Навигация
5 packet(s) transmitted
5 packet(s) received
0.00% packet loss
round-trip min/avg/max = 1/1/2 ms
deal mode: global
[Quidway] rip
[Quidway-rip] display rip
RIP is running
public net
Checkzero is on Default cost: 1
Summary is on Preference: 100
Validate-source-address is on
Traffic-share-across-interface is off
Period update timer: 30
Timeout timer: 180
Garbage-collection timer: 120
No peer router
[Quidway-rip] network 192.168.0.0
[Quidway-rip] display rip
RIP is running
public net
Checkzero is on Default cost: 1
Summary is on Preference: 100
Validate-source-address is on
Traffic-share-across-interface is off
Period update timer: 30
Timeout timer: 180
Garbage-collection timer: 120
No peer router
Network:
192.168.0.0
[Quidway-rip] peer 192.168.1.10
[Quidway-rip] display rip
RIP is running
public net
Checkzero is on Default cost: 1
Summary is on Preference: 100
Validate-source-address is on
Traffic-share-across-interface is off
Period update timer: 30
Timeout timer: 180
Garbage-collection timer: 120
Peer:
192.168.1.10
Network:
192.168.0.0
[Quidway-rip] undo peer 192.168.1.10
[Quidway-rip] display rip
RIP is running
public net
Checkzero is on Default cost: 1
Summary is on Preference: 100
Validate-source-address is on
Traffic-share-across-interface is off
Period update timer: 30
Timeout timer: 180
Garbage-collection timer: 120
No peer router
Network:
192.168.0.0
[Quidway-rip]
Quidway-rip] filter-policy gateway 192.168.1.10 import
The gateway does not exist, but the configuration is saved
[Quidway-rip] display rip
RIP is running
public net
Checkzero is on Default cost: 1
Checkzero is on Default cost: 1
Validate-source-address is on
Traffic-share-across-interface is off
Period update timer: 30
Timeout timer: 180
Garbage-collection timer: 120
No peer router
Network:
192.168.0.0
filter-policy gateway 192.168.1.10 import
[Quidway-rip] undo filter-policy gateway 192.168.1.10 import
[Quidway-rip] display rip
RIP is running
public net
Checkzero is on Default cost: 1
Summary is on Preference: 100
Validate-source-address is on
Traffic-share-across-interface is off
Period update timer: 30
Timeout timer: 180
Garbage-collection timer: 120
No peer router
Network:
192.168.0.0
[Quidway-rip] display rip
RIP is running
public net
Checkzero is on Default cost: 1
Host-route is off
Summary is on Preference: 100
Validate-source-address is on
Traffic-share-across-interface is off
Period update timer: 30
Timeout timer: 180
Garbage-collection timer: 120
No peer router
Network:
192.168.0.0
[Quidway-rip] host-route
[Quidway-rip] undo summary
[Quidway-rip] display rip
RIP is running
public net
Checkzero is on Default cost: 1
Summary is off Preference: 100
Validate-source-address is on
Traffic-share-across-interface is off
Period update timer: 30
Timeout timer: 180
Garbage-collection timer: 120
No peer router
Network:
192.168.0.0
[Quidway-rip] summary
[Quidway-rip] preference 150
[Quidway-rip] display rip
RIP is running
public net
Checkzero is on Default cost: 1
Summary is on Preference: 150
Validate-source-address is on
Traffic-share-across-interface is off
Period update timer: 30
Timeout timer: 180
Garbage-collection timer: 120
No peer router
Network:
192.168.0.0
[Quidway-rip] preference 100
[Quidway-rip] timers timeout 200
[Quidway-rip] display rip
RIP is running
public net
Checkzero is on Default cost: 1
Summary is on Preference: 100
Validate-source-address is on
Traffic-share-across-interface is off
Period update timer: 30
Timeout timer: 200
Garbage-collection timer: 120
No peer router
Network:
192.168.0.0
[Quidway-rip] timers timeout 180
[Quidway-rip] timers update 1005
[Quidway-rip] display rip
RIP is running
public net
Checkzero is on Default cost: 1
Summary is on Preference: 100
Validate-source-address is on
Traffic-share-across-interface is off
Period update timer: 1005
Timeout timer: 180
Garbage-collection timer: 4020
No peer router
Network:
192.168.0.0
[Quidway-rip] timers update 30
[Quidway-rip] display rip
RIP is running
public net
Checkzero is off Default cost: 1
Summary is on Preference: 100
Validate-source-address is on
Traffic-share-across-interface is off
Period update timer: 30
Timeout timer: 180
Garbage-collection timer: 120
No peer router
Network:
192.168.0.0
<Quidway>
Внутренний протокол маршрутизации OSPF (Open Shortest Pass First) Назначение.Протокол OSPF (Open Shortest Pass First, алгоритмы предложены Дейкстрой) является альтернативой RIP в качестве внутреннего протокола маршрутизации. OSPF представляет собой протокол состояния маршрута (в качестве метрики используется – коэффициент качества обслуживания). Каждый маршрутизатор обладает полной информацией о состоянии всех интерфейсов всех маршрутизаторов (переключателей) автономной системы. Он был изобретён для избавления сетей, использующих RIP от таких напастей, как:
1. Циклические маршруты. Так как в протоколе нет механизмов выявления замкнутых маршрутов, необходимо либо слепо верить партнерам, либо принимать меры для блокировки такой возможности.
2. Для подавления нестабильностей RIP должен использовать малое значение максимально возможного числа шагов (<16).
3. Медленное распространение маршрутной информации по сети создает проблемы при динамичном изменении маршрутной ситуации (система не поспевает за изменениями). Малое предельное значение метрики улучшает сходимость, но не устраняет проблему.
Протокол OSPF представляет собой классический протокол маршрутизации класса Link–State, который обеспечивает:
· отсутствие ограничений на размер сети
· поддержку внеклассовых сетей
· передачу обновлений маршрутов с использованием адресов типа multicast
· достаточно большую скорость установления маршрута
· использование процедуры authentication при передаче и получении обновлений маршрутов
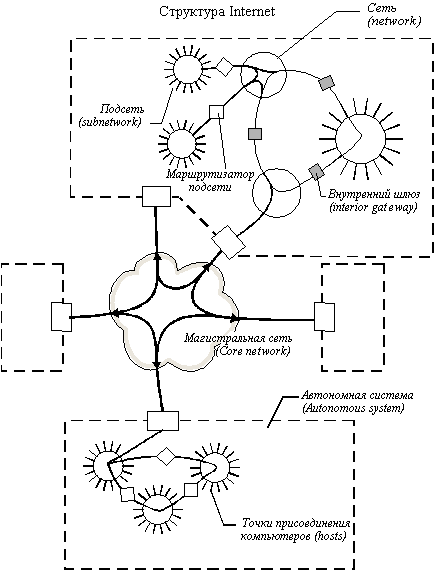
АрхитектураOSPF является иерархическим протоколом маршрутизации с объявлением состояния о канале соединения (link-state). Он был спроектирован как протокол работы внутри сетевой области – AS (Autonomous System), которая представляет собой группу маршрутизаторов и сетей, объединенных по иерархическому принципу и находящихся под единым управлением и совместно использующих общую стратегию маршрутизации. В качестве транспортного протокола для маршрутизации внутри AS OSPF использует IP‑протокол.
AS представляет собой набор сетей, которые находятся под единым управлением и совместно используют общую стратегию маршрутизации. OSPF является протоколом маршрутизации внутри AS, хотя он также может принимать и отправлять пакеты в другие AS.
Настройка на маршрутизаторах производится аналогичным образом как при настройке RIP.
Иерархическая маршрутизацияИспользование иерархической маршрутизации позволяет существенно повысить эффективность использования каналов передачи данных за счет сокращения доли передаваемого по ним служебного трафика.
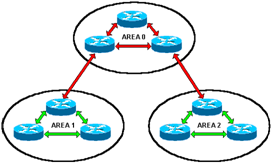
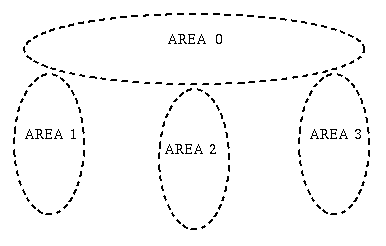
Информационный обмен, который осуществляют маршрутизаторы для определения маршрута передачи данных внутри области, показан на рисунке зелеными стрелками. Определение маршрута и информационный обмен между областями в данном случае производится через специальную центральную область – AREA 0.
Использование такой схемы логического построения сети позволяет существенно уменьшить долю неинформативного трафика, который передается по каналам передачи данных между областями. В частности в этом случае по каналам, используемых для передачи данных между областями, (красный цвет) не будет передаваться информация о сетях, которые имеют чисто локальное значение.
Распределение нагрузки между параллельными каналами (Load balancing)
При использовании протокола маршрутизации OSPF допускается существование нескольких маршрутов в направлении некоторого узла сети. В том случае, если эти маршруты обеспечивают одинаковое качество передачи данных, информационный поток в адрес данного узла может быть направлен по всем этим каналам одновременно, что обеспечит существенное увеличение скорости передачи данных. Динамическое перераспределение трафика между параллельными каналами, которое выполняется пропорционально степени загруженности этих каналов, называется Load balancing.
Иерархия маршрутизацииВ отличие от RIP, OSPF может работать в пределах некоторой иерархической системы. Самым крупным объектом в этой иерархии является автономная система (Autonomous System – AS) AS является набором сетей, которые находятся под единым управлением и совместно используют общую стратегию маршрутизации. OSPF является протоколом маршрутизации внутри AS, хотя он и способен принимать маршруты из других AS и отправлять маршруты в другие AS.
Любая AS может быть разделена на ряд областей (area). Область – это группа смежных сетей и подключенных к ним хостов. Роутеры, имеющие несколько интерфейсов, могут участвовать в нескольких областях. Такие роутеры, которые называются роутерами границы областей (area border routers), поддерживают отдельные топологические базы данных для каждой области.
Топологическая база (topological database) данных фактически представляет собой общую картину сети по отношению к роутерам. Топологическая база данных содержит набор LSA, полученных от всех роутеров, находящихся в одной области. Т.к. роутеры одной области коллективно пользуются одной и той же информацией, они имеют идентичные топологические базы данных.
Термин «домен» (domain) исользуется для описания части сети, в которой все роутери имеют идентичную топологическую базу данных. Термин «домен» часто используется вместо AS.
Топология области является невидимой для объектов, находящихся вне этой области. Путем хранения топологий областей отдельно, OSPF добивается меньшего трафика маршрутизации, чем трафик для случая, когда AS не разделена на области.
Разделение на области приводит к образованию двух различных типов маршрутизации OSPF, которые зависят от того, находятся ли источник и пункт назначения в одной и той же или разных областях.
Маршрутизация внутри области имеет место в том случае, когда источник и пункт назначения находятся в одной области.
Маршрутизация между областями – когда они находятся в разных областях.
Стержневая часть OSPF (backbone) отвечает за распределение маршрутной информации между областями. Она включает в себя все роутеры границы области, сети, которые не принадлежат полностью какого-либо из областей, и подключенные к ним роутеры. На следующем рисунке представлен пример объединенной сети с несколькими областями.
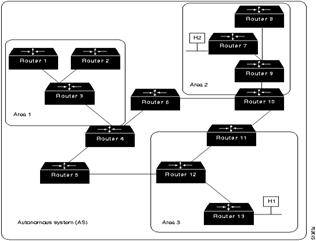
На этом рисунке роутеры 4, 5, 6, 10, 11 и 12 образуют стержень. Если хост Н1 Области 3 захочет отправить пакет хосту Н2 Области 2, то пакет отправляется в роутер 13, который продвигает его в роутер 12, который в свою очередь отправляет его в роутер 11. Роутер 11 продвигает пакет вдоль стержня к роутеру 10 границы области, который отправляет пакет через два внутренних роутера этой области (роутеры 9 и 7) до тех пор, пока он не будет продвинут к хосту Н2.
Сам стержень представляет собой одну из областей OSPF, поэтому все стержневые роутеры используют те же процедуры и алгоритмы поддержания маршрутной информации в пределах стержневой области, которые используются любым другим роутером. Топология стержневой части невидима для всех внутренних роутеров точно также, как топологии отдельных областей невидимы для стержневой части.
Область может быть определена таким образом, что стержневая часть не будет смежной с ней. В этом случае связность стержневой части должна быть восстановлена через виртуальные соединения. Виртуальные соединения формируются между любыми роутерами стержневой области, которые совместно используют какую-либо связь с любой из нестержневых областей; они функционируют так, как если бы они были непосредственными связями.
Граничные роутеры AS, использующие OSPF, узнают о внешних роутерах через протоколы внешних роутеров (EGPs), таких, как Exterior Gateway Protocol (EGP) или Border Gateway Protocol (BGP), или через информацию о конфигурации.
Спецификации.· RFC‑1245. Анализ протокола OSPF.
· RFC‑1246. Экспериментальная часть работы протокола.
· RFC‑1247 (обновлено 1349). Спецификации к протоколу OSPF версии 2.
· RFC‑1248, RFC‑1850. База управляющей информации протокола второй версии.
· RFC‑1584. Дополнение к протоколу по широковещанию.
· RFC‑1585. Расширение протокола по широковещанию, анализ и практические приложения.
· RFC‑1586. Руководство по использованию OSPF на сетях Frame Relay.
· RFC‑1587. Опция протокола для «не совсем тупиковой зоны» (Not-so-stubby area).
· RFC‑1793. Расширение к спецификациям по требованию к оборудованию с поддержкой протокола.
· RFC‑2178. Черновой вариант спецификаций.
· RFC‑2328 (STD 0054). Действующий стандарт по OSPF.
Реализация протокола. Метрики.Метрика сети, оценивающая пропускную способность, определяется как количество секунд, требуемое для передачи 100 Мбит через физическую среду данной сети. Например, метрика сети на базе 10Base-T Ethernet равна 10, а метрика выделенной линии 56 кбит/с равна 1785. Метрика канала со скоростью передачи данных 100 Мбит/с и выше равна единице.
Порядок расчета метрик, оценивающих надежность, задержку и стоимость, не определен. Администратор, желающий поддерживать маршрутизацию по этим типам сервисов, должен сам назначить разумные и согласованные метрики по этим параметрам.
Если не требуется маршрутизация с учетом типа сервиса (или маршрутизатор ее не поддерживает), используется метрика по умолчанию, равная метрике по пропускной способности.
База данных состояния связейДля работы алгоритма SPF на каждом маршрутизаторе строится база данных состояния связей, представляющая собой полное описание графа OSPF‑системы. При этом вершинами графа являются маршрутизаторы, а ребрами – соединяющие их связи. Базы данных на всех маршрутизаторах идентичны.
За создание баз данных и поддержку их взаимной синхронизации при изменениях в структуре системы сетей отвечают другие алгоритмы, содержащиеся в протоколе OSPF.
Поддержка множественных маршрутов.Если между двумя узлами сети существует несколько маршрутов с одинаковыми или близкими по значению метриками, протокол OSPF позволяет направлять части трафика по этим маршрутам в пропорции, соответствующей значениям метрик. Например, если существует два альтернативных маршрута с метриками 1 и 2, то две трети трафика будет направлено по первому из них, а оставшаяся треть – по второму.
Положительный эффект такого механизма заключается в уменьшении средней задержки прохождения дейтаграмм между отправителем и получателем, а также в уменьшении колебаний значения средней задержки.
Менее очевидное преимущество поддержки множественных маршрутов состоит в следующем. Если при использовании только одного из возможных маршрутов этот маршрут внезапно выходит из строя, весь трафик будет разом перемаршрутизирован на альтернативный маршрут, при этом во время процесса массового переключения больших объемов трафика с одного маршрута на другой весьма велика вероятность образования затора на новом маршруте. Если же до аварии использовалось разделение трафика по нескольким маршрутам, отказ одного из них вызовет перемаршрутизацию лишь части трафика, что существенно сгладит нежелательные эффекты.
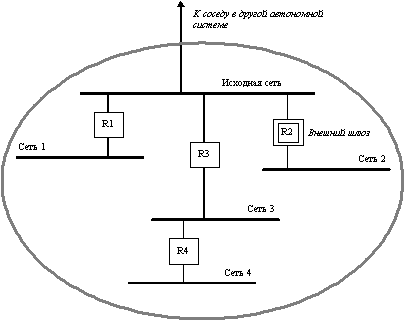
Внешние маршруты.Для достижения сетей, не входящих в OSPF‑систему (в автономную систему), используются пограничные маршрутизаторы автономной системы (autonomous system border router, ASBR), имеющие связи, уходящие за пределы системы.
ASBR вносят в базу данных состояния связей данные о сетях за пределами системы, достижимых через тот или иной ASBR. Такие сети, а также ведущие к ним маршруты называются внешними (external).
В простейшем случае, если в системе имеется только один ASBR, он объявляет через себя маршрут по умолчанию (default route) и все дейтаграммы, адресованные в сети, не входящие в базу данных системы, отправляются через этот маршрутизатор.
Если в системе имеется несколько ASBR, то, возможно, внутренним маршрутизаторам системы придется выбирать, через какой именно пограничный маршрутизатор нужно отправлять дейтаграммы в ту или иную внешнюю сеть. Это делается на основе специальных записей, вносимых ASBR в базу данных системы. Эти записи содержат адрес и маску внешней сети и метрику расстояния до нее, которая может быть, а может и не быть сравнимой с метриками, используемыми в OSPF‑системе (см. также п. 5.5.12). Если возможно, адреса нескольких внешних сетей агрегируются в общий адрес с более короткой маской.
ASBR может получать информацию о внешних маршрутах от протоколов внешней маршрутизации, а также все или некоторые внешние маршруты могут быть сконфигурированы администратором (в том числе единственный маршрут по умолчанию).
Сети множественного доступаПротокол OSPF особым образом выделяет сети множественного доступа, то есть сети, где каждый узел может непосредственно связаться с каждым. Такие сети могут также поддерживать широковещательную передачу и мультикастинг (broadcast networks, например, Ethernet, FDDI) или не поддерживать таковой (non-broadcast multi-access networks, NBMA, например, Х.25, Frame Relay, ATM). Следуя модели работы протоколов состояния связей, связь каждой пары маршрутизаторов должна рассматриваться как связь типа «точка-точка», что значит: каждый маршрутизатор должен установить смежность с каждым, то есть всего N (N‑1)/2 отношений смежности, по которым происходит обмен всеми типами сообщений.
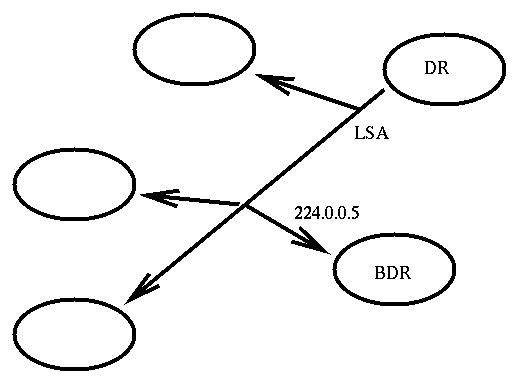
Протокол OSPF сводит ситуацию только к N отношениям смежности, выбирая среди всех маршрутизаторов данной широковещательной сети один выделенный маршрутизатор (designated router, DR), с которым все остальные маршрутизаторы устанавливают отношения смежности.
Это значит, что каждый «невыделенный» маршрутизатор поддерживает синхронизацию базы данных состояния связей не со всеми соседями, а только с выделенным маршрутизатором. При этом протокол затопления в подобной сети работает следующим образом: «обычный» маршрутизатор сообщает об изменении состояния своих связей выделенному маршрутизатору, а тот затапливает сеть этим сообщением и его получают все остальные маршрутизаторы сети. Естественно, что по своим внешним интерфейсам, ведущим к прочим маршрутизаторам системы, не находящимся в данной сети множественного доступа, каждый маршрутизатор отправляет сообщения без участия выделенного маршрутизатора.
Протокол OSPF позволяет также редуцировать размер базы данных состояния связей. Для этого в граф системы вводится виртуальная вершина «транзитная сеть», представляющая собой сеть множественного доступа как таковую. Каждый маршрутизатор, в том числе и выделенный, при таком подходе имеет не набор двухточечных связей со всеми остальными маршрутизаторами своей сети, а одну связь с вершиной «транзитная сеть».
Выборы выделенного маршрутизатора проводятся с помощью протокола Hello. Кроме выделенного маршрутизатора выбирается также и запасной выделенный маршрутизатор (backup designated router, BDR), остальные маршрутизаторы сети устанавливают отношения смежности как с DR, так и с BDR (следовательно, в предыдущем пункте при описании отношений смежности не хватает BDR). Все сообщения для DR и BDR посылаются по мультикастинговому адресу 224.0.0.6 «Всем выделенным OSPF‑маршрутизаторам».
Запасной выделенный маршрутизатор получает эти сообщения, но не предпринимает никаких действий, связанных со своей выделенной функцией. Однако если выделенный маршрутизатор отключается (этот факт детектируется с помощью протокола Hello), то запасной немедленно становится выделенным, не тратя времени на установление отношений смежности с остальными маршрутизаторами, так как эти отношения уже установлены. При этом с помощью протокола Hello выбирается новый запасной выделенный маршрутизатор. Если бывший выделенный маршрутизатор подключится снова, статус выделенного маршрутизатора ему не возвращается.
NBMA- и point-to-multipoint сетиВ случае, когда несколько OSPF‑маршрутизаторов подключены к сети множественного доступа, не поддерживающей широковещательную передачу (NBMA‑сеть), они следуют той же процедуре, что и в случае широковещательной сети, поскольку каждый маршрутизатор также может непосредственно связаться с каждым, и, следовательно, существует та же проблема по числу отношений смежности и числу записей в базе данных состояния связей. В случае NBMA‑сетей проблема даже усугубляется тем, что поддержка постоянных соединений между любыми двумя маршрутизаторами для обмена маршрутной информацией (отношения смежности) может потребовать значительных технических и финансовых затрат.
Отличие NBMA от широковещательных сетей состоит в том, что адреса всех соседей должны быть предварительно сконфигурированы на каждом маршрутизаторе, потому что возможности передавать мультикастинговые сообщения нет.
Если маршрутизатор, подключенный к нешироковещательной сети, может непосредственно связаться с несколькими, но не со всеми маршрутизаторами этой сети (неполный множественный доступ), такое соединение конфигурируется как point-to-multipoint и не рассматривается протоколом OSPF как сеть множественного доступа со всеми вышеописанными последствиями. Маршрутизатор, подключенный к соединению типа point-to-multipoint, устанавливает двухточечные связи с каждым своим соседом по соединению.
Могут быть также причины, по которым администратор пожелает сконфигурировать сеть с полным множественным доступом как point-to-multipoint.
Иерархическая маршрутизация (Разбиение на области)Для упрощения вычисления маршрутов и уменьшения размера базы данных состояния связей OSPF‑система может быть разбита на отдельные независимые области (areas), объединяемые в единую систему особой областью, называемой магистралью (backbone). Области, не являющиеся магистралью, называются периферийными.
Маршруты внутри каждой области вычисляются как в отдельной системе: база данных состояния связей содержит записи только о связях маршрутизаторов внутри области, действие протокола затопления не распространяется за пределы области.
Некоторые маршрутизаторы принадлежат магистрали и одной или нескольким периферийным областям. Такие маршрутизаторы называются областными пограничными маршрутизаторами (area border router, ABR). Каждая область должна иметь как минимум один ABR, иначе она будет полностью изолирована от остальной части системы.
Областные пограничные маршрутизаторы поддерживают отдельные базы данных состояния связей для всех областей, к которым они подключены. На основании этих данных они обобщают информацию о достижимости сетей внутри отдельных областей и сообщают результат в смежную область. Также ABR обрабатывают подобные сообщения от других ABR (граничащих с другими областями) и ретранслируют информацию о внешних маршрутах, исходящую от пограничных маршрутизаторов (автономной) системы (ASBR).
Тем самым обеспечивается передача маршрутной информации и коннективность между областями. При этом, за пределы области передается не полная база данных состояния связей, а просто список сетей этой области, достижимых извне области через данный ABR, вместе с метриками расстояния до этих сетей. Если возможно, адреса сетей агрегируются в общий адрес с более короткой маской. Подобную же информацию, но только о сетях, лежащих за пределами OSPF‑системы, распространяют ASBR.
Тупиковые и не совсем тупиковые областиОбласти, внутрь которых не передается информация о внешних маршрутах, называются тупиковыми областями (stub areas). Все дейтаграммы, исходящие из данной области и адресованные за пределы автономной системы, отправляются по маршруту по умолчанию (default) через определенный ABR. Тупиковая область может иметь несколько ABR, но для каждого узла внутри области установлен маршрут по умолчанию, проходящий только через один их ABR.
Протокол OSPF определяет также понятие не совсем тупиковых областей (not so stubby area, NSSA). К таким областям относятся тупиковые области, в которых разрешено объявлять некоторые внешние маршруты.
OSPF‑заголовокПротокол OSPF в стеке протоколов TCP/IP находится непосредственно над протоколом IP, код OSPF равен 89. То есть если значение поля «Protocol» IP‑дейтаграммы равно 89, то данные дейтаграммы являются сообщением OSPF и передаются OSPF‑модулю для обработки. Соответственно размер OSPF‑сообщения ограничен максимальным размером дейтаграммы.
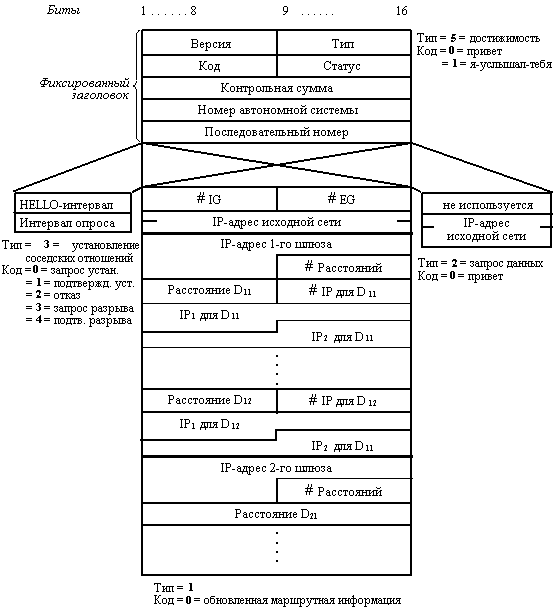
Все сообщения OSPF имеют общий заголовок (следующий в дейтаграмме непосредственно за IP‑заголовком):
Значения полей:
· Version (1 октет) – версия протокола (=2);
· Type (1 октет) – тип сообщения:
1. Hello;
2. описание базы данных (Database Description);
3. запрос состояния связей (Link State Request);
4. обновление состояния связей (Link State Update);
5. подтверждение приема сообщения о состоянии связей (Link State Acknowledgment).
· Packet length (2 октета) – длина сообщения в октетах, включая заголовок.
· Router ID (4 октета) – идентификатор маршрутизатора, отправившего сообщение. Router ID равен адресу одного из IP‑интерфейсов маршрутизатора. У маршрутизаторов Cisco это наибольший из адресов локальных интерфейсов, а если таковых нет, то наибольший из адресов внешних интерфейсов.
· Area ID (4 октета) – номер области, к которой относится данное сообщение; номер 0 зарезервирован для магистрали. Часто номер области полагают равным адресу IP‑сети (одной из IP‑сетей) этой области.
· Checksum (2 октета) – контрольная сумма, охватывает все OSPF‑сообщение, включая заголовок, но исключая поле «Authentication»; вычисляется по тому же алгоритму, что и в IP‑заголовке.
· Authentication Type (2 октета) – тип аутентификации сообщения. Стандарт определяет несколько возможных типов, самые простые из них: 0 – нет аутентификации, 1 – аутентификация с помощью пароля.
· Authentication (8 октетов) – аутентификационные данные; например, восьмисимвольный пароль.
· Далее при рассмотрении формата сообщений вышеописанный заголовок будет изображаться в виде поля «OSPF‑заголовок», помещенного в начало сообщения.
Протокол Hello
После инициализации модуля OSPF (например, после подачи питания на маршрутизатор) через все интерфейсы, включенные в OSPF‑систему, начинают рассылаться Hello‑сообщения. Задача Hello‑протокола – обнаружение соседей и установление с ними отношений смежности.
Соседями называются OSPF‑маршрутизаторы, подключенные к одной сети (к одной линии связи) и обменивающиеся Hello‑сообщениями.
Смежными называются соседние OSPF маршрутизаторы, которые приняли решение обмениваться друг с другом информацией, необходимой для синхронизации базы данных состояния связей и построения маршрутов. Не все соседи становятся смежными.
Другая задача протокола Hello – выбор выделенного маршрутизатора в сети с множественным доступом, к которой подключено несколько маршрутизаторов.
Hello‑пакеты продолжают периодически рассылаться и после того, как соседи были обнаружены. Таким образом маршрутизатор контролирует состояние своих связей с соседями и может своевременно обнаружить изменение этого состояние (например, обрыв связи или отключение одного из соседей). Обрыв связи может быть также обнаружен и с помощью протокола канального уровня, который просигнализирует о недоступности канала.
В сетях с возможностью широковещательной рассылки (broadcast networks) Hello‑пакеты рассылаются по мультикастинговому адресу 224.0.0.5 («Всем ОSPF‑маршрутизаторам»). В других сетях все возможные адреса соседей должны быть введены администратором.
Значения полей:
· Network Mask (4 октета) – маска IP‑сети, в которой находится интерфейс маршрутизатора, отправившего сообщение.
· Hello Interval (2 октета) – период посылки Hello‑сообщений, в секундах.
· Options (1 октет) – определено значение нескольких бит:
| DC | EA | N/P | MC | E | T |
o Бит Т установлен, поддерживается маршрутизация по типу сервиса (этот бит исключен из последней версии стандарта OSPF, но может поддерживаться для совместимости с предыдущими версиями).
o Бит Е установлен, маршрутизатор может принимать и объявлять внешние маршруты через данный интерфейс; сброшен, данный интерфейс маршрутизатора принадлежит тупиковой области.
o Бит MC установлен, маршрутизатор поддерживает маршрутизацию мультикастинговых дейтаграмм (RFC 1584).
o Бит N/P установлен, данный интерфейс маршрутизатора принадлежит не совсем тупиковой области (NSSA).
o Бит EA установлен, маршрутизатор может получать и ретранслировать объявления о «внешних атрибутах» (к настоящему моменту описание опции не разработано).
o Бит DC установлен, маршрутизатор поддерживает работу с соединениями, устанавливаемыми по требованию (demand circuits, RFC 1793) – это, например, означает, что записи о связях, устанавливаемых по требованию, не устаревают.
o Поле «Options» используется для согласования возможностей маршрутизаторов-соседей (маршрутизатор может прервать соседские отношения, если какие-то опции соседа его не устраивают) и для определения того, какую информацию о состоянии связей не нужно посылать маршрутизатору-соседу, потому что он все равно не сможет ее обработать.
· Priority (1 октет) – приоритет маршрутизатора; устанавливается администратором, используется при выборах выделенного маршрутизатора; маршрутизатор с нулевым приоритетом никогда не будет избран.
· Dead Interval (4 октета) – время в секундах, по истечении которого маршрутизатор-сосед, не посылающий сообщения Hello, считается отключенным.
· Designated Router (DR) (4 октета) – идентификатор выделенного маршрутизатора с точки зрения маршрутизатора, посылающего сообщение (0, если выделенный маршрутизатор еще не выбран).
· Backup Designated Router (BDR) (4 октета) – идентификтор запасного выделенного маршрутизатора с точки зрения маршрутизатора, посылающего сообщение (0, если запасной выделенный маршрутизатор еще не выбран).
· Neighbor,…, Neighbor – список идентификаторов соседей, от которых получены Hello‑сообщения за последние Dead Interval секунд; число полей «Neighbor» определяется из общей длины сообщения, указанной в OSPF‑заголовке. Длина одного поля – 4 октета.
После того, как пара маршрутизаторов начинает обмениваться Hello‑сообщениями с каким-то соседом, этот процесс проходит через несколько стадий:
· DOWN – сосед не обнаружен или отключился;
· INIT – послано Hello‑сообщение или получено от маршрутизатора, еще не зачисленного в список соседей;
· 2‑WAY (двусторонняя связь) – получено Hello‑сообщение, в котором данный маршрутизатор-получатель перечислен в списке соседей, а отправитель этого сообщения также зачислен в список соседей данного маршрутизатора;
· WAIT – ожидание в течение Dead Interval секунд для обнаружения всех соседей; в это время маршрутизатор передает Hello‑сообщения, но не участвует в выборах выделенного маршрутизатора и в синхронизировании баз данных;
· EXSTART – установление ролей главный / подчиненный и инициализация структур данных для обмена описаниями баз данных (протокол обмена);
· EXCHANGE – обмен описаниями баз данных (протокол обмена);
· LOADING – синхронизация баз данных, пересылка сообщений-запросов о состояниях связей и ответов на них (протокол обмена);
· FULL – базы данных синхронизированы.
Каждый маршрутизатор самостоятельно производит выборы выделенного и запасного выделенного маршрутизаторов на основании имеющихся у него данных о соседях и о том, кого каждый из соседей назначил на эту роль. Фактически процесс выборов происходит постоянно, после получения каждого Hello‑сообщения, но алгоритм гарантирует, что при стабильном состоянии сети всеми маршрутизаторами будут выбираться одни и те же DR и BDR.
Каждый маршрутизатор может объявить себя либо выделенным, либо запасным, поместив свой идентификатор в соответствующее поле своих Hello‑сообщений. Иначе он может поместить туда адреса других маршрутизаторов, если он считает их занимающими соответствующие роли. Если маршрутизатор не определился с выбором DR и (или) BDR (например, после включения), он заполняет соответствующие поля нулями.
Выбор проводится только среди соседей, с которыми установлена двусторонняя связь и приоритет которых не равен нулю; в этот список маршрутизатор включает и себя, если его приоритет не нулевой.
Итак, после получения очередного Hello‑сообщения маршрутизатор приступает к выбору DR и BDR. Он помнит мнения своих соседей по поводу того, кто является DR и BDR, которые он узнал из получаемых Hello‑сообщений, а также свой собственный предыдущий выбор.
Сначала выбирается BDR, на эту должность назначается маршрутизатор с наивысшим приоритетом из всех, объявивших себя в качестве BDR, при этом маршрутизаторы, объявившие себя в качестве DR, не рассматриваются. Если никто не объявил себя в качестве BDR, выбирается маршрутизатор с высшим приоритетом из тех, кто не объявил себя в качестве DR. В случае равных приоритетов выбирается маршрутизатор с большим идентификатором.
На должность DR выбирается маршрутизатор с наивысшим приоритетом из всех, объявивших себя в качестве DR. В случае равных приоритетов выбирается маршрутизатор с большим идентификатором.
Если никто не предложил себя в качестве DR, в поле «Designated Router» заносится идентификатор BDR.
Если маршрутизатор только что выбрал себя на роль DR или BDR или только что потерял статус DR или BDR, шаги 1–3 повторяются. Термин «только что» означает «в результате выполнения непосредственно предшествующих шагов 1–3, а не предыдущих итераций алгоритма».
После выбора DR и BDR маршрутизатор сообщает их идентификаторы в своих Hello‑сообщениях. Если в результате процедуры выбора DR или BDR изменились по сравнению с предыдущим выбором данного маршрутизатора, он устанавливает необходимые отношения смежности, если они еще не были установлены, и разрывает ненужные больше отношения смежности, если таковые имеются.
Когда маршрутизатор подключается к сети, сначала он достигает состояния 2‑WAY со всеми своими соседями, а потом, прежде чем приступать к выборам, ожидает время WAIT. В течение этого времени он передает Hello‑сообщения с обнуленными полями DR и BDR. После истечения периода WAIT вновь подключившийся маршрутизатор может предлагать себя на роль BDR, производить выборы и формировать отношения смежности.
Протокол обменаПосле установления отношений смежности для каждой пары смежных маршрутизаторов происходит синхронизация их баз данных. Эта же операция происходит при восстановлении ранее разорванного соединения, поскольку в образовавшихся после аварии двух изолированных подсистемах базы данных развивались независимо друг от друга. Синхронизация баз данных происходит с помощью протокола обмена (Exchange protocol).
Сначала маршрутизаторы обмениваются только описаниями своих баз данных (Database Description), содержащими идентификаторы записей и номера их версий, это позволяет избежать пересылки всего содержимого базы данных, если требуется синхронизировать только несколько записей.
Во время этого обмена каждый маршрутизатор формирует список записей, содержимое которых он должен запросить (то есть эти записи в его базе данных устарели либо отсутствуют), и соответственно отправляет пакеты запросов о состоянии связей (Link State Request). В ответ он получает содержимое последних версий нужных ему записей в пакетах типа «Обновление состояния связей (Link State Update)».
После синхронизации баз данных производится построение маршрутов.
Сообщение «Описание базы данных (Database Description)»
Значения полей:
· Options (1 октет) – то же, что и в сообщениях Hello.
· IMMS (3 бита) – последние 3 бита октета, следующего за полем «Options»: I – Initialize, бит 5; M – More, бит 6, MS – Master/Slave, бит 7. Использование этих бит будет описано ниже. Остальная часть октета, где находятся эти биты, обнулена.
· DD Sequence number (DDSN) (4 октета) – порядковый номер данного сообщения.
· LSA Header (20 октетов) – описание (набор идентификаторов) записи из базы данных состояния связей, представляющее собой заголовок «Объявления о состоянии связей». В сообщении может присутствовать несколько описаний (полей «LSA Header»), следующих друг за другом; их число определяется из общей длины сообщения, указанной в OSPF заголовке.
Обмен сообщениями «Описание базы данных» происходит при работе протокола обмена (Exchange protocol) между двумя смежными маршрутизаторами. Обмен начинается с выяснения, кто из двух маршрутизаторов будет играть главную роль, а кто подчиненную.
Маршрутизатор, желающий начать обмен на правах главного, отправляет пустое сообщение с установленными битами IMMS и произвольным, но не использованным в обозримом прошлом номером DDSN (предлагается использовать время суток). Второй маршрутизатор подтверждает, что согласен играть подчиненную роль: он отправляет обратно также пустое сообщение с тем же DDSN, c установленными битами I и M и сброшенным битом MS.
Если же оба маршрутизатора одновременно решили начать процедуру обмена, то маршрутизатор, получивший в ответ на свое сообщение о начале обмена сообщение второго маршрутизатора о начале обмена вместо подтверждения подчиненной роли, сравнивает адрес второго маршрутизатора со своим. Если свой адрес меньше, маршрутизатор принимает подчиненную роль и отправляет соответствующее подтверждение, иначе принятое сообщение игнорируется.
После того, как роли распределены, начинается обмен описаниями базы данных. Главный отправляет подчиненному сообщения с описаниями своей базы данных; номера DDSN увеличиваются с каждым сообщением, бит I сброшен, бит МS установлен, бит M установлен во всех сообщениях, кроме последнего.
Подчиненный отправляет подтверждения на каждое полученное от главного сообщения. Эти подтверждения представляют собой сообщения того же типа, содержащие описание базы данных подчиненного маршрутизатора. Номер DDSN равен номеру подтверждаемого сообщения, биты I и MS сброшены, бит М установлен во всех сообщениях, кроме последнего.
При неполучении подтверждения от подчиненного в течение некоторого тайм-аута главный посылает сообщение повторно. Если подчиненный получает сообщение с уже встречавшимся номером DDSN, он должен повторить передачу соответствующего подтверждения. Это касается также и фазы инициализации (распределения ролей).
Если один из маршрутизаторов уже передал все данные, он продолжает передавать пустые сообщения со сброшенным битом М, пока другая сторона также не закончит передачу всех данных и не передаст сообщение (или подтверждение) со сброшенным битом М.
На этом процедура обмена описаниями базы данных заканчивается.
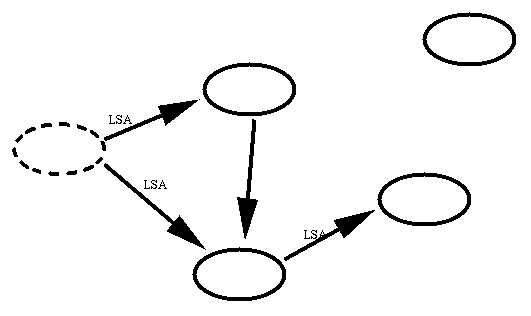
Протокол затопления (flooding)Каждый маршрутизатор отвечает за те и только те записи в базе данных состояния связей, которые описывают связи, исходящие от данного маршрутизатора. Это значит, что при образовании новой связи, изменении в состоянии связи или ее исчезновении (обрыве), маршрутизатор, ответственный за эту связь, должен соответственно изменить свою копию базы данных и немедленно известить все остальные маршрутизаторы OSPF‑системы о произошедших изменениях, чтобы они также внесли исправления в свои копии базы данных.
Подпротокол OSPF, выполняющий эту задачу, называется протоколом затопления (Flooding protocol). При работе этого протокола пересылаются сообщения типа «Обновление состояния связей (Link State Update)», получение которых подтверждается сообщениями типа «Link State Acknowledgment».
Каждая запись о состоянии связей имеет свой номер (номер версии), который также хранится в базе данных. Каждая новая версия записи имеет больший номер. При рассылке сообщений об обновлении записи в базе данных номер записи также включается в сообщение для предотвращения попадания в базу данных устаревших версий.
Маршрутизатор, ответственный за запись об изменившейся связи, рассылает сообщение «Обновление состояния связи» по всем интерфейсам. Однако новые версии состояния одной и той же связи должны появляться не чаще, чем оговорено определенной константой.
Далее на всех маршрутизаторах OSPF‑системы действует следующий алгоритм.
1. Получить сообщение. Найти соответствующую запись в базе данных.
2. Если запись не найдена, добавить ее в базу данных, передать сообщение по всем интерфейсам.
3. Если номер записи в базе данных меньше номера пришедшего сообщения, заменить запись в базе данных, передать сообщение по всем интерфейсам.
4. Если номер записи в базе данных больше номера пришедшего сообщения и эта запись не была недавно разослана, разослать содержимое записи из базы данных через тот интерфейс, откуда пришло сообщение. Понятие «недавно» определяется значением константы.
Похожие работы
... ) и обладает многими особенностями, ориентированными на применение в больших гетерогенных сетях. Протокол OSPF вычисляет маршруты в IP-сетях, сохраняя при этом другие протоколы обмена маршрутной информацией. Непосредственно связанные (то есть достижимые без использования промежуточных маршрутизаторов) маршрутизаторы называются "соседями". Каждый маршрутизатор хранит информацию о том, в каком ...

... метрика интерфейса может быть также непосредственно изменена командой router(config-if)#ip ospf cost метрика Подчеркнем, что речь идет о метрике связей, исходящих из интерфейса. 4.3 Идентификаторы маршрутизаторов Каждый OSPF-маршрутизатор идентифицируется некоторым IP-адресом, который помещается во все OSPF-пакеты, сгенерированные маршрутизатором. Поскольку у маршрутизатора есть несколько IP- ...


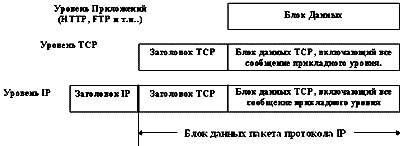
... офиса подразделения к сети главного офиса. Автостатические маршруты Автостатические маршруты — это статические маршруты, которые автоматически добавляются в таблицу маршрутизации маршрутизатора после запроса маршрутов с помощью протокола RIP для IP при подключении по требованию. Преимущество автостатических маршрутов заключается в том, что для недостижимых узлов маршрутизатор не подключается к ...




... сигналов, поступающих от разных источников информации (телефонные сигналы от междугородней телефонной станции, телевизионные сигналы от междугородней телевизионной аппаратной и т.д.) в сигналы, передаваемые по радиорелейной линии, а также обратное преобразование сигналов, приходящих по РРЛ, в сигналы телерадиовещания или телефонии. Радиосигналы ОРС с помощью передающего устройства и антенны ...
0 комментариев