Навигация
Раза. В процессе полурасширения узлы каждой пары, более далекие от корня
45769
знаков
0
таблиц
0
изображений
2 раза. В процессе полурасширения узлы каждой пары, более далекие от корня,
включаются в новый путь ( узлы x и z ), а более близкие из него
исключаются ( узлы w и y ).
Сохранение операцией полурасширения лексикографического порядка в деревьях кода
префикса не является обязательным. Единственно важным в операциях с кодом
префикса является точное соответствие дерева, используемого процедурой сжатия
дереву, используемому процедурой развертывания. Любое его изменение, допущенное
между последовательно идущими буквами, производится только в том случае, если
обе процедуры осуществляют одинаковые изменения в одинаковом порядке.
Hенужность поддержки лексикографического порядка значительно упрощает проведение
операции полурасширения за счет исключения случая зигзага. Это может быть
сделано проверкой узлов на пути от корня к целевому листу и переменой местами
правых наследников с их братьями. Назовем это ПОВОРОТОМ дерева. Тепеpь новый код
префикса для целевого листа будет состоять из одних нулей, поскольку он стал
самым левым листом. На рисунке 3 дерево было повернуто вокруг листа C. Эта
операция не нарушает никаких ограничений представления полурасширения.
Второе упрощение возникает, когда мы обнаруживаем, что можем по желанию менять
между собой не только наследников одного узла, но и все внутренние узлы дерева
кодов префиксов, поскольку они анонимны и не несут информации. Это позволяет
заменить используемую в полурасширении операцию обоpота на операцию, требующую
обмена только между двумя звеньями в цепи, которую будем называть ПОЛУОБОРОТОМ.
Она показано на рисунке 4. Эта операция оказывает такое же влияние на длину пути
от каждого листа до корня, как и полный обоpот, но уничтожает лексикографический
порядок, выполняя в нашем примере отсечение и пересадку всего двух ветвей на
дереве, в то время как полный обоpот осуществляет отсечение и пересадку 4
ветвей.
Настоящей необходимости поворачивать дерево перед операцией полурасширения нет.
Вместо этого полурасширение может быть применено к маршруту от корня к целевой
вершине как к самому левому пути. Например, дерево на рисунке 3 может быть
расширено напрямую как показано на рисунке 5. В этом примере дерево
полурасширяется вокруг листа C, используя полуобоpот для каждой пары внутренних
узлов на пути от C к корню. Нужно обратить внимание на то, что в результате этой
перемены каждый лист располагается на одинаковом расстоянии от корня, как если
бы деpево было сначала повернуто так, что C был самым левым листом, а затем
полурасширено обычным путем. Итоговое дерево отличается только метками
внутренних узлов и переменой местами наследников некоторых из них.
Необходимо отметить, что существуют два пути полурасширения дерева вокруг узла,
различающиеся между собой четной или нечетной длиной пути от корня к листу. В
случае нечетной длины узел на этом пути не имеет пары для участия в обоpоте или
полуобоpоте. Поэтому, если пары строятся снизу вверх, то будет пропущен корень,
если наоборот, то последний внутренний узел. Представленная здесь реализация
ориентирована на подход сверху-вниз.
Алгоритм расширяемого префикса.
Представленная здесь программа написана по правилам языка Паскаль с выражениями,
имеющими постоянное значение и подставляемыми в качестве констант для повышения
читаемости программы. Структуры данных, используемые в примере, реализованы на
основе массивов, даже если логическая структура могла быть более ясной при
использовании записей и ссылок. Это соответствует форме представления из ранних
работ по этой же тематике [5,10], а также позволяет осуществлять и простое
решение в более старых, но широко используемых языках, таких как Фортран, и
компактное представление указателей. Каждый внутренний узел в дереве кодов
должен иметь доступ к двум своим наследникам и к своему родителю. Самый простой
способ для этого - использовать для каждого узла 3 указателя: влево, вправо и
вверх. Такое представление, обсуждаемое в [9] было реализовано только при помощи
двух указателей на узел(2), но при этом компактное хранение их в памяти будет
компенсировано возрастанием длительности выполнения программы и запутанностью ее
кода. Нам потребуются следующие основные структуры данных:
const
maxchar = ... { максимальный код символа исходного текста };
succmax = maxchar + 1;
twicemax = 2 * maxchar + 1;
root = 1;
type
codetype = 0..maxchar { кодовый интервал для символов исходного текста };
bit = 0..1;
upindex = 1..maxchar;
downindex = 1..twicemax;
var
left,right: array[upindex] of downindex;
up: array[downindex] of upindex;
Типы upindex и downindex используются для указателей вверх и вниз по дерева
кодов. Указатели вниз должны иметь возможность указывать и на листья, и на
внутренние узлы, в то время как ссылки вверх указывают только на внутренние
узлы. Внутренние узлы будут храниться ниже листьев, поэтому значения индексов
между 1 и maxchar включительно будут применены для обозначения ссылок на
внутренние узлы, когда как значения индексов между maxchar + 1 и 2 * maxchar + 1
включительно - ссылок на листья. Заметим что корень дерева всегда находится в
1-ой ячейке и имеет неопределенного родителя. Cоотвествующая листу буква может
быть найдена вычитанием maxchar + 1 из его индекса.
Если окончание текста источника может быть обнаружено из его контекста, то коды
исходного алфавита все находятся в интервале codetype, а максимально возможное в
этом тексте значение кода будет maxchar. В противном случае, интервал codetype
должен быть расширен на один код для описания специального символа "конец
файла". Это означает, что maxchar будет на 1 больше значения максимального кода
символа исходного текста.
Следующая процедура инициализирует дерево кодов. Здесь строится сбалансированное
дерево кодов, но на самом деле, каждое начальное дерево будет удовлетворительным
до тех пор, пока оно же используется и для сжатия и для развертывания.
procedure initialize;
var
i: downindex;
j: upindex;
begin
for i := 2 to twicemax do
up[i] := i div 2;
for j := 1 to maxchar do begin
left[j] := 2 * j;
right[j] := 2 * j + 1;
end
end { initialize };
После того, как каждая буква сжата ( развернута ) с помощью текущей версии
дерева кодов, оно должно быть расширено вокруг кода этой буквы. Реализация этой
операции показана в следующей процедуре, использующей расширение снизувверх:
procedure splay( plain: codetype );
var
c, d: upindex { пары узлов для полуобоpота };
a, b: downindex { вpащаемые наследники узлов };
begin
a := plain + succmax;
repeat { обход снизу вверх получередуемого дерева }
c := up[a];
if c # root then begin { оставляемая пара }
d := up[c];
{ перемена местами наследников пары }
b := left[d];
if c = b then begin b := right[d];
right[d] := a;
end else left[d] := a;
if a = left[c] then left[c] := b;
else right[c] := b;
up[a] := d;
up[b] := c;
a := d;
end else a := c { управление в конце нечетным узлом };
until a = root;
end { splay };
Чтобы сжать букву исходного текста ее нужно закодировать, используя дерево
кодов, а затем передать. Поскольку процесс кодирования производится при обходе
дерева от листа к корню, то биты кода записываются в обpатном порядке.
Для изменения порядка следования битов процедура compress пpименяет свой стек,
биты из которого достаются по одному и передаются процедуре transmit.
procedure compress( plain: codetype );
var
a: downindex;
sp: 1..succmax;
stack: array[upindex] of bit;
begin
{ кодирование }
a := plain + succmax;
sp := 1;
repeat { обход снизу вверх дерева и помещение в стек битов }
stack[sp] := ord( right[up[a]] = a );
sp := sp + 1;
a := up[a];
until a = root;
repeat { transmit }
sp := sp - 1;
transmit( stack[sp] );
until sp = 1;
splay( plain );
end { compress };
Для развертывания буквы необходимо читать из архива следующие друг за другом
биты с помощью функции receive. Каждый прочитанный бит задает один шаг на
маршруте обхода дерева от корня к листу, определяющем разворачиваемую букву.
function expand: codetype;
var
a: downindex;
begin
a := root;
repeat { один раз для каждого бита на маршруте }
if receive = 0 then a := left[a]
else a := rignt[a];
until a > maxchar;
splay( a - succmax );
expand := a - succmax;
end { expand };
Процедуры, управляющие сжатием и развертыванием, просты и представляют собой
вызов процедуры initialize, за которым следует вызов либо compress, либо expand
для каждой обрабатываемой буквы.
Характеристика алгоритма расширяемого префикса.
На практике, расширяемые деревья, на которых основываются коды префикса, хоть и
не являются оптимальными, но обладают некоторыми полезными качествами. Прежде
всего это скорость выполнения, простой программный код и компактные структуры
данных. Для алгоритма расширяемого префикса требуется только 3 массива, в то
время как для Л-алгоритма Уитерса, вычисляющего оптимальный адаптированный код
префикса, - 11 массивов . Предположим, что для обозначения множества символов
исходного текста используется 8 бит на символ, а конец файла определяется
символом, находящимся вне 8-битового предела, maxchar = 256, и все элементы
массива могут содержать от 9 до 10 битов ( 2 байта на большинстве машин)(3).
Неизменные запросы памяти у алгоритма расширяемого префикса составляют
приблизительно 9.7К битов (2К байтов на большинстве машин). Подобный подход к
хранению массивов в Л-алгоритме требует около 57К битов (10К байтов на
большинстве машин ).
Другие широко применяемые алгоритмы сжатия требуют еще большего пространства,
например, Уэлч советует для реализации метода Зива-Лемпела использовать
хеш-таблицу из 4096 элементов по 20 битов каждый, что в итоге составляет уже82К
битов ( 12К байтов на большинстве машин ). Широко используемая команда сжатия в
системе ЮНИКС Беркли применяет код Зива-Лемпела, основанный на таблице в 64К
элементов по крайней мере в 24 бита каждый, что в итоге дает 1572К битов ( 196К
байтов на большинстве машин ).
В таблице I показано как Л-алгоритм Уиттера и алгоритм расширяющегося префикса
характеризуются на множестве разнообразных тестовых данных. Во всех случаях был
применен алфавит из 256 отдельных символов, расширенный дополнительным знаком
конца файла. Для всех файлов, результат работы Л-алгоритма находится в пределах
5% от H и обычно составляет 2% от H . Результат работы алгоритма расширяющегося
префикса никогда не превышает H больше, чем на 20%, а иногда бывает много меньше
H .
Тестовые данные включают программу на Си (файл 1), две программы на Паскале
(файлы 2 и 3) и произвольный текстовый файл (файл 4). Все текстовые файлы
используют множество символов кода ASCII с табуляцией, заменяющей группы из 8
пробелов в начале, и все пробелы в конце строк. Для всех этих файлов Лалгоритм
достигает результатов, составляющих примерно 60% от размеров исходного текста, а
алгоритм расширения - 70%. Это самый худший случай сжатия, наблюдаемый при
сравнении алгоритмов.
Два объектых файла М68000 были сжаты ( файлы 5 и 6 ) также хорошо, как и файлы
вывода TEX в формате .DVI ( файл 7 ). Они имеют меньшую избыточность, чем
текстовые файлы, и поэтому ни один метод сжатия не может сократить их размер
достаточно эффективно. Тем не менее, обоим алгоритмам удается успешно сжать
данные, причем алгоритм расширения дает результаты, большие результатов работы
Л-алгоритма приблизительно на 10%.
Были сжаты три графических файла, содержащие изображения человеческих лиц (
файлы 8, 9 и 10 ). Они содержат различное число точек и реализованы через 16
оттенков серого цвета, причем каждый хранимый байт описывал 1 графическую точку.
Для этих файлов результат работы Л-алгоритма составлял приблизительно 40% от
первоначального размера файла, когда как алгоритма расширения - только 25% или
60% от H . На первый взгляд это выглядит невозможным, поскольку H есть
теоретический информационный минимум, но алгоритм расширения преодолевает его за
счет использования марковских характеристик источников.
Последние 3 файла были искусственно созданы для изучения класса источников, где
алгоритм расширяемого префикса превосходит ( файлы 11, 12 и 13 ) все остальные.
Все они содержат одинаковое количество каждого из 256 кодов символов, поэтому H
одинакова для всех 3-х файлов и равна длине строки в битах. Файл 11, где полное
множество символов повторяется 64 раза, алгоритм расширения префикса преобразует
незначительно лучше по сравнению с H . В файле 12 множество символов повторяется
Похожие работы
... , а во втором случае — всего лишь номер, то ясно, что чем больше элементарных изображений одинаковы, тем лучше будет сжатие. Изображение, поступающее на вход кодировщика, разделяется на буквы выделением черных компонент связности. Алгоритм рассчитан на то, что элементарными изображениями будут как раз буквы, и действительно, после такого разбиения обычно остаются отдельные буквы, хотя и куски в ...
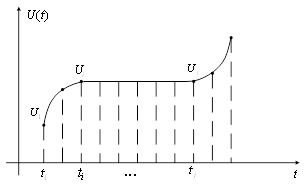

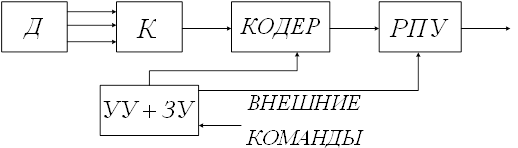
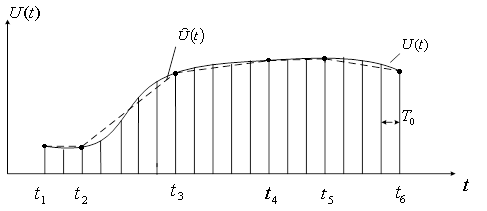
... формула: . ( 10) Сжатие с помощью предсказателя первого порядка требует запоминание последнего существенного отсчета и предсказанного значения отсчета (рисунок 10). Рисунок 10 Согласно экспериментальным данным при сжатии медленно меняющихся параметров предсказатель нулевого порядка дает коэффициент сжатия около 50, а предсказатель первого порядка – 70. Использование полиномов более ...
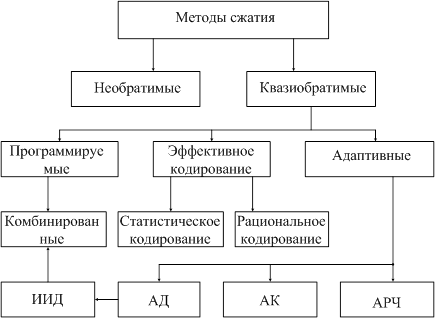
... информации в данных системах. Изучению этого раздела современной радиотехники – основ теории и техники экономного, или безызбыточного, кодирования - и посвящена следующая часть нашего курса. Цель сжатия данных и типы систем сжатия Передача, хранение и обработка информации требуют достаточно больших затрат. И чем с большим количеством информации нам приходится иметь дело, тем дороже это ...




... к сжатым данным ведет к снижению коэффициента сжатия, но с этим ничего нельзя поделать. Листинг программы осуществляющей сжатие данных методом Шеннона приведён в приложении 1. 2.2.Кодирование Хаффмана Алгоритм кодирования Хаффмана очень похож на алгоритм сжатия Шеннона-Фано. Этот алгоритм был изобретен Девидом Хаффманом (David Huffman) в 1952 году ("A method for the Construction of ...
0 комментариев