Навигация
Расширение SSE и SSE2 — блок XMM
181295
знаков
4
таблицы
0
изображений
4. Расширение SSE и SSE2 — блок XMM
Процессоры Pentium 3 имеют так называемое потоковое расширение SSE (Streaming SIMD Extensions). В те времена, когда будущий Pentium III называли еще Kathmai, фирма Intel объявила о новых инструкциях KNI (Kathmai New Instruction), так что SSE — это синоним "староинтеловского" KNI. Новые процессоры имеют дополнительный независимый блок из восьми 128-битных регистров, названных ХММ0...ХММ7 (очевидно, eXtended MultiMedia), и регистр состояния/управления MXCSR. В каждый из регистров ХММ помещаются четыре 32-битных числа в формате с плавающей точкой одинарной точности. Блок позволяет выполнять векторные (они же пакетные) и скалярные инструкции. Векторные инструкции реализуют операции сразу над четырьмя комплектами операндов. Скалярные инструкции работают с одним комплектом операндов — младшим 32-битным словом. При выполнении инструкций с ХММ традиционное оборудование FPU/MMX не используется, что позволяет эффективно смешивать инструкции ММХ с инструкциями над операндами с плавающей точкой. Здесь блоки процессора меняются ролями — регистры ММХ, наложенные на регистры традиционного сопроцессора, используются для целочисленных потоковых вычислений, а вычисления с плавающей точкой (правда, только с одинарной точностью, но для мультимедийпых приложений ее хватает) возлагаются на новый блок ХММ. Кроме инструкций с новым блоком ХММ в расширение SSE входят и дополнительные целочисленные инструкции с регистрами ММХ, а также инструкции управления кэшированием. Новые инструкции с регистрами ММХ, как и их предшественники из "классического" ММХ, не допускают чередования с инструкциями FPU без переключения контекста FPU/MMX.
С инструкциями SSE могут использоваться префиксы замены сегмента и изменения разрядности адреса (влияют на инструкции, обращающиеся к памяти). Использование префиксов изменения разрядности операнда зарезервировано (может привести к непредсказуемым результатам). Префикс Lock вызывает исключение #UD. Из префиксов повтора можно использовать только безусловный (REP) и только для "потоковых" инструкций (с ХММ), Остальные применения префиксов повтора могут привести к непредсказуемым результатам.
В процессоре Pentium 4 набор инструкций получил очередное расширение — SSE2, в основном касающееся добавления новых типов 128-битных операндов для блока ХММ:
• упакованная пара вещественных чисел двойной точности;
• упакованные целые числа: 16 байт, 8 слов, 4 двойных слова или пара учетверенных (по 64 бита) слов.
В процессор введены новые функции целочисленной арифметики SIMD, 128-разрядные для регистров ХММ и такие же 64-разрядные для регистров ММХ; ряд старых инструкций ММХ распространили и на ХММ (в 128-битном варианте); добавлены инструкции преобразований для новых форматов данных, а также расширены возможности "перемешивания" данных в блоке ХММ. Кроме того, расширена поддержка управления кэшированием и порядком исполнения операций с памятью. Инструкции SSE2 предназначены для ЗD-графики, кодирования/декодирования видео, а также шифрования данных.
5. Команды обработки данных
Система команд 32-разрядных процессоров является существенно расширенной системой команд процессоров 8086/80286. Расширения касаются увеличения разрядности адресов и операндов, более гибкой системы адресации, появления принципиально новых типов данных (битовые строки и поля) и команд.
Команды (инструкции) содержат одно- или двухбайтный код инструкции, за которым может следовать несколько байт, определяющих режим исполнения команды, и операнды. Команды могут использовать до трех операндов (или ни одного). Операнды могут находиться в памяти, регистрах процессора или непосредственно в команде. Для 32-разрядных процессоров разрядность слова (word) по умолчанию может составлять 32, а не 16 бит. Это распространяется на многие инструкции, включая и строковые. В реальном режиме и режиме виртуального процессора 8086 по умолчанию используется 16-битная адресация и 16-битные операнды-слова. В защищенном режиме режим адресации и разрядность слов по умолчанию определяются дескриптором кодового сегмента. Перед любой инструкцией может быть указан префикс переключения разрядности адреса или слова. При адресации памяти использование сегментного регистра, предусмотренного командой, в ряде инструкций может подавляться префиксом изменения сегмента (Segment Override).
В системе команд насчитывается несколько сотен инструкций, поэтому в данной работе обзорно рассмотрены все команды обработки данных (блоков процессора АЛУ, FPU, MMX, и XMM), а далее более подробно описаны инструкции, появившиеся в процессорах Pentium 3 (блок XMM — SSE) и Pentium 4 (блок XMM — SSE2).
Инструкции пересылки данных (см. табл) позволяют передавать константы или переменные между регистрами и памятью, а также портами ввода-вывода в различных комбинациях, но в памяти может находиться не более одного операнда. В эту группу отнесены и инструкции преобразования форматов — расширений и перестановки байт. Операции со стеком выполняются словами с разрядностью, определяемой текущим режимом. При помещении в стек слова указатель стека SP уменьшается на число байт слова (2 или 4), при извлечении — увеличивается. "Классические" (8086) инструкции пересылки не влияют на содержимое регистра флагов. Инструкции пересылки по результатам сравнения (CMPXCHG) модифицируют флаг ZF. Новые инструкции условной пересылки (CMOVxx) позволяют сократить число ветвлений в программе.
Таблица. Инструкции пересылки данных
Инструкция Описание
BSWAP Перестановка байт из порядка младший-старший (L-H) в порядок старший-младший (H-L) (486+)
CBW/CWDE Преобразование байта AL в слово АХ (расширение знака AL в АН: АН заполняется битом AL.7) или слова АХ в двойное слово ЕАХ
CMOVA/CMOVNBE Пересылка, если выше "CF ИЛИ ZF)=0) (P6+)
CMOVAE/CMOVNB Пересылка, если не ниже (CF=0) (P6+)
CMOVB/CMOVNAE Пересылка, если ниже (CF=1) (P6+)
CMOVBE/CMOVNA Пересылка, если не выше ((CF ИЛИ ZF)=1) (P6+)
CMOVC Пересылка, если перенос (CF=1) (P6+)
CMOVE/CMOVZ Пересылка, если равно (ZF=1) (P6+)
CMOVG/CMOVNLE Пересылка, если больше (SF=(0F И ZF)) (P6+)
CMOVGE/CMOVNL Пересылка, если больше или равно (SF=0F) (P6+)
CMOVL/CMOVNGE Пересылка, если меньше (ZF0F) (P6+)
CMOVLE/CMOVNG Пересылка, если меньше или равно (SF0F или ZF=0) (P6+)
CMOVNC Пересылка, если нет переноса (CF=0) (P6+)
CMOVNE/CMOVNZ Пересылка, если не равно (ZF=0) (P6+)
CMOVNO Пересылка, если нет переполнения (0F=0) (P6+)
CMOVNP/CMOVPO Пересылка, если нет паритета (нечетность) (P6+)
CMOVNS Пересылка, если неотрицательно (SF=0) (P6+)
CMOVO Пересылка, если переполнение (0F=1) (P6+)
CMOVP/CMOVPE Пересылка, если паритет (четность) (Р6+)
CMOVS Пересылка, если отрицательно (SF=1)(P6+)
CMPXCHG r/in,r Обмен по результату сравнения байта, слова или двойного слова (486+)
CMPXCHG8B m64 Обмен по результату сравнения учетверенного слова (5+)
CWD/CDQ Преобразование слова АХ в двойное слово DX:AX (расширение знака, DX заполняется битом АХ. 15) или двойного слова ЕАХ в учетверенное EDX:EAX
IN Ввод из порта ввода-вывода в AL/(E)AX
MOV Пересылка(копирование)данных
MOVSX Копирование байта/слова со знаковым расширением до слова/ двойного слова(386+)
MOVZX Копирование байта/слова с нулевым расширением до слова/ двойного слова(386+)
OUT Вывод в порт из AL/(E)AX
POP Извлечение слова данных из стека в регистр или память, (E)SP инкрементируется
POPA(POPAll) Извлечение данных из стека в регистры Dl, SI, ВР, ВХ, DX, CX, AX (286+)
POPAD Извлечение данных из стека в регистры EDI, ESI, ЕВР, ЕВХ, EDX, ЕСХ, ЕАХ (386+)
PUSH Помещение слова из регистра или памяти в стек после декремента (E)SP
PUSHA (PUSH All) Помещение в стек регистров АХ, CX, DX, BX, SP (исходное значение), ВР, SI, Dl (286+)
PUSHAD Помещение в стек регистров ЕАХ, ЕСХ, EDX, ЕВХ, ESP (исходное значение), ЕВР, ESI, EDI (386+)
XCHG Обмен данными (взаимный) между регистрами или регистром и памятью
Инструкции ввода-вывода позволяют пересылать как одиночный бант или слово между портом и регистром процессора (инструкции IN и OUT), так и блок байт (слов) между портом и группой смежных ячеек памяти (инструкции INSB/INSW и OUTSB/OUTSW с префиксом повтора, см. ниже). Непосредственная адресация порта в команде обеспечивает доступ только к первым 256 адресам портов, косвенная (через регистр DX) — ко всему пространству ввода-вывода (64 Кбайт). Разрядность операнда и адрес должны согласовываться с физическими возможностями и особенностями поведения адресуемого устройства. При работе с памятью такие нюансы во внимание принимать обычно не приходится.
Инструкции двоичной арифметики выполняют все арифметические действия с байтами, словами и двойными словами, кодирующими знаковые или беззнаковые целые числа. Умножение и деление для 8086 возможны только с аккумулятором, результат для 16-битных операндов расширяется в регистре DX.
Для 286+ возможно двух- и трехадресное умножение с расширенном тилько в старший байт (два байта для 386+).
Таблица. Инструкции двоичной арифметики
Инструкция Описание
ADC Сложение двух операндов с учетом переноса от предыдущей операции
ADD Сложение двух операндов
СМР Сравнение (вычитание без сохранения результата — установка флагов)
DEC Декремент (вычитание 1, но не действует на флаг CF)
DIV Деление беззнаковое
IDIV Деление знаковое
IMUL Умножение знаковое
INC Инкремент (сложение с 1, но не действует на флаг CF)
MUL Беззнаковое умножение
NEG Изменение знака операнда
SBB Вычитание с заемом
SUB Вычитание
XADD Обмен содержимым и сложение (486+)
Инструкции десятичной арифметики являются дополнением к предыдущим. Они позволяют оперировать с неупакованными (биты [7:4] = 0, биты [3:0] содержат десятичную цифру 0-9) или упакованными (биты [7:4] содержат старшую, биты [3:0] — младшую десятичную цифру 0-9) двоичнодесятичными числами. Арифметические операции над этими числами требуют применения инструкций коррекции форматов.
Таблица. Инструкции десятичной арифметики
Инструкция Описание
ААА Десятичная коррекция после сложения двух неупакованных чисел
AAD Десятичная коррекция перед делением неупакованного двузначного числа
ААМ Десятичная коррекция после умножения двух неупакованных чисел
AAS Десятичная коррекция после вычитания двух неупакованных чисел
DAA Десятичная коррекция AL после сложения двух упакованных чисел
DAS Десятичная коррекция AL после вычитания двух упакованных чисел
Инструкции AAD и ААМ допускают обобщенный формат вызова, при котором коррекция выполняется но любому модулю (а не только по модулю 10).
Инструкции логических операций выполняют все функции булевой алгебры над байтами, словами или двойными словами.
Таблица. Инструкции логических операций
Инструкция Описание
AND Логическое И
NOT Инверсия (переключение всех бит)
OR Логическое ИЛИ
XOR Исключающее ИЛИ
Сдвиги и вращения (циклические сдвиги) выполняются над регистром или операндом в памяти. Число позиций, на которое производится сдвиг, берется непосредственно из операнда или регистра CL по модулю 8 для однобайтного операнда и по модулю 16 или 32 для операнда-слова, в зависимости от разрядности данных (32 только для 386+). Биты, выталкиваемые при сдвигах, попадают во флаг CF. При сдвигах влево и простом сдвиге вправо освобождающиеся биты заполняются нулями (инструкции SAL и SHL — синонимы). При арифметическом сдвиге вправо старший бит (знак) сохраняет свое значение. При циклических сдвигах выталкиваемые биты попадают и во флаг CF, и в освобождающиеся позиции. В сдвигах могут участвовать и два операнда (инструкции SHLD и SHRD).
Таблица. Инструкции сдвигов
Инструкция Описание
RCL Циклический сдвиг влево через бит переноса
RCR Циклический сдвиг вправо через бит переноса
ROL Циклический сдвиг влево
ROR Циклический сдвиг вправо
SAL Сдвиг арифметический влево
SAR Сдвиг арифметический (с сохранением старшего бита) вправо
SHL Сдвиг влево
SHR Сдвиг вправо
SHLD Сдвиг влево и вставка данных в освободившиеся позиции (386+)
SHRD Сдвиг вправо и вставка данных в освободившиеся позиции (386+)
Инструкции обработки бит и байт позволяют проверять (копировать в CF) и устанавливать значение указанного операнда, а также искать установленный бит. Битовые операции выполняются над 16-или 32-битным словом памяти или регистром. Инструкции BSF, BSR и ВТ не изменяют значения слова; ВТС, BTR и BTS воздействуют на указанный бит слова. Номер интересующего бита берется из операнда по модулю 16 или 32, в зависимости от разрядности.
Операции с байтами обеспечивают условную установку значений 00h или 01h. Инструкция тестирования может выполняться над байтом, словом или двойным словом.
Таблица. Инструкции обработки бит и байт
Инструкция Описание
BSF Сканирование бит (поиск единичного) вперед
BSR Сканирование бит назад
ВТ Тестирование бита (загрузка в CF)
ВТС Тестирование и изменения значения бита
BTR Тестирование и сброс бита
BTS Тестирование и установка бита
SALC Условная (по CF) установка А1 в FFh или OOh (не документировано, код D6h)
SETA/ Установка байта в 01h, если выше ((CF ИЛИ ZF)=0), иначе в 00h
SETNBE
SETAE/ Установка байта в 01 h, если не ниже (CF=0), иначе в 00h
SETNB/
SETNC
SETB/ Установка байта в 01h, если ниже (CF=1), иначе в 00h
SETNAE/
SETC
SETBE/ Установка байта в 01h, если не выше (CF ИЛИ ZF)=1, иначе в 00h
SETNA
SETE/ Установка байта в 01h, если равно (ZF=1), иначе в 00h
SETZ
SETG/ Установка байта в 01 h, если больше (SF=(OP И ZF)), иначе в 00h
SETNLE
SETQE/ Установка байта в 01h, если больше или равно (SF=OF), иначе в 00h
SETNL
SETL/ Установка байта в 01h, если меньше (ZFOF), иначе в 00h
SETNGE 00h
SETLE/ Установка байта в 01h, если меньше или равно (SF0F или ZF=0),иначе в 00h
SETNG
SETNE/ Установка байта в 01h, если не равно (ZF=0), иначе в 00h
SETNZ
SETNO Установка байта в 01h, если нет переполнения (0F=0), иначе в 00h
SETNS Установка байта в 01 h, если неотрицательно (SF=0), иначе в 00h
SETO Установка байта в 01h, если переполнение (0F=1), иначе в 00h
SETPE/ Установка байта в 01h, если паритет (четность), иначе в 00h
SETP
SETPO/ Установка байта в 01 h, если нет паритета (нечетность), иначе в 00h
SETNP
SETS Установка байта в 01 h, если отрицательно (SF=1), иначе в 00h
SETC Установка байта в 01 h, если перенос (CF=1), иначе в 00h
SETNC Установка байта в 01 h, если нет переноса (CF=0), иначе в 00h
TEST Проверка бит (логическое И без записи результата — установка флагов)
Строковые операции выполняются с операндами в памяти, адресуемыми регистрами DS:SI (DS:ESI) для источника и ES:DI (ES:EDI) для приемника. Операции могут использоваться с префиксами условного или безусловного повтора. После каждой пересылки или сравнения индексные регистры (SI, DI или оба) участвующих операндов автоматически инкрементируются или декрементируются на количество байт, участвующих в операции (1,2 или 4). Направление модификации определяется флагом DF: DF = 0 -инкремент, DF = 1 — декремент. Строковые инструкции ввода-вывода с префиксами повтора позволяют достигать высоких скоростей обмена с портами при условии полной загрузки процессора.
Таблица. Инструкции строковых операций
Инструкция Описание
CMPSB, CMPSD, CMPSW Сравнение строк байт, слов или двойных слов с записью результата сравнения в регистр флагов
INSB, INSD, INSW Запись байта, слова или двойного слова, введенного из порта, в память(286+)
LODSB, LODSD, LODSW Копирование байта, слова или двойного слова из строки в AL/(E)AX
MOVSB, MOVSD, MOVSW Копирование байта, слова или двойного слова из одной строки в другую
OUTSB, OUTSD, OUTSW Вывод байта, считанного из памяти, в порт (286+)
SCASB, SCASD, SCASW Сканирование строки байт, слов или двойных слов — сравнение с AL/(E)AX и запись результата сравнения в регистр флагов
STOSB, STOSD, STOSW Запись байта, слова или двойного слова в строку из AL/(E)AX
REP Префикс повтора строковых операций до обнуления (Е)СХ, (Е)СХ декрементируется на каждом повторе
REPE/REPZ Префикс условного повтора строковых операций — выполнения REP при ZF=1
REPNE/ Префикс условного повтора строковых операций — выполнения
REPNZ REP при ZF=0
Инструкции математического сопроцессора (FPU) имеют свою специфику задания операндов. Переменная st(0) находится на вершине стека сопроцессора, st(i) смещена от вершины на i. Загрузка данных начинается с декремента указателя стека сопроцессора (поле TOP) — перемещения вершины. Если новая вершина не пустая (по полю TAG) или стек исчерпан, вызывается исключение с указанием причины.
После загрузки поле TAG устанавливается в соответствии с загруженным числом. При извлечении из стека производится инкремент ТОР, а в поле TAG старой вершины устанавливается признак пустой ячейки. Попытка использования пустого регистра в операциях или для сохранения результатов в памяти вызывает исключение. Инструкции с префиксом F предварительно проверяют флаг исключения ES (они называются ожидающими инструкциями), инструкции с префиксом FN флаг исключения не проверяют (неожидающие инструкции). Ряд инструкций не вызывает исключения в случае, если обнаруживаются операнды не-числа (NaN).
Таблица. Инструкции FPU
Инструкция Описание
Пересылки данных
FBLD Преобразование и помещение (push) числа в упакованном BCD-формате из памяти в стек
FBSTP Извлечение из стека и запись в память в упакованном BCD-формате (10 байт, 18 цифр)
FCMOVB Пересылка, если ниже (CF=1) (P6+)
FCMOVBE Пересылка, если не выше (CF ИЛИ ZF)=1 (P6+)
FCMOVE Пересылка, если равно (ZF=1) (P6+)
FCMOVNB Пересылка, если не ниже (CF=0) (P6+)
FCMOVNBE Пересылка, если выше ((CF ИЛИ ZF)=0) (P6+)
FCMOVNE Пересылка, если не равно (ZF=0) (P6+)
FCMOVNU Пересылка, если не NaN (PF=0) (P6+)
FCMOVU Пересылка, если NaN (unordered) (PF=0) (P6+)
FILD Загрузка (push) целого числа из памяти
FIST Запись в память в формате целого числа
FISTP Запись в память в формате целого числа с извлечением
FLD Загрузка (push) вещественного числа
FST Сохранение (копирование) числа в памяти (в вещественном формате) или в регистре стека
FSTP Запись числа в память (в вещественном формате) или в регистр стека с извлечением
FXCH Обмен значениями вершины стека и регистра
Загрузка констант
FLD1 Загрузка (push)+1,0
FLDL2E Загрузка (push) log2(e)
FLDL2T Загрузка (push) log2( 10)
FLDLG2 Загрузка (push) lg(2)
FLDLN2 Загрузка (push) ln(2)
FLDPI Загрузка (push) pi
FLDZ Загрузка (push) + 0,0
Базовая арифметика
FABS Нахождение абсолютного значения
FADD Сложение вещественных чисел
FADDP Сложение вещественных чисел с извлечением
FCHS Изменение знака
FDIV Деление вещественных чисел
FDIVP Деление вещественных чисел с извлечением
FDIVR Обратное деление вещественных чисел
FDIVRP Обратное деление вещественных чисел с извлечением
FIADD Сложение с целым числом
FIDIV Деление на целое число
FIDIVR Обратное деление целых чисел
FIMUL Умножение на целое число
FISUB Вычитание целого числа
FISUBR Вычитание из целого числа
FMUL Умножение вещественных чисел
FMULP Умножение вещественных чисел с извлечением
FPREM Нахождение частичного остатка
FPREM1 Нахождение частичного остатка в стандарте IEEE (387+)
FRNDINT Округление до ближайшего целого
FSCALE Масштабирование — умножение на округленную в сторону нуля степень числа 2
FSQRT Извлечение квадратного корня
FSUB Вычитание вещественного числа
FSUBP Вычитание вещественных чисел с извлечением
FSUBR Обратное вычитание числа
FSUBRP Обратное вычитание с извлечением
FXTRACT Выделение мантиссы и порядка числа
Сравнение данных
FCOM Сравнение вещественных чисел (установка флагов сопроцессора)
FCOMI Сравнение и соответствующая установка флагов в EFLAGS (ZF, PF, CF) (P6+)
FCOMIP Сравнение и соответствующая установка флагов в EFLAGS (ZF, PF, CF), с извлечением (P6+)
FCOMP Сравнение вещественных чисел с извлечением
FCOMPP Сравнение вещественных чисел с двойным извлечением
FICOM Сравнение с целочисленным операндом из памяти
FICOMP Сравнение с целочисленным операндом из памяти с извлечением
FTST Проверка на нуль
FUCOM Сравнение без генерации исключения в случае NaN (387+)
FUCOMI Сравнение без генерации исключения в случае NaN и соответствующая установка флагов в EFLAGS (ZF, PF, CF) (P6+)
FUCOMIP Сравнение без генерации исключения в случае NaN и соответствующая установка флагов в EFLAGS (ZF, PF, CF) с извлечением (P6+)
FUCOMP Сравнение без генерации исключения в случае NaN с извлечением (387+)
FUCOMPP Сравнение без генерации исключения в случае NaN с двойным извлечением (387+)
FXAM Анализ числа — установка кода условия в СО, С2, СЗ
Трансцендентные функции
Р2ХМ1 Вычисление
FCOS Косинус (387+)
PPATAN Арктангенс частного с извлечением
FPTAN Вычисление тангенса и загрузка (push) в стек +1,0
FSIN Вычисление синуса (387+)
FSINCOS Вычисление синуса и косинуса с помещением (push) в стек (387+)
FYL2X Вычисление Yxlog2(X)
FYL2XP1 Вычисление Yxlog2(X+1)
Управление сопроцессором
FCLEX Сброс флагов исключений с предварительной проверкой
ожидающих немаскированных исключений
FDECSTP Декремент указателя стека FPU
FFREE Освобождение регистра — пометка как свободного
FINCSTP Инкремент указателя стека FPU
FINIT Инициализация FPU с предварительной проверкой ожидающих исключений
FLDCW Загрузка управляющего слова (FPU CW) из памяти
FLDENV Загрузка состояния сопроцессора из памяти, сохраненного инструкциями FSTENV/FNSTENV
FNCLEX Сброс флагов исключений без проверки ожидающих
FNINIT Инициализация FPU без проверки ожидающих исключений
FNOP Пустая операция FPU
FNSAVE Сохранение состояния сопроцессора и стека регистров в памяти без проверки ожидающих исключений
FNSTCW Сохранение управляющего слова без проверки ожидающих исключений
FNSTENV Сохранение состояния сопроцессора (SR, CR, TAGW, FIP и FDP) в памяти без проверки ожидающих исключений
FNSTSW Запись слова состояния без проверки ожидающих исключений
FRSTOR Загрузка состояния сопроцессора и регистров из памяти
FSAVE Сохранение состояния сопроцессора и стека регистров в памяти с предварительной проверкой ожидающих исключений
FSTCW Сохранение управляющего слова с предварительной проверкой ожидающих исключений
FSTENV Сохранение состояния сопроцессора (SR, CR, TAGW, FIP и FDP) в памяти с предварительной проверкой ожидающих исключений
FSTSW Запись слова состояния для последующего переноса кода завершения в регистр флагов с предварительной проверкой ожидающих исключений
WAIT/FWAIT Синхронизация — останов CPU до завершения текущей операции FPU, проверка ожидающих исключений FPU
Инструкции ММХ появились в процессорах Pentium ММХ и с тех пор поддерживаются всеми более современными процессорами (Pentium Pro, появившийся раньше, эти инструкции не поддерживает). Они имеют сложную мнемонику, которая включает следующие элементы:
• префикс Р (Packed), указывающий на обработку упакованных форматов;
• мнемонику операции (например, ADD, CMP или XOR);
• суффикс, идентифицирующий тип насыщения: US (Unsigned Saturation) — насыщение беззнаковое, S (Signed saturation) — насыщение знаковое;
• суффикс, идентифицирующий тип данных: В — упакованные байты, W — упакованные слова, D — упакованные двойные слова, Q -учетверенное слово.
Инструкции, у которых типы входных и выходных данных различаются (например, преобразования), имеют два суффикса.
Для инструкций пересылки данных операнды источника и назначения могут находиться в памяти (m32 или m64), целочисленных регистрах (ir32) или регистрах ММХ (mm). Для остальных инструкций, кроме вышеперечисленных, операнд-источник может быть и непосредственным, а операнд назначения всегда является регистром ММХ. Для операндов, находящихся в памяти, применимы все существующие режимы адресации.
Таблица. Инструкции ММХ
Инструкция Описание
EMMS Очистка стека регистров — установка всех единиц в слове тегов
Пересылка данных
MOVD Пересылка данных в младшие 32 бита регистра ММХ (с заполнением старших бит нулями) или из младших 32 бит регистра ММХ
MOVQ Пересылка данных (64 бит) из/в регистр ММХ
Преобразование форматов
PACKSSDW Упаковка со знаковым насыщением четырех двойных слов в четыре
слова
PACKSSWB Упаковка со знаковым насыщением восьми слов в восемь байт
PACKUSWB Упаковка с насыщением восьми знаковых слов в восемь беззнаковых байт
PUNPCKHBW Чередование в регистре назначения байт старшей половины операнда-источника с байтами старшей половины операнда назначения
PUNPCKHWD Чередование в регистре назначения слов старшей половины операнда-источника со словами старшей половины операнда назначения
PUNPCKHDQ Чередование в регистре назначения двойного слова старшей половины операнда-источника с двойным словом старшей половины операнда назначения
PUNPCKLBW Чередование в регистре назначения байт младшей половины операнда-источника с байтами младшей половины операнда назначения
PUNPCKLWD Чередование в регистре назначения слов младшей половины операнда-источника со словами младшей половины операнда назначения
PUNPCKLDQ Чередование в регистре назначения двойного слова младшей половины операнда-источника с двойным словом младшей половины операнда назначения
Упакованная арифметика
PADDB Сложение упакованных байт (слов или двойных слов) без насыщения
PADDW (с циклическим переполнением)
PADDD
PADDSB Сложение знаковых упакованных байт (слов) с насыщением
PADDSW
PADDUSB Сложение упакованных беззнаковых байт (слов) с насыщением PADDUSW
PMADDWD Умножение четырех знаковых слов операнда-источника на четыре знаков слова операнда назначения. Два двойных слова результатов умножения младших слов суммируются и записываются в младшее двойное слово операнда назначения. Два двойных слова результатов умножения старших слов суммируются и записываются в старшее двойное слово операнда назначения
PMULHW Умножение упакованных знаковых слов с сохранением только старших 16 элементов результата
PMULLW Умножение упакованных знаковых или беззнаковых слов с сохранением только младших 16 бит элементов результата
PSUBB Вычитание упакованных байт (слов или двойных слов) без
PSUBW насыщения (с циклическим антипереполнением)
PSUBD
PSUBSB Вычитание упакованных знаковых байт (слов) с насыщением PSUBSW
PSUBUSB Вычитание упакованных беззнаковых байт (слов) с насыщением PSUBUSW
Логика
PAND Логическое И
PANDN Логическое И mm/m64 и инверсного значения mm
POR Логическое ИЛИ
PXOR Исключающее ИЛИ
Сравнение
PCMPEQB Сравнение (на равенство) упакованных байт (слов, двойных
слов). Все биты элемента результата будут единичными (True)
PCMPEQD совпадении соответствующих элементов (байт, слов или двойных
PCMPEQW слов) операндов и нулевыми (False) при несовпадении
PCMPGTB Сравнение (по величине) упакованных знаковых байт (слов, двойных слов).
PCMPGTD, PCMPGTW Все биты элемента результата будут единичными (True), если соответствующий элемент операнда назначения больше элемента операнда-источника, и нулевыми (False) в противном случае
Сдвиги и вращения
PSLLD, PSLLQ, PSLLW Логический сдвиг влево упакованных слов (двойных, учетверенных) операнда назначения на количество бит, указанных в операнде-источнике, с заполнением младших бит нулями
PSRAD, PSRAW Арифметический сдвиг вправо упакованных двойных (учетверенных) знаковых слов операнда назначения на количество бит, указанных в операнде-источнике, с заполнением младших бит битами знаковых разрядов
PSRLD, PSRLQ, PSRLW Логический сдвиг вправо упакованных слов (двойных, учетверенных) операнда назначения на количество бит, указанных в операнде- источнике, с заполнением старших бит нулями
Инструкции SSE появились в процессорах Pentium 3. Они делятся на три основные группы: инструкции над числами в блоке ХММ, дополнительные целочисленные SIMD-инструкции (в блоке ММХ) и новые инструкции кэширования. Основное число новых инструкций предназначено для работы с блоком ХММ. Векторные инструкции выполняются сразу над четырьмя парами чисел. Скалярные инструкции выполняются только над числами, расположенными в младших 32 битах операндов. Операнд-источник для инструкций ХММ может быть как регистром ХММ, так и 128-битной ячейкой памяти. Для многих инструкций требуется, чтобы операнд в памяти был выровнен по границе параграфа. При обработке скалярными инструкциями операнда в памяти пересылка между памятью и регистрами ХММ производится для всего 128-битного слова, хотя используется только 32 бита.
Таблица. Инструкции расширения SSE
Инструкция Описание
Пересылка данных с участием регистров ХММ
MOVAPS Пересылка 128-битных данных между памятью и регистрами ХММ или
между регистрами ХММ. Данные в памяти должны быть выровнены по границе 16-байтного параграфа
MOVUPS Пересылка 128-битных данных между памятью и регистрами ХММ или между регистрами ХММ (без требования выравнивания)
MOVHPS Пересылка 64-битных данных между памятью и старшей половиной регистров ХММ или между регистрами ХММ (младшая половина ХММ не изменяется)
MOVHLPS Пересылка старшей половины источника в младшую половину назначения (старшая половина регистра назначения не меняется)
MOVLHPS Пересылка младшей половины источника в старшую половину назначения (младшая половина регистра назначения не меняется)
MOVLPS Пересылка 64-битных данных между памятью и младшей половиной регистров ХММ или между регистрами ХММ (старшая половина ХММ не изменяется)
MOVMSKPS Сборка старших бит упакованных операндов из регистра ХММ в регистр общего назначения (биты 31, 63, 95 и 127 регистра ХММ попадают в биты О, 1, 2 и 3 регистра-приемника, остальные биты приемника будут нулевыми)
MOVSS Пересылка скалярного операнда (младшие 32 бита) между памятью и регистрами ХММ или между регистрами ХММ
Арифметические инструкции над числами в FP-формате в регистрах ХММ
ADDPS Векторное сложение
SUBPS Векторное вычитание
ADDSS Скалярное сложение
SUBSS Скалярное вычитание
MULPS Векторное умножение
MULSS Скалярное умножение
DIVPS Векторное деление
DIVSS Скалярное деление
SQRTPS Векторное извлечение квадратного корня
SQRTSS Скалярное извлечение квадратного корня
MAXPS Векторное нахождение максимума
MAXSS Скалярное нахождение максимума
MINPS Векторное нахождение минимума
MINSS Скалярное нахождение минимума
Сравнение
CMPPS Векторное сравнение (задается полный набор 12 условий, как в инструкциях условных переходов). В том элементе операнда назначения, для которого условие сравнения выполняется, устанавливаются все единицы (32 бита), где не выполняется — все нули
CMPSS Скалярное сравнение (12 условий), аналогично предыдущему, но только для младших 32 бит
COMISS Скалярное сравнение с установкой бит ZF, PF и CF регистра EFLAGS (биты 0F, SF и AF обнуляются)
UCOMISS Скалярное сравнение, но без генерации исключения в случае NaN (при этом ZF=PF=CF=1)
Инструкции преобразований
CVTPI2PS Преобразование двух знаковых целых из регистра ММХ или 64-битной ячейки памяти в два младших РР-числа в регистре ХММ (старшая пара не изменяется). При необходимости выполняется округление
CVTSI2SS Преобразование знакового целого из 32-битного регистра или 64-битной ячейки памяти в младшее упакованное FP-число в регистре ХММ (старшие три числа не изменяются). При необходимости выполняется округление
CVTPS2PI Преобразование двух младших FP-чисел из регистра ХММ или памяти в пару целых знаковых в регистре ММХ или 64-битной ячейки памяти. При необходимости выполняется округление; если результат не умещается, возвращается значение бесконечности (80000000h)
CVTTPS2PI Преобразование, аналогичное CVTPS2PI, но при невозможности точного преобразования выполняется усечение
CVTSS2SI Преобразование младшего FP-числа из регистра ХММ в целое знаковое в 32-битном регистре. При необходимости выполняется округление; если результат не умещается, возвращается значение бесконечности (80000000h)
CVTTSS2SI Преобразование, аналогичное CVTSS2SI, но при невозможности точного преобразования выполняется усечение
Логические инструкции в блоке ХММ
ANDPS Логическое И двух пакетов операндов
ANDNPS Логическое И-НЕ двух пакетов операндов
ORPS Логическое ИЛИ двух пакетов операндов
XORPS Исключающее ИЛИ двух пакетов операндов Перестановки операндов в ХММ
SHUFPS Перестановка слов в регистре ХММ под управлением 8-битного непосредственного операнда
UNPCKHPS Переупаковка старших половин с чередованием слов в результате
UNPCKLPS Переупаковка старших половин с чередованием слов в результате
Управление состоянием
LDMXCSR Загрузка регистра MXCSR
STMXCSR Сохранение регистра MXCSR
FXSAVE Сохранение состояния блоков FP/MMX и ХММ
FXRSTOR Восстановление состояния блоков FP/MMX и ХММ
Дополнительные целочисленные SIMD-инструкции (выполняются с операндами в регистрах ММХ, входят и в расширенный набор 3DNow!)
PAVGB/PAVGW Нахождение среднего упакованных беззнаковых байт или слов
PEXTRW Извлечение 16-битного слова из регистра ММХ в младшую половину 32-битного регистра (старшая половина обнуляется). Номер слова определяется младшими битами непосредственного операнда
PINSRW Помещение младшей половины 32-битного регистра в выбранное слово регистра ММХ. Номер слова определяется младшими битами непосредственного операнда
PMAXUB, PMAXSW Нахождение максимума упакованных беззнаковых байт/знаковых слов
PMINUB, PMINSW Нахождение минимума упакованных беззнаковых байт/знаковых слов
PMOVMSKB Сборка старших бит упакованных байт в 8-битную маску, помещаемую в целочисленный регистр
PMULHUW Умножение беззнаковых слов с сохранением старших половин произведений
PSADBW Нахождение суммы модулей разности пар слов (результат — 16-битное число)
PSHUFW Перемешивание слов под управлением 8-битного непосредственного операнда
Управление кэшированием (входят и в расширенный набор 3DNow!)
MASKMOVQ Выборочная запись байт из регистра ММХ в память, минуя кэш MOVNTQ Запись из регистра ММХ в память, минуя кэш
MOVNTPS Запись из регистра ХММ в память, минуя кэш (адрес должен быть
выровнен по границе параграфа)
PREFETCHTO Загрузка 32 или более байт в кэш-память
PREFETCHT1
PREFETCHT2
PREFETCHNT
SFENCE Выгрузка результатов всех предыдущих инструкций в кэш-память
Новые инструкции управления кэшированием обеспечивают запись содержимого регистров ММХ и ХММ в память, минуя кэш, что позволяет избегать "загрязнения" кэш-памяти промежуточными данными. Появилась и возможность "закачивать" требуемые данные в кэш прежде использующих их инструкций.
По сравнению с расширением 3DNow! набор инструкций SSE шире, часть инструкций пересекается, но и в 3DNow! имеются уникальные инструкции, не реализованные в SSE.
Инструкции SSE2 появились в процессорах Pentium 4. Большая их часть предназначена для работы с числами с плавающей точкой двойной точности (64-битные операнды), расположенными в регистрах ХММ, векторными (упакованная пара 64-битных чисел) и скалярными (старшим или младшим числом). Они обеспечивают векторные и скалярные пересылки этих чисел, арифметические инструкции (сложение, вычитание, умножение, деление, извлечение корня, нахождение максимума и минимума), сравнение чисел, преобразования форматов, перестановки операндов, а также побитные логические функции. Появились и SIMD-инструкции обработки 32- и 64-битных целых чисел, расположенных в регистрах ХММ. Новые инструкции управления кэшированием позволяют миновать кэш при записи в память из регистров ХММ и общих регистров, упорядочивать последовательности загрузки данных из памяти и записи в память и выполнять некоторые другие действия.
Таблица. Инструкции SSE2
Инструкция Описание
Инструкции пересылки данных (чисел с плавающей точкой двойной точности между регистрами ХММ, а также регистрами ХММ и памятью)
MOVAPD Пересылка пары упакованных выровненных чисел
MOVUPD Пересылка пары упакованных невыровненных чисел
MOVHPD Пересылка старшего упакованного числа
MOVLPD Пересылка младшего упакованного числа
MOVMSKPD Извлечение знаковой маски из пары чисел
MOVSD Пересылка скалярного числа
Арифметические инструкции над операндами с плавающей точкой двойной точности в регистрах ХММ
ADDPD Векторное сложение
ADDSD Скалярное сложение
SUBPD Векторное вычитание
SUBSD Скалярное вычитание
MULPD Векторное умножение
MULSD Скалярное умножение
DIVPD Векторное деление
DIVSD Скалярное деление
SQRTPD Векторное извлечение квадратного корня
SQRTSD Скалярное извлечение квадратного корня
MAXPD Векторное нахождение максимума
MAXSD Скалярное нахождение максимума
MINPD Векторное нахождение минимума
MINSD Скалярное нахождение минимума
Логические инструкции над упакованными 64-битными операндами в регистрах ХММ (побитные функции)
ANDPD Логическое И
ANDNPD Логическое И-НЕ
ORPD Логическое ИЛИ
XORPD Исключающее ИЛИ
Инструкции сравнения упакованных (векторных) и скалярных операндов с плавающей точкой двойной точности в регистрах ХММ с помещением результата в операнд-приемник или регистр EFLAGS
CMPPD Сравнение векторное
CMPSD Сравнение скалярное
COMISD Упорядоченное сравнение скалярных чисел с помещением результата в биты регистра EFLAGS (если хоть один из операндов QNaN или SNaN, генерируется исключение #I и EFLAGS не модифицируется)
UCOMISD Неупорядоченное сравнение (то же, но исключение #I генерируется только в случае SNaN)
Инструкции перестановок и распаковки операндов с плавающей точкой двойной точности в регистрах ХММ
SHUFPD Перестановка элементов в упакованных операндах
UNPCKHPD Распаковка и чередование старших элементов (в приемнике собираются старшие части операндов)
UNPCKLPD Распаковка и чередование младших элементов (в приемнике собираются младшие части операндов)
Инструкции преобразований в формат и из формата упакованных и скалярных чисел с плавающей точкой двойной точности
CVTPD2PI Преобразование упакованных чисел с плавающей точкой в упакованные целые (двойные слова)
CVTTPD2PI Преобразование с усечением упакованных чисел с плавающей точкой двойной точности в упакованные целые (двойные слова)
CVTP12PD Преобразование упакованных целых (двойных слов) в упакованные числа с плавающей точкой двойной точности
CVTPD2DQ Преобразование упакованных чисел с плавающей точкой в упакованные целые (двойные слова)
CVTTPD2DQ Преобразование с усечением упакованных чисел с плавающей точкой двойной точности в упакованные целые (двойные слова)
CVTDQ2PD Преобразование упакованных 32-битных целых в упакованные числа с плавающей точкой двойной точности
CVTPS2PD Преобразование упакованных чисел с плавающей точкой одинарной точности в числа двойной точности
CVTPD2PS Преобразование упакованных чисел с плавающей точкой двойной точности в числа одинарной точности
CVTSS2SD Преобразование скалярного числа с плавающей точкой одинарной точности в число двойной точности
CVTSD2SS Преобразование скалярного числа с плавающей точкой двойной точности в число одинарной точности
CVTSD2SI Преобразование скалярного числа одинарной точности в 32-битное целое
CVTTSD2SI Преобразование с усечением скалярного числа двойной точности в 32-битное целое
CVTS12SD Преобразование 32-битного целого в число двойной точности
Инструкции преобразований с числами одинарной точности
CVTDQ2PS Преобразование упакованных 32-битных целых в упакованные числа с плавающей точкой одинарной точности
CVTPS2DQ Преобразование упакованных чисел одинарной точности в числа двойной точности
CVTTPS2DQ Преобразование с усечением упакованных чисел одинарной точности в числа двойной точности
Целочисленные 128-битные SIMD-инструкции
MOVDQA Пересылка выровненного 128-битного операнда
MOVDQU Пересылка невыровненного 128-битного операнда
MOVQ2DQ Пересылка 64-битного целого из ММХ в ХММ
MOVDQ2Q Пересылка 64-битного целого из ХММ в ММХ
PMULUDQ Умножение упакованных беззнаковых 32-битных целых
PADDQ Сложение упакованных 64-битных целых
PSUBQ Вычитание упакованных 64-битных целых
PSHUFLW Перестановка упакованных младших слов
PSHUFHW Перестановка упакованных старших слов
PSHUFD Перестановка упакованных двойных слов
PSLLDQ Логический сдвиг 64-битных чисел влево
PSRLDQ Логический сдвиг 64-битных чисел вправо
PUNPCKHQDQ Распаковка старших 64-битных чисел
PUNPCKLQDQ Распаковка младших 64-битных чисел Управление кэшированием
CLFLUSH Очистка и инвалидация строки кэша (всех уровней), связанной с указанным операндом в памяти
LFENCE Упорядочивание операций загрузки из памяти
MFENCE Упорядочивание операций загрузки и записи
PAUSE Улучшение выполнения цикла ожидания
MASKMOVDQU Выборочная запись байтов из ХММ в память, минуя кэш
MOVNTPD Запись пары упакованных чисел из ХММ в память, минуя кэш
MOVNTDQ Запись 128-битного числа из ХММ в память, минуя кэш
MOVNTI Запись двойного слова из регистра общего назначения в память, минуя кэш
Инструкции 3DNow!, появившиеся с процессорами AMD K6-2, поддерживаются всеми последующими процессорами AMD и некоторыми другими процессорами.
Процессоры Intel этот набор не поддерживают, хотя в SSE имеются инструкции, совпадающие с частью инструкций 3DNow!. В процессорах Athlon расширение 3DNow! получило дополнительные инструкции для сигнальных процессоров. Целочисленные инструкции ММХ и управления кэшированием совпадают с одноименными инструкциями SSE. В данной работе инструкции 3DNow! не рассмотрены, так как не относятся к инструкциям процессоров Pentium 3,4.
Похожие работы
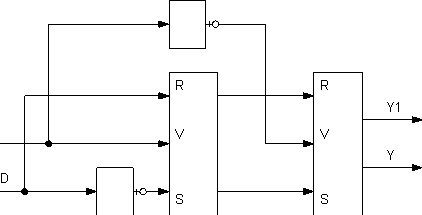
... Это почти все что касается самого общего рассказа о процессорах - почти любая операция может быть выполнена последовательностью простых инструкций, подобных описанным. 2.2. Алгоритм работы процессора Весь алгоритм работы процессора можно описать в трех строчках НЦ | чтение команды из памяти по адресу, записанному в СК | увеличение СК на длину прочитанной команды | ...
... руки журналистов называют «королем» системного блока, единовластно повелевающим всеми его ресурсами. Но уследить абсолютно за всем, что происходит в его «королевстве», даже шустрый процессор не в состоянии — королевская занятость разбрасываться не позволяет. И тогда на помощь «королю» приходят «наместники» — специализированные микропроцессоры-чипы по обработке, например, обычной и трехмерной ...
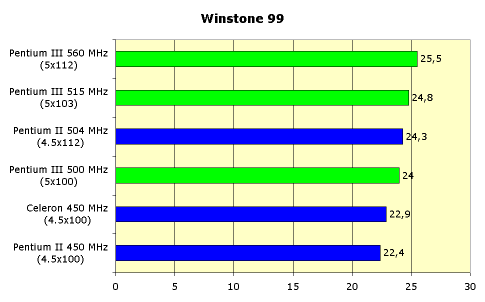
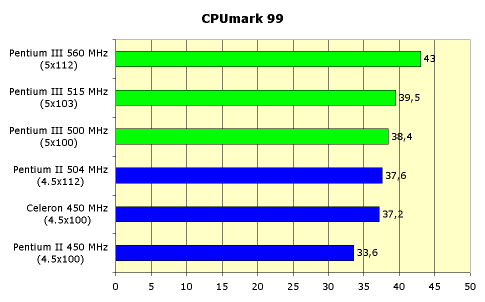
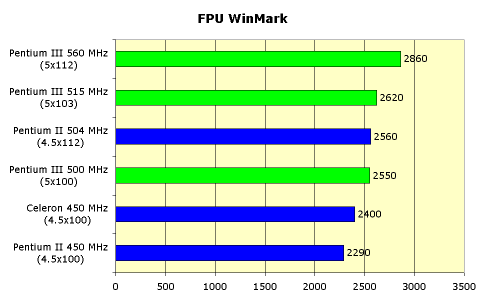
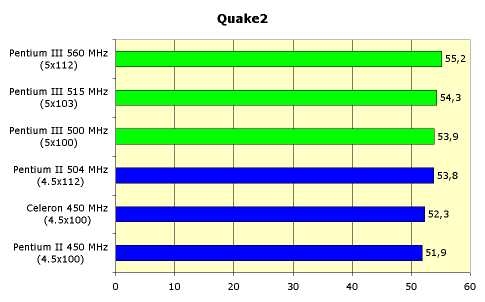
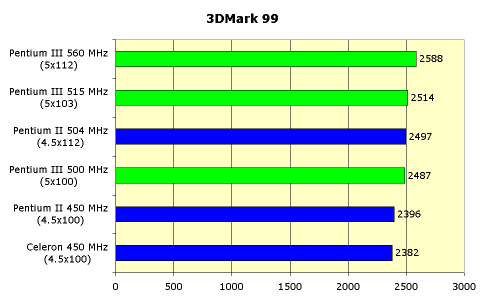
... потокового доступа к памяти. Однако эти изменения не дают никаких особых преимуществ в производительности, а носят скорее косметический характер. Мы же озаботимся вопросом практического функционирования процессора Intel Pentium III. Во-первых, необходимо иметь в виду, что для запуска системы на новом процессоре новая системная плата не требуется. Нужна всего-навсего обновленная версия BIOS, ...


... : -производитель чипсет, если возможно – модель материнской платы; -тактовые частоты процессора, памяти, системных шин; -названия, параметры работы всех системных и периферийных устройств; -расширенная информация о процессоре, памяти, жестких дисках, 3D-ускорителе; -разнообразные параметры программной среды: ОС, драйверы, процессы, системные файлы и т.д.; -информация о поддержке видеокартой ...
0 комментариев