Навигация
Адресное пространство. Подсистемы ввода-вывода
61662
знака
29
таблиц
63
изображения
Железо Процессоры
Сегментная организация памяти
Виды интерфейсов





Типы процессоров:
1. с регистрами общего назначения (РОН);
2. аккумуляторные;
3. стековые.
Процессоры с РОНЛюбой регистр как операнд может участвовать в любой команде. Работа с операндами осуществляется только через регистры. Среди всех регистров выделяются два:
SP - указатель стека
PC - счетчик команд
Нет команд push и pop, всегда используется mov:
mov (SP)+,R0 вместо pop R0
mov R0,-(SP) вместо push R0
Вместо непосредственной загрузки константы в регистр (mov #5,R0) используется:
mov (PC)+,R0
db 5
PC может использоваться как универсальный регистр во всем множестве команд ЦП. PC используется и при выборке команды и при ее исполнении.
Конвейеризация сильно затруднена.
Недостаток: большой размер команд, т.к. много операндов, много типов адресации.
Можно уменьшить оперативность инструкций и упростить внутреннюю топологию ЦП.
Процессоры аккумуляторного типаПри любой операции один из операндов всегда находится в аккумуляторе и результат всегда помещается в аккумулятор. Непосредственно обратиться к PC и SP уже нельзя, но этого и не требуется.
Процессоры стекового типаУ них стек регистров. Система команд не позволяет непосредственно адресовать регистры. При выполнении операции из вершины стека снимаются операнды и кладется результат.
 |
Имеется стандартный набор команд:
- ADD
- SUB
- MUL
- DIV
- и т.д.
и еще дополнительные (только они работают с операндами в памяти):
- LOAD – помещение данных из памяти в верх стека
- STORE – перемещение данных с верха стека в память
Параметры ЦПРазрядность ЦП – разрядность его регистров.
Во время выполнения инструкции состояние процессора не определено, оно становится строго определенным после завершения выполнения текущей инструкции.
В качестве операндов кроме данных в АЛУ поступают и адреса, следовательно, разрядность ЦП прямо определяет размер адресного пространства.
Архитектуры ЦПСкалярная.

ЦП делится на две секции, каждая из которых независимо тактируется одним тактовым генератором.
Идея: АЛУ не должно простаивать, пока идет выборка команды из памяти.
Выборка инструкции происходит параллельно с работой АЛУ. Для этого используется конвейер.
Суперскалярная.
Несколько АЛУ и каждое занимается своим делом. Добавляется АЛУ для вычисления адресов. Несколько команд могут выполняться одновременно. Возникает проблема, когда команда, стоящая в памяти дальше, выполняется быстрее. Выход – механизм замещения регистров: используются копии регистров для хранения результатов.
Принцип параллельности команд – независимость операндов, т.е. если у команд есть общий операнд – они не параллельны. Если в инструкциях операнды в памяти, то трудно проверить, пересекаются ли они – процессор считает такие команды не параллельными. Процессор оперирует относительными адресами в адресном пространстве процесса, которые дал компилятор и линковщик. Два адреса могут указывать на одно место в физической памяти и два одинаковых адреса – на разные участки физической памяти.
Архитектура RISC.
Запрещает использовать методы адресации во всех инструкциях, кроме load и store. Все мнемонические команды остаются (они необходимы всем ЦП).
add R0,R1 команды почти одинаковы с точки
sub R0,R1 зрения внутренней топологии
add R0,R1 эти сильно
add R0,(R1) отличаются
Запретив команды add R0,(R1) существенно меняем набор команд.
Таким образом, можно максимально сгруппировать команды загрузки из/в память. Еще надо побольше регистров (лучше несколько десятков).
Рост быстродействия RISC колоссален, по сравнению с CISC (если еще использовать кэш для ОП и сгруппировать обращения к ОП вместе).
Адресное пространствоСуществует два типа адресных пространств:
- Логическое АП – этими адресами оперирует ЦП (разрядность ЦП)
- Физическое АП – этот адрес выставляется на шину.
В общем случае ЛА и ФА – разные.
ЦП не может сгенерировать адрес, выходящий за пределы его разрядности. Для памяти нужен ФА большой разрядности.
Возникает две проблемы:
1. Сделать физическую память разрядности больше разрядности ЦП.
2. Если увеличить разрядность ФА, тогда не хватит физической памяти, что делать? (Например, 32-разрядный процессор позволяет каждому процессу иметь ЛАП 4Гб, но где взять столько физической памяти)
Пусть ЛАП < ФАП.
 |
Тогда нужен отдельный базовый регистр для кода – CS. Следовательно, ЦП должен выдавать Устройству Сопряжения с Шиной какой-то признак вместе с операцией, чтобы УСШ знало, какой базовый регистр использовать.
Все операции работы с памятью используют CS, если выбирается код, и DS, если выбираются данные.
 |
Недостатки данной схемы: сегменты могут налезать друг на друга, программа сама заполняет сегментные регистры, следовательно, ей доступна вся память.
Страничное преобразованиеВсе логическое адресное пространство делится на страницы фиксированного размера. Все физическое адресное пространство делится на страницы того же размера.
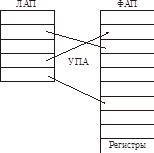
УПА = Устройство Преобразования Адреса. УПА может добавлять к смещению произвольный базовый адрес страницы.

Таблицу страниц можно (и нужно) вынести за пределы ЦП.
В таком случае получаем диспетчер памяти (ДП) вместо УПА.
Сегментная организация памяти

Нужно частично размещать программу в памяти (?) – существуют два метода: страничный и сегментный метод организации памяти.
Вся память делится на сегменты произвольной длины. Каждый сегмент характеризуется базовым адресом и смещением.
Надо выделять физическую память сегменту (половинке – нельзя (?)).
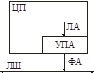
УПА преобразует логический адрес в физический:
В Intel-процессорах имеется набор базовых регистров – CS, DS, SS, ES, GS, FS.
Для идентификации сегментов используются не их логические адреса, а их логические номера.

Дескрипторная таблица (ДТ)
Дескриптор: адресная часть (содержит базовый адрес сегмента в физической памяти) и дескрипторная часть (?) (содержит сведения о защите + длину + бит присутствия).
ДТ находится в оперативной памяти.
При обращении к байту каждый раз производится преобразование адреса + контроль выхода за границу сегмента + права доступа. Т.е., чтобы прочитать байт, нужно два обращения к памяти – так нельзя, нужно кэшировать дескрипторы!
![]()
Дескриптор загружается в скрытую часть сегментного регистра каждый раз, когда в сегментный регистр загружается нами номер сегмента. Далее - проверка выхода и прав доступа. В разных режимах работы ЦП используется один режим адресации. Скрытые части базовых сегментных регистров фактически выполняют функцию кэшей!
Недостатком данного метода является переменная длина сегментов, трудно организовать загрузку/выгрузку сегментов. Возникает фрагментация памяти.
Страничная организация памятиЕсли все блоки (которые меняются) имеют один и тот же размер, исчезает фрагментация 1-го уровня. (Однако есть фрагментация 2-го уровня – блоки одного сегмента «разбегаются» по памяти).
Это и есть механизм страничной организации памяти.
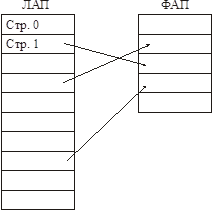
ЛАП и ФАП делится на страницы фиксированного размера.
ТСП (таблица страничного преобразования) – это вектор, содержащий дескрипторы для страниц. Тут должны быть описаны все страницы ЛАП-ва. В дескрипторе страниц есть бит присутствия (есть ли страница в памяти или она на диске).
Если происходит обращение к странице, отсутствующей в памяти происходит страничное прерывание.
Существует два типа исключений: прерывание и ловушка.
В первом случае управление возвращается на ту же инструкцию, которая вызвала исключение (специально для того, чтобы можно было, загрузив недостающую страницу, повторить эту операцию). В другом – управление возвращается на инструкцию, следующую за вызвавшей исключение.

Таблица страниц каждого процесса занимает 4 Мб (?), она должна быть резидентна в памяти – это не допустимо.
Применяется 2-х уровневая система.
Каталог страниц (КС) состоит из одной физической страницы, он обязательно резидентен.
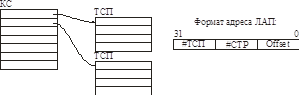
На одну операцию чтения байта потребуется три (!!!) обращения к памяти – Ужас!
Нужен кэш. Кэшируются все данные, с которыми работает ЦП (логическое кэширование не годится, нужно универсальное). Чаще всего происходит обращение к ТСП, они и будут занимать большую часть кэш.
Тогда буфер трансляции адреса (TLB) – используется только для адресных преобразований. А кэш данных – только для кэширования данных (хотя, в некоторых ЦП используется только один кэш – в расчете на то, что в нем в основном будет оседать ТСП).
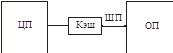
Любое обращение к памяти происходит через кэш.
Кэш никогда не обменивается байтами или словами. Обращаясь к байту, кэш считывает целый блок (например, 128 бит в случае 128-разрядной шины).
Понятие интерфейсаИнтерфейс – это правила перехода границы (т.е. правила, по которым граница может быть пересечена).
Типы интерфейсов:
- Физический интерфейс – правила, описывающие механические характеристики подключения ВУ.
- Электрический интерфейс – определяет величины напряжений, токов и нагрузок, которые должны выполняться при подключении.
- Логический интерфейс – определяет последовательность во времени сигналов (оперирует логическими понятиями 0 и 1, а не вольтами).
- Программный интерфейс – описывает как интерпретировать значения регистров в процессе управления устройством.
Логический интерфейс системной шины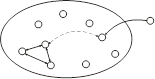
Системная шина нужна для объединения узлов ВС.
Связь между каждыми двумя узлами может быть специализированна для этих двух узлов.
Добавление еще одного узла приводит к нехилому увеличению числа связей.
Жертвуем оптимальностью, так, что сложность связей не зависит от сложности системы. Появляется шинный интерфейс.
Оптимальность этого интерфейса будет логарифмически падать с ростом числа устройств и различием между ними.
Виды интерфейсов
Интерфейс «общая шина» (UNIBUS)

Реализовано в PDP-11 (DEC).
Максимально универсальна.
Этот интерфейс предполагает, что все устройства примерно одинаковы. Вывод идет со скоростью «самого медленного солдата» - все определяется самым медленным устройством.
Шина ISA
ISA (Industry Standard Architecture) – применяется с первых моделей PC.
ISA-8 (8 бит данных и 20 бит адреса) и ISA-16 (16 бит данных и 24 бит адреса).
Частота системной шины – до 8 МГц.
Существует расширение до 32 бит – EISA (совместима, для режима EISA используются специальные управляющие сигналы) – 32 бит адрес и данные, частота до 33 МГц.
Шина PCI
PCI (Peripheral Component Interconnect) – локальная шина, являющаяся мостом между шиной процессора и шиной ввода/вывода ISA/EISA.
Разрядность данных – 32/64 бит. Разрядность адреса – 32 бит. Частота – 33/66 МГц.
Шина является синхронной.
На ее базе существуют расширения (например AGP).
Шина VLB
VLB (VESA Local Bus) – использует шину процессора для подключения периферии (графический адаптер, контроллеры дисков и т.д.).
32-битная шина (32/64 – данные, 32 – адрес), частота колеблется от 33 до 50 МГц.
Шина MassBus
MassBus – высокоскоростная синхронная блочная шина.
Использовалась на VAX-11 (DEC).
В многошинных интерфейсах некоторые узлы выведены из-под управления общей шины.
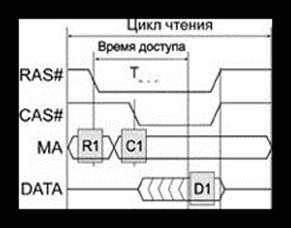
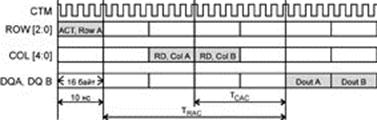
Интерфейс системной шины. Асинхронная шинаИнициатор – ЦП. Взаимодействие происходит с одним устройством.
Любое устройство – дешифратор адреса (ДША). Обладает диапазоном адресов.
Вводится специальный таймаут для проверки существования адреса.
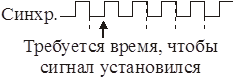
Среагировать на изменение сигнала можно в лучшем случае на следующем такте, т.к. триггеры переключаются не мгновенно.
Синхронная шинаК ней могут подключаться только те устройства, которые соответствуют ее временным характеристикам.
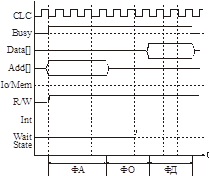
Цикл шины делится на фазы фиксированного времени.
Фаза адреса (ФА): длина – не менее 2-х тактов, чтобы приемники смогли «засечь» адрес.
Фаза ожидания (ФО): пока ВУ не выдает данные на шину. ФО имеет стандартный фиксированный размер.
Все ВУ должны успевать за ФО дешифровать адреса, выбрать данные и т.д. Иначе они не смогут работать с этой шиной.
Фаза данных – на шину выставляются данные.
Но все устройства имеют разное быстродействие. Для этого заводится сигнал wait state (WS). Он устанавливается до фазы данных – в середине ФО. ЦП, получив сигнал WS (медленное устройство), продлевает ФО еще на один такт.
Есть также сигнал High Speed (например, для ОП) – от ФО отнимается один такт.
IO/Mem – определяет, это порт ввода-вывода или адрес памяти.
Высокочастотные шиныИз-за высокой частоты передачи возникают некоторые эффекты, из-за которых могут потеряться данные.
Применяется код Хэмминга:
![]()
Завершающие три бита формируются по восьми.
Похожие работы
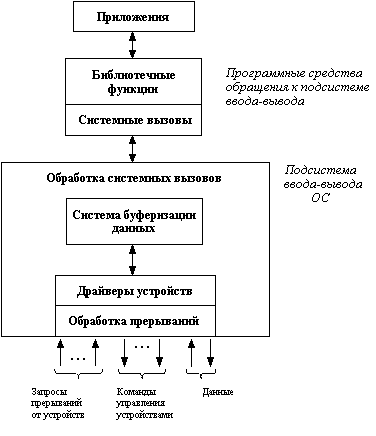
... различными пользователями. Наличие выделенных устройств создает для операционной системы некоторые проблемы. Для решения поставленных проблем целесообразно разделить программное обеспечение ввода-вывода на четыре слоя (рисунок 2.30): Обработка прерываний, Драйверы устройств, Независимый от устройств слой операционной системы, Пользовательский слой программного обеспечения. Рис ...
... производительность 1600 Мбайт/с на двухбайтной шине данных при частоте 400 МГц. Стандарт DRDRAM поддержан множеством производителей микросхем и модулей памяти, он претендует на роль основного высокопроизводительного стандарта для памяти компьютеров любого размера. Подсистема памяти (ОЗУ) DRDRAM состоит из контроллера памяти, канала и собственно микросхем памяти. По сравнению с DDR SDRAM при той ...
... времени суток и дням недели для различных пользователей; блокировка ПЭВМ на время отсутствия пользователя на рабочем месте; контроль и тестирование средств защиты; По требованию Заказчика БАЗОВАЯ СИСТЕМА ВВОДА-ВЫВОДА может быть дополнена программами обслуживания специальных устройств, а также введена поддержка национальных таблиц маркировки клавиатур и кодовых таблиц знакогенератора адаптера ...
... также невысока и обычно составляет около 100 кбайт/с. НКМЛ могут использовать локальные интерфейсы SCSI. Лекция 3. Программное обеспечение ПЭВМ 3.1 Общая характеристика и состав программного обеспечения 3.1.1 Состав и назначение программного обеспечения Процесс взаимодействия человека с компьютером организуется устройством управления в соответствии с той программой, которую пользователь ...
0 комментариев