановления. Для восстановления сегмента речевого сигнала необходимо знать номер соответствующего вектора возбуждения в кодовой книге, параметры фильтров A\.(z) и A(z), коэффициент усиления СУ. Восстановление речевого сигнала по указанным параметрам выполняется в декодере только с помощью элементов, входящих в верхнюю часть схемы, изображенной на рисунке 2.2.
В настоящее время применяется несколько стандартов, основывающихся на рассмотренной схеме сжатия:
1) RPE-LPC со скоростью передачи 13 Кбит/с используется в качестве стандарта мобильной связи в Европейских странах;
2)CELP со скоростью передачи 4,8 Кбит/с. Одобрен в США федеральным стандартом FS-1016. Используется в системах скрытой телефонной связи;
3)VCELP со скоростью передачи 7,95 Кбит/с (vector sum excited linearprediction). Используется в цифровых сотовых системах в Северной Америке. VCELP со скоростью передачи 6,7 Кбит/с принят в качестве стандарта в сотовых сетях Японии;
4)LD-CELP (low-delay CELP) одобрен стандартом МККТТ G.728. Вданном стандарте достигается небольшая задержка примерно 0,625 мс(обычно методы CELP имеют задержку 40-60 мс), используются короткие векторы возбуждения и не применяется фильтр долговременного предсказания с передаточной функцией АL(z).
Необходимо отметить, что рассмотренные методы сжатия речи, использующие линейное предсказание с кодовым возбуждением, хорошо приспособлены для работы с речевыми сигналами в среде без шумов. В случае шумового воздействия на речевые сигналы синтезированная речь имеет плохое качество. Поэтому в настоящее время разрабатывается ряд методов линейного предсказания с кодовым возбуждением для использования в шумовой обстановке (ACELP, CS-CELP).
На рисунке 2.3,а изображена обобщенная схема сжатия речевого сигнала с помощью алгоритмов векторного квантования.
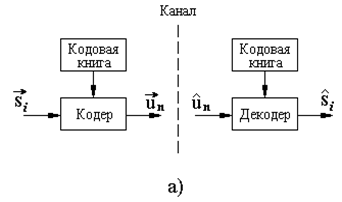 |  | ||
Рисунок 2.3 – Векторное квантование
Входной вектор si представляет собой вектор признаков речевого сигнала (например, спектральных),
![]() .
.
Кодер отображает входной вектор ![]() в выходной символ un, n = 1, 2, …, L с помощью кодовой книги. Кодовая книга содержит L векторов
в выходной символ un, n = 1, 2, …, L с помощью кодовой книги. Кодовая книга содержит L векторов
![]() , n = 1, 2, …, L.
, n = 1, 2, …, L.
Предположим, что канал не имеет шумов, т.е. ![]() .
.
Векторный квантователь функционирует следующим образом. Входной вектор ![]() сравнивается с каждым вектором из кодовой книги. В результате из кодовой книги выбирается вектор
сравнивается с каждым вектором из кодовой книги. В результате из кодовой книги выбирается вектор ![]() , ближайший к вектору
, ближайший к вектору ![]() , и в канал передается символ un, представляющий адрес найденного кодового вектора. На приемной стороне с помощью полученного адреса un восстанавливается вектор признаков речевого сигнала
, и в канал передается символ un, представляющий адрес найденного кодового вектора. На приемной стороне с помощью полученного адреса un восстанавливается вектор признаков речевого сигнала ![]() , на основе которого синтезируется речевой процесс. В такой интерпретации векторное квантование, по сути, является распознаванием образов, где вектор
, на основе которого синтезируется речевой процесс. В такой интерпретации векторное квантование, по сути, является распознаванием образов, где вектор ![]() представляет собой входной образ, кодовая книга соответствует базе эталонов.
представляет собой входной образ, кодовая книга соответствует базе эталонов.
В качестве меры расстояния между входными векторами и векторами из кодовой книги обычно используется сумма квадратов отклонений si(k) и ![]() :
:
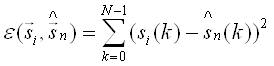 (2.3)
(2.3)
Кодовая книга (база эталонов) создается путем разделения N - мерного пространства признаков на L непрерывающихся ячеек (областей) (рисунок 2.3,а). Каждая ячейка ассоциируется Cn с вектором-эталоном ![]() . Если входной вектор
. Если входной вектор ![]() принадлежит ячейке Cn, то квантователь назначает этому вектору символ un, который представляет собой адрес вектора-эталона данной ячейки (центроида).
принадлежит ячейке Cn, то квантователь назначает этому вектору символ un, который представляет собой адрес вектора-эталона данной ячейки (центроида).
В простейшем случае, если вектор ![]() представляет собой блок отсчетов речевого сигнала, рассмотренная схема квантования является обобщением импульсной кодовой модуляции (ИКМ), и называется векторной ИКМ. В векторной ИКМ (ВИКМ) число битов, приходящихся один отсчет речевого сигнала определяется по формуле
представляет собой блок отсчетов речевого сигнала, рассмотренная схема квантования является обобщением импульсной кодовой модуляции (ИКМ), и называется векторной ИКМ. В векторной ИКМ (ВИКМ) число битов, приходящихся один отсчет речевого сигнала определяется по формуле
 (2.4)
(2.4)
ВИКМ имеет преимущество перед различными видами ИКМ [ 1 ], если ![]() .
.
Процесс проектирования кодовой книги, который связан с обучением, может быть реализован двумя способами. В первом случае кодовая книга разрабатывается на основе алгоритма К-средних. Рекомендуется, чтобы обучающая выборка содержала по 40 примеров векторов признаков для каждого кодового вектора. Вычислительную сложность разработки кодовой книги можно снизить, если определенным образом структурировать кодовую книгу. Действительно, так как в процессе построения кодовой книги выполняется поиск среди L векторов-эталонов, то упорядочение книги может привести к сокращению времени поиска. Для ускорения поиска часто применяют бинарные деревья [2]. Сложность вычислений можно уменьшить, если в кодовой книге отдельно хранить нормализованные векторы ![]() и масштабный коэффициент G (коэффициент усиления).
и масштабный коэффициент G (коэффициент усиления).
Во втором случае кодовая книга создается с помощью алгоритма обучения, в соответствии с которым положение центроидов на каждом шаге уточняется по рекуррентной формуле
![]() , (2.5)
, (2.5)
где t – номер шага; α - коэффициент обучения, α ~![]() .Формула уточняет положение только того центроида, для которого входной вектор
.Формула уточняет положение только того центроида, для которого входной вектор ![]() оказался ближайшим.
оказался ближайшим.
Выражение (2.5) соответствует правилу обучения состязательных нейронных сетей, в частности, правилу Кохонена. Подробнее см. в [2].
Существует различные схемы сжатия речи c помощью алгоритмов векторного квантования. Большинство из них основано на схеме “анализ-синтез”. Применяют два варианта таких схем – без обратной связи и с обратной связью [1]. В основе каждой из схем лежит модель синтеза речи на основе коэффициентов линейного предсказания [1]. В соответствии с этой моделью речь может быть получена путем подачи специальным образом подобранного возбуждающего сигнала на вход линейного фильтра, который моделирует резонансные частоты голосового тракта. Передаточная функция фильтра описывается уравнением
 (2.6)
(2.6)
где G - коэффициент усиления, ai - коэффициенты линейного предсказания, P - порядок предсказателя.
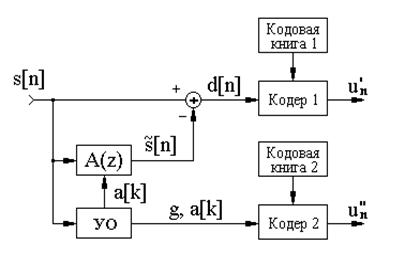
Возможная структурная схема системы низкоскоростного кодирования речи с помощью алгоритмов векторного квантования изображена на рисунке 2.2.
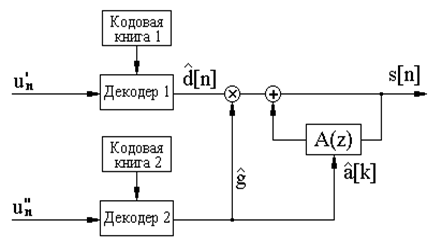 |
Рисунок 2.4 – Низкоскоростное кодирование речи
Процедура кодирования речи сводится к следующему:
- оцифрованный речевой сигнал s[n] нарезается на сегменты длительностью 20 мс (при fg=8 КГц в каждом сегменте будет по 160 выборок);
- для каждого сегмента вычисляются с помощью устройства оценивания (УО) параметры фильтра линейного предсказания и определяется ошибка предсказания d[n], соответствующая функции возбуждения;
- функция возбуждения и параметры фильтра линейного предсказания кодируются с помощью отдельных векторных квантователей и передаются в канал.
Процедура декодирования заключается в пропускании восстановленного сигнала возбуждения через синтезирующий фильтр (2.4), параметры которого переданы одновременно с функцией возбуждения.
Приведенное описание процессов кодирования и декодирования речи не является исчерпывающим, оно объясняет лишь принцип действия кодера. Практические схемы намного сложнее, и это связано в основном со следующими двумя моментами.
Во-первых, на рисунке 2.2 изображена схема без обратной связи. Лучшего качества синтезируемой речи можно добиться в схемах с обратной связью [1]. Однако такие схемы сложнее.
Во-вторых, описанная выше схема, использует кратковременное предсказание и не обеспечивает в достаточной степени устранения избыточной речи. Поэтому в дополнение к кратковременному предсказанию используется еще и долговременное предсказание [1]. Выходной сигнал фильтра кратковременного предсказания используется для оценивания параметров фильтра долговременного предсказания – задержки τ и коэффициента предсказания a:
![]()
При оценке качества кодирования и сопоставлении различных кодеров оцениваются разборчивость речи и качество синтеза речи (качество звучания). Для оценки разборчивости речи используется метод ДРТ (диагностический рифмованный текст). В этом методе подбираются пары близких по звучанию слов, отличающиеся отдельными согласными (“кол-гол-пол”), которые многократно произносятся рядом дикторов, и по результатам испытаний оценивается доля искажений [3,4].
Для оценки качества звучания используется критерий ДМП (диагностическая мера приемлемости) [4]. Испытания заключаются в чтении несколькими дикторами, мужчинами и женщинами, ряда специально подобранных фраз, которые прослушиваются на выходе тракта связи рядом экспертов-слушателей, выставляющих свои оценки по 5-балльной шкале. Результатом является средняя оценка мнений (MOS).
Обратим внимание на следующий факт. Если кодовая книга создается на обучающих данных, принадлежащих только одному диктору, тоне следует ожидать, что она будет обеспечивать хорошее качество звучания для другого диктора. Соответственно, кодовая книга, полученная в лабораторных условиях, не обеспечит того же качества звучания при записи речи в шумовой обстановке, например, в салоне автомобиля. Для построения дикторо-независимой системы необходимо проектировать кодовую книгу на речевых сигналах различных дикторов.
Похожие работы

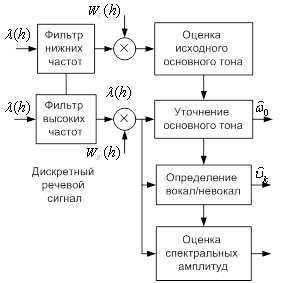
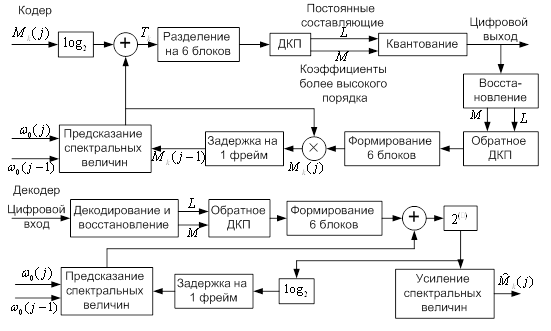
... – для каждого из четырех подсегментов. В табл. 5.2 приведено содержание выходной информации кодера с указанием числа бит, используемых для кодирования. Таблица 5.2 Кодирование выходной информации кодера речи стандарта D-AMPS Передаваемые параметры Число бит Примечание Параметры кратковременного предсказания (коэффициенты частичной корреляции , ) 38 – 6 бит; – по 5 бит; ...
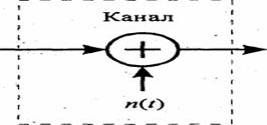
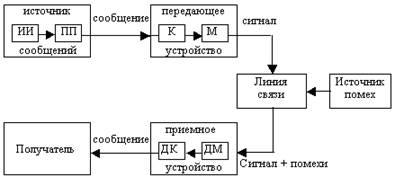
... за которым следует устройство дискретизации (рисунок 4.2), подастся известный сигнал s(t) плюс шум AWGN n(t). 4.4 Межсимвольная интерференция На рисунке 4.3 а) представлены фильтрующие элементы типичной системы цифровой связи. В системе - передатчике, приемнике и канале - используется множество разнообразных фильтров (и реактивных элементов, таких как емкость и индуктивность). В передатчике ...



... , работавших в области электротехники, заинтересовалась возможностью создания технологии хранения данных, обеспечивающей более экономное расходование пространства. Одним из них был Клод Элвуд Шеннон, основоположник современной теории информации. Из разработок того времени позже практическое применение нашли алгоритмы сжатия Хаффмана и Шеннона-Фано. А в 1977 г. математики Якоб Зив и Абрахам Лемпел ...




... необходимо загрузить весь файл целиком. Другим, не принципиальным, но существенным ограничением формата является большой объем полученных файлов. Таким образом, на телефонах появился формат видео, способный обеспечить высокое качество изображения при практически кинематографической частоте кадров. Качество воспроизведения зависит лишь от объема доступной памяти. Видеоролик проигрывается на полный ...
0 комментариев