Навигация
КЛАССИФИКАЦИЯ ПАРАЛЛЕЛЬНЫХ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ
57787
знаков
26
таблиц
0
изображений
2. КЛАССИФИКАЦИЯ ПАРАЛЛЕЛЬНЫХ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ
Основным параметром классификации паралелльных компьютеров является наличие общей (SMP) или распределенной памяти (MPP). Нечто среднее между SMP и MPP представляют собой NUMA-архитектуры, где память физически распределена, но логически общедоступна. Кластерные системы являются более дешевым вариантом MPP. При поддержке команд обработки векторных данных говорят о векторно-конвейерных процессорах, которые, в свою очередь могут объединяться в PVP-системы с использованием общей или распределенной памяти. Все большую популярность приобретают идеи комбинирования различных архитектур в одной системе и построения неоднородных систем.
При организациях распределенных вычислений в глобальных сетях (Интернет) говорят о мета-компьютерах, которые, строго говоря, не представляют из себя параллельных архитектур.
Более подробно особенности всех перечисленных архитектур будут рассмотрены далее на этой странице, а также в описаниях конкретных компьютеров - представителей этих классов. Для каждого класса приводится следующая информация:
- краткое описание особенностей архитектуры;
- примеры конкретных компьютеров;
- перспективы масштабируемости;
- типичные особенности построения операционных систем;
- наиболее характерная модель программирования (хотя возможны и другие).
Таблица 2.1 – Массивно-параллельные системы (MPP)
| Архитектура | Система состоит из однородных вычислительных узлов, включающих: - один или несколько центральных процессоров (обычно RISC); - локальную память (прямой доступ к памяти других узлов невозможен); - коммуникационный процессор или сетевой адаптер; - иногда - жесткие диски (как в SP) и/или другие устройства В/В. К системе могут быть добавлены специальные узлы ввода-вывода и управляющие узлы. Узлы связаны через некоторую коммуникационную среду (высокоскоростная сеть, коммутатор и т.п.) |
| Примеры | IBM RS/6000 SP2, Intel PARAGON/ASCI Red, CRAY T3E, Hitachi SR8000, транспьютерные системы Parsytec. |
| Масштабируемость | Общее число процессоров в реальных системах достигает нескольких тысяч (ASCI Red, Blue Mountain). |
| Операционная система | Существуют два основных варианта: Полноценная ОС работает только на управляющей машине (front-end), на каждом узле работает сильно урезанный вариант ОС, обеспечивающие только работу расположенной в нем ветви параллельного приложения. Пример: Cray T3E. На каждом узле работает полноценная UNIX-подобная ОС (вариант, близкий к кластерному подходу). Пример: IBM RS/6000 SP + ОС AIX, устанавливаемая отдельно на каждом узле. |
| Модель программирования | Программирование в рамках модели передачи сообщений ( MPI, PVM, BSPlib) |
Таблица 2.2 – Симметричные мультипроцессорные системы (SMP)
| Архитектура | Система состоит из нескольких однородных процессоров и массива общей памяти (обычно из нескольких независимых блоков). Все процессоры имеют доступ к любой точке памяти с одинаковой скоростью. Процессоры подключены к памяти либо с помощью общей шины (базовые 2-4 процессорные SMP-сервера), либо с помощью crossbar-коммутатора (HP 9000). Аппаратно поддерживается когерентность кэшей. |
| Примеры | HP 9000 V-class, N-class; SMP-cервера и рабочие станции на базе процессоров Intel (IBM, HP, Compaq, Dell, ALR, Unisys, DG, Fujitsu и др.). |
| Масштабируемость | Наличие общей памяти сильно упрощает взаимодействие процессоров между собой, однако накладывает сильные ограничения на их число - не более 32 в реальных системах. Для построения масштабируемых систем на базе SMP используются кластерные или NUMA-архитектуры. |
| Операционная система | Вся система работает под управлением единой ОС (обычно UNIX-подобной, но для Intel-платформ поддерживается Windows NT). ОС автоматически (в процессе работы) распределяет процессы/нити по процессорам (scheduling), но иногда возможна и явная привязка. |
| Модель программирования | Программирование в модели общей памяти. (POSIX threads, OpenMP). Для SMP-систем существуют сравнительно эффективные средства автоматического распараллеливания. |
Таблица 2.3 – Системы с неоднородным доступом к памяти (NUMA)
| Архитектура | Система состоит из однородных базовых модулей (плат), состоящих из небольшого числа процессоров и блока памяти. Модули объединены с помощью высокоскоростного коммутатора. Поддерживается единое адресное пространство, аппаратно поддерживается доступ к удаленной памяти, т.е. к памяти других модулей. При этом доступ к локальной памяти в несколько раз быстрее, чем к удаленной. В случае, если аппаратно поддерживается когерентность кэшей во всей системе (обычно это так), говорят об архитектуре cc-NUMA (cache-coherent NUMA) |
| Примеры | HP HP 9000 V-class в SCA-конфигурациях, SGI Origin2000, Sun HPC 10000, IBM/Sequent NUMA-Q 2000, SNI RM600. |
| Масштабируемость | Масштабируемость NUMA-систем ограничивается объемом адресного пространства, возможностями аппаратуры поддежки когерентности кэшей и возможностями операционной системы по управлению большим числом процессоров. На настоящий момент, максимальное число процессоров в NUMA-системах составляет 256 (Origin2000). |
| Операционная система | Обычно вся система работает под управлением единой ОС, как в SMP. Но возможны также варианты динамического "подразделения" системы, когда отдельные "разделы" системы работают под управлением разных ОС (например, Windows NT и UNIX в NUMA-Q 2000). |
| Модель программирования | Аналогично SMP. |
Таблица 2.4 – Параллельные векторные системы (PVP)
| Архитектура | Основным признаком PVP-систем является наличие специальных векторно-конвейерных процессоров, в которых предусмотрены команды однотипной обработки векторов независимых данных, эффективно выполняющиеся на конвейерных функциональных устройствах. Как правило, несколько таких процессоров (1-16) работают одновременно над общей памятью (аналогично SMP) в рамках многопроцессорных конфигураций. Несколько таких узлов могут быть объединены с помощью коммутатора (аналогично MPP). | |
| Примеры | NEC SX-4/SX-5, линия векторно-конвейерных компьютеров CRAY: от CRAY-1, CRAY J90/T90, CRAY SV1, CRAY X1, серия Fujitsu VPP. | |
| Модель программирования | Эффективное программирование подразумевает векторизацию циклов (для достижения разумной производительности одного процессора) и их распараллеливание (для одновременной загрузки нескольких процессоров одним приложением). | |
Таблица 2.5 – Кластерные системы
| Архитектура | Набор рабочих станций (или даже ПК) общего назначения, используется в качестве дешевого варианта массивно-параллельного компьютера. Для связи узлов используется одна из стандартных сетевых технологий (Fast/Gigabit Ethernet, Myrinet) на базе шинной архитектуры или коммутатора. При объединении в кластер компьютеров разной мощности или разной архитектуры, говорят о гетерогенных (неоднородных) кластерах. Узлы кластера могут одновременно использоваться в качестве пользовательских рабочих станций. В случае, когда это не нужно, узлы могут быть существенно облегчены и/или установлены в стойку. |
| Примеры | NT-кластер в NCSA, Beowulf-кластеры. |
| Операционная система | Используются стандартные для рабочих станций ОС, чаще всего, свободно распространяемые - Linux/FreeBSD, вместе со специальными средствами поддержки параллельного программирования и распределения нагрузки. |
| Модель программирования | Программирование, как правило, в рамках модели передачи сообщений (чаще всего - MPI). Дешевизна подобных систем оборачивается большими накладными расходами на взаимодействие параллельных процессов между собой, что сильно сужает потенциальный класс решаемых задач. |
Классификация параллельных вычислительных систем, предложенная Т.Джоном, основана на разделении МВС по двум критериям: способу построения памяти (общая или распределенная) и способу передачи информации. Основные типы машин по классификации Т.Джона представлены в таблице 2.6. Здесь приняты следующие обозначения: p - элементарный процессор, M - элемент памяти, K - коммутатор, С - кэш-память.
Параллельная вычислительная система с общей памятью и шинной организацией обмена (машина 1) позволяет каждому процессору системы видеть", как решается задача в целом, а не только те части, над
| Типы передачи Сообщений | Типы памяти | ||
| Общая память | Общая и распределенная | Распределенная память | |
| Шинные соединения | 1.
| 2.
| 3.
|
| Фиксирован-ные перекрест-ные соедине-ния | 4.
| 5.
| 6.
|
| Коммутацион-ные структуры | 7.
| 8.
| 9.
|
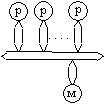



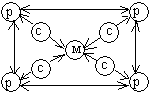


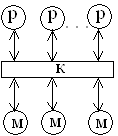

Таблица 2.6 – Классификация МВС по типам памяти и передачи сообщений которыми он работает. Общая шина, связанная с памятью, вызывает серьезные проблемы для обеспечения высокой пропускной способности каналов обмена. Одним из способов обойти эту ситуацию является использование кэш-памяти (машина 2). В этом случае возникает проблема когерентности содержимого кэш-памяти и основной. Другим способом повышения производительности систем является отказ от центральной памяти (машина 3).
Идеальной машиной является вычислительная система, у которой каждый процессор имеет прямые каналы связи с другими процессорами, но в этом случае требуется чрезвычайно большой объем оборудования для организации межпроцессорных обменов. Определенный компромисс представляет сеть с фиксированной топологией, в которой каждый процессор соединен с некоторым подмножеством процессоров системы. Если процессорам, не имеющим непосредственного канала обмена, необходимо взаимодействовать, они передают сообщения через промежуточные процессоры. Одно из преимуществ такого подхода - не ограничивается рост числа процессоров в системе. Недостаток - требуется оптимизация прикладных программ, чтобы обеспечить выполнение параллельных процессов, для которых необходимо активное воздействие на соседние процессоры.
Наиболее интересным вариантом для перспективных параллельных вычислительных комплексов является сочетание достоинства архитектур с распределенной памятью и каналами межпроцессорного обмена. Один из возможных методов построения таких комбинированных архитектур - конфигурация с коммутацией, когда процессор имеет локальную память, а соединяются процессоры между собой с помощью коммутатора (машина 9). Коммутатор может оказаться весьма полезным для группы процессоров с распределяемой памятью (машина 8). Данная конфигурация похожа на машину с общей памятью (машина 7), но здесь исключены проблемы пропускной способности шины.
Недостатками классификации Т.Джона является скрытие уровня параллелизма в системе.
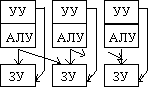
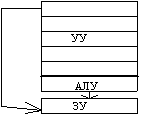
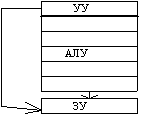
Параллелизм любого рода требует одновременной работы, по крайней мере, двух устройств. Такими устройствами могут быть: арифметико-логические устройства (АЛУ), устройства управления (УУ). В ЭВМ классической архитектуры УУ и АЛУ образуют процессор. Увеличение числа процессоров или числа АЛУ в каждом из них приводит к соответствующему росту параллелизма. Наличие в ЭВМ нескольких процессоров означает, что одновременно (параллельно) могут выполняться несколько программ или несколько фрагментов одной программы. Работа нескольких АЛУ под управлением одного УУ означает, что множество данных может обрабатываться параллельно по одной программе. В соответствии с этим описание структур параллельных систем можно представить в виде упорядоченной тройки:
<k,d,w>,
где k - количество устройств управления, т.е. наибольшее количество независимо и одновременно выполняемых программ в системе;
d - количество АЛУ, приходящихся на одно устройство управления;
w - количество разрядов, содержимое которых обрабатывается одновременно (параллельно) одним арифметико-логическим устройством.
Другая форма распараллеливания - конвейеризация, также требует наличия нескольких ЦП или АЛУ. В то время, как множество данных обрабатывается на одном устройстве, другое множество данных может обрабатываться на следующем устройстве и т.д., при этом в процессе обработки возникает поток данных от одного устройства (ЦП или АЛУ) к следующему. В течение всего процесса над одним множеством данных выполняется одно за другим n действий. Одновременно в конвейере на разных стадиях обработки могут находиться от 1 до n данных.
Параллелизм и конвейеризацию можно рассматривать на трех различных уровнях, представленных в таблице 2.7. Шесть основных форм параллелизма, в широком смысле этого слова, позволяют построить схему классификации, в рамках которой можно описать разнообразие высокопроизводительных вычислительных систем и отразить их эволюцию.
Таблица 2.7 – Классификация МВС по типу распараллеливания
| Уровень параллелизма | Параллелизм | Конвейеризация |
| Программы | Мультипроцессор
| Макроконвейер
|
| Команды | Матричный процессор
| Конвейер команд
|
| Данные | Множество разрядов
| Арифметический конвейер
|


Похожие работы
... в популяциях, которые являются существенными для развития. Точный ответ на вопрос: какие биологические процессы существенны для развития, и какие нет? - все еще открыт для исследователей. Реализация генетических алгоритмов В природе особи в популяции конкурируют друг с другом за различные ресурсы, такие, например, как пища или вода. Кроме того, члены популяции одного вида часто конкурируют ...
... , обусловливающие при её изготовлении и эксплуатации безопасность человека (показатели техники безопасности). Показатели транспортируемости отражают приспособленность конструкции ЭВМ к транспортированию, а также подготовительным и заключительным технологическим операциям, связанным с транспортированием. Экономические показатели характеризуют затраты на проведение научно-исследовательских и ...
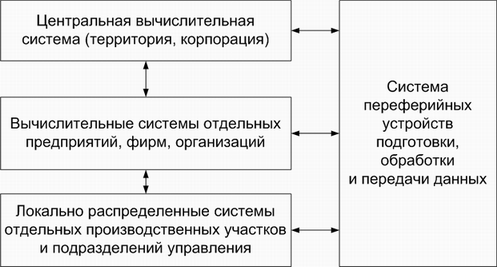
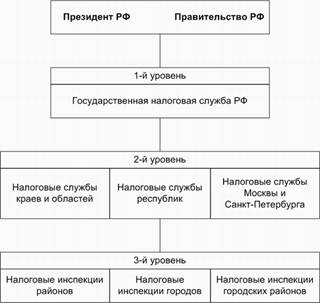
... техникой всех отраслей человеческой деятельности остро ставит вопрос о технологическом обеспечении информационных систем и технологий. Технологическое обеспечение реализует информационные процессы в автоматизированных системах организационного управления с помощью ЭВМ и других технических средств. Разработка технологического обеспечения требует учета особенностей структуры экономических систем. ...
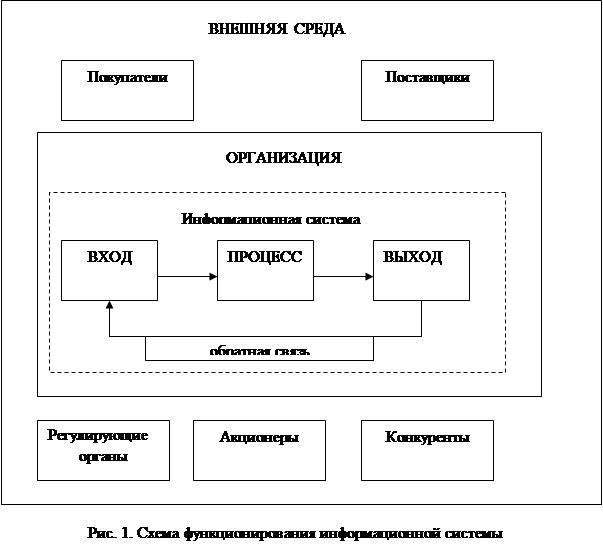
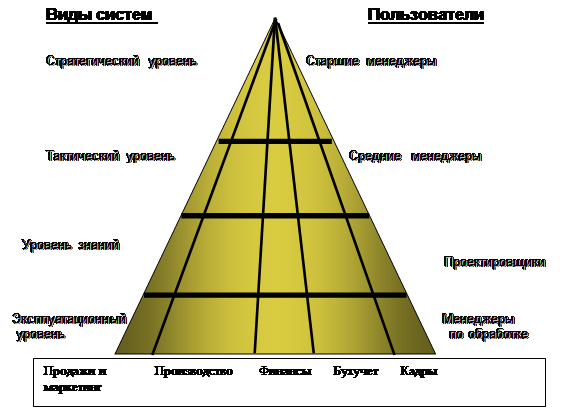
... операционной системы компьютер мертв. ОС загружается при включении компьютера. Прикладное ПО предназначено для решения конкретных задач пользователя и организации вычислительного процесса информационной системы в целом. Прикладное ПО позволяет разрабатывать и выполнять задачи (приложения) пользователя по бухгалтерскому учету, управлению персоналом и т.п. Прикладное программное обеспечение ...
0 комментариев