Навигация
Методи із пророкуваннями
42785
знаков
3
таблицы
8
изображений
2.2 Методи із пророкуваннями
Кардинально інший метод обліку особливостей реальних зображень при кодуванні базується на пророкуваннях1. Кодируемое значення осередку матриці передвіщається на основі інформації про сусідні значення. (Пророкування виступає як функція від цих значень. Як правило, використається середнє значень або їхня лінійна комбінація.) Як об'єкт кодування виступає не саме значення, а різниця між цим значенням і пророкуванням - так називана помилка пророкування. Помилки пророкування розподілені далеко не випадковим образом: маленькі за абсолютним значенням помилки зустрічаються значно частіше більших помилок, а крім того, існує імовірнісна залежність між помилкою й контекстом для оброблюваної позиції.
Тому помилки пророкування можуть бути дуже ефективно закодовані.
Для моделювання помилок застосовна описана вище двомірна контекстно-контекстно-залежна модель. При цьому залишається актуальної проблема одержання адекватних оцінок для дуже великої кількості різних значень. Для її рішення використається підхід, відмінний від описаного раніше. В основі даного підходу припущення про те, що значення помилок пророкування розподілені по деякому параметричному законі, параметри якого споконвічно не відомі, але можуть бути оцінені в процесі кодування. Оцінка всього декількох параметрів дозволяє обчислювати ймовірності появи для фактично необмеженої кількості значень помилок пророкування, що при правильному виборі розподілу гарантує високу ефективність кодування.
Імовірність появи целочисленной помилки ε виходить шляхом інтегрування щільності імовірнісного розподілу ρ(x) в околиці [ε- ½, ε + ½]:
ε+1/2
p(ε) = / ρ(x)dx.
ε-1/2
Як правило, за основу береться розподіл Лапласа, щільність якого обчислюється по формулі
ρ (x) = ~т2 σ 2 exp(-в -2 \x - µ\)).
У розподілі фігурують два невідомих параметри: математичне очікування µ і дисперсія σ. Для одержання їхніх оцінок використається двомірна контекстно-контекстно-залежна модель. Особливість моделювання в цьому випадку полягає в методі розбивки безлічі факторних векторів на підмножини: визначальну роль грають не абсолютні значення, що перебувають на позиціях, близьких до кодируемой, а різниці цих значень (тобто відносні значення).
2.3 Методи прогресивного кодування
З метою спрощення моделювання при формуванні факторного вектора, як правило, використаються тільки ті значення матриці, які перебувають на сусідні (примыкающих) позиціях стосовно кодируемой позиції. Таким чином, у розрахунок не приймаються значення, що перебувають на деякому видаленні. Таке рішення невигідно, тому що між вилученими крапками зображення також можуть існувати залежності, які ніяк не враховуються. Для обліку цих залежностей можна використати методику, при якій зображення кодується в прогресивному режимі: спочатку кодуються крапки зображення, що утворять мережу з деяким досить більшим кроком; потім кодуються ще незакодовані крапки, що належать мережі з меншим кроком, і так далі, доти, поки не будуть закодовані всі крапки зображення (кодування в більшості випадків є контекстно-контекстно-залежним). Одним з переваг описаної методики є можливість відновлення зображення з послідовним поліпшенням його деталізації, що може мати особливу цінність при її використанні в телекомунікаційних додатках1. Один з найбільш удалих методів прогресивного кодування описаний у роботі. До методів прогресивного кодування ставляться також методи, засновані на застосуванні оборотних вейвлет-преобразований. Крім усього іншого, прогресивний режим вносить елемент завадостійкості.
2.4 Квантування
Ефективність ощадливого кодування природного напівтонового зображення (наприклад, фотографічного) методами, описаними в попередньому розділі, у середньому становить трохи битов на одне закодоване значення колірної матриці. Стосовно до синтезованих зображень (такі зображення можуть містити текст, малюнки, графічні об'єкти й т.п.) ефективність виявляється трохи вище й іноді становить менш одного біта на закодоване значення. Однак існують технології кодування, що дозволяють домогтися істотно більшого результату. Висока ефективність досягається за рахунок того, що при кодуванні стають припустимими деякі інформаційні перекручування. Щоб перекручування були як можна менш помітні, їхні характеристики вибираються з урахуванням особливостей психовизуального сприйняття зображення людиною.
Перекручування найчастіше виникають внаслідок квантування значень інформаційної вибірки. Ідея квантування полягає в заміні всіх значень із групи (інтервалу) деяким єдиним значенням. Даний прийом дозволяє зменшити кількість різних значень, що зустрічаються в матриці, що дозволяє кодувати її більш ефективно. Інформаційні перекручування, мабуть, виникають через розбіжність группируемых значень зі значенням, отриманим у процесі їхнього квантування. Повне відновлення інформації стає, таким чином, неможливим.
Розвитком зазначеного підходу є метод у якому групуються не окремі значення, а цілі вектора, складені зі значень, що перебувають на близьких позиціях у матриці. Квантованное значення в даному випадку відповідає деякій безлічі векторів значень. Таке рішення представляє значно більше можливостей для інформаційного опису. Воно зветься векторне квантування, а розглянутий раніше спрощений варіант називається скалярним, квантуванням.
Как неважко помітити, векторне квантування частково виконує функції контекстно-контекстно-залежного моделювання: об'єднання векторів значень, що перебувають на близьких позиціях, дозволяє врахувати можливі імовірнісні взаємозв'язки між ними. Тому векторне квантування, як альтернативний метод обліку інформаційних закономірностей, є предметом для окремого розгляду, і буде залишений за рамками даної роботи. Надалі мова йтиме тільки про ті методи кодування, у яких використається скалярне квантування.
Зупинимося більш докладно на деяких деталях практичної реалізації скалярного квантування. Як ми вже відзначали вище, об'єднання значень у групи повинне вироблятися з урахуванням вимог конкретного завдання. У тих випадках, коли специфіка оброблюваної інформації не дозволяє однозначно вибрати спосіб групування значень, використається найбільш просте рішення - квантуемые значення розбиваються на рівні по довжині інтервали. Даний метод квантування називається рівномірним.
Позначимо через ∆ довжину інтервалу при рівномірному квантуванні {параметр квантування). Сукупність інтервалів представима у вигляді [xо + ∆-i, xо + ∆-(i + 1)). Значення xq належить речовинному інтервалу [—∆/2, ∆/2) і задає базовий зсув інтервалів при квантуванні. i приймає довільні целочисленные значення і являє собою номер інтервалу.
Номер інтервалу виступає в ролі кодируемого об'єкта. У процесі декодування по ньому відновлюється шуканий інтервал значень (деквантование). Тому що конкретні значення відновленню не підлягають, при деквантовании вони заміняються деяким фіксованим числом. Оптимально використати як дане число математичне очікування значень інтервалу. У випадку, коли значення розподілені рівномірно, математичне очікування відповідає середині інтервалу - xо + ∆ • i + ∆/2.
Квантуемая інформаційна вибірка часто представлена числами зі знаком, симетрично розподіленими щодо нуля. Маленькі по абсолютній величині значення звичайно не грають визначальної ролі - їхнє перекручування залишається практично непомітним для нашого сприйняття. У подібних ситуаціях базовий зсув інтервалу xq має сенс вибирати рівним —∆/2. При такому виборі значення в околиці [—∆/2, ∆/2) будуть замінятися нулями (так називана мертва зона). З метою поліпшення схеми квантування розмір мертвої зони збільшують, залишаючи незмінними розміри інших інтервалів. Крім підвищення ефективності це дозволяє спростити процедуру квантування: якщо вибрати розмір мертвої зони рівним 2?, визначення номера інтервалу при квантуванні зведеться до розподілу квантуемого значення на параметр квантування. Дане рішення використається в багатьох практичних додатках, зокрема, у стандартах кодування відеоінформації JPEG, JPEG2000, MPEG, Н.261, Н.263.
Інформаційні перекручування, що виникають у результаті скалярного квантування, звичайно помітно погіршують якість зображення, роблячи його східчастим. В ідеалі перекручування не повинні приводити до істотної зміни основного малюнка, зображення й не повинні вносити в зображення нові, що раніше не існували деталі. Із цієї причини доцільно квантовать не самі значення колірної матриці, а деякі їхні узагальнені характеристики, зміна яких не веде до кардинальної зміни рельєфу зображення. Як показує практика, найбільшою ефективністю володіють методи, у яких як об'єкт квантування виступають параметри двомірних інтерполяційних функцій, використовуваних для наближеного опису зображень.
Застосування інтерполяції саме по собі є ефективним иметодом одержання ощадливих подань інформації. Ефективність залежить від кількості вільних параметрів інтерполяційної функції й від того, наскільки точно ця функція наближає кодируемые дані. На практиці найбільше часто використається особливий різновид інтерполяційного методу - базисне розкладання.
Похожие работы
... ональних інтересів та безпеку інформаційного простору. Підсумки: В цьому розділі ми з’ясували, які саме зміни всередині урядових організацій, в їх структурі, функціях і методах роботи ініціює запровадження електронного уряду. А саме: відбувається перенесення акцентів з вертикальних на горизонтальні зв’язки всередині уряду, між різними його підрозділами і гілками влади. За рахунок створення внутрі ...
... системи, вибираються тип моделі і математичні методи її опису в залежності від мети і роду інформації. Заключний етап складається в створенні моделі і порівнянні її із системою-об'єктом з метою ідентифікації. Структурне моделювання зорової системи Зоровий аналізатор являє собою складну функціональну систему, що містить багато рівнів для переробки зорової інформації, якість роботи якої багато в ...
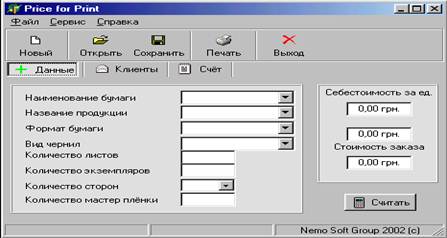
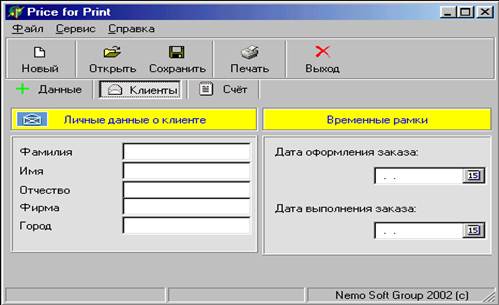
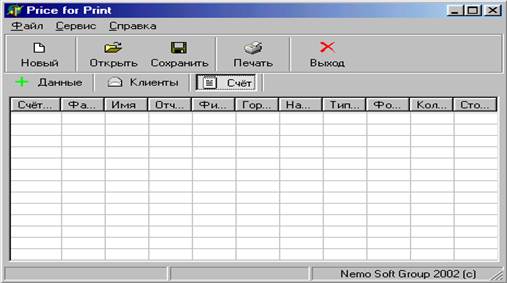
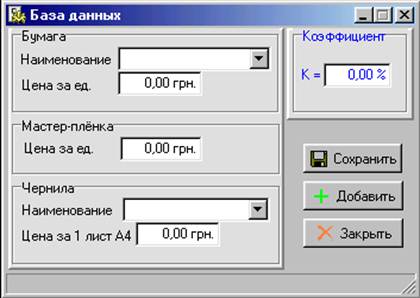
... і організації, у якій її члени отримують стимул в усуненні перепон і досягненні максимальних результатів. У своїй роботі я хочу розглянути автоматизоване робоче місце менеджера як комплексне поняття, що включає в себе такий компонент як: - програмне забезпечення для більш ефективної роботи менеджера. Детальний розгляд цього компонента допомагає глибше розкрити і зрозуміти самий процес організац ...
... 15. Білецька В. Українські сорочки, їх типи, еволюція і орнаментація//Матеріали доетнографії та антропології. 1929. Т. 21—22. Ч. 1. С. 81. 16. Кравчук Л. Т. Вишивка // Нариси історії українського декоративно-прикладного мистецтва. Львів, 1969. С. 62. 17. Добрянська І. О„ Симоненко І. Ф, Типи та колорит західноукраїнської вишивки//Народна творчість та етнографія. 1959. № 2. С. 80. 18. ...
0 комментариев