Навигация
3. MPI у прикладах
3.1 Найпростіша MPI-програма
Ми почнемо наше знайомство з MPI з вивчення найпростішої програми:
===== Example1.cpp =====
#include <mpi.h> // очевидно;)
#include <stdio.h>
int main(int argc, char* argv[])
{
int myrank, size;
MPI_Init(&argc,&argv); // Ініціалізація MPI
MPI_Comm_size(MPI_COMM_WORLD,&size); // Розмір комунікатора
MPI_Comm_rank(MPI_COMM_WORLD,&myrank); // Одержуємо наш номер
printf("Proc %d of %d\n",myrank,size);
MPI_Finalize(); // Фіналізація MPI
puts ("Done.");
return 0;
}
===== Example1.cpp =====
Перед викликом будь-якої процедури MPI, потрібно викликати ініціалізацію MPI_Init, перед цим викликом може знаходитися тільки виклик MPI_Initialized, призначення якого очевидно. MPI_Init крім усього іншого створює глобальний комунікатор MPI_COMM_WORLD, через которий буде проходити обмін повідомленнями. Область взаємодії комунікатора MPI_COMM_WORLD – усі процеси даної програми. Якщо є необхідність у розбивці області взаємодії на більш дрібні сегменти (частково-широкомовні розсилання), використовуються виклики MPI_Comm_dup/create/split/etc (тут не розглядаються). Розмір комунікатора, одержуваний викликом MPI_Comm_size – число процесів у ньому. Розмір комунікатора MPI_COMM_WORLD – загальне число процесів. Кожен процес має свій унікальний (у рамках комунікатора!) номер – ранг. Ранги процесів у контекстах різних комунікаторів можуть розрізнятися. Після виконання всіх обмінів повідомленнями в програмі повинний розташовуватися виклик MPI_Finalize() – процедура видаляє всі структури даних MPI і робить інші необхідні дії. Програміст повинний сам подбати про те, щоб до моменту виклику MPI_Finalize усі пересилання даних були довершені. Після виконання MPI_Finalize виклик будь-яких, крім MPI_Initialized, процедур (навіть MPI_Init!) неможливий. MPI_Initialized у даному випадку буде показувати, визивал-ли процес MPI_Init. Отже, уже стало ясно, що наша програма виводить повідомлення від усіх породжених нею процесів. Приклад висновку (порядок повідомлень, що надходять від процесів, може і буде мінятися) приведений нижче (np - кількість процесів):
Example1 output (np = 3):
Proc 1 of 3
Done.
Proc 0 of 3
Done.
Proc 2 of 3
Done.
Зверніть увагу, що після виклику MPI_Finalize() паралелізм не закінчується – “Done” виводиться кожним процесом.
Вправа 1: У принципі, такого об’єму вже досить, щоб писати програми в моделі паралелізму даних – напишіть який-небудь приклад.
3.2 Обмін повідомленнями
У MPI існує величезна множина процедур обміну повідомленнями. Вони можуть використовуватися, як для посилки керуючих сигналів, так і для передачі даних (ці випадки будуть розглянуті в прикладах 3 і 4). Два основних види обміну: двухточений і глобальний. Останній буде описаний пізніше.
З погляду програміста, двохточковий обмін виконується в такий спосіб: для пересилання повідомлення процес-джерело викликає підпрограму передачі, при звертанні до якої вказується ранг процесу-одержувача (адресата) у відповідній області взаємодії. Остання задається своїм комунікатором, звичайно це MPI_COMM_WORLD. Процес-одержувач, для того, щоб одержати спрямоване йому повідомлення, викликає підпрограму прийому, указавши при цьому ранг джерела.


Нагадаємо, що MPI гарантує виконання деяких властивостей двохточкового обміну, таких як збереження порядку повідомлень, і гарантоване виконання обміну. Якщо один процес посилає повідомлення, а іншої - запит на його прийом, то або передача, або прийом будуть вважатися виконаними. При цьому можливі три сценарії обміну:
другий процес одержує від першого адресоване йому повідомлення;
відправлене повідомлення може бути отримано третім процесом, при цьому фактично виконана буде передача повідомлення, а не його прийом (повідомлення пройшло повз адресата);
другий процес одержує повідомлення від третього, тоді передача не може вважатися виконаної, тому що адресат одержав не те "лист".
У двохточковом обміні слід дотримуватися правила відповідності типів переданих і прийнятих даних. Це утрудняє обмін повідомленнями між програмами, написаними на різних мовах програмування.
Існують чотири різновиди крапкового обміну: синхронний, асинхронний, блокуючий і неблокуючий. У MPI маються також чотири режими обміну, що розрізняються умовами ініціалізації і завершення передачі повідомлення:
стандартна передача вважається виконаною і завершується, як тільки повідомлення відправлене, незалежно від того, дійшло воно до чи адресата ні. У стандартному режимі передача повідомлення може починатися, навіть якщо ще не початий його прийом;
синхронна передача відрізняється від стандартної тим, що вона не завершується доти, поки не буде довершений прийом повідомлення. Адресат, одержавши повідомлення, посилає процесу, що відправив його, повідомлення, що повинне бути отримане відправником для того, щоб обмін вважався виконаним. Операцію передачі повідомлення іноді називають "рукостисканням";
буферизована передача завершується відразу ж, повідомлення копіюється в системний буфер, де й очікує своєї черги на пересилання. Завершується буферизованна передача незалежно від того, виконаний прийом чи повідомлення ні;
передача "по готовності" починається тільки в тому випадку, коли адресат ініціалізував прийом повідомлення, а завершується відразу, незалежно від того, прийняте чи повідомлення ні.
Кожний з цих чотирьох режимів існує як у що блокуючий, так і в неблокуючій формах. При формі прийому, що блокуючий,/передачі виконання програми припиняється по завершення виконання операції.
У MPI прийняті наступні угоди про імена підпрограм двохточкового обміну: MPI_[I][R|S|B]Send. Префікс I (Immediate) позначає режим, неблокуючий, один із префіксів R|S|B позначає режим обміну по відповідно готовності, синхронний і буферизований, відсутність префікса позначає стандартний обмін. Разом – 8 різновидів передачі повідомлень. Для прийому ж існує всього 2 різновиди: MPI_[I]Recv. Приклади: MPI_Irsend - виконує передачу «по готовності» у режимі, неблокуючий, MPI_Bsend - буферизована передача з блокуванням, MPI_Recv - прийом, що блокуючий. Відзначимо, що підпрограма прийому будь-якого типу може прийняти повідомлення від будь-якої програми передачі. Перейдемо до приклада 2:
===== Example2.cpp =====
#include <mpi.h>
#include <stdio.h>
#define TAG_SEND_FWD 99
#define TAG_SEND_BACK 98
#define TAG_REPLY 97
int main(int argc, char* argv[])
{
int k,x;
int myrank, size;
MPI_Status status;
MPI_Init(&argc,&argv);
MPI_Comm_size(MPI_COMM_WORLD,&size);
MPI_Comm_rank(MPI_COMM_WORLD,&myrank);
if (myrank == 0) // призначимо один процес головним
{
puts("Running procs forwards"); fflush(stdout); // негайний вивід повідомлення
x=1;
while (x < size)
{
MPI_Ssend(&x, 1, MPI_INT, x, TAG_SEND_FWD, MPI_COMM_WORLD);
MPI_Recv (&k, 1, MPI_INT, x, TAG_REPLY, MPI_COMM_WORLD, &status);
printf("Reply from proc %d received %d\n",x,k); fflush(stdout);
x++;
}
puts("Running procs backwards"); fflush(stdout);
x=size-1;
while (x >0)
{
MPI_Send(&x,1, MPI_INT, x, TAG_SEND_BACK, MPI_COMM_WORLD);
x--;
}
else // інші процеси - підлеглі
{
MPI_Recv(&k, 1, MPI_INT, 0, TAG_SEND_FWD, MPI_COMM_WORLD, &status);
printf("Proc %d received %d\n",myrank,k); fflush(stdout);
MPI_Ssend(&k,1, MPI_INT, 0, TAG_REPLY, MPI_COMM_WORLD);
MPI_Recv(&k, 1, MPI_INT, 0, TAG_SEND_BACK, MPI_COMM_WORLD, &status);
printf("Proc %d Received %d\n",myrank,k); fflush(stdout);
}
MPI_Finalize();
return 0;
}
===== Example2.cpp =====
У цьому прикладі один із процесів (з рангом 0) розсилає повідомлення іншому у прямому, а потім у зворотному порядку.
Прототип функції: int MPI_[..]Send(void* buf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm).
Вхідні параметри (однакові для усіх функцій *send):
buf – адреса першого елемента в буфері передачі
count – кількість елементів у буфері передачі
| Тип даних MPI | Тип даних З |
| MPI_CHAR | signed char |
| MPI_SHORT | signed short int |
| MPI_INT | signed int |
| MPI_LONG | signed long int |
| MPI_UNSIGNED_CHAR | unsigned char |
| MPI_UNSIGNED_SHORT | unsigned short int |
| MPI_UNSIGNED | unsigned int |
| MPI_UNSIGNED_LONG | unsigned long int |
| MPI_FLOAT | float |
| MPI_DOUBLE | double |
| MPI_LONG_DOUBLE | long double |
| MPI_BYTE | Ні відповідності |
| MPI_PACKED | Ні відповідності |
datatype – тип MPI кожного переданого елемента. MPI визначає власні типи даних, схожі на типи даних C, однак, існують і унікальні для MPI типи (див. таблицю відповідності). У MPI повинні дотримуватися правила сумісності типів, з базових типів можуть бути сконструйовані більш складні.
dest – ранг процесу-одержувача повідомлення. Ранг тут – ціле число від 1 до n-1, де n – число процесів в області взаємодії
tag – тег – унікальний ідентифікатор повідомлення
comm – комунікатор.
Стандартна передача, що блокуючий, починається незалежно від того, чи був зареєстрований відповідний прийом, а завершується тільки після того, як повідомлення прийняте системою і процес-джерело може знову використовувати буфер передачі. Повідомлення може бути скопійоване прямо в буфер прийому, а може бути поміщене в тимчасовий системний буфер, де і буде чекати виклику адресатом підпрограми прийому. У цьому випадку говорять про буферизації повідомлення. Передача може завершитися ще до виклику відповідної операції прийому. З іншого боку, буфер може бути недоступний чи MPI може вирішити не буферизувати вихідні повідомлення з міркувань збереження високої продуктивності. У цьому випадку передача завершиться тільки після того, як буде зареєстровані відповідний прийом і дані будуть передані адресату.
Прийом виконується підпрограмою:
int MPI_Recv (void *buf, int count, MPI_Datatype datatype, int source, int tag, MPI_Comm comm, MPI_Status * status)
Її вхідні параметри (у MPI_Irecv – такі ж):
count – максимальна кількість елементів у буфері прийому. Фактична їхня кількість можна визначити за допомогою підпрограми MPI_Get_count;
datatype – тип прийнятих даних. Нагадаємо про необхідність дотримання відповідності типів аргументів підпрограм прийому і передачі;
source – ранг джерела. Можна використовувати спеціальне значення mpi_any_source, що відповідає довільному значенню рангу. У програмуванні ідентифікатор, що відповідає довільному значенню параметра, часто називають "джокером". Цей термін будемо використовувати і ми;
tag – тег чи повідомлення "джокер" mpi_any_tag, що відповідає довільному значенню тега;
comm — комунікатор. При вказівці комунікатора "джокери" використовувати не можна.
Варто мати на увазі, що при використанні значень mpi_any_source (будь-яке джерело) і mpi_any_tag (будь-який тег) є небезпеку прийому повідомлення, не призначеного даному процесу.
Вихідними параметрами є:
buf – початкова адреса буфера прийому. Його розмір повинний бути достатнім, щоб розмістити прийняте повідомлення, інакше при виконанні прийому відбудеться збій – виникне помилка переповнення;
status – статус обміну – спеціальна структура MPI.
Якщо повідомлення менше, ніж буфер прийому, змінюється вміст лише тих комірок пам'яті буфера, що відносяться до повідомлення. Інформація про довжину прийнятого повідомлення міститься в одному з полів статусу, але до цієї інформації в програміста немає прямого доступу (як до поля рядка чи елементу масиву). Розмір отриманого повідомлення (count) можна визначити за допомогою виклику підпрограми MPI_Get_count:
int MPI_Get_count (MPI_Status *status, MPI_Datatype datatype, int *count)
Аргумент datatype повинний відповідати типу даних, зазначеному в операції обміну.
Висновок Example2 output(np = 6): Ssend & replies
Running procs forwards
Proc 1 received 1
Reply from proc 1 received 1
Proc 2 received 2
Reply from proc 2 received 2
Proc 3 received 3
Reply from proc 3 received 3
Proc 4 received 4
Reply from proc 4 received 4
Proc 5 received 5
Reply from proc 5 received 5
Running procs backwards
Proc 5 Received 5
Proc 4 Received 4
Proc 3 Received 3
Proc 2 Received 2
Proc 1 Received 1
Завдання 1: Проаналізуйте висновок приклада. Спробуйте забрати зворотні повідомлення (replies), що зміниться? Застосуєте різні сполучення *send (Send,Ssend,Rsend) і прокоментуйте відповідні висновки програм.
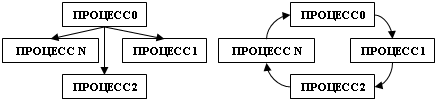
Завдання 2: Зміните топологію пересилання повідомлень у Прикладі 2 з «зірки» на «кільце» (див. мал.). Проробіть усі те ж, що й у Завданні 1.

Похожие работы
... і окремих процесів. Виробничий цикл складного виробу дорівнює найбільшій сумі циклів взаємозв'язаних послідовних процесів. 3. Економічне значення і способи скорочення виробничого циклу. Виробничий цикл є важливим показником рівня організації виробничого процесу, що істотно впливає на його ефективність. Скорочення виробничого циклу зменшує незавершене виробництво і відповідно оборотні кошти пі ...
0 комментариев