Навигация
3. Описание операций
3.1 Разработка операции добавления элемента
В данной реализации АТД-список подразумевается (по умолчанию) принцип добавления элемента, тождественный аналогичному в АТД-очередь. Таким образом можно сформулировать инварианты для операции (по умолчанию) добавления элемента в список:
Предусловие: список существует
Постусловие: указатель на хвост указывает на созданный элемент
Так как все операции над структурами данных являются методами дружественного класса, реализующего список, то, очевидно, что операция добавления элемента также является методом этого класса. Следовательно, чтобы выполнить данный метод необходимо создать экземпляр класса List, иными словами, предусловие выполняется всегда.
Следует отметить, что указатели в С++ должны быть инициализированы. Так как список изначально создается пустым, указатели должны быть инициализированы константой NULL. Это операция реализуется в конструкторе по умолчанию класса List:
Таким образом, в результате выполнения операции добавления элемента в список, указатели будут инициализированы корректно.
Логично, что операция инициализации данных в создаваемом элементе следует сразу за созданием узла (записи) списка. Данную операцию удобно не выносить в интерфейс в виде метода, а поручить конструктору по умолчанию класса Node – в данной реализации списка не предусмотрена возможность существования пустых записей:
Процесс связываения узлов отличается в зависимости от того, пуст ли список или нет.
В первом случае сначала необходимо создать голову списка, создав экземпляр класса Node. Поскольку список в данном случае состоит лишь из одного узла, то для выполнения условия связности непустого списка указатель на хвост должен указывать на последний созданный узел – в данном случае на голову. Этот факт и составляет основное отличие между двумя процессами добавления элемента, поскольку в данном случае память выделялаcь для первого элемента, а в остальных случаях – для последнего.
Операция добавления (по умолчанию) элемента в пустой список:

Операция добавления элемента в конец списка:

Макрос assert, определенный в библиотеке cassert проверяет была ли выделена память под узлы корректным образом.
3.2 операциЯ добавления элемента после указанного
Операция добавления элемента после указанного сильно отличается от уже разработанной операции добавления элемента в список и пред-, постусловия предыдущей операций будут неполными в данном контексте. Прежде всего это связано с тем, что вводится решающий фактор существования (или не существования) элемента, указываемого пользователем по имени. В случае несуществования элемента, указанного пользователем, вставка становится невозможной.
К тому же, необходимо сначала найти указанный элемент или выявить признак его отсутствия. Для этой цели необходимо произвести обход списка. Так как список неупорядоченный мы не можем применить бинарный поиск, который значительно более эффективный, чем последовательный – его сложность порядка О(log2n) против О(n), т.е., например, при количестве записей 106, алгоритм бинарного поиска найдет элемент в худшем случае за 19 тактов, в то время как последовательный – за 106 тактов. Основные алгоритмы поиска и сортировки подробно рассмотрены в [3, 4, 5].
Последовательный поиск представляет собой обход списка со сравнением с контрольным ключом (в данном случае именем микросхемы) в каждом узле. Поскольку данный процесс совершенно линейный, удобно реализовать всю функцию рекурсивно. Базовая задача – создание нового узла и его связывание с предыдущим и последующим узлами, шаг рекурсии – сравнение записи с контрольной, условие завершения рекурсии – решение базовой задачи либо завершение обхода.
Предусловия: список существует, указанный элемент существует
Постусловие: новый элемент вставлен после указанного, сохраняя связность списка
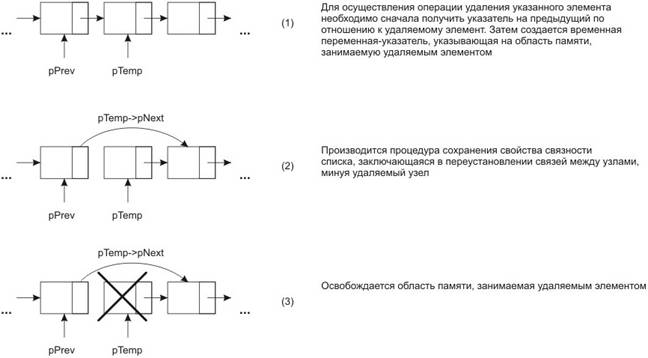
3.3 ОперациЯ удаления указанного элемента
Инварианты для данной операции сходны с аналогичными для предыдущей операции, так как основным процессом является последовательный поиск указанного элемента.
Предусловие: список существует, указанный элемент существует
Постусловие: указанный элемент удален, связность списка сохранена
Очевидно, что для сохранения связности списка необходимо переопределить связи элементов записи таким образом, чтоб миновать в цепочке указанный элемент, но сохранить указатель на удаляемый узел, во избежании утечки памяти. Для этой цели, кроме указателя на удаляемый узел, необходим указатель на предыдущий узел. Обход списка совершается как раз для получения такого указателя.
Очевидно, что операции удаления первого и последнего элементов списка представляют собой отдельные задачи, так как требуют переопределения указателей на голову и хвост списка.
Случай удаления хвоста списка, кроме всего прочего, означает, что указатель на хвост получает значение константы NULL, несмотря на то, что список необязательно пуст. Строго говоря, установка значения указателя на хвост (голову) равным константе NULL является флагом, устанавливающим, признак того, что список пуст. Это приводит к тому, что нарушается механизм, обеспечивающий связность списка, иными словами список перестает существовать.
Во избежании подобной ситуации, носящей для списка, вообще говоря, катастрофический характер, необходимо в теле самой функции, непосредственно в блоке, в котором реализован алгоритм удаления узла, являющегося хвостом списка, предусмотреть операцию установки указателя на хвост.
Для этого достаточно совершить обход списка, начиная с головы до тех пор, пока не будет достигнут хвост.
Для удаления всех элементов с указанным именем, необходимо реализовать цикл, в котором бы выполнялась уже реализованная процедура удаления одного элемента.
В данном случае, нет необходимости совершать обход в этой же функции, тем более, что необходимо не только произвести обход, но и определить, существует ли еще элемент с указанным именем.
Пусть данная функция поиска возвращает ноль, если элемент не найден, единицу, если элемент с указанным именем найден. Данная функция не имеет права модифицировать данные, следовательно, объявляется с ключевым словом const.
Очевидно, что от значения, возвращаемого функцией поиска, зависит, будет ли продолжен последовательный обход списка для удаления элемента.
Таким образом, функция Remove_ предполагает интерфейс для операций удаления вне зависимости от количества удаляемых записей.
Операция удаления первого элемента:

Операция удаления указанного элемента:
3.4 Операция распечатки записей списка
По сути, операция распечатки записей списка представляет собой все тот же последовательный обход списка, начиная с головы списка. Единственным дополнением является тот момент, что при посещении каждого узла, производится вывод на экран данных, хранящихся в каждом конкретном узле (записи).
Обход списка реализован рекурсивно.
4. Реализация АТД-список
4.1 Главная функция
#include <iostream>
#include "iface.h"
#include "code.h"
using namespace std;
int main() {
List aList;
char temp[50];
bool exit = false;
for (;;) {
int choice = menu();
switch(choice) {
case (1):
aList.Insert();
break;
case (2):
cout<<"\nEnter name: "; cin>>temp;
aList.Insert(temp, aList.GetHead());
break;
case (3):
cout<<"\nEnter name: "; cin>>temp;
aList.Remove_(temp);
break;
case (4):
aList.Print(aList.GetHead());
break;
case (5):
exit = true;
break;
default:
cout<<"\n-----Try to enter defined keys!-----\n";
break;
}
if (exit) break;
}
return 0;
}
Похожие работы

водить все действия, что и с обычными переменными. Для работы с динамическим распределением памяти очень удобно использовать связанные структуры данных, например односвязные списки. Простейшим примером списка является массив, в котором последовательно расположены все его элементы. Но у такого представления есть существенный недостаток – требуется заранее точно указать количество элементов ...




... подход к разработке эффективного алгоритма для решения любой задачи – изучить ее сущность. Довольно часто задачу можно сформулировать на языке теории множеств, относящейся к фундаментальным разделам математики. В этом случае алгоритм ее решения можно изложить в терминах основных операций над множествами. К таким задачам относятся и задачи информационного поиска, в которых решаются проблемы, ...
... данных будет нести больше смысла, если его отсортировать каким‑либо образом. Часто требуется сортировать данные несколькими различными способами. Во‑вторых, многие алгоритмы сортировки являются интересными примерами программирования. Они демонстрируют важные методы, такие как частичное упорядочение, рекурсия, слияние списков и хранение двоичных деревьев в массиве. Наконец, сортировка ...
... мощность (заменять процессоры), расширять емкость оперативной памяти, добавлять внешние устройства. Машины имеют большие наборы команд, развитое системное программное обеспечение, включающее трансляторы языков программирования Ассемблер, ФОРТРАН, ПЛ/1, КОБОЛ, АЛГОЛ, ПАСКАЛЬ, операционные системы с различными функциональными возможностями. Основная особенность управляющих вычислительных машин ...
0 комментариев