Навигация
Выполнение статистических расчетов с помощью ЭВМ в системе MINITAB и Exсel
28281
знак
4
таблицы
21
изображение
Министерство образования и науки Украины Севастопольский Национальный технический Университет
Выполнение статистических расчетов с помощью ЭВМ в системе MINITAB и Exсel
Методические указания к выполнению лабораторной работы №1
по дисциплине “Прикладная статистика”
Севастополь
2008 г.
УДК 658.
Ознакомление со статистическим пакетом "Minitab". Методические указания по выполнению лабораторной работы по дисциплине "Прикладная статистика" / Сост. Букач Б.А., Погорелова М.В. - Севастополь: Изд-во СевГТУ, 2008. -20 с.
Целью методического указания является ознакомление с возможностями статистического пакета "Minitab". Методические указания предназначены для студентов экономических специальностей всех форм обучения.
Методические указания содержат описание способов анализа данных в статистическом пакете MINITAB.
Методические указания рассмотрены и утверждены на заседании кафедры МЭМ, (протокол № ____ от “___”____________2008 г.)
Допущено учебно-методическим центром СевГТУ в качестве методических указаний
Рецензент:
Жвава В.Н., к.э.н., доцент кафедры "Бухгалтерский учет"
- нормоконтроль
Цель работы: получение практических навыков работы со статистическим пакетом MINITAB и проведения расчетов в программе MS Exel при расчете и анализе основных статистических показателей.
1. Основные характеристики распределения экономических величин Исходным материалом любого статистического исследования являются совокупность результатов наблюдений. В простейших случаях они представляют собой выборочные (полученные в результате наблюдений) значения некоторой случайной величины X. В задачах статистики распределение этой случайной величины зачастую неизвестно. Пусть есть N наблюдений некоторой величины X (![]() ).Основными статистическими параметрами данной величины являются следующие.
).Основными статистическими параметрами данной величины являются следующие.
1. Среднее значение ![]()
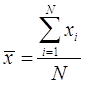
Среднее показывает "центральное положение" (центр) переменной и рассматривается совместно с доверительным интерваломM:\Моя Библиотека\books\Statistika\glossary\gloss_d.html - Confidence Interval. Обычно интерес представляют статистики (например, среднее), дающие информацию о генеральной совокупности в целом. Чем больше размер выборки, тем более надежна оценка среднего. Чем больше изменчивость данных (больше разброс), тем оценка менее надежна.
2. Среднеквадратическое (стандартное) отклонение:
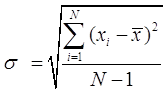
Стандартное отклонение - это широко используемая мера разброса или вариабельности (изменчивости) данных. Среднеквадратическое отклонение показывает средний разброс данных относительно своего среднего значения.
3. Медиана - это значение, которое разбивает выборку на две равные части. Половина наблюдений лежит ниже медианы, и половина наблюдений лежит выше медианы. Медиана вычисляется следующим образом. Изучаемая выборка упорядочивается в порядке возрастания. Получаемая последовательность ak, где k=1,..., 2*m+1называется вариационным рядом или порядковыми статистиками. Если число наблюдений нечетно, то медиана оценивается как: am+1. Если число наблюдений четно, то медиана оценивается как:
| m= | am+am+1 |
| 2 |
4. Усеченное среднее. При расчете среднего значения возможно исключение крайних точек из распределения значений переменной. Например, можно исключить (удалить) 5% наименьших и 5% наибольших значений. Среднее значение, рассчитанное для усеченного таким образом распределения, будет называться "усеченным средним" (этот термин впервые был использован Тьюки в 1962г.).
5. Квартили. Нижняя и верхняя квартили (термин был впервые использован Галтоном, 1882; также их называют квантилями 0.25 и 0.75) равны соответственно 25-й и 75-й процентилям распределения. 25-я процентиль переменной - это такое значение, ниже которого попадают 25% значений переменной. Аналогично, 75-я процентиль - это такое значение, ниже которого попадают 75% значений переменной.
6. Доверительный интервал для среднего задает область вокруг среднего, в которой с заданным уровнем доверия (точностью) содержится "истинное" среднее генеральной совокупности. Например, если среднее в вашей выборке равно 23, а нижняя и верхняя границы для p=.05 равны 19 и 27 соответственно, то вы можете заключить, что с 95% вероятностью среднее выборки больше 19 и меньше 27. Если вы установите меньшее значение p-уровня, то интервал будет шире, и увеличится "уверенность" в оценке, и наоборот; как мы знаем из прогнозов погоды, чем "неопределеннее" прогноз (т.е. шире доверительный интервал), тем скорее он сбудется. Заметим, что ширина доверительного интервала зависит от размера выборки и дисперсии наблюдений. Вычисление доверительных интервалов основывается на предположении, что переменная в совокупности нормально распределена. Эта оценка может быть неверной, если это предположение не выполнено, и пока размер выборки мал, например, n меньше 100.
7. Корреляция Пирсона. Наиболее часто используемый коэффициент корреляции Пирсона r называется также линейной корреляцией, т.к. измеряет степень линейных связей между переменными. Можно сказать, что корреляция определяет степень, с которой значения двух переменных пропорциональны друг другу. Важно, что значение коэффициента корреляции не зависит от масштаба измерения. Например, корреляция между ростом и весом будет одной и той же, независимо от того, проводились измерения в дюймах и фунтах или в сантиметрах и килограммах. Пропорциональность означает просто линейную зависимость. Корреляция высокая, если на графике зависимость можно представить прямой линией (с положительным или отрицательным углом наклона). Проведенная прямая называется прямой регрессии или прямой, построенной методом наименьших квадратов. Последний термин связан с тем, что сумма квадратов расстояний (вычисленная по оси Y) от наблюдаемых точек до прямой является минимальной из всех возможных. Заметим, что использование квадратов расстояний приводит к тому, что на оценки параметров сильно влияют выбросы. Корреляция Пирсона предполагает, что две рассматриваемые переменные измерены, по крайней мере, в интервальной шкале. Коэффициент корреляции Пирсона вычисляется следующим образом:
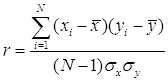
Коэффициент корреляции изменяется в диапазоне от -1 до +1. Чем больше по модулю коэффициент, тем сильнее связь между изучаемыми переменными. Например, между ценой и спросом на товар в случае высокой эластичности спроса будет наблюдаться сильная отрицательная корреляция:
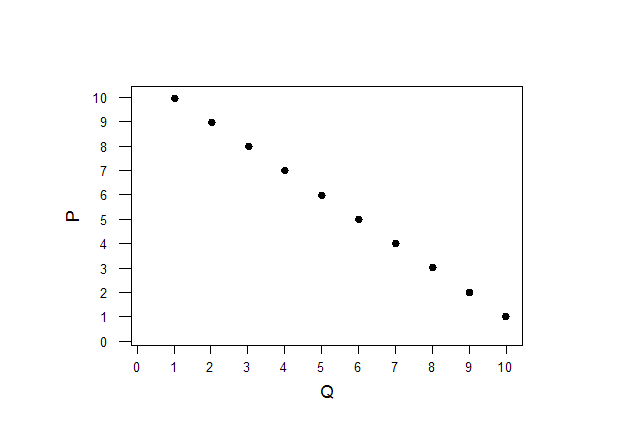
Коэффициент корреляции -1
А между ценой на товар и предложением его на рынке будет наблюдаться сильная корреляция.

Коэффициент корреляции – 1
В случае, если связи между переменными нет, коэффициент корреляции будет стремиться к нулю.
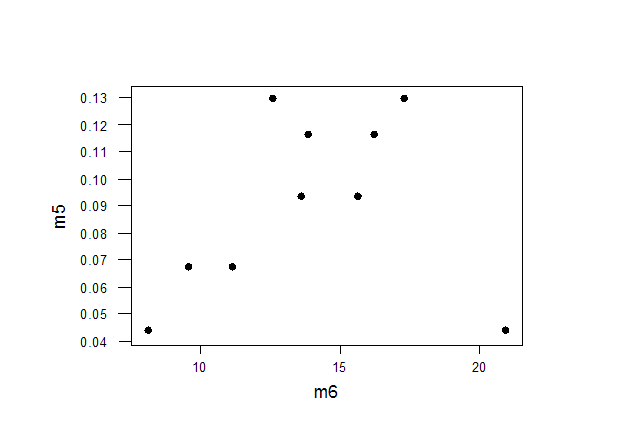
Коэффициент корреляции – 0,22
0 комментариев