Навигация
Дополнительный сегмент данных
81515
знаков
6
таблиц
14
изображений
4. Дополнительный сегмент данных.
Неявно алгоритмы выполнения большинства машинных команд предполагают, что обрабатываемые ими данные расположены в сегменте данных, адрес которого находится в сегментном регистре ds.
Если программе недостаточно одного сегмента данных, то она имеет возможность использовать еще три дополнительных сегмента данных. Но в отличие от основного сегмента данных, адрес которого содержится в сегментном регистре ds, при использовании дополнительных сегментов данных их адреса требуется указывать явно с помощью специальных префиксов переопределения сегментов в команде.
Адреса дополнительных сегментов данных должны содержаться в регистрах es, gs, fs (extension data segment registers).
Регистры состояния и управления eflags и ip
Они постоянно содержат информацию о состоянии, как самого микропроцессора, так и программы, команды которой в данный момент загружены на конвейер. Используя эти регистры, можно получать информацию о результатах выполнения команд и влиять на состояние самого микропроцессора.
eflags/flags (flag register) — регистр флагов. Разрядность eflags/flags — 32/16 бит. Отдельные биты данного регистра имеют определенное функциональное назначение и называются флагами. Младшая часть этого регистра полностью аналогична регистру flags для i8086.
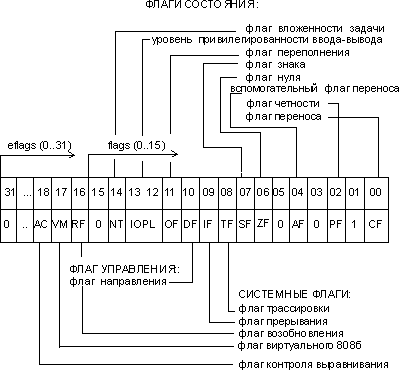

Рис. 2. Содержимое регистра eflags
Исходя из особенностей использования, флаги регистра eflags/flags можно разделить на три группы:
· 8 флагов состояния. Эти флаги могут изменяться после выполнения машинных команд. Флаги состояния регистра eflags отражают особенности результата исполнения арифметических или логических операций. Это дает возможность анализировать состояние вычислительного процесса и реагировать на него с помощью команд условных переходов и вызовов подпрограмм.
· 1 флаг управления - df (Directory Flag). Значение флага df определяет направление поэлементной обработки цепочек данных: от начала строки к концу (df = 0) либо наоборот, от конца строки к ее началу (df = 1).
· 5 системных флагов, управляющих вводом/выводом, маскируемыми прерываниями, отладкой, переключением между задачами и виртуальным режимом 8086. Прикладным программам не рекомендуется модифицировать без необходимости эти флаги, так как в большинстве случаев это приведет к прерыванию работы программы.
eip/ip (Instraction Pointer register) — регистр-указатель команд.
Регистр eip/ip имеет разрядность 32/16 бит и содержит смещение следующей подлежащей выполнению команды относительно содержимого сегментного регистра cs в текущем сегменте команд. Этот регистр непосредственно недоступен программисту, но загрузка и изменение его значения производятся различными командами управления, к которым относятся команды условных и безусловных переходов, вызова процедур и возврата из процедур. Возникновение прерываний также приводит к модификации регистра eip/ip.
Типы данных. Переменные
В программе на ассемблере переменными являются регистры или ячейки памяти, в которых хранятся данные. Существует несколько типов данных-переменных:
1. Непосредственные данные, представляющие собой числовые или символьные значения, являющиеся частью команды. 20d, 0a2h, 10111b
2. Данные простого типа, описываемые с помощью ограниченного набора директив резервирования памяти, позволяющих выполнить самые элементарные операции по размещению и инициализации числовой и символьной информации.
Эти два типа данных являются элементарными, или базовыми; работа с ними поддерживается на уровне системы команд микропроцессора. Используя данные этих типов, можно формализовать и запрограммировать практически любую задачу. Но насколько это будет удобно — вот вопрос.
3. Данные сложного типа, (массивы, структуры, записи и пр.) которые были введены в язык ассемблера с целью облегчения разработки программ. Сложные типы данных строятся на основе базовых типов, которые являются как бы кирпичиками для их построения. Введение сложных типов данных позволяет несколько сгладить различия между языками высокого уровня и ассемблером
Физическая интерпретация данных простого типа основывается на размерности данных:
· байт — восемь последовательно расположенных битов, пронумерованных от 0 до 7, при этом бит 0 является самым младшим значащим битом;
· слово — последовательность из двух байт, имеющих последовательные адреса. Размер слова — 16 бит; биты в слове нумеруются от 0 до 15. Байт, содержащий нулевой бит, называется младшим байтом, а байт, содержащий 15-й бит - старшим байтом. Микропроцессоры Intel имеют важную особенность — младший байт всегда хранится по меньшему адресу. Адресом слова считается адрес его младшего байта. Адрес старшего байта может быть использован для доступа к старшей половине слова.
· двойное слово — последовательность из четырех байт (32 бита), расположенных по последовательным адресам.
· учетверенное слово — последовательность из восьми байт (64 бита), расположенных по последовательным адресам.
· 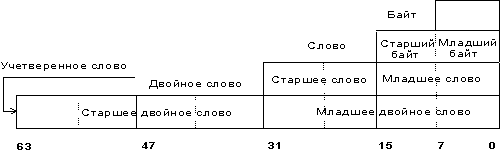
Рис. 3. Основные типы данных микропроцессора
Логическая интерпретация этих типов:
- Целый тип со знаком — двоичное значение со знаком, размером 8, 16 или 32 бита. Знак в этом двоичном числе содержится в 7, 15 или 31-м бите соответственно. Ноль в этих битах в операндах соответствует положительному числу, а единица — отрицательному. Отрицательные числа представляются в дополнительном коде. Числовые диапазоны для этого типа данных следующие:
o 8-разрядное целое — от –128 до +127;
o 16-разрядное целое — от –32 768 до +32 767;
o 32-разрядное целое — от –231 до +231–1.
- Целый тип без знака — двоичное значение без знака, размером 8, 16 или 32 бита. Числовой диапазон для этого типа следующий:
o байт — от 0 до 255;
o слово — от 0 до 65 535;
o двойное слово — от 0 до 232–1.
- Указатель на память двух типов:
o ближнего типа — 32-разрядный логический адрес, представляющий собой относительное смещение в байтах от начала сегмента. Эти указатели могут также использоваться в сплошной (плоской) модели памяти, где сегментные составляющие одинаковы;
o дальнего типа — 48-разрядный логический адрес, состоящий из двух частей: 16-разрядной сегментной части — селектора, и 32-разрядного смещения.
- Цепочка — представляющая собой некоторый непрерывный набор байтов, слов или двойных слов максимальной длины до 4 Гбайт.
- Битовое поле представляет собой непрерывную последовательность бит, в которой каждый бит является независимым и может рассматриваться как отдельная переменная. Битовое поле может начинаться с любого бита любого байта и содержать до 32 бит.
- Неупакованный двоично-десятичный тип — байтовое представление десятичной цифры от 0 до 9. Неупакованные десятичные числа хранятся как байтовые значения без знака по одной цифре в каждом байте. Значение цифры определяется младшим полубайтом.
- Упакованный двоично-десятичный тип представляет собой упакованное представление двух десятичных цифр от 0 до 9 в одном байте. Каждая цифра хранится в своем полубайте. Цифра в старшем полубайте (биты 4–7) является старшей.
-
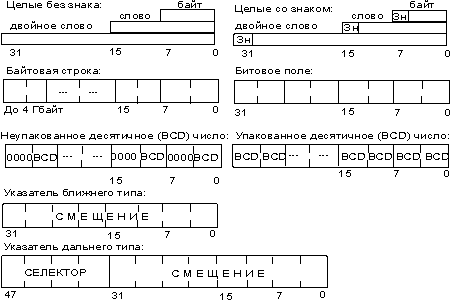
Рис. 4. Основные логические типы данных микропроцессора
Язык микроопераций. Ассемблер.
Структура программы на ассемблере:
Model small ;модель программы, или же количество памяти на сегмент
.data ;сегмент данных
;описание переменных
.stack 100h ;сегмент стека
.code ;сегмент данных
;процедуры, макрокоманды
main:
;основная программа
end main
Директивы резервирования памяти
Для описания простых типов данных в программе используются специальные директивы резервирования и инициализации данных, которые, по сути, являются указаниями транслятору на выделение определенного объема памяти. Если проводить аналогию с языками высокого уровня, то директивы резервирования и инициализации данных являются определениями переменных.
Машинного эквивалента этим директивам нет; просто транслятор, обрабатывая каждую такую директиву, выделяет необходимое количество байт памяти и при необходимости инициализирует эту область некоторым значением.
Директивы резервирования и инициализации данных простых типов имеют формат:

Рис. 5. Директивы описания данных простых типов
На рис. 5 использованы следующие обозначения:
· ? показывает, что содержимое поля не определено, то есть при задании директивы с таким значением выражения содержимое выделенного участка физической памяти изменяться не будет. Фактически, создается неинициализированная переменная;
· значение инициализации — значение элемента данных, которое будет занесено в память после загрузки программы. Фактически, создается инициализированная переменная, в качестве которой могут выступать константы, строки символов, константные и адресные выражения в зависимости от типа данных. Подробная информация приведена в приложении 1;
· выражение — итеративная конструкция с синтаксисом, описанным на рис. 5.17. Эта конструкция позволяет повторить последовательное занесение в физическую память выражения в скобках n раз.
· имя — некоторое символическое имя метки или ячейки памяти в сегменте данных, используемое в программе.
· db — резервирование памяти для данных размером 1 байт. Директивой db можно задавать следующие значения:
o выражение или константу, принимающую значение из диапазона:
- для чисел со знаком –128...+127;
- для чисел без знака 0...255;
o символьную строку из одного или более символов. Строка заключается в кавычки. В этом случае определяется столько байт, сколько символов в строке.
· dw — резервирование памяти для данных размером 2 байта. Директивой dw можно задавать следующие значения:
o выражение или константу, принимающую значение из диапазона:
- для чисел со знаком –32 768...32 767;
- для чисел без знака 0...65 535;
o выражение, занимающее 16 или менее бит, в качестве которого может выступать смещение в 16-битовом сегменте или адрес сегмента;
o 1- или 2-байтовую строку, заключенная в кавычки.
· dd — резервирование памяти для данных размером 4 байта. Директивой dd можно задавать следующие значения:
o выражение или константу, принимающую значение из диапазона:
- для i386 и выше:
- для чисел со знаком –2 147 483 648...+2 147 483 647;
- для чисел без знака 0...4 294 967 295;
o относительное или адресное выражение, состоящее из 16-битового адреса сегмента и 16-битового смещения;
o строку длиной до 4 символов, заключенную в кавычки.
· df — резервирование памяти для данных размером 6 байт;
· dp — резервирование памяти для данных размером 6 байт. Директивами df и dp можно задавать следующие значения:
o выражение или константу, принимающую значение из диапазона:
- для чисел со знаком –2 147 483 648...+2 147 483 647;
- для чисел без знака 0...4 294 967 295;
o относительное или адресное выражение, состоящее из 32 или менее бит (для i80386) или 16 или менее бит (для младших моделей микропроцессоров Intel);
o адресное выражение, состоящее из 16-битового сегмента и 32-битового смещения;
o строку длиной до 6 байт, заключенную в кавычки.
· dq — резервирование памяти для данных размером 8 байт. Директивой dq можно задавать следующие значения:
o относительное или адресное выражение, состоящее из 32 или менее бит
o константу со знаком из диапазона –263...263–1;
o константу без знака из диапазона 0...264–1;
o строку длиной до 8 байт, заключенную в кавычки.
· dt — резервирование памяти для данных размером 10 байт. Директивой dt можно задавать следующие значения:
o относительное или адресное выражение, состоящее из 32 или менее бит
o адресное выражение, состоящее из 16-битового сегмента и 32-битового смещения;
o константу со знаком из диапазона –279...279-1;
o константу без знака из диапазона 0...280-1;
o строку длиной до 10 байт, заключенную в кавычки;
o упакованную десятичную константу в диапазоне 0...99 999 999 999 999 999 999.
Очень важно уяснить себе порядок размещения данных в памяти. Он напрямую связан с логикой работы микропроцессора с данными. Микропроцессоры Intel требуют следования данных в памяти по принципу: младший байт по младшему адресу.
Для иллюстрации данного принципа рассмотрим листинг 1, в котором определим сегмент данных. В этом сегменте данных приведено несколько директив описания простых типов данных.
Листинг 1. Пример использования директив резервирования и инициализации данных. Программа вводит строку с клавиатуры.
model small
.stack 100h
.data
message db 'Массив байт, содержащих символьные переменные',10,13 '$'
po db 1, 3, 4, 5, 0fh, 0bh, 32, 01011b
perem_1 db 0ffh
perem_2 dw 3a7fh
perem_3 dd 0f54d567ah
k1 db 10
k2 db ?
mas db 10 dup ('?')
adr dw k1
adr_full dd perem_3
.code
start:
mov ax,@data
mov ds,ax
mov ah,0ah
mov dx,offset message ; mov dx, adr
int 21h
mov ax,4c00h
int 21h
end start
Система команд Формат предложения ассемблера[имя метки:] КОП [операнд1] [,операнд2] [;комментарии]
Команды пересылки данных
| mov <операнд назначения>,<операнд-источник> | ||
| можно | Нельзя | Должно быть |
| mov ах, вх; ах:=вх mov ах,0а2h; ах:= 0а2h mov per1,ax | mov ax,bh mov per1, per2 mov ds,per1 mov cs,ds mov cs,ax; пара cs:ip содержит адрес следующей команды | mov ah, bh mov al, per2 mov per1,al mov ax, per1 mov ds,ax mov ax,ds либо push ds mov cs,ax pop cs |
xchg <операнд1>,<операнд2> ; двунаправленный обмен данными а:=в; в:=с; с:=а
xchg dl,dh; меняет местами данные
Команды ввода-вывода в порт
in аккумулятор,номер_порта — ввод в аккумулятор из порта
out порт,аккумулятор — вывод содержимого аккумулятора в порт
Команды работы с адресами и указателями памятиlea назначение,источник — загрузка эффективного адреса источника в регистр-назначение;
lea dx, x ; аналогично команде mov dx,offset x
lds назначение,источник — загрузка эффективного адреса источника в регистр назначения и загрузка указателя (адрес сегмента где содержится источник) в регистр сегмента данных ds;
les назначение,источник —-//-регистр дополнительного сегмента данных es;
lgs назначение,источник — -//- регистр дополнительного сегмента данных gs;
lfs назначение,источник — -//- регистр дополнительного сегмента данных fs;
lss назначение,источник — -//- регистр сегмента стека ss.
les dx,per1 ;полный указатель на per1 в пару es:dx
Команды работы со стеком
Для работы со стеком предназначены три регистра:
ss — сегментный регистр стека;
sp/esp — регистр указателя стека;
bp/ebp — регистр указателя базы кадра стека.
push источник — запись значения источник в вершину стека.

Алгоритм работы:
· уменьшить значение указателя стека esp/sp на 4/2 (в зависимости от значения атрибута размера адреса — use16 или use32);
· записать источник в вершину стека (адресуемую парой ss:esp/sp).
Размер записываемых значений — слово или двойное слово. Также в стек можно записывать непосредственные значения. В стек можно класть значение сегментного регистра cs. Другой интересный момент связан с регистром sp. Команда push esp/sp записывает в стек значение esp/sp по состоянию до выдачи этой команды
Команда push используется совместно с командой pop для записи значений в стек и извлечения их из стека
pop назначение — запись значения из вершины стека по месту, указанному операндом назначение. Значение при этом “снимается” с вершины стека.
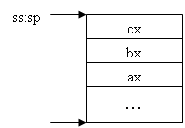
Push ax
Push bx
push cx
…
|
pop bx
pop ax
push ax
pop bx ; аналогично команде mov bx,ax
pusha - размещение в стеке регистров общего назначения в следующей последовательности: ax, cx, dx, bx, sp, bp, si, di
pushad - размещение в стеке регистров общего назначения в следующей последовательности: eax, ecx, edx, ebx, esp, ebp, esi, edi
pushf - размещение в вершине стека (ss:sp) содержимого регистра флагов flags
pushfd - размещение в стеке содержимого регистра флагов eflags.
popa - извлечение из стека регистров общего назначения di, si, bp, sp, bx, dx, cx, ax
popad - извлечение из стека регистров общего назначения edi, esi, ebp, esp, ebx, edx, ecx, eax
popf - извлечение из стека слова и восстановление его в регистр флагов flags
popfd - извлечение из стека двойного слова и восстановление его в регистр флагов eflags
Организация вычислений
Логические командыЛюбая логическая команда меняет значение следующих флагов of, sf,zf,pf,cf (переполнение, знак, нуля, паритет, перенос)
and операнд_1,операнд_2 — операция логического умножения (И - конъюнкция).
оп1:=оп1 ٧ оп2
and ah, 0a1h; ah:=ah٧0ah
and bx, cx; bx:=bx٧cx
and dx, x1; dx:=dx٧x1
or операнд_1,операнд_2 — операция логического сложения (ИЛИ - дизъюнкцию)
or al, x1; оп1:=оп1 & оп2
or eax,edx
or dx, x1
xor операнд_1,операнд_2 — операция логического исключающего сложения (исключающего ИЛИ ИЛИ-НЕ)
test операнд_1,операнд_2 — операция “проверить” (способом логического умножения).
Команда выполняет поразрядно логическую операцию И над битами операндов операнд_1 и операнд_2. Состояние операндов остается прежним, изменяются только флаги zf, sf, и pf, что дает возможность анализировать состояние отдельных битов операнда без изменения их состояния.
not операнд — операция логического отрицания. Команда выполняет поразрядное инвертирование (замену значения на обратное) каждого бита операнда. Результат записывается на место операнда.
Пример программы логического сложения двух однобайтных чисел.
model small
.stack 100h
.data
x1 db 0c2h
x2 db 022h
y db ?
.code
start:
mov ax,@data
mov ds,ax
mov al, x1
or al, x2
mov y, al
mov ax,4c00h
int 21h
end start
Арифметические операции над целыми двоичными числами Сложение двоичных чисел без знакаinc операнд - операция инкремента, то есть увеличения значения операнда на 1;
inc ax; ax:=ax+1
inc x1
add оп1,оп2 - команда сложения с принципом действия: оп1 = оп1 + оп2 (addition)
add al, bl
add ax, 0fe2h
add ebx, x1+2
add x1, 0fh
add x2, ax
adc оп1,оп2 - команда сложения с учетом флага переноса cf. оп1 = оп1 + оп2 + знач_cf
Вычитание двоичных чисел без знакаdec операнд — операция декремента, то есть уменьшения значения операнда на 1;
dec cx ;cx:=cx-1
dec x
sub операнд_1,операнд_2 — команда вычитания; ее принцип действия:
операнд_1 = операнд_1 – операнд_2
sub al, bl; al:=al-bl
sub ax, x1
sub x2, dx
sub eax, 0f35h
sub x2, 22h
sbb операнд_1,операнд_2 — команда вычитания с учетом заема (флага cf ):
операнд_1 = операнд_1 – операнд_2 – значение_cf
Пример программы сложения двух однобайтных чисел.
model small
.stack 100h
.data
x1 db 0c2h
x2 db 022h
y db ?
.code
start:
mov ax,@data
mov ds,ax
mov al, x1
add al, x2
mov y, al
mov ax,4c00h
int 21h
end start
Умножение двоичных чиселmul множитель_1 - операция умножения двух целых чисел без учета знака
Алгоритм работы:
Команда выполняет умножение двух операндов без учета знаков. Алгоритм зависит от формата операнда команды и требует явного указания местоположения только одного сомножителя, который может быть расположен в памяти или в регистре. Местоположение второго сомножителя фиксировано и зависит от размера первого сомножителя
mul dl; ax:=al*dl, dl- множитель_1 , al- множитель_2
mul x1; dx:ax=ax*0ad91h, x1 word- множитель_1 , ax- множитель_2
mul ecx; edx:eax=eax*ecx, ecx- множитель_1 , eax- множитель_2
imul множитель_1 - операция умножения двух целочисленных двоичных значений со знаком
Деление двоичных чиселdiv делитель - выполнение операции деления двух двоичных беззнаковых значений
Алгоритм работы:
Для команды необходимо задание двух операндов — делимого и делителя. Делимое задается неявно и размер его зависит от размера делителя, который указывается в команде
div dl ;ah:al=ax/dl, ax –делимое, dl- делитель , ah-частное, al -остаток
div x1 ;ax:dx=dx:ax/0ad91h, dx:ax –делимое, x1 word- делитель , ax-частное,
;dx -остаток
div ecx ;eax:edx=edx:eax/ecx, edx:eax –делимое, ecx- делитель , eax-частное,
;edx -остаток
idiv делитель - операция деления двух двоичных значений со знаком
Пример программы умножения двух однобайтных чисел.
model small
.stack 100h
.data
x1 db 78
yl db ?
yh db ?
.code
start:
mov ax,@data
mov ds,ax
xor ax, ax
mov al, 25
mul x1
jnc m1 ;если нет переполнения
mov yh,ah
m1:
mov yl, al
mov ax,4c00h
int 21h
end start
Пример. Вычислите следующее выражение у=(х2-х3)/х1, х1,х2,х3 - однобайтные числа
model small
.stack 100h
.data
s1 db 'Введите х1',10,13,'$'
s2 db 'Введите х2',10,13,'$'
s3 db 'Введите х3',10,13,'$'
x1 db ?
x2 db ?
yc db ? ;частное
yo db ? ;остаток
.code
start:
mov ax,@data
mov ds,ax
![]()
mov ah,09h
mov dx, offset s1
int 21h ;вывод строки
mov ah,01h вводим х1
int 21h ;вводим число
sub al,30h ;al:=x1
mov x1,al
mov ah,09h
![]() mov dx, offset s2
mov dx, offset s2
int 21h
mov ah,01h вводим х2
int 21h
sub al,30h ;al:=x2
mov x2,al
mov ah,09h
![]() mov dx, offset s3
mov dx, offset s3
int 21h
mov ah,01h вводим х3
int 21h
sub al,30h ;al:=x3
![]()
mov bl,x2 ;bl:=x2
sub bl,al ;bl:=x2-x3
xchg al,bl ;al:=bl, al:=x2-x3
xor ah,ah ;ax:=x2-x3 вычисляем у
mov dl,x1 ;dl:=x1
div dl ;ax/dl, ax/x1
mov yc,ah
mov yo,al
; можно вывести результат на экран
mov ax,4c00h
int 21h
end start
Команды сдвигаВсе команды сдвига обеспечивают манипуляции над отдельными битами операндов, они перемещают биты в поле операнда влево или вправо в зависимости от кода операции.
Все команды сдвига устанавливают флаг переноса cf.
shl операнд,счетчик_сдвигов (Shift Logical Left) - логический сдвиг влево. Содержимое операнда сдвигается влево на количество битов, определяемое значением счетчик_сдвигов. Справа (в позицию младшего бита) вписываются нули;
shr операнд,счетчик_сдвигов — логический сдвиг вправо.
|

Алгоритм работы команд:
· очередной “выдвигаемый” бит устанавливает флаг cf;
· бит, вводимый в операнд с другого конца, имеет значение 0;
· при сдвиге очередного бита он переходит во флаг cf, при этом значение предыдущего сдвинутого бита теряется!
sal операнд,счетчик_сдвигов (Shift Arithmetic Left)
sar операнд,счетчик_сдвигов
арифметический сдвиг влево/вправо. Содержимое операнда сдвигается влево/ вправо на количество битов, определяемое значением счетчик_сдвигов. Справа/ Слева в операнд вписываются нули.
Команда sal не сохраняет знака, но устанавливает флаг cf в случае смены знака очередным выдвигаемым битом. В остальном команда sal полностью аналогична команде shl;
Команда sar сохраняет знак, восстанавливая его после сдвига каждого очередного бита.

rol операнд,счетчик_сдвигов (Rotate Left) — циклический сдвиг влево.
Содержимое операнда сдвигается влево на количество бит, определяемое операндом счетчик_сдвигов. Сдвигаемые влево биты записываются в тот же операнд справа.
ror операнд,счетчик_сдвигов (Rotate Right) — циклический сдвиг вправо.
|

Как видно из рис., команды простого циклического сдвига в процессе своей работы осуществляют одно полезное действие, а именно: циклически сдвигаемый бит не только вдвигается в операнд с другого конца, но и одновременно его значение становиться значением флага cf.
Команды циклического сдвига через флаг переноса cf отличаются от команд простого циклического сдвига тем, что сдвигаемый бит не сразу попадает в операнд с другого его конца, а записывается сначала в флаг переноса cf. Лишь следующее исполнение данной команды сдвига (при условии, что она выполняется в цикле) приводит к помещению выдвинутого ранее бита с другого конца операнда (см. рис. 4).
rcl операнд,счетчик_сдвигов (Rotate through Carry Left) — циклический сдвиг влево через перенос.
Содержимое операнда сдвигается влево на количество бит, определяемое операндом счетчик_сдвигов. Сдвигаемые биты поочередно становятся значением флага переноса cf.
rcr операнд,счетчик_сдвигов (Rotate through Carry Right) — циклический сдвиг вправо через перенос.
Содержимое операнда сдвигается вправо на количество бит, определяемое операндом счетчик_сдвигов. Сдвигаемые биты поочередно становятся значением флага переноса cf.

Из рис. 4 видно, что при сдвиге через флаг переноса появляется промежуточный элемент, с помощью которого, в частности, можно производить подмену циклически сдвигаемых битов, в частности, рассогласование битовых последовательностей.
Под рассогласованием битовой последовательности здесь и далее подразумевается действие, которое позволяет некоторым образом локализовать и извлечь нужные участки этой последовательности и записать их в другое место
Пример. Дано отрицательное число. Выведите на экран его значение по модулю деленное на 2.
Любое отрицательное число хранится в дополнительном формате
-1 ffh
-2 feh
…
-10 f6h
получить значение числа по модулю, можно осуществив логическое отрицание над числом и добавив 1.
model small
.stack 100h
.data
x db -12
.code
start:
mov ax,@data
mov ds,ax
mov al,x ;в al отрицательное число
not al
inc al ;число по модулю
shr al,1
;выводим результат на экран
aam ;
;преобразование двоичного числа меньшего 63h (9910), которое находится в al в его ;неупакованный BCD-эквивалент
; -разделить значение регистра al на 10;
; -записать частное в регистр ah, остаток — в регистр al.
mov dx,ax ;число в регистр dx
or dx,3030h ;получаю ASCII код числа
xchg dh,dl ;меняю местами старший и младший байт, для вывода символа из dl
mov ah,02h ;
int 21h ;вывожу старшую половинку числа
xchg dh,dl ;меняю местами старший и младший байт,
int 21h ;вывожу младшую половинку числа
mov ax,4c00h
int 21h
end start
Команды передачи управления
По принципу действия, команды микропроцессора, обеспечивающие организацию переходов в программе, можно разделить на три группы:
1. Команды безусловной передачи управления:
- команда безусловного перехода; jmp
- вызова процедуры и возврата из процедуры; call, ret
- вызова программных прерываний и возврата из программных прерываний. Int, iret
2. Команды условной передачи управления:
- команды перехода по результату команды сравнения cmp;
- команды перехода по состоянию определенного флага;
- команды перехода по содержимому регистра ecx/cx.
3. Команды управления циклом:
- команда организации цикла со счетчиком ecx/cx;
- команда организации цикла со счетчиком ecx/cx с возможностью досрочного выхода из цикла по дополнительному условию.
jmp адрес_перехода - безусловный переход без сохранения информации о точке возврата. Аналог goto.
jmp m1 m4:
… …
m1: jmp m4
Условные переходыКоманды условного перехода имеют одинаковый синтаксис:
jcc метка_перехода
Мнемокод всех команд начинается с “j” — от слова jump (прыжок), cc — определяет конкретное условие, анализируемое командой. Что касается операнда метка_перехода, то эта метка может находится только в пределах текущего сегмента кода, межсегментная передача управления в условных переходах не допускается.
Для того чтобы принять решение о том, куда будет передано управление командой условного перехода, предварительно должно быть сформировано условие, на основании которого и будет приниматься решение о передаче управления. Источниками такого условия могут быть:
- любая команда, изменяющая состояние арифметических флагов;
- команда сравнения cmp, сравнивающая значения двух операндов;
- состояние регистра ecx/cx.
Условные переходы по содержимому флагов
| Название флага | Номер бита в eflags/flag | Команда условного перехода | Значение флага для осуществления перехода |
| Флаг переноса cf | 1 | jc | cf = 1 |
| Флаг четности pf | 2 | jp | pf = 1 |
| Флаг нуля zf | 6 | jz | zf = 1 |
| Флаг знака sf | 7 | js | sf = 1 |
| Флаг переполнения of | 11 | jo | of = 1 |
| Флаг переноса cf | 1 | jnc | cf = 0 |
| Флаг четности pf | 2 | jnp | pf = 0 |
| Флаг нуля zf | 6 | jnz | zf = 0 |
| Флаг знака sf | 7 | jns | sf = 0 |
| Флаг переполнения of | 11 | jno | of = 0 |
jcxz метка_перехода (Jump if cx is Zero) — переход, если cx ноль;
jecxz метка_перехода (Jump Equal ecx Zero) — переход, если ecx ноль.
Пример программы: определите, равны ли два числа вводимые пользователем с клавиатуры.
model small
.stack 100h
.data
s1 db 'числа равны$'
s2 db 'числа не равны$'
.code
start:
mov ax,@data
mov ds,ax
mov ah,01h
int 21h ;ввели первое число
mov dl,al
mov ah,01h
int 21h ;ввели второе число
sub al,dl ;сравнили числа
jnz m1
mov dx, offset s1
jmp m2
m1: mov dx, offset s2
m2: mov ah,09h
int 21h ;выводим информационную строку
mov ax,4c00h
int 21h
end start
Команда сравнения cmp
cmp операнд_1,операнд_2 - сравнивает два операнда и по результатам сравнения устанавливает флаги. Команда сравнения cmp имеет интересный принцип работы. Он абсолютно такой же, как и у команды вычитания sub. Единственное, чего она не делает — это запись результата вычитания на место первого операнда.
Алгоритм работы:
-выполнить вычитание (операнд1-операнд2);
-в зависимости от результата установить флаги, операнд1 и операнд2 не изменять (то есть результат не запоминать).
Условные переходы после команд сравнения
| Типы операндов | Мнемокод команды условного перехода | Критерий условного перехода | Значения флагов для осществления перехода |
| Любые | je | операнд_1 = операнд_2 | zf = 1 |
| Любые | jne | операнд_1<>операнд_2 | zf = 0 |
| Со знаком | jl/jnge | операнд_1 < операнд_2 | sf <> of |
| Со знаком | jle/jng | операнд_1 <= операнд_2 | sf <> of or zf = 1 |
| Со знаком | jg/jnle | операнд_1 > операнд_2 | sf = of and zf = 0 |
| Со знаком | jge/jnl | операнд_1 => операнд_2 | sf = of |
| Без знака | jb/jnae | операнд_1 < операнд_2 | cf = 1 |
| Без знака | jbe/jna | операнд_1 <= операнд_2 | cf = 1 or zf=1 |
| Без знака | ja/jnbe | операнд_1 > операнд_2 | cf = 0 and zf = 0 |
| Без знака | jae/jnb | операнд_1 => операнд_2 | cf = 0 |
Пример программы: определите, равны ли два числа вводимые пользователем с клавиатуры.
model small
.stack 100h
.data
s1 db 'числа равны$'
s2 db 'числа не равны$'
.code
start:
mov ax,@data
mov ds,ax
mov ah,01h
int 21h ;ввели первое число
mov dl,al
mov ah,01h
int 21h ;ввели второе число
cmp al,dl ;сравнили числа
jne m1
mov dx, offset s1
jmp m2
m1: mov dx, offset s2
m2: mov ah,09h
int 21h ;выводим информационную строку
mov ax,4c00h
int 21h
end start Организация цикловloop метка_перехода (Loop) — повторить цикл
Работа команды заключается в выполнении следующих действий:
- декремента регистра ecx/cx;
- сравнения регистра ecx/cx с нулем:
- если (ecx/cx) > 0, то управление передается на метку перехода;
- если (ecx/cx) = 0, то управление передается на следующую после loop команду
mov cx, количество циклов
м1: тело цикла
loop m1
loope/loopz метка_перехода (Loop till cx <> 0 or Zero Flag = 0) — повторить цикл, пока cx <> 0 или zf = 0.
loopne/loopnz метка_перехода (Loop till cx <> 0 or Not Zero flag=0) — повторить цикл пока cx <> 0 или zf = 1
Недостаток команд организации цикла loop, loope/loopz и loopne/loopnz в том, что они реализуют только короткие переходы (от –128 до +127 байт).
Организация вложенных циклов
mov cх,n ; в сх заносим количество итераций внешнего цикла
m1:
push cx
![]() …
…
mov cx,n1; в сх заносим количество итераций внутреннего цикла
m2:
тело внутреннего цикла
loop m2
…
pop cx
loop m1
Пример программы: Напишите программу подсчета у=1+2+3+…+n, n не более 10000.
model small
.stack 100h
.data
yb dd ?
ym dw ?
s1 db 'введите n',10,13,'$'
.code
start:
mov ax,@data
mov ds,ax
mov dx, offset s1
mov ah,09h
int 21h
mov cx,3
![]() m: shl bx,4
m: shl bx,4
mov ah,01h
int 21h вводим n в регистр bx
sub ax,130h
add bx,ax
loop m
mov cx,bx
![]() xor dx,dx
xor dx,dx
xor al,al
m1: add dx,cx считаем у
jnc m2
mov al,1
m2: loop m1
cmp al,1
je m3
mov ym,dx
m3: mov yb,edx
mov ax,4c00h
int 21h
end start
Цепочечные команды
(Команды обработки строк символов)
Цепочка – это последовательность элементов, размер которых может быть байт, слово, двойное слово. Содержимое этих элементов может быть любое – символы, числа.
В системе команд микропроцессора имеется семь операций-примитивов обработки цепочек.
Каждая из них реализуется в микропроцессоре тремя командами, в свою очередь, каждая из этих команд работает с соответствующим размером элемента — байтом, словом или двойным словом.
Вместе с цепочечными командами обычно применяют префиксы повторений, которые ставятся перед командой в поле [метки]. Цепочечная команда без префикса выполняется один раз. С префиксом цепочечные команды выполняются циклично.
rep (REPeat) - команда выполняется, пока содержимое в ecx/cx не станет равным 0. При этом цепочечная команда, перед которой стоит префикс, автоматически уменьшает содержимое ecx/cx на единицу. Та же команда, но без префикса, этого не делает.
repe или repz (REPeat while Equal or Zero) - команда выполняется до тех пор, пока содержимое ecx/cx не равно нулю или флаг zf равен 1. Как только одно из этих условий нарушается, управление передается следующей команде программы
repne или repnz (REPeat while Not Equal or Zero) - команда циклически выполняется до тех пор, пока содержимое ecx/cx не равно нулю или флаг zf равен нулю. При невыполнении одного из этих условий работа команды прекращается.
Формирования физического адреса операндов адрес_источника и адрес_приемника происходит следующим образом:
адрес_источника — пара ds:esi/si;
адрес_приемника — пара es:edi/di
Важный момент, касающийся всех цепочечных команд, — это направление обработки цепочки. Есть две возможности:
- от начала цепочки к ее концу, то есть в направлении возрастания адресов;
- от конца цепочки к началу, то есть в направлении убывания адресов.
Цепочечные команды сами выполняют модификацию регистров, адресующих операнды, обеспечивая тем самым автоматическое продвижение по цепочке. Количество байт, на которые эта модификация осуществляется, определяется кодом команды. А вот знак этой модификации определяется значением флага направления df (Direction Flag) в регистре eflags/flags. Состоянием флага df можно управлять с помощью двух команд, не имеющих операндов:
cld (Clear Direction Flag) — очистить флаг направления df = 0, значение индексных регистров esi/si и edi/di будет автоматически увеличиваться (операция инкремента) цепочечными командами, то есть обработка будет осуществляться в направлении возрастания адресов;
std (Set Direction Flag) — установить флаг направления df = 1, то значение индексных регистров esi/si и edi/di будет автоматически уменьшаться (операция декремента) цепочечными командами, то есть обработка будет идти в направлении убывания адресов.
Типовой набор действий для выполнения любой цепочечной команды:
- Установить значение флага df в зависимости от того, в каком направлении будут обрабатываться элементы цепочки — в направлении возрастания или убывания адресов.
- Загрузить указатели на адреса цепочек в памяти в пары регистров ds:(e)si и es: (e)di.
- Загрузить в регистр ecx/cx количество элементов, подлежащих обработке.
- Выдать цепочечную команду с префиксом повторений.
Пересылка цепочек
movs адрес_прием, адрес_источника (MOVe String)- переслать цепочку;
movsb MOVe String Byte) — переслать цепочку байт;
movsw (MOVe String Word) — переслать цепочку слов;
movsd (MOVe String Double word) — переслать цепочку двойных слов.
Команда копирует байт, слово или двойное слово из цепочки источника, в цепочку приемника. Размер пересылаемых элементов ассемблер определяет, исходя из атрибутов идентификаторов. К примеру, если эти идентификаторы были определены директивой db, то пересылаться будут байты, если идентификаторы были определены с помощью директивы dd, то пересылке подлежат двойные слова.
Для цепочечных команд с операндами типа movs адрес_приемника,адрес_источника, не существует машинного аналога. При трансляции в зависимости от типа операндов транслятор преобразует ее в одну из трех машинных команд: movsb, movsw или movsd.
Сама по себе команда movs пересылает только один элемент, исходя из его типа, и модифицирует значения регистров esi/si и edi/di. Если перед командой написать префикс rep, то одной командой можно переслать до 64 Кбайт данных. Число пересылаемых элементов должно быть загружено в счетчик — регистр cx (use16) или ecx (use32).
Пример проги. Пересылка строк командой movs
MODEL small
STACK 256
.data
source db 'Тестируемая строка','$' ;строка-источник
dest db 19 DUP (' ') ;строка-приёмник
.code
main:
mov ax,@data ;загрузка сегментных регистров
mov ds,ax ;настройка регистров DS и ES на адрес сегмента данных
mov es,ax
cld ;сброс флага DF — обработка строки от начала к концу
lea si,source ;загрузка в si смещения строки-источника
lea di,dest ;загрузка в DS смещения строки-приёмника
mov cx,20 ;для префикса rep — счетчик повторений (длина строки)
rep movs dest,source ;пересылка строки
lea dx,dest
mov ah,09h ;вывод на экран строки-приёмника
int 21h
mov ax,4c00h
int 21h
end main
Операция сравнения цепочек
cmps адрес_приемника,адрес_источника(CoMPare String) — сравнить строки;
cmpsb (CoMPare String Byte) — сравнить строку байт;
cmpsw (CoMPare String Word) — сравнить строку слов;
cmpsd (CoMPare String Double word) — сравнить строку двойных слов.
Алгоритм работы команды cmps заключается в последовательном выполнении вычитания (элемент цепочки-источника — элемент цепочки-получателя) над очередными элементами обеих цепочек. Принцип выполнения вычитания командой cmps аналогичен команде сравнения cmp. Она, так же, как и cmp, производит вычитание элементов, не записывая при этом результата, и устанавливает флаги zf, sf и of.
После выполнения вычитания очередных элементов цепочек командой cmps, индексные регистры esi/si и edi/di автоматически изменяются в соответствии со значением флага df на значение, равное размеру элемента сравниваемых цепочек.
Чтобы заставить команду cmps выполняться несколько раз, то есть производить последовательное сравнение элементов цепочек, необходимо перед командой cmps определить префикс повторения. С командой cmps можно использовать префикс повторения repe/repz или repne/repnz:
- repe или repz — если необходимо организовать сравнение до тех пор, пока не будет выполнено одно из двух условий: достигнут конец цепочки (содержимое ecx/cx равно нулю) или в цепочках встретились разные элементы (флаг zf стал равен нулю);
- repne или repnz — если нужно проводить сравнение до тех пор, пока: не будет достигнут конец цепочки (содержимое ecx/cx равно нулю) или в цепочках встретились одинаковые элементы (флаг zf стал равен единице).
Пример программы Сравнение двух строк командой cmps
MODEL small
STACK 256
.data
sov db 0ah,0dh,'Строки совпадают.','$'
nesov db 0ah,0dh,'Строки не совпадают','$'
s1 db '0123456789',0ah,0dh,'$';исследуемые строки
s2 db 10
s3 db 11 dup (0)
.code
main:
mov ax,@data ;загрузка сегментных регистров
mov ds,ax
mov es,ax ;настройка ES на DS
;вводим строку
mov ah, 0аh
mov dx, offset s2
int 21h
;поиск совпадающих элементов, сброс флага DF - сравнение в направлении возрастания адресов
cld
lea si,s1 ;загрузка в si смещения string1
lea di,s3 ;загрузка в di смещения string2
mov cx,10 ;длина строки для префикса repe
repe cmpsb ;сравнение строк (пока сравниваемые элементы строк равны)
;выход при обнаружении не совпавшего элемента
jcxz equal ;cx=0, то есть строки совпадают
lea dx, nesov
jmp exit ;выход
equal: lea dx, sov
exit: mov ah,09h
int 21h ;вывод сообщения
mov ax,4c00h
int 21h
end main ;конец программы
Операция сканирования цепочек
scas адрес_приемника (SCAning String) — сканировать цепочку;
scasb (SCAning String Byte) — сканировать цепочку байт;
scasw (SCAning String Word) — сканировать цепочку слов;
scasd (SCAning String Double Word) — сканировать цепочку двойных слов
Эти команды осуществляют поиск искомого значения, которое находится в регистре al/ax/eax. Принцип поиска тот же, что и в команде сравнения cmps, то есть последовательное выполнение вычитания
(содержимое регистра_аккумулятора – содержимое очередного_элемента_цепочки).
В зависимости от результатов вычитания производится установка флагов, при этом сами операнды не изменяются.
Так же, как и в случае команды cmps, с командой scas удобно использовать префиксы repe/repz или repne/repnz:
- repe или repz — если нужно организовать поиск до тех пор, пока не будет выполнено одно из двух условий: достигнут конец цепочки (содержимое ecx/cx равно 0) или в цепочке встретился элемент, отличный от элемента в регистре al/ax/eax;
- repne или repnz — если нужно организовать поиск до тех пор, пока не будет выполнено одно из двух условий достигнут конец цепочки (содержимое ecx/cx равно 0)или в цепочке встретился элемент, совпадающий с элементом в регистре al/ax/eax.
Пример проги. найти количество * в строке
MODEL small
STACK 256
.data
s1 db 20
s2 db 21 dup ?
s3 db 'количество * в строке',0ah,0dh,'$'
.code
main:
mov ax,@data
mov ds,ax
mov es,ax ;настройка ES на DS
;вводим строку
mov ah,0ah
mov dx, offset s1
int 21h
;поиск *
mov al,'*' ;символ для поиска — `а`(кириллица)
cld ;сброс флага df
lea di, s2 ;загрузка в es:di смещения строки
inc di ;первый элемент в s3 это количество введенных символов, его игнорируем
xor bl ;обнуляем счетчик звездочек
mov cx,20 ;для префикса repne — длина строки
m1: repne scasb ;пока искомый символ и символ в строке не совпадут идет поиск, ;выход при совпадении
je found ;если равны - переход на обработку
;вывод количества звездочек в строке
mov ah,09h
mov dx,offset s3
int 21h ;вывод сообщения nochar
mov al,bl
aam
or ax, 3030h
mov dx,ax
xchg dh,dl
mov ah, 02h
int 21h
xchg dh,dl
int 21h
mov ax,4c00h
int 21h
;суммируем количество звездочек
found: inc bl
jmp m1
end main
Загрузка элемента цепочки в аккумуляторlods адрес_источника (LOaD String) — загрузить элемент из цепочки в регистр-аккумулятор al/ax/eax;
lodsb (LOaD String Byte) — загрузить байт из цепочки в регистр al;
lodsw (LOaD String Word) — загрузить слово из цепочки в регистр ax;
lodsd (LOaD String Double Word) — загрузить двойное слово из цепочки в регистр eax.
Эта операция-примитив позволяет извлечь элемент цепочки и поместить его в регистр-аккумулятор al, ax или eax. Эту операцию удобно использовать вместе с поиском (сканированием) с тем, чтобы, найдя нужный элемент, извлечь его (например, для изменения).
Перенос элемента из аккумулятора в цепочку stos адрес_приемника (STOre String) — сохранить элемент из регистра-аккумулятора al/ax/eax в цепочке; stosb (STOre String Byte) — сохранить байт из регистра al в цепочке; stosw (STOre String Word) — сохранить слово из регистра ax в цепочке; stosd (STOre String Double Word) - сохранить двойное слово из регистра eax в цепочке.
Эта операция-примитив позволяет произвести действие, обратное команде lods, то есть сохранить значение из регистра-аккумулятора в элементе цепочки. Эту операцию удобно использовать вместе с операцией поиска (сканирования) scans и загрузки lods, с тем, чтобы, найдя нужный элемент, извлечь его в регистр и записать на его место новое значение.
Сложные структуры данных
Одномерные массивы
Все элементы массива располагаются в памяти последовательно
Описание элементов массива
mas db 1,2,3,4,5
mas dw 5 dup (0)
Доступ к элементам массива
mov ax,mas[si] ; в si номер элемента в массиве
mov mas[si], ax ; в di номер элемента в массиве
Используя команды i486 можно использовать адресацию с масштабированием, при размере элементов больше байта
Mov ax, mas[si*2] ;
Пример программы Найти в строке хотя бы один нулевой элемент
model small
.stack 100h
.data
bufer dw 25 ;формирую размер буфера для ввода строки
mas dw 25 dup (' ') ;формирую буфер
adr dw bufer ;описываю адрес
subj1 db ‘в строке найден нулевой элемент', '$'
subj2 db ‘в строке не найден нулевой элемент', '$'
.code
main:
mov ax,@data
mov ds,ax
mov ah,0ah
mov dx, adr
int 21h ; ввод строки с клавиатуры
;поиск нулевого элемента
xor si, si
mov cx, mas[si] ;загружаем в сх количество элементов в строке
mov ax, 030h ;в ax загружаем ASCII код нуля
m1: inc si либо inc si
inc si cmp ax, mas[si*2]
cmp ax, mas[si]
je m2 ;если в строке найдем нулевой элемент, то выходим из цикла на вывод subj1
loop m1
;нормальный выход из цикла означает что в строке нет нулевых элементов
mov ah,09h
lea dx, subj2
int 21h
jmp exit
m2: mov ah, 09h
lea dx,subj1
int 21h
exit: mov ax,4c00h
int 21h
end main
Двумерные массивов
!Специальных средств для описания двумерных массивов в ассемблере нет!
Двумерный массив описывается также как и одномерный массив, отличие заключается в трактовке расположения элементов. Пусть последовательность элементов трактуется как двумерный массив, расположенный по строкам, тогда адрес элемента [i,j] вычисляется так
База+колич_элем_строке*размер_элем*I+j
Для определения базы используют имя массива, для второго слагаемого регистр bx , для третьего si, это базово-индексная адресация.
Описание массива:
Mas1 db 10 dup (3 dup (?))
Mas2 db 1,2,3,4,5
3,4,5,6,7
4,7,9,2,0
Пример поиска максимального элемента в каждой строке однобайтного массива mas, размером 5*10, с занесением максимальных элементов в массив max (1*5). Инициализацию массива mas рассматривать не будем.
…
xor di, di ;обнуляем индексы массива max
xor bx, bx ;обнуляем индексы строк массива mas
xor si, si ;обнуляем индексы столбцов массива mas
mov cx,5 ;в cx количество строк, внешний цикл
m1: push cx
mov cx, 10 ;в сх количество столбцов, внутренний цикл
mov al, mas[si+bx];первый элемент из 1 строки mas в аl
m2: inc si
cmp al, mas[si+bx] ;сравниваем со следующим элем. строки
jb m3 ;если меньше на m3
mov al, mas[si+bx] ;иначе в аl заносим больший элемент
m3: loop m2 ;после выхода из цикла в ах максимальный элемент в данной строке
mov max[di],al ;кладем максимальный элемент в массив max
inc di
xor si,si ;обнуляем номер столбца
add bx, 10 ;переходим на следующую строку
pop cx ;достаем сх
loop m1
…
Структура – это тип данных, состоящий из фиксированного числа элементов разного типа.
Для использования структур в программе необходимо выполнить три действия:
1. Задать шаблон структуры. По смыслу это означает определение нового типа данных (схемы или шаблона), который впоследствии можно использовать для определения переменных этого типа. Память при этом не выделяется, это информация для транслятора о расположении полей и их значению по умолчанию.
Синтаксис описания шаблона структуры:
имя_структуры STRUC
<описание полей> ; последовательность директив описания данных dd,dw,db…
имя_структуры ENDS
2. Определить экземпляр структуры. Этот этап подразумевает инициализацию конкретной переменной заранее определенной (с помощью шаблона) структурой. В данном случае транслятору дается указание выделить память и присвоить этой области символическое имя.
Описать структуру в программе можно только один раз, а определить – любое количество раз.
Определение данных с типом структуры имеет следующий вид:
[имя переменной] имя_структуры <[список значений]>
Похожие работы
... сопроцессор или нет, что особенно важно при создании кода, который будет исполняться внутри обработчика аппаратного прерывания. 4. СТРУКТУРА МИКРОПРОЦЕССОРА Разработкой микропроцессоров в России занимаются ЗАО «МЦСТ» и НИИСИ РАН. НИИСИ разрабатывает процессоры серии Komdiv на основе архитектуры MIPS. МЦСТ разработаны и внедрены в производство универсальные RISC-микропроцессоры с ...
... Это почти все что касается самого общего рассказа о процессорах - почти любая операция может быть выполнена последовательностью простых инструкций, подобных описанным. 2.2. Алгоритм работы процессора Весь алгоритм работы процессора можно описать в трех строчках НЦ | чтение команды из памяти по адресу, записанному в СК | увеличение СК на длину прочитанной команды | ...


... в секунду карман не тянет. Не успеешь глазом моргнуть, как новые процессоры, интеллектуальные дисковые и графические контроллеры используют его до корки, и попросят добавки. Определенной проблемой новой технологии является притормаживание перехода на нее компании Intel. Гигант не торопится переключаться на RIMM-ы, объясняя это необходимостью плавного перехода. Как именно задержка обеспечивает ...


... : -производитель чипсет, если возможно – модель материнской платы; -тактовые частоты процессора, памяти, системных шин; -названия, параметры работы всех системных и периферийных устройств; -расширенная информация о процессоре, памяти, жестких дисках, 3D-ускорителе; -разнообразные параметры программной среды: ОС, драйверы, процессы, системные файлы и т.д.; -информация о поддержке видеокартой ...
0 комментариев