Навигация
Данные всегда расположены там, где они обрабатываются - следовательно, скорость доступа к ним существенно увеличивается
192976
знаков
8
таблиц
10
изображений
1. Данные всегда расположены там, где они обрабатываются - следовательно, скорость доступа к ним существенно увеличивается.
2. Передача только операций, изменяющих данные (а не всех операций доступа к удаленным данным, как в технологии STAR), и к тому же в асинхронном режиме позволяет значительно уменьшить трафик.
3. Со стороны исходной БД для принимающих БД репликатор выступает как процесс, инициированный одним пользователем, в то время как в физически распределенной среде с каждым локальным сервером работают все пользователи распределенной системы, конкурирующие за ресурсы друг с другом.
4. Никакой продолжительный сбой связи не в состоянии нарушить передачу изменений. Дело в том, что тиражирование предполагает буферизацию потока изменений (транзакций); после восстановления связи передача возобновляется с той транзакции, на которой тиражирование было прервано.
Технология тиражирования данных имеет и недостатки, вытекающие из ее специфики. Например, невозможно полностью исключить конфликты между двумя версиями одной и той же записи. Они могут возникнуть, когда вследствие асинхронности передачи данных два пользователя на разных узлах исправят одну и ту же запись в тот момент, пока изменения в данных из первой базы данных еще не были перенесены во вторую. Следовательно, при проектировании распределенной среды с использованием технологии тиражирования данных необходимо предусмотреть конфликтные ситуации и запрограммировать репликатор на какой-либо вариант их разрешения.
1.4 Взаимодействие с PC-ориентированными СУБДПервоначально профессиональные СУБД создавались для мощных высокопроизводительных платформ - IBM, DEC, Helwett-Packard, Sun. Но затем, учитывая все возрастающую популярность и широкое распространение персональных компьютеров, разработчики приступили к переносу (портированию) СУБД в операционные среды desktop-компьютеров (OS/2, NetWare, UnixWare, SCO UNIX).
В настоящее время большинство компаний - поставщиков СУБД развивает три направления своих систем. Во-первых, совершенствование СУБД для корпоративных информационных систем, которые характеризуются большим числом пользователей (от 100 и выше), базами данных огромного объема (их часто называют сверхбольшими базами данных - Very Large Data Base - VLDB), смешанным характером обработки данных (решение задач оперативной обработки транзакций и поддержки принятия решений) и т.д. Это - традиционная область mainframe-систем и приближающихся к ним по производительности RISC-компьютеров.
Другое направление - СУБД, поддерживающие так называемые рабочие группы. Это направление характеризуется относительно небольшим количеством пользователей с сохранением, тем не менее, всех "многопользовательских" качеств. Системы этого класса ориентированы преимущественно на "офисные" применения, не требующие специальных возможностей. Так, большинство современных многопользовательских СУБД имеют версии системы, функционирующие в сетевой операционной системе Novell NetWare. Ядро СУБД оформлено здесь как загружаемый модуль NetWare (NetWare Loadable Module - NLM), выполняющийся на файловом сервере. База данных также располагается на файловом сервере. SQL-запросы поступают к ядру СУБД от прикладных программ, которые запускаются на станциях сети - персональных компьютерах (отметим, что, несмотря на использование файлового сервера, здесь мы имеем дело с RDA-моделью).
Наконец, новый импульс в развитии получило направление настольных (desktop) версий СУБД, ориентированных на персональное использование - преимущественно в операционной среде MS Windows (системы этого класса получили неформальное определение "light" или "local").
Стремление компаний - поставщиков СУБД иметь фактически по три варианта своих систем, покрывающих весь спектр возможных применений, выглядит для пользователей чрезвычайно привлекательно. Действительно, для специалиста исключительно удобно иметь на своем портативном компьютере локальную базу данных (постоянно используемую во время командировок) в том же формате и обрабатываемую по тем же правилам, что и стационарную корпоративную базу фирмы, куда собранные данные могут быть без труда доставлены.
В последние годы (1987-94) в нашей стране было разработано множество программ, ориентированных на использование СУБД типа PARADOX, FoxPRO, dBASE IV, Clipper. При переходе на более мощную многопользовательскую СУБД у пользователей возникает естественное желание интегрировать уже существующие разработки в эту среду. Например, может возникнуть потребность хранить локальные данные на персональном компьютере и осуществлять к ним доступ с помощью системы FoxPRO, и одновременно иметь доступ к глобальной базе данных под управлением СУБД Oracle. Организация такого доступа, когда программа может одновременно работать и с персональной, и с многопользовательской СУБД, представляет собой сложную проблему по следующей причине.
Как известно, разработчики PC-ориентированных СУБД первоначально использовали свой собственный интерфейс к базам данных, никак не учитывая требования стандарта языка SQL. Лишь впоследствии они стали постепенно включать в свои системы возможности работы с базой данных при помощи SQL. В то же время для истинно многопользовательских СУБД интерфейс SQL - фактический стандарт. При этом возникла задача согласования интерфейсов СУБД различных классов. Она может решаться несколькими способами, но большинство из них имеют частный характер. Рассмотрим наиболее общее решение этой задачи.
Специалисты фирмы Microsoft разработали стандарт Open Database Connectivity (ODBC). Он представляет собой стандарт прикладного программного интерфейса прикладных (Application Programming Interface - API) и позволяет программам, работающим в среде Microsoft Windows, взаимодействовать (посредством операторов языка SQL) с различными СУБД, как персональными, так и многопользовательскими, функционирующими в различных операционных системах. Фактически, интерфейс ODBC универсальным образом отделяет чисто прикладную, содержательную сторону приложений (обработка электронных таблиц, статистический анализ, деловая графика) от собственно обработки и обмена данными с СУБД. Основная цель ODBC - сделать взаимодействие приложения и СУБД прозрачным, не зависящим от класса и особенностей используемой СУБД (мобильным с точки зрения используемой СУБД).
Отметим, что стандарт ODBC является неотъемлемой частью семейства стандартов, облегчающих написание и обеспечивающих вертикальную открытость приложений (WOSA - Windows Open Services Architecture - открытая архитектура сервисов системы Windows).
Интерфейс ODBC обеспечивает взаимную совместимость серверных и клиентских компонентов доступа к данным. Для реализации унифицированного доступа к различным СУБД было введено понятие драйвера ODBC (представляющего собой динамически загружаемую библиотеку).
ODBC-архитектура содержит четыре компонента:
· приложение;
· менеджер драйверов;
· драйверы;
· источники данных.
Роли среди них распределены следующим образом. Приложение вызывает функции ODBC для выполнения SQL-инструкций, получает и интерпретирует результаты; менеджер драйверов загружает ODBC-драйверы, когда этого требует приложение; ODBC-драйверы обрабатывают вызовы функций ODBC, передают операторы SQL СУБД и возвращают результат в приложение; источник данных (data source) - объект, скрывающий СУБД, детали сетевого интерфейса, расположение и полное имя базы данных и т.д.
Действия, выполняемые приложением, использующим интерфейс ODBC, сводятся к следующему. Для начала сеанса работы с базой данных приложение должно подключиться к источнику данных, ее скрывающему. Затем приложение обращается к базе данных, посылая SQL-инструкции, запрашивает результаты, отслеживает и реагирует на ошибки и т.д., то есть имеет место стандартная схема взаимодействия приложения и сервера БД, характерная для RDA-модели. Важно, что стандарт ODBC включает функции управления транзакциями (начало, фиксация, откат транзакции). Завершив сеанс работы, приложение должно отключиться от источника данных.
Слой доступа к данным, подобный ODBC использует в своих продуктах компания Borland. Эта система носит название Borland Database Engine (BDE) и имеет некоторые преимущества по сравнению с ODBC.
1.5 Обработка транзакцийТранзакция представляет собой последовательность операторов языка SQL, которая рассматривается как некоторое неделимое действие над базой данных, осмысленное с точки зрения пользователя. В то же время, это логическая единица работы системы. Транзакция реализует некоторую прикладную функцию, например, перевод денег с одного счета на другой в банковской системе.
Существуют различные модели транзакций, которые могут быть классифицированы на основании различных свойств, включающих структуру транзакции, параллельность внутри транзакции, продолжительность и т.д. Чаще всего имеют в виду традиционные транзакции, характеризуемые четырьмя классическими свойствами: атомарности, согласованности, изолированности, долговечности (прочности) - ACID (Atomicity, Consistency, Isolation, Durability). Иногда традиционные транзакции называют ACID-транзакциями. Упомянутые выше свойства означают следующее:
1. Свойство атомарности выражается в том, что транзакция должна быть выполнена в целом или не выполнена вовсе.
2. Свойство согласованности гарантирует, что по мере выполнения транзакций данные переходят из одного согласованного состояния в другое - транзакция не разрушает взаимной согласованности данных.
3. Свойство изолированности означает, что конкурирующие за доступ к базе данных транзакции физически обрабатываются последовательно, изолированно друг от друга, но для пользователей это выглядит так, как будто они выполняются параллельно.
4. Свойство долговечности трактуется следующим образом: если транзакция завершена успешно, то те изменения в данных, которые были ею произведены, не могут быть потеряны ни при каких обстоятельствах (даже в случае последующих ошибок).
Расширенные транзакции допускают формирование из ACID-транзакций иерархических структур. Если конкретная модель ослабляет некоторые из требований ACID, то речь идет об ослабленной транзакции.
Возможны два варианта завершения транзакции. Если все операторы выполнены успешно, и в процессе выполнения транзакции не произошло никаких сбоев программного или аппаратного обеспечения, транзакция фиксируется.
Фиксация транзакции - это действие, обеспечивающее запись на диск изменений в базе данных, которые были сделаны в процессе выполнения транзакции. До тех пор, пока транзакция не зафиксирована, возможно аннулирование этих изменений, восстановление базы данных в то состояние, в котором она была на момент начала транзакции. Фиксация означает, что все результаты выполнения транзакции становятся постоянными. Они станут видимыми другим транзакциям только после того, как текущая транзакция будет зафиксирована. До этого момента все данные, затрагиваемые транзакцией, будут "видны" пользователю в состоянии на начало текущей транзакции.
Если в процессе выполнения транзакции произошла ошибка, база данных должна быть возвращена в исходное состояние. Откат транзакции - это действие, обеспечивающее аннулирование всех изменений данных, которые были сделаны операторами SQL в теле текущей незавершенной транзакции.
Каждый оператор в транзакции выполняет свою часть работы, но для успешного завершения всей работы в целом требуется безусловное завершение их всех. Группирование операторов в транзакции сообщает СУБД, что вся эта группа должна быть выполнена как единое целое, причем такое выполнение должно поддерживаться автоматически.
В стандарте ANSI/ISO SQL определены модель транзакций и функции операторов COMMIT и ROLLBACK. Стандарт определяет, что транзакция начинается с первого SQL-оператора, инициируемого пользователем или содержащегося в программе. Все последующие SQL-операторы составляют тело транзакции. Транзакция завершается одним из четырех возможных способов:
· оператор COMMIT означает успешное завершение транзакции; его использование делает постоянными изменения, внесенные в базу данных в рамках текущей транзакции;
· оператор ROLLBACK прерывает транзакцию, отменяя изменения, сделанные в базе данных в рамках этой транзакции; новая транзакция начинается непосредственно после использования ROLLBACK;
· успешное завершение программы, в которой была инициирована текущая транзакция, означает успешное завершение транзакции (как будто был использован оператор COMMIT);
· ошибочное завершение программы прерывает транзакцию (как будто был использован оператор ROLLBACK).
Откат и фиксация транзакций становятся возможными благодаря журналу транзакций. Он используется следующим образом.
Известно, что все операции над реляционной базой данных - это операции над строками таблиц. Следовательно, для обеспечения отката таблиц к предыдущим состояниям достаточно хранить не состояния всей таблицы, а лишь те ее строки, которые подверглись изменениям.
При выполнении любого оператора SQL, который модифицирует базу данных, СУБД автоматически заносит очередную запись в журнал транзакций. Запись состоит из двух компонентов: первый - это состояние строки до внесения изменений, второй - ее же состояние после внесения изменений. Только после занесения записи в журнал транзакций (идеология «write ahead log»), СУБД действительно модифицирует базу данных. Если после данного оператора SQL был выполнен оператор COMMIT, то в журнале транзакций делается отметка о завершении текущей транзакции. Если же после оператора SQL следовал оператор ROLLBACK, то СУБД просматривает журнал транзакций и отыскивает записи, отражающие состояние измененных строк до модификации. Используя их, СУБД восстанавливает те строки в таблицах базы данных, которые были модифицированы текущей транзакцией - таким образом аннулируются все изменения в базе данных.
Важные проблемы многопользовательских СУБД связаны с организацией с помощью механизма транзакций одновременного доступа множества пользователей к одним и тем же данным. Они кратко могут быть сформулированы как потеря изменений, незафиксированные изменения и ряд других, более сложных проблем.
Потеря изменений происходит в ситуации, когда две или несколько программ читают одни и те же данные, вносят в них какие-либо изменения и затем пытаются одновременно записать результат по прежнему месту. Разумеется, в базе данных могут быть сохранены изменения, выполненные только одной программой - другие изменения будут потеряны.
Проблема незафиксированных изменений возникает в случае, когда в процессе выполнения транзакции одной программой в данные были внесены изменения, которые тут же прочитала другая программа, однако затем в первой программе транзакция была прервана оператором ROLLBACK. Получается, что вторая программа прочитала неверные, незафиксированные данные.
Для устранения подобных проблем применяются следующие правила:
1. В процессе выполнения транзакции пользователь (или программа) "видит" только согласованные состояния базы данных. Пользователь (или программа) никогда не может получить доступ к незафиксированным изменениям в данных, достигнутым в результате действий другого пользователя (программы).
2. Если две транзакции, A и B, выполняются параллельно, то СУБД полагает, что результат будет такой же, как если бы:
· транзакция A выполнялась первой, а за ней была выполнена транзакция B;
· транзакция B выполнялась первой, а за ней была выполнена транзакция A.
Это так называемая сериализация транзакций. Фактически она гарантирует, что каждый пользователь (программа), обращающаяся к базе данных, работает с ней так, как будто не существует других пользователей (программ), одновременно с ним обращающихся к тем же данным. Для практической реализации этой дисциплины большинство коммерческих СУБД используют механизм блокировок.
Транзакции могут попасть в тупиковую ситуацию, состояние неразрешимой взаимоблокировки. Для её предотвращения СУБД периодически проверяет блокировки, установленные активными транзакциями. Если СУБД обнаруживает взаимоблокировки, она выбирает одну из транзакций, вызвавшую ситуацию взаимоблокировки, и прерывает ее. Это освобождает данные для внесения изменений конкурирующей транзакцией, разрешая тупиковую ситуацию. Программа, которая инициировала прерванную транзакцию, получает сообщение об ошибке, информирующее ее о причине прерывания (имела место тупиковая ситуация). Избежать их может и правильная стратегия внесения изменений в базу данных. Одним из наиболее простых и эффективных правил может быть следующее: все программы, которые обновляют одни и те же таблицы, должны, по мере возможности, делать это в одинаковой последовательности.
В современных СУБД предусмотрен так называемый протокол двухфазовой (или двухфазной) фиксации транзакций (two-phase commit). Фаза 1 начинается, когда при обработке транзакции встретился оператор COMMIT. Сервер распределенной БД (или компонент СУБД, отвечающий за обработку распределенных транзакций) направляет уведомление "подготовиться к фиксации" всем серверам локальных БД, выполняющим распределенную транзакцию. Если все серверы приготовились к фиксации (то есть откликнулись на уведомление и отклик был получен), сервер распределенной БД принимает решение о фиксации. Серверы локальных БД остаются в состоянии готовности и ожидают от него команды "зафиксировать". Если хотя бы один из серверов не откликнулся на уведомление в силу каких-либо причин, будь то аппаратная или программная ошибка, то сервер распределенной БД откатывает локальные транзакции на всех узлах, включая даже те, которые подготовились к фиксации и оповестили его об этом.
Фаза 2 - сервер распределенной БД направляет команду "зафиксировать" всем узлам, затронутым транзакцией, и гарантирует, что транзакции на них будут зафиксированы. Если связь с локальной базой данных потеряна в интервал времени между моментом, когда сервер распределенной БД принимает решение о фиксации транзакции и моментом, когда сервер локальной БД подчиняется его команде, то сервер распределенной БД продолжает попытки завершить транзакцию, пока связь не будет восстановлена.
1.6 Средства защиты данных в СУБДСущественным аспектом современных СУБД является защита данных. В самом общем виде требования к безопасности реляционных СУБД формулируются так:
· данные в любой таблице должны быть доступны не всем пользователям, а лишь некоторым из них
· некоторым пользователям должно быть разрешено обновлять данные в таблицах, в то время как для других допускается лишь выбор данных из этих же таблиц
· для некоторых таблиц необходимо обеспечить выборочный доступ к ее столбцам
· некоторым пользователям должен быть запрещен непосредственный (через запросы) доступ к таблицам, но разрешен доступ к этим же таблицам в диалоге с прикладной программой.
Схема доступа к данным во всех реляционных СУБД выглядит примерно одинаково и базируется на трех принципах:
· Пользователи СУБД рассматриваются как основные действующие лица, желающие получить доступ к данным. СУБД от имени конкретного пользователя выполняет операции над базой данных, то есть добавляет строки в таблицы (INSERT), удаляет строки (DELETE), обновляет данные в строках таблицы (UPDATE). Она делает это в зависимости от того, обладает ли конкретный пользователь правами на выполнение конкретных операций над конкретным объектом базы данных.
· Объекты доступа - это элементы базы данных, доступом к которым можно управлять (разрешать доступ или защищать от доступа). Обычно объектами доступа являются таблицы, однако ими могут быть и другие объекты базы данных - формы, отчеты, прикладные программы и т.д. Конкретный пользователь обладает конкретными правами доступа к конкретному объекту.
· Привилегии (priveleges) - это операции, которые разрешено выполнять пользователю над конкретными объектами.
Таким образом, в СУБД авторизация доступа осуществляется с помощью привилегий. Установление и контроль привилегий - задача администратора базы данных.
Привилегии устанавливаются и отменяются специальными операторами языка SQL - GRANT (ПЕРЕДАТЬ) и REVOKE (ОТОБРАТЬ). Оператор GRANT указывает конкретного пользователя, который получает конкретные привилегии доступа к указанной таблице.
Конкретный пользователь СУБД опознается по уникальному идентификатору (user-id). Любое действие над базой данных, любой оператор языка SQL выполняется не анонимно, но от имени конкретного пользователя. Идентификатор пользователя определяет набор доступных объектов базы данных для конкретного физического лица или группы лиц. Однако он ничего не сообщает о механизме его связи с конкретным оператором SQL. Для этого в большинстве СУБД используется сеанс работы с базой данных. Для запуска на компьютере-клиенте программы переднего плана (например, интерактивного SQL) пользователь должен сообщить СУБД свой идентификатор и пароль. Все операции над базой данных, которые будут выполнены после этого, СУБД свяжет с конкретным пользователем, который запустил программу.
Некоторые СУБД (Oracle, Sybase, InterBase) используют собственную систему паролей, в других (Ingres, Informix, MS SQL Server) применяется идентификатор пользователя и его пароль из операционной системы.
Для облегчения процесса администрирования большого количества пользователей их объединяют в группы. Традиционно применяются два способа определения групп пользователей:
1. Один и тот же идентификатор используется для доступа к базе данных целой группы физических лиц. Это упрощает задачу администратора базы данных, так как достаточно один раз установить привилегии для этого "обобщенного" пользователя. Однако такой способ в основном предполагает разрешение на просмотр, быть может, на включение, но ни в коем случае - на удаление и обновление. Как только идентификатор (и пароль) становится известен большому числу людей, возникает опасность несанкционированного доступа к данным посторонних лиц.
2. Конкретному физическому лицу присваивается уникальный идентификатор. В этом случае администратор базы данных должен позаботиться о том, чтобы каждый пользователь получил собственные привилегии. Если количество пользователей базы данных возрастает, то администратору становится все труднее контролировать привилегии. В организации, насчитывающей свыше 100 пользователей, решение этой задачи потребует от него массу внимания.
3. Поддержка, помимо идентификатора пользователя, еще и идентификатора группы пользователей. Каждый пользователь, кроме собственного идентификатора, имеет также идентификатор группы, к которой он принадлежит. Чаще всего группа пользователей соответствует структурному подразделению организации, например, отделу. Привилегии устанавливаются не только для отдельных пользователей, но и для их групп.
Одна из проблем защиты данных возникает по той причине, что с базой данных работают как прикладные программы, так и пользователи, которые их запускают. Часто необходимость запуска некоторых прикладных программ пользователями, которые обладают различными правами доступа к данным, приводит к нарушению схемы безопасности.
Одно из решений проблемы заключается в том, чтобы прикладной программе также были приданы некоторые привилегии доступа к объектам базы данных. В этом случае пользователь, не обладающий специальными привилегиями доступа к некоторым объектам базы данных, может запустить прикладную программу, которая имеет такие привилегии.
В СУБД Ingres и Oracle это решение обеспечивается механизмом ролей (role). Роль представляет собой именованный объект, хранящийся в базе данных. Роль связывается с конкретной прикладной программой для придания последней привилегий доступа к базам данных, таблицам, представлениям и процедурам базы данных. Роль создается и удаляется администратором базы данных, ей может быть придан определенный пароль. Как только роль создана, ей можно предоставить привилегии доступа к объектам базы данных.
Современные информационные системы обеспечивают также другую схему безопасности - обязательный или принудительный контроль доступа (mandatory access control). Он основан на отказе от понятия владельца данных и опирается на так называемые метки безопасности (security labels), которые присваиваются данным при их создании. Каждая из меток соответствует некоторому уровню безопасности. Метки служат для классификации данных по уровням.
Так как данные расклассифицированы по уровням безопасности метками, конкретный пользователь получает ограниченный доступ к данным. Он может оперировать только с данными, расположенными на том уровне секретности, который соответствует его статусу. При этом он не является владельцем данных.
Эта схема безопасности опирается на механизм, позволяющий связать метки безопасности с каждой строкой любой таблицы в базе данных. Любой пользователь может потребовать в своем запросе отобразить любую таблицу из базы данных, однако увидит он только те строки, у которых метки безопасности не превышают уровень его компетенции.
Это означает, например, что строки таблицы, отмеченные как строки уровня максимальной безопасности, может увидеть только тот пользователь, у которого уровень безопасности - наивысший. Пользователи определенного уровня секретности могут видеть строки таблицы, отмеченные для их уровня безопасности, равно как и для всех уровней ниже данного. СУБД проверяет уровень безопасности пользователя и, в ответ на его запрос, возвращает только те строки таблицы, которые удовлетворяют запросу и соответствуют этому уровню.
По оценкам экспертов, концепция многоуровневой безопасности в ближайшие годы будет использована в большинстве коммерческих СУБД.
1.7 Применение CASE-средств для информационного моделирования в системах обработки данных .В условиях рынка все большее число компаний осознают преимущества использования информационных систем (ИС). Чтобы получить выгоду от использования информационной системы, ее следует создавать в короткие сроки и с уменьшенными затратами. Кроме того, информационная система должна быть легко сопровождаемой и управляемой.
Создание информационной системы предприятия - сложный и многоступенчатый процесс, который содержит фазу информационного моделирования. Информационная модель - это спецификация структуры данных и бизнес правил (правил предметной области). Для построения информационной модели предприятия используют так называемые CASE-средства.
Computer Aided Software Engineering (CASE) - это технология автоматизированного проектирования информационных систем, позволяющая значительно ускорить процесс их разработки, сократить затраты труда, а также повысить качество проектирования.
Под этим следует понимать совокупность методов и средств, применяемых в программной инженерии.
Основное отличие методов программной инженерии от непосредственного программирования, во-первых, то, что программная инженерия отделяет анализ и проектирование от программирования (кодирования) как такового. Во-вторых, программная инженерия выделяет в общем ходе разработки различные типы деятельности, выполняемые на различных фазах жизненного цикла.
Стандартный подход выделяет в жизненном цикле программной разработки несколько этапов:
· анализ;
· проектирование;
· программирование;
· тестирование;
· сопровождение.
Первоначально считалось, что эти этапы проходят последовательно. В настоящее время принята модель так называемой быстрой прототипизации, в которой возвраты к началу основной последовательности происходят регулярно, с каждым циклом проектирования. Другими словами требуется одновременное выполнение всех задач всех фаз жизненного цикла, что не отменяет разделение действий в соответствии с фазами процесса проектирования.
Такое возможно только с использованием CASE-средств.
На этапах анализа и проектирования принимаются решения, которые оказывают решающее влияние на конечный продукт. Поэтому обычно CASE-средства применяют прежде всего на этих этапах.
Основной частью этапа проектирования является построение информационной модели объекта. При разработке прикладной системы по схеме “сверху - вниз”, информационная модель постепенно дополняется и детализируется.
На завершающий стадии этапа проектирования на основе информационной модели выполняется генерация объектов БД: таблиц, индексов, ключей последовательностей и т.д.
2. Реализация распределенной базы данных с удаленным доступом
В качестве примера реализации распределенной базы данных рассмотрим информационную систему для автоматизации расчетов с абонентами АО «Связьинформ» РМ.
В данной организации возникает задача учета финансовых поступлений за оказанные услуги связи. Сейчас для ее выполнения используется программный комплекс «Парус», который реализует часть необходимых функций. В последнее время возникла задача повременной тарификации и учета проведенных телефонных разговоров, что приводит к резкому увеличению объемов данных, циркулирующих в системе. Кроме того, для выработки политики тарификации услуг связи необходимо анализировать объем и структуру начислений, что требует постоянного хранения данных об оказанных услугах. С увеличением потока информации необходимо увеличить число операторских мест для занесения данных, следовательно система должна хорошо работать в многопользовательской среде. Программа «Парус» построена по идеологии настольных систем и поэтому её перенос в сетевую среду возможен только по архитектуре файл-сервера. Такой подход отличается плохой масштабируемостью и делает практически невозможной работу удаленных пользователей, Существующая система не может обрабатывать накапливаемый объем данных, поэтому возникает необходимость создания новой системы обработки информации, построенной по идеологии клиент-сервер.
Основные требования к системе таковы:
* система автоматизации расчетов с абонентами должна обрабатывать данные по имеющимся клиентам;
* система должна учитывать начисления по оказанным услугам;
* система должна учитывать оплату, поступившую с клиента за оказанные услуги;
* система должна иметь механизм регистрации изменений и возможность отката к одному из предыдущих состояний;
* система должна обеспечивать возможность оперативного доступа к информации;
* система должна иметь развитые механизмы обеспечения информационной безопасности (защита от несанкционированного доступа, избыточность хранения информации).
2.1 Анализ существующей системыДля определения потребностей в построении системы расчета с абонентами и определения её структуры проведем анализ уже существующей схемы обмена данными.
Схема функционирования организации в первом приближении такова:
1. АО «Связьинформ» оказывает своим клиентам услуги в области связи.
2. Клиенты оплачивают оказанные услуги.
Ошибка! Ошибка связи.
Рис.2.1. Схема функционирования в первом приближении.
Внутренняя структура предприятия в самом общем виде может быть представлена следующим образом:
1. Имеется центральное отделение (управление связи), которое осуществляет контроль за деятельностью всего предприятия.
2. В каждом районе Республики Мордовия функционируют районные узлы связи (РУС) или эксплуатационно-технические узлы связи (ЭТУС), которые напрямую подчиняются управлению связи.
3. Существуют филиалы АО «Связьинформ», такие как ГТС, МТС, СТС и т.д.
4. Каждое из подразделений направляет в управлений связи ежемесячные отчеты.
Существующая система обмена информацией и её хранения такова:
1. Расчет за услуги связи каждый клиент проводит с РУС или ЭТУС по месту установки телефона.
2. В каждом из РУС или ЭТУС установлен персональный компьютер, на котором функционирует программный комплекс «Парус». В конце каждого месяца проводится расчет за услуги связи, в соответствие с которым выставляются счета клиентам.
3. Отчеты по проведенным расчетам пересылаются по электронной почте в управление связи.
Недостатки этой схемы проявляются в отсутствии оперативного доступа к информации по предоставленным услугам и поступившим средствам, низкой нагрузочной способности системы, невозможности анализа данных за достаточно длительный промежуток времени.
2.2 Новая схема обмена информациейУчитывая перечисленные недостатки возникла необходимость организации единого информационного пространства для решения поставленных задач. Суть решения в следующем:
1. Провести установку в каждом из РУС или ЭТУС серверов для обработки и хранения данных по отдельно взятому району.
2. В управлении связи установить сервер, который будет хранить данные расчетов с абонентами по всей республике Мордовия.
3. Наладить каналы связи между районными узлами и управлением.
4. Построить распределенную базу данных по расчетам за услуги связи по всей Мордовии.
5. Разместить полученную базу на районных серверах с репликацией данных на сервер управления связи.
6. Для тех районов, установка в которых выделенных серверов экономически нецелесообразна, обеспечить удаленный доступ к базам данных других районов.

Рис. 2.2. Идеология информационной системы расчетов с абонентами.
Данная схема обладает следующими достоинствами по сравнению с предыдущей:
1. За счет использования выделенных серверов резко возрастает нагрузочная способность системы.
2. Из-за использования технологии клиент-сервер снижается трафик в каналах связи, что позволяет получить оперативный доступ к информации, находящейся на удаленном сервере.
3. Появляется возможность централизованного администрирования полученной системы.
4. Возможно гибкое распределение прав пользователей на доступ к данным.
5. За счет реализации принципа избыточности при хранении данных повышается надежность хранения. (В любой момент времени в системе существует две копии данных: одна на сервере управления связи, другая распределена между районными серверами).
6. Возможно практически неограниченное масштабирование системы.
2.3 Выбор операционной системыВ данное время на рынке операционных систем широко представлены несколько продуктов:
· UNIX-системы
· Системы семейства Novell NetWare
· Системы на основе Windows NT
К достоинствам систем UNIX (Solaris, AIX, Linux, BSD UNIX, UNIX System V) относится вытесняющая многозадачность, стабильность, высокая производительность, поддержка мультипроцессорных систем и систем с массовым параллелизмом. Эти системы представлены на рынке очень давно, что позволяет говорить об их надежности. К их недостаткам относится высокая стоимость программного и аппаратного обеспечения (большинство систем функционируют на RISC платформах). Кроме того, системы на базе UNIX сложны в администрировании и слабо стандартизованы, что затрудняет построение на их основе интегрированных решений.
Системы на основе Novell NetWare построены на основе корпоративной многозадачности, что делает практически невозможным их применение в качестве серверов приложений и баз данных. Длительная транзакция со стороны одного из клиентов сервера Novell NetWare приводит к невозможности доступа других клиентов к ресурсам сервера. Все процессы на сервере выполняются в нулевом кольце защиты процессора, таким образом ошибка в одном из них с большой вероятностью приводит к краху всей системы вплоть до потери файлов. Это приводит к невозможности выполнения пользовательских процессов на сервере. В настоящее время системы на базе Novell NetWare используются в большинстве случаев как файл-серверы.
Системы Windows NT появились на рынке достаточно давно, но широкое распространение они получили только с момента выхода версии 3.5.
В них реализована вытесняющая многозадачность, что делает эти системы хорошей основой для серверов приложений. Системы на базе Windows NT отвечают требованиям уровня безопасности C2 Министерства обороны США, что позволяет их использовать в самых ответственных приложениях. Windows NT функционирует как на платформе Intel, так и на RISC платформах, что дает возможность легко наращивать мощность системы по мере увеличения потока данных. Так как в качестве клиентских мест в системе будут использоваться компьютеры под управлений Windows 95/Windows 3.11, использование Windows NT в качестве сервера позволит создать целостную информационную систему. Следует учитывать также и наличие достаточно большого количества программистов, имеющих опыт работы с Windows 95, которые могут после дополнительной подготовки разрабатывать серверные части приложений под управлением Windows NT.
Учитывая тенденции развития рынка операционных систем в качестве платформы для реализации информационной системы выбрана Windows NT 4.0.
2.4 Выбор сервера баз данныхОсновные требования, предъявляемые к серверу баз данных таковы:
· Хорошая масштабируемость
· Высокая производительность
· Легкость в администрировании
· Наличие мощных инструментов для разработки приложений
· Низкая цена рабочего места
В настоящее время на рынке серверов баз данных представлено множество систем. Среди них Oracle, Informix, Sybase, Open Ingres, IBM DB2, Borland InterBase, Microsoft SQL Server и др.
Одна из особенностей поставленной задачи - установка серверов баз данных в районах Республики Мордовия. При этом особую роль играет отсутствие в местах установки серверов квалифицированных администраторов, способных управлять базой данных. Таким образом, одним из основных требований к серверу баз данных наряду с высокой производительностью и хорошей масштабируемостью является простота администрирования. Кроме того, сервер должен поддерживать распределенные базы данных.
Исходя из сравнительных характеристик данных серверов баз данных в качестве платформы для реализации корпоративной информационной системы был выбран сервер Borland InterBase 4.0 для Windows NT.
Borland InterBase Workgroup Server - сервер реляционных баз данных, оптимизированный для реализации технологии upsizing (укрупнения) многопользовательских приложений.
Версия InterBase 4.0 - сервера, традиционно доступного на всех основных UNIX-платформах (IBM, Sun, HP), оптимизирована для использования на Novell NetWare и Windows NT и обладает рядом функций, обязательных для современного SQL-сервера баз данных. К таким функциям относятся наличие хранимых процедур, расширенная поддержка триггеров, декларативная ссылочная целостность и т.д. Эти функции соответствуют стандарту ANSI/ISO SQL92 или, где возможно, проекту SQL3.
Важной особенностью InterBase является поддержка технологии C/S Express. Это особенно полезно при использовании InterBase 4.0 в качестве upsizing средства, т.к. позволяет сохранить привычную навигационную нотацию файл-серверной модели при переходе к архитектуре C/S.
Возможность обеспечивать как навигационный, так и SQL доступ к данным, является уникальной и делает InterBase 4.0, привлекательным средством для построения информационных систем различного масштаба - от небольшой рабочей группы до целого предприятия.
Borland InterBase Workgroup Server обладает рядом свойств, позволяющих решать задачи оперативной обработки транзакций и обеспечивать режим поддержки принятия решений. Среди таких свойств важнейшими являются технология многоверсионности (Versioning Engine), поддержка распределенных баз данных и наличие нестандартных типов данных.
Технология многоверсионности ядра обеспечивает бесконфликтный доступ к данным за счет ведения нескольких поколений записей. Когда транзакция модифицирует запись, InterBase создает новую запись. Во многих случаях новая запись представляет собой компактную запись изменений. InterBase связывает все такие записи и образует многоверсионную запись. Когда транзакция стартует, ей доступна наиболее поздняя версия записи, созданная завершенной транзакцией.
Если в процессе работы длинной транзакции, такой как получение архивной копии базы данных, будут внесены изменения в базу данных, это не нарушит целостный вид архивной копии, так как эта транзакция имеет дело с предыдущей версией записи. Таким образом, транзакция по чтению никогда не конфликтует с транзакцией по записи.
Побочным эффектом такой архитектуры является повышенная готовность системы, т.к. в случае аппаратных сбоев осуществляется откат к предыдущему состоянию с отменой незавершенных транзакций и результата их работы по обновлению базы данных.
Предыдущие версии записей ведутся до тех пор, пока существует активная транзакция, начавшаяся до момента модификации данной версии. Версии записи, более старые, чем самая старая активная транзакция, удаляются из системы следующей транзакцией с освобождением занимаемых системных ресурсов.
Технология построения InterBase позволяет создавать распределенные базы данных и обеспечивает возможность для приложения-клиента открыть необходимое количество БД, что обеспечивается механизмом двухфазной фиксации транзакций (two-phase commit).
Помимо общепринятых типов данных, таких как алфавитно-цифровая информация, даты и т.д., InterBase обладает возможностью работы с неструктурированными данными, сохраняя их в виде объектов типа BLOB (Binary Large Objects - большие двоичные объекты). В виде BLOB может быть сохранена любая двоичная информация: изображения, оцифрованный звук, исполняемые модули программ. Особенностью реализации BLOB в InterBase является сегментированный доступ к ним, что позволяет увеличить производительность прикладных систем.
Другим нетрадиционным типом данных, допустимым в InterBase, является многомерный массив. В InterBase в качестве поля записи может быть сохранен массив произвольных данных (кроме BLOB) с размерностью от 1 до 16. Наличие такого типа данных позволяет эффективно строить приложения, работающие в финансовой, промышленной и научно-исследовательской области.
InterBase предлагает разработчику прикладных систем ряд возможностей по реализации активных функций ядра. Это позволяет перенести часть приложения с компьютера - клиента на сервер, что повышает производительность и облегчает сопровождение прикладных систем
Декларативная целостность обеспечивает непротиворечивость данных на сервере. В отличие от реализации целостности с помощью триггеров декларативная целостность проще в применении и отладке. Существуют четыре категории средств обеспечения декларативной целостности:
· Unique and Primary Key (уникальный первичный ключ) - гарантирует уникальность значения ключевого поля записи;
· Referential Integrity (ссылочная целостность) - гарантирует соответствие значения ключевого поля записи подчиненной таблицы значению ключевого поля в главной таблице;
· Check Constraint (ограничение допустимости) - гарантирует, что правило допустимости, связанное с данным ограничением, истинно для каждой записи в таблице;
· Domain (домен) - позволяет создать новые подтипы с описанием допустимых значений и значений по умолчанию.
· Хранимые процедуры - хранимые процедуры InterBase соответствуют проекту ANSI/ISO SQL 3. В хранимых процедурах допустимы конструкции begin....end, if...then...else, while, for, when и т. д. Внутри хранимых процедур может быть предусмотрена обработка исключений. Исключения затем могут быть обработаны, используя оператор WHEN. Хранимые процедуры могут быть вложенными, а также рекурсивными, т.е. вызывать сами себя.
Триггеры - В InterBase возможно явное указание порядка выполнения триггеров, если триггерное условие выполняется для нескольких триггеров одновременно.
Сигнализаторы событий. InterBase полностью поддерживает механизм оповещения о событиях в базе данных.
PC-клиенты подключаются к InterBase 4.0 с помощью технологии интегрированного интерфейса к базам данных (Integrated Database Application Programming Interface - IDAPI) фирмы Borland, которая является общей технологией промежуточного уровня, используемой в таких программных продуктах Borland, как Paradox и dBASE. Сегодня IDAPI поддерживает связь c dBASE и Paradox через ориентированный на интерактивную работу интерфейс, а подключение к InterBase, Oracle и Sybase - через ориентированный на работу с наборами интерфейс SQL (Borland SQL Link).
Альтернативным способом доступа к данным InterBase может быть технология ODBC. В комплект поставки InterBase входит ODBC драйвер, а все IDAPI-приложения имеют возможность взаимодействовать с ODBC-совместимым источником данных.
С появлением InterBase 4.0 средства IDAPI поддерживают для InterBase 4.0 специальную технологию связи с базой данных, которая называется Express Link. Являясь частью технологии IDAPI фирмы Borland, Express Link, минуя собственные средства персонального приложения, обеспечивает через IDAPI прямую связь между персональными приложениями и сервером InterBase.
Подобные функциональные возможности требуют наличия двух компонентов: драйвера и сервера, который может отвечать на команды персонального приложения. С помощью InterBase 4.0 сервер базы данных поддерживает две модели взаимодействия с сервером. С использованием Express Link, InterBase 4.0 может функционировать, как подлинный сервер для клиентов Paradox и dBASE с непосредственной поддержкой в механизме базы данных таких средств, как перемещение по записям и их обновление. Через динамические и встроенные вызовы SQL InterBase 4.0 может также поддерживать операционную среду для традиционных SQL-приложений.
Таким образом, InterBase 4.0 поддерживает две интерфейсных операционных среды:
· Технологию Express Link (использующую IDAPI) с поддержкой таких персональных инструментов, как dBASE, Paradox и другие продукты Windows на базе IDAPI.
· SQL, позволяющую реализовать доступ на базе статических или динамических операторов SQL.
Основываясь на конкретных потребностях, приложение может свободно сочетать эти модели.
Для взаимодействия с сервером персональное приложение на PC, включая Paradox и dBASE, может вызывать администратор IDAPI. Сами функции IDAPI по характеру выполняемой ими работы подразделяются на функции перемещения и функции SQL. Вызовы SQL в IDAPI основаны на спецификации X-Open Call Level Interface, в то время как расширения вызовов персональных приложений IDAPI предназначены для реализации характерной технологии программирования персональных приложений. Для получения общей рабочей среды некоторые вызовы используются совместно как в режиме SQL, так и в режиме перемещения. Режим взаимодействия приложения с сервером InterBase 4.0 обычно определяется режимом текущего вызова IDAPI. Использование SQL или режима перемещения прозрачно для пользователя.
Для поддержки ориентированного на записи доступа обычно требуется выполнение на промежуточном уровне трансляции, преобразующей запросы персонального приложения в команды SQL. Например, чтобы открыть индексный курсор, транслирующий уровень строит оператор SQL с предложением Order By, соответствующим столбцам индекса, а затем выполняет его на сервере. Фильтрующие выражения завершаются предложением Where сгенерированного оператора SQL. Сервер реляционной базы данных эмулирует через SQL семантику данных работающего с упорядоченной информацией персонального приложения, что ведет к заметному снижению производительности.
Позволяя открывать курсоры для таблиц и индексов без использования операторов SQL, InterBase 4.0 с помощью многопользовательской среды клиент-сервер обеспечивает производительность, близкую к производительности локального персонального приложения. Это означает, что когда курсор открывается для таблицы, то записи возвращаются в естественном порядке, а когда он открывается для индекса, то они возвращаются в отсортированном порядке.
Важным аспектом дизайна InterBase 4.0 является прямая, осуществляемая на уровне механизма базы данных поддержка подобных операций перебора. Для более быстрой выборки записей из таблиц и индексов InterBase 4.0 использует специальные структуры данных, алгоритмы и протоколы. Для подготовки и выполнения таких операций операторы SQL не требуются, поэтому отпадает необходимость в промежуточных транслирующих модулях, а буферизация результирующего набора сводится с минимуму. Кроме того, к данным параллельно могут обращаться как пользователи Express Link, так и SQL.
Закладка - это метка записи относительно ее позиции среди других записей. Механизм InterBase 4.0 поддерживает закладки непосредственно на уровне сервера, позволяя использовать вызовы для установки, получения и сравнения закладок. Закладка действует в течение всего подключения к базе данных и допустима даже после закрытия исходного курсора и завершения первоначальной транзакции. Используя внутренние идентификаторы записи, InterBase 4.0 поддерживает быстрые операции с закладками.
Многие персональные приложения не используют понятия множественной транзакции и предполагают обычно, что каждая операция базы данных выполняется немедленно. Для поддержки такого представления InterBase 4.0 использует возможность автоматической фиксации, которая принудительно интерпретирует каждое обновление как полную транзакцию.
С этой целью в InterBase 4.0 поддерживается сохранение контекста курсора. Это позволяет поддерживать текущий курсор даже после завершения транзакции.
Когда сервер использует в качестве своего интерфейса исключительно SQL, он ограничен налагаемыми SQL правилами блокировок транзакций. В соответствии с правилами SQL пользователь может определить уровень выделения, но не может управлять блокировками (их установкой и отменой). Персональные приложения используют парадигмы явных и монопольных блокировок и в общем случае не применяют неявных блокировок. Более того, может потребоваться, чтобы запрашиваемые приложением блокировки сохранялись в течение транзакции, пока не будут явным образом отменены пользователем.
Для обеспечения потребностей пользователей персональных приложений PC, InterBase 4.0 поддерживает явные блокировки, но следует также и стандартной модели сервера, которая обеспечивает явные блокировки для традиционных пользователей SQL.
Персональные приложения часто позволяют пользователю просматривать большие объемы данных. Устанавливать для таких записей блокировки по чтению непрактично. В типичной системе клиент-сервер клиентское приложение выводит пользователю набор данных, не устанавливая на сервере никаких блокировок. Для поддержки целостности и согласованности данных клиентское приложение вынуждено следовать одним из путей:
· Через регулярные интервалы обновлять данные путем опроса сервера.
· Игнорировать изменения и продолжать выводить старые данные. Изменения распознаются, только если пользователь пытается обновить данные. В этом случае приложение информирует пользователей, что другое приложение изменило данные, и отражает это изменение.
· Блокировать все кэшируемые данные
В InterBase 4.0 предусмотрена специальная технология, которая называется обновлением кэша. Используя это средство, приложение IDAPI может идентифицировать диапазон интересующих его записей и регистрирует это на сервере. Когда в записи из этого диапазона происходит изменение (например, параллельно работающий пользователь модифицирует запись), сервер инициирует событие, которое уведомляет клиентское приложение с помощью механизмов уведомления о событиях - InterBase 4.0 Event Alerters. Клиентское приложение получает это событие и может либо игнорировать его, либо запросить изменение записей в данном диапазоне.
InterBase 4.0 допускает использование для хранения данных и работы с ними нескольких национальных наборов символов. Для всех строковых операций и операций с объектами BLOB поддерживаются как 8-битовые, так и 16-битовые наборы. Заданный по умолчанию набор символов и порядок сравнения можно определить для базы данных в целом. Сравнение можно также определить с помощью предложения Order By в операторе Select. Для спецификации символов национальных алфавитов можно использовать строковые литералы с префиксом имени набора символов. В стандартный комплект поставки включена поддержка кодовой таблицы ANSI 1251, являющейся стандартом при работе с русским языком в среде Windows.
2.5 Выбор средств разработкиВ качестве CASE-средства использован программный продукт ERWin 2.5 фирмы Logic Works. ERwin - средство разработки структуры базы данных. ERwin сочетает графический интерфейс Windows, инструменты для построения ER-диаграмм, редакторы для создания логического и физического описания модели данных и прозрачную поддержку ведущих реляционных СУБД и настольных баз данных. С помощью ERwin можно создавать или проводить обратное проектирование (реинжиниринг) баз данных.
Предыдущие версии ERwin - 1.5 и 2.1 - завоевали все возможные призы среди программ своего класса, в том числе DBMS Readers' Choice в 1992, 1993, 1994, 1995 годах, Software Development Productivity Award 1993, Data Based Advisor Readers' choice 1992 и 1994. Текущая версия продукта - 2.6.
ERWin позволяет проводить анализ системы как в стандарте IDEF1X, так и в стандарте IE, что увеличивает удобство работы с продуктом. ERwin объединяет логический и физический уровни представления модели в единую диаграмму, что позволяет провести анализ предметной области и полностью разработать структуры базы данных используя только один программный продукт. Выбор этого продукта обусловлен также возможностью легкого переноса разработанной модели на другой сервер баз данных.
Для написания клиентской части приложений использована среда разработчика Borland Delphi C/S 2.01. Delphi относится к средствам быстрой разработки приложений (RAD - Rapid Applications Development). Определяющим фактором при выборе Delphi в качестве средства разработки клиентской части является наличие большой библиотеки объектов для быстрого построения приложений, работающих с базами данных. Кроме того, Delphi поддерживает интерфейс PVCS, что позволяет вести параллельную разработку проекта несколькими программистами.
Для разработки процессов, функционирующих на стороне сервера использована среде разработки Microsoft Visual C 4.2 из пакета Microsoft Developer Studio. Эта среда сочетает в себе мощь языка C++, удобные средства отладки программ и навигации по тексту. Кроме того, она позволяет использовать в программах все возможности операционной системы (RPC, RAS, TAPI, сервисы Windows NT).
2.6 Организация взаимодействия между серверами 2.6.1 Выбор модели распределенной базы данныхТак как для обмена данными между серверами предполагается использовать медленные асинхронные каналы связи, а также учитывая большое количество серверов в данной информационной системе использован механизм репликации данных. Недостатки этого механизма, такие как задержка синхронизации различных копий данных, для данной системы играют малую роль.
2.6.2 Модель взаимодействияДля организации репликации данных и удаленного администрирования серверов в районах необходимо предусмотреть средства взаимодействия между серверами. При анализе процесса взаимодействия серверов можно выделить следующие компоненты системы:
· Процесс-клиент (сервер 1)
· Среда передачи данных
· Процесс-сервер (сервер 2)
В этой схеме в каждый конкретный момент времени в качестве клиента выступает один из взаимодействующих серверов. Таким образом, на каждом из серверов в любой момент времени должен быть запущен процесс, отвечающий за взаимодействие с удаленным узлом сети. В Windows NT в качестве такого процесса может выступать специально разработанный сервис операционной системы (system service). Он должен «уметь» обслуживать подключения удаленных клиентов, а также при необходимости сам выступать в роли клиента. Кроме того, на него можно возложить функции удаленного администрирования и резервного копирования данных.
Для организации обмена информацией в общем случае необходимо разработать протокол этого обмена, что само по себе является достаточно сложной задачей. Кроме того, необходимо реализовать поддержку сервисом различных транспортных протоколов (TCP/IP, NetBIOS, IPX/SPX), что выливается в многократное дублирование программного кода. Для решения этой задачи использован слой вызова удаленных процедур Microsoft RPC (Microsoft Remote Procedure Call).
2.6.3 Использование слоя RPC для распределенной обработки данных на платформе Windows NTВ соответствие с моделью RPC любой сервер может рассматриваться как сервер вычислений, т.е. он может предоставлять свои вычислительные мощности клиентам. Рабочая станция может послать запрос серверу на выполнение определенных вычислений и возврат результатов. Используя RPC, клиент не только использует файлы и принтеры сервера, но и разделяет его центральный процессор с другими компьютерами в сети.
Слой Microsoft RPC - только часть стандарта среды для распределенных вычислений, названной OSF (Open Software Foundation), разработанной группой компаний для определения компонентов сетевой среды, которая поддерживает распределенные вычисления.
2.6.4 Компоненты Microsoft RPC
Microsoft RPC включает следующие основные компоненты:
· Компилятор MIDL (Microsoft IDL)
· Библиотеки времени выполнения и заголовочные файлы.
· Модули транспортного интерфейса
· Сервис разрешения имен
· Сервис поддержки конечной точки
В модели PRC можно формально определить интерфейс для удаленной процедуры, используя язык, специально разработанный для этой цели. Этот язык – IDL (Interface Definition Language - язык определения интерфейсов). Диалект языка, реалиçованный фирмой Microsoft, назван MIDL (Microsoft IDL).
После создания интерфейса его описание обрабатывается компилятором MIDL. MIDL компилятор генерирует «заглушки» (stubs), которые транслируют вызовы локальных процедур в вызовы процедур, находящихся на сервере. «Заглушка» -- это процедура-заполнитель, которая делает вызовы библиотечных функций RPC для управления вызовами удаленных процедур. Применение заглушек обеспечивает прозрачность сетевого уровня для распределенных приложений. Клиентская программа вызывает их как локальные процедуры, весь код, который передает данные по сети и принимает результаты, генерируется MIDL компилятором и невидим для разработчика.
2.6.5 Механизм работы RPCRPC позволяет клиенту напрямую вызывать процедуры, находящиеся в программе на удаленном сервере. Клиент и сервер имеют различные адресные пространства; так, каждый имеет свою собственную память, в которой распределены данные, используемые процедурами. Следующий рисунок иллюстрирует архитектуру RPC:
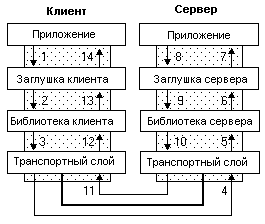
Рис.2.3. Механизм работы RPC.
Как показано на рис.2.3, клиентское приложение вызывает локальную заглушку вместо кода, непосредственно реализующего необходимую процедуру. Заглушка компилируется и линкуется с клиентским приложением. Заглушка клиента выполняет следующие действия:
· Запрашивает необходимые параметры из адресного пространства клиента
· Переводит параметры в стандартную форму представления данных в сети (NDR - standard network data representation)
· Вызывает необходимые функции из библиотеки времени выполнения RPC для отсылки запроса с параметрами на сервер.
Заглушка сервера выполняет следующие шаги:
· Библиотека времени выполнения RPC принимает запрос и вызывает процедуру заглушки сервера
· Заглушка сервера принимает параметра из буфера и конвертирует их из формата NDR в формат, процедуры сервера.
· Заглушка вызывает необходимую процедуру на сервере.
Удаленная процедура выполняется, генерирует выходные параметры и возвращаемое значение. Когда процедура завершена, следующие шаги возвращают данные клиенту:
· Удаленная процедура возвращает данные заглушке сервера
· Заглушка сервера конвертирует возвращаемые параметры в формат NDR и возвращает их функции библиотеки времени выполнения RPC
· Библиотечные функции передают данные через сеть на клиентский компьютер
Клиент завершает процесс принятием данных из сети и их возвратом вызывающей функции:
· Клиентская библиотека времени выполнения RPC принимает значения, возвращаемые удаленной процедурой и возвращает их заглушке
· Заглушка клиента конвертирует данные из формата NDR в формат, используемый клиентским приложением
· Приложение клиента продолжает свою работу.
Для Microsoft Windows и Windows NT библиотеки времени выполнения используются двумя путями: как статическая библиотека, линкуемая в приложение; и библиотека, реализованная как DLL.
Серверное приложение содержит вызовы библиотеки времени выполнения сервера, которая регистрирует интерфейсы сервера и позволяет серверу принимать вызовы удаленных процедур. Серверное приложение также содержит специфичные для каждого приложения процедуры, которые вызываются с клиента.
Таким образом, реализовав коммуникационный сервис на базе слоя RPC, можно существенно сэкономить время на разработке протоколов обмена информацией, а также получить систему, работающую по любым транспортным протоколам.
2.6.6 Организация логического канала передачи данных
Другой компонент модели - среда передачи данных может быть реализована несколькими способами. В простейшем случае она может быть построена на базе асинхронных каналов связи с использованием протоколов PPP (Point to Point Protocol), а также на базе существующих сетей X.25. На системный сервис можно также возложить ответственность за установление логического канала между серверами.
В случае каналов X.25 для установления соединения используется специальная каналообразующая аппаратура (коммутаторы X.25).
Решением начального уровня может служить удаленный доступ по протоколу PPP (Point to Point Protocol). Организация удаленного доступа по асинхронным каналам связи по протоколу PPP рассмотрена ниже.
2.7 Организация доступа удаленных пользователей 2.7.1 Необходимость удаленного доступаПри реализации данной системы экономически целесообразно устанавливать серверы баз данных только в тех районах республики, в которых количество абонентов достаточно велико. Для районов с малым числом абонентов наилучшим решением является использование сервера баз данных ближайшего РУС. Для этого необходимо организовать доступ операторов к территориально удаленному серверу. Средой передачи данных в этом случае являются телефонные линии, протоколом передачи на сетевом уровне - PPP (или SLIP).
2.7.2 Использование слоя RAS для удаленного доступа на платформеWindows NT
На платформе Windows NT задача удаленного доступа по протоколу PPP решается с помощью сервера RAS (Remote Access Server - сервер удаленного доступа). Сервер RAS - это процесс, который принимает и обрабатывает запросы клиентов на подключение через асинхронные линии и передачу данных. Схема взаимодействия удаленного клиента с сервером RAS приведена на рис.2.4.

Рис.2.4. Схема удаленного доступа с использованием RAS.
В качестве транспортного протокола могут использоваться протоколы TCP/IP, IPX/SPX, NetBIOS. Подключение клиента через сервер удаленного доступа абсолютно прозрачно, т.е. клиент может работать с удаленными серверами так, как если бы он находился в локальной сети.
В системе Windows NT существует программный интерфейс приложений (Application Program Interface), который позволяет установить логический канал с удаленной сетью по асинхронному соединению. Он носит название RAS API (Remote Access Service API).
Сервис удаленного доступа (RAS) позволяет удаленным пользователям получить доступ к одному или нескольким RAS серверам также, как и по локальной сети.
Win32 RAS позволяет RAS-клиенту установить соединение, получить информацию о существующих соединениях и завершить соединение. Связь осуществляется по протоколам PPP или SLIP. В качестве транспортного протокола могут быть использованы стеки TCP/IP, IPX/SPX и NetBIOS.
В Windows существуют стандартные программы для связи через RAS, таким образом для работы с удаленной базой данных можно использовать стандартные средства Windows.2.7.3 Обеспечение информационной безопасности при удаленном доступе
Учитывая то, что информация на серверах баз данных носит коммерческий характер, особую роль играет вопрос её защиты от несанкционированного доступа. Система Windows NT имеет сертификат соответствия уровню безопасности C2 Министерства обороны США. Данный уровень безопасности предполагает обязательную идентификацию пользователей системы для определения прав доступа к отдельным ресурсам системы. Удаленный вход в сеть также требует соответствующих привилегий, кроме того, все попытки удаленного доступа обязательно фиксируются в журнале событий. В систему Windows NT встроена возможность шифрования трафика в каналах передачи данных, таким образом злоумышленник, имеющий возможность перехвата данных в каналах связи, не получает доступа к жизненно важным данным (пароли и имена пользователей, финансовая информация).
Одним из способов ограничения доступа удаленных пользователей к ресурсам сети является использования так называемых серверов-барьеров (FireWalls) на стыке внутренней и внешней (какой в данном случае является удаленный пользователь) сетей. В данном случае можно гибко регулировать права удаленного пользователя на доступ к отдельным компьютерам в сети. Кроме того, серверы-барьеры скрывают топологию сети от внешнего пользователя. На платформе Windows NT функции сервера-барьера выполняет продукт Microsoft Proxy Server. Одним из побочных эффектов использования этого класса продуктов является экономия IP-адресов.
2.8 Проектирование структуры базы данныхПостроим информационную модель системы расчета с абонентами.
В ходе исследования существующей схемы расчетов были выявлены следующие основные сущности:
· Клиент (абонент, владелец телефона)
· Услуга
· Подразделение
· Начисление
· Телефонный разговор, подлежащий повременной тарификации
· Начисление за повременные разговоры (за один день)
· Оплата
· Категория клиента
· Проведенные расчеты
IDEF1X-диаграмма взаимодействия между этими сущностями представлена в Приложении 6.
После нормализации данных и разрешения связей «многие ко многим» путем введения граничных сущностей диаграмма принимает вид, указанный в
Приложении 6. Кроме того, для сущностей «Подразделение» и «Категория абонента» введена обратная неидентифицирующая связь для иерархического представления данных.
Постановка задачи требует наличия механизма поддержки истории для сущностей, влияющих на результаты расчетов. К сущностям, для которых должен поддерживаться механизм регистрации изменений относятся:
· Клиент (владелец телефона)
· Услуга
· Подразделение
· Начисление
· Постоянное начисление
· Категория клиента
Для регистрации изменений используется структура данных, представленная на рис.2.5.
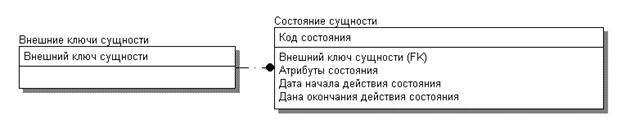
Рис.2.5. Структура данных для поддержки механизма регистрации изменений
Суть данной модели такова:
1. Каждая сущность характеризуется набором состояний, изменяющихся во времени.
2. Каждое состояние характеризуется набором атрибутов сущности, а также датой начала и датой окончания состояния.
3. Сущность однозначно идентифицируется своим внешним ключом и актуальной датой.
4. Дочерние таблицы ссылаются на сущность по её внешнему ключу.
5. При смене состояния внешний ключ не меняется.
Целостность данных обеспечивается с помощью триггеров на сервере.
Для дальнейшего анализа выделим в структуре базы данных несколько подсистем:
· Картотека абонентов
· Начисления
· Повременный учет
После определения атрибутов сущностей схема данных с учетом механизма поддержки истории принимает вид, приведенный в Приложении 6.
SQL-скрипт для генерации базы данных представлен в Приложении 1.
2.9 Схема репликации данных
Тиражирование данных в системе построено по схеме с одним сервером подписки (центральный сервер) и множеством серверов репликации (районы).

Рис.2.6. Организация репликации данных.
Данные на центральном сервере доступны только для чтения чтобы избежать конфликтов по модификации записи.
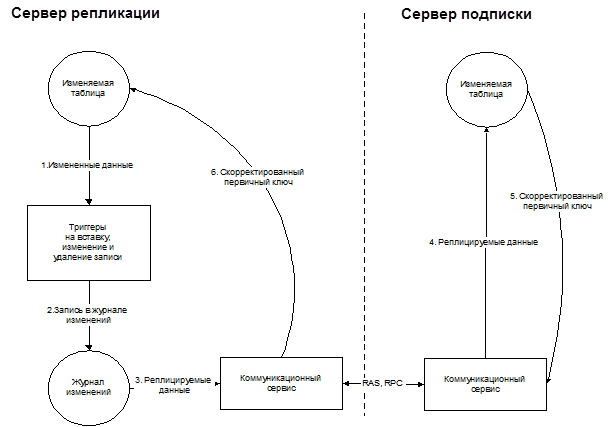
Рис.2.7. Подробная схема репликации данных.
Схема репликации приведена на рис.2.7. Рассмотрим процесс передачи изменений подробнее:
1. При изменении данных в реплицируемой таблице новые данные через триггер записываются в журнал изменений. Кроме того, туда заносится имя таблицы, код сделанного изменения и первичный ключ измененной записи.
2. При возникновении в базе определенного события (например при большом количестве записей в журнале изменений) или в определенный момент времени коммуникационный сервис запускает процесс репликации.
3. Процесс репликации устанавливает соединение с сервером подписки и начинает синхронизацию данных.
4. Сервер подписки принимает измененную запись и модифицирует соответствующим образом таблицу на своей стороне.
5. Если в процессе изменения записи был сгенерирован новый ключ, то он передается на сервер репликации.
6. Сервер репликации заменяет первичный ключ реплицируемой записи на ключ, возвращаемый с сервера подписки и удаляет соответствующую запись из журнала изменений.
При передаче изменений коммуникационным сервисом используется протокол двухфазной фиксации транзакций (Two-phase commit transactions), что позволяет застраховаться от ошибок.
При синхронизации данных подобным методом процесс репликации может быть прерван в любой момент времени и продолжен позднее с той же точки. Данная особенность позволяет использовать такую схему тиражирования даже на очень плохих каналах связи.
2.10 Проектирование коммуникационного сервера 2.10.1 Постановка задачиДля решения задач репликации, резервного копирования, удаленного доступа и удаленного управления на сервере баз данных необходим процесс, планирующий запуск процессов и обрабатывающий подключения удаленных пользователей. Основные требования, предъявляемые к коммуникационному серверу таковы:
1. Так как информационная система носит распределенный характер, а также учитывая отсутствие квалифицированных кадров в местах установки сервера необходимо предусмотреть возможность удаленного конфигурирования системы.
2. Для облегчения задач администрирования необходимо как можно более полно автоматизировать выполнение наиболее часто встречающихся задач, таких как резервное копирование данных и репликация.
3. Учитывая необходимость дальнейшего расширения системы необходимо предусмотреть возможность наращивания функциональности коммуникационного сервера.
4. Учитывая разнородность сети необходимо обеспечить возможность подключения пользователей по нескольким протоколам: TCP/IP, Named Pipes, IPX/SPX, NetBIOS.
2.10.2 Архитектура коммуникационного сервераУчитывая специфику платформы Windows NT коммуникационный сервер построен по архитектуре системного сервиса (System Service). Для разработки коммуникационного сервера применялась среда разработчика Microsoft Developer Studio 4.2/Visual C++ Enterprise Edition.
Архитектура сервера представлена в Приложении 2.
Для обеспечения наращиваемости системы проведено разделение функциональности сервера на две части:
· Ядро сервера - обслуживает подключения удаленных пользователей, планирует запуск пользовательских задач а также обеспечивает возможность удаленного конфигурирования системы.
· Пользовательские задачи - обеспечивают реплицирование, резервное копирование, синхронизацию картотек, съем данных с аппаратуры повременного учета.
Пользовательские задачи реализованы в виде многопоточных DLL. Каждая пользовательская задача должна обеспечивать две точки входа:
· void TaskProc(void) - основной поток - реализует необходимую функциональность.
· void Terminate(void) - функция для принудительного останова задачи (например при останове сервера)
Информация о пользовательских задачах хранится в реестре Windows NT
(ключ HKEY_LOCAL_MACHINE\SOFTWARE\Svyazinform\CommService\Tasks, рис.2.8).

Рис.2.8. Конфигурация задач коммуникационного сервера в реестре Windows NT.
Ядро cервера построено по многопоточной архитектуре и включает в себя следующие модули:
· Модуль инициализации - основная точка входа сервиса - регистрирует сервис в диспетчере сервисов.
· Модуль управления сервисом - реализует функции запуска и останова сервера.
· Планировщик задач - осуществляет запуск пользовательских задач в заданное время.
· Модуль обслуживания подключений - обрабатывает запросы удаленных пользователей, а также отвечает за удаленное конфигурирование системы.
· Модуль регистрации событий - записывает информацию о состоянии сервера в системный журнал событий.
2.10.3 Вспомогательное программное обеспечениеДля установки коммуникационного сервиса разработана программа, регистрирующая сервис в системе и создающая необходимые ключи в реестре Windows NT. Исходный код программы представлен в Приложении 4.
Для удаления сервера разработана программа, выполняющая чистку системного реестра. Исходный текст программы представлен в Приложении 5.
Для удаленного конфигурирования пользовательских задач разработано клиентское приложение «Менеджер задач коммуникационного сервера».
Данная программа позволяет управлять списком пользовательских задач (именами модулей и временем запуска). Главное окно программы представлено на рис.2.9.
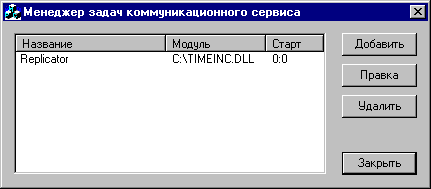
Рис.2.9. Главное окно программы конфигурирования коммуникационного сервера.
Разработка программы велась с помощью пакета Microsoft Visual C++ 4.2. Механизм реализации этой программы выходит за рамки данного дипломного проекта.
3. Технико-экономическое обоснование
Целью дипломного проекта было создание информационной системы для автоматизации расчетов с абонентами АО «Связьинформ» РМ.
Учитывая то, что объем дипломного проекта не позволяет рассчитать экономический эффект от научно-исследовательских разработок, ограничимся составлением плана выполнения дипломного проекта, построением ленточного графика выполнения проекта и расчетом сметы затрат.
3.1 План выполнения дипломного проектаВ соответствие с темой дипломного проекта определяются этапы НИР и их содержание. Этапы НИР необходимо максимально детализировать.
Таб.4.1. Этапы НИР.
| № n/n | Этап и содержание работы | Длительность цикла, дн. | Трудоемкость в % от общей трудоемкости | Исполнитель |
| 1 | 2 | 3 | 4 | 5 |
| 1 | Постановка задачи и составление технического задания | 5 | 3,1 | И1, Р, Д |
| 2 | Составление плана и календарного графика работы | 1 | 0,7 | Д, Р |
| 3 | Подбор и изучение технической документации и литературы | 14 | 10,55 | Д, Р |
| 4 | Написание вводной части и литературного обзора | 5 | 4,35 | Д |
| 5 | Информационное моделирование системы | 28 | 20,25 | Д, Р |
| 6 | Разработка коммуникационного сервера | 12 | 6,28 | Д |
| 7 | Отладка коммуникационного сервера | 18 | 8,35 | Д, Р |
| 1 | 2 | 3 | 4 | 5 |
| 8 | Написание теоретической части работы | 15 | 14,07 | Д, Р |
| 9 | Выводы по теоретической части проекта | 2 | 2,1 | Д, Р |
| 10 | Подбор данных и расчет экономической части проекта | 4 | 2,85 | Д, К1 |
| 11 | Анализ проделанной работы | 2 | 1,65 | Д |
| 12 | Составление пояснительной записки к дипломному проекту | 12 | 8,4 | Д |
| 13 | Оформление графической части работы | 12 | 10,75 | Д |
| 14 | Оформление приложений к дипломному проекту | 5 | 3,025 | Д |
| 15 | Сдача работы на отзыв руководителю | 2 | 1,65 | Д |
| 16 | Сдача работы на рецензирование | 2 | 1,2 | Д |
| 17 | Сдача дипломного проекта на кафедру | 1 | 0,725 | Д |
| ИТОГО: | 140 | 100 |
Примечание: Д-дипломник;
И1-инженер-консультант
Р-руководитель
К1-консультант по экономической части
Трудоемкость выполнения НИР определяется по сумме этапов и видов работ, оцениваемых экспертным путем в человеко-днях и носит вероятностный характер, так как зависит от множества трудно учитываемых факторов.
3.2 Расчет ожидаемой продолжительности выполнения работ и их дисперсий
Ожидаемая продолжительность работ рассчитывается по формуле:
![]()
где Tmin - оптимистическая оценка времени разработки, исходящая из
наиболее благоприятных условий её выполнения;
Т н.в. - наиболее вероятная продолжительность выполнения работы при
нормальных, чаще всего встречающихся условиях;
Т max - максимальное время выполнения работы при наиболее
неблагоприятных условиях её выполнения;
Одновременно с расчетом величины Тож. Определяют дисперсию (разброс) по формуле:
![]()
Дисперсия определяет степень неопределенности выполнения работы за ожидаемое время Тож.
Расчеты ожидаемой продолжительности работ сведены в таблицу.
Таб.4.2. Продолжительность работ.
| № n/n | Этап и содержание работы | Tmin | Tн.в. | Tmax | Tож | Di |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 1 | Постановка задачи и составление технического задания | 3 | 5 | 7 | 5 | 0,44 |
| 2 | Составление плана и календарного графика работы | 1 | 1 | 2 | 1,167 | 0,03 |
| 3 | Подбор и изучение технической документации и литературы | 12 | 14 | 16 | 14 | 0,44 |
| 4 | Написание вводной части и литературного обзора | 3 | 5 | 7 | 5 | 0,44 |
| 5 | Информационное моделирование системы | 26 | 28 | 29 | 27,8 | 0,25 |
| 6 | Разработка коммуникационного сервера | 11 | 12 | 14 | 12,2 | 0,25 |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 7 | Отладка коммуникационного сервера | 16 | 18 | 20 | 18 | 0,44 |
| 8 | Написание теоретической части работы | 13 | 15 | 17 | 15 | 0,44 |
| 9 | Выводы по теоретической части проекта | 1 | 2 | 2 | 1,8 | 0,027 |
| 10 | Подбор данных и расчет экономической части проекта | 3 | 4 | 6 | 4,2 | 0,25 |
| 11 | Анализ проделанной работы | 1 | 2 | 2 | 1,8 | 0,27 |
| 12 | Составление пояснительной записки к дипломному проекту | 10 | 12 | 14 | 12 | 0,44 |
| 13 | Оформление графической части работы | 11 | 12 | 13 | 12 | 0,44 |
| 14 | Оформление приложений к дипломному проекту | 4 | 5 | 5 | 4,8 | 0,027 |
| 15 | Сдача работы на отзыв руководителю | 2 | 2 | 3 | 2,2 | 0,027 |
| 16 | Сдача работы на рецензирование | 1 | 2 | 3 | 2 | 0,11 |
| 17 | Сдача дипломного проекта на кафедру | 1 | 1 | 1 | 1 | 0 |
Анализ проведенных расчетов позволяет сделать вывод о том, что расчетное ожидаемое время выполнения работы приближается к наиболее вероятному времени и разброс временных параметров располагается в интервале от 0 до 0,44. Это говорит о том, что при проведении работ необходимо строго соблюдать временной режим.
3.3 Построение ленточного графика выполнения работыОдной из основных целей планирования проведения работы является определение их общей продолжительности. Наиболее удобным, простым и наглядным является ленточный график проведения работ.
Продолжительность каждой работы Tn определяется по формуле:
![]()
где Ti - трудоемкость работ (чел./дн.)
Ci - численность исполнителей (чел.)
Таб.4.3. Ленточный график выполнения работ.
| № n/n | Этап и содержание работы | Трудоемкость (чел./дн.) | Численность (чел.) | Длит-ть работы (дн.) |
| 1 | 2 | 3 | 4 | 5 |
| 1 | Постановка задачи и составление технического задания | 5 | 3 | 1,67 |
| 2 | Составление плана и календарного графика работы | 1 | 2 | 0,5 |
| 3 | Подбор и изучение технической документации и литературы | 14 | 2 | 7 |
| 4 | Написание вводной части и литературного обзора | 5 | 1 | 5 |
| 5 | Информационное моделирование системы | 28 | 2 | 14 |
| 6 | Разработка коммуникационного сервера | 12 | 1 | 12 |
| 7 | Отладка коммуникационного сервера | 18 | 2 | 9 |
| 8 | Написание теоретической части работы | 15 | 2 | 7,5 |
| 9 | Выводы по теоретической части проекта | 2 | 2 | 1 |
| 10 | Подбор данных и расчет экономической части проекта | 4 | 2 | 2 |
| 11 | Анализ проделанной работы | 2 | 1 | 2 |
| 12 | Составление пояснительной записки к дипломному проекту | 12 | 1 | 12 |
| 13 | Оформление графической части работы | 12 | 1 | 12 |
| 1 | 2 | 3 | 4 | 5 |
| 14 | Оформление приложений к дипломному проекту | 5 | 1 | 5 |
| 15 | Сдача работы на отзыв руководителю | 2 | 1 | 2 |
| 16 | Сдача работы на рецензирование | 2 | 1 | 2 |
| 17 | Сдача дипломного проекта на кафедру | 1 | 1 | 1 |
| ИТОГО: | 140 | 94,67 |
Целью расчета себестоимости НИР является экономически обоснованной определение величины затрат на её выполнение. В плановую себестоимость включают все затраты, связанные с выполнением работы, независимо от источника финансирования. Определение затрат производится путем составления затрат на НИР.
Смета затрат на НИР должна быть представлена по следующим статьям калькуляции:
1. Материалы, покупные изделия и полуфабрикаты;
2. Спецоборудование для научных исследований;
3. Расходы на силовую электроэнергию.
4. Основная заработная плата производственного персонала;
5. Отчисления на социальное страхование;
6. Косвенные (накладные) расходы отдела(кафедры);
7. Производственные командировки;
8. Контрагентные работы, которые включают стоимость работ, выполняемых для темы другими организациями.
9. Оплата услуг опытного производства, находящегося на самостоятельном балансе;
10. Общеуниверситетские косвенные расходы;
11. Расходы на научно-техническую информацию;
12. Расходы на зарубежные лицензии и патенты;
13. Отчисления в пенсионный фонд;
14. Отчисления в фонд занятости;
15. Отчисления на медицинское страхование;
16. Затраты на эксплуатацию оборудования (амортизацию).
1. Расчет стоимости покупных изделий представлен в таблице.
Таб.4.3. Стоимость покупных изделий.
| Изделие | Количество | Цена за единицу, руб | Сумма, руб |
| Дискета 3.5’’ | 1 | 5500 | 5500 |
| Ватман | 5 | 5000 | 25000 |
| Бумага | 1 | 30000 | 30000 |
| ИТОГО: | 60500 |
2. Спецоборудование для работ не применялось, расходы отсутствуют.
3. Работы с использованием силовой электроэнергии не проводились, расходы отсутствуют.
4. В качестве базы для расчета заработной платы принимается месячный оклад кандидата наук в размере 345000 руб. (13 разряд), что составляет в пересчете на 1 учебный час работы при 800-часовой годовой нагрузке :
(345000 * 12) / 800 = 5175 (руб./час)
Руководство дипломным проектированием оценивается преподавателем в 6 учебных часов. Таким образом, получим основную заработную плату производственного персонала в размере:
5175 * 26 = 134550 (руб.)
5. Отчисление на социальное страхование. По условию договора составляют 5,4% от заработной платы (п.4). Сумма расходов по статье 7265 руб.
6. Косвенные (накладные) расходы кафедры условиями договора не предусмотрены.
7. Производственные командировки условиями договора не предусмотрены.
8. Контрагентные работы не проводились, расходы отсутствуют.
9. Оплата услуг опытного производства, находящегося на самостоятельном балансе не проводилась.
10. Общевузовские расходы. По условиям договора берутся 15% от заработной платы (от п.4) и составляют 20183 руб.
11. Расходы на научно-техническую информацию отсутствуют.
12. Расходы на зарубежные лицензии и патенты отсутствуют.
13. Отчисления в пенсионный фонд. Данные расходы берутся в размере 1% от основной заработной платы производственного персонала (п.4) и составляют 1345 руб.
14. Отчисления в фонд занятости. Расходы по данной статье 2% от основной заработной платы производственного персонала (п.4) или 2691 руб.
15. Отчисления на медицинское страхование. На эти нужды отчисляется 3,6% от основной заработной платы производственного персонала (п.4) или 4844 руб.
16. Затраты на эксплуатацию оборудования (амортизацию). В процессе работы над проектом использовались персональный компьютер IBM PC Pentium 133 и принтер. Отчисления на амортизацию данной техники составляют 3200 руб. за 1 час работы и составляют при 300-часовой эксплуатации компьютера и 5-часовой принтера
3200 * (300 + 5) = 976000 руб.
Результаты калькуляции по статьям сведены в таблицу
Таб.4.4. Калькуляция по статьям расходов.
| Статья расходов | Сумма, руб. |
| Материалы, покупные изделия и полуфабрикаты | 60500 |
| Основная заработная плата производственного персонала | 134550 |
| Отчисления на социальное страхование (5,4% от зарплаты) | 7265 |
| Отчисления в фонд занятости (2% от зарплаты) | 2691 |
| Отчисления на медицинское страхование (3,6 % от зарплаты) | 4844 |
| Налог на содержание МВД (1% от минимальной заработной платы) | 835 |
| Общеуниверситетские косвенные расходы (15% от зарплаты) | 20183 |
| Отчисления в пенсионный фонд (1% от зарплаты) | 1345 |
| Затраты на эксплуатацию оборудования (амортизацию) | 976000 |
| ИТОГО: | 1207213 |
Заключение
За время работы над дипломным проектом по теме «Организация удаленного доступа к распределенным базам данных» были изучены теоретические основы построения распределенных информационных систем с возможностью оперативного удаленного доступа к данным.
Результатом дипломного проектирования является информационная система для автоматизации расчетов с абонентами АО «Связьинформ» РМ. В ходе работы было проведено информационное моделирование объекта, построена структура баз данных, отвечающая предъявляемым требованиям, а также разработана архитектура информационной системы. Кроме того, было разработано программное обеспечение для автоматизации администрирования и решения задач удаленного доступа, удаленного управления и репликации данных.
Отдельная глава посвящена технико-экономическому обоснованию данного дипломного проекта.
Список литературы
1. Borland InterBase Workgroup Server. API Guide. - Borland International Inc, 1995 - 330 c.
2. Borland InterBase Workgroup Server. DataDefinition Guide. - Borland International Inc, 1995 - 212 c.
3. Borland InterBase Workgroup Server. Language Reference. - Borland International Inc, 1995 - 234 c.
4. Borland InterBase Workgroup Server. Programmer’s Guide. - Borland International Inc, 1995 - 340 c.
5. Microsoft Online Documentation: Win32 Programmers Reference.
6. R.Barker "CASE* Method - Entity Relationship Modelling". - Oracle Inc., 1990 - 243 c.
7. Биллиг В.А., Мусикаев И.Х. «Visual C++ 4. Книга для программистов». - М.: Издательский отдел «Русская редакция» ТОО «Channel Trading Ltd.» , 1996. - 352 с. ил.
8. Галатенко В. «Информационная безопасность - обзор основных положений: Ч1»: - Информационный бюллетень Jet Info №1/1996.
9. Галатенко В. «Информационная безопасность - обзор основных положений: Ч2»: - Информационный бюллетень Jet Info №2/1996.
10. Галатенко В. «Информационная безопасность - обзор основных положений: Ч3»: - Информационный бюллетень Jet Info №3/1996.
11. Грабер Мартин. “Введение в SQL”. Пер. с англ. - М.: Издательство “ЛОРИ”, 1996. - 375 с., ил.
12. Зубанов Ф. «Windows NT - выбор «профи»». - М.: Издательский отдел «Русская редакция» ТОО «Channel Trading Ltd.» , 1996. - 392 с. ил.
13. Кастер Х. «Основы Windows NT и NTFS». Пер. с англ. - М: Издательский отдел «Русская редакция» ТОО «Channel Trading Ltd.» , 1996. - 440 с. ил.
14. Ладыженский Глеб. «СУБД - коротко о главном» : - Информационный бюллетень Jet Info №3-5/1995.
15. Ларин Л.С., Челдаева Л.А., Гуськова Н.Д."Технико-экономическое обоснование дипломных проектов", Саранск, 1983, 100 с.
16. «Решения Microsoft» - Вып. 4. - М: АООТ «Типография Новости», 1996. 124 с., ил.
17. «Решения Microsoft» - Вып. 5. - М: АООТ «Типография Новости», 1997. 132 с., ил.
18. Рихтер Дж.. «Windows для профессионалов (Программирование в Win32 API для Windows 95 и Windows NT)». Пер. с англ. - М: Издательский отдел «Русская редакция» ТОО «Channel Trading Ltd.» , 1995. - 720 с. ил.
19. Паппас К., Мюррей У.. «Visual C++. Руководство для профессионалов»: пер. с англ. - Спб.: BHV - Санкт-Петербург, 1996. - 912 с., ил.
20. «Сетевые средства Windows NT»: Пер. с англ. - СПб.: BHV - Санкт-Петербург, 1996 - 496 с., ил.
21. Фролов А.В., Фролов Г.В. «Microsoft Visual C++ и MFC». - М: Диалог-МИФИ, 1996 - 288 с., ил.
22. Фролов А.В., Фролов Г.В. «Программирование для Windows NT: Ч2». - М: Диалог-МИФИ, 1997 - 271 с., ил.
23. Янг М. «Mastering Microsoft Visual C++». Пер. с англ.- К.: ВЕК+, М.: ЭНТРОП, 1997. - 704 с., ил.
Приложение 1
SQL-скрипт для генерации базы данных
CREATE GENERATOR genUslPropsKeys;
CREATE GENERATOR genUslProps;
CREATE GENERATOR genPhonesRegions;
CREATE GENERATOR genPhonesStations;
CREATE GENERATOR genPhonesStreets;
CREATE GENERATOR genPhonesBanks;
CREATE GENERATOR genTalksPay;
CREATE GENERATOR genTalks;
CREATE GENERATOR genNach;
CREATE GENERATOR genNachBillings;
CREATE GENERATOR genNachBillDates;
CREATE GENERATOR genNachConstUsl;
CREATE GENERATOR genUslDivisions;
CREATE GENERATOR genUslLgots;
CREATE GENERATOR genUslsKeys;
CREATE GENERATOR genUsls;
CREATE GENERATOR genUslCatKeys;
CREATE GENERATOR genUslCat;
CREATE GENERATOR genPhones;
CREATE GENERATOR genPhonesOwnersKeys;
CREATE GENERATOR genPhonesOwners;
CREATE GENERATOR genSysSettings;
CREATE GENERATOR genPhonesKeys;
CREATE GENERATOR genPlat;
CREATE GENERATOR genPhonesPostStations;
CREATE GENERATOR genSysLog;
CREATE GENERATOR genUslTypes;
CREATE GENERATOR genUslDivisionsKeys;
CREATE DOMAIN CALLTIME_TYPE INTEGER NOT NULL;
CREATE DOMAIN CURR_TYPE FLOAT DEFAULT 0 NOT NULL;
CREATE DOMAIN DATE_TYPE DATE NOT NULL;
CREATE DOMAIN DESCR_TYPE CHAR(32);
CREATE DOMAIN PHONE_TYPE CHAR(7) NOT NULL;
CREATE DOMAIN PROCENT_TYPE FLOAT DEFAULT 100 NOT NULL
CHECK (VALUE BETWEEN 0 AND 300);
CREATE TABLE Nach (
Code INTEGER NOT NULL,
Owner INTEGER NOT NULL,
Usl INTEGER NOT NULL,
Phone INTEGER,
UslSum CURR_TYPE,
NachDate DATE_TYPE,
BillDate DATE_TYPE
);
ALTER TABLE Nach
ADD CONSTRAINT XPKNach PRIMARY KEY (Code);
CREATE TABLE NachBillDates (
Code INTEGER NOT NULL,
BillingDate INTEGER NOT NULL
);
ALTER TABLE NachBillDates
ADD CONSTRAINT XPKBillDates PRIMARY KEY (Code);
CREATE TABLE NachBillings (
Code INTEGER NOT NULL,
Division INTEGER NOT NULL,
Owner INTEGER NOT NULL,
BillDateCode INTEGER NOT NULL
);
ALTER TABLE NachBillings
ADD CONSTRAINT XPKNachBillings PRIMARY KEY (Code);
CREATE TABLE NachConstUsl (
Code INTEGER NOT NULL,
Owner INTEGER NOT NULL,
Usl INTEGER NOT NULL,
Phone INTEGER NOT NULL,
UslSum CURR_TYPE,
BegDate DATE_TYPE,
EndDate DATE_TYPE
);
ALTER TABLE NachConstUsl
ADD CONSTRAINT XPKNachConstUsl PRIMARY KEY (Code);
CREATE TABLE Phones (
Code INTEGER NOT NULL,
Street INTEGER NOT NULL,
Owner INTEGER NOT NULL,
PKey INTEGER NOT NULL,
Comment DESCR_TYPE,
PhoneNmb PHONE_TYPE,
InstallDate DATE_TYPE,
RemoveDate DATE_TYPE,
BegDate DATE_TYPE,
EndDate DATE_TYPE
);
ALTER TABLE Phones
ADD CONSTRAINT XPKPhones PRIMARY KEY (Code);
CREATE TRIGGER Phones_BUH FOR Phones
BEFORE UPDATE POSITION 0
AS
BEGIN
/* Изменение BegDate */
IF (new.BegDate <> old.BegDate) THEN
BEGIN
IF (new.BegDate < old.BegDate) THEN
BEGIN
/* Расширение BegDate */
UPDATE Phones
SET EndDate = new.BegDate
WHERE ((new.BegDate BETWEEN BegDate AND EndDate) AND (PKey = new.PKey));
END
ELSE
BEGIN
/* Сужение BegDate */
UPDATE Phones
SET EndDate = new.BegDate
WHERE ((EndDate = old.BegDate) AND (PKey = new.PKey));
END
END
/* Изменение EndDate */
IF (new.EndDate <> old.EndDate) THEN
BEGIN
IF (new.EndDate > old.EndDate) THEN
BEGIN
/* Расширение EndDate */
UPDATE Phones
SET BegDate = new.EndDate
WHERE ((new.EndDate BETWEEN BegDate AND EndDate) AND (PKey = new.PKey));
END
ELSE
BEGIN
/* Сужение EndDate */
UPDATE Phones
SET BegDate = new.EndDate
WHERE ((BegDate = old.EndDate) AND (PKey = new.PKey));
END
END
/* Сборка мусора */
DELETE FROM Phones
WHERE ((BegDate >= new.BegDate) AND (EndDate <= new.EndDate) AND (PKey = new.PKey) AND (Code <> new.Code));
END ^
CREATE TRIGGER Phones_BIH FOR Phones
BEFORE INSERT POSITION 0
AS
BEGIN
DELETE FROM Phones
WHERE ((BegDate >= new.BegDate) AND (EndDate <= new.EndDate) AND (PKey = new.PKey));
UPDATE Phones
SET BegDate = new.EndDate
WHERE ((new.EndDate BETWEEN BegDate AND EndDate) AND (PKey = new.PKey));
UPDATE Phones
SET EndDate = new.BegDate
WHERE ((new.BegDate BETWEEN BegDate AND EndDate) AND (PKey = new.PKey));
END ^
CREATE TRIGGER Phones_BDH FOR Phones
BEFORE DELETE POSITION 0
AS
BEGIN
UPDATE Phones
SET EndDate = old.EndDate
WHERE ((EndDate = old.BegDate) AND (PKey = old.PKey));
END ^
CREATE TABLE PhonesBanks (
Code INTEGER NOT NULL,
Name1 DESCR_TYPE,
PMFO CHAR(12) NOT NULL,
Name2 DESCR_TYPE,
ELMFO CHAR(12) NOT NULL,
PlatCount SMALLINT NOT NULL,
Acc1 CHAR(12) NOT NULL,
Acc2 CHAR(12) NOT NULL
);
CREATE INDEX XIEPhonesBanksName ON PhonesBanks
(
Name1,
Name2
);
ALTER TABLE PhonesBanks
ADD CONSTRAINT XPKPhonesBanks PRIMARY KEY (Code);
CREATE TABLE PhonesKeys (
Code INTEGER NOT NULL
);
ALTER TABLE PhonesKeys
ADD CONSTRAINT XPKPhonesKeys PRIMARY KEY (Code);
CREATE TABLE PhonesOwners (
Code INTEGER NOT NULL,
PKey INTEGER NOT NULL,
Name1 DESCR_TYPE,
Name2 DESCR_TYPE,
Category INTEGER NOT NULL,
Bank INTEGER,
Street INTEGER NOT NULL,
PostStation INTEGER,
House CHAR(5),
Corpus CHAR(3),
Flat CHAR(3),
Account CHAR(5),
RS CHAR(9),
INN CHAR(13),
Nmb_Dogov CHAR(6),
Date_Dogov DATE,
BegDate DATE_TYPE,
EndDate DATE_TYPE
);
ALTER TABLE PhonesOwners
ADD CONSTRAINT XPKPhonesOwners PRIMARY KEY (Code);
CREATE TRIGGER PhonesOwners_BUH FOR PhonesOwners
BEFORE UPDATE POSITION 0
AS
BEGIN
/* Изменение BegDate */
IF (new.BegDate <> old.BegDate) THEN
BEGIN
IF (new.BegDate < old.BegDate) THEN
BEGIN
/* Расширение BegDate */
UPDATE PhonesOwners
SET EndDate = new.BegDate
WHERE ((new.BegDate BETWEEN BegDate AND EndDate) AND (PKey = new.PKey));
END
ELSE
BEGIN
/* Сужение BegDate */
UPDATE PhonesOwners
SET EndDate = new.BegDate
WHERE ((EndDate = old.BegDate) AND (PKey = new.PKey));
END
END
/* Изменение EndDate */
IF (new.EndDate <> old.EndDate) THEN
BEGIN
IF (new.EndDate > old.EndDate) THEN
BEGIN
/* Расширение EndDate */
UPDATE PhonesOwners
SET BegDate = new.EndDate
WHERE ((new.EndDate BETWEEN BegDate AND EndDate) AND (PKey = new.PKey));
END
ELSE
BEGIN
/* Сужение EndDate */
UPDATE PhonesOwners
SET BegDate = new.EndDate
WHERE ((BegDate = old.EndDate) AND (PKey = new.PKey));
END
END
/* Сборка мусора */
DELETE FROM PhonesOwners
WHERE ((BegDate >= new.BegDate) AND (EndDate <= new.EndDate) AND (PKey = new.PKey) AND (Code <> new.Code));
END ^
CREATE TRIGGER PhonesOwners_BIH FOR PhonesOwners
BEFORE INSERT POSITION 0
AS
BEGIN
DELETE FROM PhonesOwners
WHERE ((BegDate >= new.BegDate) AND (EndDate <= new.EndDate) AND (PKey = new.PKey));
UPDATE PhonesOwners
SET BegDate = new.EndDate
WHERE ((new.EndDate BETWEEN BegDate AND EndDate) AND (PKey = new.PKey));
UPDATE PhonesOwners
SET EndDate = new.BegDate
WHERE ((new.BegDate BETWEEN BegDate AND EndDate) AND (PKey = new.PKey));
END ^
CREATE TRIGGER PhonesOwners_BDH FOR PhonesOwners
BEFORE DELETE POSITION 0
AS
BEGIN
UPDATE PhonesOwners
SET EndDate = old.EndDate
WHERE ((EndDate = old.BegDate) AND (PKey = old.PKey));
END ^
CREATE TABLE PhonesOwnersKeys (
Code INTEGER NOT NULL,
InRest CURR_TYPE,
OutRest CURR_TYPE,
NDolg INTEGER NOT NULL
);
ALTER TABLE PhonesOwnersKeys
ADD CONSTRAINT XPKPhonesOwnersKeys PRIMARY KEY (Code);
CREATE TABLE PhonesPostStations (
Code INTEGER NOT NULL,
Name DESCR_TYPE,
Region INTEGER NOT NULL,
PostIndex CHAR(6) NOT NULL,
PostNmb CHAR(6) NOT NULL
);
CREATE UNIQUE INDEX XAKPhonesPostStationsIndex ON PhonesPostStations
(
PostIndex
);
CREATE UNIQUE INDEX XAKPhonesPostStationsPostNmb ON PhonesPostStations
(
PostNmb
);
CREATE INDEX XIEPhonesPostStationsName ON PhonesPostStations
(
Name
);
ALTER TABLE PhonesPostStations
ADD CONSTRAINT XPKPhonesPostStations PRIMARY KEY (Code);
CREATE TABLE PhonesRegions (
Code INTEGER NOT NULL,
Name DESCR_TYPE NOT NULL
);
CREATE INDEX XIEPhonesRegionsName ON PhonesRegions
(
Name
);
ALTER TABLE PhonesRegions
ADD CONSTRAINT XPKPhonesRegions PRIMARY KEY (Code);
CREATE TABLE PhonesStations (
Code INTEGER NOT NULL,
Region INTEGER NOT NULL,
Name DESCR_TYPE NOT NULL
);
CREATE INDEX XIEPhonesStationsName ON PhonesStations
(
Name
);
ALTER TABLE PhonesStations
ADD CONSTRAINT XPKPhonesStations PRIMARY KEY (Code);
CREATE TABLE PhonesStreets (
Code INTEGER NOT NULL,
Station INTEGER NOT NULL,
Region INTEGER NOT NULL,
Name DESCR_TYPE
);
CREATE INDEX XIEPhonesStreetsName ON PhonesStreets
(
Name
);
ALTER TABLE PhonesStreets
ADD CONSTRAINT XPKPhonesStreets PRIMARY KEY (Code);
CREATE TABLE Plat (
Code INTEGER NOT NULL,
Owner INTEGER NOT NULL,
ToUsl INTEGER,
PlatDate DATE_TYPE,
PlatType INTEGER NOT NULL,
DocNmb CHAR(12) NOT NULL
);
ALTER TABLE Plat
ADD CONSTRAINT XPKPlat PRIMARY KEY (Code);
CREATE TABLE SysLog (
Code INTEGER NOT NULL,
TableName CHAR(16) NOT NULL,
OpType INTEGER NOT NULL,
NewData CHAR(64) NOT NULL,
OpDate DATE NOT NULL
);
ALTER TABLE SysLog
ADD CONSTRAINT XPKSysLog PRIMARY KEY (Code);
CREATE TABLE SysSettings (
Code INTEGER NOT NULL,
TimeTalksUsl INTEGER NOT NULL,
NullOwner INTEGER NOT NULL
);
ALTER TABLE SysSettings
ADD CONSTRAINT XPKSysSettings PRIMARY KEY (Code);
CREATE TABLE Talks (
Code INTEGER NOT NULL,
DayCode INTEGER NOT NULL,
Phone INTEGER NOT NULL,
ToPhone INTEGER NOT NULL,
CallTime CALLTIME_TYPE,
PhoneNmb PHONE_TYPE,
HowLong INTEGER NOT NULL,
ToPhoneNmb PHONE_TYPE,
Calculated SMALLINT NOT NULL,
CallDate DATE_TYPE
);
CREATE INDEX XAK1TalksCallDate ON Talks
(
CallDate
);
ALTER TABLE Talks
ADD CONSTRAINT XPKTalks PRIMARY KEY (Code);
CREATE TABLE TalksPay (
Code INTEGER NOT NULL,
Phone INTEGER NOT NULL,
TotalSum CURR_TYPE,
TotalLgotTime CALLTIME_TYPE,
TotalFullTime CALLTIME_TYPE,
TotalTime COMPUTED BY (TotalLgotTime+TotalFullTime),
CallDate DATE_TYPE
);
ALTER TABLE TalksPay
ADD CONSTRAINT XPKTalksPay PRIMARY KEY (Code);
CREATE TABLE UslCat (
Code INTEGER NOT NULL,
PKey INTEGER NOT NULL,
Name DESCR_TYPE,
Parent INTEGER NOT NULL,
BegDate DATE_TYPE,
EndDate DATE_TYPE
);
CREATE INDEX XIEUslCatName ON UslCat
(
Name
);
CREATE INDEX XIEUslCatParent ON UslCat
(
Parent
);
ALTER TABLE UslCat
ADD CONSTRAINT XPKUslCat PRIMARY KEY (Code);
CREATE TRIGGER UslCat_BUH FOR UslCat
BEFORE UPDATE POSITION 0
AS
BEGIN
/* Изменение BegDate */
IF (new.BegDate <> old.BegDate) THEN
BEGIN
IF (new.BegDate < old.BegDate) THEN
BEGIN
/* Расширение BegDate */
UPDATE UslCat
SET EndDate = new.BegDate
WHERE ((new.BegDate BETWEEN BegDate AND EndDate) AND (PKey = new.PKey));
END
ELSE
BEGIN
/* Сужение BegDate */
UPDATE UslCat
SET EndDate = new.BegDate
WHERE ((EndDate = old.BegDate) AND (PKey = new.PKey));
END
END
/* Изменение EndDate */
IF (new.EndDate <> old.EndDate) THEN
BEGIN
IF (new.EndDate > old.EndDate) THEN
BEGIN
/* Расширение EndDate */
UPDATE UslCat
SET BegDate = new.EndDate
WHERE ((new.EndDate BETWEEN BegDate AND EndDate) AND (PKey = new.PKey));
END
ELSE
BEGIN
/* Сужение EndDate */
UPDATE UslCat
SET BegDate = new.EndDate
WHERE ((BegDate = old.EndDate) AND (PKey = new.PKey));
END
END
/* Сборка мусора */
DELETE FROM UslCat
WHERE ((BegDate >= new.BegDate) AND (EndDate <= new.EndDate) AND (PKey = new.PKey) AND (Code <> new.Code));
END ^
CREATE TRIGGER UslCat_BIH FOR UslCat
BEFORE INSERT POSITION 0
AS
BEGIN
DELETE FROM UslCat
WHERE ((BegDate >= new.BegDate) AND (EndDate <= new.EndDate) AND (PKey = new.PKey));
UPDATE UslCat
SET BegDate = new.EndDate
WHERE ((new.EndDate BETWEEN BegDate AND EndDate) AND (PKey = new.PKey));
UPDATE UslCat
SET EndDate = new.BegDate
WHERE ((new.BegDate BETWEEN BegDate AND EndDate) AND (PKey = new.PKey));
END ^
CREATE TRIGGER UslCat_BDH FOR UslCat
BEFORE DELETE POSITION 0
AS
BEGIN
UPDATE UslCat
SET EndDate = old.EndDate
WHERE ((EndDate = old.BegDate) AND (PKey = old.PKey));
END ^
CREATE TABLE UslCatKeys (
Code INTEGER NOT NULL
);
ALTER TABLE UslCatKeys
ADD CONSTRAINT XPKUslCatKeys PRIMARY KEY (Code);
CREATE TABLE UslDivisions (
Code INTEGER NOT NULL,
Name DESCR_TYPE,
PKey INTEGER NOT NULL,
Parent INTEGER NOT NULL,
BegDate DATE_TYPE,
EndDate DATE_TYPE
);
CREATE INDEX XIEUslDivisionsname ON UslDivisions
(
Name
);
CREATE INDEX XIEUslDivisionsParent ON UslDivisions
(
Parent
);
ALTER TABLE UslDivisions
ADD CONSTRAINT XPKUslDivisions PRIMARY KEY (Code);
CREATE TRIGGER UslDivisions_BUH FOR UslDivisions
BEFORE UPDATE POSITION 0
AS
BEGIN
/* Изменение BegDate */
IF (new.BegDate <> old.BegDate) THEN
BEGIN
IF (new.BegDate < old.BegDate) THEN
BEGIN
/* Расширение BegDate */
UPDATE UslDivisions
SET EndDate = new.BegDate
WHERE ((new.BegDate BETWEEN BegDate AND EndDate) AND (PKey = new.PKey));
END
ELSE
BEGIN
/* Сужение BegDate */
UPDATE UslDivisions
SET EndDate = new.BegDate
WHERE ((EndDate = old.BegDate) AND (PKey = new.PKey));
END
END
/* Изменение EndDate */
IF (new.EndDate <> old.EndDate) THEN
BEGIN
IF (new.EndDate > old.EndDate) THEN
BEGIN
/* Расширение EndDate */
UPDATE UslDivisions
SET BegDate = new.EndDate
WHERE ((new.EndDate BETWEEN BegDate AND EndDate) AND (PKey = new.PKey));
END
ELSE
BEGIN
/* Сужение EndDate */
UPDATE UslDivisions
SET BegDate = new.EndDate
WHERE ((BegDate = old.EndDate) AND (PKey = new.PKey));
END
END
/* Сборка мусора */
DELETE FROM UslDivisions
WHERE ((BegDate >= new.BegDate) AND (EndDate <= new.EndDate) AND (PKey = new.PKey) AND (Code <> new.Code));
END ^
CREATE TRIGGER UslDivisions_BIH FOR UslDivisions
BEFORE INSERT POSITION 0
AS
BEGIN
DELETE FROM UslDivisions
WHERE ((BegDate >= new.BegDate) AND (EndDate <= new.EndDate) AND (PKey = new.PKey));
UPDATE UslDivisions
SET BegDate = new.EndDate
WHERE ((new.EndDate BETWEEN BegDate AND EndDate) AND (PKey = new.PKey));
UPDATE UslDivisions
SET EndDate = new.BegDate
WHERE ((new.BegDate BETWEEN BegDate AND EndDate) AND (PKey = new.PKey));
END ^
CREATE TRIGGER UslDivisions_BDH FOR UslDivisions
BEFORE DELETE POSITION 0
AS
BEGIN
UPDATE UslDivisions
SET EndDate = old.EndDate
WHERE ((EndDate = old.BegDate) AND (PKey = old.PKey));
END ^
CREATE TABLE UslDivisionsKeys (
Code INTEGER NOT NULL
);
ALTER TABLE UslDivisionsKeys
ADD CONSTRAINT XPKUslDivisionsKeys PRIMARY KEY (Code);
CREATE TABLE UslLgots (
Code INTEGER NOT NULL,
Category INTEGER NOT NULL,
Property INTEGER,
Tax CURR_TYPE,
Usl INTEGER NOT NULL,
NachCoeff INTEGER NOT NULL,
Nalog INTEGER NOT NULL,
BegDate INTEGER NOT NULL,
Info INTEGER NOT NULL,
EndDate INTEGER NOT NULL
);
ALTER TABLE UslLgots
ADD CONSTRAINT XPKUslLgots PRIMARY KEY (Code);
CREATE TABLE UslProps (
Code INTEGER NOT NULL,
PKey INTEGER NOT NULL,
Tag INTEGER NOT NULL,
ValInteger INTEGER,
ValFloat FLOAT,
BegDate DATE_TYPE,
EndDate DATE_TYPE
);
ALTER TABLE UslProps
ADD CONSTRAINT XPKUslProps PRIMARY KEY (Code);
CREATE TRIGGER UslProps_BUH FOR UslProps
BEFORE UPDATE POSITION 0
AS
BEGIN
/* Изменение BegDate */
IF (new.BegDate <> old.BegDate) THEN
BEGIN
IF (new.BegDate < old.BegDate) THEN
BEGIN
/* Расширение BegDate */
UPDATE UslProps
SET EndDate = new.BegDate
WHERE ((new.BegDate BETWEEN BegDate AND EndDate) AND (PKey = new.PKey));
END
ELSE
BEGIN
/* Сужение BegDate */
UPDATE UslProps
SET EndDate = new.BegDate
WHERE ((EndDate = old.BegDate) AND (PKey = new.PKey));
END
END
/* Изменение EndDate */
IF (new.EndDate <> old.EndDate) THEN
BEGIN
IF (new.EndDate > old.EndDate) THEN
BEGIN
/* Расширение EndDate */
UPDATE UslProps
SET BegDate = new.EndDate
WHERE ((new.EndDate BETWEEN BegDate AND EndDate) AND (PKey = new.PKey));
END
ELSE
BEGIN
/* Сужение EndDate */
UPDATE UslProps
SET BegDate = new.EndDate
WHERE ((BegDate = old.EndDate) AND (PKey = new.PKey));
END
END
/* Сборка мусора */
DELETE FROM UslProps
WHERE ((BegDate >= new.BegDate) AND (EndDate <= new.EndDate) AND (PKey = new.PKey) AND (Code <> new.Code));
END ^
CREATE TRIGGER UslProps_BIH FOR UslProps
BEFORE INSERT POSITION 0
AS
BEGIN
DELETE FROM UslProps
WHERE ((BegDate >= new.BegDate) AND (EndDate <= new.EndDate) AND (PKey = new.PKey));
UPDATE UslProps
SET BegDate = new.EndDate
WHERE ((new.EndDate BETWEEN BegDate AND EndDate) AND (PKey = new.PKey));
UPDATE UslProps
SET EndDate = new.BegDate
WHERE ((new.BegDate BETWEEN BegDate AND EndDate) AND (PKey = new.PKey));
END ^
CREATE TRIGGER UslProps_BDH FOR UslProps
BEFORE DELETE POSITION 0
AS
BEGIN
UPDATE UslProps
SET EndDate = old.EndDate
WHERE ((EndDate = old.BegDate) AND (PKey = old.PKey));
END ^
CREATE TABLE UslPropsKeys (
Code INTEGER NOT NULL
);
ALTER TABLE UslPropsKeys
ADD CONSTRAINT XPKUslPropsKeys PRIMARY KEY (Code);
CREATE TABLE Usls (
Code INTEGER NOT NULL,
PKey INTEGER NOT NULL,
Division INTEGER NOT NULL,
UslType INTEGER NOT NULL,
Name CHAR(64) NOT NULL,
BegDate DATE_TYPE,
EndDate DATE_TYPE
);
CREATE INDEX XIEUslsName ON Usls
(
Name
);
ALTER TABLE Usls
ADD CONSTRAINT XPKUsls PRIMARY KEY (Code);
CREATE TRIGGER Usls_BUH FOR Usls
BEFORE UPDATE POSITION 0
AS
BEGIN
/* Изменение BegDate */
IF (new.BegDate <> old.BegDate) THEN
BEGIN
IF (new.BegDate < old.BegDate) THEN
BEGIN
/* Расширение BegDate */
UPDATE Usls
SET EndDate = new.BegDate
WHERE ((new.BegDate BETWEEN BegDate AND EndDate) AND (PKey = new.PKey));
END
ELSE
BEGIN
/* Сужение BegDate */
UPDATE Usls
SET EndDate = new.BegDate
WHERE ((EndDate = old.BegDate) AND (PKey = new.PKey));
END
END
/* Изменение EndDate */
IF (new.EndDate <> old.EndDate) THEN
BEGIN
IF (new.EndDate > old.EndDate) THEN
BEGIN
/* Расширение EndDate */
UPDATE Usls
SET BegDate = new.EndDate
WHERE ((new.EndDate BETWEEN BegDate AND EndDate) AND (PKey = new.PKey));
END
ELSE
BEGIN
/* Сужение EndDate */
UPDATE Usls
SET BegDate = new.EndDate
WHERE ((BegDate = old.EndDate) AND (PKey = new.PKey));
END
END
/* Сборка мусора */
DELETE FROM Usls
WHERE ((BegDate >= new.BegDate) AND (EndDate <= new.EndDate) AND (PKey = new.PKey) AND (Code <> new.Code));
END ^
CREATE TRIGGER Usls_BIH FOR Usls
BEFORE INSERT POSITION 0
AS
BEGIN
DELETE FROM Usls
WHERE ((BegDate >= new.BegDate) AND (EndDate <= new.EndDate) AND (PKey = new.PKey));
UPDATE Usls
SET BegDate = new.EndDate
WHERE ((new.EndDate BETWEEN BegDate AND EndDate) AND (PKey = new.PKey));
UPDATE Usls
SET EndDate = new.BegDate
WHERE ((new.BegDate BETWEEN BegDate AND EndDate) AND (PKey = new.PKey));
END ^
CREATE TRIGGER Usls_BDH FOR Usls
BEFORE DELETE POSITION 0
AS
BEGIN
UPDATE Usls
SET EndDate = old.EndDate
WHERE ((EndDate = old.BegDate) AND (PKey = old.PKey));
END ^
CREATE TABLE UslsKeys (
Code INTEGER NOT NULL
);
ALTER TABLE UslsKeys
ADD CONSTRAINT XPKUslsKeys PRIMARY KEY (Code);
CREATE TABLE UslTypes (
Code INTEGER NOT NULL,
Name DESCR_TYPE
);
ALTER TABLE UslTypes
ADD CONSTRAINT XPKUslTypes PRIMARY KEY (Code);
ALTER TABLE Nach
ADD CONSTRAINT R_59
FOREIGN KEY (Usl)
REFERENCES UslsKeys;
ALTER TABLE Nach
ADD CONSTRAINT R_57
FOREIGN KEY (Phone)
REFERENCES PhonesKeys;
ALTER TABLE Nach
ADD FOREIGN KEY (Owner)
REFERENCES PhonesOwnersKeys;
ALTER TABLE NachBillings
ADD CONSTRAINT R_65
FOREIGN KEY (Division)
REFERENCES UslDivisionsKeys;
ALTER TABLE NachBillings
ADD FOREIGN KEY (BillDateCode)
REFERENCES NachBillDates;
ALTER TABLE NachBillings
ADD FOREIGN KEY (Owner)
REFERENCES PhonesOwnersKeys;
ALTER TABLE NachConstUsl
ADD CONSTRAINT R_60
FOREIGN KEY (Usl)
REFERENCES UslsKeys;
ALTER TABLE NachConstUsl
ADD CONSTRAINT R_58
FOREIGN KEY (Phone)
REFERENCES PhonesKeys;
ALTER TABLE NachConstUsl
ADD FOREIGN KEY (Owner)
REFERENCES PhonesOwnersKeys;
ALTER TABLE Phones
ADD FOREIGN KEY (Owner)
REFERENCES PhonesOwnersKeys;
ALTER TABLE Phones
ADD FOREIGN KEY (PKey)
REFERENCES PhonesKeys;
ALTER TABLE Phones
ADD FOREIGN KEY (Street)
REFERENCES PhonesStreets;
ALTER TABLE PhonesOwners
ADD FOREIGN KEY (PostStation)
REFERENCES PhonesPostStations;
ALTER TABLE PhonesOwners
ADD FOREIGN KEY (Street)
REFERENCES PhonesStreets;
ALTER TABLE PhonesOwners
ADD FOREIGN KEY (Bank)
REFERENCES PhonesBanks;
ALTER TABLE PhonesOwners
ADD FOREIGN KEY (Category)
REFERENCES UslCatKeys;
ALTER TABLE PhonesOwners
ADD FOREIGN KEY (PKey)
REFERENCES PhonesOwnersKeys;
ALTER TABLE PhonesPostStations
ADD CONSTRAINT R_62
FOREIGN KEY (Region)
REFERENCES PhonesRegions;
ALTER TABLE PhonesStations
ADD FOREIGN KEY (Region)
REFERENCES PhonesRegions;
ALTER TABLE PhonesStreets
ADD FOREIGN KEY (Region)
REFERENCES PhonesRegions;
ALTER TABLE PhonesStreets
ADD FOREIGN KEY (Station)
REFERENCES PhonesStations;
ALTER TABLE Plat
ADD CONSTRAINT R_61
FOREIGN KEY (ToUsl)
REFERENCES UslsKeys;
ALTER TABLE Plat
ADD FOREIGN KEY (Owner)
REFERENCES PhonesOwnersKeys;
ALTER TABLE SysSettings
ADD FOREIGN KEY (NullOwner)
REFERENCES PhonesOwnersKeys;
ALTER TABLE SysSettings
ADD FOREIGN KEY (TimeTalksUsl)
REFERENCES UslsKeys;
ALTER TABLE Talks
ADD FOREIGN KEY (ToPhone)
REFERENCES PhonesKeys;
ALTER TABLE Talks
ADD FOREIGN KEY (Phone)
REFERENCES PhonesKeys;
ALTER TABLE Talks
ADD FOREIGN KEY (DayCode)
REFERENCES TalksPay;
ALTER TABLE TalksPay
ADD FOREIGN KEY (Phone)
REFERENCES PhonesKeys;
ALTER TABLE UslCat
ADD FOREIGN KEY (PKey)
REFERENCES UslCatKeys;
ALTER TABLE UslDivisions
ADD CONSTRAINT R_63
FOREIGN KEY (PKey)
REFERENCES UslDivisionsKeys;
ALTER TABLE UslLgots
ADD CONSTRAINT R_50
FOREIGN KEY (Property)
REFERENCES UslPropsKeys;
ALTER TABLE UslLgots
ADD FOREIGN KEY (Usl)
REFERENCES UslsKeys;
ALTER TABLE UslLgots
ADD FOREIGN KEY (Category)
REFERENCES UslCatKeys;
ALTER TABLE UslProps
ADD CONSTRAINT R_51
FOREIGN KEY (PKey)
REFERENCES UslPropsKeys;
ALTER TABLE Usls
ADD CONSTRAINT R_64
FOREIGN KEY (Division)
REFERENCES UslDivisionsKeys;
ALTER TABLE Usls
ADD FOREIGN KEY (UslType)
REFERENCES UslTypes;
ALTER TABLE Usls
ADD FOREIGN KEY (PKey)
REFERENCES UslsKeys;
CREATE PROCEDURE PrGenUslPropsKeys
RETURNS (ACode INTEGER)
AS
BEGIN
ACode = GEN_ID(genUslPropsKeys, 1);
END ^
CREATE PROCEDURE PrGenUslProps
RETURNS (ACode INTEGER)
AS
BEGIN
ACode = GEN_ID(genUslProps, 1);
END ^
CREATE PROCEDURE PrGenPhonesRegions
RETURNS (ACode INTEGER)
AS
BEGIN
ACode = GEN_ID(genPhonesRegions, 1);
END ^
CREATE PROCEDURE PrGenPhonesStations
RETURNS (ACode INTEGER)
AS
BEGIN
ACode = GEN_ID(genPhonesStations, 1);
END ^
CREATE PROCEDURE PrGenPhonesStreets
RETURNS (ACode INTEGER)
AS
BEGIN
ACode = GEN_ID(genPhonesStreets, 1);
END ^
CREATE PROCEDURE PrGenPhonesBanks
RETURNS (ACode INTEGER)
AS
BEGIN
ACode = GEN_ID(genPhonesBanks, 1);
END ^
CREATE PROCEDURE PrGenTalksPay
RETURNS (ACode INTEGER)
AS
BEGIN
ACode = GEN_ID(genTalksPay, 1);
END ^
CREATE PROCEDURE PrGenTalks
RETURNS (ACode INTEGER)
AS
BEGIN
ACode = GEN_ID(genTalks, 1);
END ^
CREATE PROCEDURE PrGenNach
RETURNS (ACode INTEGER)
AS
BEGIN
ACode = GEN_ID(genNach, 1);
END ^
CREATE PROCEDURE PrGenNachBillings
RETURNS (ACode INTEGER)
AS
BEGIN
ACode = GEN_ID(genNachBillings, 1);
END ^
CREATE PROCEDURE PrGenNachBillDates
RETURNS (ACode INTEGER)
AS
BEGIN
ACode = GEN_ID(genNachBillDates, 1);
END ^
CREATE PROCEDURE PrGenNachConstUsl
RETURNS (ACode INTEGER)
AS
BEGIN
ACode = GEN_ID(genNachConstUsl, 1);
END ^
CREATE PROCEDURE PrGenUslDivisions
RETURNS (ACode INTEGER)
AS
BEGIN
ACode = GEN_ID(genUslDivisions, 1);
END ^
CREATE PROCEDURE PrGenUslLgots
RETURNS (ACode INTEGER)
AS
BEGIN
ACode = GEN_ID(genUslLgots, 1);
END ^
CREATE PROCEDURE PrGenUslsKeys
RETURNS (ACode INTEGER)
AS
BEGIN
ACode = GEN_ID(genUslsKeys, 1);
END ^
CREATE PROCEDURE PrGenUsls
RETURNS (ACode INTEGER)
AS
BEGIN
ACode = GEN_ID(genUsls, 1);
END ^
CREATE PROCEDURE PrGenUslCatKeys
RETURNS (ACode INTEGER)
AS
BEGIN
ACode = GEN_ID(genUslCatKeys, 1);
END ^
CREATE PROCEDURE PrGenUslCat
RETURNS (ACode INTEGER)
AS
BEGIN
ACode = GEN_ID(genUslCat, 1);
END ^
CREATE PROCEDURE PrGenPhones
RETURNS (ACode INTEGER)
AS
BEGIN
ACode = GEN_ID(genPhones, 1);
END ^
CREATE PROCEDURE PrGenPhonesOwnersKeys
RETURNS (ACode INTEGER)
AS
BEGIN
ACode = GEN_ID(genPhonesOwnersKeys, 1);
END ^
CREATE PROCEDURE PrGenPhonesOwners
RETURNS (ACode INTEGER)
AS
BEGIN
ACode = GEN_ID(genPhonesOwners, 1);
END ^
CREATE PROCEDURE PrGenSysSettings
RETURNS (ACode INTEGER)
AS
BEGIN
ACode = GEN_ID(genSysSettings, 1);
END ^
CREATE PROCEDURE PrGenPhonesKeys
RETURNS (ACode INTEGER)
AS
BEGIN
ACode = GEN_ID(genPhonesKeys, 1);
END ^
CREATE PROCEDURE PrGenPlat
RETURNS (ACode INTEGER)
AS
BEGIN
ACode = GEN_ID(genPlat, 1);
END ^
CREATE PROCEDURE PrGenPhonesPostStations
RETURNS (ACode INTEGER)
AS
BEGIN
ACode = GEN_ID(genPhonesPostStations, 1);
END ^
CREATE PROCEDURE PrGenSysLog
RETURNS (ACode INTEGER)
AS
BEGIN
ACode = GEN_ID(genSysLog, 1);
END ^
CREATE PROCEDURE PrGenUslTypes
RETURNS (ACode INTEGER)
AS
BEGIN
ACode = GEN_ID(genUslTypes, 1);
END ^
CREATE PROCEDURE PrGenUslDivisionsKeys
RETURNS (ACode INTEGER)
AS
BEGIN
ACode = GEN_ID(genUslDivisionsKeys, 1);
END ^
^
CREATE PROCEDURE TalksExamineOwner (APhoneNmb CHAR(7), ADate DATE)
RETURNS (APhone INTEGER)
AS
DECLARE VARIABLE AStreet INTEGER;
DECLARE VARIABLE NOwner INTEGER;
DECLARE VARIABLE APhoneCode INTEGER;
BEGIN
SELECT PKey FROM Phones WHERE (PhoneNmb = :APhoneNmb) AND (:ADate BETWEEN BegDate AND EndDate)
INTO :APhone;
IF (:APhone IS NULL) THEN
BEGIN
SELECT NullOwner FROM SysSettings INTO :NOwner;
SELECT Street FROM PhonesOwners
WHERE (PKey = :NOwner) AND (:ADate BETWEEN PhonesOwners.BegDate AND PhonesOwners.EndDate)
INTO :AStreet;
IF (:AStreet IS NOT NULL) THEN
BEGIN
EXECUTE PROCEDURE PrGenPhonesKeys RETURNING_VALUES :APhone;
INSERT INTO PhonesKeys (Code)
VALUES (:APhone);
INSERT INTO Phones(Owner, PKey, PhoneNmb, Street, InstallDate, RemoveDate, BegDate, EndDate)
VALUES (:NOwner, :APhone, :APhoneNmb, :AStreet, :ADate, "12.12.2222", :ADate, "12.12.2222");
END
END
END ^
CREATE PROCEDURE TalksGetTax
AS
BEGIN
EXIT;
END ^
CREATE PROCEDURE TalksGetPay (APhone INTEGER, ADay DATE, ACallTime INTEGER, AHowLong INTEGER)
RETURNS (APay FLOAT, ACalculated SMALLINT, IsLgot SMALLINT)
AS
DECLARE VARIABLE ATax FLOAT;
DECLARE VARIABLE AProcNach FLOAT;
DECLARE VARIABLE ATalksUsl INTEGER;
DECLARE VARIABLE AOwner INTEGER;
DECLARE VARIABLE ANalog FLOAT;
BEGIN
ACalculated = 0;
SELECT TimeTalksUsl FROM SysSettings INTO :ATalksUsl;
IF (:ATalksUsl IS NULL) THEN EXIT;
SELECT Owner FROM Phones WHERE (PKey = :APhone) AND (:ADay BETWEEN BegDate AND EndDate)
INTO :AOwner;
IF (:AOwner IS NULL) THEN EXIT;
EXECUTE PROCEDURE UslGetOwnerTax(:AOwner, :ATalksUsl, :ADay)
RETURNING_VALUES :ATax, :AProcNach, :ANalog;
IF (:ATax IS NULL) THEN EXIT;
APay = ATax*AHowLong*AProcNach/3000;
ACalculated = 1;
END ^
CREATE PROCEDURE TalksCallBilling (APhone INTEGER, ACallDate DATE, ACallTime INTEGER, AHowLong INTEGER)
RETURNS (ATalksPayCode INTEGER, ACalculated SMALLINT)
AS
DECLARE VARIABLE APay FLOAT;
DECLARE VARIABLE PayCode INTEGER;
DECLARE VARIABLE IsLgot SMALLINT;
DECLARE VARIABLE TTime INTEGER;
DECLARE VARIABLE LTime INTEGER;
BEGIN
EXECUTE PROCEDURE TalksGetPay(APhone, ACallDate, ACallTime, AHowLong)
RETURNING_VALUES :APay, :ACalculated, :IsLgot;
SELECT Code FROM TalksPay WHERE (Phone = :APhone) AND (CallDate = :ACallDate)
INTO PayCode;
IF (:ACalculated = 0) THEN EXIT;
IF (:IsLgot = 0) THEN BEGIN
TTime = AHowLong;
LTime = 0;
END
ELSE BEGIN
LTime = AHowLong;
TTime = 0;
END
IF (:PayCode IS NULL) THEN BEGIN
EXECUTE PROCEDURE PrGenTalksPay RETURNING_VALUES :PayCode;
INSERT INTO TalksPay (Code, Phone, CallDate, TotalSum, TotalFullTime, TotalLgotTime)
VALUES (:PayCode, :APhone, :ACallDate, :APay, :TTime, :LTime);
END
ELSE BEGIN
UPDATE TalksPay
SET TotalSum = TotalSum+:APay,
TotalFullTime = TotalFullTime+:TTime,
TotalLgotTime = TotalLgotTime+:LTime
WHERE Code = :PayCode;
END
END ^
CREATE PROCEDURE UslGetOwnerTax(AOwner INTEGER, AUsl INTEGER, ADate DATE)
RETURNS (ATax FLOAT,
AProcNach FLOAT,
ANalog FLOAT)
AS
DECLARE VARIABLE ACategory INTEGER;
BEGIN
SELECT Category FROM PhonesOwners
WHERE (PKey = :AOwner) AND (:ADate BETWEEN BegDate AND EndDate)
INTO :ACategory;
SELECT Tax, NachCoeff, Nalog FROM UslLgots
WHERE (Usl = :AUsl) AND (:ADate BETWEEN BegDate AND EndDate)
INTO :ATax, :AProcNach, :ANalog;
EXIT;
END
Приложение 2

Приложение 3
Исходные тексты коммуникационного сервиса
ServiceMain.c
Файл ServiceMain.c - Модуль инициализации и управления сервером.
/*************************************************************/
/* Main unit for Communication Service */
/* Copyright (c) 1997 by Malkov O.V. */
/* JSC "Svyazinform" RM */
/*************************************************************/
#include <windows.h>
#include "DoService.h"
#include "CommonConfig.h"
/* Globals */
SERVICE_STATUS ServiceStatus;
SERVICE_STATUS_HANDLE ServiceStatusHandle;
/* Function Prototypes */
void WINAPI ServiceStart (DWORD argc, LPTSTR *argv);
VOID WINAPI ServiceCtrlHandler (IN DWORD opcode);
DWORD ServiceInitialization(DWORD argc, LPTSTR *argv,
DWORD *specificError);
VOID _CRTAPI1 main(int argc, char **argv)
{
int i;
SERVICE_TABLE_ENTRY DispatchTable[] = {
{ TEXT("SiTime"), ServiceStart },
{ NULL, NULL }
};
/* Allow the user to override settings with command line switches */
for ( i = 1; i < argc; i++) {
if ((*argv[i] == '-') || (*argv[i] == '/')) {
switch (tolower(*(argv[i]+1))) {
case 'p': // protocol sequence
pszProtocolSequence = argv[++i];
break;
case 'e': // endpoint
pszEndpoint = argv[++i];
break;
default: ;
}
}
}
if (!StartServiceCtrlDispatcher( DispatchTable)) {
/* Error Handling */
}
}
void WINAPI ServiceStart(DWORD argc, LPTSTR *argv)
{
DWORD status;
DWORD specificError;
ServiceStatus.dwServiceType = SERVICE_WIN32;
ServiceStatus.dwCurrentState = SERVICE_START_PENDING;
ServiceStatus.dwControlsAccepted = SERVICE_ACCEPT_STOP |
SERVICE_ACCEPT_PAUSE_CONTINUE;
ServiceStatus.dwWin32ExitCode = 0;
ServiceStatus.dwServiceSpecificExitCode = 0;
ServiceStatus.dwCheckPoint = 0;
ServiceStatus.dwWaitHint = 0;
ServiceStatusHandle = RegisterServiceCtrlHandler(
TEXT("SiTime"),
ServiceCtrlHandler);
if (ServiceStatusHandle == (SERVICE_STATUS_HANDLE)0) {
/* Error Handling */
return;
}
// Initialization code goes here.
status = ServiceInitialization(argc,argv, &specificError);
// Handle error condition
if (status != NO_ERROR) {
ServiceStatus.dwCurrentState = SERVICE_STOPPED;
ServiceStatus.dwCheckPoint = 0;
ServiceStatus.dwWaitHint = 0;
ServiceStatus.dwWin32ExitCode = status;
ServiceStatus.dwServiceSpecificExitCode = specificError;
SetServiceStatus (ServiceStatusHandle, &ServiceStatus);
return;
}
// Initialization complete - report running status
ServiceStatus.dwCurrentState = SERVICE_RUNNING;
ServiceStatus.dwCheckPoint = 0;
ServiceStatus.dwWaitHint = 0;
if (!SetServiceStatus (ServiceStatusHandle, &ServiceStatus)) {
status = GetLastError();
}
// This is where the service does its work. //
ServerProcess();
return;
}
/* stub initialization function */
DWORD ServiceInitialization(DWORD argc, LPTSTR *argv,
DWORD *specificError)
{
*specificError = ServerInit();
if (*specificError) return *specificError;
return(0);
}
void WINAPI ServiceCtrlHandler ( IN DWORD Opcode)
{
DWORD status;
switch(Opcode) {
case SERVICE_CONTROL_PAUSE:
/* Do whatever it takes to pause here. */
ServerDoPause();
ServiceStatus.dwCurrentState = SERVICE_PAUSED;
break;
case SERVICE_CONTROL_CONTINUE:
/* Do whatever it takes to continue here.*/
ServerDoContinue();
ServiceStatus.dwCurrentState = SERVICE_RUNNING;
break;
case SERVICE_CONTROL_STOP:
/* Do whatever it takes to stop here. */
ServerDoStop();
ServiceStatus.dwWin32ExitCode = 0;
ServiceStatus.dwCurrentState = SERVICE_STOPPED;
ServiceStatus.dwCheckPoint = 0;
ServiceStatus.dwWaitHint = 0;
if (!SetServiceStatus (ServiceStatusHandle, &ServiceStatus))
{
status = GetLastError();
}
return;
case SERVICE_CONTROL_INTERROGATE:
/* fall through to send current status */
break;
default:
/* Error handling */
break;
}
/* Send current status.*/
if (!SetServiceStatus (ServiceStatusHandle, &ServiceStatus)) {
status = GetLastError();
}
return;
}
CommonConfig.c
Файл CommonConfig.c - Управление конфигурацией
#include <windows.h>
#include "CommonConfig.h"
#include "EventLog.h"
#define REGVALUENAME_LENGTH 255
DWORD ConfigWatchingThread;
HANDLE hConfigMutex = NULL;
HANDLE hTaskMutex = NULL;
unsigned char * pszProtocolSequence = "ncacn_np";
unsigned char * pszSecurity = NULL;
unsigned char * pszEndpoint = "\\pipe\\CommServ";
unsigned int cMinCalls = 1;
unsigned int cMaxCalls = 20;
unsigned int fDontWait = FALSE;
struct TASKENTRY TaskTable[TASK_COUNT];
int EntryCount = 0;
DWORD TaskThreads[TASK_COUNT];
int TaskCount = 0;
void UpdateVariables()
{
HKEY hKey;
DWORD dwIndex = 0;
DWORD VNameLength = REGVALUENAME_LENGTH;
char VName[REGVALUENAME_LENGTH];
DWORD dwLength = sizeof(struct TASKENTRY);
int i;
__try {
WaitForSingleObject(hConfigMutex, INFINITE);
// Инициализация таблицы задач
for (i = 0; i < TASK_COUNT; i++) {
TaskTable[i].Active = FALSE;
TaskTable[i].ExecTime = 0;
ZeroMemory(&TaskTable[i].DllName, sizeof(TaskTable[i].DllName));
TaskTable[i].TermProc = NULL;
TaskTable[i].TaskThread = 0;
}
// Загрузка таблицы задач из реестра
if (RegOpenKeyEx(HKEY_LOCAL_MACHINE,
REGISTRY_TASKS_PATH,
0, KEY_ALL_ACCESS, &hKey) == ERROR_SUCCESS) {
dwIndex = 0;
EntryCount = 0;
while (RegEnumValue(hKey,
dwIndex,
(char *)&VName,
&VNameLength,
NULL,
NULL,
(LPVOID)&TaskTable[dwIndex],
&dwLength) == ERROR_SUCCESS) {
if (dwLength != sizeof(struct TASKENTRY)) {
LogEvent(EVENTLOG_ERROR_TYPE, "Invalid Task Parameter");
break;
}
EntryCount+=1;
dwIndex+=1;
}
RegCloseKey(hKey);
} else LogEvent(EVENTLOG_ERROR_TYPE, "Error Loading Configuration");
}
__finally {
ReleaseMutex(hConfigMutex);
}
}
DoService.c
#include <windows.h>
#include "DoService.h"
#include "..\Comm.h"
#include "CommonConfig.h"
#include "ClientHandler.h"
#include "EventLog.h"
#include "ShedulerServ.h"
void ServerProcess() {
hConfigMutex = CreateMutex(NULL, FALSE, NULL);
hTaskMutex = CreateMutex(NULL, FALSE, NULL);
CreateThread(NULL, 0, ShedulingProc, NULL, 0, &ShedulingThread);
CreateThread(NULL, 0, RPCClientHandling, NULL, 0, &ClientHandlingThread);
}
DWORD ServerInit() {
RPC_STATUS status;
status = RpcServerUseProtseqEp(
pszProtocolSequence,
cMaxCalls,
pszEndpoint,
pszSecurity); // Security descriptor
if (status != NO_ERROR) {
return(1);
}
status = RpcServerRegisterIf(
CommService_ServerIfHandle, // !!!
NULL, // MgrTypeUuid
NULL); // MgrEpv; null means use default
if (status != NO_ERROR) {
return(2);
}
LogEvent(EVENTLOG_INFORMATION_TYPE, "\"Svyazinform\" Communicatin Service Initialized");
return(0);
}
void ServerDoPause()
{
SuspendThread(&ShedulingThread);
SuspendThread(&ClientHandlingThread);
LogEvent(EVENTLOG_INFORMATION_TYPE, "\"Svyazinform\" Communicatin Service Paused");
}
void ServerDoContinue()
{
ResumeThread(&ShedulingThread);
ResumeThread(&ClientHandlingThread);
LogEvent(EVENTLOG_INFORMATION_TYPE, "\"Svyazinform\" Communicatin Service Resumed");
}
void ServerDoStop() {
RPC_STATUS status;
status = RpcMgmtStopServerListening(NULL);
if (status != NO_ERROR) {
// Error handling
}
status = RpcServerUnregisterIf(NULL, NULL, FALSE);
if (status != NO_ERROR) {
// Error handling
}
TerminateTasks();
WaitForSingleObject(&ClientHandlingThread, 5000);
CloseHandle(&ClientHandlingThread);
InterlockedIncrement(&TerminateSheduling);
WaitForSingleObject(&ShedulingThread, 5000);
CloseHandle(&ShedulingThread);
WaitForSingleObject(hConfigMutex, 3000);
ReleaseMutex(hConfigMutex);
CloseHandle(hConfigMutex);
WaitForSingleObject(hTaskMutex, 3000);
ReleaseMutex(hTaskMutex);
CloseHandle(hTaskMutex);
LogEvent(EVENTLOG_INFORMATION_TYPE, "\"Svyazinform\" Communicatin Service Stopped");
}
/**************************************************************/
/* MIDL allocate and free */
/**************************************************************/
void __RPC_FAR * __RPC_USER midl_user_allocate(size_t len)
{
return(malloc(len));
}
void __RPC_USER midl_user_free(void __RPC_FAR * ptr)
{
free(ptr);
}
ClientHandler.c
/**********************************************************/
/* Этот модуль обрабатывает подключения клиентов */
/**********************************************************/
#include <windows.h>
#include "ClientHandler.h"
#include "CommonConfig.h"
#include "../Comm.h"
DWORD ClientHandlingThread;
DWORD WINAPI RPCClientHandling(LPVOID ThreadParm)
{
RPC_STATUS status;
status = RpcServerListen(
cMinCalls,
cMaxCalls,
fDontWait);
if (status != NO_ERROR) {
return 1;
}
return 0;
}
void RefreshIniProps()
{
MessageBeep(1);
return;
}
EventLog.c
#include <windows.h>
#include "EventLog.h"
void LogEvent(WORD EventType, LPSTR EventMsg)
{
HANDLE h;
h = RegisterEventSource(NULL, /* uses local computer */
"CommServ"); /* source name */
if (h != NULL)
{
ReportEvent(h, /* event log handle */
EventType, /* event type */
0, /* category zero */
0x1003, /* event identifier */
NULL, /* no user security identifier */
1, /* one substitution string */
0, /* no data */
&EventMsg, /* address of string array */
NULL); /* address of data */
DeregisterEventSource(h);
}
return;
}
Comm_s.c
/* this ALWAYS GENERATED file contains the RPC server stubs */
/* File created by MIDL compiler version 3.00.15 */
/* at Tue Jun 03 11:35:46 1997
*/
/* Compiler settings for comm.idl:
Os, W1, Zp8, env=Win32, ms_ext, c_ext, oldnames
error checks: none
*/
//@@MIDL_FILE_HEADING( )
#include <string.h>
#include "comm.h"
#define TYPE_FORMAT_STRING_SIZE 1
#define PROC_FORMAT_STRING_SIZE 3
typedef struct _MIDL_TYPE_FORMAT_STRING
{
short Pad;
unsigned char Format[ TYPE_FORMAT_STRING_SIZE ];
} MIDL_TYPE_FORMAT_STRING;
typedef struct _MIDL_PROC_FORMAT_STRING
{
short Pad;
unsigned char Format[ PROC_FORMAT_STRING_SIZE ];
} MIDL_PROC_FORMAT_STRING;
extern const MIDL_TYPE_FORMAT_STRING __MIDLTypeFormatString;
extern const MIDL_PROC_FORMAT_STRING __MIDLProcFormatString;
/* Standard interface: CommService, ver. 1.0,
GUID={0x4a25d2e0,0x6703,0x11d0,{0x89,0x27,0x00,0xa0,0x24,0x13,0x85,0x0e}} */
extern RPC_DISPATCH_TABLE CommService_DispatchTable;
static const RPC_SERVER_INTERFACE CommService___RpcServerInterface =
{
sizeof(RPC_SERVER_INTERFACE),
{{0x4a25d2e0,0x6703,0x11d0,{0x89,0x27,0x00,0xa0,0x24,0x13,0x85,0x0e}},{1,0}},
{{0x8A885D04,0x1CEB,0x11C9,{0x9F,0xE8,0x08,0x00,0x2B,0x10,0x48,0x60}},{2,0}},
&CommService_DispatchTable,
0,
0,
0,
0,
0
};
RPC_IF_HANDLE CommService_ServerIfHandle = (RPC_IF_HANDLE)& CommService___RpcServerInterface;
extern const MIDL_STUB_DESC CommService_StubDesc;
void __RPC_STUB
CommService_RefreshIniProps(
PRPC_MESSAGE _pRpcMessage )
{
MIDL_STUB_MESSAGE _StubMsg;
RPC_STATUS _Status;
((void)(_Status));
NdrServerInitializeNew(
_pRpcMessage,
&_StubMsg,
&CommService_StubDesc);
RpcTryFinally
{
RefreshIniProps();
}
RpcFinally
{
}
RpcEndFinally
_pRpcMessage->BufferLength =
(unsigned int)((long)_StubMsg.Buffer - (long)_pRpcMessage->Buffer);
}
static const MIDL_STUB_DESC CommService_StubDesc =
{
(void __RPC_FAR *)& CommService___RpcServerInterface,
MIDL_user_allocate,
MIDL_user_free,
0,
0,
0,
0,
0,
__MIDLTypeFormatString.Format,
0, /* -error bounds_check flag */
0x10001, /* Ndr library version */
0,
0x300000f, /* MIDL Version 3.0.15 */
0,
0,
0, /* Reserved1 */
0, /* Reserved2 */
0, /* Reserved3 */
0, /* Reserved4 */
0 /* Reserved5 */
};
static RPC_DISPATCH_FUNCTION CommService_table[] =
{
CommService_RefreshIniProps,
0
};
RPC_DISPATCH_TABLE CommService_DispatchTable =
{
1,
CommService_table
};
#if !defined(__RPC_WIN32__)
#error Invalid build platform for this stub.
#endif
static const MIDL_PROC_FORMAT_STRING __MIDLProcFormatString =
{
0,
{
0x5b, /* FC_END */
0x5c, /* FC_PAD */
0x0
}
};
static const MIDL_TYPE_FORMAT_STRING __MIDLTypeFormatString =
{
0,
{
0x0
}
};
ShedulerServ.c
/**********************************************************//* Task Sheduler
/**********************************************************/
#include <windows.h>
#include "ShedulerServ.h"
#include "CommonConfig.h"
#include "EventLog.h"
#define SLEEP_INTERVAL 5000
#define ACTIVATE_INTERVAL 60000
BOOL TerminateSheduling = FALSE;
DWORD ShedulingThread;
DWORD WINAPI TaskProc(LPVOID ThreadParm);
void AnalyseTaskTable();
DWORD GetTimeInMins();
DWORD WINAPI ShedulingProc(LPVOID ThreadParm)
{
long i = 0;
while (!TerminateSheduling) {
if ((i += SLEEP_INTERVAL) >= ACTIVATE_INTERVAL) {
i = 0;
if (TaskCount == 0) UpdateVariables();
AnalyseTaskTable();
}
Sleep(SLEEP_INTERVAL);
}
return 0;
}
DWORD WINAPI TaskProc(LPVOID ThreadParm)
{
HINSTANCE hLib;
FARPROC hProc;
InterlockedIncrement(&TaskCount);
WaitForSingleObject(hConfigMutex, INFINITE);
MessageBeep(1);
if (hLib = LoadLibrary((char *)&((struct TASKENTRY*)ThreadParm)->DllName)) {
if (((struct TASKENTRY*)ThreadParm)->TermProc = GetProcAddress(hLib, (LPCSTR)TaskProcName))
{
((struct TASKENTRY*)ThreadParm)->Active = TRUE;
ReleaseMutex(hConfigMutex);
if (hProc = GetProcAddress(hLib, (LPCSTR)TaskProcName)) {
hProc();
__try {
WaitForSingleObject(hConfigMutex, INFINITE);
((struct TASKENTRY*)ThreadParm)->Active = FALSE;
CloseHandle((HANDLE)((struct TASKENTRY*)ThreadParm)->TaskThread);
}
__finally {
ReleaseMutex(hConfigMutex);
}
} else LogEvent(EVENTLOG_ERROR_TYPE, "Error Getting Procedure Address");
} else LogEvent(EVENTLOG_ERROR_TYPE, "Error Getting TermProc Address");
} else {
ReleaseMutex(hConfigMutex);
LogEvent(EVENTLOG_ERROR_TYPE, "Error Loading Library");
}
InterlockedDecrement(&TaskCount);
return 0;
}
void AnalyseTaskTable()
{
DWORD CurrTime;
int i;
CurrTime = GetTimeInMins();
__try {
WaitForSingleObject(hConfigMutex, INFINITE);
for (i = 0; i < EntryCount; i++) {
if ((TaskTable[i].ExecTime == CurrTime) &&
(!TaskTable[i].Active)) {
CreateThread(NULL, 0, TaskProc, &TaskTable[i], 0, &TaskTable[i].TaskThread);
}
}
}
__finally {
ReleaseMutex(hConfigMutex);
}
}
DWORD GetTimeInMins()
{
SYSTEMTIME SysTime;
GetLocalTime(&SysTime);
return SysTime.wHour*60+SysTime.wMinute;
}
void TerminateTasks()
{
int i;
DWORD TaskIndex = 0;
HANDLE Handles[TASK_COUNT];
for (i = 0; i < EntryCount; i++) {
if (TaskTable[i].Active) {
TaskTable[i].TermProc();
Handles[TaskIndex++] = (HANDLE)TaskTable[i].TaskThread;
}
}
WaitForMultipleObjects(TaskIndex, Handles, TRUE, INFINITE);
}
Comm.h
/* this ALWAYS GENERATED file contains the definitions for the interfaces */
/* File created by MIDL compiler version 3.00.15 */
/* at Tue Jun 03 11:35:46 1997
*/
/* Compiler settings for comm.idl:
Os, W1, Zp8, env=Win32, ms_ext, c_ext, oldnames
error checks: none
*/
//@@MIDL_FILE_HEADING( )
#include "rpc.h"
#include "rpcndr.h"
#ifndef __comm_h__
#define __comm_h__
#ifdef __cplusplus
extern "C"{
#endif
/* Forward Declarations */
void __RPC_FAR * __RPC_USER MIDL_user_allocate(size_t);
void __RPC_USER MIDL_user_free( void __RPC_FAR * );
#ifndef __CommService_INTERFACE_DEFINED__
#define __CommService_INTERFACE_DEFINED__
/****************************************
* Generated header for interface: CommService
* at Tue Jun 03 11:35:46 1997
* using MIDL 3.00.15
****************************************/
/* [implicit_handle][version][uuid] */
void RefreshIniProps( void);
extern handle_t CommServ_IfHandle;
extern RPC_IF_HANDLE CommService_ClientIfHandle;
extern RPC_IF_HANDLE CommService_ServerIfHandle;
#endif /* __CommService_INTERFACE_DEFINED__ */
/* Additional Prototypes for ALL interfaces */
/* end of Additional Prototypes */
#ifdef __cplusplus
}
#endif
#endif
DoService.h
/**************************************************************/
/* DoService Module - implementation of initialisation other
/* tasks */
/* */
/* Copuright (c) 1997 by Malkov O.V. */
/* JSC "Svyazinform" RM */
/**************************************************************/
#ifndef __DOSERVICE
#define __DESERVICE
void ServerProcess();
DWORD ServerInit();
void ServerDoPause();
void ServerDoStop();
void ServerDoContinue();
#endif
CommonConfig.h
/**************** Server Engine Header File *******************/
#ifndef __COMMON_CONFIG
#define __COMMON_CONFIG
#define TASK_COUNT 10
#include "../RegistryConfig.h"
extern DWORD ConfigWatchingThread;
extern HANDLE hConfigMutex;
extern HANDLE hTaskMutex;
extern unsigned char *pszProtocolSequence;
extern unsigned char *pszSecurity;
extern unsigned char *pszEndpoint;
extern unsigned int cMinCalls;
extern unsigned int cMaxCalls;
extern unsigned int fDontWait;
extern struct TASKENTRY TaskTable[TASK_COUNT];
extern int EntryCount;
extern DWORD TaskThreads[TASK_COUNT];
extern int TaskCount;
DWORD WINAPI CommonConfigWatcher(LPVOID ThreadParm);
void UpdateVariables();
#endif
EventLog.h
#ifndef __EVENT_LOG
#define __EVENT_LOG
void LogEvent(WORD EventType, LPSTR EventMsg);
#endif
ClientHandler.h
#ifndef __CLIENT_HANDLER
#define __CLIENT_HANDLER
extern DWORD ClientHandlingThread;
DWORD WINAPI RPCClientHandling(LPVOID ThreadParm);
void RefreshIniProps();
#endif
ShedulerServ.h
#ifndef __SHEDULING_SERVICE
#define __SHEDULING_SERVICE
#define TaskProcName "TaskProc"
extern BOOL TerminateSheduling;
extern DWORD ShedulingThread;
DWORD WINAPI ShedulingProc(LPVOID ThreadParm);
void TerminateTasks();
#endif
RegistryConfig.h
#ifndef __REGISTRY_CONFIG
#define __REGISTRY_CONFIG
#define REGISTRY_TASKS_PATH "SOFTWARE\\Svyazinform\\CommService\\Tasks"
struct TASKENTRY
{
DWORD ExecTime;
char DllName[256];
FARPROC TermProc;
DWORD TaskThread;
BOOL Active;
};
#endif
Comm.idl
/* IDL File */
[ uuid (4a25d2e0-6703-11d0-8927-00a02413850e),
version(1.0)
]
interface CommService
{
void RefreshIniProps();
}
Comm.acf
/* acf file for TimeInclude Service (RPC) */
[ implicit_handle(handle_t CommServ_IfHandle)
]interface CommService
{
}
Приложение 4Исходные тексты программы установки коммуникационного сервиса
#include <windows.h>
#include <stdio.h>
void RegEventSource();
VOID _CRTAPI1 main(void)
{
LPCTSTR lpszBinaryPathName =
TEXT("c:\\ibserver\\bin\\CommServ.exe");
SC_HANDLE schSCManager;
SC_HANDLE schService;
/* Open a handle to the SC Manager database. */
schSCManager = OpenSCManager(
NULL, /* local machine */
NULL, /* ServicesActive database */
SC_MANAGER_ALL_ACCESS); /* full access rights */
if (schSCManager == NULL) {
printf("\nError opening Service Manager.\n");
return;
}
schService = CreateService(
schSCManager, /* SCManager database */
TEXT("CommServ"), /* name of service */
TEXT("JSC \"SvjazInform\" Communication Service"), /* service name to display */
SERVICE_ALL_ACCESS, /* desired access */
SERVICE_WIN32_OWN_PROCESS, /* service type */
SERVICE_DEMAND_START, /* start type */
SERVICE_ERROR_NORMAL, /* error control type */
lpszBinaryPathName, /* service's binary */
NULL, /* no load ordering group */
NULL, /* no tag identifier */
NULL, /* no dependencies */
NULL, /* LocalSystem account */
NULL); /* no password */
if (schService == NULL) {
printf("\nFailed to create service!\n");
}
else
printf("CreateService SUCCESS\n");
CloseServiceHandle(schService);
CloseServiceHandle(schSCManager);
RegEventSource();
}
void RegEventSource()
{
HKEY hk;
DWORD dwData;
UCHAR szBuf[80];
if (RegCreateKey(HKEY_LOCAL_MACHINE, "SYSTEM\\CurrentControlSet\\Services\
\\EventLog\\Application\\CommServ", &hk)) {
printf("could not create registry key");
return;
}
/* Set the Event ID message-file name. */
strcpy(szBuf, "c:\\ibserver\\bin\\CommServ.exe");
/* Add the Event ID message-file name to the subkey. */
if (RegSetValueEx(hk, /* subkey handle */
"EventMessageFile", /* value name */
0, /* must be zero */
REG_EXPAND_SZ, /* value type */
(LPBYTE) szBuf, /* address of value data */
strlen(szBuf) + 1)) /* length of value data*/
{
printf("could not set event message file");
return;
}
/* Set the supported types flags. */
dwData = EVENTLOG_ERROR_TYPE | EVENTLOG_WARNING_TYPE |
EVENTLOG_INFORMATION_TYPE;
if (RegSetValueEx(hk, /* subkey handle */
"TypesSupported", /* value name */
0, /* must be zero */
REG_DWORD, /* value type */
(LPBYTE) &dwData, /* address of value data*/
sizeof(DWORD))) /* length of value data */
{
printf("could not set supported types");
return;
}
RegCloseKey(hk);
}
Приложение 5Исходные тексты программы удаления коммуникационного сервиса
#include <windows.h>
#include <stdio.h>
void CleanRegistry();
VOID _CRTAPI1 main(void)
{
SC_HANDLE schSCManager;
SC_HANDLE schService;
/* Open a handle to the SC Manager database. */
schSCManager = OpenSCManager(
NULL, /* local machine */
NULL, /* ServicesActive database */
SC_MANAGER_ALL_ACCESS); /* full access rights */
if (schSCManager == NULL) {
printf("\nError opening Service Manager.\n");
return;
}
schService = OpenService(
schSCManager, /* SCManager database */
TEXT("CommServ"), /* name of service */
DELETE); /* only need DELETE access */
if (! DeleteService(schService) )
printf("\nFailed to Delete service!\n");
else
printf("DeleteService SUCCESS\n");
CloseServiceHandle(schService);
CloseServiceHandle(schSCManager);
}
void CleanRegistry()
{
if (RegDeleteKey(HKEY_LOCAL_MACHINE, "SYSTEM\\CurrentControlSet\\Services\
\\EventLog\\Application\\CommServ"))
{
printf("\nError Cleaning Registry");
} else {
printf("\nCleaning Registry SUCCESS");
}
return;
}
Приложение 6
Структуры баз данных
Похожие работы

... влиять на информацию в других полях. В последние годы подавляющее большинство баз данных являются реляционными и практически все СУБД ориентированы на такое представление информации. 1.5 Типы СУБД Системой управления базами данных называют программную систему, предназначенную для создания на ЭВМ общей базы данных для множества приложений, поддержания ее в актуальном состоянии и обеспечения ...
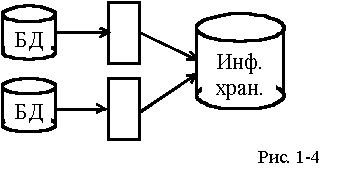
... данных и обеспечением доступа к ней. При обеспечении WWW-доступа к существующим БД, возможен ряд путей - комплексов технологических и организационных решений. Практика использования WWW-технологии для доступа к существующим БД предоставляет широкий спектр технологических решений, по разному связанных между собой - перекрывающих, взаимодействующих и т.д. Выбор конкретных решений при обеспечении ...
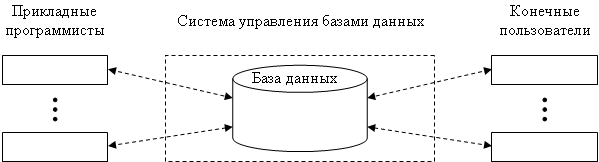




... и в то же время мощного математического аппарата, опирающегося главным образом на теорию множеств и математическую логику и обеспечивающего теоретический базис реляционного подхода к организации баз данных; 3. возможность ненавигационного манипулирования данными без необходимости знания конкретной физической организации баз данных во внешней памяти. Однако реляционные системы далеко не ...
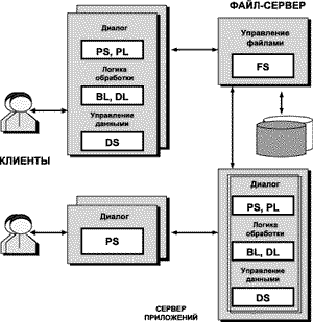
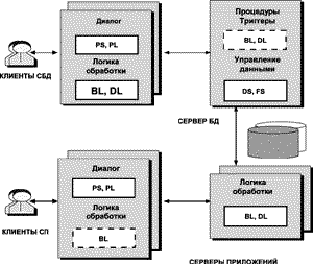
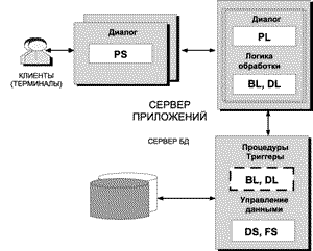
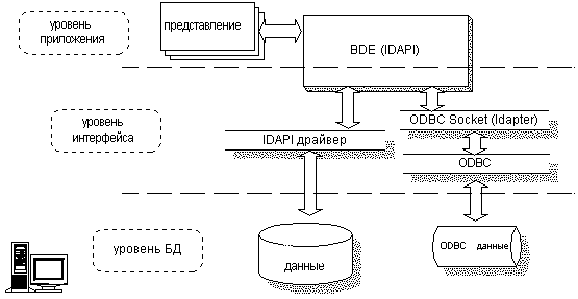
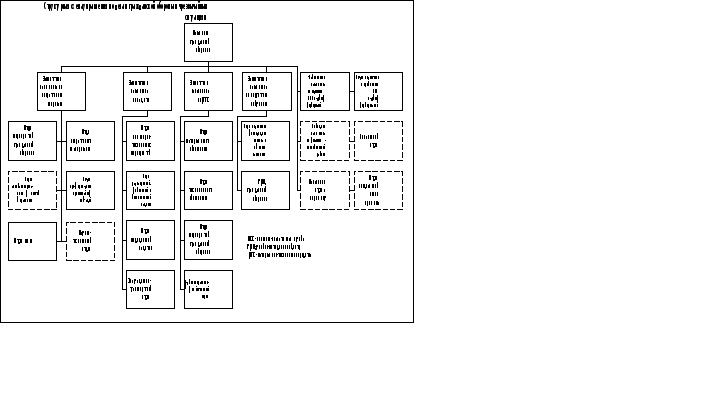
... технического обеспечения оснащенность ближайших объектов техникой и т.д. Данный проект позволяет вести необходимую информацию о объектах ГО и оценить в ЧС складывающеюся обстановку.7. РАЗРАБОТКА ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ ДЛЯ СИСТЕМЫ УПРАВЛЕНИЯ БАЗОЙ ДАННЫХ ОБЪЕКТОВ ГО. 7.1. Назначение и цели создания программного продукта Данное программное средство должно выполнять технологические функции в ...
0 комментариев